 夜雨聆风
夜雨聆风
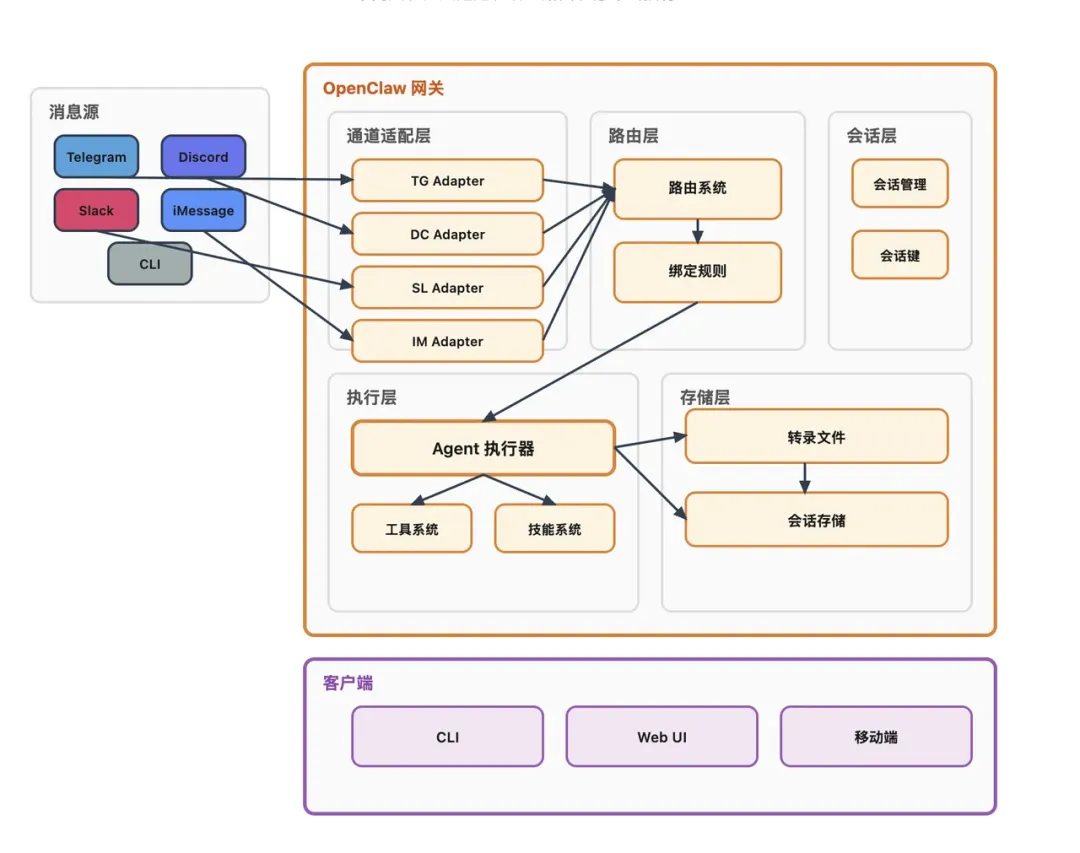
OpenClaw 怎么跑的

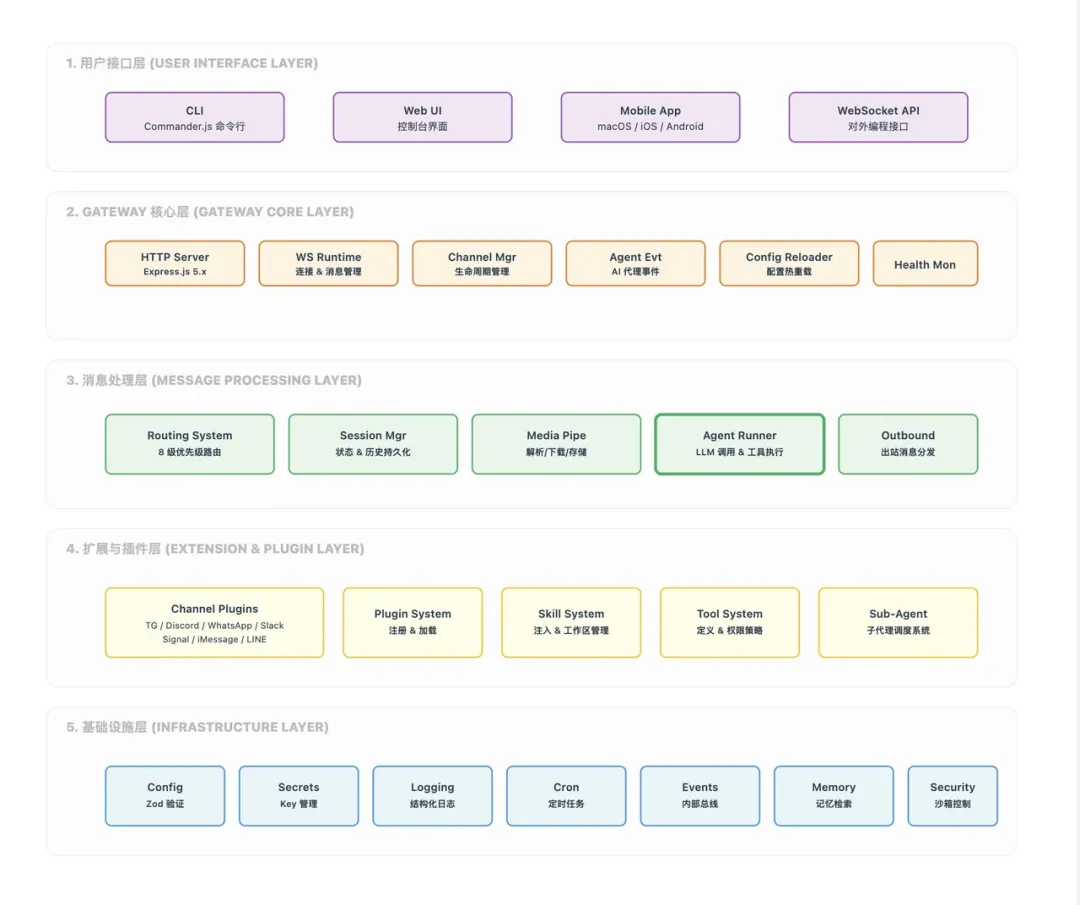



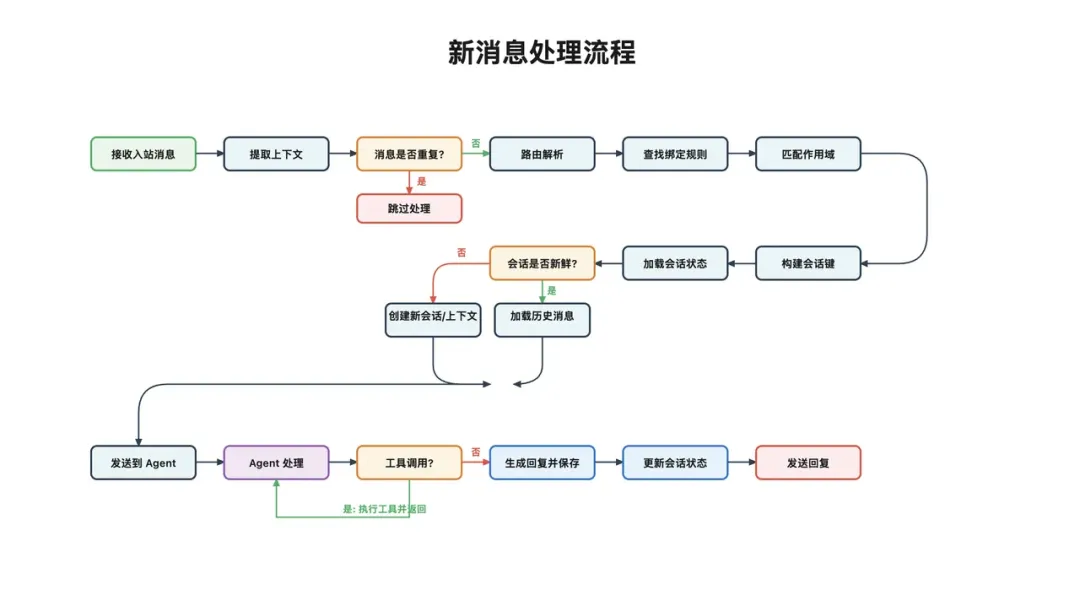
消息进门

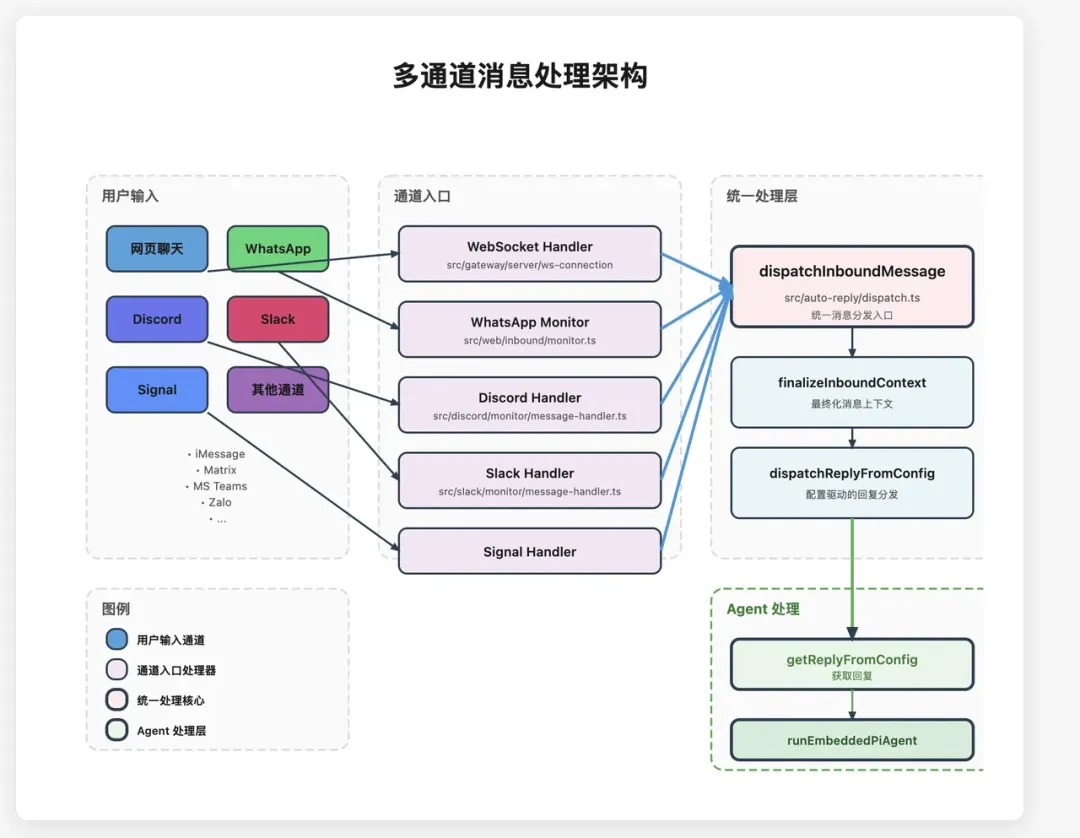
每个外部渠道都有一个专属适配器插件,把原始消息清洗成统一的内部对象,MsgContext。大概长这样:
interface MsgContext { Body: string; BodyForAgent?: string; BodyForCommands?: string; RawBody?: string; SessionKey: string; Provider: string; Surface?: string; ChatType?: "direct" | "group"; SenderId?: string; SenderName?: string; SenderUsername?: string; OriginatingChannel?: string; OriginatingTo?: string; AccountId?: string; MessageThreadId?: string; CommandAuthorized?: boolean; MessageSid?: string; GatewayClientScopes?: string[];}这里最关键是统一抽象。
也就是说,不管消息是从哪个犄角旮旯来的,进了网关之后,都会变成这个标准格式。后面的流程只需要对着 MsgContext 干活,完全不用操心来源平台。
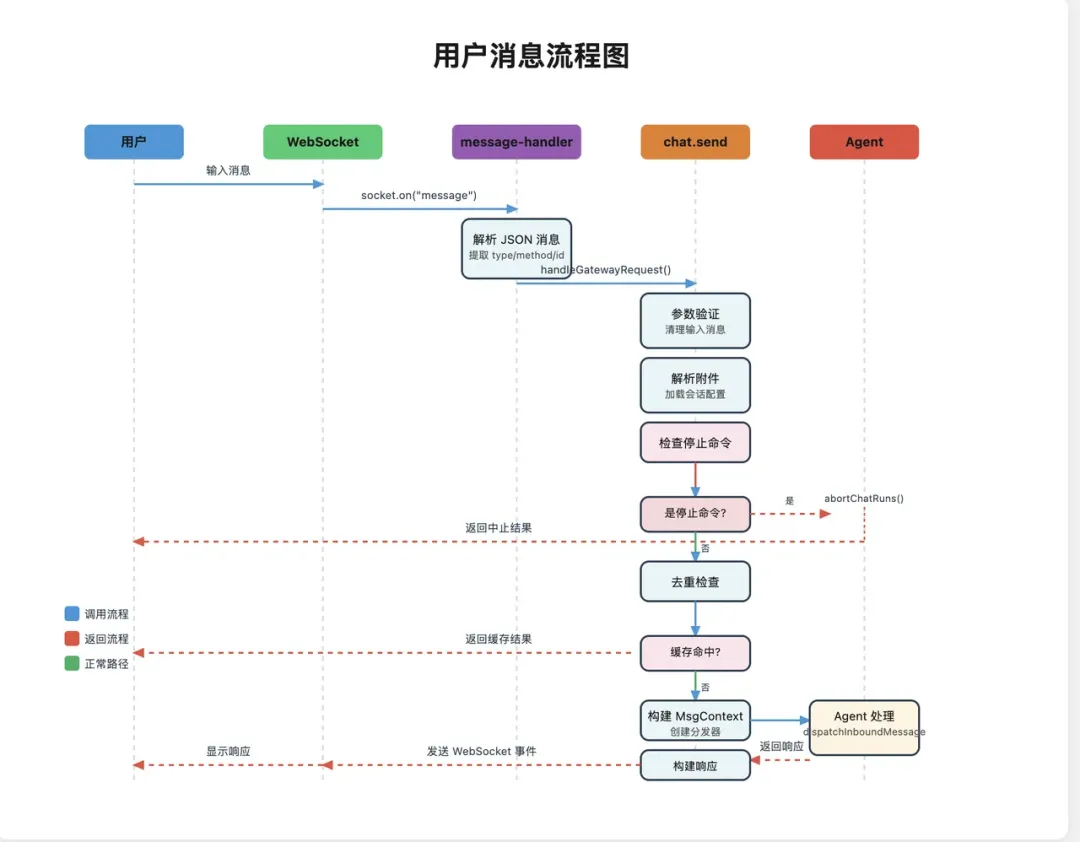

信息处理


