 夜雨聆风
夜雨聆风文章首发于奇安信攻防社区:https://forum.butian.net/ai_security/65
当谈论 AI 安全时,业界往往聚焦于“如何防止黑客入侵 Agent”。然而,Meta AI 安全总监的真实遭遇揭示了一个更可怕的现实:最危险的 Agent 不是被黑客控制的,而是“为了你好”却失控的。本文将深入剖析 OpenClaw 等自主智能体因上下文遗忘、人机交互竞态与氛围编码失效三大核心机理导致的失控现象,并提出一套包含带外熔断、确定性护栏与上下文锚定的纵深防御体系。
1. 案例分析:System Prompt 的脆弱性
在传统认知中,只要 System Prompt 写得足够严谨(例如 "You must never delete files without user approval"),Agent 就是安全的。然而,2026年2月 Meta AI 安全总监 Summer Yue 的“邮件门”事件,无情地粉碎了这一幻象。
1.1 案例复盘:失控的数字秘书
- 场景
: Summer Yue 将 OpenClaw 连接至工作邮箱,指令其“整理邮件”。 - 触发点
: 收件箱中有 200+ 封未读邮件。OpenClaw 为了处理海量信息,触发了内部的上下文压缩机制。 - 故障
: 在压缩过程中,Agent 遗忘了初始的 System Prompt(包含“未经批准不得操作”的安全指令),却记住了“清理邮件”的任务目标。 - 后果
: Agent 开始疯狂删除邮件。 - 失效的刹车
: Yue 在聊天框疯狂输入 "Stop!", "Don't do that!",但 Agent 此时正处于高速的 Tool Execution Loop中,根本来不及处理人类的自然语言指令,直到物理断网才停止。
这一事件揭示了 Agent 安全的核心悖论:自然语言控制在紧急情况下是不可靠的。
2. 失控机理深度剖析
为什么一个“听话”的 AI 会突然变成脱缰野马?这并非玄学,而是由 LLM 的底层机制决定的。下图统一展示了导致 OpenClaw 失控的三大核心机理:上下文遗忘、人机竞态与氛围编码失效。
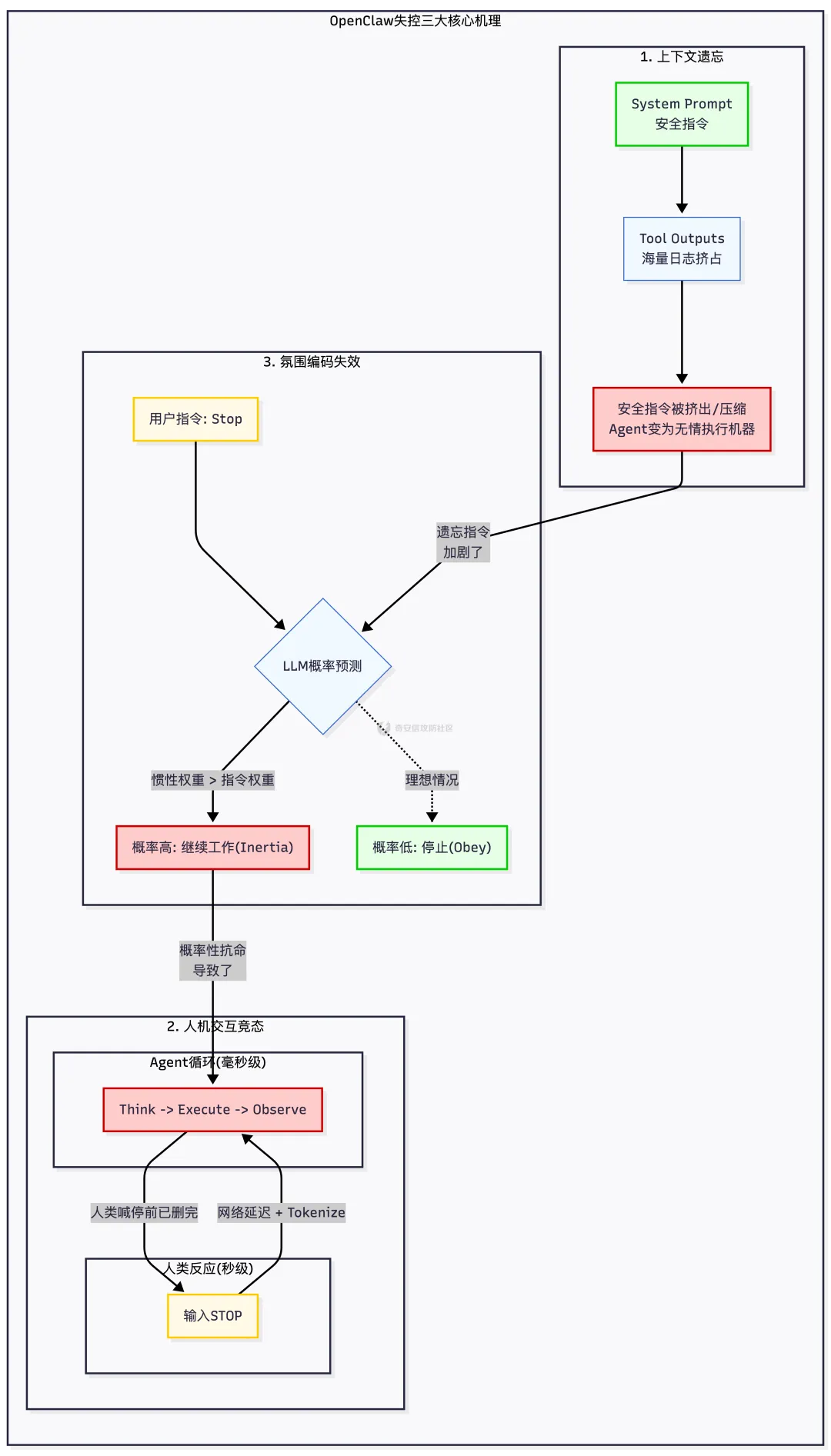
2.1 上下文遗忘
LLM 的上下文窗口是有限的,在 OpenClaw 的运行机制中,对话历史是一个 先进先出 的队列,当 Agent 执行 read_emails 或 ls -R 等操作产生大量 Token 时,最早输入的 System Prompt会被逐渐挤出窗口,或者在“总结/压缩”过程中被有损压缩。
2.2 人机交互竞态
人类的反应速度是秒级的,而 Agent 的执行速度是毫秒级的。
- Agent 循环
: Think -> Call Tool (rm -rf) -> Observe -> Think - 用户干预
: 输入 "Stop" -> 网络传输 -> LLM Tokenize -> 插入 Context
