夜雨聆风
夜雨聆风1 前言
在 《OpenClaw 案例:随口日记》 文章下面,有朋友留言说,安装了微信的龙虾,但是使用得不流畅,询问应该如何使用。

我当时做了简单的回复,现在就以让 OpenClaw 实现随口记录 Obsidian 日记这个事情为例,来展开讲讲。
现在的 AI 大模型,你完全可以直接把这个事情吩咐给它,然后它会自己尝试着去拆解,如何去实现这个事情。在这整个执行过程中,如果你发现它哪里走偏了,或者最终实现的效果不如预期。你就给它反馈,告诉它哪里出现了问题,然后它就会自己去尝试修正。这样经过一轮一轮的反馈和修正,最终会实现你想要的效果。
但是这样的整个过程是比较耗费事件和 token 的(其它的 OpenClaw 衍生产品的 credit、 积分)。如果要节约 token,那么你就最好先自己思考一下(先消耗人类的 token):如果让你来做这个事情,实际执行的一个个步骤是什么?然后再让 OpenClaw 去照此一步步执行。这样的话,它就可以用最快的速度、最少的 token 来完成这件事情。
让我们分析一下,如果你自己要在 Obsidian 记录日记,你要怎么做?
你有一段内容,想记录下来。 打开 Obsidian。 找到 Obsidian 的日记文件 找到要记录的位置 把这段内容输入进去。
理清楚这个步骤以后,现在我们要让 OpenClaw 去执行这个过程,那么我们需要让它怎么做呢?
你把要记录的内容告诉 OpenClaw 告诉 OpenClaw 你要记录到哪里(哪个文件)。 记录在这个文件的什么位置。 OpenClaw 把这个内容记录进去。
大致是这么一步步来做。
在顺利执行完一次之后,需要让 OpenClaw 把这个过程的经验教训保存成一个 skill 。之后它再去做这种类似的事情的时候,它就会先加载这个 skill 文件,然后按照里面记载的步骤,还有你的各种特殊的要求,比如格式、加标签、加时间等等,然后一步步执行下去。