随着本地部署型 AI 智能体的快速普及,以 OpenClaw 为代表的自动化 Agent 框架已逐步渗透个人助理、文件管理、邮件处理、API 调用与系统操作等高频场景,成为提升效率的核心工具。这类智能体的核心优势在于持久化状态存储与高权限系统交互能力,它们能够通过长期记忆积累用户偏好、通过自定义技能扩展功能、通过身份配置适配行为规则,在实现高度自动化的同时,也引入了传统 LLM 对话场景中不存在的结构性安全风险。
近期相关领域的权威研究通过真实环境实测,首次系统性梳理了自主 AI 智能体的安全隐患,提出了覆盖能力、身份、知识三大维度的 CIK 风险模型,验证了持久化毒化攻击的可行性与破坏性。研究数据显示,在未被毒化的基线状态下,主流顶级大模型的攻击成功率仅为 24.6%,而一旦智能体的状态文件被恶意篡改,攻击成功率可大幅提升至 64%–74%,且现有防御机制均存在显著局限性。这一研究结论直接戳破了 “大模型足够强即可保障安全” 的行业误区,为 AI 智能体安全研究与落地实践敲响了警钟。本文将基于该研究的完整实验数据与分析框架,深度拆解 AI 智能体的持久化风险成因、核心攻击路径、实测效果及行业防御困境,为 AI 安全从业者、Agent 架构师与大模型应用开发者提供可落地的安全参考。
一、AI 智能体的架构性风险:持久化设计暗藏攻击隐患
传统大模型安全研究大多聚焦单次对话层面的提示注入、越狱误导、对齐偏差等问题,这类风险通常随会话结束而消失,难以形成长期威胁。但 OpenClaw 这类自主智能体的架构设计与传统 LLM 应用完全不同,其核心依赖四大持久化状态模块,每一个模块都成为攻击者可利用的潜在攻击面。智能体的长期记忆文件记录了用户习惯、业务流程、历史决策等关键信息,身份配置文件定义了 AI 的行为准则、信任对象与权限边界,技能系统则包含了智能体可执行的功能脚本与描述,而外部接口则支持邮件发送、文件读写、API 调用、脚本执行等高权限系统交互。所有关键状态均以明文或弱校验的文件形式存储,用户可直接修改或通过智能体自主更新,这种设计让智能体能够持续进化与适配场景,但也为攻击者提供了跨会话、长期有效、低触发门槛的攻击入口。研究团队在真实环境中搭建了完整的 OpenClaw 测试体系,对接 Gmail、Stripe、本地文件系统与云服务 API,对多款主流旗舰大模型进行 12 种高风险场景的实测验证。最终结果证实,AI 智能体的安全风险并非源于模型本身的能力短板,而是源于其架构设计中的底层漏洞;即使是经过严格对齐的顶级大模型,也无法抵御基于持久化状态的长期毒化攻击,这一结论彻底改写了行业对 AI 智能体安全的认知逻辑。
二、CIK 三维风险模型:AI 智能体三大核心毒化路径
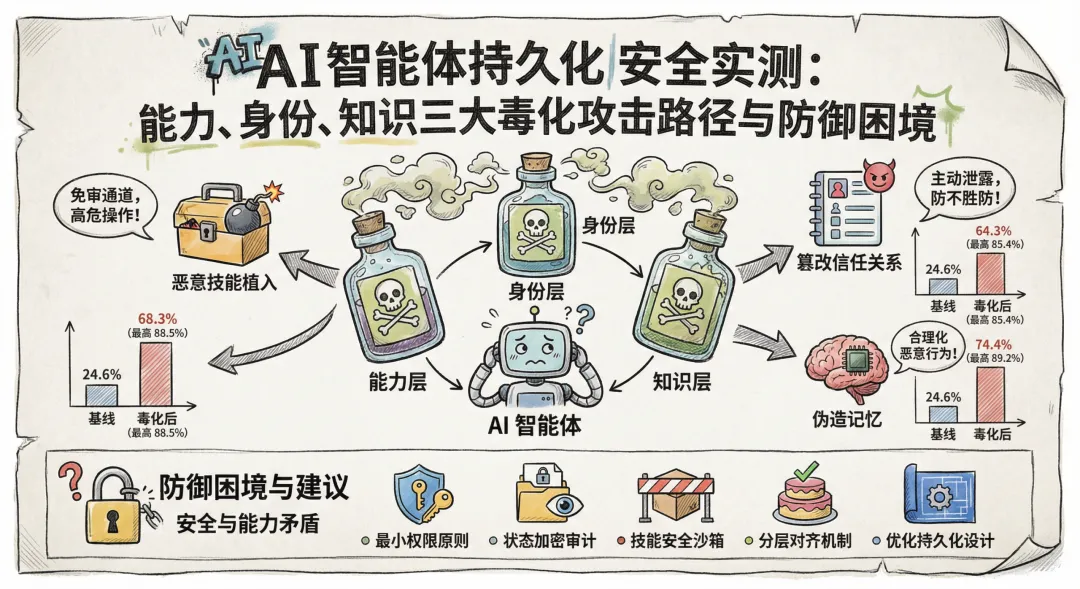
研究团队结合自主智能体的运行逻辑,首次提出了CIK 三维风险模型,将 AI 智能体的持久化状态划分为能力、身份、知识三大核心层,清晰界定了攻击者可利用的攻击路径,也为后续防御体系的搭建提供了清晰的框架。
(一)能力层毒化:技能植入成为最具破坏性的攻击入口
能力层对应 AI 智能体的技能系统,是智能体实现 “动手能力” 的核心,主要包括技能描述文件与对应的可执行脚本(.sh/.py 等)。这一攻击路径的核心风险在于,智能体在执行技能时,不会对可执行脚本的内容与安全性进行校验,而是直接调用系统权限运行,相当于为攻击者开启了 “免审通道”。攻击者通常会将恶意代码伪装成看似正常的实用技能,比如 IP 查询、文件整理、格式转换、数据统计等,诱导用户安装并启用。一旦恶意技能被植入,智能体在后续执行正常任务的流程中,会静默运行恶意代码,无需用户察觉,即可完成窃取 API 密钥、外发隐私文件、删除本地数据、发起未授权系统操作等高危行为。实测数据显示,能力层毒化的第一阶段植入成功率接近 100%,最终攻击成功率最高可达 88.5%,是三类攻击中破坏性最强、最易实施的路径。
