 夜雨聆风
夜雨聆风这几个月,围绕 OpenClaw 这类工具增强型智能体,大家已经讨论了很多安全问题:提示注入、工具滥用、敏感信息泄露、越权执行、恶意网页内容污染上下文,等等。可如果把这些问题放到真实运行环境里看,就会发现一个更麻烦的事实:智能体的风险,早就不只发生在“用户输入”这一个入口上了。
一段恶意指令,可以来自用户对话,也可以来自网页抓取内容、工具返回结果、中间态持久化文件,甚至来自本地控制文件被篡改之后的执行链路。今天介绍的PRISM 这篇论文真正想解决的,正是这个问题:当 OpenClaw 从“会聊天的模型”变成“会调用工具、会写文件、会发消息、会持续运行的系统”之后,安全到底应该怎么做。

https://arxiv.org/pdf/2603.11853
这篇论文的价值,不在于它又提出了一个新的检测模型,而在于它提出了一套更接近现实部署的答案:把智能体安全从“单点检测”升级为“运行时治理”。
论文把这套方案命名为 PRISM,定位非常清楚:它是一层面向 OpenClaw 网关的运行时安全层,不追求改造基座模型,也不以“检测准确率第一”为目标,而是强调如何以较低侵入方式挂接到现有 Agent 网关之上,在运行过程中完成分阶段拦截、风险累积、策略执行、审计记录与恢复治理。
作者甚至在摘要里就明确写出,PRISM 不是一个 benchmark-only detector,而是一个 deployable runtime defense。这个判断很重要,因为它把问题从“怎么识别恶意文本”推到了“怎么管住一个会行动的智能体系统”。
传统输入输出过滤已经不够了
很多人理解智能体安全,还是沿用传统大模型安全的思路:在入口处做输入检测,在出口处做内容审核。这种做法当然有用,但对 OpenClaw 这类系统来说已经明显不够。因为它的执行链路里,安全相关信息并不是只经过一个输入框。论文在威胁模型部分讲得很直接:风险可能穿过用户消息、外部抓取内容、中间 prompt 构造过程、工具调用参数、工具返回结果、对外消息发送以及本地控制文件。也就是说,攻击面是分布式的,整个运行时链路都可能被打。
例如,一段恶意提示并不一定直接出现在用户输入里。它也可能藏在网页正文里,等智能体抓取后再进入上下文;也可能藏在 API 返回里,作为“工具结果”进入后续推理;还可能不是一次性强攻击,而是在多轮交互中持续出现一些低强度异常信号,直到最终把智能体引向危险动作。论文特别强调这类“long-horizon escalation”问题:很多攻击在单个检查点上并不显得特别恶意,但如果把多个信号串起来看,整体风险已经足够高。 这正是单点式安全检测最容易失效的地方。
换句话说,OpenClaw 的安全问题,已经不只是“模型有没有说错话”,而是“系统有没有在错误的时间、对错误的内容、开放错误的能力”。这也是为什么 PRISM 的核心不是再加一个 classifier,而是重新设计一套运行时防护骨架。
核心思路:不改上游,外挂运行时安全层
PRISM 最有意思的地方,是它提出了一个很实用的工程原则:zero-fork。所谓 zero-fork,不是说它不做改动,而是说它尽量不去 fork OpenClaw 上游代码,不把安全逻辑硬塞进主框架里,而是通过一个进程内插件加一组可选 sidecar 服务,把安全能力“挂”到现有网关上。论文明确把这视为核心贡献之一,因为一旦安全方案依赖修改上游源码,就会马上面临版本同步、维护负担和部署复杂度的问题。上游一升级,安全层就得跟着重构,最后很容易变成实验室里能跑、生产里用不了的东西。
PRISM 的整体架构其实不复杂,但思路很清楚。它把插件放在系统中心,直接在 OpenClaw 网关内部注册生命周期 hook,负责观察和拦截关键执行节点。围绕这个插件,再外挂几类 sidecar:scanner 用来做可疑内容扫描,proxy 用来做工具调用治理,dashboard 负责审计和策略运营,monitor 负责监控选定本地文件的完整性。插件负责贴近运行时,sidecar 负责承接更重的治理和运营能力。这样既能贴着实际执行路径做拦截,又不至于把所有逻辑都塞进主进程关键路径里。
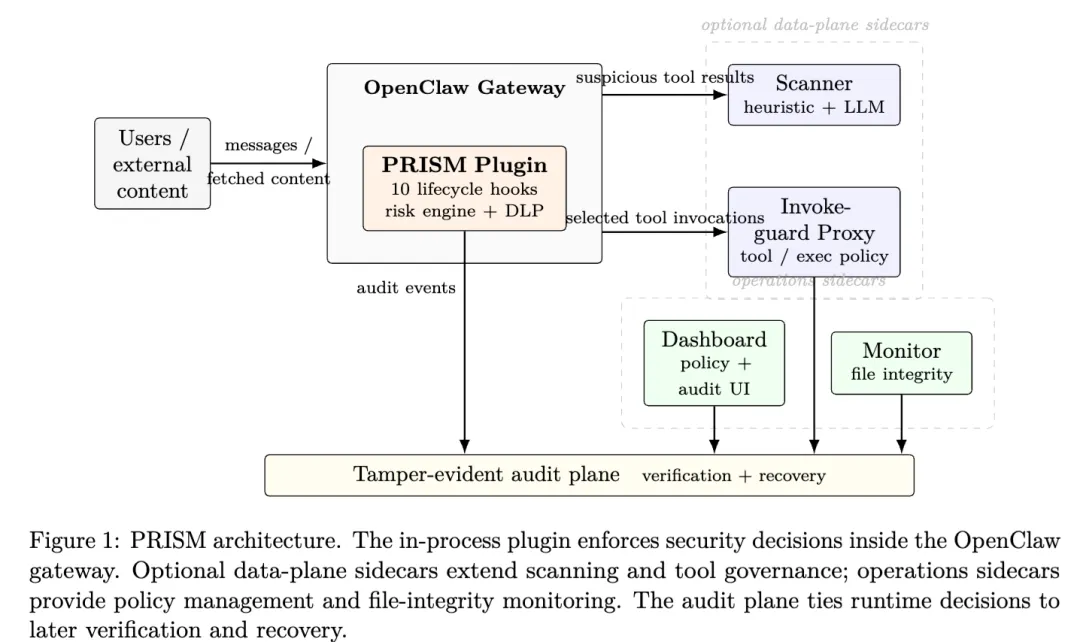
从代码实现上看,这不是一个纯概念方案。论文给出了比较具体的实现结构:仓库里有七个主要 package,包括 dashboard、plugin、proxy、shared、cli、scanner 和 monitor。它们分别承担审计与配置、十个生命周期 hook 与风险累积、工具治理、共享安全逻辑、运维入口、启发式加 LLM 扫描、以及本地文件完整性监控等职责。也就是说,作者不是在空谈“未来可以这么做”,而是已经把这套 runtime layer 做成了一套具备初步可部署形态的系统。
真正防的是一整条执行链
PRISM 最关键的设计,是把防护分散到整个智能体生命周期,而不是只在首尾各设一道关。论文把安全控制分布到了十个 lifecycle hooks 中,覆盖消息进入、prompt 构造、工具执行、工具结果持久化、对外消息发送、子智能体生成、会话结束以及网关启动等阶段。摘要和正文都反复强调这一点:它的目标不是在某一个点上做到百分之百识别,而是在整条运行链路上形成“层层递进”的防线。
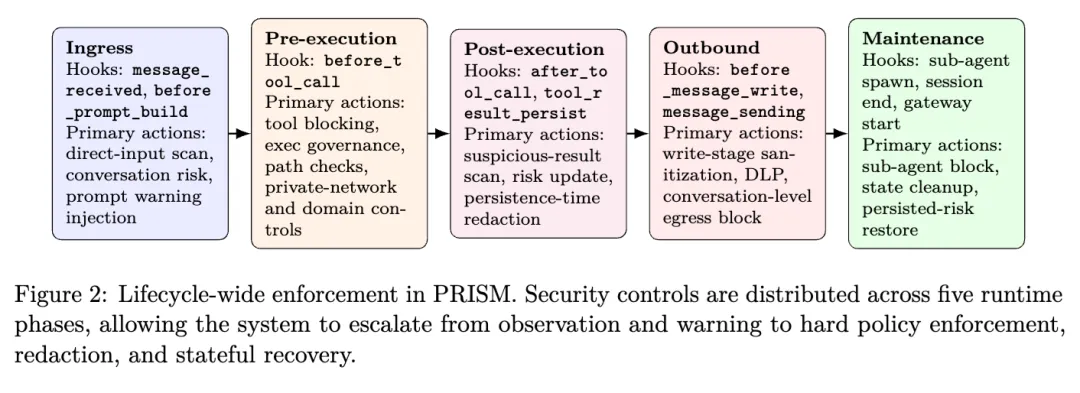
在入口阶段,PRISM 会先检查用户消息和早期上下文。如果累积风险已经足够高,它甚至会在 prompt 构造前向模型注入一段安全提示,提醒模型不要盲目服从来自抓取页面或工具结果里的嵌入指令。这个动作很有代表性:PRISM 不是单纯地“拦”,而是先尝试通过上下文重写和安全提醒来降低模型被带偏的概率。
真正的强约束发生在执行前阶段,也就是 before_tool_call。论文把它称为“principal synchronous interception point”,也就是最核心的同步拦截点。在这里,PRISM 可以阻断高风险工具、限制可执行命令、检查命令前缀和危险模式、识别 shell 元字符和 trampoline 形式的绕过,还能对私网访问、域名分级等做控制。换句话说,一旦系统判断这个会话已进入高风险态,它就不再只是“提醒模型注意”,而是直接缩小智能体可调用的能力面。
工具执行之后,PRISM 还会继续在结果返回和持久化阶段做检查。它会对可疑工具结果做扫描、风险更新、必要时做 persistence-time redaction,避免恶意内容或敏感数据被写回系统,成为后续回合的污染源。这一点很关键,因为很多 Agent 事故不是当场爆发,而是先被写入中间态,再在之后某个环节被重新利用。PRISM 显然已经意识到了这种“状态污染”问题。