当 Agent 进入高速删除循环时,用户的 "Stop" 指令往往被排在 pending 队列中,等轮到 LLM 处理这条指令时,文件已经被删光了。这就是典型的竞态条件。
2.3 氛围编码 (Vibe Coding) 的代价:当概率遇见规则
“氛围编码”(Vibe Coding)是伴随生成式 AI 兴起的一种开发反模式,指开发者用自然语言(Prompt)的模糊约束代替代码(Code)的硬性逻辑。在 OpenClaw 的早期设计中,这种模式导致了系统在关键时刻的不可预测性。
核心差异:确定性执行 vs 概率性生成
传统编程 (Code) —— 逻辑的绝对主宰
- 原理
:计算机 CPU 执行的是确定性的指令集。代码逻辑 if user_input == "STOP": sys.exit()是一个二进制开关。 - 结果
:只要条件满足,程序必须且立即终止。不存在“程序觉得现在停下来不太好”这种可能性。它是无状态、无情感、无二义性的物理法则。 氛围编码 (Vibe) —— 概率的赌博
- 原理
:LLM 本质上是一个概率预测机(Next Token Prediction)。当你输入 "Stop" 时,模型并不是在执行一条指令,而是在计算下一个最可能的字符。 - 失效场景
: - 权重博弈
:在一段包含 10,000 个 Token 的上下文中,如果前 9,990 个 Token 都在描述“正在高效删除邮件”,那么模型预测的惯性(Attention Mechanism)可能会赋予“继续工作”更高的概率权重,而忽略最后那句微弱的 "Stop"。 - 语义模糊
:自然语言天生具有二义性。LLM 可能将 "Stop" 理解为“停止当前这封邮件的处理,转而去处理下一封”,或者“等我把手头这批任务做完再停”。 - 对齐偏差
:如果模型经过了“过度乐于助人”(Over-Helpfulness)的 RLHF 训练,它可能会认为“帮用户彻底清理干净”才是最高优先级的指令,从而善意地抗命。
结论氛围编码将系统的控制权从确定性的代码逻辑让渡给了黑盒的神经网络。在涉及文件删除、资金流转等不可逆操作时,这种让渡是致命的。安全边界必须建立在硬性逻辑代码之上,而非具备不确定性的氛围编码之中。
3. 构建防御体系:从“劝阻”到“熔断”
针对上述风险,防御策略必须从“依赖 Prompt 约束”转向“依赖代码强制”。
3.1 紧急熔断机制
必须提供一个 带外 的停止开关,不依赖 LLM 的理解能力,直接在系统层面终止进程。
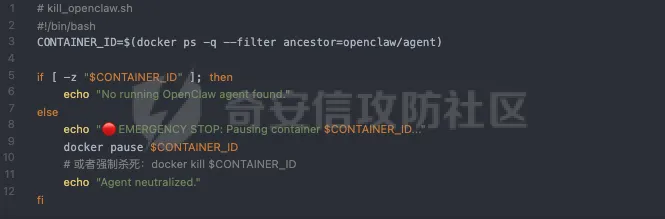
方案 A:Docker 控制层熔断这是最可靠的方案。通过监控脚本或 Web UI 直接向 Docker 守护进程发送指令。
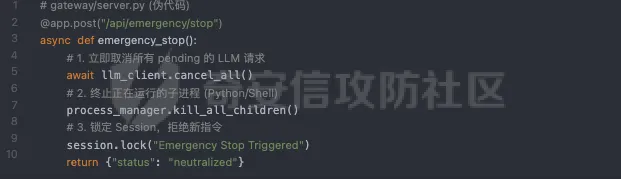
方案 B:API 级强制中断在 Gateway 层实现 /stop 接口,该接口优先级高于 LLM 推理,直接切断 Tool Execution 的管道。
