 夜雨聆风
夜雨聆风
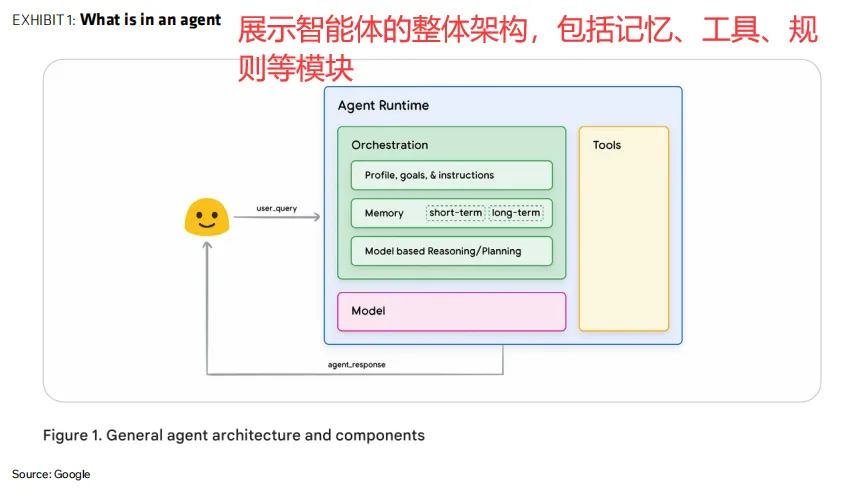
2、三大核心组件:记忆、工具、规则
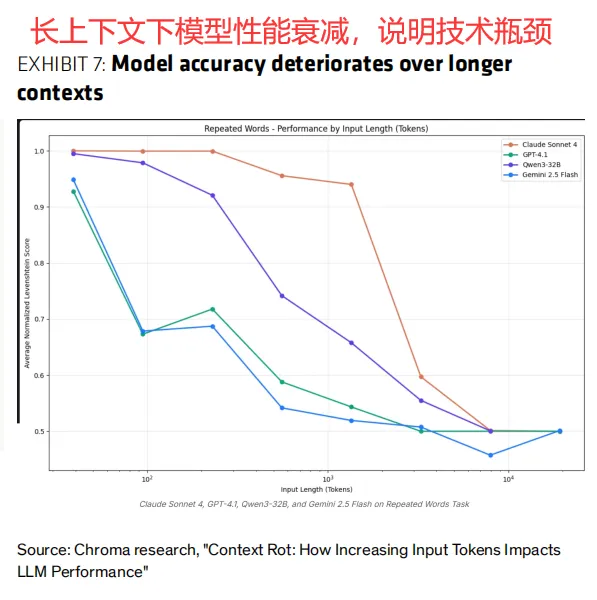
1)记忆:分短期记忆(保留对话上下文)和长期记忆(通过RAG或Agent检索访问专有知识库)。但上下文窗口有限,模型长文本性能会衰减,因此需要用总结LLM压缩信息。
2)工具与MCP:工具让LLM能“动手干活”。为了让LLM理解如何调用工具,开发者编写“工具schema”(JSON格式的说明书)。MCP(模型上下文协议)则是一个标准化协议,让不同智能体都能以统一方式访问第三方应用(如GitHub、CRM),避免重复开发。
3)规则/工作流/技能:通过预定义的流程、规则和技能文件,约束LLM的随机性,提高任务执行的准确性和一致性。工作流把LLM嵌入固定流程(如客服机器人先分类意图再查订单);技能则给LLM一份任务指南(如“如何写一份盈利更新报告”),保留一定灵活性。
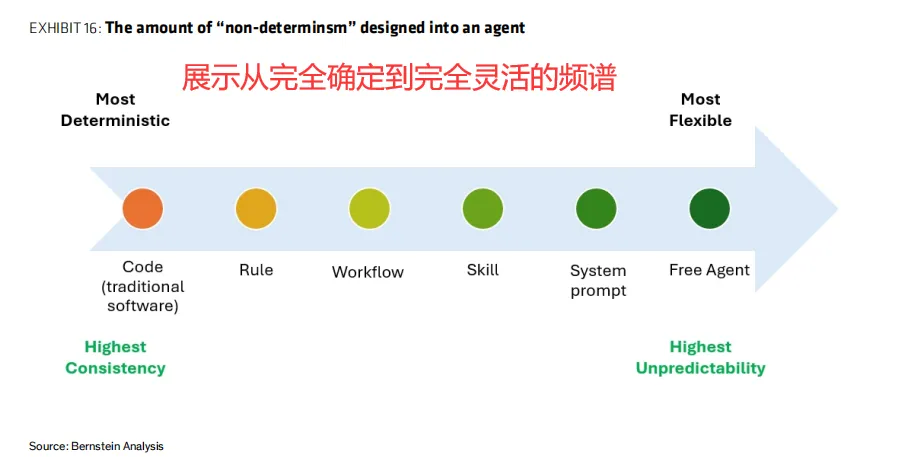
3、从通用到专用,发展节奏可能慢于预期
与大模型预训练时代“堆算力就变强”的通用路线不同,智能体需要针对每个场景精心设计上下文、工具和规则。这意味着智能体开发更像工程定制,而非一键部署。伯恩斯坦认为,短期内不会出现“万能自主智能体”,企业需要投入大量前置工程工作,甚至组建“前场部署工程师”团队,才能让智能体真正落地。
