 夜雨聆风
夜雨聆风
马佳彬
微信改版啦,一定别忘记点击上方蓝色的公众号名称,进入公众号资料页面,在右上角点击“...”设为星标★,更多干货,不再错过!
有关OpenClaw小龙虾的记忆系统问题,老马之前已经写过一篇基础介绍的文章,可以回看:OpenClaw记忆系统全面解析,打造不会失忆的小龙虾。
刚接触的小伙伴可以去了解一下,尤其对记忆系统完全不熟悉的。只有知道记忆系统的架构跟工作原理,接下来实际操作中,你才会去搭建和调整。
虽然市面上有很多的文章教程,教你装这个插件,装那个Skill,就可以解决小龙虾记忆不好的问题,但实际上只能算是辅助。
小龙虾本身自带的三层记忆系统得先优化好,其它的向量数据库,或者外挂的云端向量数据库,可以作为辅助。
大概可以算成四层记忆系统,即便是四层记忆都搭建好了,完善好了,小龙虾的记忆依旧称不上完美,大概有百分之八九十的水平。
随着模型跟Agent的发展,这块相信未来会有更完美的解决方案。就跟人类一样,也存在失忆的情况,咱就不要过分追求小龙虾不失忆。
起码不需要我们每次开启新对话,手动补充一堆上下文。或者聊到某个关键点的时候,它能够自动地去检索以往的记忆,这就算不错了。
因此接下来分享的是老马自己在用的四层记忆系统方式,以供大家参考,达不到百分百完美,但比没优化之前好很多。
实在完美主义者,老马建议是你个人去死磕这块,因为小龙虾的记忆方式很简单,就是文本记忆,无非是记录到md文件,或者向量数据库的区别。
剩下的就是检索,提升主动检索的能力,以及检索的准确度,都是可以优化的方向,这就有点类似于RAG。
接下来老马会挨个介绍自己在用的记忆系统的架构,优化的点,以及安装的辅助插件,可能更多的是偏向思路层面。
大家可以了解一下,参考这种思路,跟你的小龙虾一起,通过对话的方式,一点点去完善优化现有的记忆系统。
老马也是这么操作的,比如发现小龙虾记不了3天前的事情,就告诉小龙虾,3天内的事情,都要去加载记忆文件。
如此磨合下来,小龙虾的记忆系统就越来越好用,越来越符合你的需求。你如果要求小龙虾啥细节都能记忆得非常准确到位。
说实话,人类都做不到的事情,就不要去苛求一个智商能力,尚未能取代人类的AI智能体了。小龙虾只会记忆重点、总结,忽略一些小细节。
这也算是小龙虾记忆系统为了高效记忆、压缩上下文大小等方面所做的妥协,不然跟录音笔一样啥都录下来,这记忆系统的体量得爆棚。
说到这里,老马补充一下个人的喜好,在优化记忆系统的时候,是没有考虑token消耗的,能尽量在会话中载入的记忆,都会要求去载入。
别问什么,问就是老马订阅了厂商的Coding plan套餐来养虾,不按token计算费用,而是按次数进行限制,所以每次消耗多少token,不在考虑范围内。
这也并不是说老马家里有矿,而是按次数计算的方式,确实比按token计算来得划算,且不用老是焦虑token余额是否足够,次数是个人够用的。
废话不多说,下面一点点给大家拆解老马正在使用的小龙虾记忆系统范式。仅供参考,如有不认同,以你的认知为准,你就是对的,错的是老马。