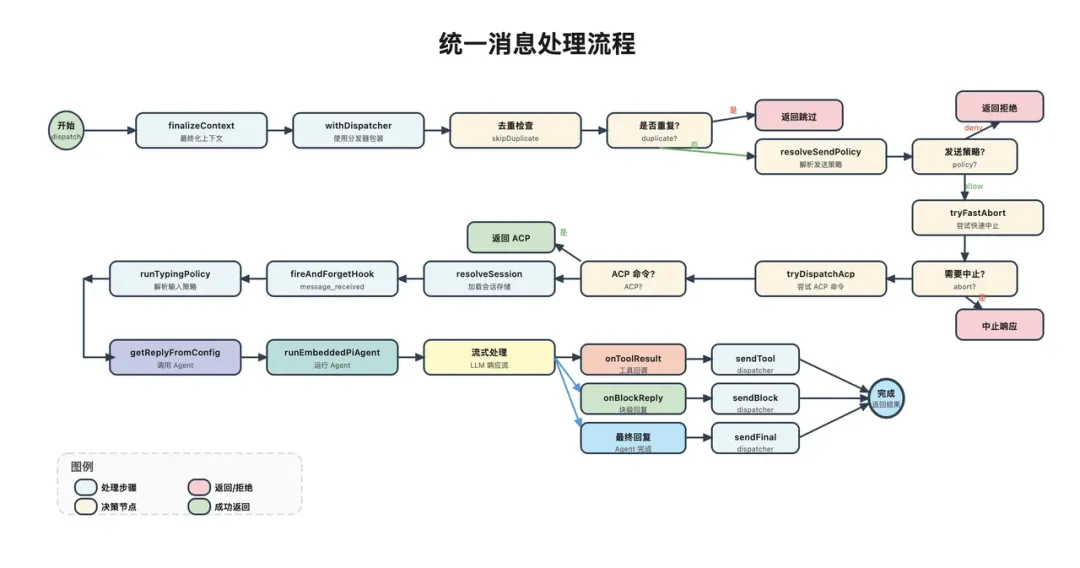
路由系统

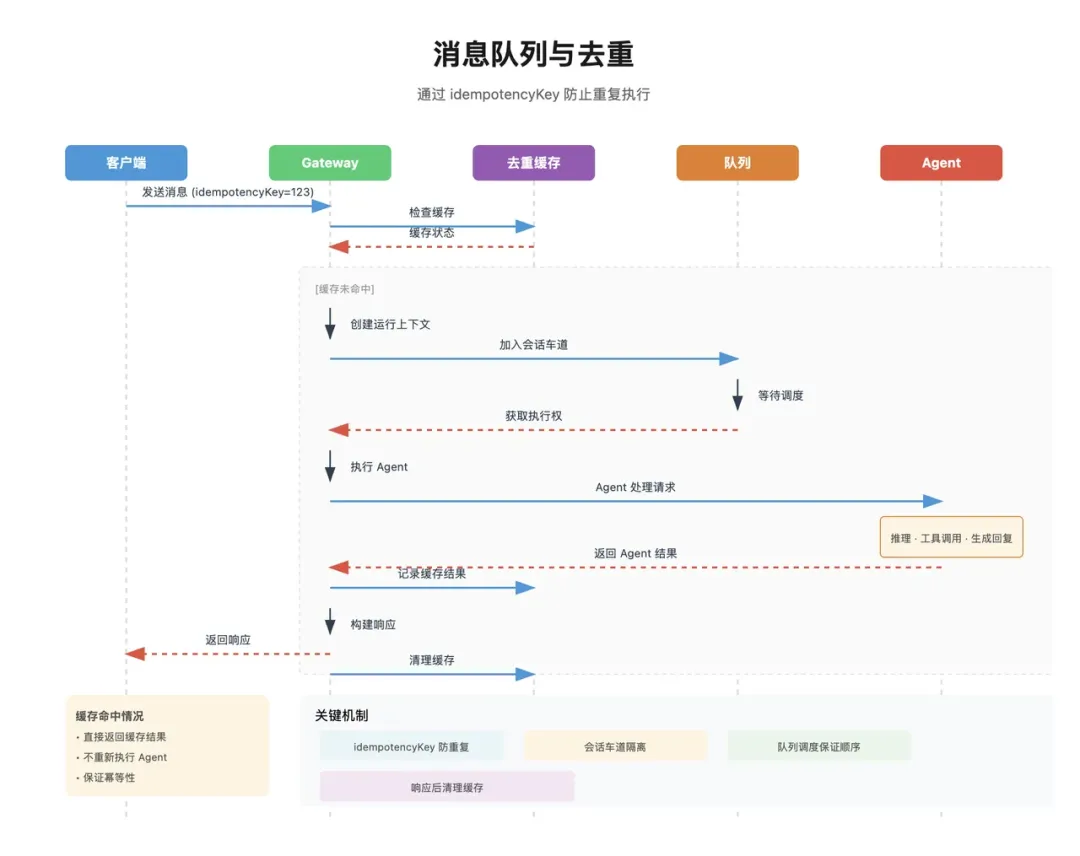
所以 OpenClaw 会为每条消息生成一个幂等键,也就是 idempotencyKey。核心逻辑由 buildInboundDedupeKey 控制:
exportfunction buildInboundDedupeKey(ctx: MsgContext): string | null { const provider = normalizeProvider( ctx.OriginatingChannel ?? ctx.Provider ?? ctx.Surface ); const messageId = ctx.MessageSid?.trim();if (!provider || !messageId) {return null; } const peerId = resolveInboundPeerId(ctx);if (!peerId) {return null; } const sessionKey = ctx.SessionKey?.trim() ?? ""; const accountId = ctx.AccountId?.trim() ?? ""; const threadId = ctx.MessageThreadId ? String(ctx.MessageThreadId) : "";return [provider, accountId, sessionKey, peerId, threadId, messageId] .filter(Boolean) .join("|");}生成格式大概是:
{provider}|{accountId}|{sessionKey}|{peerId}|{threadId}|{messageId}

Agent 登场
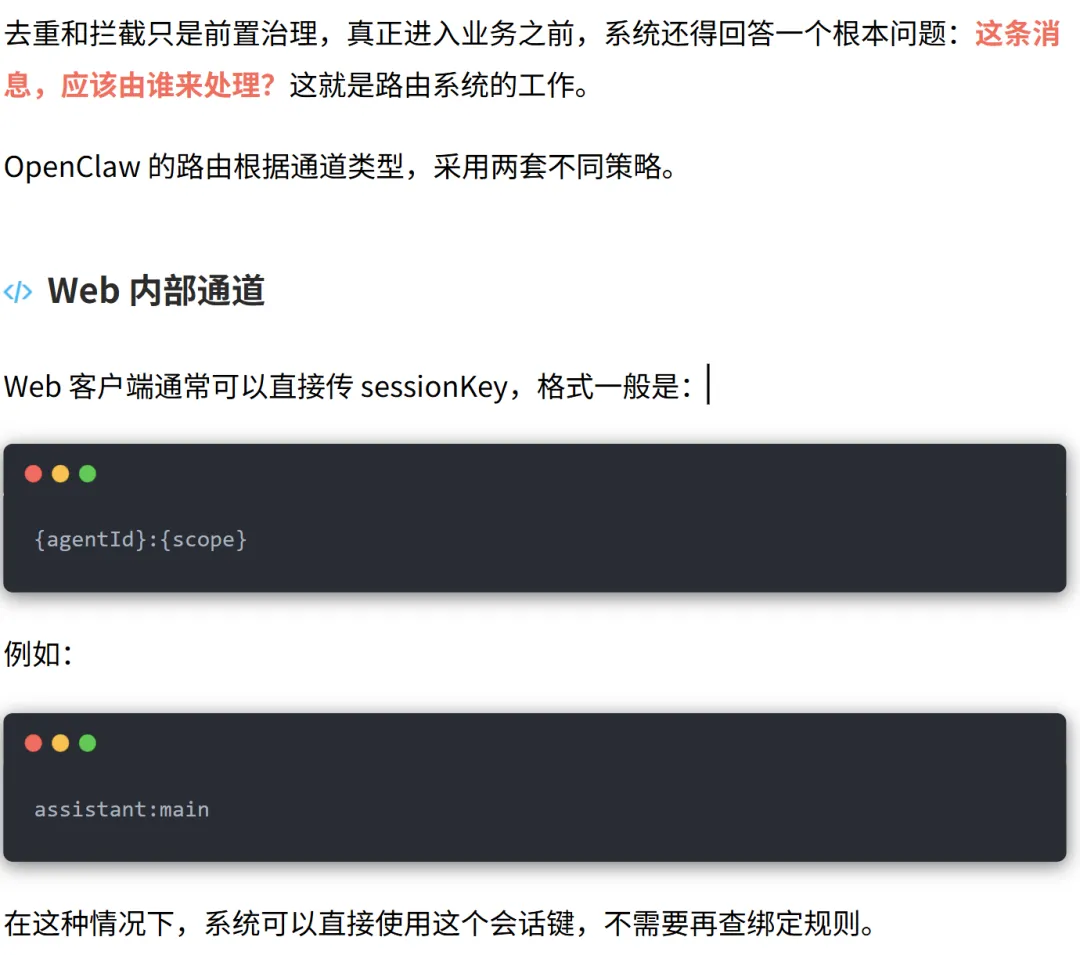
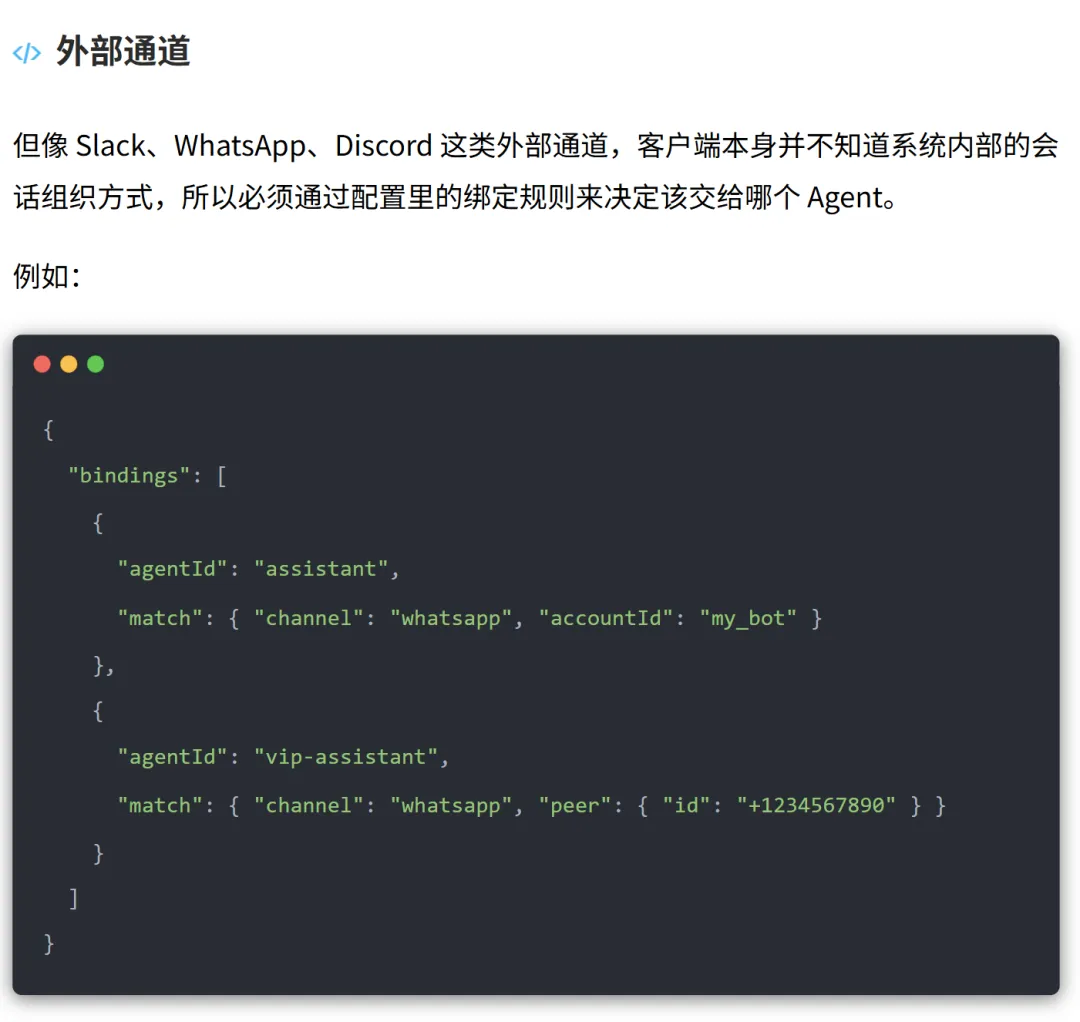