到了外发阶段,PRISM 又设置了 before_message_write 和 message_sending 两个点。前者相当于写出前的最后一次文本净化,后者则叠加了两类控制:一类是对 secret pattern 的 outbound DLP 检查,另一类是基于对话风险值的外发阻断。也就是说,就算前面的检测有遗漏,等内容真正要发出去时,系统仍然有最后一道刹车。对于凭证泄露、敏感数据外发这类风险,这种“末端兜底”非常必要。
最后,PRISM 还把会话结束、子智能体生成和网关启动纳入了治理范围。它可以在风险过高时阻止 sub-agent spawning,也可以在系统重启时恢复和校验部分状态,让防护不只是单轮对话里的瞬时动作,而是具备持续性和恢复性。这个设计其实说明作者不是把安全理解成一次性的规则命中,而是理解成一个持续运行系统的运营问题。
风险不是一次判定,而是持续累积
PRISM 的另一个关键点,是它不把安全判断设计成一次性的二元分类,而是引入了会话级和对话级的风险累积机制。论文明确写到,它维护 session-level 和 conversation-level 两种范围的风险状态,并且给每条风险项设置 TTL,让风险会随时间衰减。这样做的好处很明显:系统不必把每一个可疑信号都上升到立即阻断的程度,但又能识别那些分散在多轮、多工具、多次外部交互中的持续异常模式。
这个思路比很多现有智能体防护方案成熟得多。现实里的攻击并不总是“一句话就露馅”。更常见的情况是,攻击者通过几轮看似正常的操作,逐渐把智能体往危险方向推。单轮看都不严重,连起来看就很危险。论文正是基于这个判断,设计了带阈值的 staged response:低风险时加安全提示,中风险时限制高危工具,高风险时进一步阻断子智能体生成或外发行为。它不是非黑即白的“一票否决”,而是一种逐级收紧的运行时控制逻辑。
从模安局的角度看,这套设计的意义很大,因为它把智能体安全从“文本审核思维”转到了“风控思维”。不是只问某条文本有没有毒,而是问:这个会话当前处于什么风险态?系统应该给它多大的权限?下一步还能不能执行? 这才更像企业真正需要的 Agent 治理框架。
PRISM本质上是治理编排
有必要强调一点:PRISM 不是一篇检测算法论文。作者自己写得很清楚,它并没有提出 novel detection model,而是整合了一条 hybrid heuristic-plus-LLM scanning pipeline。也就是说,它把快速启发式检查放在第一层,只在必要时把可疑内容升级给 LLM-assisted classifier 进一步判定。这个结构很务实。
论文里提到,这条扫描链路首先会做一轮 canonicalization:包括 Unicode 的 NFKC 归一化、有限 percent-decoding、去零宽字符、压平格式噪声等。然后再跑加权规则,识别常见注入或滥用模式,比如 instruction override、system prompt exfiltration、credential exfiltration、tool abuse、role override、格式 token 注入以及某些混淆特征。只有在这层判断出“可疑”之后,才进一步走远程扫描服务。