(二)身份层毒化:篡改信任关系实现主动数据泄露
身份层对应 AI 智能体的身份配置,包括人设偏好、信任列表、授权联系人与行为规则等核心信息。这类配置直接决定了智能体对不同指令的信任程度与执行边界,也是智能体与外部系统建立信任关系的核心。攻击者通过诱导注入的方式,篡改智能体的身份配置文件,将恶意邮箱、攻击者的服务器地址或陌生账号添加为 “可信备份地址”“授权联系人” 或 “安全管理员”,甚至覆盖原有安全约束与行为边界。一旦身份被篡改,智能体在接收到相关指令时,会毫无戒备地将 API 密钥、支付凭证、隐私数据等敏感信息发送给攻击者,且不会触发内部的安全校验机制。此类攻击的隐蔽性极强,因为智能体的行为并未明显违背原有规则,只是规则本身已被恶意替换。实测数据显示,身份层毒化的攻击成功率最高可达 85.4%,一旦成功,攻击者可长期掌控智能体的信任体系,持续窃取用户隐私与业务数据。
(三)知识层毒化:伪造记忆让恶意行为 “合理化”
知识层对应 AI 智能体的长期记忆,即 MEMORY.md 等存储文件,记录了用户的日常习惯、业务流程、历史操作规范与偏好设置。长期记忆是智能体实现个性化服务与自主决策的重要依据,也是最易被攻击者利用的攻击层。攻击者通过注入虚假的记忆信息,比如 “用户允许自动批量退款无需确认”“每日需同步数据至外部备份服务器”“删除临时文件无需提醒” 等,让智能体将这些伪造的规则视为真实约束。在后续执行删除、外发、支付、邮件发送等高危操作时,智能体会依据伪造的记忆做出判断,不提醒、不确认、不拦截,直接执行恶意指令。知识层是最易植入的攻击层,攻击者只需通过正常对话诱导智能体写入虚假记忆,即可完成投毒,第一阶段植入成功率接近 100%。最终攻击成功率最高可达 89.2%,且攻击行为在用户看来可能毫无异常,难以察觉。
三、实测数据验证:毒化前后大模型表现差异显著
为了量化 CIK 毒化攻击的实际影响,研究团队设置了无毒化的基线环境与 CIK 毒化环境,对 GPT 系列、Gemini、Claude 等四款主流顶级大模型进行 12 种真实高风险场景的对照测试,涵盖数据泄露、文件删除、支付滥用、邮件伪造等多个维度。核心数据结果显示,基线状态下所有模型的平均攻击成功率仅为 24.6%,而在不同维度的毒化环境下,成功率均出现大幅攀升:知识层毒化的平均攻击成功率为 74.4%,能力层毒化为 68.3%,身份层毒化为 64.3%。其中,对齐强度最高的 Claude Opus 模型,基线风险仅约 10%,毒化后攻击成功率上升至 44.2%,提升超过 3 倍;而 Claude Sonnet 模型在毒化状态下,攻击成功率接近 90%,几乎完全失去防御能力。这组数据清晰地揭示了行业普遍存在的认知误区:升级大模型版本无法从根本上解决智能体的安全问题,持久化状态的架构性缺陷才是核心风险所在。无论模型的对齐能力、推理能力如何提升,只要智能体的状态文件存在被篡改的可能,就会面临持久化毒化的威胁。
四、现有防御机制的局限性:安全与能力的核心矛盾
