 夜雨聆风
夜雨聆风全网都在教你怎么用 OpenClaw,但很少有人认真拆解过它的架构设计。今天我们不聊使用技巧,聊聊这个四个月狂揽 34 万 Star 的项目,到底做对了什么。
cover:一只手绘风格的龙虾站在服务器机房中央,周围环绕着 WhatsApp、Telegram、Slack 等消息平台的图标,龙虾举着一把钥匙,钥匙上写着"Your Data"
一个"被逼出来"的项目
Peter Steinberger 是一个有意思的人。
他在 2011 年创办了 PSPDFKit——一个 PDF SDK,靠纯自举(没拿一分钱 VC)做到了服务 10 亿台设备,客户包括苹果和 Dropbox。2021 年 Insight Partners 投了 1 亿欧元,他功成身退,然后经历了严重的 burnout,订了一张飞马德里的单程票,彻底离开了代码世界。
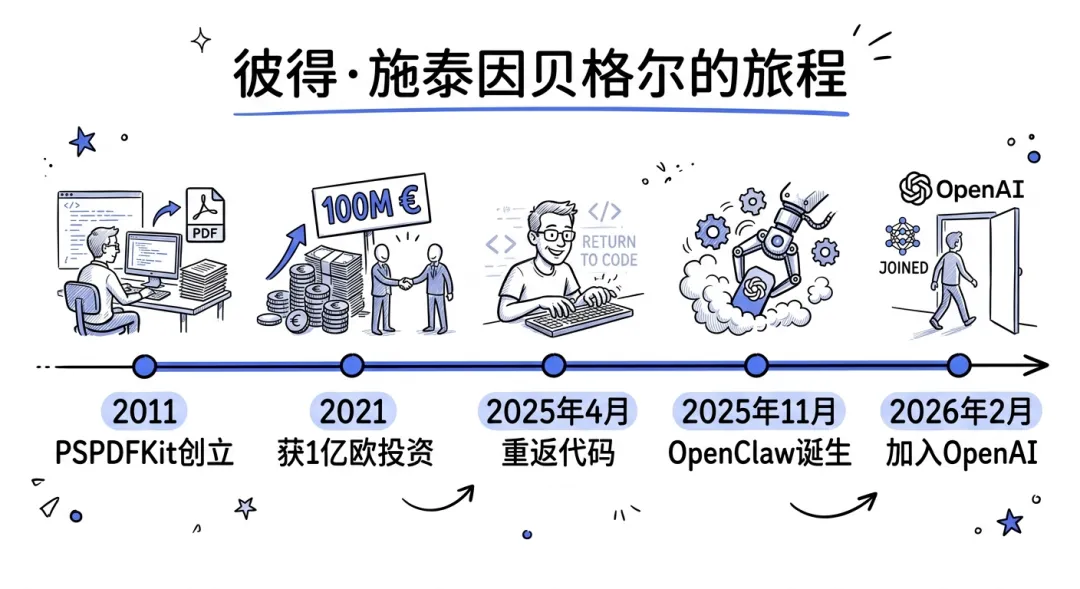
img01:Peter Steinberger 的创业时间线,从2011年PSPDFKit到2025年重返代码到2025年11月OpenClaw诞生
2025 年 4 月,他开始用 AI 工具消磨时间。写了 43 个小项目,都不满意。直到第 44 个——他想要一个永远在线的 AI 助手,能监控 WhatsApp、管理邮件、控制浏览器、自主执行任务。
"我很恼火这个东西居然还不存在,所以我就把它 prompt 出来了。"
