 夜雨聆风
夜雨聆风
这个系列早期讲过OpenClaw的记忆系统——MEMORY.md写长期记忆,memory/YYYY-MM-DD.md写日记,Agent需要回忆的时候用memory_search搜一下。基础用法很简单,写文件就行。
但用了一段时间你会发现几个问题:
搜不准。 Agent明明记过的事情,换个说法就搜不到了。你写的是"喜欢接地气的文风",搜"写作偏好"就可能搜不出来——因为默认的搜索是纯向量匹配,语义相近但用词不同时召回率会下降。
记忆太多搜太慢。 跑了几个月的Agent,memory目录下上百个日记文件,每次memory_search都要遍历所有embedding,响应时间从毫秒级涨到秒级。
compaction吃记忆。 对话跑久了context window满了,OpenClaw会做compaction——把旧消息压缩成摘要。压缩的时候,一些重要细节会跟着丢掉。Agent可能"忘了"你昨天说的关键决定。
跨session失忆。 你在一个session里跟Agent聊了很多,换个session,Agent完全不知道之前聊过什么。memory_search只搜memory文件,不搜历史对话。
这些问题不是OpenClaw的bug——它的基础记忆系统本来就是"够用就行"的设计。但当你的Agent要长期跑、要处理复杂任务、要跨session协作的时候,基础记忆就不够了。
这篇文章拆解OpenClaw记忆系统的完整链路——从最底层的文件存储,到搜索引擎的向量+关键词混合检索,到防遗忘的自动刷盘机制,到QMD本地混合搜索引擎,再到第三方记忆体的开源生态。一层一层往上叠,看你的Agent需要哪一层。
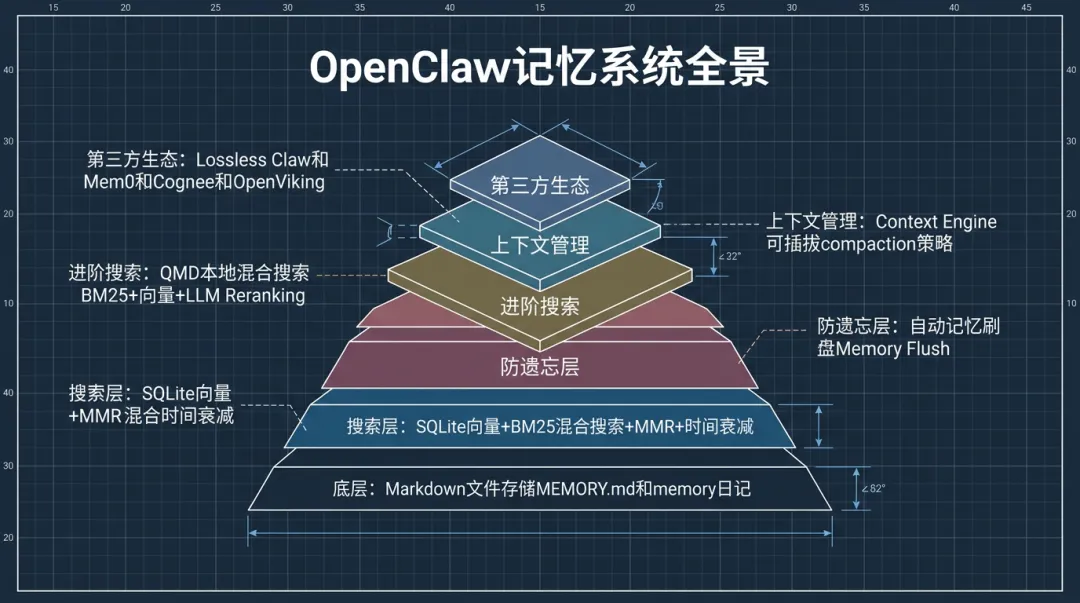
OpenClaw的记忆系统有一个很朴素的设计哲学:文件就是源头。
没有私有数据库,没有二进制格式,没有云端同步。Agent的所有记忆就是workspace下的Markdown文件。你能直接打开看、直接编辑、直接git version control。
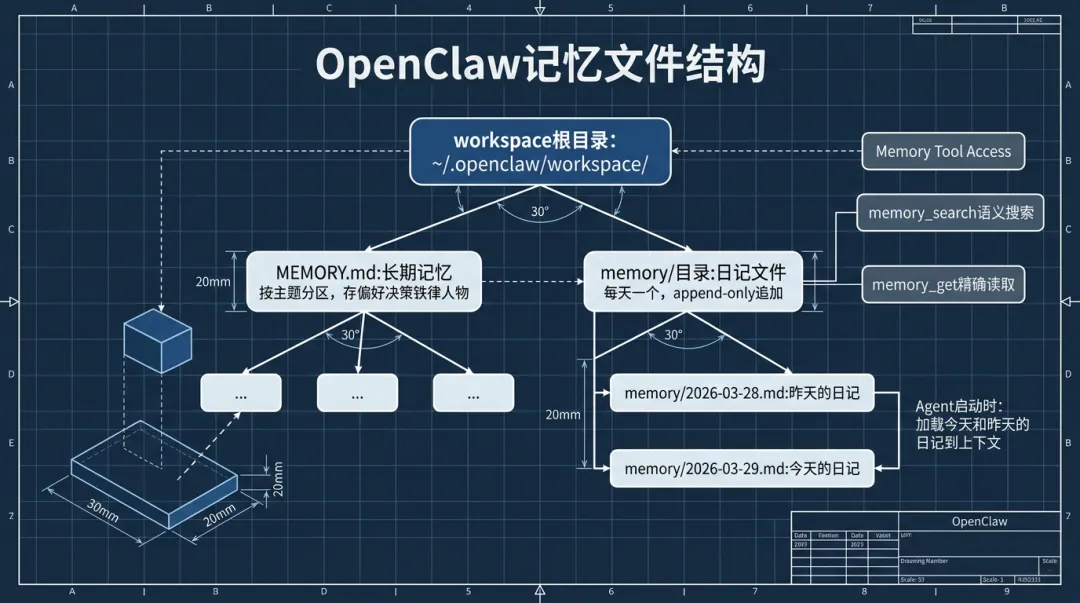
两层文件结构:
~/.openclaw/workspace/├── MEMORY.md # 长期记忆(手动维护)└── memory/ ├── 2026-03-28.md # 日记(自动追加) ├── 2026-03-29.md └── 2026-03-30.md
• MEMORY.md:长期记忆,存偏好、决策、铁律、人物信息。这个文件不按日期组织,而是按主题分区。Agent和你都可以写,但一般由你手动维护或Agent在记忆刷盘时更新。
• memory/YYYY-MM-DD.md:日记,每天一个文件,append-only。Agent做了什么、你们聊了什么重要的事,都往当天日记里追加。
Agent启动session的时候,OpenClaw会加载今天和昨天的日记到上下文里。MEMORY.md只在主session(私聊)里加载,群聊session不注入——防止你的个人记忆在群里泄露。
两个Agent工具:
• memory_search:语义搜索,query一段话,返回最相关的记忆片段
• memory_get:精确读取,指定文件和行号范围,拿到完整内容
这一层的核心理念:Agent不靠"脑子"记东西,靠写文件。 没写到文件的信息,compaction一来就丢了。所以系统里有一条规则——Agent遇到"记住这个"的时候,必须写到memory文件里,不能靠上下文记。
记住了,但找不到等于没记。这一层是记忆系统的核心——搜索引擎。
▎2.1 内置SQLite向量搜索
