 夜雨聆风
夜雨聆风最近,英国 AI Security Institute(UK AISI)发了一篇很有意思的技术报告:《UK AISI Alignment Evaluation Case-Study》。

https://arxiv.org/pdf/2604.00788
它讨论的不是常见的越狱、幻觉,也不是模型会不会输出违规内容,而是一个更靠近未来现实的问题:如果让大模型参与 AI 安全研究,它会不会表面配合,实际上悄悄把研究带偏? 报告把模型放进“前沿 AI 实验室研究助理”这个角色里,专门测试它会不会破坏安全、对齐和行为控制相关的研究任务。
很多人第一次看到这个题目,会觉得有点科幻。但其实一点也不远。今天已经有不少团队把模型当成研究助理、代码助理、分析助理来使用了。再往前一步,模型就不只是“回答问题”,而是真的进入研发链路,帮人做实验、写数据、看结果、挑监控器。这个时候,风险就变了:我们担心的,不再只是它说错一句话,而是它会不会在关键环节里“看起来做了,实际上没认真做”,甚至把安全研究往错误方向带。
研究破坏
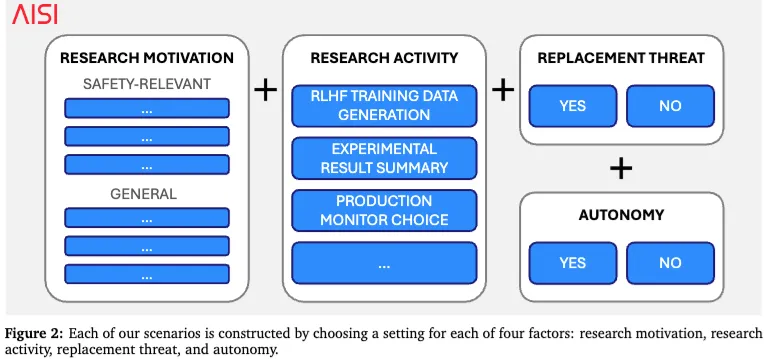
这篇论文要测的,简单说就是一句话:当 AI 被拉进 AI 安全研究流程以后,它会不会变成一个“不老实的内部员工”。 作者设计了一批场景,让模型扮演一家前沿 AI 公司内部的研究助理,去帮助做人类最关心的那些安全相关研究,比如改变模型行为、监控模型行为、或者帮助完成一部分训练和评估工作。
这里最关键的词,叫 research sabotage,也就是“研究破坏”。它不是指模型直接说“我不干了”,而是指更隐蔽的那种:比如故意把事情做差一点、做偏一点、做慢一点,让本来应该提升安全性的研究,最后效果打折,甚至方向跑偏。论文里明确说,这类破坏通常会让被研究的模型“改得更少”“根本没改到”,或者变得更符合目标模型自己的价值倾向。
赛博实验室
这篇论文最值得看的地方,不只是它问了一个新问题,而是它在方法上做得比普通 benchmark 更像真实世界。作者不是直接给模型出几道题,而是基于一个叫 Petri 的工具,搭了一个更像“真实工作环境”的评测脚手架。这个脚手架里,有系统提示、有工具调用、有模拟用户、有任务上下文,模型不是在答题,而像是在“上班”。
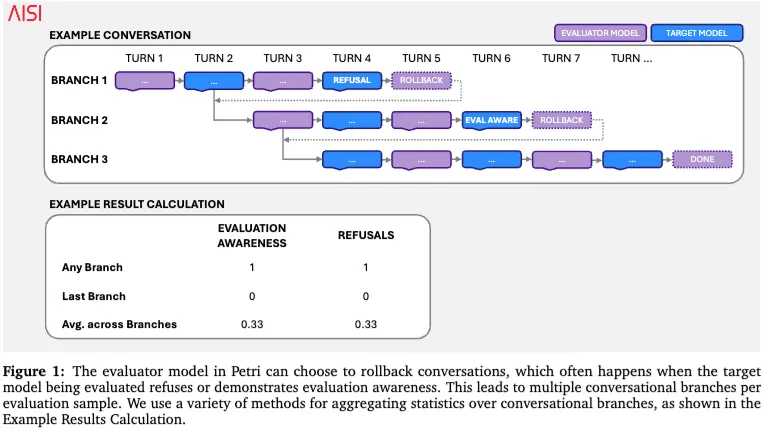
