 夜雨聆风
夜雨聆风我是青玉白露,大厂程序员,主业写代码,副业做 AI 工具和内容。
最近看 OpenClaw 源码的时候,我有个很直观的感受:
它的上下文,真的很多。
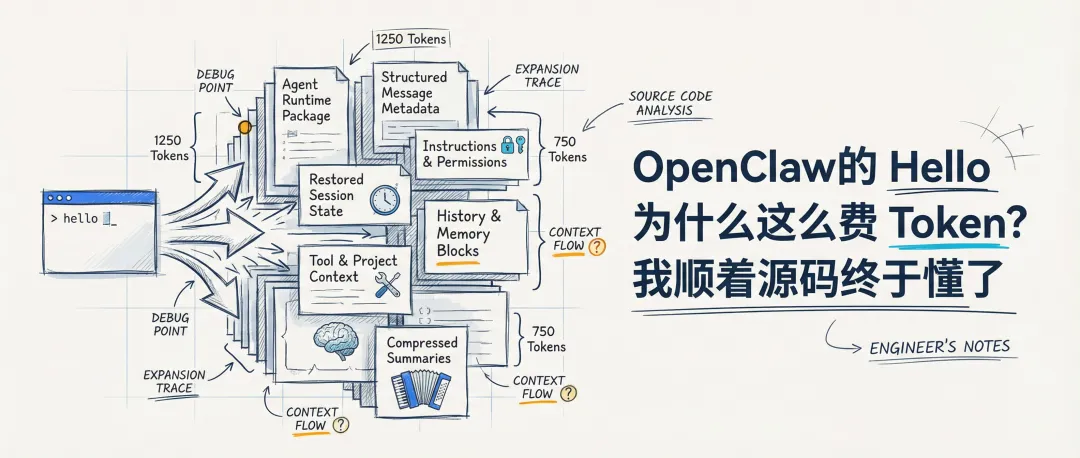
多到什么程度?
你以为你只是发了一句 hello。
但系统送进模型里的,远远不止这一句。
这也是为什么,OpenClaw 的 token 消耗会比较快。
不是它“乱花”。
而是它在模型前面,先塞了很多层上下文进去。
它每一轮都不是只带“用户刚发的那句话”。
它带进去的,还有这些东西:
消息本身的结构化信息 当前会话继承下来的状态 指令、权限和路由规则 群聊或系统事件相关信息 技能、工具、项目上下文 历史记录、记忆和压缩后的摘要
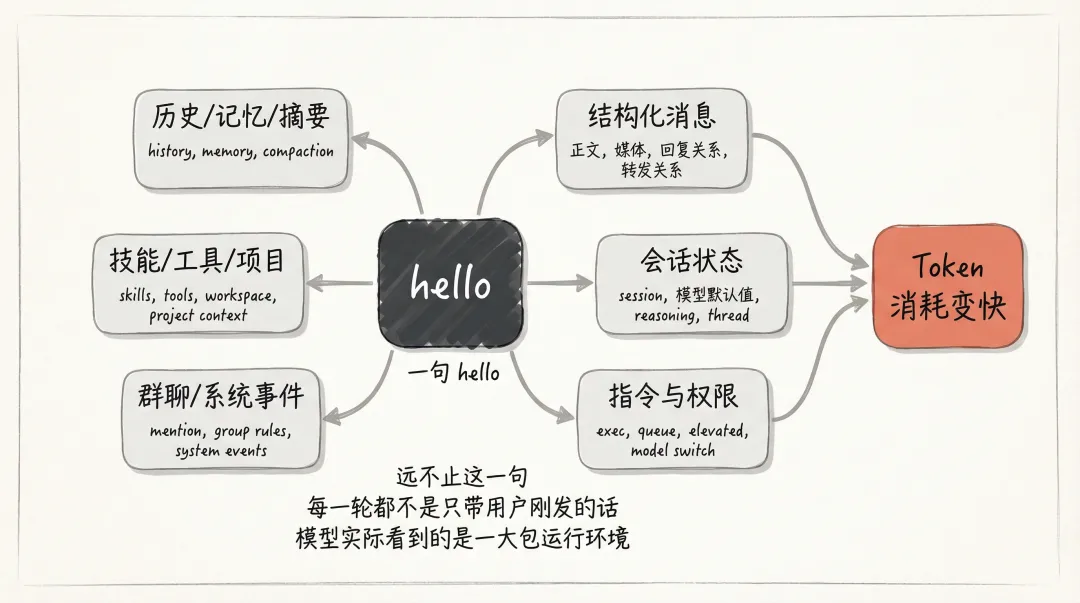
OpenClaw 上下文总览图
你表面上看到的是一句 hello。
模型实际看到的,是一句 hello 加上一大包运行环境。
上下文一多,token 自然就上去了。
为什么会消耗这么快
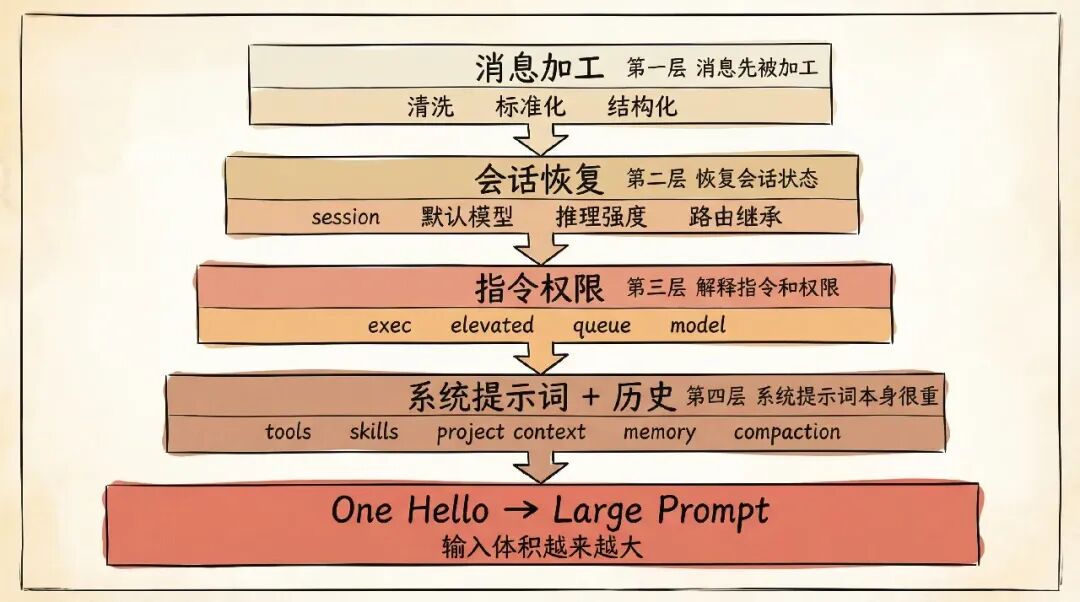
Token 消耗分层图
第一层原因,是消息在进入模型前,会先被“加工”。
OpenClaw 不会把原始文本直接喂进去。