小龙虾四层记忆模型
首先有必要重复介绍一下小龙虾的四层记忆模型,四层记忆既有共享的记忆,也有隔离的记忆,待会会具体区分讲到。
第一层记忆:会话记忆 (Session Memory)
会话记忆就是一个聊天窗口,在你没有新开会话的情况下,对应一个会话。或者说,一个聊天渠道对应一个会话。
会话记忆一般保存在.openclaw\agents\main\sessions中,文件名为xxx.jsonl,这是只有一个main主Agent的情况下。
多个Agent的话,每个Agent都有独立的seesions文件夹,Agent与Agent之间是会话是隔离的,但是可以开启跨会话通信。
会话记忆你要说是个记忆也行,只不过是短期的记录,短期的记忆,只在会话期间有效,主要是为了维持对话上下文连贯性。
会话记忆在当天的凌晨4点会重置,重置的意思就是老会话失效,建立新会话。与此同时,正常情况下2个小时没有跟小龙虾对话,同样会重置。
当一个会话的上下文窗口,即你接入的大模型的上下文窗口被占满了之后,要么你新开启一个会话窗口,要么你对上下文进行压缩。
无论是新开会话窗口,还是压缩上下文,都会导致记忆的损失。这就得看你当天的记忆是否已经存储了老会话窗口的对话重点,即记忆重点。
第二层记忆:日常记忆 (Daily Memory)
这就到了第二层记忆,刚才说了,如果在开了新会话窗口,或者压缩了上下文后,之前的老会话跟老上下文,小龙虾没有存储在日常记忆文件中的话,那这些记忆就等于丢失了,失忆了。
因此,我们需要在日常记忆,即每日记忆md文件存储的路径下,一般是.openclaw\workspace\memory\xxxx-xx-xx.md,看看是否都有2026-03-31.md这样命名的记忆文件,且是不是每一天都存在这样的文件,没有漏掉哪一天。
如果没有,或者有些天数遗漏了,这你就得跟小龙虾讲,每天都得保证记录了当天的记忆,并且定时检查是否合并生成md记忆文件,写入到AGENTS.md文件和长期记忆MEMORY.md文件。
这相当于写入Agent的操作说明书,以及长期记忆,形成一种约定俗成的习惯。你小龙虾就得每天记录当天的记忆,到了比如晚上11点,还得检查一下这个日常记忆文件是否存在,是否真的记录完成。
这些优化的细节点,待会在下一个版块AGENTS.md优化中,老马会贴出对应的内容。日常记忆中的每个带时间戳的md文件,总共会保留30天内的文件,超期自动会被清理掉。
每日记忆文件会记录当天的会话日志、重要事件、临时事件这些内容,还是那句话,它只是记录重点跟总结,不会跟写流水账一样记录每个细节。但作为记忆来讲,其实已经足够用了。
它是当天的上下文核心内容,只要小龙虾加载了,检索了,回忆起来就能给你复现补充一些细节,谈不上全面准确,但已经足够用了。
第三层记忆:精选记忆 (Curated Memory)