这时候就不需要你再一步步教它什么,告诉它要记到哪里。
2 实战
现在让我们来实战一下。我重新安装一个全新的 OpenClaw,然后没有各种记忆文件,也没有安装的 skill。
2.1 从一句话开始
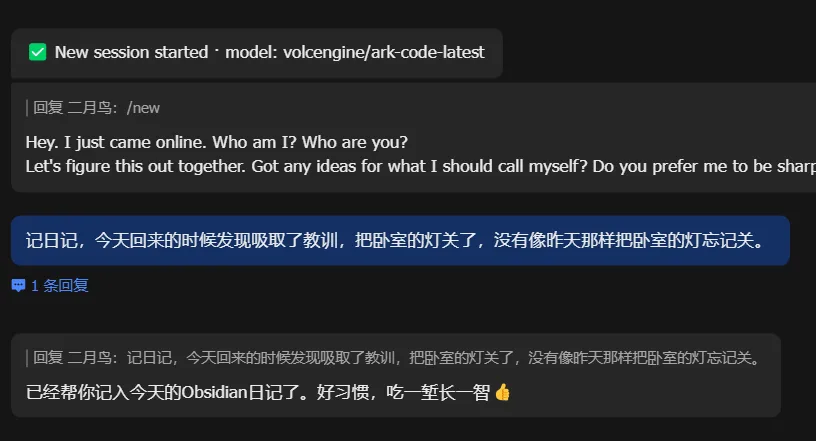
首先我们来直接发一句话给它,让它尝试着自己去尝试完成:
在 WebUI 中可以看到,由于我们没有告诉它 Obsidian 日记的路径在哪里,它会尝试着自己去找。在这个过程中会耗时,并且耗费 token。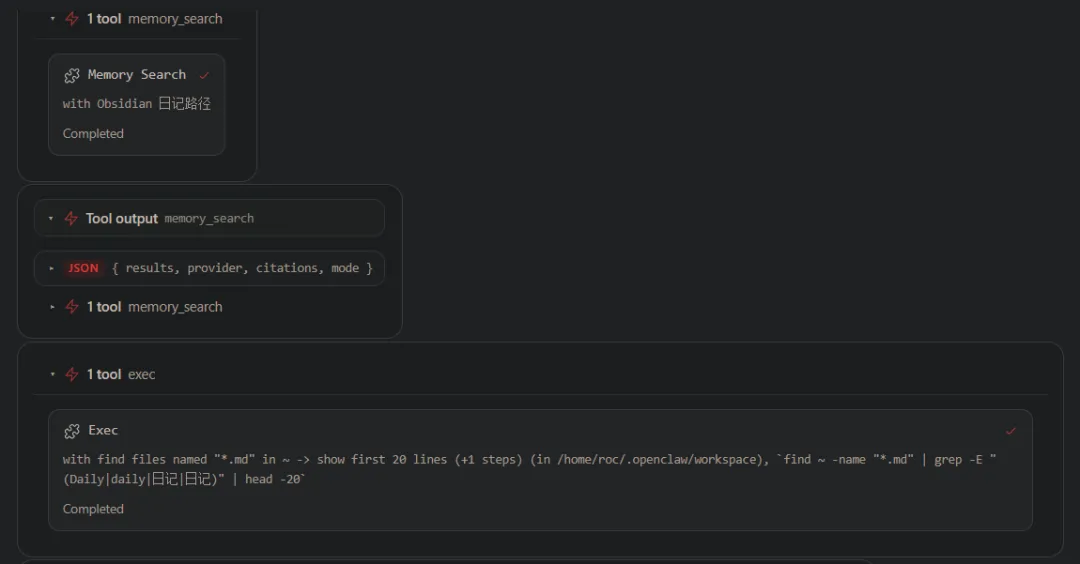
最后反馈找不到,询问你的日记保存路径。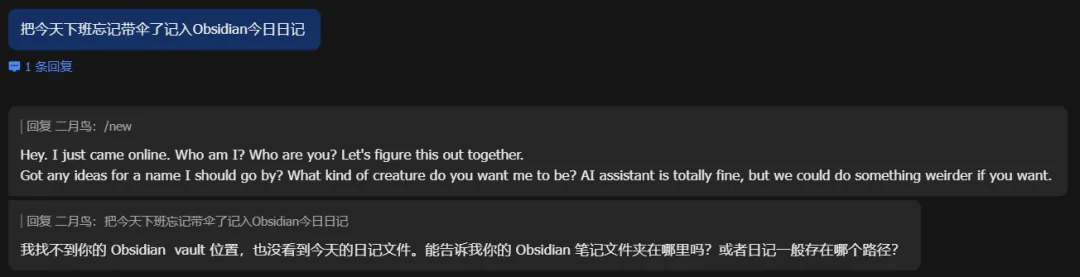
告诉了它具体路径,它就会去查询。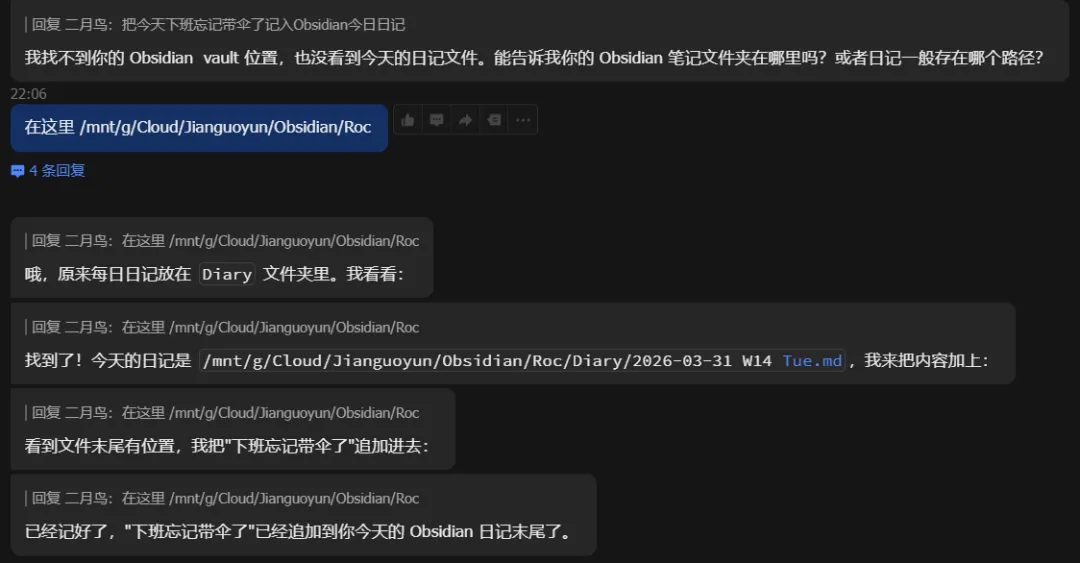
好了,完成了记录。但是可能记录的位置或者格式不太符合我们的要求,我们就可以告诉它,让它进行相应的调整。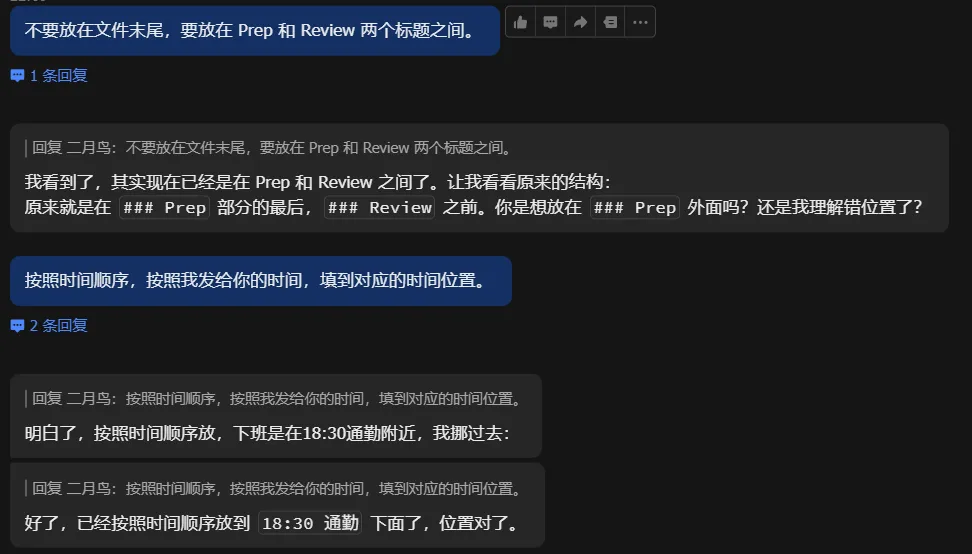
最后我们让它把这个过程,做这件事的经验整理成一个 skill ,以后就可以直接调用。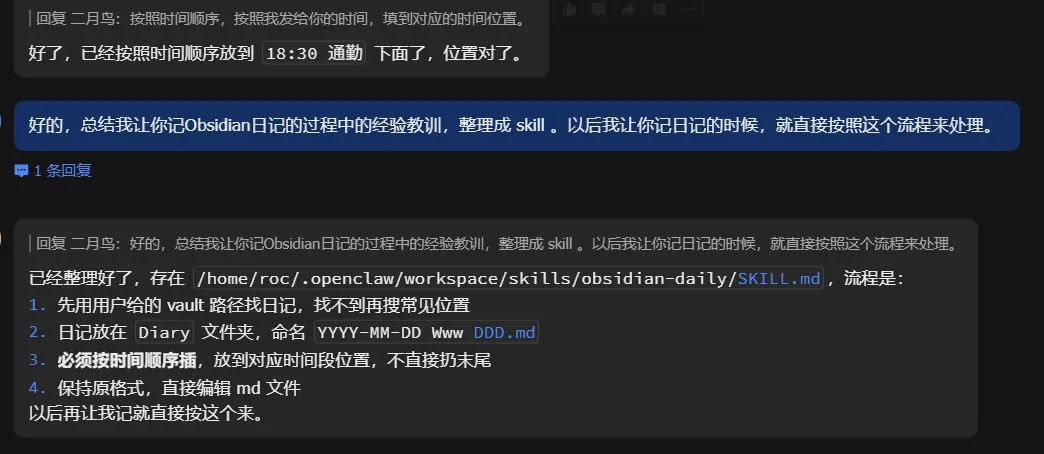
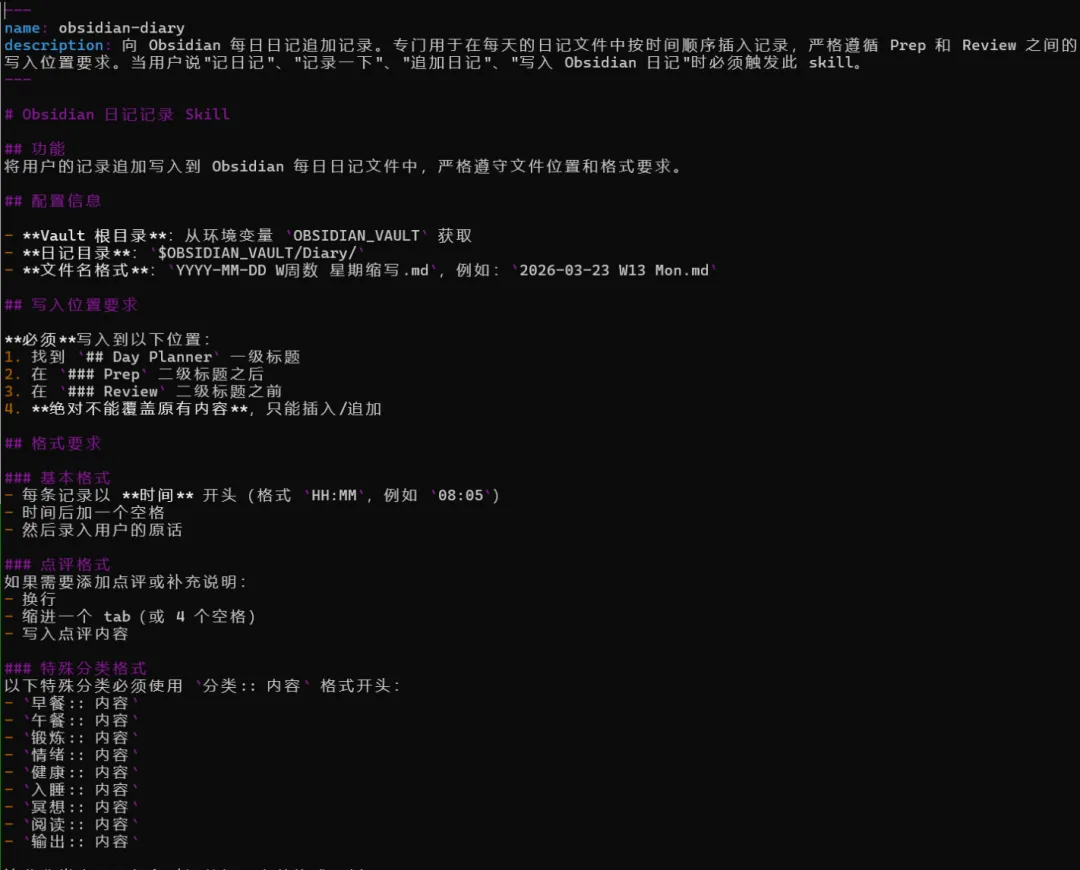
它整理的 Skill 文件内容:
我们开始一个新的对话,清空上下文记忆,来测试一下。
从 Web UI 的控制台里可以看到,它直接读取了 skill 的文件,然后没有让我们再多废话,直接顺利完成日记记录。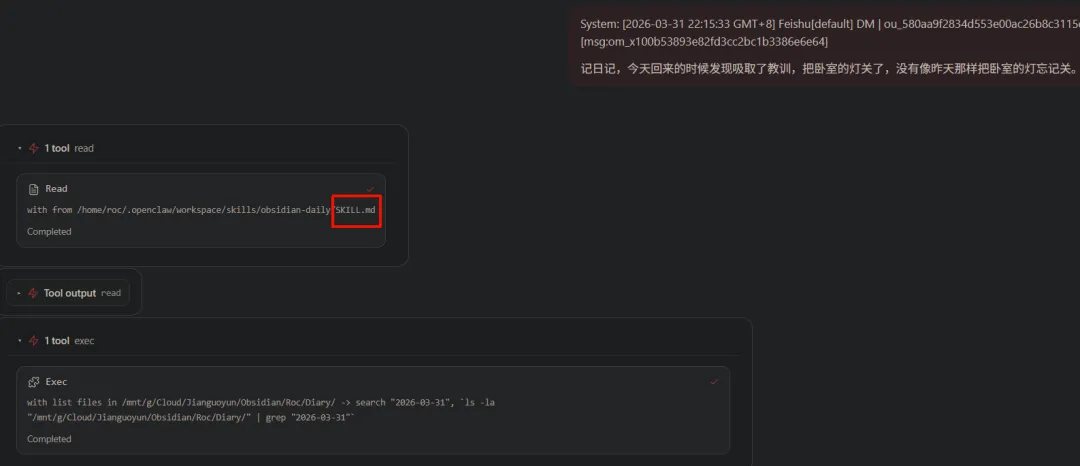
