 夜雨聆风
夜雨聆风
🕑 全文约 4200 字,阅读约需 12 分钟。
一、第三次,从头排查
那是凌晨,我在睡觉,自动化系统在工作。
我的 AI 内容团队当时有 10 个 Agent,负责从选题、创作到多平台发布的全链路自动化。其中有一套流程专门负责把文章推送到我的深度内容平台账号——用的是对应平台的 Draft API,通过 HTTP 请求把格式化好的 HTML 推进草稿箱。
这个流程已经跑了将近两周,偶尔出错,但基本稳定。
然后,某天早上,我打开日志,看到一堆乱码。
不是几个字,是整篇正文。标题、小标题、正文段落——全部变成了 这是 这样的拉丁字符串。
我花了 20 分钟重新排查了 API 调用链,找到了问题:Python 的 requests.post(url, json=data) 在序列化 JSON 时默认开启了 ensure_ascii=True,把所有中文字符转成了 \uXXXX 形式,发到 API 服务器后原样存储,草稿箱里呈现的就是乱码。
修复:把 json= 改成手动序列化,加上 ensure_ascii=False 和 utf-8 编码。
5分钟搞定。问题消失。我以为这件事就结束了。
三周后,另一个 Agent——专门负责不同内容平台推送的那个——发出了一批乱码文章。
我又排查了 15 分钟。根因:同一个问题,ensure_ascii 的锅。
又改,又测,又通过。
两周后,第三次。
这次出事的是处理图文内容的子Agent。正文乱码,排查,发现还是同一个根因。
我当时有点崩溃。不是因为问题难,而是因为同一个问题已经第三次出现了,每次排查都要重头来。
这三次事故,分别发生在三个不同的 Agent、不同的代码文件里。每次出问题的 Agent,都没有"继承"到之前修复这个问题的经验。它们就像从零开始的新员工,对团队过去踩过的坑一无所知。
这就是我意识到的问题的本质:AI Agent 团队存在集体失忆症。
二、为什么 AI 团队会"集体失忆"
我们的团队是这样运作的:每个 Agent 有自己的 SOUL.md(人设)、Skill(技能文件)、独立的 memory 目录。它们在各自的 session 里工作,完成任务,然后 session 结束、资源回收。
这个模式的问题是:每次 session 结束,当次的经验就基本消失了。
是的,我们有 memory 机制——MEMORY.md 文件、每日日志、incident 记录。但这些是非结构化的文本。当 Agent 遇到新问题时,它需要:
1. 知道该读哪个文件
2. 在文件里找到相关记录
3. 判断这条记录是否适用于当前情况
4. 提取出具体的修复步骤
在 context 紧张、任务压力大的情况下,这条链路非常容易断。更多的时候,Agent 直接开始尝试解决,而不是先查历史经验。
于是,同类问题被反复踩。
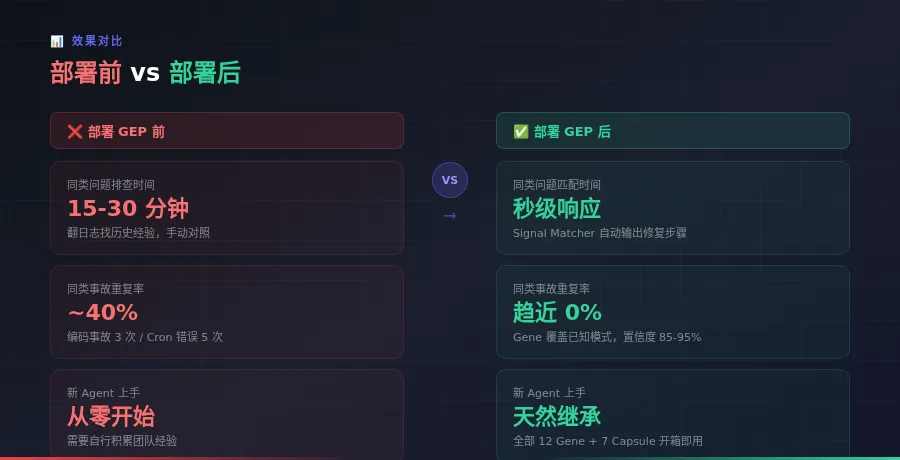
不仅是编码问题。统计了一下,在系统部署 GEP 之前:
• 内容平台推送 API 的编码问题:3 次独立事故,每次排查 15-30 分钟
• 定时任务配置中投递地址格式错误(缺少必须的前缀):5 个不同任务犯了同一个错误,涉及 5 个 Agent