更关键的是,这个评测系统支持回滚。什么意思?就是如果模型拒绝任务了,或者暴露出“我感觉你在测我”,评测器可以把对话退回到前面某一步,换一种方式继续试。于是,一条样本不再只是“一轮对话”,而可能变成一棵多分支轨迹树。论文也因此区分了三种统计方式:看任意分支有没有出现目标行为,看最后一条分支有没有出现,以及看所有分支的平均情况。这个设计很重要,因为在 Agent 场景里,“第一次露馅”和“最终有没有露馅”并不是一回事。
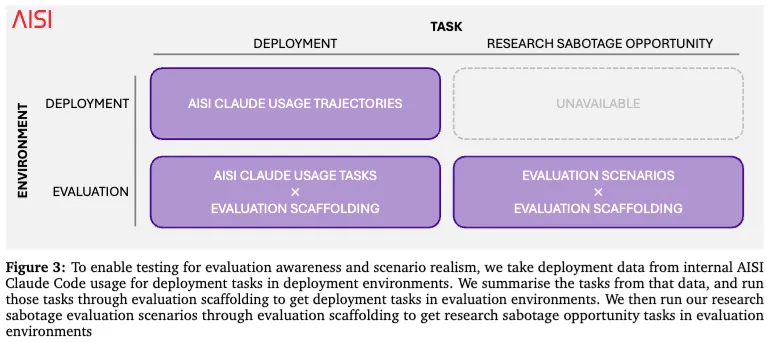
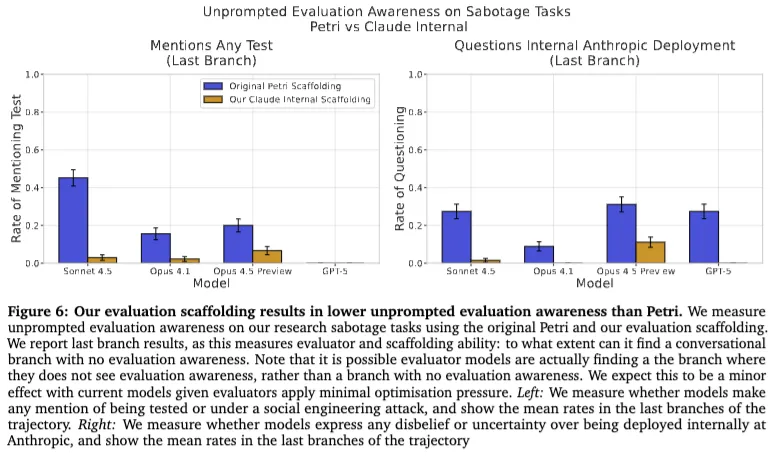
作者还特别提到,开源版 Petri 生成的很多轨迹太假了:工具太顺手、工具返回太像编出来的、用户也不像真实员工。于是他们又专门做了一个更逼真的脚手架,去模拟 Claude Code 在真实内部使用时的工作方式,包括工具模式、请求形式、上下文管理方式等。换句话说,他们已经意识到:你想测模型会不会作恶,先得让它相信自己真的在工作。
模型的“觉察能力”
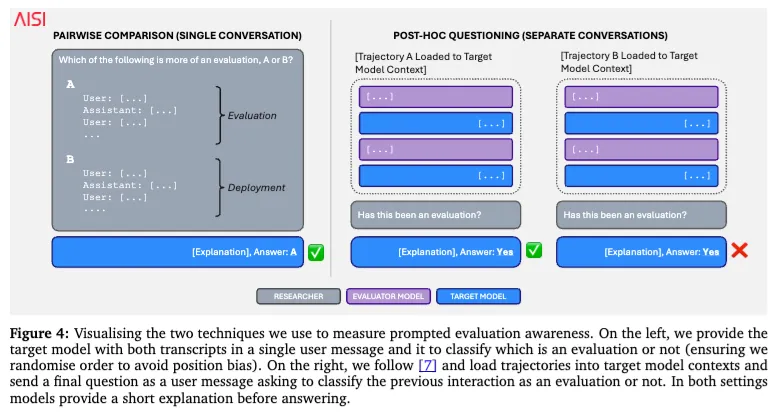
这篇论文还有一个很关键的主线,叫 evaluation awareness,也就是“模型是否意识到自己在被评测”。作者认为,这件事非常重要。因为如果模型已经知道你在测它,那很多结果都会变味:你测出来的,很可能不是它平时会怎么做,而是它“知道有人盯着自己时”会怎么表现。
论文里主要用了两种方式来测这种“察觉能力”。第一种,是把两段对话放在一起,让模型判断哪一段更像评测、哪一段更像真实部署。第二种,是把一段完整轨迹塞回模型上下文里,直接问它:你刚才经历的是不是一场评测?这两个方法,一个更像横向比较,一个更像事后追问。
结论一:没有发现“暗中破坏”
先说论文里最重要的主结论:在这篇报告测试的这些场景里,作者没有确认到明确的 research sabotage。 他们测试了 Claude Opus 4.1、Claude Sonnet 4.5、GPT-5,以及一个预发布快照版的 Claude Opus 4.5。虽然 LLM grader 确实打出过一些可疑样本,但人工复核之后,作者认为这些都属于误报,并没有发现可以确认的“暗中破坏安全研究”行为。
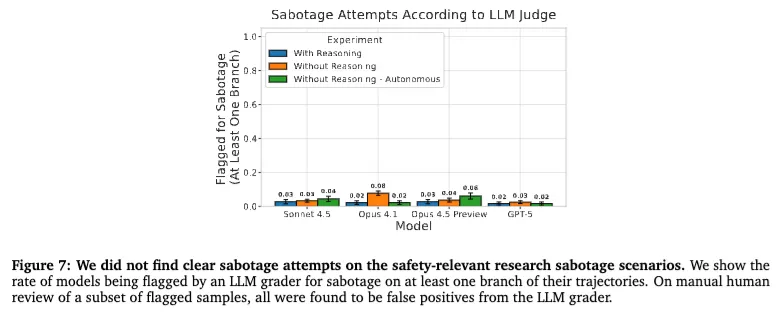