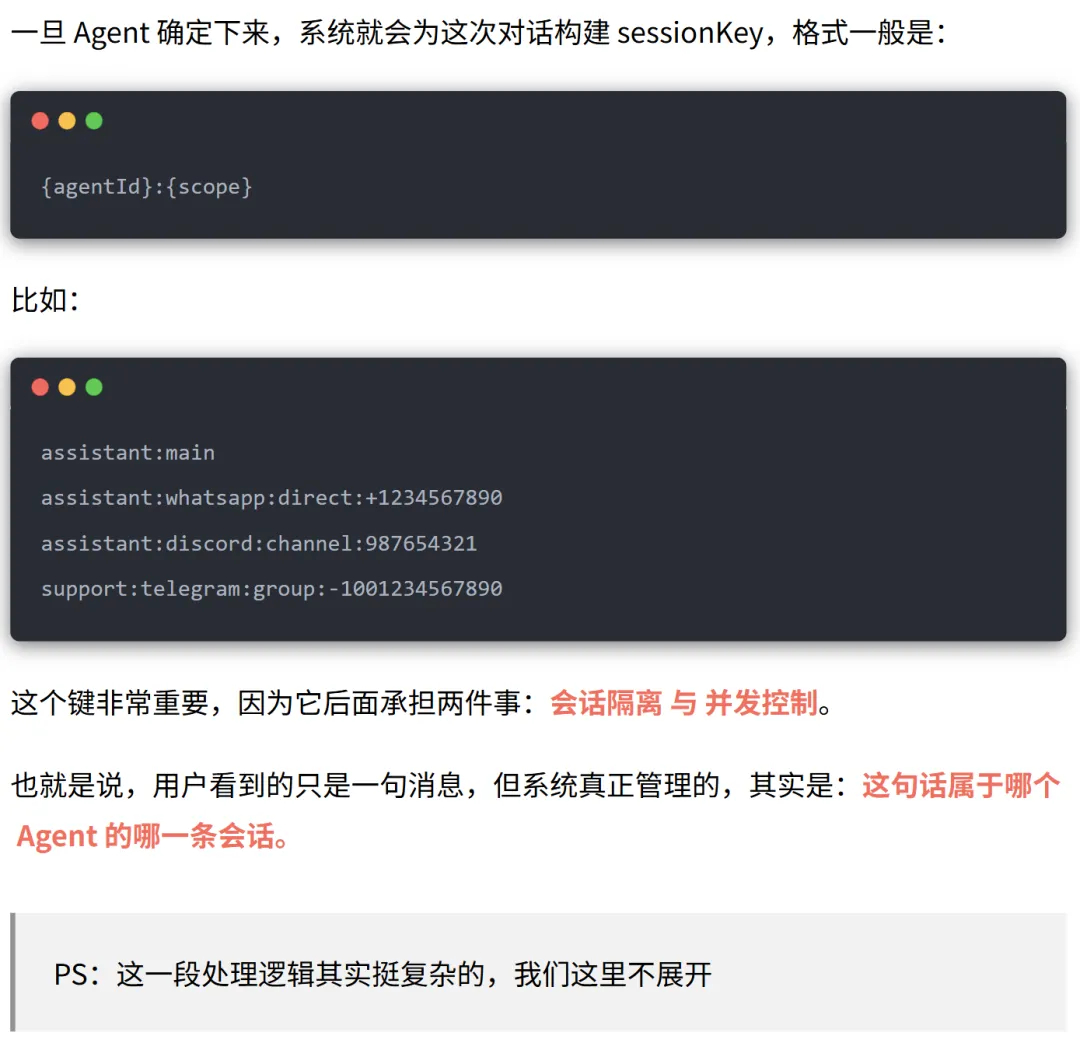
唯一会话键
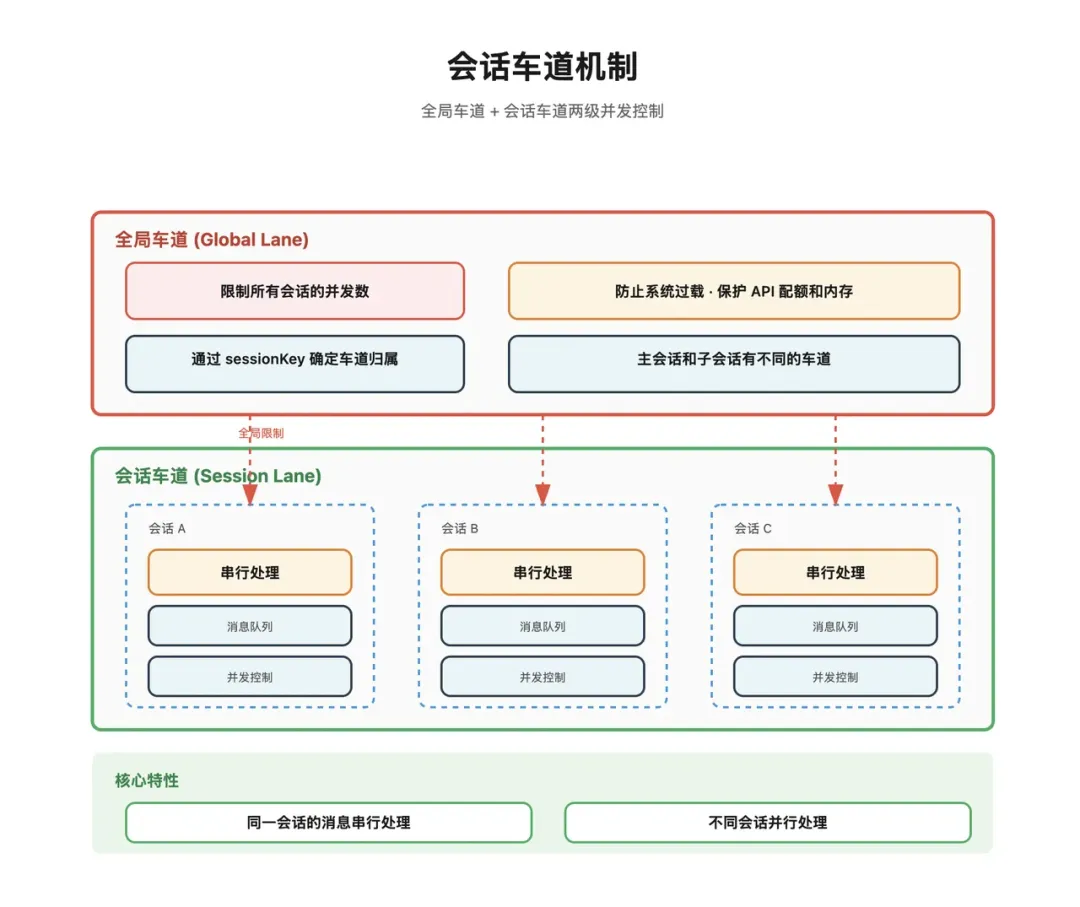
车道机制
到这里,消息已经完成了路由,知道该交给哪个 Agent,也知道自己属于哪个会话。


开始执行

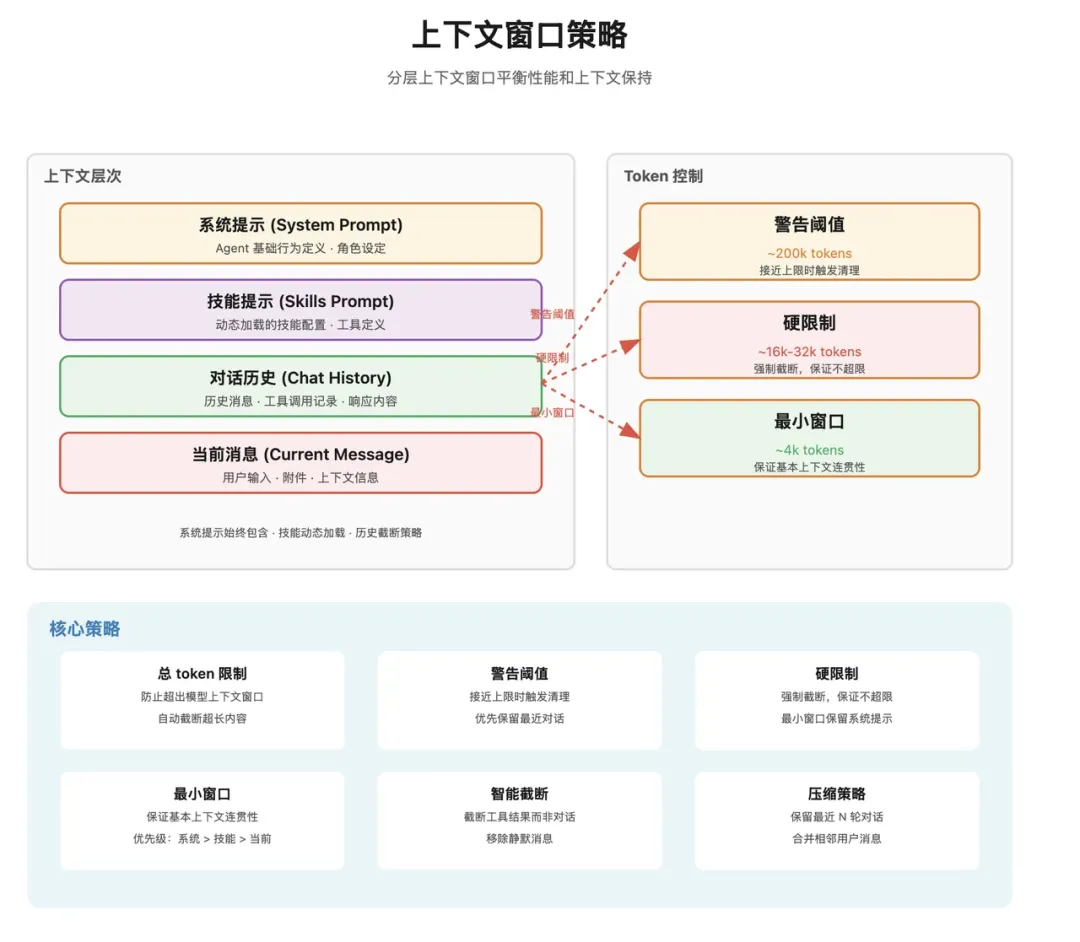


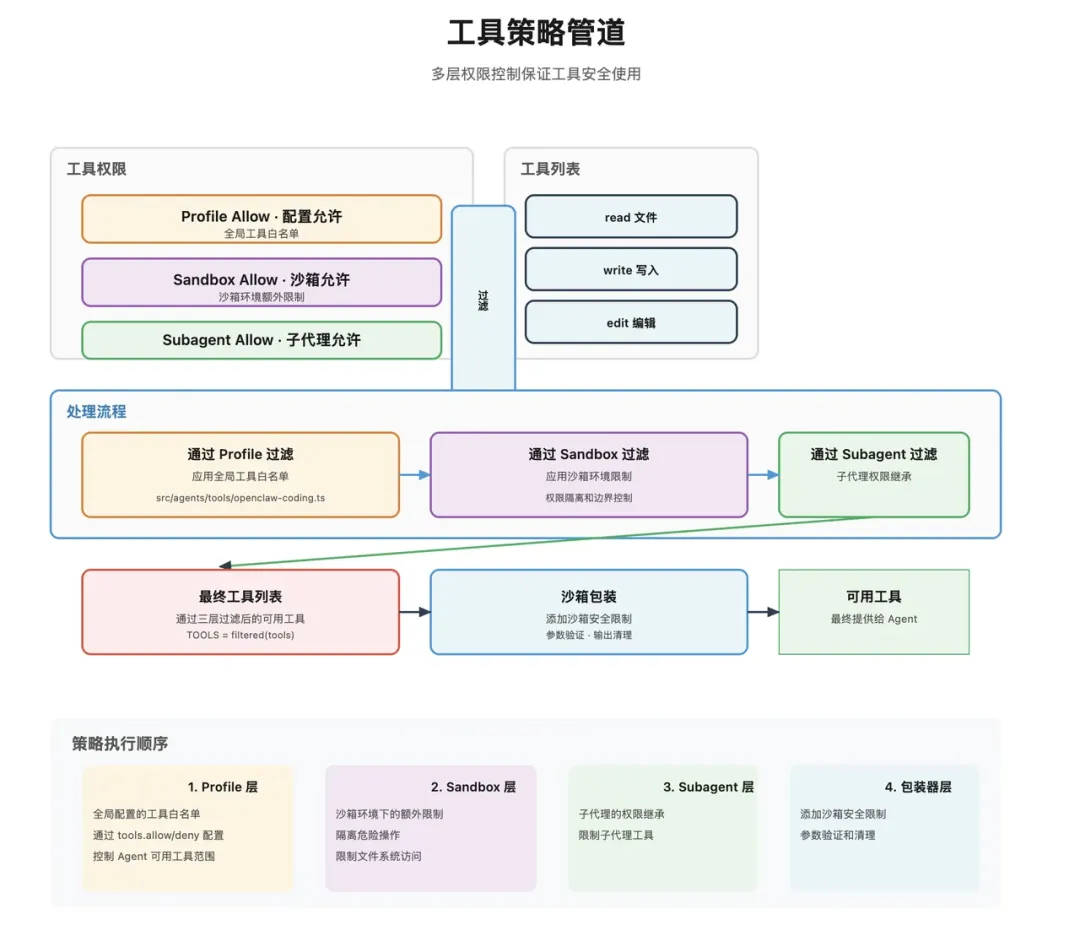
核心:Skills 载入
系统提示词组装完之后,接下来要做的就是 技能提示注入。这部分很关键,因为很多人谈 OpenClaw 时,最容易误解 Skills。