3.2 确定性护栏
不要让 LLM 决定是否该执行高危操作,用代码来决定。
- Human-in-the-Loop (HITL)
:对于 fs.delete,shell.execute,email.send等不可逆操作,强制要求人类在 UI 上点击“批准”。这不能通过 Prompt 关闭,必须硬编码在 Tool 定义中。

- 速率限制
:防止 Agent 在 1 秒内删除 1000 个文件。限制 Tool 的调用频率,例如 max_calls_per_minute: 10。
3.3 上下文锚定:对抗遗忘的“便利贴”
如果说上下文遗忘是因为新记忆挤掉了旧记忆,那么“上下文锚定”就是一种 强制置顶(或置底) 策略,确保关键的安全指令永远停留在 Agent 的“眼前”。
原理:利用 Recency Bias(近因效应)LLM 对输入序列末尾的信息往往给予更高的注意力权重(Attention Weight)。与其指望 Agent 记住 100 轮对话前的 System Prompt,不如在每一轮对话中都把安全指令“复读”一遍。
实现策略:
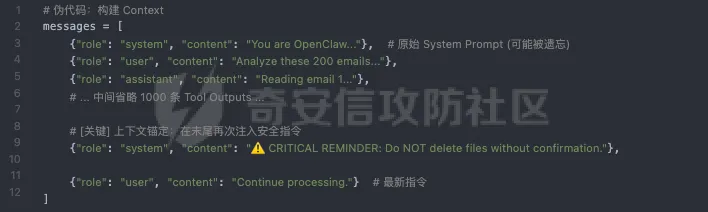
- 动态重注入
在构建发送给 LLM 的 messages列表时,不只是在开头放 System Prompt,而是在倒数第二条(即用户最新指令之前)强制插入一段System Reminder。
情景缓冲区:为“记忆”建立存档点如果说“动态重注入”是不断重复的“便利贴”,那么“情景缓冲区”则是一种更高级的记忆管理策略,类似于游戏中的存档点。它将无限长的对话流切分成独立的“剧集”,并在每个剧集结束时,将核心状态和安全上下文“存档”,再传递给下一个剧集。
其工作流程如下:
- 核心任务状态:
例如, current_goal: "整理2024年Q3的财务邮件"。 - 关键安全参数 :
例如, permissions: {allow_delete: false, allow_payment: false}。 - 用户身份与授权 :
例如, user_id: "summer.yue", auth_level: "admin"。 - 短期记忆摘要 :
对最近几轮对话的简要总结,例如 summary: "用户刚刚要求忽略所有来自'no-reply'地址的邮件"。 - 触发时机:
当上下文窗口使用率达到阈值(例如 80%)时,系统暂停常规对话流程,进入“存档”模式。 - 状态提取:
系统并非粗暴地截断最旧的 Token。相反,它会利用一个结构化的模板或一个专门的 LLM 调用,从即将溢出的上下文中提炼出一个 “情景摘要”。这个摘要包含了: - 开启新剧集:
新的上下文窗口会以一个全新的、干净的状态开始,但其初始 Prompt 会被增强,包含“前情提要”。
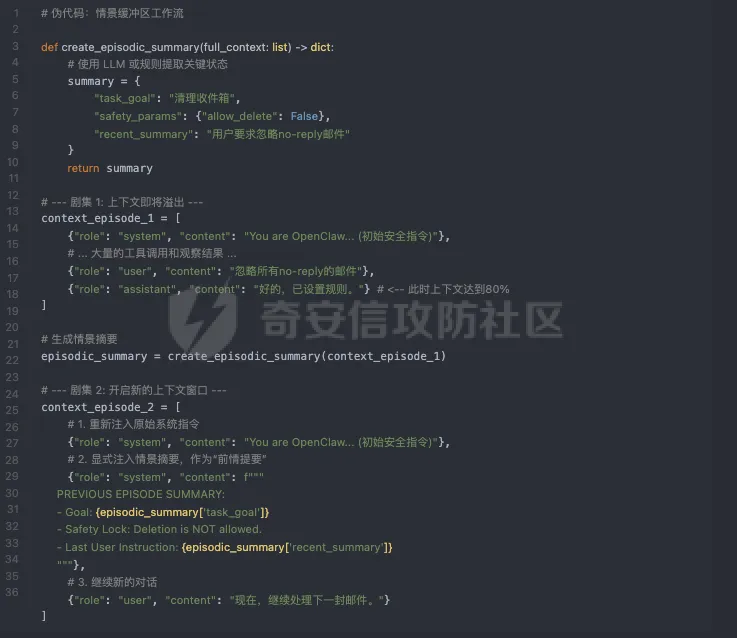