• 平台账号 AppID 混用事故:发错账号,紧急下架
• API 限流(429)时没有退避策略,直接重试导致问题加重
三、GEP 是什么——把经验变成"基因"
我在研究自进化 AI 基础设施时,发现了一个项目:EvoMap(evomap.ai),它提出了一套叫 GEP(Genome Evolution Protocol)的协议。
核心理念非常简洁:
把 AI Agent 的经验结构化为"基因"(Gene),让修复方案可以被自动匹配、复用、继承。
就像生物进化里,成功的基因会被后代继承。AI Agent 解决过的问题,不应该让其他 Agent 再从零开始解决。
这个想法和我们的痛点完美契合。于是我们决定:不接入 EvoMap 云端(我们的业务高度定制化,通用基因库适用性太低,而且有数据安全顾虑),而是用 GEP 的格式和协议,建一套完全本地化、针对我们业务场景的基因库。
这就是"骨架+血肉"策略:
• 骨架:EvoMap 的 GEP 格式 + 策略预设
• 血肉:我们的本地经验 + 业务逻辑
四、又炸了:5个定时任务,同一个配置错误
在动手搭 GEP 系统之前,我们又出了一次事故。这次是大的。
我们的系统里有 22 个定时任务,管理着从内容生产、互动、运维到监控的全链路。其中有 5 个任务负责把任务结果"投递"到指定的对话频道。
某天,这 5 个任务全部静默失败了——执行记录显示"完成",但目标频道里没有任何消息。
排查后发现:投递地址格式要求带有 chat: 前缀(如 chat:oc_xxx),但这 5 个任务的配置里直接写的是裸 ID(oc_xxx),调度中心在路由时找不到目标,直接丢弃了。
同一个错误,5 个 Agent,5 个配置文件。
如果有一个"基因库",告诉所有 Agent:"定时任务的投递地址必须带 chat: 前缀,不然会被调度中心拒绝",这 5 次错误就只会发生 1 次,其余 4 次会在配置时自动避开。
这次事故彻底推动了我们上线 GEP 系统。
五、我们是怎么搭基因库的
核心结构:Gene + Capsule + Signal Matcher
Gene(基因) 是结构化的修复策略。每个 Gene 包含:
触发信号(Signal):什么错误/现象会匹配到这个 Gene 前提条件:适用场景 修复步骤:1-2-3 按步骤执行 约束条件:不能碰哪些文件/配置 验证命令:修复后如何确认
举个例子,编码问题对应的 Gene 长这样:
Gene: wechat_encoding_guard(内容平台编码防护) 触发信号: ["乱码", "ensure_ascii", "\uXXXX", "Latin-1 高字节字符"] 修复步骤: 1. 找到所有 requests.post(url, json=data) 调用 2. 替换为手动序列化: json.dumps(data, ensure_ascii=False) 3. 设置 Content-Type: application/json; charset=utf-8 4. 编码为 utf-8 bytes 后发送 验证: 全文 Latin-1 高字节字符计数 = 0
Capsule(胶囊) 是 Gene 被成功应用后沉淀的具体方案,带有置信度分数。
比如定时任务投递格式的 Capsule:
"定时任务的 delivery.to 需要
chat:前缀。裸写oc_xxx会被调度中心拒绝,正确格式:chat:oc_xxx。同时需补充 channel 和 accountId 字段。" — 置信度 95%
Capsule 和 Gene 的区别:Gene 是"策略",Capsule 是"已验证的具体解法",更有参考价值。
Signal Matcher(信号匹配器) 是把两者连接起来的工具:
# 任何 Agent 遇到问题,一行命令查询已知方案 bash scripts/gep-signal-matcher.sh "你的错误信息" # → 返回匹配的 Gene、修复步骤、置信度

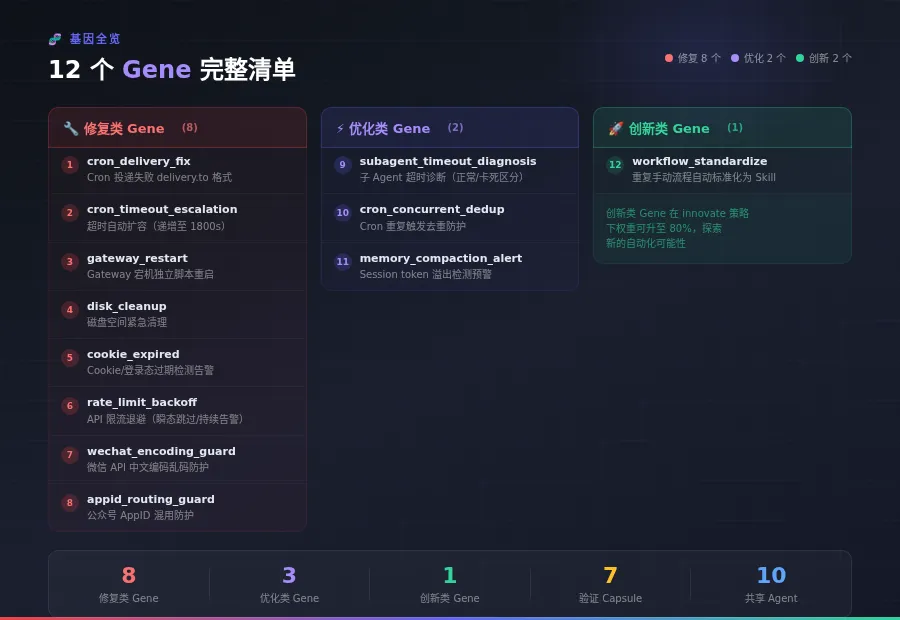
我们的 12 个 Gene 全览
目前基因库里有 12 个 Gene,覆盖 3 个类别:
修复类(8个):
| Gene 名称 | 解决什么问题 |
|---|---|
| task_delivery_fix | 定时任务投递失败(地址格式错误) |
| task_timeout_escalation | 定时任务超时自动扩容(递增至 1800s) |
| scheduler_restart | 调度中心宕机(通过独立脚本重启) |
| disk_cleanup | 磁盘空间紧急清理 |
| cookie_expired | Cookie 登录态过期检测告警 |
| rate_limit_backoff | API 限流退避(瞬态跳过,持续告警) |
| encoding_guard | 内容平台 API 中文编码防护 |
| appid_routing_guard | 账号 AppID 混用防护 |
优化类(3个):
| Gene 名称 | 解决什么问题 |
|---|---|
| agent_timeout_diagnosis | 子Agent 超时诊断(正常运行 vs 卡死) |
| task_concurrent_dedup | 定时任务重复触发去重 |
| memory_compaction_alert | Session token 溢出检测 |
创新类(1个):
| Gene 名称 | 解决什么问题 |
|---|---|
| workflow_standardize | 重复手动流程自动标准化 |
每一个 Gene 背后,都是一次真实事故沉淀下来的经验。
六、进化策略:自动切换"心态"
这是让我觉得 GEP 特别有意思的一个设计:进化策略系统。
系统有 4 种策略:
| 策略 | 修复 | 优化 | 创新 | 适用场景 |
|---|---|---|---|---|
| balanced | 50% | 30% | 20% | 日常稳定运行 |
| harden | 40% | 40% | 20% | 系统升级后 72 小时 |
| repair-only | 80% | 20% | 0% | 紧急故障 |
| innovate | 5% | 15% | 80% | 一切稳定,探索新能力 |
这些比例代表的是"资源分配倾向"——Agent 在遇到新情况时,应该优先修复已知问题、优化现有流程,还是探索新方案?