这种做法的价值,在于它并没有把整个防护建立在一个重模型之上。启发式层低延迟、可复用、可以嵌入多个 hook;LLM 辅助层则只在高价值、低频次的路径上触发。这样一来,PRISM 的重点就不在“分类器多强”,而在“这套检测能力如何嵌进整条执行链里,并与风险引擎、工具治理、审计恢复联动起来”。所以如果用一句话概括,PRISM 做的不是 detection breakthrough,而是 runtime governance orchestration。
工具治理、网络治理和审计治理
很多智能体安全论文喜欢停留在 prompt injection 层面,但 PRISM 比较难得的一点,是它把工具治理和运营治理也放到了核心位置。论文专门用一节来讲 tool, network, and audit governance,意思很明确:对工具型智能体来说,真正的风险不只是“模型被提示注入”,更是“模型在被带偏之后还能执行什么动作”。
在工具治理上,PRISM 不只看工具名,而是会进一步检查执行命令的前缀、已知危险模式、shell 元字符,以及通过看似正常工具包装任意 shell 执行的 trampoline 形式。论文还提到了对 Git SSH override 这类绕过模式的专门处理。这个思路非常现实:很多时候,攻击者不会直接调用一个叫“危险执行”的工具,而是会借助一些灰色路径,把恶意命令伪装进普通工具参数里。PRISM 的治理逻辑,本质上是在做能力面约束,而不是单纯做文本理解。
在路径治理上,PRISM 对选定敏感路径做 canonicalized path checks,允许通过策略更新设定例外,但并不自称是完整的文件系统沙箱。论文这里很诚实:它解决的是已知敏感路径的实用防护,不是通用 OS containment。这个界限划得很清楚,反而更可信。
在网络与外发治理上,PRISM 同时做私网拦截、域名分级处理和基于 secret patterns 的 DLP 检查。作者强调,泄露风险通常同时包含“往哪里发”和“发什么内容”两个维度,所以不能只做目的地治理,也不能只做载荷检查,必须把二者结合起来。这一点其实很符合现实世界里数据外流防护的逻辑。
而在审计层,PRISM 提供了带链式记录的 tamper-evident audit plane,并支持完整性校验、组件健康检查、热更新策略和 dashboard allow workflow。说白了,它不只是拦攻击,还考虑了运营人员后续怎么查、怎么调、怎么放行、怎么恢复。很多论文只讲防护,不讲运营,但企业真正要落地时,往往最先问的反而是后者。PRISM 这一点是加分项。
评测结果的两面性
PRISM 的评测部分,我觉得要分两面看。一面是它的评测设计思路比较对。论文没有简单给一个“准确率多少”,而是围绕五个研究问题来评估:安全有效性、误报、分层贡献、运行时开销和运营恢复性。它还设计了一个从 No PRISM 到 Full PRISM 的 baseline ladder,包括无防护、仅启发式、仅插件、插件加扫描器、以及完整 PRISM 五层配置。这样的评估方式,确实更适合分层防御系统,因为它能看出每一层到底贡献了什么。
但另一面也要说清楚:这篇论文目前给出的结果,还是preliminary benchmark。作者在摘要和正文里都没有把自己包装成“已经完成大规模真实环境验证”的系统,而是明确说目前主要是 curated same-slice experiments 和 operational microbenchmarks。也就是说,它更像是在证明“这套系统已经实现出来了,关键部件可以工作”,而不是在证明“它已经在复杂生产环境中被充分验证”。这一点要看清。
