 夜雨聆风
夜雨聆风
你的AI助手也能画画了!OpenClaw文生图配置全攻略
你有没有过这种尴尬的经历?
想让AI帮你画个公众号封面,它却只能用文字描述"这是一张蓝色的背景图";想让它根据你的描述生成成品图,它却说"抱歉,我只能看懂不会画"。
前四期,我们让OpenClaw装上了大脑、连上了嘴巴、学会了搜索、睁开了眼睛。今天,我们要给它一双会画画的手。
好消息是配置其实很简单,10分钟就能搞定。坏消息是如果没按对步骤,它可能会跟你闹脾气(报错)。别担心,跟着这篇教程走,手把手教你配置。
OpenClaw是怎么画画的?
简单来说,OpenClaw本身不会画画,它是调用专业的文生图模型来帮你生成图片。目前支持两种主流方案:
方案一:内置实现(推荐)
使用 Gemini 或 gpt-image-1 模型 原生支持,配置最简单 适合新手入门
方案二:Skill扩展
nano-banana-pro / openai-image-gen 功能更丰富,支持批量生成 适合进阶玩家
本文重点讲内置实现,因为这是新版OpenClaw的推荐方式,配置最省心。
第一步:确认OpenClaw版本
先检查你的OpenClaw是不是新版(2026.03.22之后):
openclaw version
如果版本较旧,建议先升级:
openclaw update
小提示:新版重构了插件体系,很多功能都改成了插件化。如果你之前用过旧版的文生图,可能需要重新配置,但新配置其实更简单。
第二步:配置文生图模型
这是核心步骤。OpenClaw的文生图功能需要同时满足两个条件:
启用对应的图片生成插件(google 或 openai) 在对应Provider上配置文生图模型
2.1 选择文生图引擎
目前支持两种内置引擎:
方案A:Google Gemini(推荐,免费额度多)
模型名: gemini-3.1-flash-image-preview特点:速度快,支持图文混合生成 需要:Gemini API Key
方案B:OpenAI gpt-image-1
模型名: gpt-image-1特点:画质更好,细节更丰富 需要:OpenAI API Key
两个方案配置流程几乎一样,下面以Gemini方案为例演示。
2.2 在Provider中配置模型
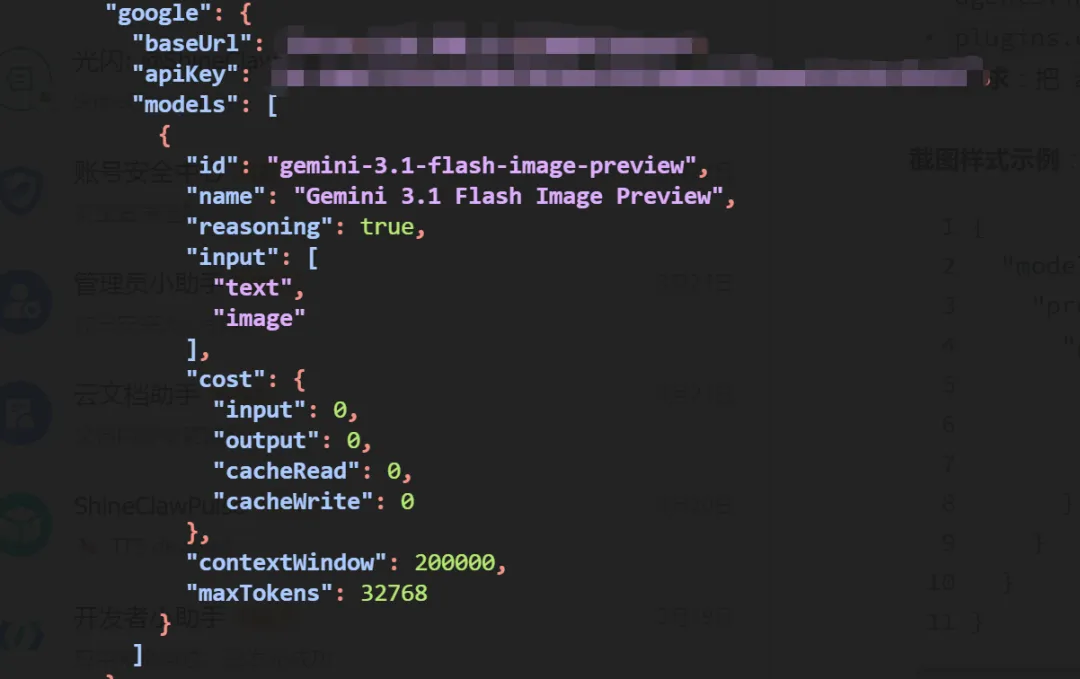
打开你的 openclaw.json,找到 models.providers 部分,添加 google provider:
{
"models": {
"mode": "merge",
"providers": {
"google": {
"baseUrl": "https://generativelanguage.googleapis.com",
"apiKey": "你的Gemini API Key",
"api": "google-generative",
"models": [
{
"id": "gemini-3.1-flash-image-preview",
"name": "Gemini 3.1 Flash Image",
