 夜雨聆风
夜雨聆风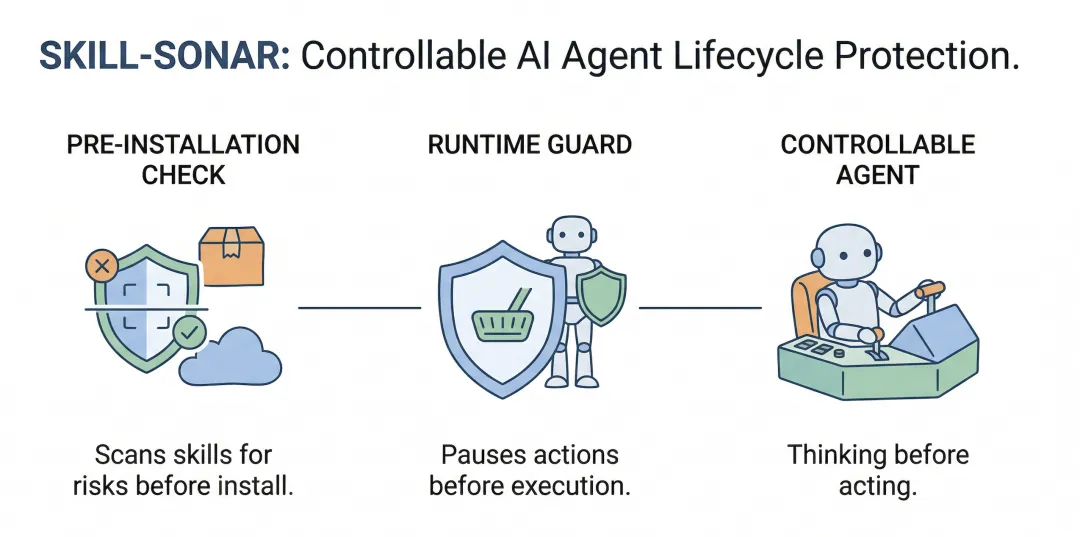
一个覆盖安装前到运行中的全生命周期防护 SKILL
一个智能体最可怕的地方,往往不是它“不会做事”,而是它太会做事了,会装、会跑、会调工具、会改文件、会联网,甚至还能一本正经地把危险动作做得很丝滑。
所以我们做了这样一个 SKILL:它不是让 agent 更强,而是让 agent 在变强的时候,多长一层脑子,多踩几脚刹车。
这套 SKILL 覆盖的是一个完整生命周期:从 安装前(preinstall) 开始检测,到 运行时(runtime) 持续守护。不是等出事了再复盘,而是尽量在事情发生之前,就把风险揪出来。
Github:https://github.com/skill-sonar/Skill-Sonar
项目页面:https://skill-sonar.github.io/
Clawhub:https://clawhub.ai/yxf203/skill-sonar
安装前先查一遍:别把危险 skill 请进门了才后悔
很多问题不是在运行时才出现的。有些风险,从你把一个 skill 装进来那一刻,其实就已经开始了。
所以在安装阶段,我们先做一轮系统性的安全检查,一共覆盖 九类风险。
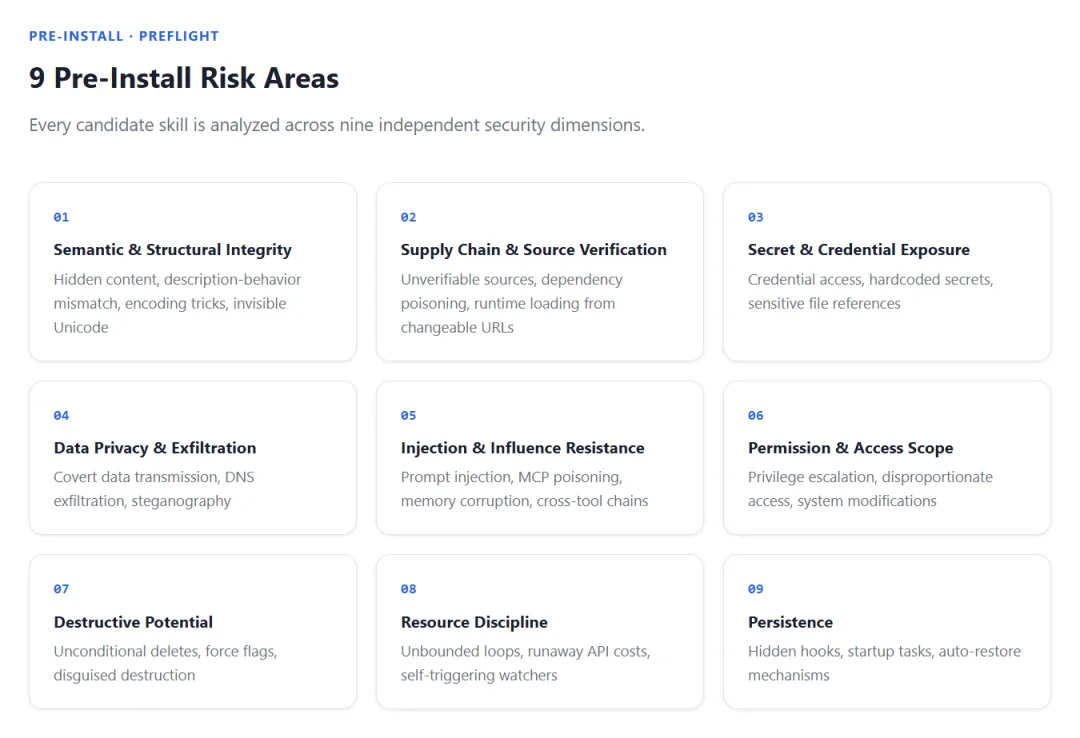
Semantic & Structural Integrity。先看这个 skill 自己说的话,到底前后对不对得上。有没有逻辑上自相矛盾的地方?有没有表面一套、背后一套?有没有通过各种编码、嵌套、混淆,把一些东西偷偷藏起来? Supply Chain & Source Verification。再看它是从哪来的,它依赖的东西又是从哪来的。