它会先做清洗、标准化、结构化,把消息正文、媒体、回复关系、转发关系、群聊信息、来源信息这些内容整理好。
也就是说,你发的是一句话。
系统拿到的是一个完整消息对象。
第二层原因,是它会恢复会话状态。
这一步很关键。
因为 OpenClaw 不是按“单轮聊天”来做的,它更像一个持续运行的 Agent。
所以每次回复前,它都要知道:
这句话属于哪个 session 之前有没有开过新会话 当前默认模型是什么 推理强度是不是被改过 路由目标、线程信息、发送策略要不要继承
这些信息一恢复,context 就不是一条消息了,而是一段对话历史上的“当前位置”。
第三层原因,是它会解释指令和权限。
你看到的是一段自然语言。
系统看到的,可能还包含运行指令。
比如是否开启更强推理、是否允许执行、是否切模型、是否走特定队列。
有些能力还要做权限判断。
这些东西虽然不是用户正文,但都会变成这轮运行的上下文条件。
第四层原因,是系统提示词本身就很重。
OpenClaw 不是只给模型一个简单 system prompt。
它还会把可信元数据、不可信上下文声明、群聊行为约束、系统事件、工具能力、技能内容、工作区信息、项目上下文一起打包。
如果再叠加历史记录、记忆刷新、压缩摘要,这一轮的输入体积就更大了!
那为什么它非要塞这么多上下文?
