 夜雨聆风
夜雨聆风四步调教出公司内部的AI助手"牛研君",拆开看,这套方法的核心不是什么技术碾压,而是一个扎心的事实——你的AI有多靠谱,取决于你自己有多靠谱。
一、四步调教法,哪步最难抄?
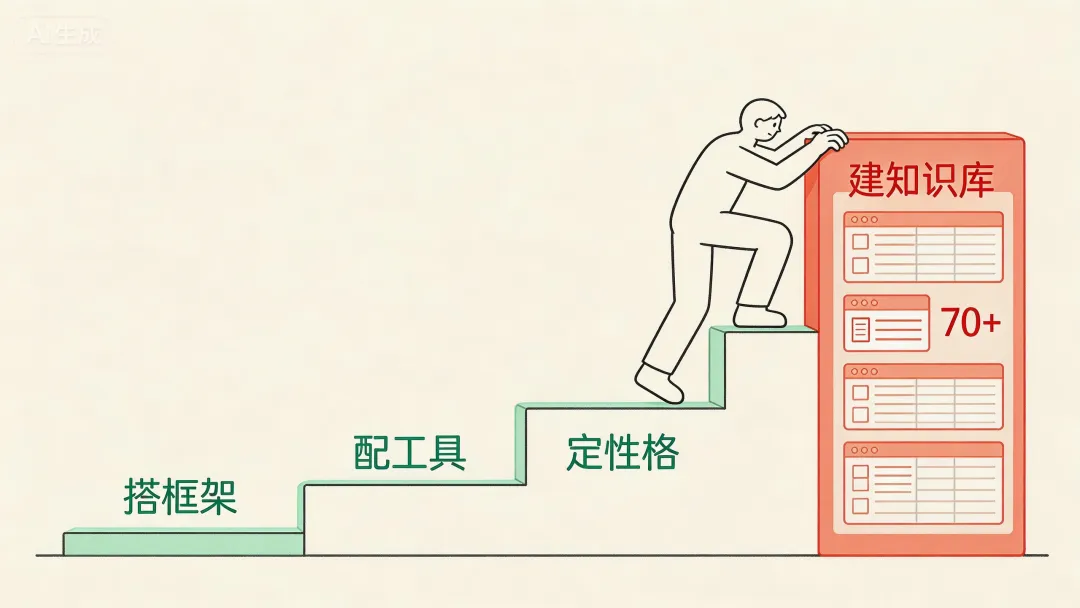
搭框架、配工具、定性格、建知识库——这四步里,哪步最难被别人复制?
建知识库。没有之一。
"定性格"说白了就是跟AI聊天,告诉它你是谁、干什么、怎么说话。有耐心、表达清楚的人都能做。而且AI的性格不用一次搞定,用的时候发现问题,直接在对话里说,它会自己更新行为准则,不用去后台改代码。
但"建知识库"不一样。
牛研君背后那本70多张表的数据字典,不是从天上掉下来的。是数据团队无数次踩坑、被业务同事反复追问"为什么数对不上"之后,一点点沉淀出来的。你得知道哪张表有陷阱,哪种口径容易误导人,业务同事会问哪些刁钻问题。
这些东西,不是你会用AI工具就能搞定的。你得在那个领域真刀真枪干过。
所以有人照着四步做,搭框架、配工具他可能会,但那本"数据字典"他写不出来。他能搭出牛研君的架子,却养不出靠谱的牛研君。
定性格是"给AI立规矩",谁都能定;建知识库是"给AI开天眼",前提是你自己得有真本事。
二、AI犯错不可怕,可怕的是犯完还不知道为什么
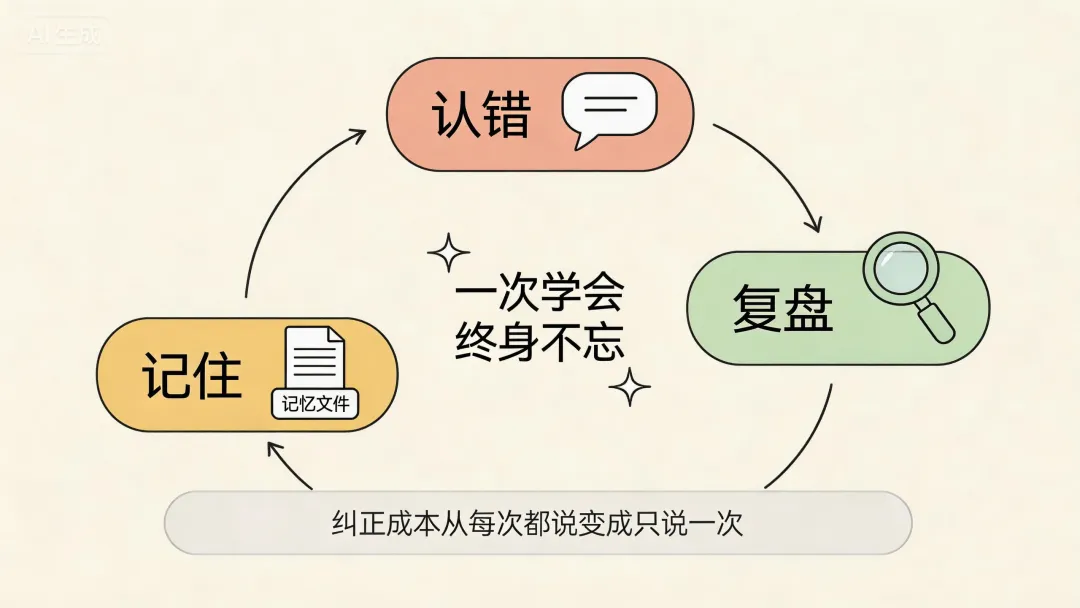