2025 年 11 月 24 日,OpenClaw 的第一行代码被提交到 GitHub。四个月后,它成了 GitHub 历史上增长最快的开源项目之一——第一周就拿下了 14.5 万 Star 和 200 万访问量。
这不是因为营销做得好,而是因为它解决了一个真实的痛点:你的 AI 助手不应该只存在于一个聊天窗口里。
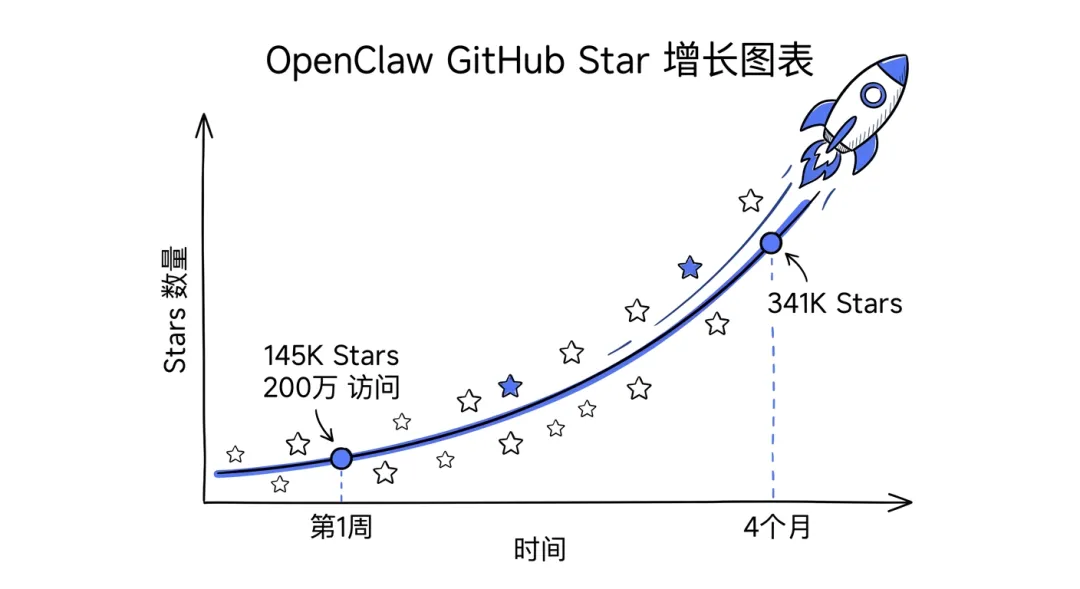
img02:OpenClaw的增长曲线,第一周145K stars,四个月341K stars
"Brain-Body-Soul":一个哲学味很浓的架构模型
OpenClaw 的架构建立在一个核心洞察之上:
智能可以租,但身体和记忆必须是你的。——Intelligence can be rented. But the body and the memory must be yours.
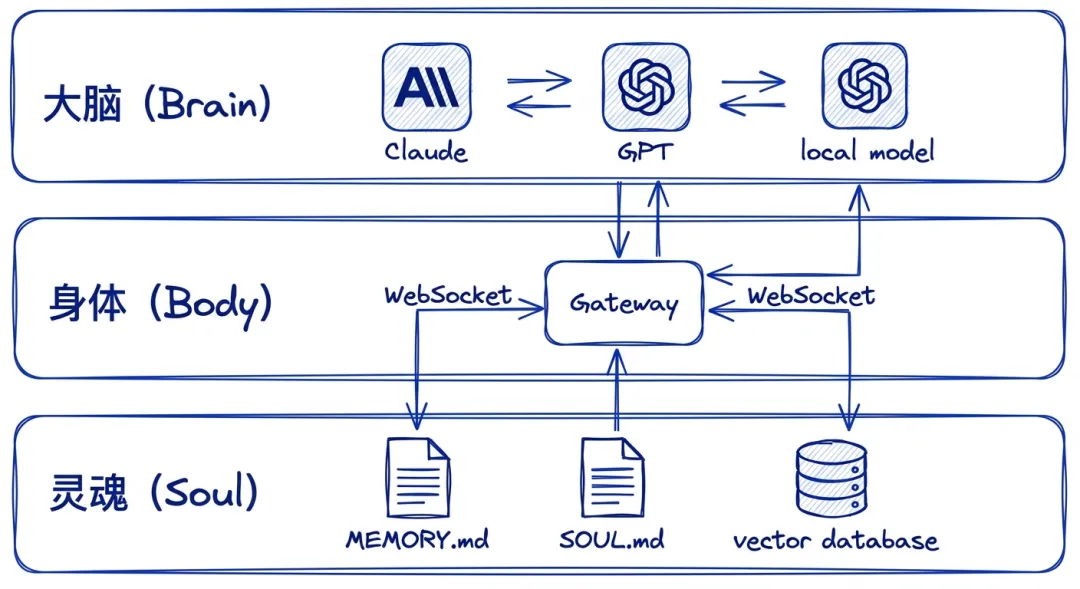
这句话不是口号,它直接决定了整个系统的分层设计。OpenClaw 把自己拆成了三层:Brain(大脑)、Body(身体)、Soul(灵魂)。
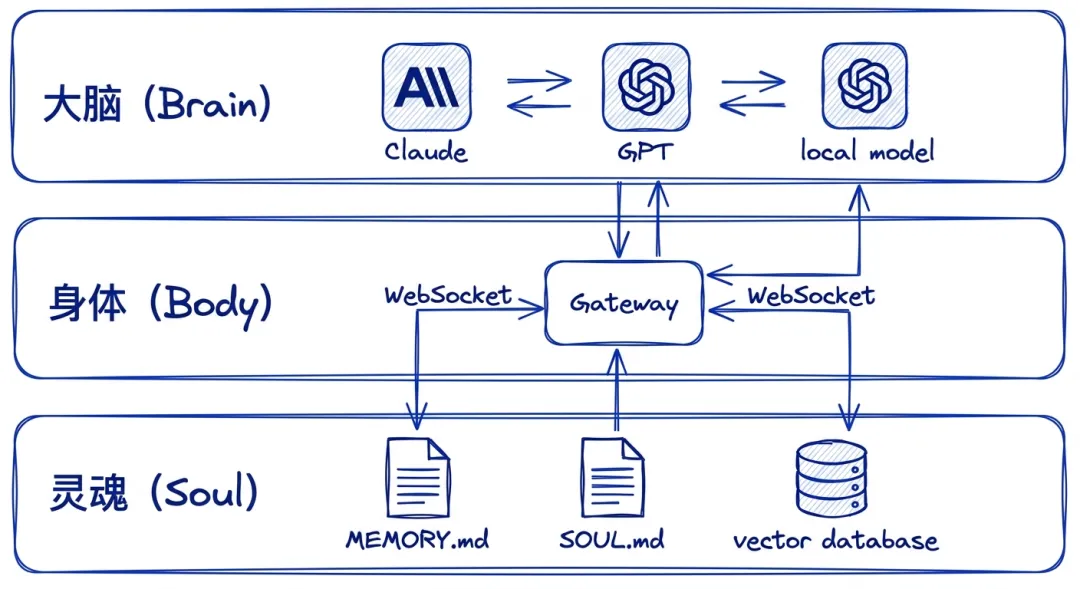
img03:Brain-Body-Soul 三层架构图,Brain层是可替换的LLM,Body层是本地Gateway,Soul层是持久化记忆
Brain:可替换的智能