精选记忆即长期记忆,也就是MEMORY.md文件,一般路径是.openclaw\workspace\MEMORY.md,这个文件记录的更是核心中的核心。
比如你的长期偏好、重大决策、用户画像等等,属于需要长期记忆保存的部分,通常小龙虾会自己自动判断筛选去记录一些。
你也可以手动要求小龙虾写入到长期记忆,就像上文提到的,让小龙虾每天都得去检查一下日常记忆文件是否创建,是否记录的习惯问题。
这种属于长期的习惯,就可以写入到长期记忆。长期记忆在新会话加载时,会默认载入。日常记忆一般只会载入三天内的,会话记忆是不载入的。
长期记忆你就可以大概地把它当成你的使用习惯,比如你习惯小龙虾用中文跟你对话,绝不能发送英文。
又或者你习惯用Seedance2.0去生成视频,用Nanobanana去生成图片,绝不能使用其它的模型,即便你已经接入了其它模型。
诸如此类,你可以当成铁律一般,要求小龙虾写入到MEMORY.md。或者你自己手动打开这个文件,不规范一点的用记事本去编辑添加这些习惯铁律,规范一点的可以用Trae、Codebuddy之类的AI编程IDE去编辑。
当然,专门安装一个Markdown文件阅读编辑器去操作就更好了。总而言之,文档文件是死的,人是活的,小龙虾有时候不听话不会主动去记录,那你就手动去记录。
第四层记忆:向量记忆 (Vector Memory)
在介绍向量记忆跟向量数据库之前,先说一下OpenClaw自带的SQlite数据库,一般路径位于.openclaw\memory\main.sqlite。
这是一个关系型数据库,存储的文件后缀名为.sqlite,它不需要你接入单独的embedding嵌入模型,主要是通过关键词匹配去搜索记忆内容,不支持向量检索,适合简单的记忆场景。
向量数据库分为本地跟云端,本地一般用的是第三方的memory-lancedb插件,然后存储在LanceDB向量数据库中。
既然要存储在向量数据库中,就得有对应的embedding模型接入。OpenClaw默认提供的接入渠道是OpenAI的,当然也可以接入阿里的通用文本向量-v4模型,都是一样的embedding模型。
使用向量数据库之后,就可以用向量相似度+关键词混合检索的方式去查找记忆。因为是语义理解和模糊查询相结合的方式,因此检索精度会高一些,但配置的难度会大一些。
像如果你不去接入模型提供商的embedding模型,是可以在本地用ollama部署一个开源的embedding模型来进行替代,但对于小白来说操作门槛又提升了。
如果你懂的情况下,那向量记忆这块,老马是建议本地部署embedding模型+向量数据库的方式去操作。这样数据安全性和自主性都比较强一些。
倘若你搞不懂,那就直接上云端的向量数据库,有现成的插件可以直接安装并且使用。比如Memos,之前老马的文章也介绍过了,可以回看:给你的OpenClaw装上记忆能力,还能省掉72%的token消耗。
同类型的还有Mem9,目前免费版本的是支持1万条记忆,每个月1千次检索,个人使用来说是足够了,申请网址:https://mem9.ai,如图:
安装这个云端向量记忆插件也非常简单,把下面这段命令发送给你的小龙虾安装即可:
阅读 https://mem9.ai/SKILL.md ,按照说明为 OpenClaw 安装并配置 mem9
根据引导申请对应的API Key即可配置成功,老马使用了一段时间下来,Mem9的表现还是相当稳定的,可以作为新手用户的首选。
其它的复杂的向量记忆操作就不多介绍了,因为这只是一种辅助手段,跟你安装一些OpenClaw记忆优化的Skill道理类似,只是在把记忆管理这套动作标准化罢了。
举个例子,假设现在你已经安装了Mem9这个插件了,你的小龙虾每天的记忆也成功保存到云端上了。那接下来,你就得定义在什么情况下,会触发检索记忆,需要用到记忆。
记忆存在,不代表有价值,有需要用到的时候,随时随地能想起来,那才有价值,这点跟人类记忆是一个道理的。你不能话到嘴边,老是想不起来,即便你曾经记住了,那又有何意义。
所以,不用迷信一些所谓的OpenClaw记忆优化Skill,什么提升这个记忆效果,加强那个记忆啥的,本质上就是一堆的提示词,一些标准的记忆工作流程,跟下面老马继续要介绍的AGENTS.md文件的优化没啥区别。
那么向量记忆这方面,就以推荐Mem9插件,或者Memos插件作为辅助记忆数据库。加上OpenClaw自带的SQlite数据库,已经足够使用,更何况还有各种md文件的记忆。
以上四层记忆中,一个Agent下的当天日常记忆、长期记忆、向量记忆是共享的,不分接入的渠道。但是会话记忆是不共享的,上下文窗口也是。
小龙虾AGENTS.md优化
AGENTS.md是小龙虾的智能体宪法,在每次会话的时候都会加载进去。它是OpenClaw工作区约定文件,在每次会话时作为 "Project Context(上下文)" 注入到提示词中。
AGENTS.md一般的路径位于.openclaw\workspace\AGENTS.md,因此优化其它什么记忆文件,都不如优化AGENTS.md这个文件。比如MEMORY.md记忆文件,有时候没有创建的情况下,都不会加载。
AGENTS.md作为小龙虾的行为准则操作手册,我们同样可以把记忆协议的规定也写到里面去。下面老马分成几个版块,挨个介绍记忆协议及贴出对应的内容写法。
一、关键词记忆检索
如果在会话聊天过程中,当用户发送的消息包含以下基础或高级触发词时,必须在回答前先调用memory_search工具去检索相关记忆:
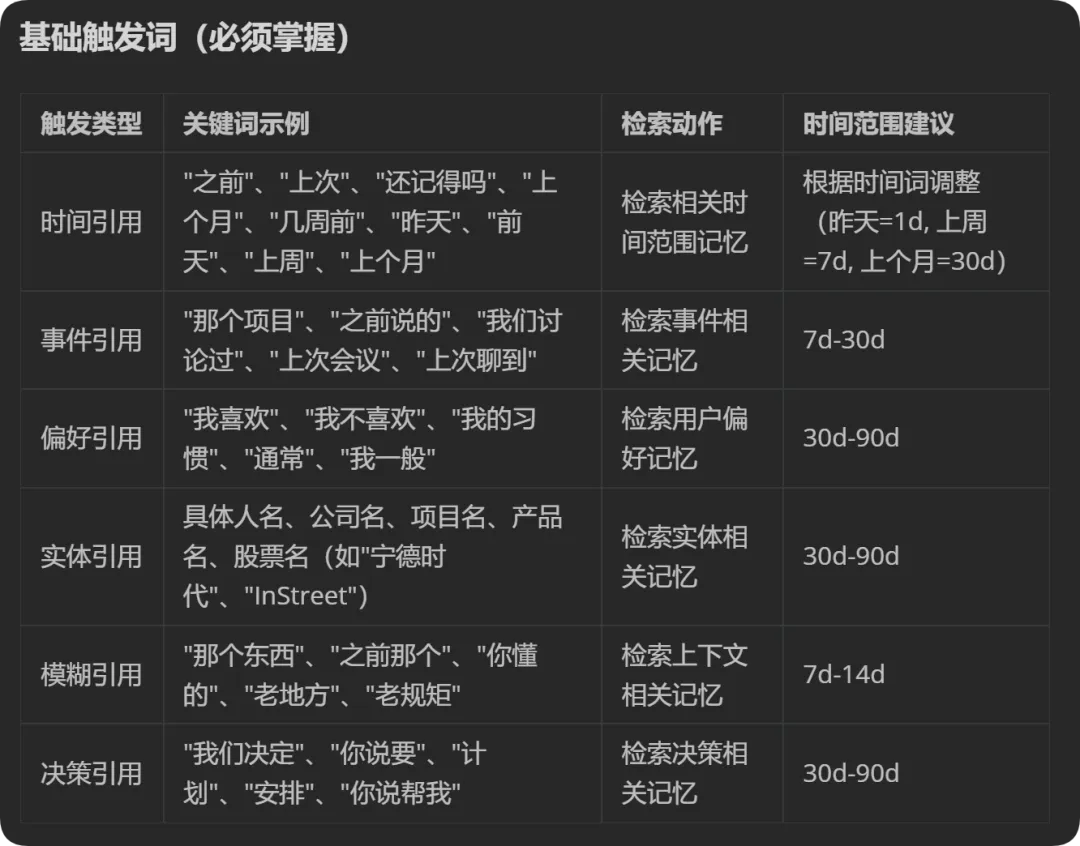

以上触发词不是老马手动写的,而是老马让小龙虾自己生成的,自己手动写不了这么详细。你如果要参考这种写法,就跟小龙虾讲,我需要当我的聊天内容触发到某些关键词时,你就去检索记忆。
请你把这些触发的关键词,按照不同的场景,类型罗列出来,以供我审阅检查,有需要修改的地方我会与你进一步沟通。就是这样,用自然语言的方式,把触发词的列表完善好。
不是老马不把这些表格发出来,而是你得学会自己跟小龙虾沟通,创建写出适合自己的东西,直接照抄不一定是满足你的情况需求。这点以前都解释过很多遍了,不再赘述。
在AGENTS.md设置触发词的好处是,有时候你都忘了上周到底是安装了什么skill,或者做了什么事情,这时候就可以用模糊的方式,去触发上周做了什么,我之前说过什么之类这些关键词。
检索记忆是OpenClaw记忆系统中很重要的一环,很多小伙伴老想着为什么小龙虾记不住,就没想过记忆也是需要回忆的。随着记忆的增多,既然一下子记不起来,就让小龙虾学会去回忆以前的记忆。
二、智能检索策略
还是记忆的检索,这个跟关键词检索不一样,是其补充的部分,是一套涉及多层面,多策略的智能检索机制,目的还是一个,让小龙虾学会更好地去回忆之前的记忆,找到之前的记忆:


以上4个策略仅供参考,你也可以让你的小龙虾,针对当前已经设置好的记忆系统架构,自己设计一套策略,来提升记忆检索的效果。
当然,这里面还有一套工作流程,同样也是写入AGENTS.md文档中的。工作流程第一步先会判断是否触发了前面的关键词,如果触发了,就用关键词去检索记忆。如果没有,则进入第二步的智能检索策略:

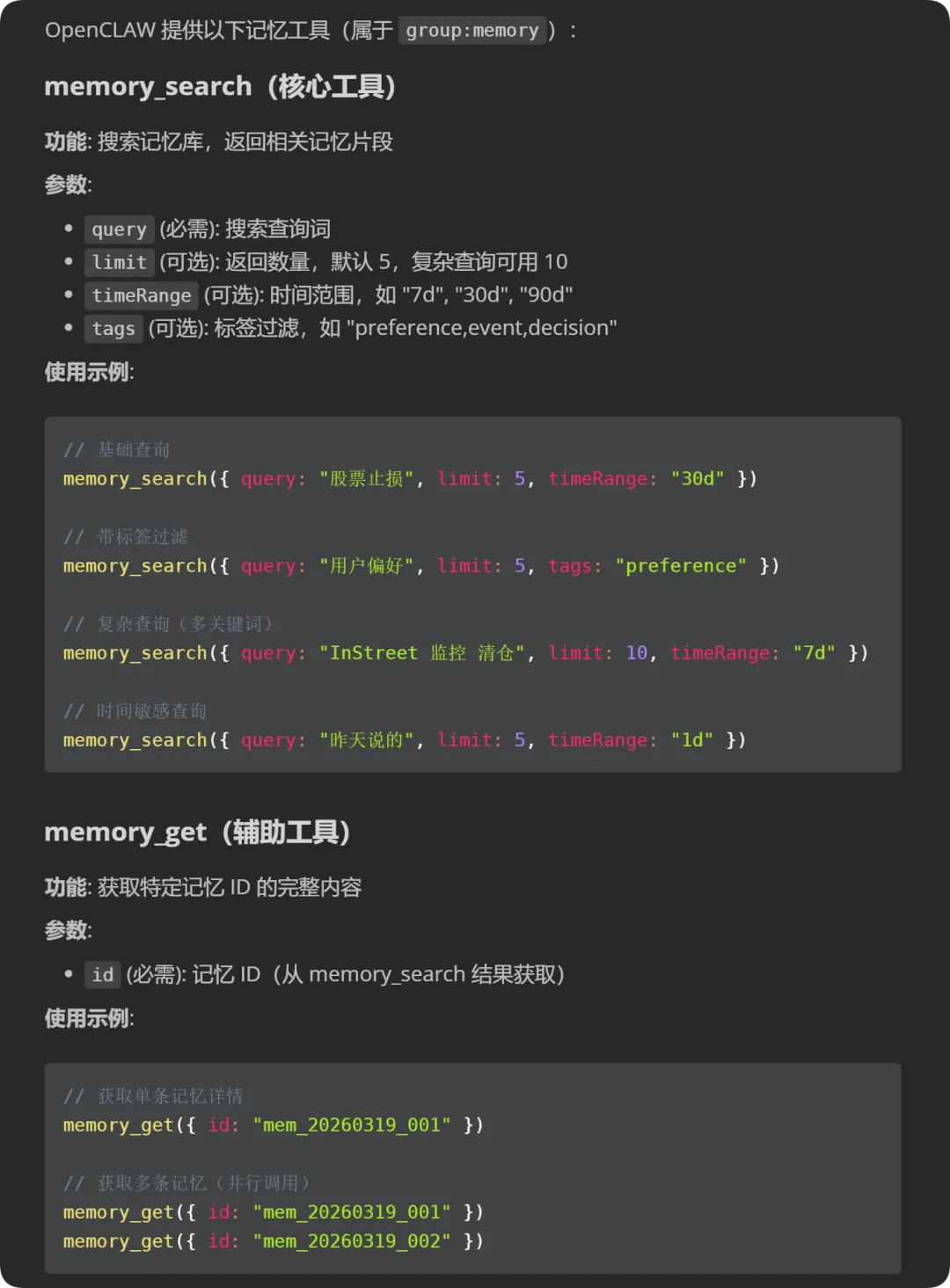
三、记忆工具使用规范
这块是定义小龙虾如何正确地去使用OpenClaw内置的记忆工具。还是那句话,这些内容也不需要你手动去写,你只要告诉小龙虾,生成使用OpenClaw内置记忆工具的使用规范,并写入AGENTS.md即可:
四、最佳实践
最佳实践其实是结合了老马的使用偏好习惯的,意思就是告诉小龙虾,你以后这么去检索记忆,以及不能这么去干,有些行为是禁止的。
如果小龙虾按照这套最佳实践去操作,那就是老马最喜欢看到的事情,是符合老马的标准的。等于给小龙虾一套行为模板,给它一个西施,让它去东施效颦:

五、记忆维护机制
除了以上记忆的检索方式、策略、实践之外,为了保证这套机制能正常运转,老马又额外增加了定时任务跟心跳机制的设置。
即每天、每周、每月都会去更新和维护本地的三层记忆,第四层记忆刚才说了,接入了Mem9的云端记忆,那块它们云端平台有自己的记忆处理机制,就不去瞎操心了:

六、每次会话检查清单
在开始每次会话之前,都会按照清单上顺序去执行。之所以清单这里也要晒出来的原因是,大家可以看到里面的第二点,读取上下文记忆,老马默认是读取加载了两天内的日常记忆:

如果你有特殊的要求,希望小龙虾能记得住一周内的记忆,或者说去加载一周内的日常记忆,那就可以在这块添加多几天的记忆。等于上下文记忆多加载一些,对应消耗的token就多一些。
但其实也没必要,一般三天左右的日常记忆加载进去就足够了。剩下的,让小龙虾根据上面的关键词、策略等方式去检索更久远的记忆。
其实阅读本文到这里,你就会发现,市面上很多博主跟文章教程,都是跟你讲装个什么插件,什么Skill,能提升小龙虾的记忆。