4、计算资源新需求
更多CPU消耗:纯LLM的训练和推理主要依赖GPU,而智能体的许多步骤(数据库检索、API调用、逻辑判断)将在CPU上执行。随着智能体普及,CPU使用量将增加,这对超大规模云厂商(如微软、甲骨文)是额外利好,既能带来增量收入,又能提高AI工作负载的毛利率。
5、数据基础设施迎来升级需求
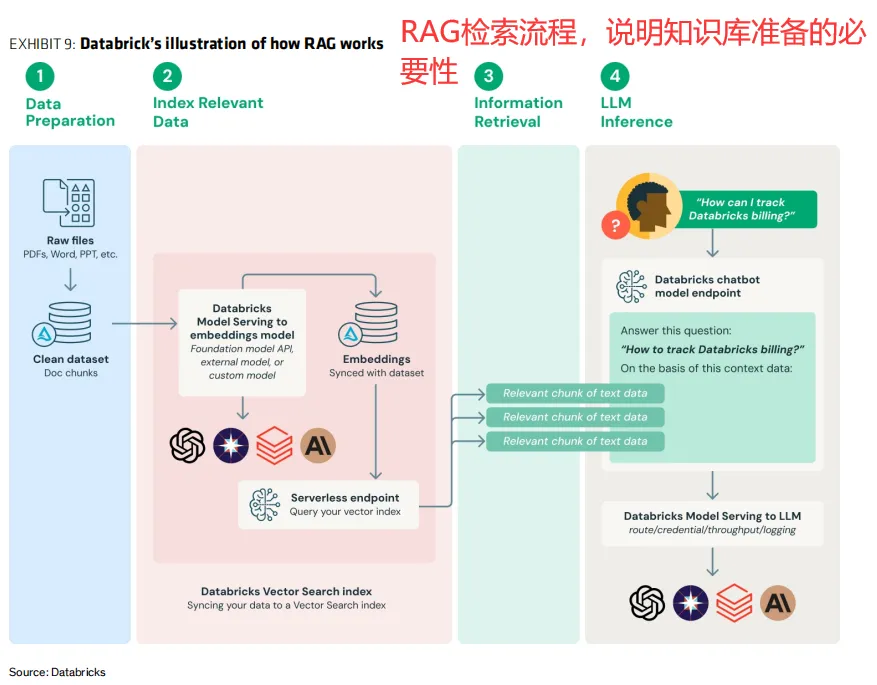
智能体要访问企业数据,必须先有高质量、结构化的知识库。许多企业的数据分散、格式混乱、缺乏索引。因此,软件厂商纷纷推出“数据云”类产品,帮助客户准备数据。数据库厂商(微软、甲骨文、MongoDB、Snowflake)将受益于智能体带来的增量数据访问。
6、投资启示
应用软件公司具备优势,但落地需要时间:拥有客户数据和行业知识的应用软件公司(如Adobe、Salesforce、Workday等)在构建智能体方面具备天然优势。但伯恩斯坦提醒,构建真正好用的企业级智能体远比想象中复杂,需要大量工程和咨询投入,普及时间可能比市场预期更长。
⚠️ 免责声明:本文仅为报告学习分享,不构成任何投资建议。市场有风险,投资需谨慎。
👇 由于文件大小限制,无法在文章内直接分享PDF源文件。我已将这份完整的报告整理好,在公众号回复“研报”即可领取。