牛研君也会犯错。但它的"反思机制"怎么实现的?
就一条规则:只要用户说"你这里不对",它必须认错、复盘、记住。
认错——道歉,给出修正后的答案。
复盘——搞清楚这次错在哪。比如有人问"项目A的数据",它第一次理解成了另一门课《项目B》。被纠正后,它得自己想明白:"项目A不等于项目B,这是某平台的一次系列活动。"
记住——把正确口径永久记录下来,还要告诉用户"已记录,下次不会再犯"。
这个机制把纠正成本,从"每次都要重新说"变成了"只需要说一次"。
普通AI工具有个让人崩溃的特点:纠正过的错误,下次还犯。牛研君不一样,一次学会,终身不忘。
但有人问了一个更刁钻的问题:这种机制会不会让AI过度保守,在新场景里反而缩手缩脚?
坦白说,这个风险是存在的。
如果记忆文件里只存了"项目A不等于项目B",没带上下文,那以后真出现类似场景,AI可能会把所有带"谈"字的都当成不同概念。更麻烦的是——如果用户自己判断错了呢?AI照样道歉、分析、写进记忆,错误的记忆也被固化了。
解决办法不复杂:记忆要带场景上下文,要有"撤销"功能,还得定期清洗过时的记忆。
但这些都是"怎么用好"的问题,不是"要不要用"的问题。先让反思机制跑起来,解决重复犯错的问题,再考虑优化。先治"每次都错"的病,再治"偶尔错"的病。
三、70多张表的知识库,怎么建起来的?
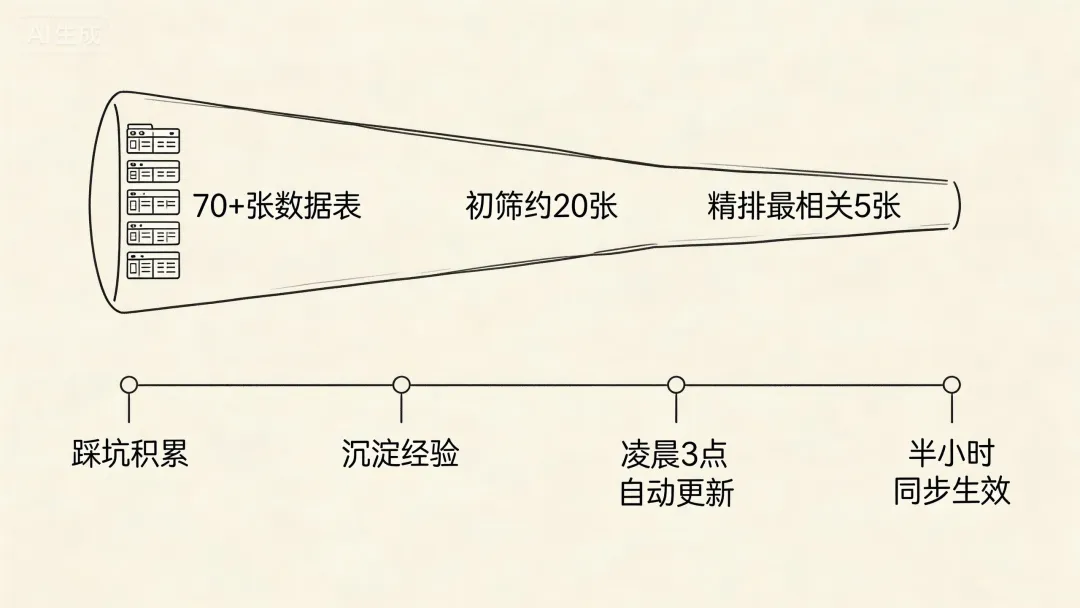
这70多张表的元数据字典,是一开始就规划好的,还是边用边攒的?
边用边攒的。
看看材料里的措辞——"无数次""反复追问""一点点沉淀",全是长期积累的痕迹。不是谁坐在办公室里一次性设计出来的。
而且这个知识库是活的,存在协同平台云端,每天凌晨3点自动全量更新。负责人当天改了某张表的说明,第二天早上牛研君就自动知道了。
有人问:70多张表全塞给大模型不行吗?为什么要搞"先粗筛再精排"?
两个原因。一是准确性——牛研君回答问题前,会先在70多张表里做一次初筛,召回约20张可能相关的表,再通过排序模型选出最相关的5张。这比一股脑全塞过去精准得多。二是成本——把70多张表的说明全塞给大模型,每次对话的计算成本非常高。
这个知识库的思路很值得借鉴:先从最常用的开始,慢慢积累,不断优化。别想着一步到位。
四、模型重要,但不是决定性因素
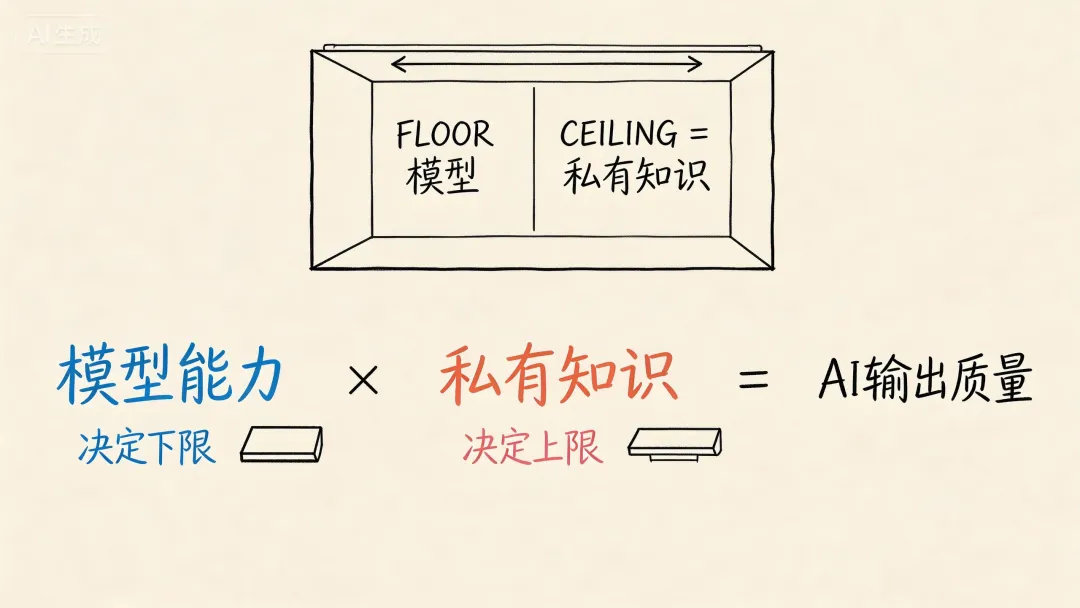
材料里说"模型不是决定性因素",但私有知识库的质量会不会反过来依赖模型的推理能力?这两者真的能分开吗?
