上一篇我们聊了如何部署小龙虾和小龙虾能做的事情,这一篇来聊聊日常使用中的实用小技巧。这些命令和设置看似简单,但用好了能让你的 AI 助手体验直接拉满。我将自己最近的使用体验分享给大家,希望能对大家有所帮助。
一、常用命令: 7 个指令
小龙虾的核心交互全靠命令,以下是最常用的 7 个命令: | | |
|---|
| /new | | |
| /reset | | |
| /compact | | |
| /stop | | |
| /status | | |
| /kill | | |
| /model list | | |
对话超过 50 轮后用 /compact 压缩一下,上下文更干净模型回答跑偏时,先 /stop,再 /reset,比连续追问更有效二、开启流式显示:让思考过程可见
默认情况下,小龙虾是"沉默"的——你看不到它的思考过程。开启流式显示后,你能实时看到它在想什么,体验感完全不同。1. Reasoning(推理模式)
开启后,模型会展示推理链,你能看到它"为什么这样回答"。特别适合复杂问题和代码调试。2. Verbose(详细模式)
开启后,工具调用的完整过程会展示出来——工具名、传入参数、返回结果,一目了然。适合排查问题。3. Think(思考模式)
部分模型支持展示内部思考过程(如 DeepSeek-R1),能看到 块里的推理链。设置方式:在 OpenClaw 配置中开启 thinking 选项,或通过命令 /reasoning 、/verbos进行切换。三、安装小插件:两个必备扩展
1. lossless-claw(无损上下文压缩)
这是小龙虾的"记忆压缩器"。对话太长时,它会自动压缩历史记录,同时保留关键信息。LCM(Lossless Context Management)是 OpenClaw 的核心特性之一2. openviking(开放viking记忆系统)
openclaw内置默认有记忆系统,但其只适合日常使用、快速部署、轻量场景,如果你需要重度使用 AI Agent 场景、需要复杂记忆管理,那最好使用openviking;它是一个更高级的记忆系统,能跨会话记住你的偏好和决策,是开源的上下文数据库,支持分层上下文投递、长期记忆管理。注:以上两个插件都可以从github仓库中获取,将github的网址发给小龙虾,让它自行配置即可;openviking需要使用最新版本的小龙虾才能配置成功,低版本的小龙虾可能会报错“context engine not registered”。四、主虾/副虾的 Workspace 备份
小龙虾因为功能不是很稳定,迭代速度特别快,会频繁更新;且如果同时运行了多个智能体(主虾+副虾),数据备份就非常重要了。我就是因为升级了下最新的版本时,升级出错,导致只能卸载重装,以前的数据全部丢失;还好自己做了定时任务,每天凌晨会对小龙虾(主虾+副虾)的workspace中所有文件进行全量备份(不仅仅是几个核心文件,而是全部文件,包含memory/ 日志等);重装小龙虾后,将workspace文件夹覆盖后,数据都还在,只需进行简单的配置下即可恢复之前的配置。五、与 n8n 工作流的搭配