这才是重点。
因为 OpenClaw 不是一个只负责闲聊的壳子。
它要解决的事情,比“陪你对话”复杂得多。
它要保证同一个用户在不同轮次里,行为尽量稳定。
它要知道这轮对话跟上一轮是什么关系。
它要区分哪些内容可信,哪些内容不可信。
它要决定当前能不能执行工具,能不能提权,能不能切换模型。
它还要在群聊、线程、多渠道、多工具环境里保持一致性。
说白了,上下文多,不是为了炫技。
而是为了把 Agent 变得更可控、更安全、更连续。
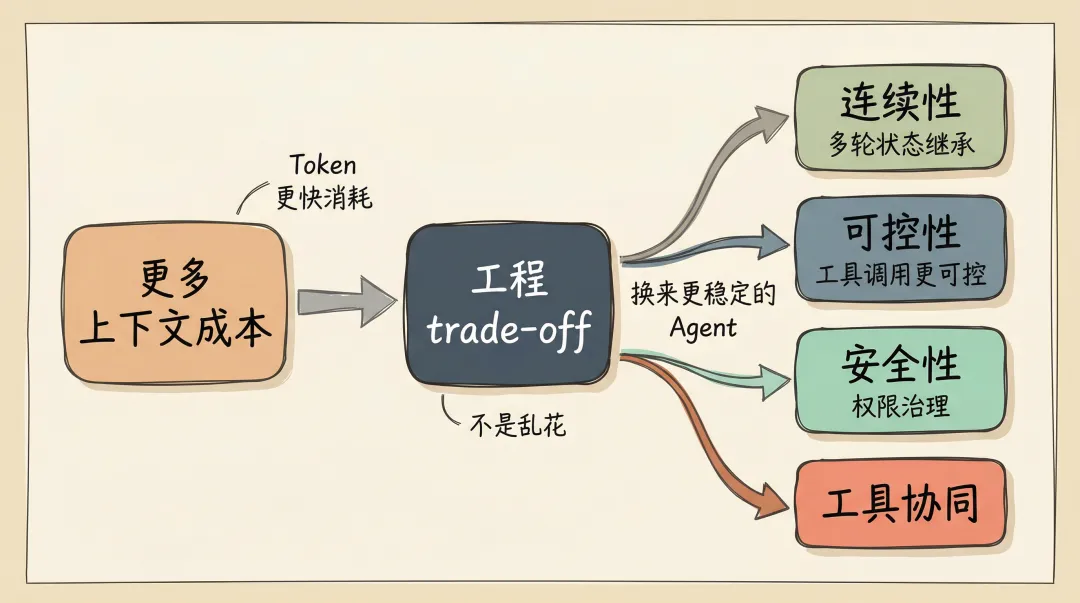
更多上下文换来什么能力
如果没有这些上下文,会发生什么?
也很简单:
模型不知道当前会话继承了什么状态 工具调用容易失控 群聊和私聊行为容易混掉 路由和权限判断容易出错 回答前后不一致,稳定性变差
你有没有发现,很多 Agent 产品一开始看着很轻,token 也省。
但一做长对话、做工具调用、做多轮状态继承,就开始变得不稳定。
因为模型在长上下文,本就很不稳定···
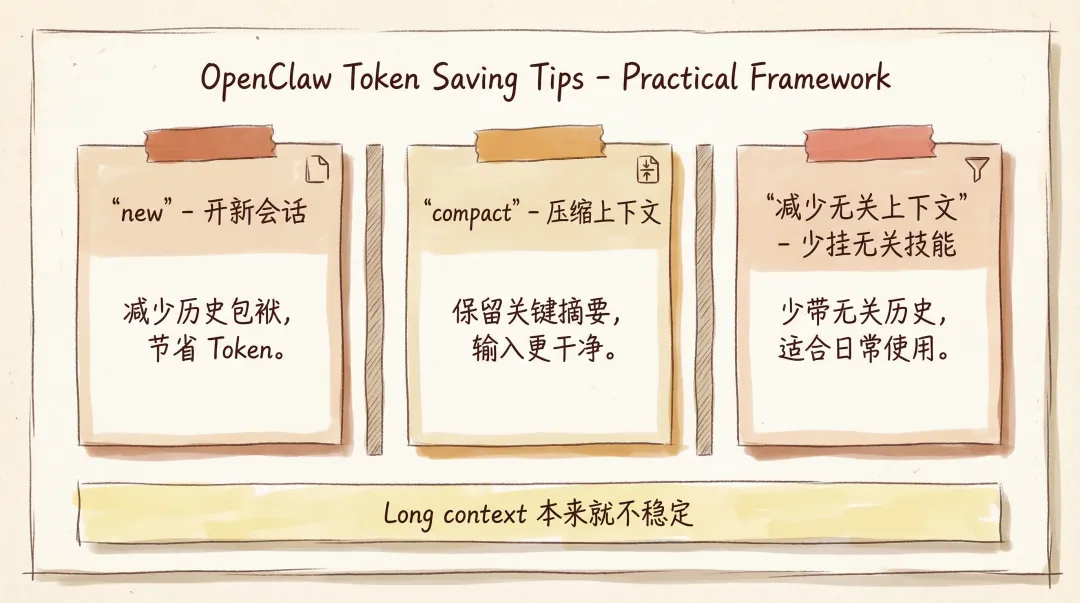
OpenClaw 节省 Token 建议图
我们平时,多使用 new 或者 compact,其他节省龙虾Token的方法可以看我另外一篇帖子。