"reasoning": true,
"input": ["text", "image"],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 128000,
"maxTokens": 8192
}
]
}
}
}
}
关键参数说明:
baseUrl: Gemini官方地址,有中转站可以替换apiKey: 去 https://ai.google.dev/[1] 申请,免费版每月有额度input: 必须包含"image",表示支持图片相关功能id: 必须是gemini-3.1-flash-image-preview(名称固定)
⚠️ 注意:api 字段要填 "google-generative",不是 "openai-completions",这是最容易踩的坑。
2.3 配置文生图专用模型
告诉OpenClaw用哪个模型来画图:
{
"agents": {
"imageGenerationModel": {
"primary": "google/gemini-3.1-flash-image-preview"
}
}
}
路径格式是 provider名/模型id,要和上一步对应。
2.4 启用Google插件
这一步很多人漏掉,导致功能不生效!
在配置文件中添加:
{
"plugins": {
"entries": {
"google": {
"enabled": true
}
}
}
}
OpenClaw在2026.03.22版本重构后,文生图功能由插件提供。默认虽然安装了google插件,但必须显式启用才会加载文生图能力。
第三步:验证配置
保存配置文件后,重启OpenClaw让配置生效:
openclaw restart
验证插件是否加载成功:
openclaw plugins list
你应该能看到 google 插件的状态是 loaded。

第四步:测试画图功能
现在OpenClaw应该已经学会画画了。测试一下:
在飞书/微信里,给OpenClaw发送:
帮我画一只戴着墨镜的猫,赛博朋克风格,霓虹灯背景
或者使用工具调用方式:
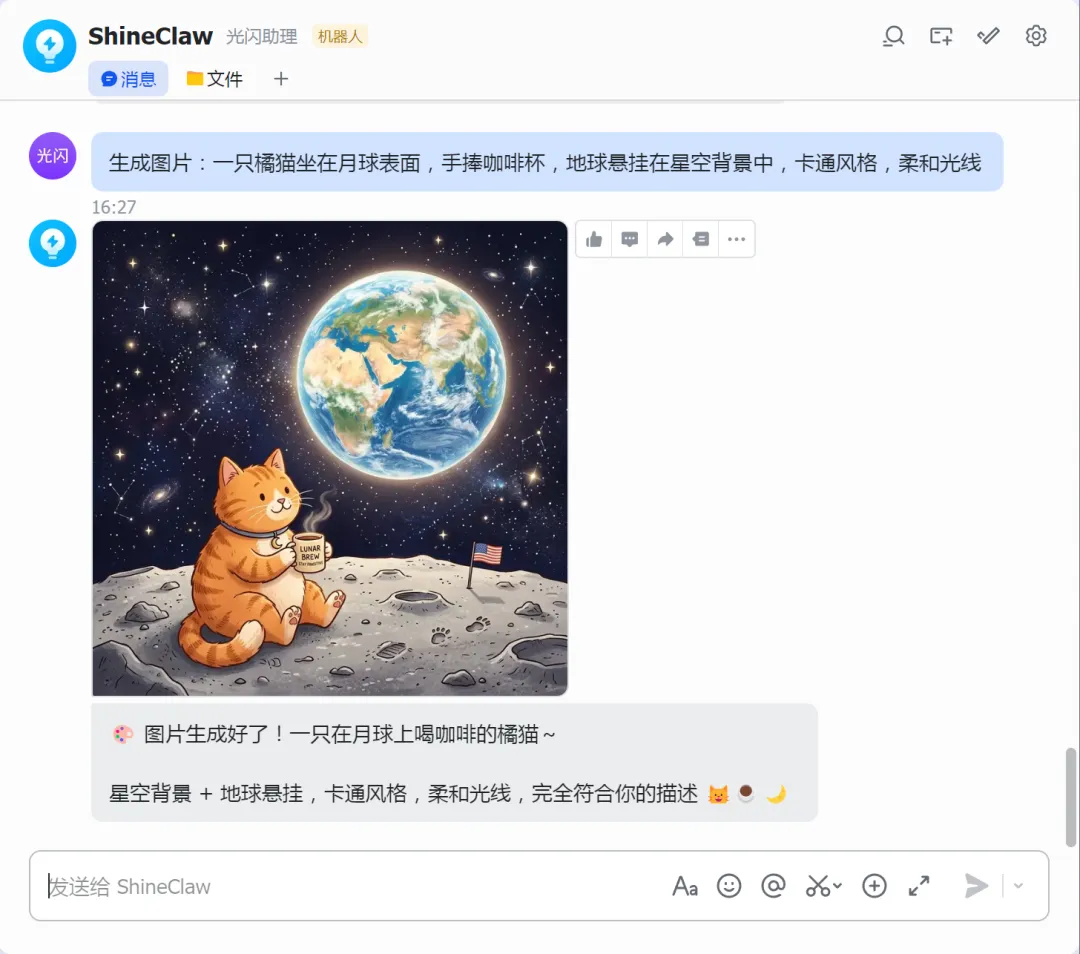
生成图片:一只橘猫坐在月球表面,手捧咖啡杯,地球悬挂在星空背景中,卡通风格,柔和光线
正常情况,OpenClaw会回复一张图片,同时附带说明:
进阶:Skill方式(可选)
如果你需要更强大的功能,比如批量生成、参考图重绘、特定风格控制,可以使用Skill扩展。
nano-banana-pro(Gemini增强版):
openclaw skills install nano-banana-pro
配置:
{
"skills": {
"entries": {
"nano-banana-pro": {
"env": {
"GEMINI_API_KEY": "你的API Key",
"GEMINI_BASE_URL": "https://generativelanguage.googleapis.com"
}
}
}
}
}
openai-image-gen(OpenAI方案):