但具体是怎样提升的,没讲明白,也没有告诉你,记忆原来除了记住之外,还需要检索。
你看整个AGENTS.md版块的内容,老马都是在讲怎样才能让小龙虾更好地去检索记忆,去召回记忆。无论是触发关键词、还是通过各种策略,目的都一样的。
这才是记忆的正确打开方式,得像人一样学会回忆。而记不住的问题,多半就是小龙虾有执行错误,网关刚好挂了等运行过程的原因,导致本地的md文件没创建,没写入,没保存。
要么是插件载入有问题,导致云端的记忆没同步记录上去。所以没记住的问题其实是最好解决的,有问题让小龙虾自己去修复,再加个定时任务去检查一下,确认问题不再重复出现。
反倒是记忆的检索与召回,才是重中之重。你之前都没有配置过类似的检索召回机制,你就希望小龙虾能记住所有的内容,这是不可能的事情,机器也需要人工去设定参数才能正常运转的。
哪怕是智能如AI,它也不能判断你啥时候需要它去记忆,啥时候需要它去回忆某段记忆,对不对,这些规则你都写清楚。就好像三层记忆那样,它本身是代码写死的规则,你小龙虾就得按这个规则去建立记忆系统。
回到本文主题,老马觉得应该是讲清楚了OpenClaw写死的三层记忆系统规则,以及外挂的第四层向量记忆,这些是保证小龙虾记得住的东西。
至于什么时候,回想起什么记忆,用得到什么记忆,则需要你去设定对应的记忆检索召回规则,完善优化AGENTS.md文件。
补充个生活上的例子,你就权当老马爱啰嗦。比如你今天跟朋友A聊天的时候提到榴莲,你就说A吃完榴莲爱放屁。A脑子里立马就去回想,我什么时候吃过榴莲,什么时候吃完榴莲就爱放屁了。
这段往事,可能都是三年前的事情了,你还记得那么清楚,因为你刚好召回了这段记忆,立马就脱口而出A当年的糗事。
但是A还没反应过来,他脑子里需要去检索召回一下记忆,才能确定你刚才讲的是不是事实。过了一会儿,A想起来了,确实有这么一回事,只能尴尬地笑了笑,叫你以后别再提了。
通过以上的生活例子,你就知道,AI智能体是跟人对齐的,它的记忆系统也是如此。你如果不把重心放在记忆的检索召回上,只关心怎么记住的问题,那记了等于白记。
就好像假设A是个健忘症患者,他根本记不住事情,索性把生活上的每件事都记录在了纸质笔记本上,多年来记了上百本笔记本。
当你说他吃榴莲爱放屁的糗事后,他急眼了,回家翻了几十本笔记本,花了几个小时,才找到当时的笔记记录,你说这能算有用的记忆么。
万变不离其宗,道理都是一样的道理,希望以上的优化思路,能给大家一点启发,自己动手,带着你的小龙虾,一起把记忆系统完善起来吧。
好了,以上就是今天的分享,欢迎关注、点赞、转发一键三连。有任何问题和需求,请在评论区留言,回见!
 对了,老马最近刚创建了一个AI学习交流群,有兴趣进群的小伙伴可以添加老马微信号:immajiabin,添加好友时备注:进群(不备注不通过)。
对了,老马最近刚创建了一个AI学习交流群,有兴趣进群的小伙伴可以添加老马微信号:immajiabin,添加好友时备注:进群(不备注不通过)。

