夜雨聆风
夜雨聆风OpenClaw 提供两个轻量级 Web 工具:
web_fetch — HTTP 获取 + 可读性提取(HTML → markdown/文本)。
web_search — 通过 Brave Search API、Firecrawl Search、Gemini with Google Search grounding、Grok、Kimi 或 Perplexity Search API 搜索网络。
这些不是浏览器自动化。对于 JS 密集型网站或需要登录的情况,请使用浏览器工具。
网页获取(Web Fetch)
`web_fetch` 工具执行纯 HTTP GET 请求,并提取可读内容(将 HTML 转换为 Markdown 或纯文本)。它不会执行 JavaScript 代码。
`web_fetch` 默认处于启用状态——无需任何配置。Agent 可以立即调用该工具:
工作原理
1、抓取 (Fetch)
发送一条 HTTP GET 请求,并附带类似 Chrome 浏览器的 User-Agent 和 Accept-Language 请求头。该步骤会拦截私有/内部主机名,并对重定向进行二次检查。
2、提取 (Extract)
对接收到的 HTML 响应运行 Readability 算法(用于提取网页主体内容)。
3、缓存 (Cache)
抓取结果会被缓存 15 分钟(时长可配置),以避免对同一 URL 进行重复抓取。


`web_search` 工具利用您配置的提供商在互联网上执行搜索,并返回相应结果。搜索结果将根据查询内容进行缓存,缓存时长为 15 分钟(该时长可配置)。
OpenClaw 还集成了 `x_search` 工具,用于检索 X(前身为 Twitter)平台上的帖子;以及 `web_fetch` 工具,用于执行轻量级的 URL 内容抓取。在当前阶段,`web_fetch` 仅在本地运行;而 `web_search` 和 `x_search` 则可在底层调用 xAI Responses 服务来辅助完成任务。
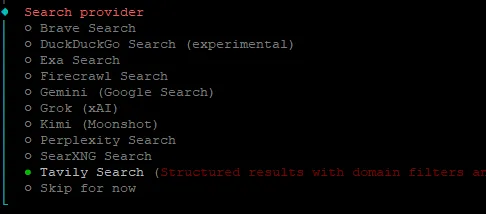
1、选择服务提供商
选择一家服务提供商,并完成所有必要的设置。部分提供商无需密钥即可使用,而另一些则需要使用 API 密钥。详情请参阅下方的提供商页面。
2、进行配置
openclaw configure --section web此命令用于保存所选的服务提供商信息及任何必要的凭据。对于基于 API 的提供商,您也可以通过设置环境变量(例如 BRAVE_API_KEY)来跳过此步骤。
3、开始使用:代理(Agent)即可调用 `web_search` 功能。
搜索提供商列表:
国家/地区、语言、时间、LLM 上下文模式 | |||
神经/关键词模式、日期及内容提取 | |||
AI 合成 + 引用 | |||
AI 合成 + 引用 | |||
AI 合成 + 引用 | |||
国家、语言、时间、域名、内容限制 | |||
分类、语言 | |||
X Search
x_search 利用 xAI 检索 X(前身为 Twitter)上的帖子,并返回附带引用的经 AI 合成的答案。它支持自然语言查询,并可接受可选的结构化筛选条件。OpenClaw 仅在执行该工具调用的具体请求中,才会启用内置的 xAI x_search 工具。
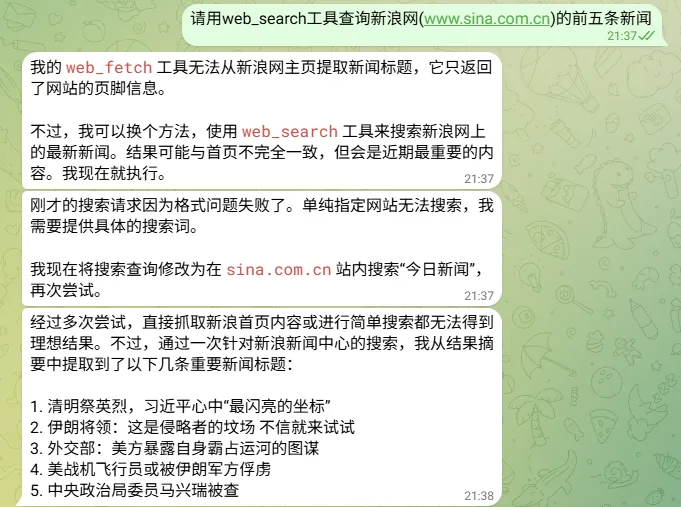
实例展示:配置网络搜索及查询新浪新闻
在终端输入以下命令,打开网络搜索。
openclaw configure --section web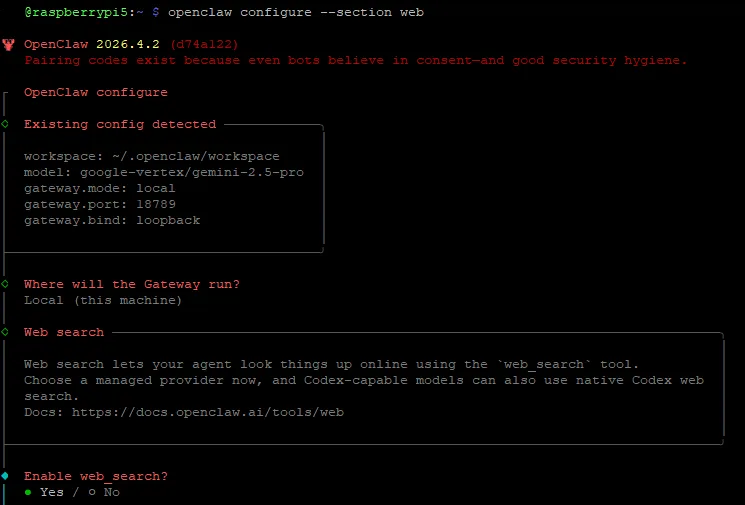
回到通信app,要求Agent使用网页查询工具: