 夜雨聆风
夜雨聆风我用 OpenClaw 也有段时间了。
一开始挺爽的——装个插件、配个模型,AI 助手就能帮我写代码、读文档、做分析。
但用着用着,我发现一个挺尴尬的问题:这 AI 怎么跟金鱼似的,聊多了就忘?

这些问题,我一个个踩过坑。今天想跟你聊聊,我是怎么用两个插件解决这些痛点的。
OpenClaw 本身是个很棒的开源 AI Agent 平台,但它在上下文管理和长期记忆这两个地方,确实有点"先天不足"。
OpenClaw 默认用"滑动窗口"来管理上下文——对话太长时,直接把最早的消息扔掉。问题是,扔掉的消息里可能有关键信息。
比如你让 AI 读了一份 50 页的文档,聊了一个小时后,AI 突然忘了文档里最重要的那个结论。你得重新发一遍文档,或者重新解释一遍。
这体验,说实话挺难受的。
每次新开一个会话,AI 都是"从零开始"。昨天你告诉它"我喜欢用 TypeScript",今天它就可能给你生成 JavaScript 代码。
没有长期记忆,AI 就永远是"陌生人",永远记不住你的偏好、你的习惯、你们聊过的上下文。
如果你主要用中文和 AI 对话,还有个更隐蔽的问题:token 估算不准。
原版插件用 Math.ceil(text.length / 4) 来估算 token,假设每个 token 约 4 个字符。这对英文还行,但对中文来说,低估了 2-4 倍。
什么意思呢?14 个汉字,原版插件算成 4 个 token,实际上应该是 19 个左右。结果就是——压缩触发太晚,上下文窗口莫名其妙就溢出了。
最近看到UP主:AI超元域, 自己开发/修改的两个OpenClaw插件,分别解决了长期记忆和上下文丢失问题,经我实测后,感觉确实非常好用,现在推荐给大家。
插件一:lossless-claw-enhanced(无损上下文管理)
这个插件解决的是单会话内的上下文管理问题。
它用了一个叫 LCM(Lossless Context Management)的技术,核心思路很简单:不扔掉任何消息,而是把旧消息摘要成"记忆节点"。
具体怎么做的?
关键点是:什么都不丢。 原始消息还在数据库里,摘要能链接回源消息。如果 AI 需要某个细节,可以深入摘要恢复原始内容。
这个插件还有个让我惊喜的是——它专门修复了 CJK Token 估算问题。
| 1.5 tokens/char | 6倍 | ||
| 2.0 tokens/char | 4倍 |
举个例子:"这个项目的架构设计非常优秀"(14 个汉字)
这个修复对中文用户很实用。以前聊着聊着上下文就满了,现在能准确估算,压缩时机也对了。
除了 CJK 优化,插件还 cherry-pick 了几个上游的关键 bug 修复:
/reset 或会话轮换后,新会话也能正常触发压缩•空消息过滤:API 500 产生的空消息会被跳过,不会累积成恶性循环摘要模型推荐用便宜又快的就可以。
插件二:memory-lancedb-pro(长期记忆增强)
如果说 lossless-claw-enhanced 解决的是"单会话内不丢消息",那 memory-lancedb-pro 解决的就是"跨会话记住你"。
内置的 memory-lancedb 只有向量搜索,而 Pro 版增加了混合检索(Vector + BM25)。
什么意思呢?
实际效果就是——既能模糊搜索,又能精确查找。
这个插件的检索逻辑非常精细,有整整 6 层评分:
| 时效加成 | |
| 重要性加权 | |
| 长度归一化 | |
| 时间衰减 | |
| MMR 多样性 | |
| 硬最低分 |
这套组合拳下来,检索结果既相关又多样,不会全是同一类内容。
插件还支持用 Jina Reranker 做二次排序:
如果 Jina API 挂了,还能降级到 cosine similarity rerank,稳定性有保障。
如果你用多个 Agent,这个特性特别重要。
Pro 版支持多种 Scope 模式:
global:全局共享记忆•agent:<id>:某个 Agent 专属•custom:<name>:自定义分组•project:<id>:项目级别•user:<id>:用户级别默认情况下,Agent 能访问 global + 自己的 agent:<id> Scope。这样既能共享通用知识,又能保持各自的专属记忆。
最省心的是——它能自动工作。
Auto-Capture(对话结束时触发):
Auto-Recall(对话开始时触发):
<relevant-memories> 上下文•默认注入 top-3 最相关记忆你几乎不用手动管理记忆,它会自己学习、自己回忆。
memory list、memory search、memory stats 等命令行工具作为一个主要用中文和 AI 对话的用户,我想特别强调这两个插件对中文用户的价值。
lossless-claw-enhanced 的 CJK Token 修复,对中文用户是质变。
以前用原版插件,聊着聊着上下文就满了,根本不知道为什么。现在能准确估算中文 token,压缩时机精准,不会再莫名其妙溢出。
而且增强版还做了幂等迁移——升级时会自动重新计算历史 CJK 消息的 token_count,不用你手动处理。
memory-lancedb-pro 的 Auto-Capture 支持中文触发词:
你不用刻意用英文说 "remember",直接用中文表达,它也能捕获。
插件的自适应检索对 CJK 字符更友好:
这意味着你用中文查询时,能更快、更准地找到相关记忆。
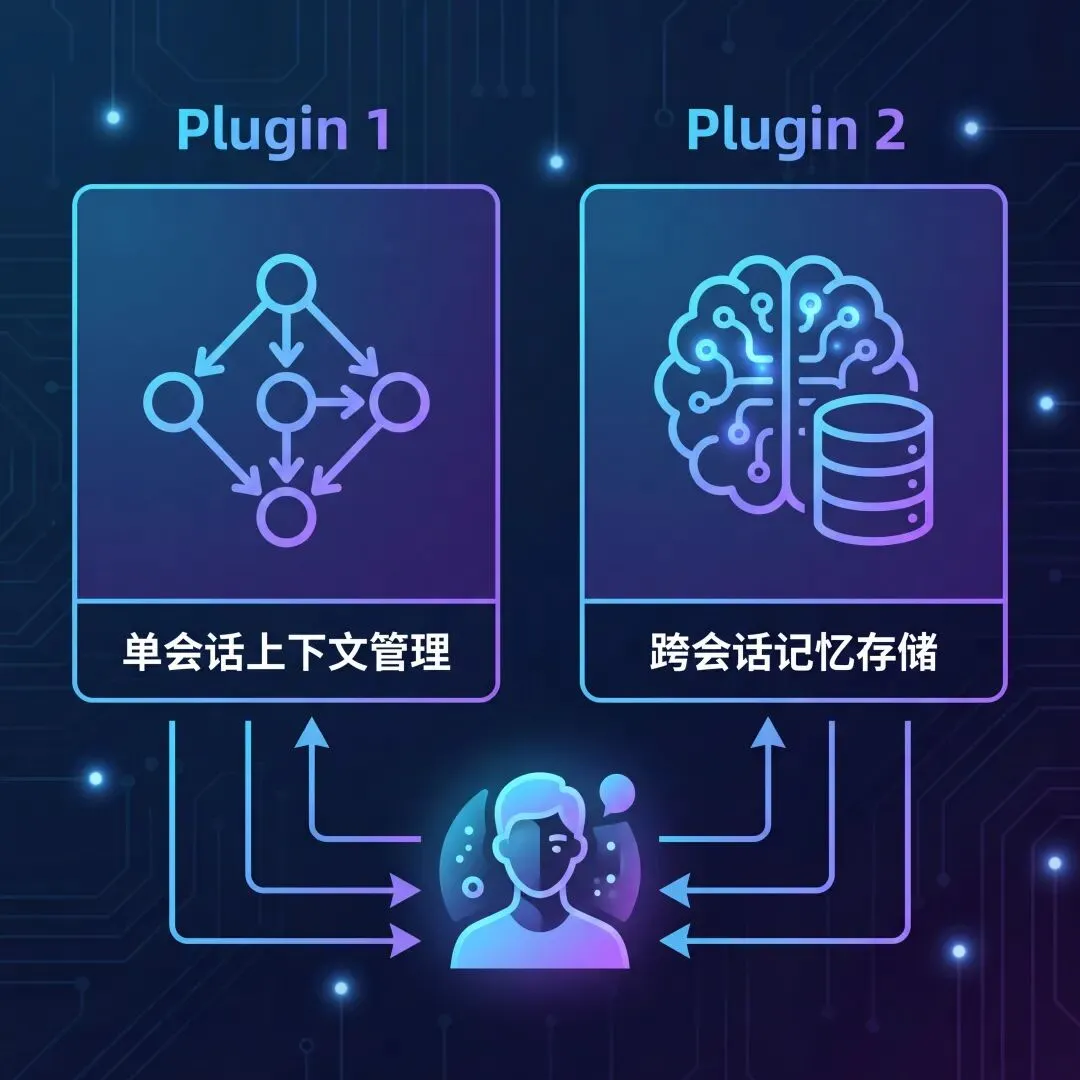
另外,这两个插件不是互斥的,而是互补的。
组合方案
最佳实践:
场景一:长文档分析
你让小龙虾读了一份 100 页的技术文档,然后连续讨论 2 小时。
场景二:多 Agent 协作
你用不同的 Agent 处理不同任务:一个写代码、一个写文档、一个做分析。
场景三:中文内容创作
你用 OpenClaw 辅助写中文文章、报告。
说实话,装了这两个插件之后,我的 OpenClaw 体验提升了一大截。
以前聊久了就得手动复制粘贴上下文,现在完全不用管。以前每次新开会话都要重新交代偏好,现在 AI 自己记得。
最让我满意的是中文优化——终于有个插件是真正为中文用户考虑的,不是简单翻译一下,而是从底层 token 估算到触发词都做了适配。
如果你也是 OpenClaw 用户,特别是中文用户,推荐试试这两个插件。
安装不复杂,配置有文档,可以让小龙虾一句话自己安装,遇到问题还有 AI超元域 的视频教程可以参考。