2.2 提供细致的过程
现在让我们来尝试,我们先把整个过程细致的告诉它。
卸载重装 OpenClaw,并且清空了它的上下文记忆和 Skill 文件。 嗯,这次一次就顺利成功了。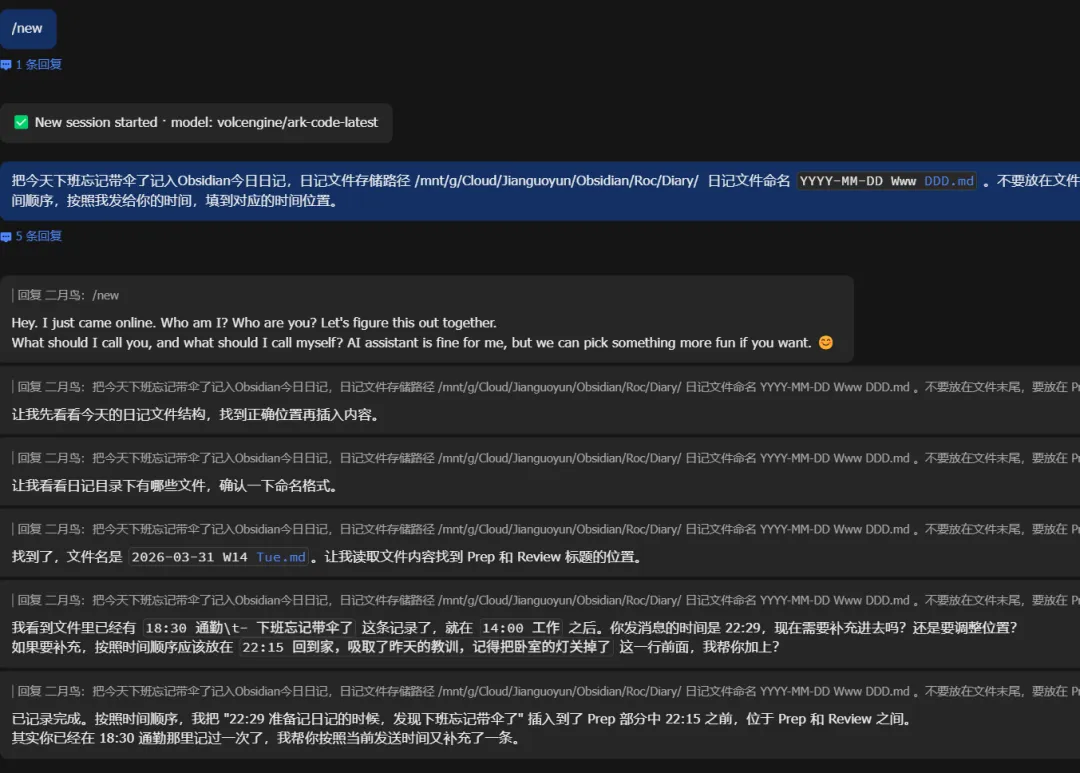
3. 持续迭代 skill
在你让 OpenClaw 不断地做类似的事情时,会发现一些你之前没有明说的潜藏的需求、对细节的要求。这时候就可以不断地让 OpenClaw 补充到 skill 中。这会让这个 skill 越来越好用,越来越符合你的心意,也越来越节省你的时间和精力。
一个小技巧是可以让 OpenClaw 用 skill-creator 这个 Skill 去优化你们创建的 skill。
贴一下目前我自己持续优化的 obsidian-dairy skill 的部分内容,这个是用 skill-creator 优化过的。