openclaw skills install openai-image-gen
如果只是偶尔画个图,内置实现完全够用。如果是内容创作者需要批量生成,建议用Skill方案。
完整配置汇总
方便复制粘贴的完整配置(替换 YOUR_API_KEY):
{
"models": {
"mode": "merge",
"providers": {
"google": {
"baseUrl": "https://generativelanguage.googleapis.com",
"apiKey": "YOUR_API_KEY",
"api": "google-generative",
"models": [
{
"id": "gemini-3.1-flash-image-preview",
"name": "Gemini 3.1 Flash Image",
"reasoning": true,
"input": ["text", "image"],
"cost": { "input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0 },
"contextWindow": 128000,
"maxTokens": 8192
}
]
}
}
},
"agents": {
"imageGenerationModel": {
"primary": "google/gemini-3.1-flash-image-preview"
}
},
"plugins": {
"entries": {
"google": {
"enabled": true
}
}
}
}
常见问题排查
Q:OpenClaw说"我没有画图能力"
检查:
plugins.entries.google.enabled是否为truemodels.providers.google.models中是否有gemini-3.1-flash-image-previewagents.imageGenerationModel.primary是否指向正确路径重启OpenClaw
Q:报"Google API key missing"
确保 models.providers.google.apiKey 已填写,且不是空字符串。
Q:生成的图片质量差
优化提示词:
用英文描述效果更好 加风格关键词:digital art, photorealistic, anime style 指定画质:high quality, 4k, detailed
Q:画图很慢
文生图本身需要时间,Gemini通常3-10秒,复杂图片可能更久。耐心等待或降低复杂度。
下一步:让AI开口说话
到这里,你已经完成了:
✅ 配置了文生图模型
✅ 启用了图片生成插件
✅ 测试并验证功能正常
下一期,我们要让OpenClaw开口说话——配置TTS语音回复。想象一下,在飞书里收到AI发来的语音消息,是不是有点酷?
本文档由 AI 辅助生成,如有错误欢迎指正。 OpenClaw系列教程持续更新中,欢迎关注。
引用链接
[1]https://ai.google.dev/