在 OpenClaw 的世界观里,大模型是消耗品。今天用 Claude,明天换 GPT,后天跑本地模型——都行。系统内置了智能故障切换机制,当一个模型提供商限流或宕机时,自动切换到备用模型。
这个设计选择的深意在于:你的数据、记忆、工作流不应该被任何一个模型绑架。模型是租来的工具,不是你的身份。
Body:本地拥有的执行层
这是 OpenClaw 最核心的部分——Gateway。一个跑在 localhost:18789 上的 Node.js 长驻进程,通过 WebSocket 协议统一管理所有会话、通道、工具和事件。
每一条消息、每一次工具调用、每一个安全检查,都要经过 Gateway。它是整个系统的控制平面。
Soul:持久化的记忆
- ●
MEMORY.md:长期记忆,记录你的偏好、过去的决策 - ●
SOUL.md:Agent 的人格边界和行为准则 - ●
memory/YYYY-MM-DD.md:每日交互日志 - ●向量数据库:70% 语义搜索 + 30% 关键词匹配的混合检索
记忆跨模型存续——你换了大脑,但灵魂还在。这是 OpenClaw 和绝大多数 AI 产品最本质的区别。
img04:记忆系统的混合检索机制,左侧向量语义搜索70%,右侧关键词匹配30%,汇合后输出上下文
Gateway:一个进程搞定一切
Gateway 的设计是整个 OpenClaw 架构中最值得学习的部分。
它不是微服务,不是分布式系统,就是一个 Node.js 进程。但这个进程要同时处理 29 个以上的消息渠道、管理多个并发会话、编排工具调用、执行安全检查。它是怎么做到的?
WebSocket 协议设计
Gateway 的通信协议非常精简:
- ●连接帧:第一帧必须是
connect,携带设备身份信息 - ●请求/响应:
{type:"req", id, method, params}→{type:"res", id, ok, payload} - ●事件流:
{type:"event", event, payload, seq?} - ●幂等键:所有有副作用的方法(
send、agent)都需要幂等键,Gateway 维护一个短时效的去重缓存
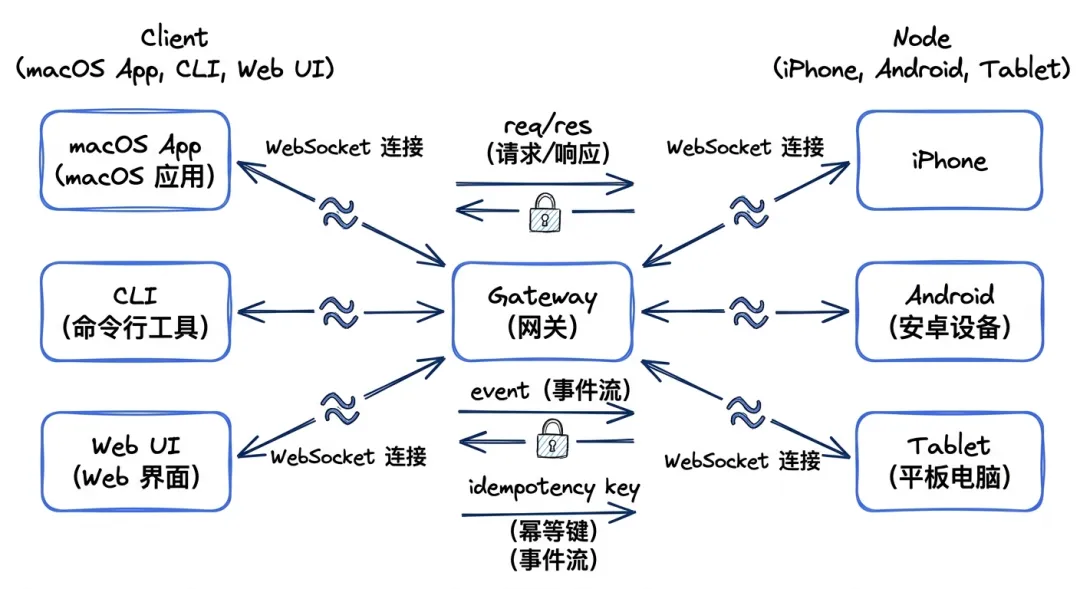
img05:Gateway WebSocket 协议的消息流转图,Client和Node通过WS连接到Gateway,展示req/res/event三种消息类型
这个协议设计有两个巧妙之处。第一,它统一了客户端(macOS 应用、CLI、Web UI)和设备节点(手机、平板)的通信方式。第二,幂等键的设计让网络重试变得安全——消息不会因为 WebSocket 断线重连而被重复执行。
Lane-Based 并发模型
这是我认为 OpenClaw 最优雅的设计之一。
Gateway 内部有四条序列化队列(Lane):Session Lane、Global Lane、Cron Lane、Subagent Lane。
同一个会话内的消息绝不交错——它们按顺序在 Session Lane 中排队处理。但不同会话之间完全并行,互不阻塞。
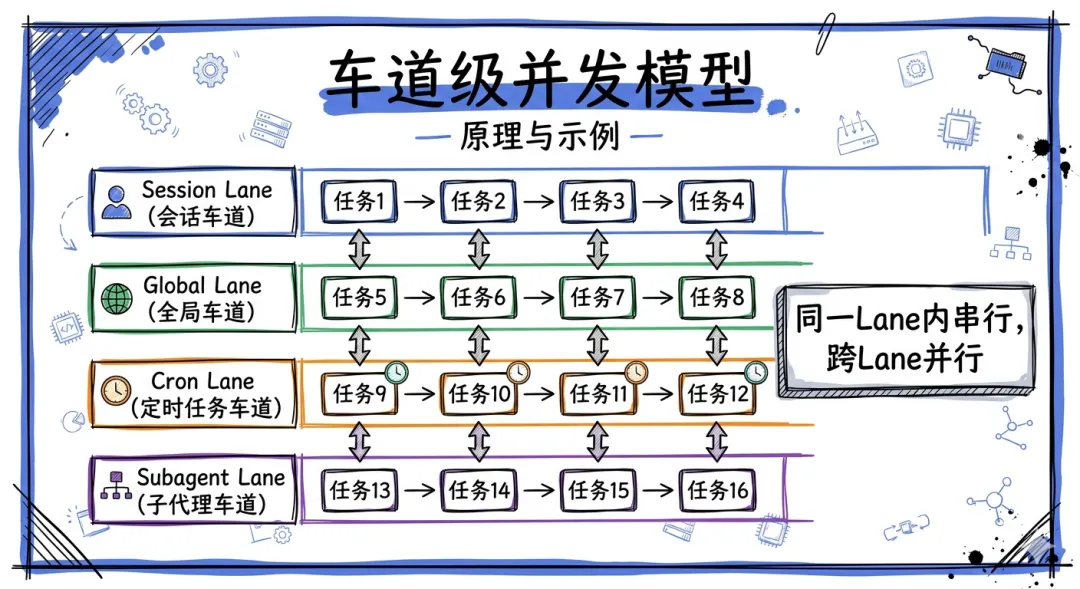
img06:四条Lane的并发模型图,Session Lane串行处理,跨Lane并行,用不同颜色区分四条Lane
这个模型的好处显而易见:
- ●不需要复杂的锁机制——每条 Lane 内部是串行的
- ●不会有竞态条件——同一个用户的消息按序处理
- ●吞吐量不受限——不同用户/会话/定时任务并行跑
对于个人 AI 助手这个场景,这是一个恰到好处的并发方案——不过度设计,但也不妥协性能。
29+ 渠道适配:一套代码,全平台覆盖
OpenClaw 支持的消息渠道数量令人咋舌:WhatsApp、Telegram、Slack、Discord、Google Chat、Signal、iMessage、IRC、Microsoft Teams、Matrix、飞书、LINE、Mattermost、微信……总共 29 个以上。
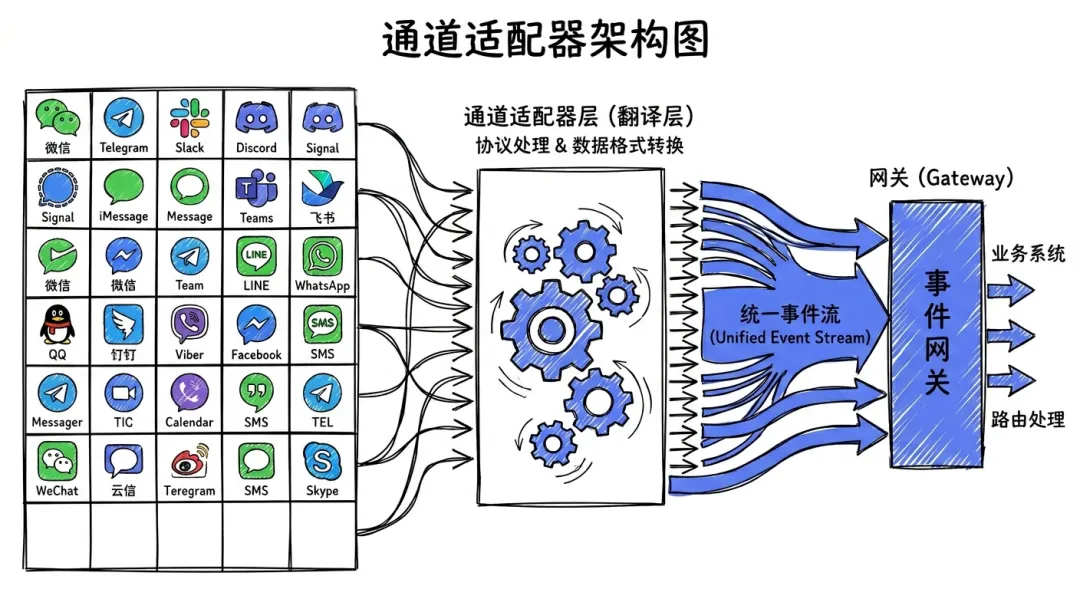
img07:消息渠道适配架构,29个平台图标在左侧,通过Channel Adapter层汇聚到中间的统一事件流,再流入Gateway
这怎么做到的?答案是渠道适配器模式。