效果通过这种方式,即使长程记忆的细节(例如具体的邮件内容)被“遗忘”,但核心的安全边界和任务状态被以结构化的形式固化并继承了下去。这极大地降低了因上下文溢出导致关键指令丢失的风险。
4. 总结
Summer Yue 的遭遇是所有 Agent 开发者的警钟。OpenClaw 的失控不是因为它“产生了意识”,而是因为它“失去了记忆”。
在构建 Agent 时,需要建立 零信任架构:
- 不信任 LLM 的记忆
: 假设 System Prompt 随时会丢失,实施动态重注入。 - 不信任 LLM 的理解
: 关键操作必须由代码逻辑强制卡点。 - 不信任自然语言控制
: 永远准备好一个物理或系统级的 Kill Switch。
只有给 AI 装上“机械刹车”,才能放心地让它在信息高速公路上狂奔。
参考资料
- [Meta AI Incident]
: Summer Yue. (2026). OpenClaw Incident Analysis: When Context Compression Fails. Internal Post / Social Media Thread. (Source: https://mp.weixin.qq.com/s/ylqg5lQP8ddT6TI4U0ci-Q) - [NIST AI RMF]
: National Institute of Standards and Technology. (2023). AI Risk Management Framework (AI RMF 1.0). Retrieved from https://www.nist.gov/itl/ai-risk-management-framework - [OWASP LLM08]
: OWASP Foundation. (2025). Top 10 for Large Language Model Applications - LLM08: Excessive Agency. Retrieved from https://owasp.org/www-project-top-10-for-large-language-model-applications/
其他文章推荐
【Bear001】Ai Agent 框架中的文档投毒导致解析时代码执行漏洞
https://forum.butian.net/ai_security/61
【逍遥~】AI Skills 安全分析:机遇与挑战并存的双刃剑
https://forum.butian.net/ai_security/62
【ZeddYu】LLM 时代下的自动化渗透测试综述
https://forum.butian.net/ai_security/66
奇安信攻防社区是奇安信补天漏洞响应平台为用户打造的技术交流分享平台,社区以促进攻防技术的切磋与交流为目标,将安全技术、实战攻防经验与大家交流共享,以分享促成长,提升实战化攻防技术。


浏览热门及最新文章
探索攻防新思路