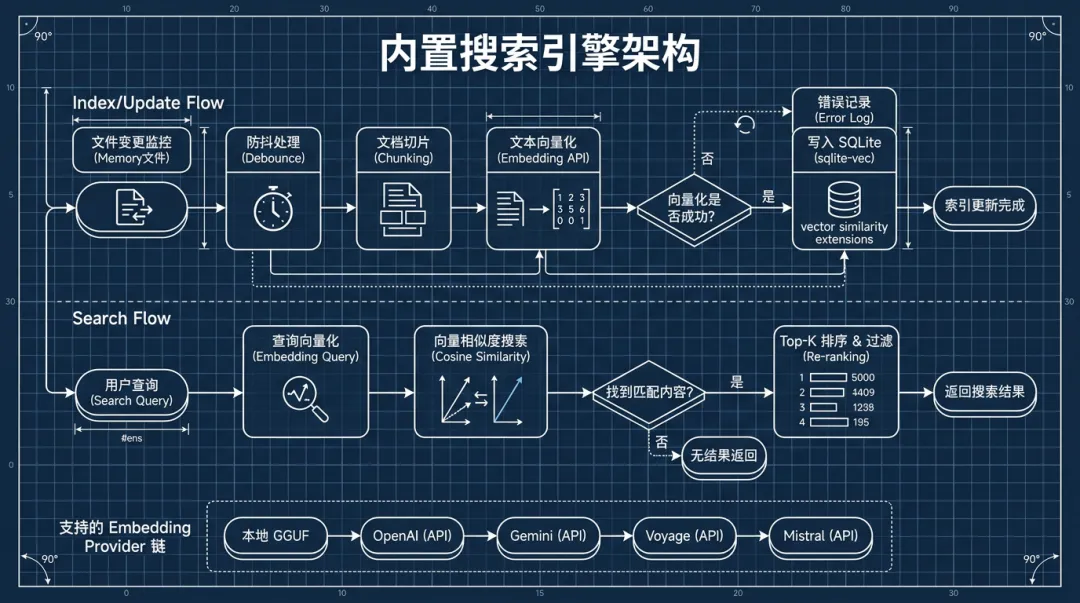
OpenClaw默认用memory-core插件提供搜索能力。流程:
索引阶段:
1. 监听memory文件变更(debounced,不是每次写都触发)
2. 把Markdown文件切成chunk(按段落/标题分块)
3. 调用embedding API把每个chunk转成向量
4. 向量存入SQLite(用sqlite-vec扩展加速)
搜索阶段:
1. 用户query经过同一个embedding模型转成向量
2. 在SQLite里做余弦相似度计算
3. 返回top-K最相关的chunk
embedding provider的选择链(自动降级):
1. 本地GGUF模型(如果配了memorySearch.local.modelPath)
2. OpenAI(如果有API key)
3. Gemini
4. Voyage
5. Mistral
6. 都没有就不启用搜索
默认的本地embedding模型是embeddinggemma-300m-qat-Q8_0.gguf,大约0.6GB,首次使用自动下载。用node-llama-cpp在本地跑推理,不需要云端API,零成本零泄露。
▎2.2 混合搜索(Hybrid Search)
纯向量搜索有一个已知的弱点:精确关键词匹配不行。
比如你搜"CVE-2026-25253",向量搜索会去找语义相近的内容,但一个CVE编号没有"语义"可言——它就是一串精确的字符。这时候传统的BM25关键词搜索反而更准。
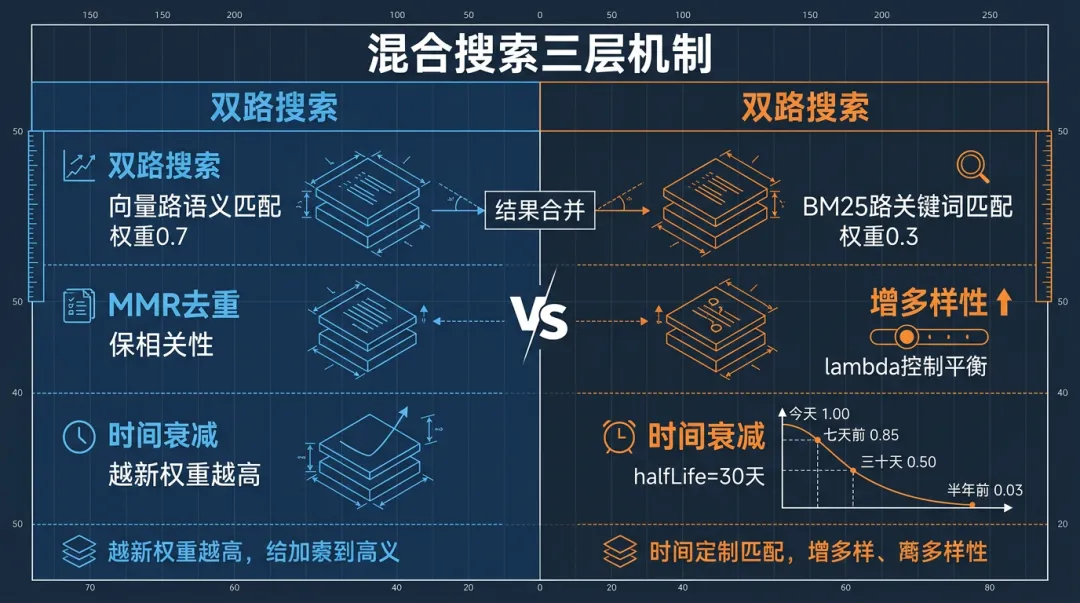
OpenClaw从2026.3版本开始支持混合搜索——向量和BM25双路并行,结果合并排序:
agents: { defaults: { memorySearch: { query: { hybrid: { enabled: true, vectorWeight: 0.7, // 向量权重 textWeight: 0.3, // BM25权重 candidateMultiplier: 4 } } } }}
两路搜索同时跑:
• 向量路:embedding相似度,擅长语义匹配("写作偏好"能匹配到"接地气的文风")
• BM25路:关键词精确匹配,擅长名字、编号、专有名词
结果按权重合并。默认向量0.7、BM25 0.3,可以根据你的场景调。
▎2.3 MMR去重排序
混合搜索还有一个问题:返回的结果可能高度相似。你在memory里写了五天日记都提到了同一件事,搜索结果可能五条都是这件事的不同版本——浪费了宝贵的上下文窗口。
MMR(Maximal Marginal Relevance)解决这个问题:在保证相关性的同时,增加结果的多样性。
hybrid: { mmr: { enabled: true, lambda: 0.7 // 0=最大多样性,1=最大相关性 }}
lambda=0.7的意思是:70%看相关性,30%看跟已选结果的差异度。每选一条结果,后续候选都会跟已选的做去重。
▎2.4 Temporal Decay时间衰减
你的Agent跑了半年,memory目录下180个日记文件。搜"每天几点开始工作",纯语义匹配可能会把半年前的旧记录排到最前面(因为那条写得最详细、语义匹配分最高),而最近的更新反而排后面。
时间衰减让越旧的记忆权重越低:
hybrid: { temporalDecay: { enabled: true, halfLifeDays: 30 // 每30天得分减半 }}
举个例子:
• 今天的记录:score × 1.00(无衰减)
• 7天前:score × 0.85