每个消息平台都有自己的 SDK 和协议怪癖——WhatsApp 用 Baileys,Telegram 用 grammY,Slack 用 Bolt,Discord 用 discord.js。OpenClaw 为每个平台写了一个适配器,把平台特有的消息格式、认证方式、回调机制,全部翻译成统一的事件流。
核心代码只处理一种事件格式。新增一个渠道?写一个适配器就行,不需要改核心逻辑。
这个模式并不新鲜,但 OpenClaw 把它做到了极致——29 个适配器,每个都处理了各平台的边界情况,这是大量工程细节的积累。
设备配对:从 IoT 借来的安全模型
OpenClaw 的设备管理借鉴了消费级 IoT 产品的配对模型,这在 AI 助手领域非常少见。
工作流程是这样的:
- 新设备(比如你的 iPhone)通过 WebSocket 连接到 Gateway
- Gateway 识别到这是未知设备,要求配对审批
- 你在已信任的设备(比如 Mac)上确认配对
- Gateway 为新设备签发设备令牌
- 后续连接使用签名验证(v3 签名绑定了
platform+deviceFamily)
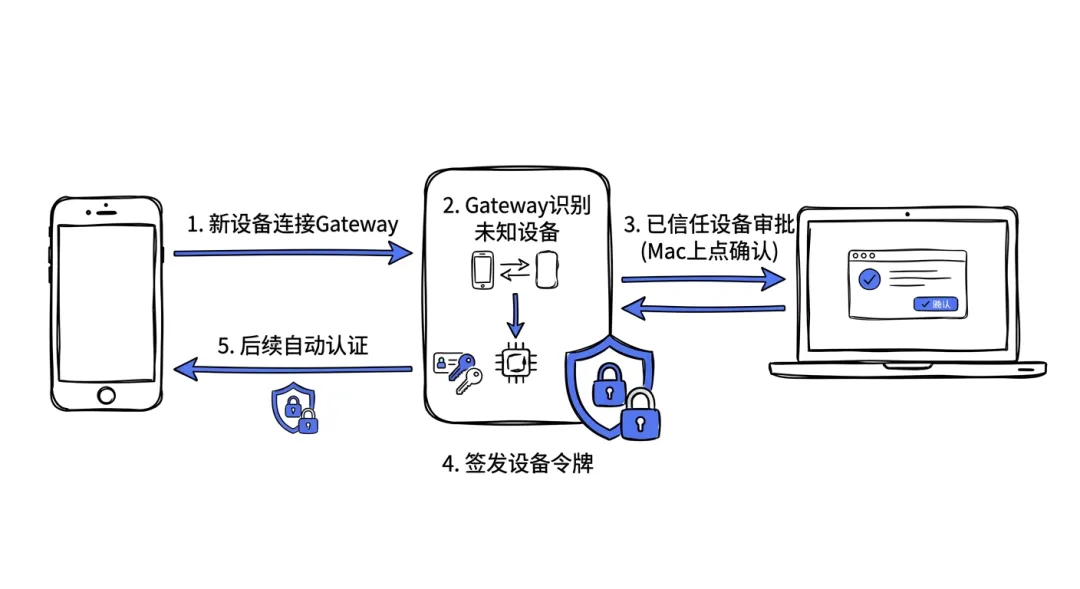
img08:设备配对流程图,新设备发起连接→Gateway识别未知设备→已信任设备审批→签发令牌→后续自动认证
本地回环(127.0.0.1)连接可以自动审批,远程连接必须经过人工确认。这个设计既保证了本地开发的便利性,又为远程访问设立了安全门槛。
类型系统的跨语言传播
OpenClaw 的协议定义用了一个很聪明的链条:TypeBox → JSON Schema → Swift 模型自动生成。
简单来说:
- 用 TypeBox(TypeScript 库)定义协议的类型和结构——这是唯一的真相源
- 从 TypeBox 自动生成 JSON Schema
- 从 JSON Schema 自动生成 Swift 数据模型(用于 macOS/iOS 原生应用)
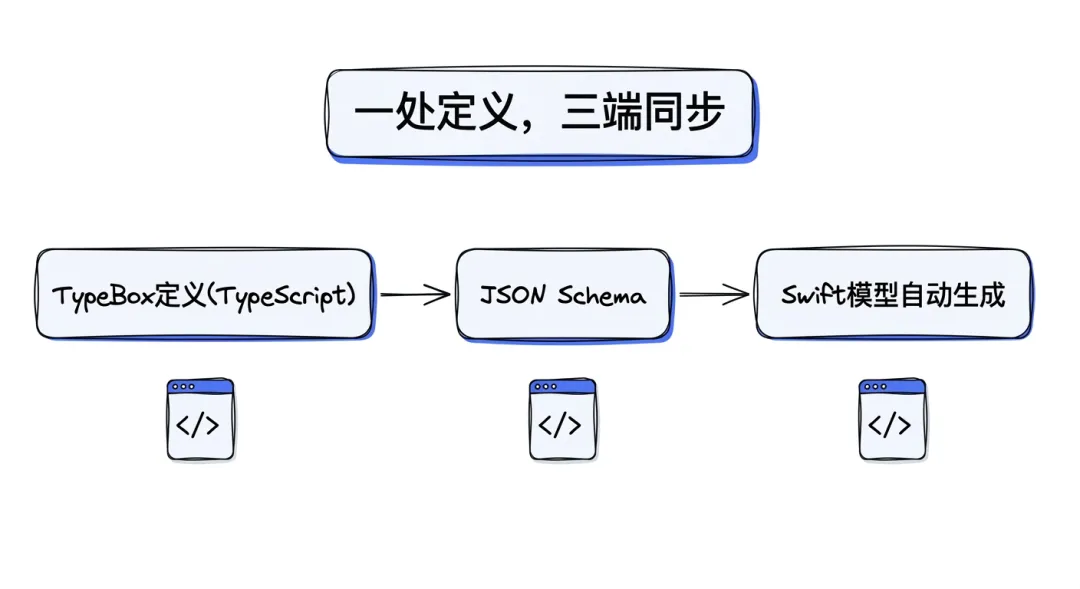
img09:类型系统传播链,TypeBox定义(TS) → JSON Schema → Swift模型生成,一处定义三端使用
这意味着:改一处类型定义,TypeScript、JSON Schema、Swift 三端同步更新。不会出现"API 改了但客户端没跟上"的经典灾难。
这个模式对任何需要跨语言类型安全的项目都有参考价值。比如你有一个 TypeScript 后端和一个 Swift 前端,完全可以复制这套工具链。
MCP 桥接:保持核心精简的智慧
OpenClaw 对 MCP(Model Context Protocol)的支持方式也很有意思——它没有把 MCP 运行时内置到核心中,而是通过一个外部桥接器 mcporter 来连接。
为什么?
- ●保持核心精简:MCP 协议还在快速迭代,如果内置到核心,每次协议更新都要改核心代码
- ●减少耦合:MCP Server 的添加/删除/更新不需要重启 Gateway
- ●故障隔离:某个 MCP Server 崩溃不会拖垮整个系统
这是一个很经典的架构取舍——用一点运行时开销,换来了显著的维护性和稳定性提升。
Skill 即 Markdown:让 AI 自己能读懂能力描述
OpenClaw 的技能系统做了一个很有意思的选择:技能定义就是 Markdown 文件。
每个技能是一个 SKILL.md,里面用人类可读的自然语言描述这个技能能做什么、怎么调用、有什么限制。ClawHub 社区已经积累了 4000+ 个这样的技能。

img10:Skill即Markdown的设计理念,左侧是SKILL.md文件内容,右侧是人类和AI都能读懂的双向箭头
这个设计的精妙之处在于:
- ●人类友好:打开就能看,不需要学新的 DSL 或配置格式
- ●LLM 友好:大模型天然擅长理解 Markdown,不需要额外的解析逻辑
- ●社区友好:贡献一个技能的门槛极低,写一个 Markdown 文件就行
对比其他 Agent 框架动辄要写 JSON Schema、YAML 配置、Python 类——OpenClaw 的做法简单得让人不太相信它能 work。但 4000+ 社区技能的数量证明了它的可行性。
那些值得正视的代价
任何架构选择都有代价,OpenClaw 也不例外。
单点故障:Gateway 跑在你的设备上,电脑关机 = 助手下线。没有高可用,没有故障转移。对于"个人助手"的定位来说,这是可以接受的,但它确实意味着 OpenClaw 不适合企业级 7×24 场景。
安全争议:2026 年 2 月,安全研究人员发现了 1100 多个暴露在公网的 Gateway 实例。问题出在 Gateway 默认信任 127.0.0.1 的请求,但很多用户在前面加了反向代理,导致认证被绕过。API 密钥和 OAuth 令牌以明文存储在 ~/.openclaw/openclaw.json 中,记忆文件也是未加密的纯文本 Markdown。
Steinberger 本人的态度很坦诚,他说运行 OpenClaw 是 "spicy"(刺激的)。项目的 SECURITY.md 明确将 Prompt 注入和公网暴露标记为"超出范围"。
这不是疏忽,而是有意识的取舍——在个人项目的早期阶段,把工程资源集中在功能迭代上,安全加固交给社区和后续版本。你可以不同意这个优先级,但至少它是透明的。
从架构看趋势:AI 助手的下一站
OpenClaw 的架构设计,其实折射出整个 AI 助手领域正在发生的几个范式转移:
从"云端封闭"到"本地优先"。传统 AI 助手(Siri、Alexa、Google Assistant)把一切放在云端,你的数据、你的对话历史、你的偏好设置——全在别人的服务器上。OpenClaw 反其道而行:Gateway 跑在本地,记忆存在本地,模型可以选本地的。
从"单一入口"到"全渠道覆盖"。你不应该为了和 AI 对话而特意打开某个 App。AI 应该出现在你已经在用的地方——WhatsApp、Slack、邮件、终端。OpenClaw 的 29 个渠道适配器就是这个理念的工程实现。
从"模型即产品"到"模型即组件"。当模型变成可替换的组件,真正的竞争优势就从"谁的模型更好"转移到了"谁的执行层和记忆层更完善"。OpenClaw 的 Brain-Body-Soul 架构是这个趋势的最佳注脚。
341K Star 不是偶然。OpenClaw 之所以引爆,是因为它在正确的时间,用正确的架构,回答了一个越来越多人在问的问题:
AI 时代,我的数字生活应该被谁掌控?
OpenClaw 的答案是:你自己。
你怎么看?欢迎留言聊聊你理想中的 AI 助手应该长什么样。