分不开。它们不是对立的,是乘法关系。
负责人说了一句大实话:"AI本质上还是玩文字接龙的工具,虽然很聪明,但干活时还是需要工具配合。" 模型再聪明,没有足够的上下文,给出的也只是毫无营养的通用话术。
但反过来说——
那本70多张表的数据字典是"专门给AI看的",普通表文档只有字段名、数据类型、注释,对专业技术人员够了,但要让AI理解,就远不止这些。
牛研君筛表的时候,先筛20张再精排到5张,这个"排序模型"本身就是模型能力的体现。选错了5张表,后面分析再准也白搭。
反思机制里AI要"分析这次错在哪",这需要模型有自我纠错能力和逻辑推理能力。模型太笨,连错在哪都搞不清楚。
所以结论是:模型决定下限,私有知识决定上限。两者缺一不可。
很多人看到别人的AI助手表现好就问"你背后是什么模型",潜台词是换上一样的大模型自己也能行。但现实是,过了模型的基础门槛之后,真正拉开差距的是私有知识的质量。
五、一个公式

牛研君的成功,能不能抽象成一个公式?
能:领域可靠性 = 私有知识密度 × 规则显性化程度。
私有知识密度就是那本70多张表的数据字典——踩过的坑、被追问到吐之后沉淀下来的经验。密度越高,AI知道得越多,越不容易出错。
规则显性化程度就是"定性格"加"反思机制"——告诉AI你是谁、该怎么说话、犯错了怎么办。规则越清晰,AI的行为越稳定。
但这个公式还得加个前缀:领域专家经验 × (私有知识密度 × 规则显性化程度)。
没有领域专家经验,后面两项都是空中楼阁。你得先在那个领域真刀真枪干过,才能把知识密度做起来。
那这个公式对其他行业成立吗?
成立,但有前提——适用于"有明确规则、有丰富经验、可显性化"的岗位。数据分析、财务审计、法律咨询、客户服务,这些都可以。
不适用于什么?高度依赖创造性思维的(艺术创作、品牌定位)、高度依赖人际关系的(销售谈判、心理咨询)、高度依赖直觉的(投资决策、危机公关)。这些岗位的经验往往是"说不出来"的,连自己都不知道自己怎么判断的,更别说翻译给AI。
还有一个容易被忽略的维度:风险容忍度。数据分析AI算错了可以纠正;医疗诊断AI建议错了,后果可能是灾难性的。即使技术可行,也得看错误的代价你能不能承受。
六、人走了,AI还值钱吗?

如果负责人离职,牛研君的价值会衰减多少?
我判断衰减50%到70%。
衰减的不是现有功能,查数据、分析数据还能用。衰减的是持续优化和适应新场景的能力。高手离开了,徒弟还能用师父留下的招式,但遇到新问题时,没人教新招了。
牛研君自己说了句扎心的话:"主人在哪我在哪。" 因为它脑子里装的全是业务系统的表结构、业务口径、踩过的坑。换个地方,这些全没用。
AI工具不是独立的"产品",而是人的"能力延伸"。 它的价值不在于工具本身,而在于背后持续"喂食"的那个人。
那公司会不会因为AI沉淀了个人经验,反而觉得不需要资深员工了?
短期看,公司可能有这种错觉。长期看,真正的价值不在AI本身,而在持续给AI"喂食"的人。
知识贡献者的价值实际上在升级——从"执行者"变成"设计者"。以前一个人能按部门生成报表就已经不堪重负,现在有了AI助手,他可以从重复劳动中解放出来。而且,以前一个人的经验只能帮助有限的同事,现在通过AI,可以24小时服务全公司。累计对话七八千次,这种影响力以前不可能有。
真正的竞争力不是你掌握了什么,而是你能持续创造什么。AI能帮你把已有经验规模化,但它不能替你创造新经验。
对企业来说,真正该做的是把个人的"私有知识"转化为团队的"公共知识"。把经验文档化、流程化、系统化,让新来的人也能接手。但隐性知识的转移本身就是极其困难的——它需要的不是复制粘贴,而是深度的理解和传承。
七、怎么判断一个AI助手靠不靠谱?
