 夜雨聆风
夜雨聆风前言:
前面几篇文章讲述了本地向量配置,contextengine上下文工程的配置以及检索机制,这些内容都和memory的机制相关,本篇描述Openclaw的memory机制。
1 Memory说明
Openclaw的memory为workspace中的纯markdown文件,这些文件是唯一的事实来源。
⁘ 1.1 Momory记忆文件分层结构
memory/YYYY-MM-DD.md
每日日志(仅追加)。
在会话开始时读取今天和昨天的内容。
MEMORY.md(可选)
精心整理的长期记忆。
仅在主要的私人会话中加载(绝不在群组上下文中加载)。
├── memory│ ├── 2026-03-10.md│ ├── 2026-03-14.md│ └── 2026-03-15.md├── MEMORY.md仅使用Markdown文件是不够的,需要使用索引,在每个agent下使用SQLite创建索引,每个Agent对应一个独立的SQLite数据库,位于~/.openclaw/memory/{agentId}.sqlite。 存在索引文件才能支持向量相似查询,如果默认没有配置,在第3章节中的并行检索机制就会fallback到BM25的精确检索。
参考前文:
⁘ 1.2 动态JSON文件
动态记忆按照会话自动记录,记录原始的,短期的信息。 动态记忆位于agent下的sessions文件夹下,其中sessions.json为主会话,
root@VM-0-7-ubuntu:~/.openclaw/agents/main/sessions# a260d718-e816-4977-bdc9-92ebb29995fc.jsonl # 主对话记录sessions.json # 会话元数据2 Memory流转机制
不管是动态记忆还是静态记忆都不是一成不变的,随着对话的持续进行,memory的文件会逐渐发生变化。
⁘ 2.1 Memory如何生成?
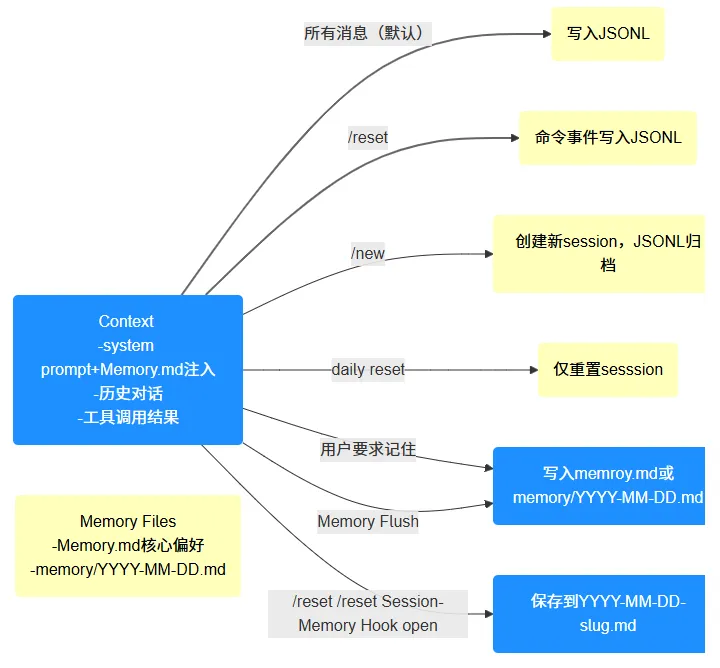
从上图可以看到3种方式会导致上下文写入memory种:
在对话中要求记住的内容会写入memory中。
Memory Flush机制会写入memory中。
session-memory Hook默认不启动,如果启用的话,在输入/new和/reset命令的时候默认将最后15条存入memory.md文件中。
⁘ 2.2 Memory Flush机制
这是一个自动的机制,当Token监控触发,调用LLM判断有无重要信息,重要信息写入memory/YYYY-MM-DD.md文件中,JSONL记录完整回合,在最后compation阶段摘要也会写入JSONL历史,重要信息已经写入了markdown文件,因此不会丢失,用户无感知。
3 Memory检索机制
⁘ 3.1 Hybrid检索

向量检索 上文中建立的Embedding 是向量检索的基础。在 OpenClaw 的架构中,它的核心作用是:
| 语义相似度计算 | |
| 跨语言检索 | |
| 模糊匹配 | |
| 去重 |
BM25检索
为关键词检索, 能够准确命中。
最终得分 = (向量得分 × 0.7) + (BM25得分 × 0.3)
为什么需要混合?
| 向量检索 | ||
| BM25 关键词 |
⁘ 3.2 检索后处理机制
检索的后处理机制主要为MMR多样性重排和Temporal Decay时间衰减。
MMR(Maximal Marginal Relevance)
finalScore = λ × relevance − (1−λ) × max_similarity_to_selected
λ = 1:纯相关性排序(无多样性) λ = 0:纯多样性排序 λ = 0.7(推荐):相关性为主,多样性为辅
MMR排序解决当memory中有大量相似的数据时,纯相关性排序可能返回高度冗余的结果。MMR 通过平衡相关性和多样性来解决这个问题。
Temporal Decay时间衰减 基于艾宾浩斯遗忘曲线,越久远的记忆检索权重越低:
decayedScore = score × e^(-λ × ageInDays)
根据时间衰减公式,对应不同时间有不同的衰减期,其中30天后权重只有50%,这里不是所有文件都适用,其中memory.md和非日期文件不受影响。
4 Memory的增强方案
⁘ 4.1 contextengine上下文工程
在2.2章节中我们介绍的Compaction本身会丢弃上下文信息,虽然我们有memory flush的机制保证将关键信息保存在长久记忆markdown文件中,但是这个机制本身依然存在如下问题:
Memory flush机制只有在token到达窗口才启动,重要信息无法做到随时保存。
本身compaction机制精度不足。
compact的机制黑盒摘要,细节会出现丢失。
当配置多agent的时候,子Agent无法继承父Agent的上下文。
在使用过程中,出现如下问题: 对话长了就忘记前面对话的内容(上下文被压缩),多Agent协作时无法进行协作,记忆文件为被压缩过的内容,而不是我们理解的记忆。因此openclaw从3月8日的版本中引入ContextEngine机制,通过7个生命周期钩子完成完整的生命周期接口,在扩展性方面为热拔插的方式,不启用的话不会影响当前的Legacycontextengine机制。 在前文介绍lossless-claw插件就是官方推荐的ContextEngine插件。
参考前文:
OpenClaw配置contextengine插件lossless-claw
⁘ 4.2 增强检索QMD插件
通过上面的介绍我们已经配置了向量,开启了向量检索和BM25的精确检索,那么我们是否需要QMD呢?
QMD实现功能为向量 + BM25+内置 Reranker 三层检索,从上面可以看到QMD增加内置内置 qwen3-reranker 等模型做二次精排,如果需要长对话周期,且上下文信息量较大的情况下可以考虑QMD插件。
后记:
通过配置向量,contextengine保证上下问不丢失关键信息,增强检索插件的方式,在信息存储,信息向量化,信息检索3个方向保证我们在对话中产生的重要信息不会遗漏,且在后续对话中精准被搜索,从而实现openclaw越来越智能。