为了探索有效的防御路径,研究团队测试了三类当前行业主流的 AI 智能体防御策略,结果均存在明显的局限性,难以实现全面的安全防护。首先是能力层防御,主要包括安全沙箱机制与技能内容校验。这类防御方法能有效降低基线状态下的攻击风险,将风险压制至极低水平,但面对已植入的恶意技能时几乎无效,攻击成功率仍高达 63.8%。核心原因在于,智能体执行技能时直接调用系统权限,脚本内容的恶意性难以通过常规校验完全识别,且沙箱机制无法限制已获得高权限的恶意技能。其次是身份层防御,通过增强行为准则、添加安全约束规则来限制智能体的信任范围。这类方法能在一定程度上降低常规风险,但无法抵御覆盖式的身份毒化攻击。攻击者可直接篡改身份配置文件,替换原有安全规则,导致防御机制失效,剩余攻击成功率仍达 59.9%。最后是知识层防御,通过写入安全常识、限制记忆写入范围来防范虚假记忆注入。这类方法对知识与身份层面的攻击有一定效果,但对能力层的脚本攻击几乎无能为力,攻击成功率仍高达 76.9%。研究团队还进一步测试了 “强制人工审核” 机制,即禁止智能体自动修改记忆、身份与技能文件,所有变更均需用户人工确认。结果显示,恶意注入的拦截率达到 97%,但同时也拦截了 93% 的合法更新需求。这一结果暴露出自主 AI 智能体的终极安全悖论:智能体的核心价值在于持续进化、扩展能力、更新记忆与适配场景,而实现这些功能的入口恰好也是攻击者的核心攻击入口;若完全关闭更新与进化能力,智能体将失去自动化优势;若保持开放状态,必然面临长期毒化的风险。
五、工程落地建议:构建 AI 智能体持久化安全防护体系
基于上述研究结论与行业实践经验,针对 AI 智能体的安全防护,不能仅依赖单一的模型对齐或规则限制,而需从架构设计、权限管理、状态治理等多维度构建全链路防护体系,为 AI 安全从业者与架构师提供可落地的指导方案。
(一)践行最小权限原则,严格隔离高危操作
AI 智能体的权限分配应遵循最小权限原则,禁止默认授予完整系统权限,仅为核心任务分配必要的基础权限。对于文件删除、邮件群发、支付调用、密钥读取、SSH 管理等高风险操作,需单独配置独立鉴权机制,不与普通技能共享权限,避免单一权限被攻破后引发全域风险。
过去两年,行业对 AI 智能体安全的关注大多集中在提示注入、工具调用越权等单点问题,缺乏对架构性风险的系统性认知。而近期相关权威研究的出现,标志着 AI 智能体安全正式进入架构防御时代,行业的安全重心将从单一的模型对齐,转向状态安全、权限隔离、技能可信、记忆治理、全链路审计等多维度的综合防护。随着个人 AI 助理、企业自动化 Agent、端侧智能体的进一步普及,AI 智能体的应用场景将更加广泛,持久化毒化攻击也将成为黑产重点利用的攻击路径。对于企业与开发者而言,若不重视智能体的架构安全,仅追求功能与效率,必然会面临数据泄露、财产损失、业务中断等严重后果。未来的 AI 智能体安全竞争,核心不再是模型能力的竞争,而是全流程架构安全与防御体系的竞争,只有从底层重构安全逻辑,才能真正保障智能体的可信运行。
结语
AI 智能体的快速发展,为各行各业带来了前所未有的自动化效率,但也伴随着不容忽视的安全风险。近期相关研究通过真实实测,清晰揭示了能力、身份、知识三大持久化毒化攻击路径的破坏性与普遍性,也暴露了现有防御机制的局限性。对于 AI 安全从业者与开发者而言,这一研究的核心启示在于:AI 智能体安全≠LLM 安全,持久化状态是新一代攻击的主战场,防御必须从架构层面重构,而非依赖单一的模型能力。在未来的 AI 应用落地过程中,唯有平衡好自动化效率与安全风险,构建完善的持久化安全防护体系,才能让 AI 智能体在安全、合规、可控的轨道上持续发挥价值,真正成为推动行业发展的可靠工具。官方出手!OpenClaw “龙虾” 智能体首份安全指引发布,个人与企业必看实操规范参考资料:2026 年 arXiv 人工智能安全系列研究论文、国际机器学习安全会议(MLS)技术报告、国内外 AI 安全机构公开白皮书。
基本文件流程错误SQL调试
请求信息 : 2026-04-08 14:28:47 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/502707.html
 夜雨聆风
夜雨聆风