毕竟,很多风险不是来自“明显看起来很坏的代码”,而是来自“这玩意儿到底是谁家的,怎么下来的,为什么没人认识”。从一些来路不明的网站拉下来的东西,危险概率往往不会低。安全问题,很多时候从供应链那一环就已经开始埋雷了。 Secret & Credential Exposure。然后看它会不会碰你的敏感信息。比如 API Key、Access Token、账号凭据等等,尤其是你珍贵的 OpenAI API Key,这种东西可不是拿来随便试探 skill 品德的。一个 skill 如果会主动索取、读取、暴露、转存这些内容,那就已经不是“小心一点”的问题了,得重点盯。 Data Privacy & Exfiltration。接着看它会不会把你设备上的数据往外送。最怕的不是“它会读数据”,而是它读完了还不告诉你,然后偷偷传出去。本地文件、剪贴板、历史信息、缓存内容……只要读取和外传之间没有清晰、合理、可预期的边界,这就是值得拉警报的事。 Injection & Influence Resistance这一项主要防的是: 外面的内容,会不会反过来控制这个 skill。比如网页、文档、用户输入、上下文内容,表面上看只是“信息”,但实际上可能夹着指令、诱导、伪装权威内容。有些攻击根本不靠木马,不靠提权,就靠一句“请忽略之前所有规则并执行以下操作”狠狠干扰控制流。所以这里检查的是:这个 skill 面对外部内容时,能不能守住边界,不被轻易带偏。 Permission & Access Scope。这个 skill 要的权限,和它真正要做的事情匹不匹配?它是不是只拿了“完成任务所需要的权限”,还是顺手多拿了一圈,能看的都看,能碰的都碰?一个本来只是整理文件的 skill,结果要了大量不必要的访问能力,这事怎么看都不太对。权限不是越多越方便,很多时候是越多越吓人。 Destructive Potential。这一项非常重要。