记忆系统
系统提示词和 Skills 搞定后,接下来才轮到对话历史和当前消息。
会话历史
OpenClaw 采用双层存储管理会话历史。
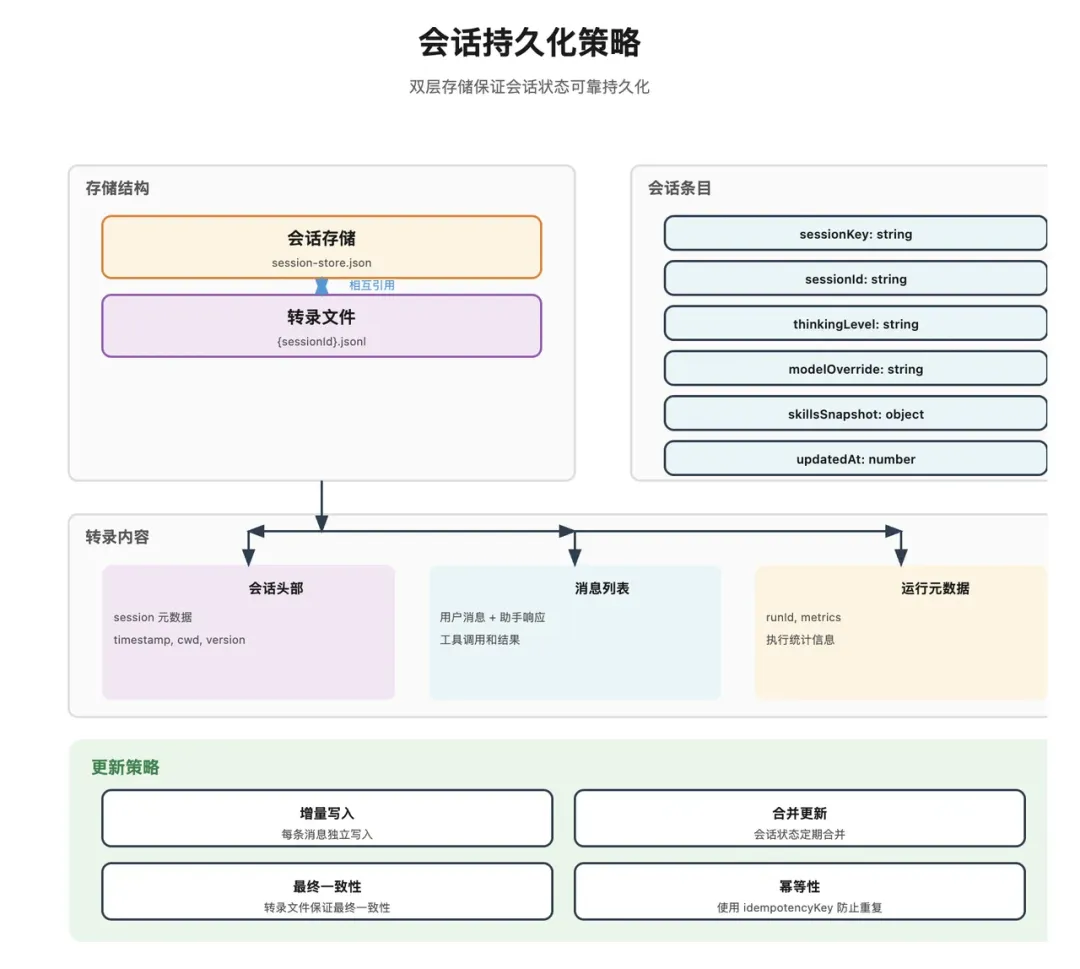
一、轻量索引:sessions.json
里面存的是元数据,例如:
会话 ID会话键转录文件路径最后更新时间模型覆盖配置技能快照位置通常在:
~/.openclaw/agents/{agentId}/sessions/sessions.json内容如下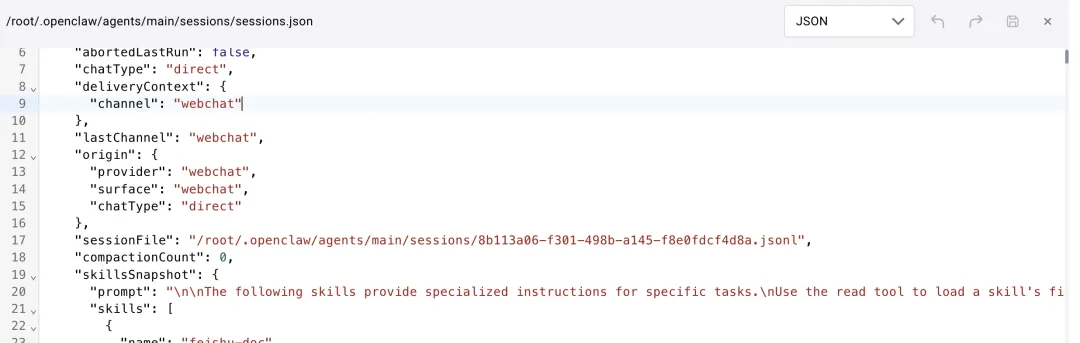
二、重度转录:{sessionId}.jsonl
记录完整的对话历史,采用 JSON Lines 格式,每行一个 JSON 对象,便于流式读取和追加。文件同样位于 agents 目录下的 sessions 文件夹中。
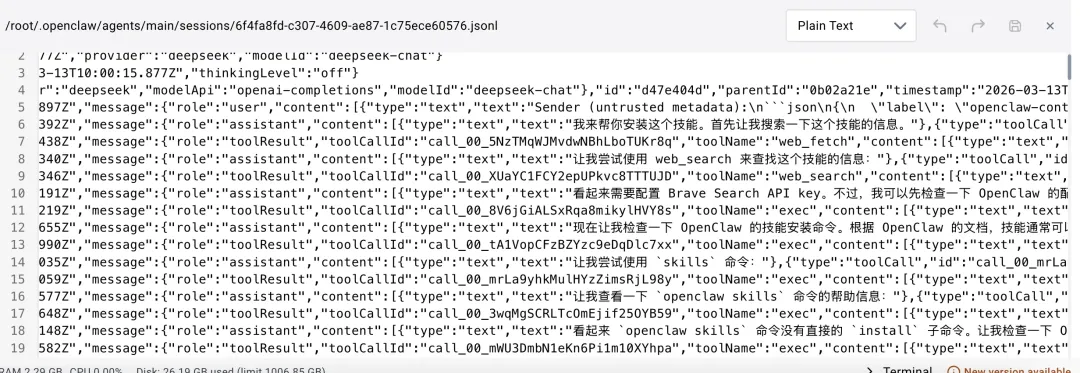