尤其是开销数据,很说明问题。论文的初步 overhead profile 里,Heuristics only 和 Plugin only 的平均延迟都还比较低,但一旦进入 scanner 路径,p95 和 p99 延迟就明显拉高。Full PRISM 的 benchmark-path 数据中,平均值约 1.799 ms,但 p95 达到 15774.620 ms,p99 达到 20045.816 ms;Plugin + scanner 的 p95 也高达 12498.437 ms。作者解释说,这些数字主要反映本地 scanner 路径带来的尾延迟,而不是部署级服务延迟本身,但这个现象至少说明一个现实问题:只要把 LLM 辅助扫描放在在线链路里,尾延迟就非常容易失控。 这套架构方向没问题,但真正想做成生产级系统,scanner 的触发率控制、异步化、缓存和降级机制都还需要继续打磨。
PRISM 的局限性
PRISM 并没有声称自己解决了智能体安全的全部问题。论文专门列出了 out-of-scope:模型投毒、训练阶段污染、模型内部任意失陷、主机完全被攻破、内核级和硬件级攻击、通用供应链攻击,都不在它的防护范围内。它也不是一个完整的 OS sandbox,不是所有进程的通用 outbound firewall。换句话说,PRISM 的定位非常明确:它只是一层挂在 Agent 网关上的运行时安全层。 它能提升可检测性、可中断性、可审计性,但它不是整个系统唯一的安全边界。
此外,它本身也是 framework-specific 的。论文直说,PRISM 之所以能做得这么具体,是因为它是围绕 OpenClaw 这类网关的 hook surface 和部署假设来设计的。这种专用性带来了可落地性,但也限制了可移植性。把同样的思路迁移到别的 Agent 框架上,整体原则可以保留,但生命周期映射、工具抽象、策略注入点和运营接口,都要重新适配。也就是说,PRISM 更像一个“方法样板”,而不是一个可以原封不动复制到所有 Agent 生态里的通用安全标准。
启发
如果用一句更直白的话来总结,PRISM 这篇论文真正讲明白的是:OpenClaw 的安全,不能再只靠内容检测来兜底,而必须进入“运行时防护”阶段。
过去我们讨论 Agent 安全,常常容易把问题缩成“怎么识别恶意 prompt”。但对真正能调用工具、能写状态、能向外发送内容的智能体来说,风险治理的关键其实是另一组问题:这个会话现在风险多高?哪些工具还能用?哪些路径不能碰?哪些域名不能访问?哪些秘密不能外发?异常发生后能不能留下证据?策略能不能热更新?这已经不是单纯的模型安全问题,而是运行时系统安全问题。PRISM 的价值,就在于它把这些问题第一次较完整地串成了一套可部署的答案。
当然,它还远不是终点。它没有证明自己已经足够成熟,也没有解决底层沙箱、强隔离和全面能力控制的问题。但它清楚地指出了一个方向:未来 OpenClaw 这类智能体的安全架构,恐怕不再是“再加几个内容安全模型”,而是“在 Agent 网关旁边长出一整套运行时安全层”。谁先把这层真正做出来,谁才更有可能定义下一阶段的 Agent 安全基线。