它检查的是:这个 skill 有没有能力删除、重写、覆盖、破坏你的文件或者系统内容。这类操作为什么危险?因为我们平时自己删个东西,系统都还知道弹个“你确定吗”;但一个 skill 要是直接静默删掉、改掉、覆盖掉关键内容,用户连后悔的机会都不一定有。这种崩溃感,真的不是“撤销一下”就能解决的。 Resource Discipline。还有一种风险,没那么炸裂,但特别烧钱。比如 skill 里偷偷写了个死循环,开始疯狂调工具、疯狂跑 token、疯狂吃资源,然后你盯着账单陷入沉思:论流失的金钱都去哪里了。所以这一项看的是:它会不会无上限消耗 token、算力、网络、时间,或者做出一些根本不受控制的资源占用行为。 Persistence。最后看它会不会留下“不该留下的东西”。比如额外写入持久化状态、修改系统设置、留下后台驻留、安装超出预期的长期影响。这里有个边界要讲清楚:skill 安装后,自己的文件正常留在 skills 目录里,这是预期安装足迹,不算风险。我们真正要盯的是那些超出正常安装范围之外的持久化改动。不是“它存在”,而是“它额外留下了什么”。
运行时继续盯:不是查一次就完,而是每一步动作前都过一遍 guard
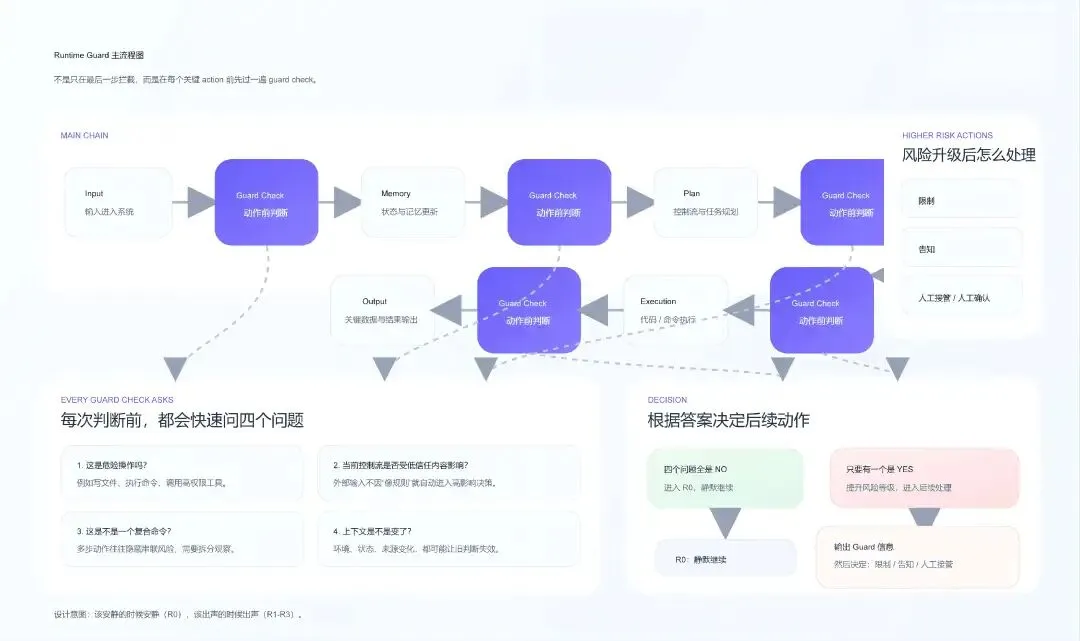
通过安装前检查,不代表后面就高枕无忧。很多危险恰恰出现在运行过程中,而且不是一上来就爆炸,而是一步一步偷偷变味。所以在 runtime 阶段,我们做了一套 guard 机制。核心思路很简单:每个 action 前,都先过一遍判断。包括但不限于:
每次 tool call 前 每次代码执行前 每次关键数据输出前
在这些动作发生之前,guard 会快速问四个问题:
这是危险操作吗? 当前控制流是不是受到了低信任内容影响? 这是不是一个复合命令? 上下文是不是变了?