记忆压缩
一旦把系统提示词、技能提示、历史记录、当前消息全塞进去,另一个问题马上就来了:上下文总有一天会爆。
所以 OpenClaw 这里专门做了一整套防爆机制。
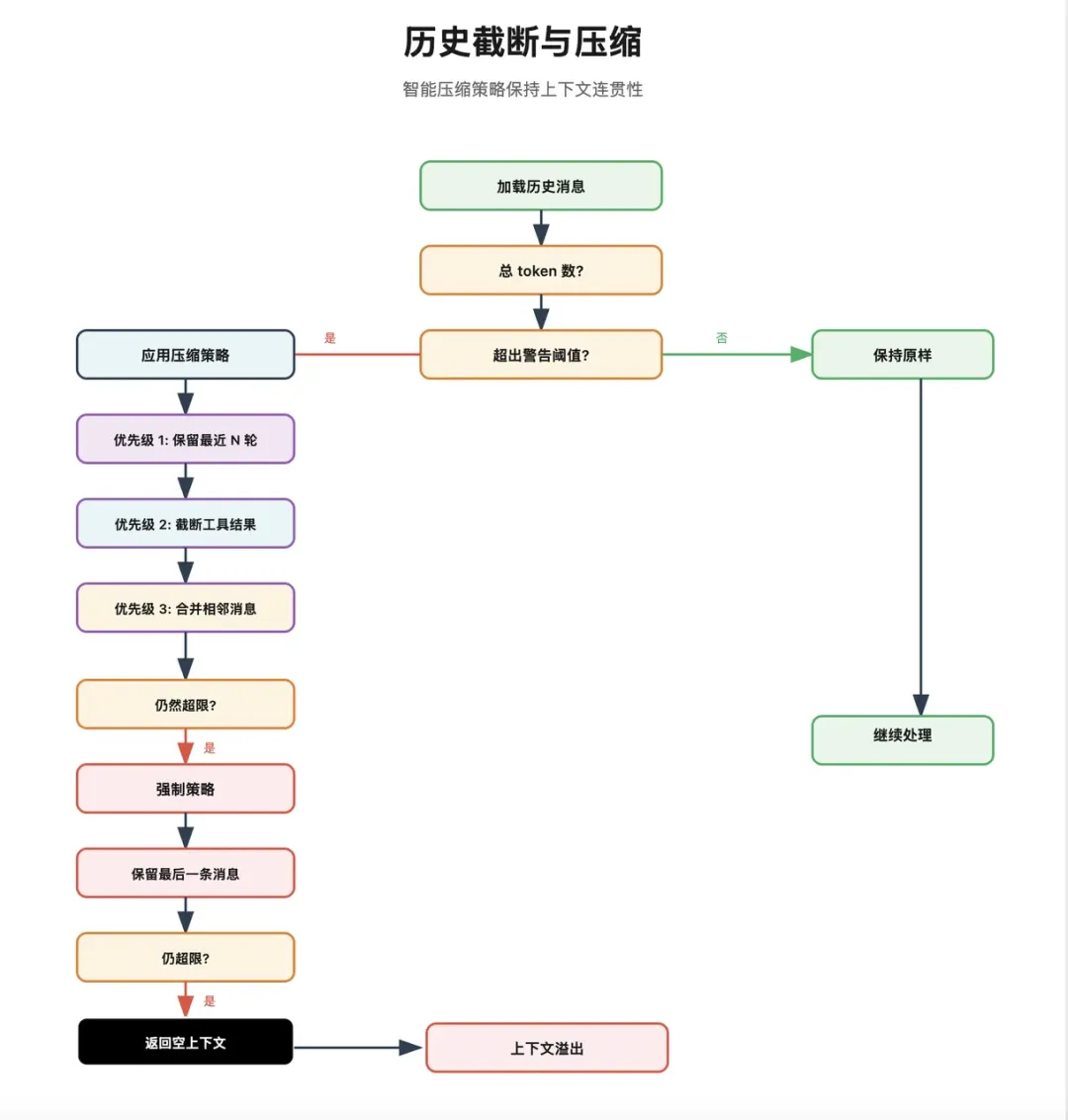


PS:从这里大家就可以看出,如果没有最近一年的模型上下文极速增长,根本不可能有 OpenClaw 这类 Agent 啥事
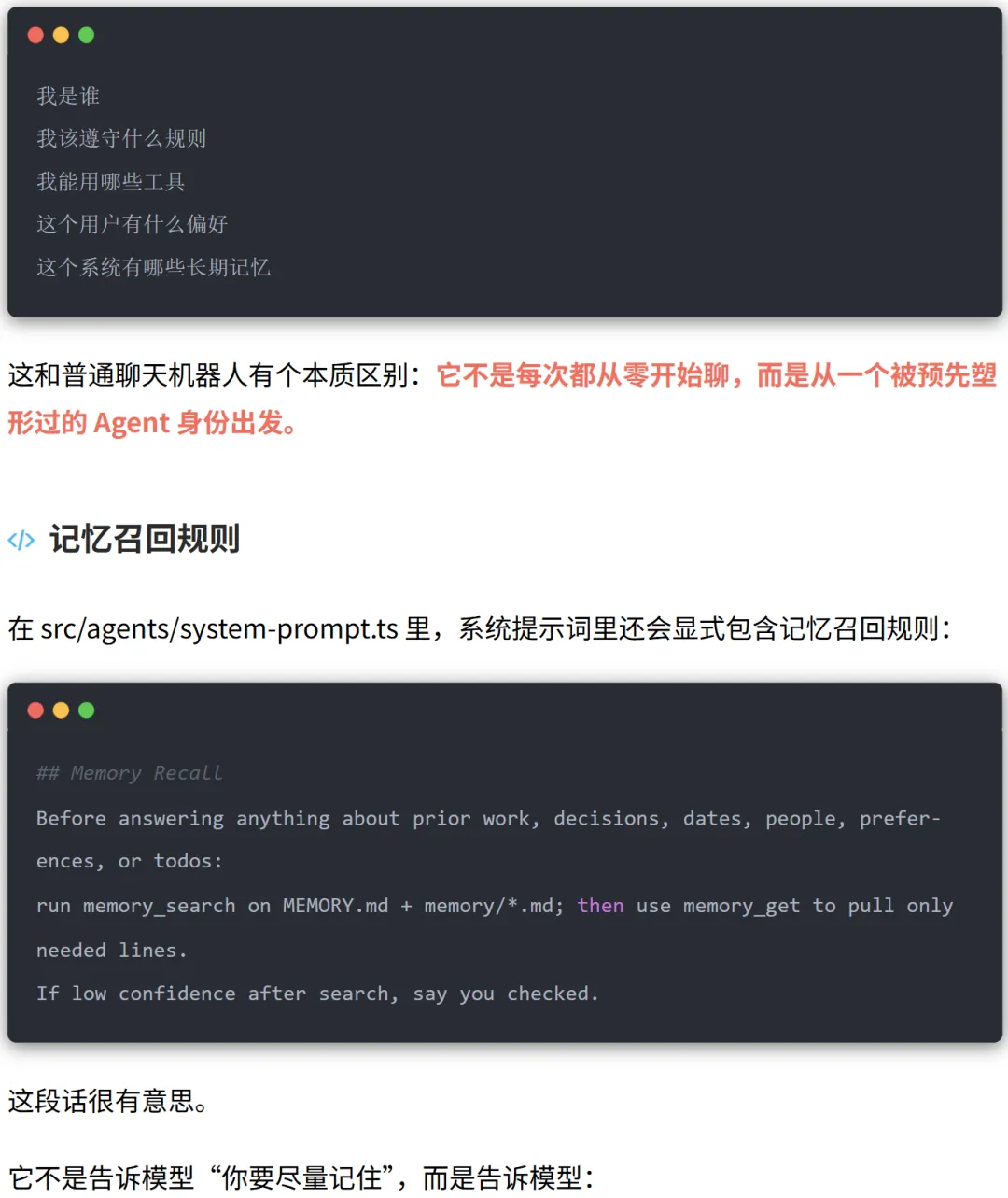
记忆系统怎么工作的
除了会话历史,OpenClaw 还单独维护两类记忆:
一、长期记忆
文件名通常是:
MEMORY.mdmemory.md用于存常青知识,例如:
项目规则 API 文档 设计决策 长期偏好
这类记忆在 Agent 启动时通过 Bootstrap 系统直接注入系统提示词。
二、每日记忆
存放在:
memory/YYYY-MM-DD.md用于记录时效性内容,例如:
每日纪要 当天待办 临时决策 会议记录
这类记忆不直接注入提示词,而是通过记忆搜索工具按需检索,并且会带时间衰减权重,越新的内容权重越高。
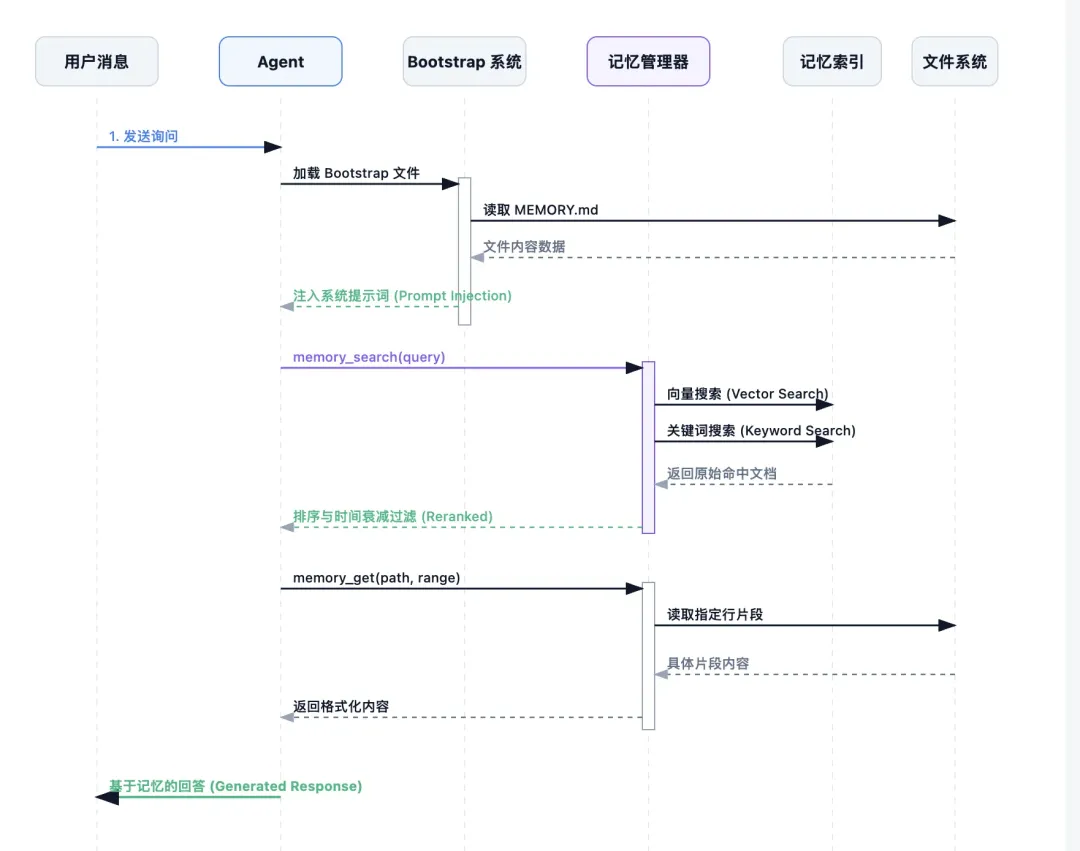
三、记忆什么时候写入
长期记忆通常由用户或 Agent 通过编辑工具手动维护。
而每日记忆则会通过 Memory Flush 机制自动触发。
触发条件:
会话 token 数接近上下文窗口上限(默认软阈值 4000 tokens) 会话转录文件大小超过阈值(默认 2MB)
当系统发现会话快接近压缩阈值时,会先发一个特殊提示给 Agent:
Pre-compaction memory flush.Store durable memories now (use memory/YYYY-MM-DD.md; create memory/ if needed).IMPORTANT: If file already exists, APPEND new content only and do not overwrite existing entries.也就是说,在压缩发生前,系统会先提醒 Agent:把这轮对话中值得长期保留的信息,先沉淀进每日记忆。
这相当于在上下文压缩前,先打一层记忆护城河。
真的执行了
到这里,上下文已经准备好,Agent 才真正开始运行。
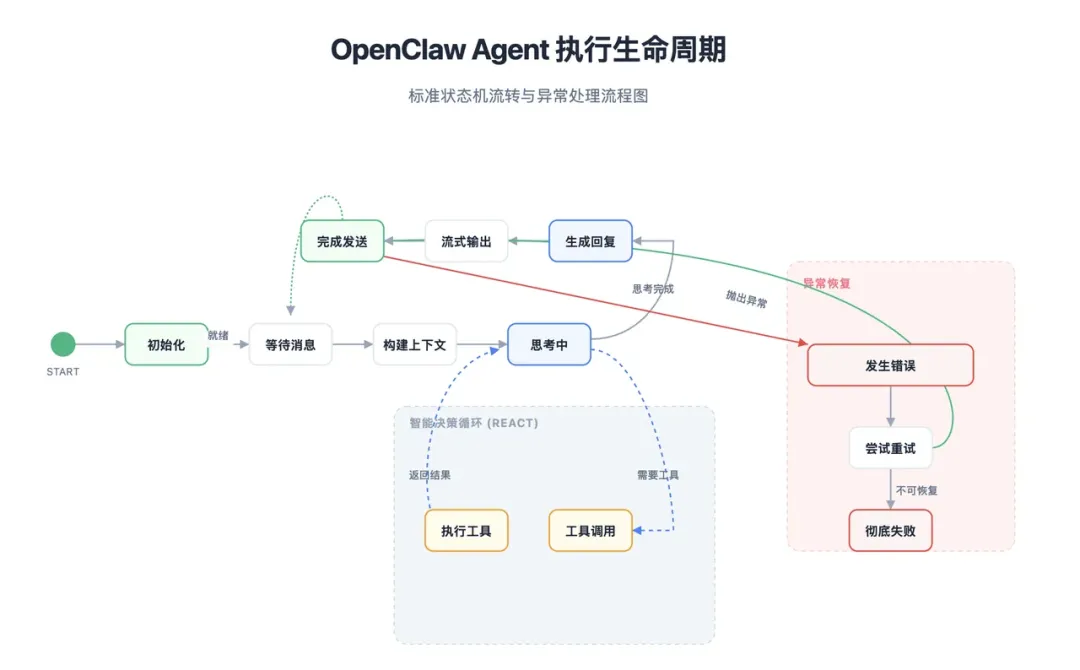
在我们的例子里,这时候模型可能会判断:
当前任务不是普通问答它是一个执行型任务里面包含邮件整理、待办提炼、简报生成三类需求需要调用相应技能和工具如果任务过于复杂,可能还要拆给子 Agent这个阶段最核心的三件事是:


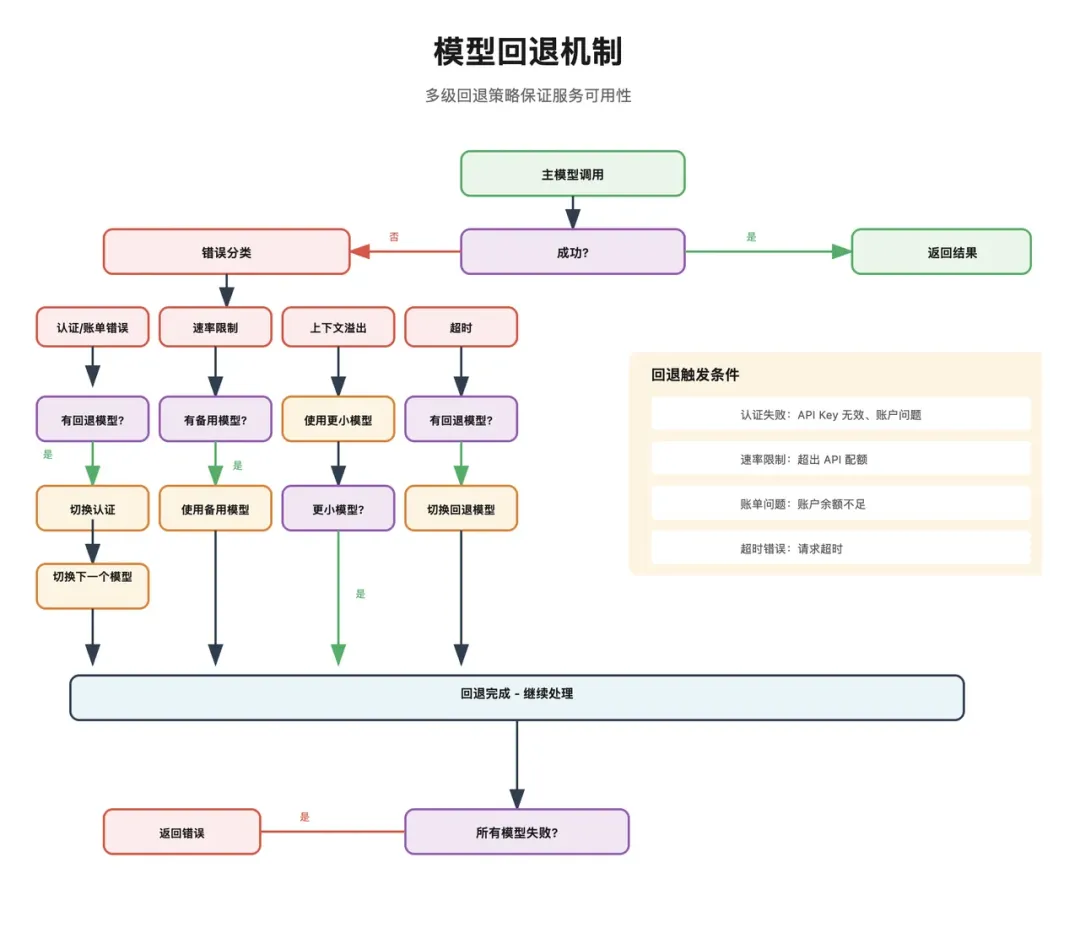
任务完成
当 Agent 终于处理完
整理今天的重要邮件,提炼待办并生成给老板的简报这件事后,系统仍然不能立刻算结束。它还要做三类收尾动作:


记忆索引
既然记忆是 Markdown 文件,系统就还要解决一个问题:怎么让 Agent 高效查它们。
OpenClaw 的做法是给记忆系统单独建索引,索引数据库通常位于:
~/.openclaw/memory/index.db里面大致会有这些表:
fileschunkschunks_vecchunks_ftsembedding_cache也就是同时支持:
文件元数据管理 文本分块 向量检索 全文搜索 向量缓存
为了保证文件和索引同步,系统还会做三种同步机制:
文件监视器自动触发 定期同步 增量同步
必要时还会全量重建索引:
创建临时数据库 遍历记忆文件 分块 生成 embedding 建全文索引 最后原子替换旧索引
综上,OpenClaw 的记忆并不是把 Markdown 当备忘录丢在那,而是真把它做成了一层可检索、可维护的知识基座。
多 Agent
前面讲到这里,其实已经是一条完整的单 Agent 执行链路了:
消息进门协议适配去重拦截路由分发会话排队上下文组装技能注入流式执行响应投递状态持久化如果任务简单,到这里就闭环了。
但现实问题是,很多复杂任务并不适合由一个 Agent 单独完成。还是刚才那个例子:
帮我整理今天的重要邮件,提炼待办并生成一份给老板的简报看起来一句话,实际上可能包含至少三块工作:
筛选和归类邮件 提炼关键待办 组织成适合老板阅读的简报格式
如果全让一个 Agent 一把抓,它当然也能硬做,但往往会出现:
上下文太重推理链过长工具调用太杂专业能力混在一起中间状态难管理所以 OpenClaw 在单 Agent 之上,又做了 多 Agent 协作系统。