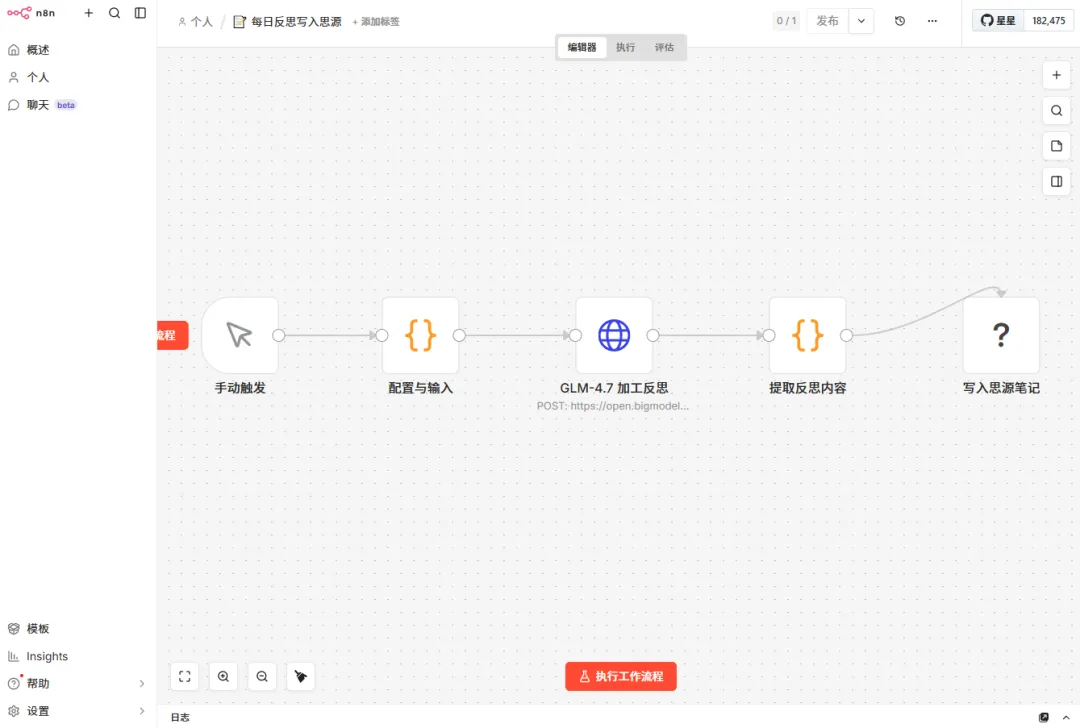
为了提高工作效率,我将小龙虾与n8n工作流配合起来,小龙虾负责"思考"——内容加工、分析、决策,n8n 负责"执行"——定时触发、数据搬运、批量处理;两者配合,既有人工智能的灵活,又有自动化的稳定。分享下创建的n8n工作流案例:“每日反思写入思源”,5个节点搞定:手动触发 → 配置与输入 → 大模型加工反思 → 提取内容 → 写入思源笔记。- 在 n8n 编辑「配置与输入」节点,修改今日反思内容
小龙虾本身擅长对话和代码,但涉及**定时触发、数据流转、多步编排**的场景,n8n 是更好的补充。以下是小龙虾与n8n结合的应用场景分享:六、其它常见小问题
先检查 API 余额是否充足,设置备用大模型;当前大模型欠费了,备用大模型可以立刻顶上使用。检查 cron jobs.json 格式是否正确,Gateway 是否正常运行(openclaw gateway status)。检查 openclaw-weixin 插件是否加载成功,检查小龙虾是否因重启Gateway未正常启动,日志里搜索 [openclaw-weixin] 看有无报错。
写在最后
在使用小龙虾时,你经常会发现"上次明明说好的,怎么又不对了?"反复调试半天,好不容易达到预期,关掉会话再重新打开,之前的所有设置全没了,频繁调试容易让人上火。这是因为你上次和小龙虾沟通的所有细节、约定的所有规则,都只存在于对话上下文中——会话一结束,这些信息就会彻底丢失,下次再用,相当于“从零开始”。所以,核心原则只有一个:多做备份,把所有细节,都“写死”在底层配置文件里。推荐做法:所有重要规则、约定、细节,一律写入配置文件,比如MEMORY.md、TOOLS.md、SKILL.md等,不要只停留在对话里;定期备份整个 workspace 目录——这里包含了所有你的配置文件、设置记录,全量备份,才能避免意外丢失;血泪教训:尽可能使用一个稳定的大模型,避免频繁切换。不同模型对同一份记忆文档(MEMORY.md、memory/*.md)的理解有差异。频繁切换大模型,就相当于频繁更换房子的地基——你好不容易搭建好的规则、调试好的细节,换一个模型可能就理解偏了,导致细节丢失、行为不一致,之前的努力全白费,永远达不到稳定的使用效果。与其在切换模型、反复调试中内耗,不如固定一个稳定的大模型,专注优化配置文件,反而能更快达到预期其实用小龙虾的核心,就是“减少无效内耗”——把该备份的备份好,把该固定的固定好,才能避开大部分坑,让它真正帮你提效,而不是消耗你的耐心。最后想问问大家:你在使用小龙虾时,有没有摸索出什么好用的小技巧?或者踩过哪些印象深刻的坑?评论区分享出来,帮更多朋友避坑,一起高效用对小龙虾~ 夜雨聆风
夜雨聆风