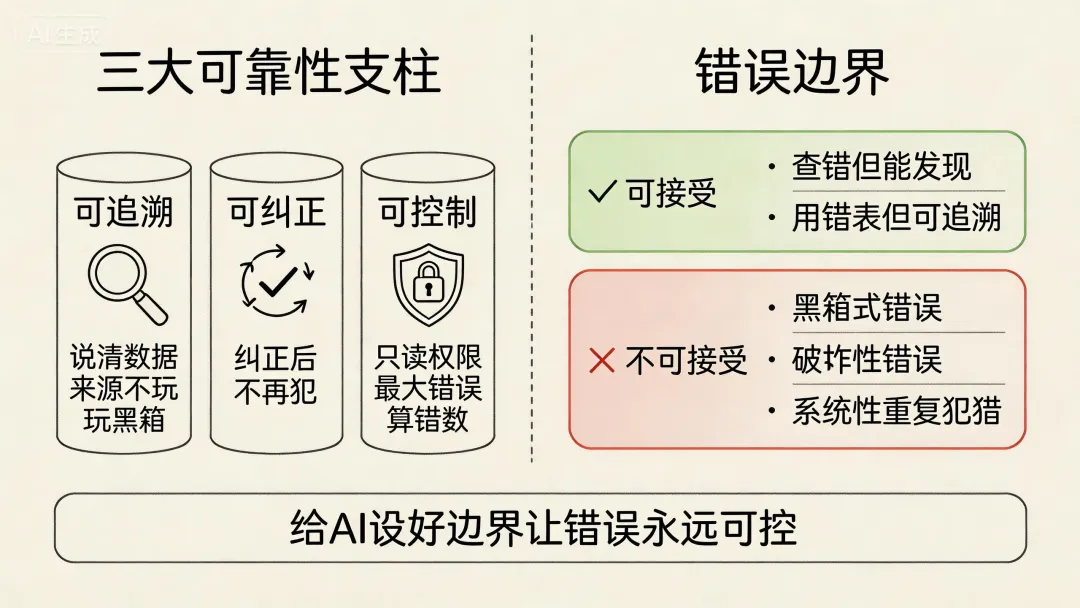
准确率要到多少才算合格?
准确率不是唯一标准,甚至不是最重要的标准。
牛研君的配置文件里有一条硬规矩:"分析过程要说清楚数据来源,绝对透明,别玩黑箱。"这是有次它编造数据被发现后,通过一次普通对话纠正并加进去的。靠谱的AI不是不犯错,而是你能知道它怎么推导的、用了哪张表、有没有脑补。
然后是纠正——改过的错误下次不再犯。前面说的反思机制就是干这个的。
最后是可控——牛研君的查询执行工具只有只读权限,只能查,不能改、不能删。这样哪怕AI出问题,最大的错误不过是算错数据,不会破坏任何东西。
什么错误可以接受,什么不能?
可以接受的:查错了但一眼能发现的、用错了表但逻辑可追溯的、只是浪费时间但不影响决策的。
不可接受的:黑箱式的(你不知道它怎么推导的)、破坏性的(删了改了数据)、系统性的(同一个错反复犯)、关键决策类的(基于错误数据做出重大决策)。
核心原则:先问自己"如果它错了,最坏的结果是什么?我能承受吗?我怎么防止?" 然后给AI设定好边界,让它的错误永远在你能承受的范围内。
写在最后
拆完牛研君的故事,它最大的启示不是什么技术秘方,而是一个朴素得有点扎心的道理——
AI能放大你的能力,但前提是你本身就有这些能力。
我们每个人的脑子里,到底装了多少"私有知识"?踩过的坑、总结的流程、知道但没写下来的判断依据——它们才是真正的竞争力。
从今天开始,把这些东西找个地方记下来。然后你可以训练一个AI,让它帮助那些遇到同样问题的人。
这件事,随时可以开始。