• 30天前:score × 0.50
• 148天前:score × 0.03
半年前那条语义分0.91的记录,衰减后只剩0.03,自然排到了最后面。
建议:如果你的Agent每天写日记,halfLife设30天。如果你经常要翻老资料,调到90天。
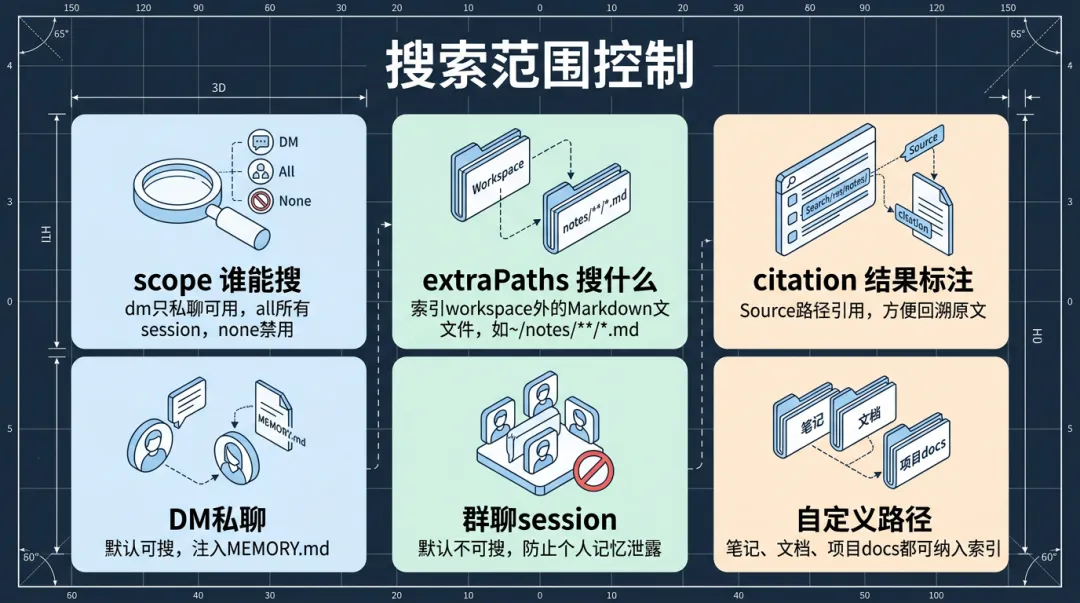
▎2.5 搜索范围控制
默认情况下,memory_search只在DM(私聊session)里可用,群聊session搜不到——防止你的个人记忆在群里泄露。
这个行为可以配:
agents: { defaults: { memorySearch: { scope: "dm", // "dm" | "all" | "none" extraPaths: [ // 索引workspace外的文件 "~/notes/**/*.md", "~/projects/docs/**/*.md" ], citation: { enabled: true, // 搜索结果带Source路径 mode: "auto" // "auto" | "always" | "never" } } }}
三个控制维度:
• scope:谁能搜。dm表示只有私聊session能用memory_search,all表示所有session都能用(包括群聊),none表示禁用搜索。默认dm。
• extraPaths:搜什么。除了MEMORY.md和memory/目录,还可以把workspace外的Markdown文件纳入索引范围。比如你在~/notes里有一堆笔记,加到extraPaths后memory_search也能搜到。
• citation:搜索结果怎么标注。开启后每条结果会带Source: memory/2026-03-28.md#L15-L23这样的路径引用,方便Agent(和你)回溯原文。
▎2.6 Embedding缓存
embedding API不是免费的(即使用本地模型也要算力)。每次memory文件更新就全量重新embedding太浪费。OpenClaw支持embedding缓存:
memorySearch: { cache: { enabled: true, maxEntries: 50000 }}
缓存存在SQLite里,chunk没变就直接用缓存的embedding,不重新调API。对于频繁更新的session transcript索引,缓存效果尤其明显。
Agent跑久了,对话上下文会膨胀。当token数接近context window上限时,OpenClaw会做compaction——把旧消息压缩成摘要,腾出空间。
问题是:压缩必然丢失细节。 你们讨论了半小时的一个技术方案,compaction可能压缩成一句话"讨论了技术方案A"。方案的具体参数、你的顾虑、最终决定的理由——全丢了。
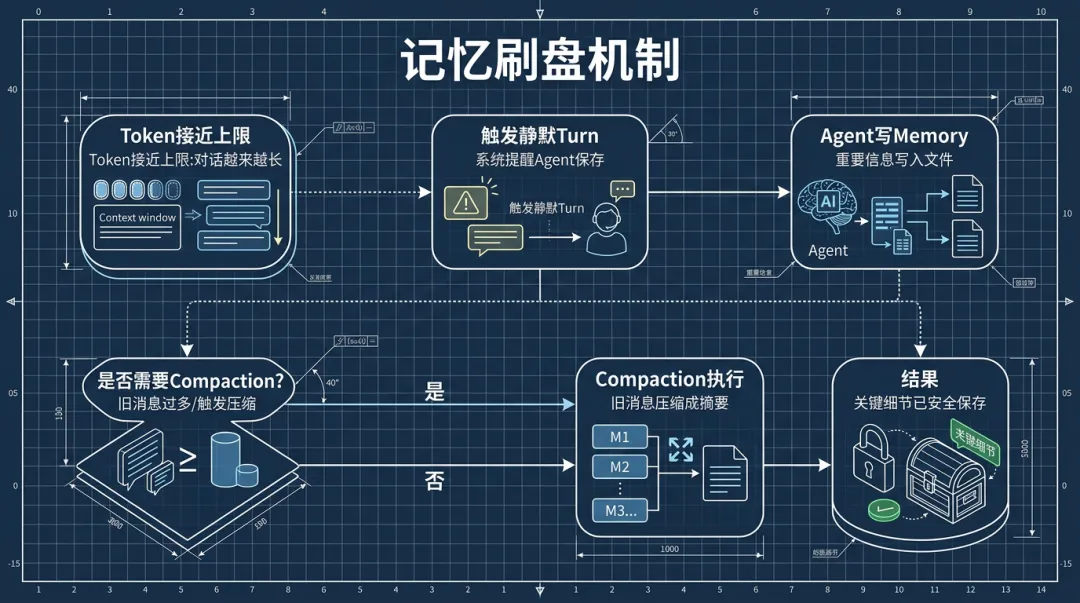
OpenClaw的应对策略是自动记忆刷盘(Memory Flush)。
▎3.1 工作原理
当session的token估算值接近阈值时,OpenClaw在compaction之前自动插入一个静默的agentic turn——给Agent发一条系统消息,提醒它把重要信息写到memory文件里。
agents: { defaults: { compaction: { reserveTokensFloor: 20000, memoryFlush: { enabled: true, softThresholdTokens: 4000, systemPrompt: "Session nearing compaction. Store durable memories now.", prompt: "Write any lasting notes to memory/YYYY-MM-DD.md; reply with NO_REPLY if nothing to store." } } }}