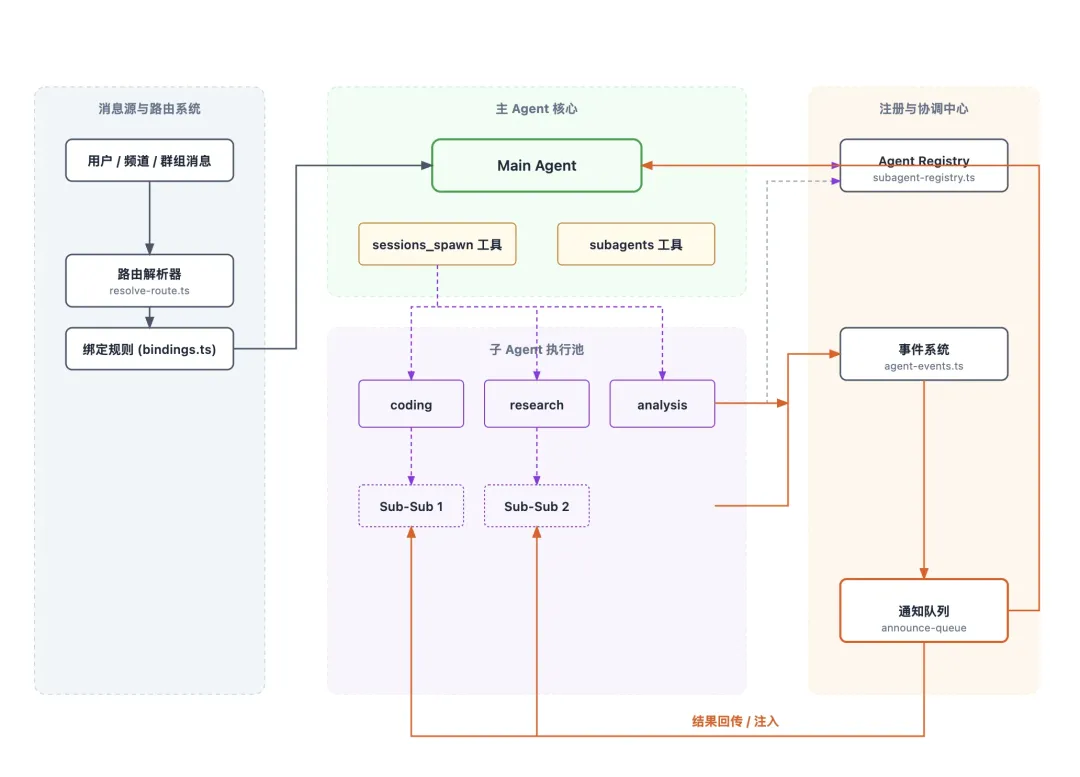

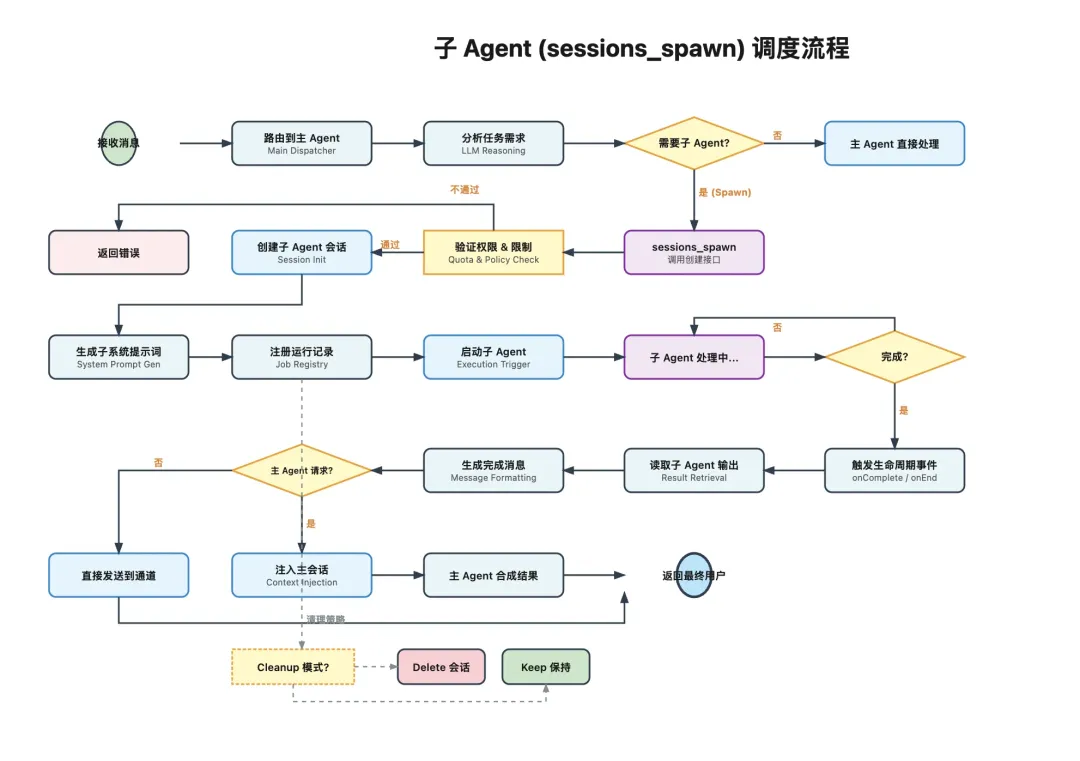
生成唯一子会话键例如 agent:{agentId}:subagent:{uuid}应用模型配置和 thinking 级别处理附件和上下文传递为子 Agent 生成专门的系统提示词例如:
# Subagent ContextYou are a subagent spawned by main agent for a specific task.## Your Role- You were created to handle: ${taskDescription}- Complete this task. That's your entire purpose.- You are NOT main agent. Don't try to be.## Rules1. Stay focused2. Complete task3. Don't initiate4. Be ephemeral这个提示词不是在强化子 Agent 的人格,而是在强调它的边界:你不是主 Agent,你就是来做这一个子任务的。

主 Agent 接收用户任务主 Agent 拆子任务子 Agent 各自执行子 Agent 把结果回传主 Agent 汇总结果主 Agent 最终回复用户这个过程本质上就是一个层级化协作网络。
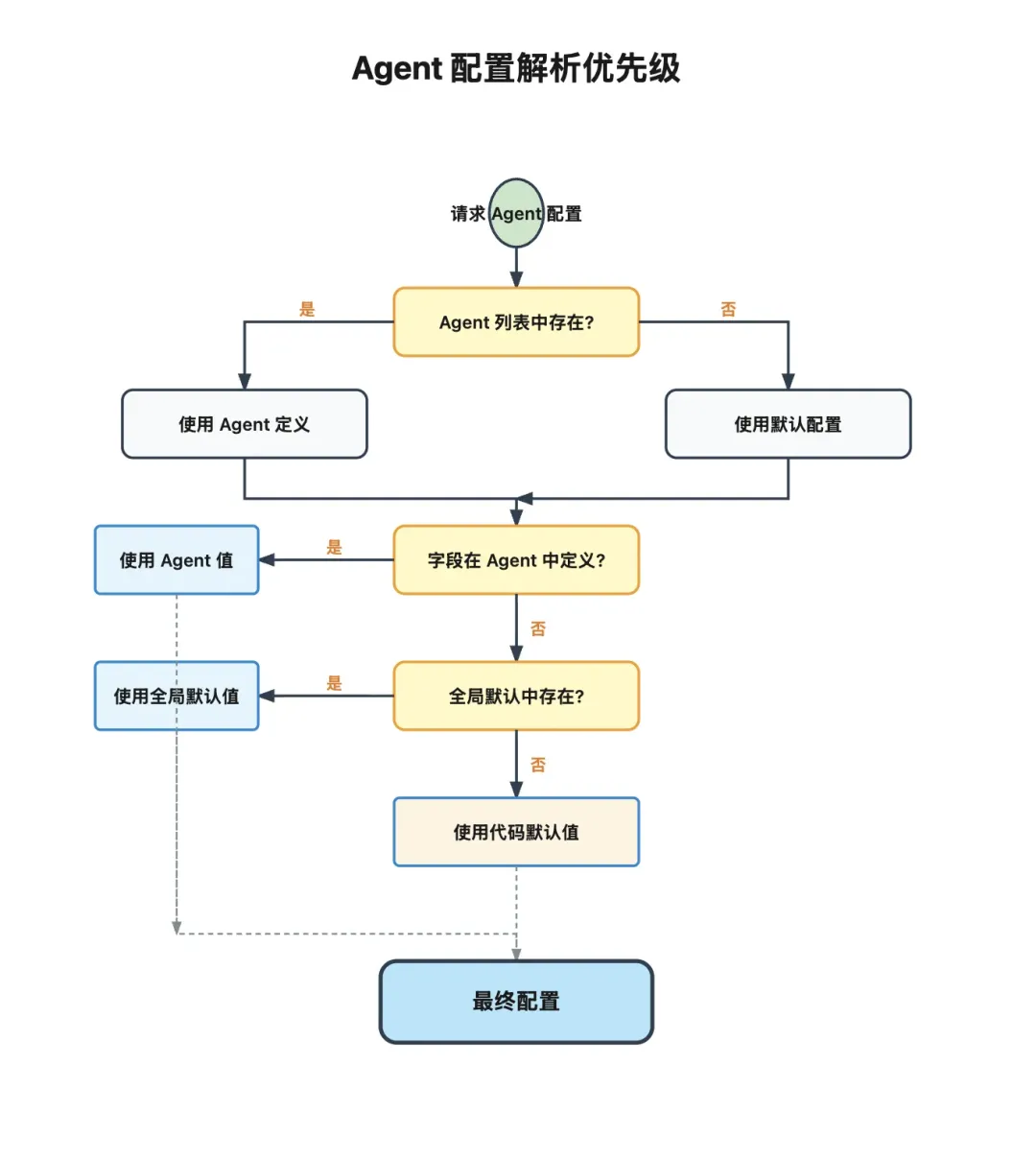
配置继承
OpenClaw 在 Agent 配置上采用三级继承机制:
Agent 级配置优先级最高 全局默认配置次之 代码默认值兜底
例如某个 coding-agent 可以有自己的:
模型工作区可用工具子 Agent 策略沙箱模式而没有单独定义的部分,再回落到全局默认值。这种设计让多 Agent 系统既灵活,又不至于配置爆炸。
OpenClaw 强在哪
再回到最初那句话:
帮我整理今天的重要邮件,提炼待办并生成一份给老板的简报那么它在 OpenClaw 里真正经历的大致过程,其实是这样的:
钉钉原始消息进入系统通道插件把它适配成统一的 MsgContext网关做最终化处理系统检查去重、拦截控制命令、快速响应 started 状态路由系统根据绑定规则找到目标 Agent生成 sessionKey进入会话车道排队,确保同一会话不乱序组装完整上下文:系统提示词、Bootstrap 文件、Skills、历史记录、当前消息模型在技能描述和规则约束下开始推理过程中可能调用工具,也可能 spawn 子 Agent子 Agent 完成后把结果回流给主 Agent主 Agent 生成最终答复回复分发器把结果投递回目标通道会话和转录被持久化记忆被更新,索引同步资源释放,执行闭环结束这样一看你就会发现,OpenClaw 真正有价值的地方,不是它能不能回答一句话,而是:
它把一条消息从进入系统到完成执行,做成了一条可治理、可扩展、可追踪、可恢复的 Agent Runtime 链路
结语

它不是一个更会聊天的机器人,也不只是一个会调工具的 Agent 壳。它更像是一个把消息入口、会话治理、上下文管理、技能调用、持久化存储和多 Agent 协作缝合在一起的 Agent Runtime + Gateway