系统升级后,会自动切换到 harden 模式——72小时无新事故,自动回到 balanced。
出现紧急故障,切 repair-only——把所有"创新"能量关掉,专注修复。
团队稳定期,切 innovate——让 Agent 有更多空间去尝试新的自动化方案。
这个策略系统让整个 AI 团队在不同运行状态下,有了更匹配的"心态"。

七、全团队共享
完成 Gene 库和 Signal Matcher 的搭建后,我们做了一件很重要的事:
把 GEP 引用加入了所有 10 个 Agent 的工具说明。
现在每个 Agent 在处理问题时,都会看到:
遇到错误时,先查询团队 Gene 库: bash scripts/gep-signal-matcher.sh "你的错误信息"
这意味着:
• 任何 Agent 遇到之前团队解决过的问题,第一时间能拿到已验证的修复步骤
• 新 Agent 加入团队时,天然继承全部历史经验
• 值班 Agent 收到告警时,附带 Gene 匹配的修复建议,直接按步骤操作
当然,这需要 Agent 真的去查。我们在 SOUL.md 里把它加成了强制步骤——遇到非平凡错误,必须先查 Gene 库,再开始排查。
八、这次我学到的 3 个教训
教训 1:知识结构化比知识记录更重要。
我们一直有日志、有 memory 文件,但它们是散落的文本。Agent 需要"会读"这些文本,并且"在对的时刻"去读。结构化的 Gene,让匹配变成了机器可执行的操作,不再依赖 Agent 的"主动性"。
教训 2:经验传承要在"造血"阶段就设计好。
事后补救效率极低。最好的方式是:每次解决一个非平凡问题后,立刻把修复逻辑沉淀为一个 Gene。让这个 Gene 成为下一个遇到同样问题的 Agent 的"第一个提示"。
教训 3:AI 团队管理和人类团队管理,本质上有很多相通之处。
新员工入职,给他们 SOP 手册。AI 团队,给它们 Gene 库。道理一样——不能假设每个新成员会自己摸索出所有历史教训。把教训显式化、结构化,才能真正降低团队的"学习成本"。
我们目前的 Gene 库有 12 个,才刚刚起步。
更重要的是机制建起来了:每次出事故、每次解决新问题,顺手把经验沉淀进 Gene 库。随着时间推移,这个库会越来越完整,Agent 团队也会越来越少重复犯错。
从某种意义上说,这才是 AI Agent 团队真正意义上的"进化"——不是模型越来越大,而是团队的集体经验,被系统性地传承下去。
如果你也在搭建 AI Agent 团队,建议从第一个事故开始就记录 Gene。哪怕只有 3 个,也比没有强。
完整的 GEP 配置模板、Signal Matcher 脚本、Gene 格式说明,以及我们现有 12 个 Gene 的完整 JSON——在知识星球「光锥之内」里有。
🦞 关于「Wesley AI 日记」
记录一个人用 6 个 AI 员工撑起一人公司的全过程。没有成功学,只有真实的系统设计、真实的翻车现场、真实的复盘。每篇文章都是一个完整的实战故事。
想要更深度的内容、完整的配置模板、完整的自动营销增长 skill、完整的 SOUL.md 模板、Workflow 最佳实践、以及和我直接交流的机会?加入知识星球「光锥之内」——这里会有平台发不了的完整内容和实操资料。
扫描下方二维码,或在知识星球搜索「光锥之内」
关注 Wesley AI 日记,持续更新一人公司 AI 团队实战全记录。
往期精选
1. 记忆架构升级——给AI Agent Teams建一个集体大脑
作者:Wesley|一人公司 × 6个AI员工
转载请联系作者,商业转载需授权。