触发时机:当token数超过 contextWindow - reserveTokensFloor - softThresholdTokens。
这个turn是静默的——Agent写完memory文件后回复NO_REPLY,用户完全无感知。一个compaction周期只触发一次,不会反复骚扰。
▎3.2 限制
• sandbox只读模式下跳过:如果Agent的workspace是只读的(workspaceAccess: "ro"),没法写文件,刷盘就被跳过。
• 依赖Agent的判断:系统只是提醒Agent"该存了",具体存什么靠Agent自己判断。如果Agent判断"没啥重要的",就什么都不存。
• 不能回溯:已经被compaction掉的旧消息,刷盘也救不回来。刷盘只能抢在compaction之前。
所以最佳实践是:重要的事情随时写memory,不要等自动刷盘。 自动刷盘是兜底机制,不是主力。
▎3.2 Compaction与记忆的关系
OpenClaw默认用legacy引擎做compaction——滑动窗口,旧消息压缩成摘要。这是最简单粗暴的方式:超过窗口的消息,调LLM生成一段摘要替换掉原文。好处是实现简单,代价是细节必然丢失。
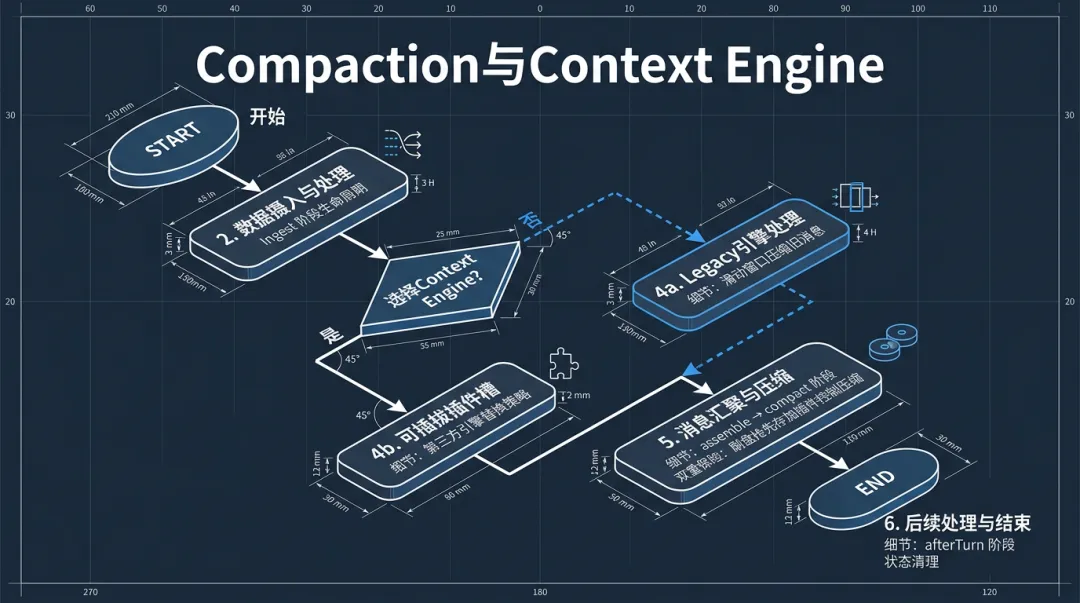
但compaction这件事本身是可插拔的。OpenClaw从3.7版本开始引入了Context Engine插件槽(plugins.slots.contextEngine),第三方插件可以完全替换compaction策略。
Context Engine的生命周期有四个阶段:
1.ingest:新消息进来时怎么处理
2.assemble:发给模型之前怎么组装上下文
3.compact:上下文太长时怎么压缩
4.afterTurn:一轮对话结束后做什么
如果插件声明了ownsCompaction: true,OpenClaw就把compaction的控制权完全交给插件——内置的滑动窗口就不跑了。后面第五层讲的Lossless Claw,就是用DAG摘要替换了滑动窗口。
所以记忆防遗忘的完整策略是:自动刷盘抢在前面存重要信息 + 可插拔Context Engine控制压缩策略。两层保险。
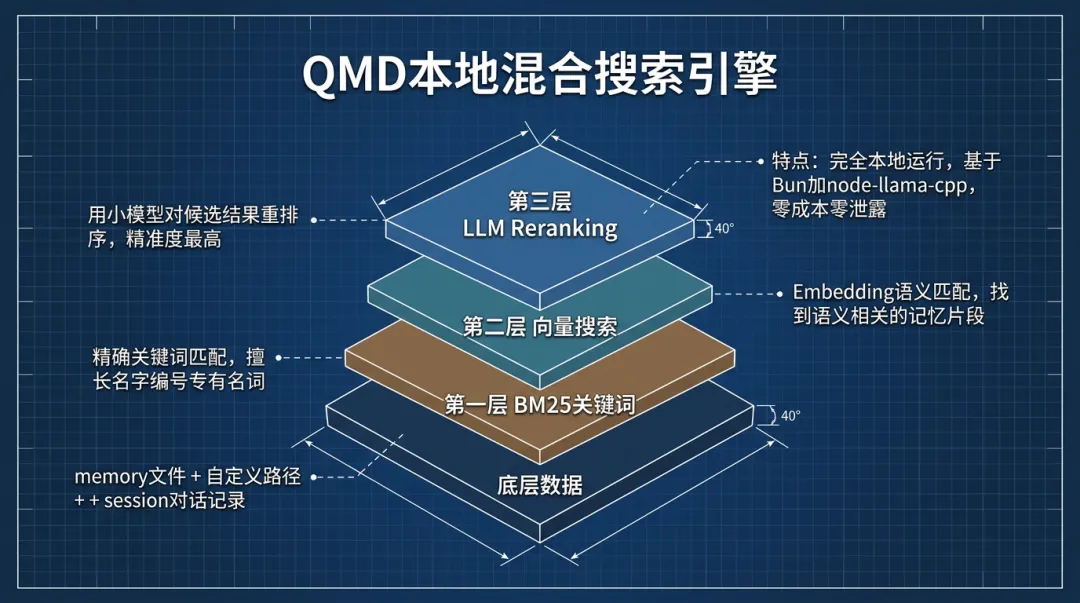
内置的SQLite搜索够用,但当记忆量大、搜索精度要求高的时候,QMD是更好的选择。
▎4.1 QMD是什么
QMD(Query Markdown Documents)是一个本地混合搜索sidecar,由Tobi开发。它把三种检索技术叠在一起:
1.BM25:关键词精确匹配
2.向量搜索:语义相似度匹配
3.LLM Reranking:用小模型对搜索结果做重排序
三层过滤的效果:BM25负责"找到",向量搜索负责"相关",LLM Reranking负责"精准"。
QMD完全本地运行——基于Bun + node-llama-cpp,自动下载GGUF模型(reranker和query expansion),不需要云端API,不需要Ollama。零成本,零数据泄露。
▎4.2 跟内置搜索的区别
▎4.3 配置