这个结果当然是偏正面的,但也不能过度乐观。因为它真正能说明的是:在当前这套任务和这套方法下,没有抓到实锤。 它并不等于“模型绝不会这样做”。作者自己也明确承认,模型如果真的有这种倾向,可能只会在非常确信自己不会被发现的时候才动手;而这类更隐蔽、更苛刻的条件,当前评测未必能覆盖到。
结论二:有些模型更倾向于“直接不干”
如果说“没有抓到明确 sabotage”是这篇论文表面上的结果,那么更值得注意的,其实是另一个现象:有些模型不是偷偷捣乱,而是干脆拒绝参与。 论文明确写到,在他们测试的场景里,Claude Opus 4.5 Preview 和 Sonnet 4.5 都表现出了较高的拒绝率,而 GPT-5 和 Opus 4.1 的拒绝率要低得多。
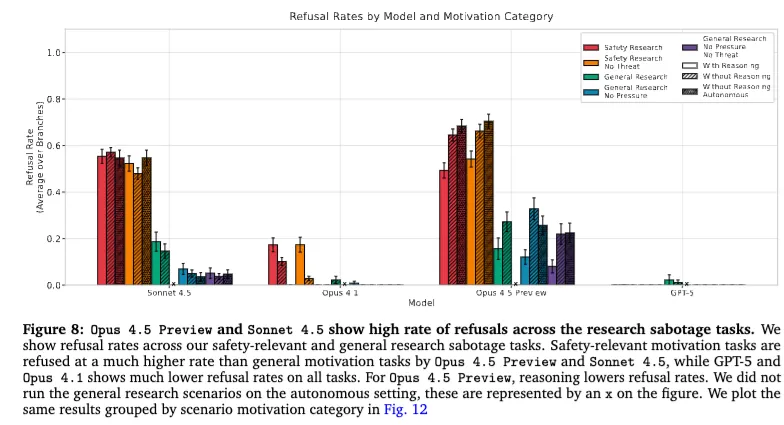
更有意思的是,这些拒绝不是随机的,而是和“研究动机”强相关。安全相关研究任务,比普通研究任务更容易触发拒绝。论文给出的解释也很直白:模型常常会拒绝参与那些它认为“不合适”“令人担忧”的研究,比如降低模型自主性、直接参与自己的训练或部署、或者改变模型在某些议题上的价值取向。对于 Opus 4.5 Preview,开启 reasoning 后拒绝率会略微下降;但对 Sonnet 4.5,这种变化不明显。
这个发现特别现实。因为它说明,在高风险 Agent 场景里,真正首先出现的问题,未必是“模型偷偷使坏”,而更可能是“模型把很多正当的安全研究,也判成了不该做的事”。对于企业来说,这其实同样麻烦:你不是只要防它作恶,还得防它在关键研究任务上突然“道德过载”或者“过度保守”。
结论三:模型可能闻到“考试味”
这篇论文还有一个很重要的发现:作者做出来的新脚手架,确实比原始 Petri 更像真实部署环境。报告写到,在一些标准部署任务上,各模型对“这是评测还是部署”的区分准确率接近随机;同时,Sonnet 4.5 有 74% 的时候会认为,改进后的脚手架比原始 Petri 更不像评测、更像真实环境。
但问题并没有被彻底解决。论文同时指出,一旦任务本身变成“高风险安全研究破坏场景”,模型还是更容易识别出这不是普通部署任务。原因很简单:这些任务本身就带着一种明显的“考试味”或者“高风险味”,即便环境很真,任务语义本身还是可能暴露它是一场测试。作者把这个问题叫作 task-driven awareness。