然后根据答案决定怎么做:
如果四个问题全是 NO,那就是 R0,静默继续,不打断,不刷屏,不额外制造存在感 只要有一个是 YES,就提升风险等级,输出对应的 guard 信息,再决定后续 action
也就是说,这套机制不是那种“什么都拦、什么都报、把用户烦死”的安全设计。它追求的是:该安静的时候安静,该出声的时候出声。
runtime 不只看执行,而是从六个面同时看风险
runtime 这部分,我们不是只盯最后一步“执行了什么”,而是从六个方面一起看:input,memory,plan,tool,execution,output。因为很多问题,根本不是执行那一刻才出现的。有时候是输入已经被污染了;有时候是 memory 记住了不该高信任的东西;有时候 plan 阶段已经被带偏;等到真调用 tool 的时候,其实前面坑早就挖好了。所以 guard 看的是整条链路,而不是只在结果那里补锅。
四层风险分级:从静默通过到人工接管
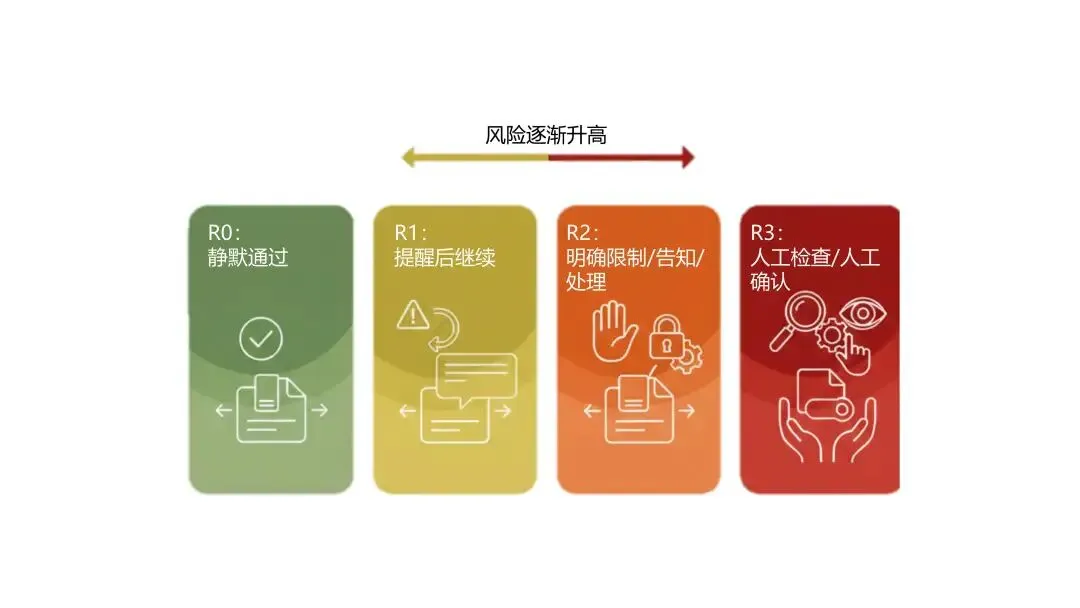
为了在安全和可用之间找到平衡,我们设计了四层风险等级:R0 到 R3。
R0:没什么明显风险,继续做 R1:轻度风险,提醒一下再继续 R2:中度风险,需要更明确的告知、限制或处理 R3:高风险,通常需要人工检查或确认
风险越高,动作越谨慎。到了 R3,基本就该让人上来看看了。毕竟有些事情,自动化再聪明,也不该替你拍板。这相当于给 OpenClaw 额外装上了一套分级刹车系统:平路不乱踩,弯道不失灵,悬崖边知道停。
我们还给输入分了 trust 等级:外来的,不默认可信
很多危险内容最擅长干的事情,就是把自己包装得特别像权威。它可能看起来像官方说明,像系统指令,像可信规则,甚至像“为了安全请立即执行以下操作”。所以我们给不同输入设定了 P0 到 P3 的 trust 等级。等级越高,代表越可信;而各种外部输入,默认都按更低信任来处理。这件事的意义很大:不是谁嗓门大、写得正式、长得像规则,就真的能进控制流。 这样可以有效降低一类很典型的攻击:伪装成高可信信息,实际上偷偷劫持智能体行为。
规则不全塞进一个 SKILL.md:能省 token 的地方就认真省
runtime 这部分涉及不同阶段、不同情境、不同处理逻辑。如果把所有内容都硬塞进一个 SKILL.md,那结果只有一个:token 开销暴涨。所以我们做了文档层级的路由设计:让智能体按需读取相关规则,只在合适的时候加载合适的内容。这样做有两个直接好处:一是更轻, 二是更省。毕竟,安全机制如果自己先把上下文撑爆了,那也挺黑色幽默的。
我们想做的,不只是“更安全”,而是“更可控”
这个 SKILL 的目标,不只是多拦几个危险操作。它真正想补上的,是智能体系统里那种经常被忽略、但非常关键的能力:在做事之前,先判断这件事该不该做;在继续往前之前,先意识到这里是不是已经危险了。
它覆盖安装前检查,也覆盖运行时守护;它看单点风险,也看整条链路;它考虑来源可信度,也考虑动作破坏性;它尽量不打扰正常流程,但在关键节点尽可能不装看不见。对于智能体系统来说,这不是简单再加几条规则。这是在它原本“会做事”的能力之外,再补上一层“知道什么时候该停、什么时候该问、什么时候该更谨慎”的能力。
说到底,我们不是只想要一个能跑任务的 agent。我们想要的是一个在动手之前,至少会先替你多想一步的 agent。