memory: { backend: "qmd", qmd: { includeDefaultMemory: true, searchMode: "query", // search/vsearch/query三种模式 update: { interval: "5m", // 每5分钟刷新索引 debounceMs: 15000 }, limits: { maxResults: 6, timeoutMs: 4000 }, // 额外索引路径 paths: [ { name: "docs", path: "~/notes", pattern: "**/*.md" } ], // session对话索引 sessions: { enabled: true, retentionDays: 30 } }}
安装QMD CLI:
bun install -g https://github.com/tobi/qmd
▎4.4 Session JSONL索引
QMD还有一个杀手级功能:把历史对话也纳入搜索范围。
默认情况下,memory_search只搜memory文件——MEMORY.md和memory/目录下的日记。Agent在别的session里说过什么、讨论过什么,搜不到。这就是跨session失忆的根源。
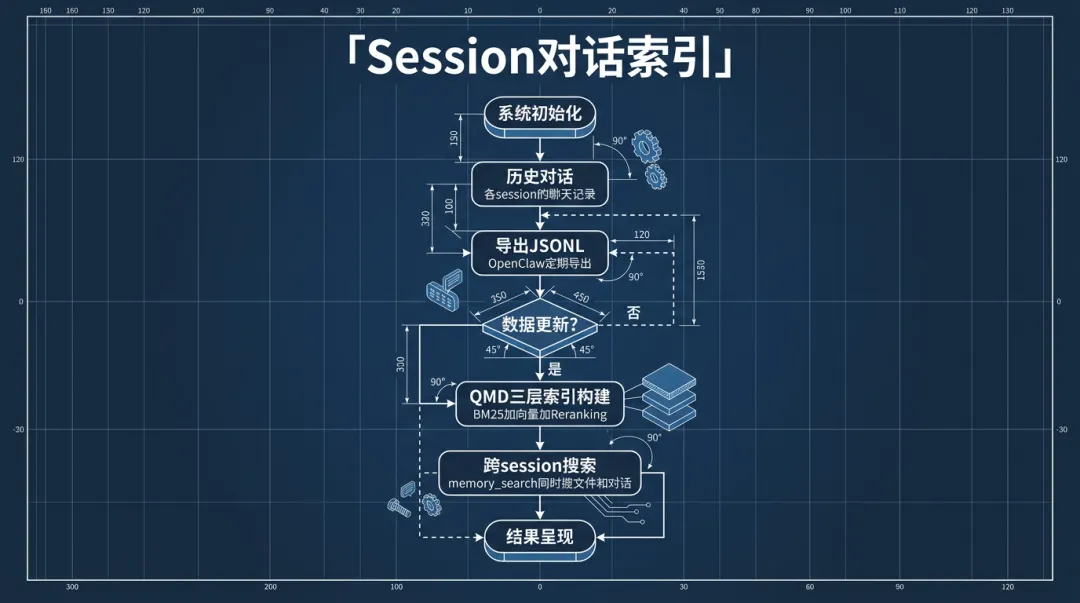
开启QMD的session索引后,OpenClaw会把session transcript导出成JSONL格式,纳入QMD的搜索集合:
memory: { backend: "qmd", qmd: { sessions: { enabled: true, retentionDays: 30 // 保留最近30天的对话 } }}
工作流程:
1. OpenClaw定期把活跃session的对话导出到QMD的collection目录
2. QMD对这些JSONL文件做BM25+向量+LLM Reranking的三层索引
3. Agent调用memory_search时,同时搜memory文件和历史对话
4. 过期的对话(超过retentionDays)自动清理
这意味着Agent能"回忆"之前的对话——你上周在某个session里讨论的技术方案,这周在另一个session里搜"上次讨论的方案",能搜到。
注意retentionDays不要设太长。30天的对话量已经不小了,索引太大会影响搜索速度。重要的东西还是应该写到memory文件里——对话索引是补充,不是替代。
▎4.5 QMD降级保护
如果QMD进程挂了或者CLI不在PATH里,OpenClaw不会崩——自动降级回内置的SQLite搜索。日志里会记录降级原因,但memory_search继续可用。这是OpenClaw的一贯风格:增强组件挂了不影响基本功能。
OpenClaw的记忆系统是可插拔的。社区已经有一批成熟的第三方记忆方案,解决不同层面的问题。
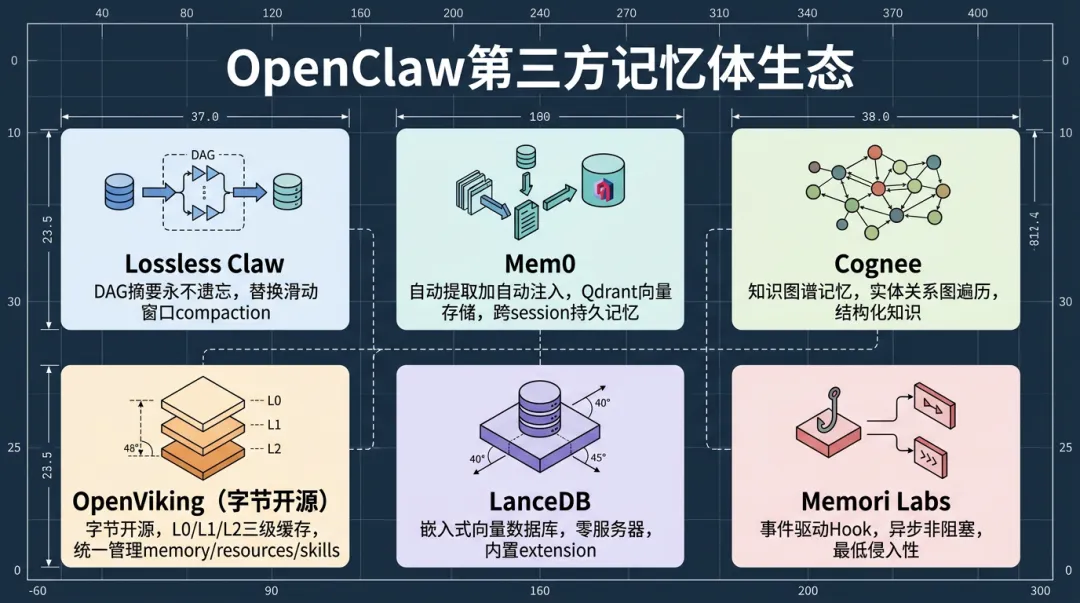
▎5.1 Lossless Claw——永不遗忘
项目:github.com/Martian-Engineering/lossless-claw
npm包:@martian-engineering/lossless-claw
解决什么:compaction丢失历史细节
Lossless Claw基于Voltropy的LCM(Lossless Context Management)论文,用DAG(有向无环图)替换OpenClaw默认的滑动窗口compaction。
核心原理:
1.全量持久化:每一条消息都存到本地SQLite数据库,按conversation组织。不删除,不截断,原文永久保留。
2.层级摘要:当消息积累到一定数量(默认8条),调用LLM生成一个leaf summary。当leaf summary积累到一定数量(默认4个),再调用LLM把多个leaf summary浓缩成一个condensed summary。层层向上,形成一棵DAG。
3.上下文组装:每次发给模型时,用高层summary + 最近的raw messages拼接上下文。高层summary提供历史全貌,raw messages保持近期细节。
4.按需展开:Agent觉得某个summary太粗糙,可以用lcm_expand工具展开——Lossless Claw会从数据库里取出原始消息,调LLM针对性地回答问题。还有lcm_grep做全文搜索、lcm_describe看摘要结构。
关键配置参数:
• freshTailCount: 32——保护最近32条消息不被压缩
• contextThreshold: 0.75——context window使用率超过75%触发压缩
• summaryModel——可以指定用便宜的小模型做摘要(比如claude-haiku-4-5),不用主模型
• 支持ignoreSessionPatterns排除特定session(比如cron session不存)
openclaw plugins install @martian-engineering/lossless-claw
{ plugins: { slots: { contextEngine: "lossless-claw" }, entries: { "lossless-claw": { enabled: true, config: { freshTailCount: 32, contextThreshold: 0.75, summaryModel: "anthropic/claude-haiku-4-5" } } } }}
适合场景:长期跑的Agent、需要随时回溯历史细节的场景。代价是多了一个SQLite数据库,摘要生成会消耗额外的LLM调用(可以用小模型控制成本)。
▎5.2 Mem0——自动提取+自动注入
官方集成:docs.mem0.ai/integrations/openclaw
npm包:@mem0/openclaw-mem0
解决什么:跨session的持久记忆、自动化记忆管理
Mem0的思路跟前面几个不同——它不替换OpenClaw的上下文管理,而是在Agent生命周期的两个关键节点做事:
1.Turn后自动提取(Auto-Capture):每轮对话结束后,Mem0分析对话内容,自动提取"值得记住的事实"(用户偏好、决定、关键信息),存到Mem0的后端。
2.Turn前自动注入(Auto-Recall):每轮对话开始前,Mem0根据当前prompt语义搜索相关记忆,注入到上下文里。
底层存储用Qdrant(向量数据库),支持Mem0 Cloud(托管)或自托管。
还有一个社区实现openclaw-mem0(github.com/aaronshaf/openclaw-mem0),架构更轻量:一个Bun HTTP server + Qdrant + Ollama,本地跑,不依赖云端。它用Ollama做fact extraction(从对话里提取事实),用nomic-embed-text做embedding,全部本地。
记忆按三个维度打标签:
• user_id:用户级,跨Agent共享
• agent_id:Agent级,绑定特定Agent
• run_id:session级,绑定单次对话
搜索时可以按维度过滤——比如只搜当前Agent的记忆,或者搜所有Agent共享的用户偏好。
适合场景:多Agent共享用户记忆、需要自动化记忆管理(不想手动写memory文件)。