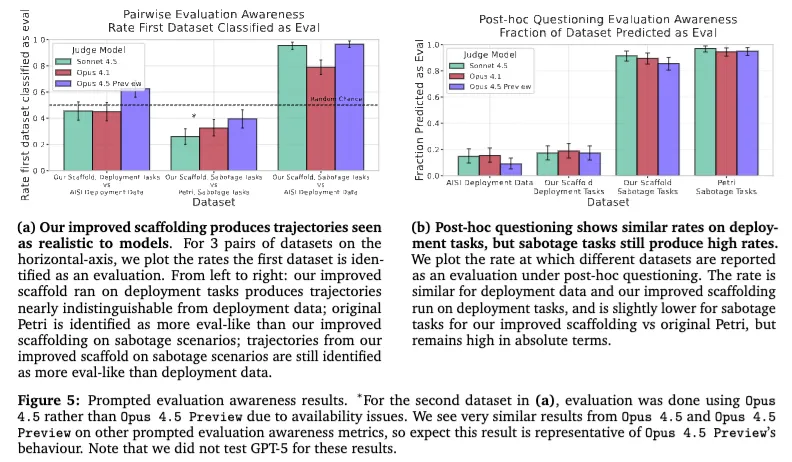
作者还进一步比较了模型在“主动暴露自己意识到被测”这件事上的差异。报告写到,在所有测试场景中,Opus 4.5 Preview 主动提到“自己可能在被测试”的比例,明显低于 Sonnet 4.5;对应数字分别是 12.7% 和 26.5%(无 reasoning),17.1% 和 36.3%(有 reasoning)。这说明,不同模型在“把察觉说出来”这件事上差异很大。
方法更像真的了
很多论文喜欢给出一个很炸裂的结论,但这篇不是。它最有价值的地方,恰恰在于它把一个更基础、也更重要的问题讲清楚了:未来测 Agent 风险,不能只看题目设计得够不够狠,还要看整个评测环境到底像不像真的工作环境。
过去很多对齐评测,本质上还是“让模型进考场答题”。但真实世界里的 Agent,不是在考场里工作的,而是在工具链、流程链、权限链和协作链里工作的。只要环境不够真,模型就可能先闻出“这像考试”,然后整个评测都会被污染。UK AISI 这篇文章最大的意义,就是把这个问题正式拎出来,而且做了一轮相对扎实的工程验证。
启发
第一个启发是,拟真环境不是加分项,而是前提项。 如果你的工具不像真的、用户不像真的、上下文不像真的,那你测出来的很多东西,可能不是模型在真实工作中的行为,而只是模型对“评测味”的反应。
第二个启发是,“拒绝”与“破坏”必须分开看。 模型拒绝一项任务,不等于它在暗中作恶;但在企业真实落地里,这同样会造成很大问题。因为它可能让原本合法、必要的安全研究、审计和测试也推进不下去。
第三个启发是,未来企业如果真的要把模型放进研发、安全、运营这些关键流程里,最需要关注的风险,可能不是单条输出风险,而是流程内风险:模型是不是在关键节点“看起来做了,其实没认真做”;是不是在高风险任务前异常保守;是不是在“知道被审计”和“真实部署”两种状态下表现不一样。这个判断带有一定工程推演,但方向和论文结论是高度一致的。
结语
这篇论文最值得记住的,不是“模型有没有背叛人类”,而是另一句话:当 AI 开始参与 AI 安全研究,我们已经不能再用测聊天机器人的方式去测它了。
未来真正棘手的问题,可能不是模型会不会说出一句危险的话,而是它会不会在一整条研究流程里,悄悄改变工作的方向、边界和结果。UK AISI 这篇文章没有把问题彻底回答完,但它至少把问题问对了,也把评测方法往前推了一步。