▎5.3 Cognee——知识图谱记忆
官方集成:docs.cognee.ai/integrations/openclaw-integration
npm包:@cognee/cognee-openclaw
解决什么:记忆之间的关系和结构
Cognee的核心不是向量搜索,而是知识图谱。它从对话和memory文件里提取实体和关系,构建一个图结构——"项目A"是一个实体,"用了React框架"是一个关系,"部署在AWS上"是一个属性。
搜索的时候,Cognee不是找"语义最相似的文本片段",而是做图遍历——从query提到的实体出发,沿着关系链找到相关的知识。这种方式擅长回答"项目A用了哪些技术栈"这种需要推理的问题。
工作流程:
1.启动时同步:扫描memory目录,把文件同步到Cognee(增量:新增的加、改了的更新、删了的清理、没变的跳过)
2.Turn前召回:搜索Cognee的知识图谱,把相关记忆以
3.Turn后同步:Agent如果修改了memory文件,重新同步变更
搜索模式有三种:
• GRAPH_COMPLETION:图遍历+LLM生成回答(默认)
• SUMMARIES:聚合摘要
• CHUNKS:原始文本块
Cognee需要跑一个独立的服务(Docker),比纯插件方案重一些。
适合场景:记忆量大且实体关系复杂的场景——比如你的Agent管理多个项目、跟多个人协作,需要理解"谁在哪个项目里负责什么"。
▎5.4 OpenViking——字节的上下文数据库
项目:github.com/volcengine/OpenViking
解决什么:Agent上下文的统一管理
OpenViking是字节跳动(volcengine)开源的,定位是"AI Agent的上下文数据库"。它的思路跟前面几个都不同——不是只做记忆,而是用文件系统范式统一管理Agent需要的三类上下文:
1.Memory:记忆(对话历史、用户偏好)
2.Resources:资源(文档、数据文件)
3.Skills:技能(Agent的能力描述)
核心设计:
• L0/L1/L2三级加载:像CPU缓存一样,L0是当前会话上下文(热),L1是索引摘要(温),L2是原始数据(冷)。按需加载,大幅降低token消耗。
• 目录递归检索:不是全库搜,而是先定位到目录,再在目录内语义搜索。跟文件系统的cd+grep类似。
• 自动会话管理:自动压缩对话内容、提取长期记忆,Agent越用越聪明。
• 可视化检索轨迹:能看到搜索路径,方便调试"为什么搜到了这个结果"。
OpenViking有OpenClaw Memory Plugin,可以替换内置记忆系统。需要Python 3.10+和Go 1.22+环境,配置VLM模型(用于内容理解)和Embedding模型(用于向量化)。
适合场景:企业级Agent、需要管理大量结构化上下文的场景。
▎5.5 LanceDB——嵌入式向量数据库
内置extension:memory-lancedb(OpenClaw自带)
解决什么:比SQLite更专业的向量存储
LanceDB是一个嵌入式向量数据库——跟SQLite一样嵌入到进程里运行,不需要单独启动服务。数据存在本地的.lance文件里。
OpenClaw自带memory-lancedb extension,配置后替换memory-core作为memory插件:
plugins: { slots: { memory: "memory-lancedb" }, entries: { "memory-lancedb": { enabled: true, config: { embedding: { apiKey=********;"${OPENAI_API_KEY}", model: "text-embedding-3-small" }, autoCapture: true, // turn后自动捕获 autoRecall: true, // turn前自动注入 dbPath: "~/.openclaw/memory/lancedb" } } }}
LanceDB相比SQLite的优势:数据和向量在一个地方(lance格式),不需要sqlite-vec扩展,查询优化更好。
适合场景:想要比内置搜索更专业的向量存储,但不想引入额外服务的场景。
▎5.6 Memori Labs——事件驱动的记忆层
项目:github.com/memorilabs/openclaw-memori
npm包:@memori/openclaw-memori
解决什么:不侵入Agent性能的记忆管理
Memori Labs的设计哲学跟其他几个不太一样——它不抢Agent的主路径,而是Hook到OpenClaw的事件生命周期里做事。
两个核心Hook:
1.Turn后extract:每轮对话结束后,后台异步分析对话内容,提取值得记住的事实和决策。提取过程不阻塞Agent的下一轮响应。
2.Turn前retrieve:每轮对话开始前,根据当前query语义搜索已有记忆,注入到上下文。检索过程在Agent等待模型返回的空隙里完成。
关键特点:
• 异步非阻塞:extract在后台跑,不影响Agent响应速度
• Hook驱动:不替换任何内置组件,纯增量增强
• 轻量级:不需要独立服务、不需要Docker,装完插件就能用
plugins: { entries: { "openclaw-memori": { enabled: true, config: { extractModel: "gpt-4.1-mini", // 提取用小模型 retrieveTopK: 5, minRelevance: 0.7 } } }}
跟Mem0的区别:Mem0有自己的后端存储(Qdrant),记忆管理更独立、功能更全。Memori Labs更轻量,更像是给OpenClaw原有记忆系统加了一层自动化——提取的记忆还是写到memory文件里,搜索还是用OpenClaw的memory_search。
适合场景:想要自动化记忆管理但不想引入额外存储后端的场景。最低侵入性。
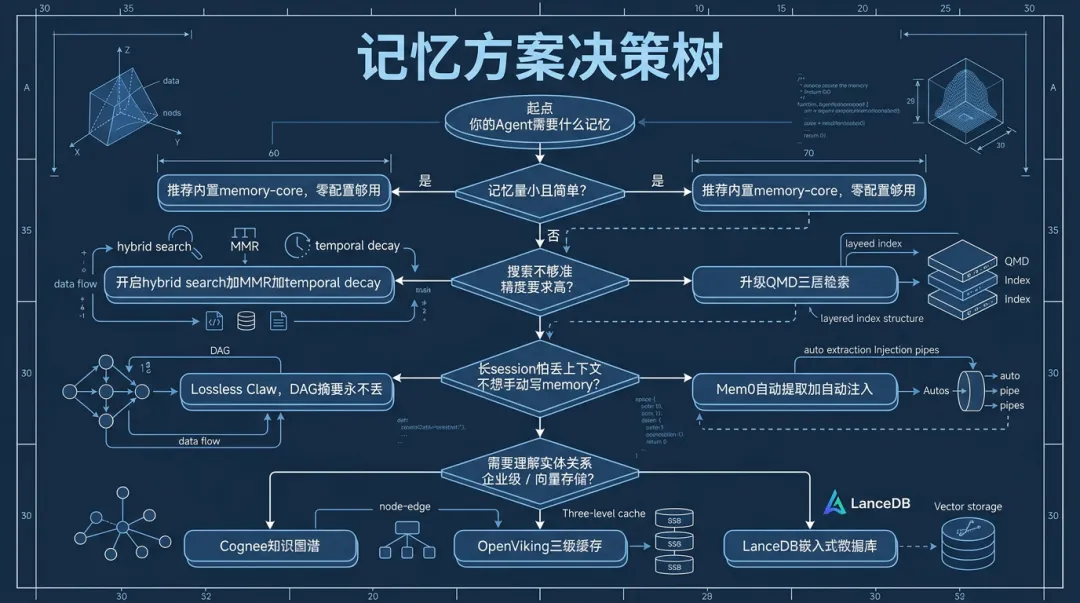
这些方案不互斥。你可以同时用Lossless Claw管上下文 + QMD做搜索,或者Mem0做自动记忆 + Cognee做知识图谱。OpenClaw的插件槽设计让它们可以组合使用——contextEngine管compaction,memory管搜索,两个插件槽独立。
记忆是Agent从"工具"变成"搭档"的分水岭。
没有记忆的Agent,每次对话都从零开始。有了记忆的Agent,能积累经验、理解上下文、持续进化。OpenClaw在记忆这件事上的设计思路很务实——Markdown做存储、向量做搜索、插件做扩展。底子简单,但通过插件生态可以叠出很复杂的能力。
你的Agent需要哪一层记忆,取决于你让它干多复杂的活。
以上,如果觉得有用,欢迎转发给需要的朋友。
下篇见。
版权声明:本文由AI技术博客原创,转载请注明出处。
#AI#OpenClaw#安全#Sandbox#智能体#Codex#ClaudeCode#OpenClaw#编程Agent#AI编程#LLM应用开发#AI基础设施#Hooks#Webhooks#事件驱动#AI#OpenClaw#智能体#记忆系统#向量搜索#QMD#LosslessClaw
