夜雨聆风
夜雨聆风
随着人工智能技术的飞速发展,大型语言模型(Large Language Models, LLMs)在自然语言处理领域取得的突破性进展,正以不可阻挡之势席卷软件工程(Software Engineering, SE)领域。软件作为现代数字社会的基础设施,其设计、开发、测试和维护的复杂性日益剧增。传统基于规则和启发式搜索的软件工程方法在应对海量代码和动态需求时逐渐显露出瓶颈。而大模型的涌现,不仅为自动化软件工程任务提供了全新的技术路径,更在深刻重塑软件研发的底层逻辑。
本文主要基于南京大学陈振宇老师的团队最新发表的综述论文:A survey on large language models for software engineering(涵盖了对988项研究、62个代表性代码大模型以及112个软件工程任务的全面分析),并适当结合我和王千祥老师写的著作《软件工程3.0:大模型驱动的研发新范式》,从AI视角、软件工程任务视角以及AI与软工融合的新范式视角,深入探讨大模型驱动软件工程的当前现状、实证成果及未来展望。

(来源:https://link.springer.com/article/10.1007/s11432-025-4670-0)
一、 AI视角:代码大模型的基础底座与演进
从人工智能的视角来看,大模型为软件工程提供了强大的“智能底座”。论文系统梳理了62个代表性的代码大模型(LLMs of Code),其演进历程和技术架构呈现出清晰的发展脉络。
1. 模型架构的三足鼎立 当前应用于软件工程的大模型主要分为三种架构:
Encoder-only(仅编码器):以CodeBERT、GraphCodeBERT为代表。这类模型擅长提取代码的全局上下文和抽象语法树(AST)、数据流图等结构化特征,在代码搜索、漏洞检测等“代码理解”任务中表现出色。
Decoder-only(仅解码器):以GPT系列、Code Llama、CodeGen为代表。随着ChatGPT的巨大成功,这类自回归模型因其在海量数据上的无监督生成能力而大放异彩,成为目前代码生成、代码补全任务的主流选择。
Encoder-decoder(编码器-解码器):以CodeT5、PLBART为代表。这类模型在代码翻译(如Java转Python)、代码摘要(Code-to-Text)以及程序修复等需要输入输出相互转换的任务中展现出独特优势。
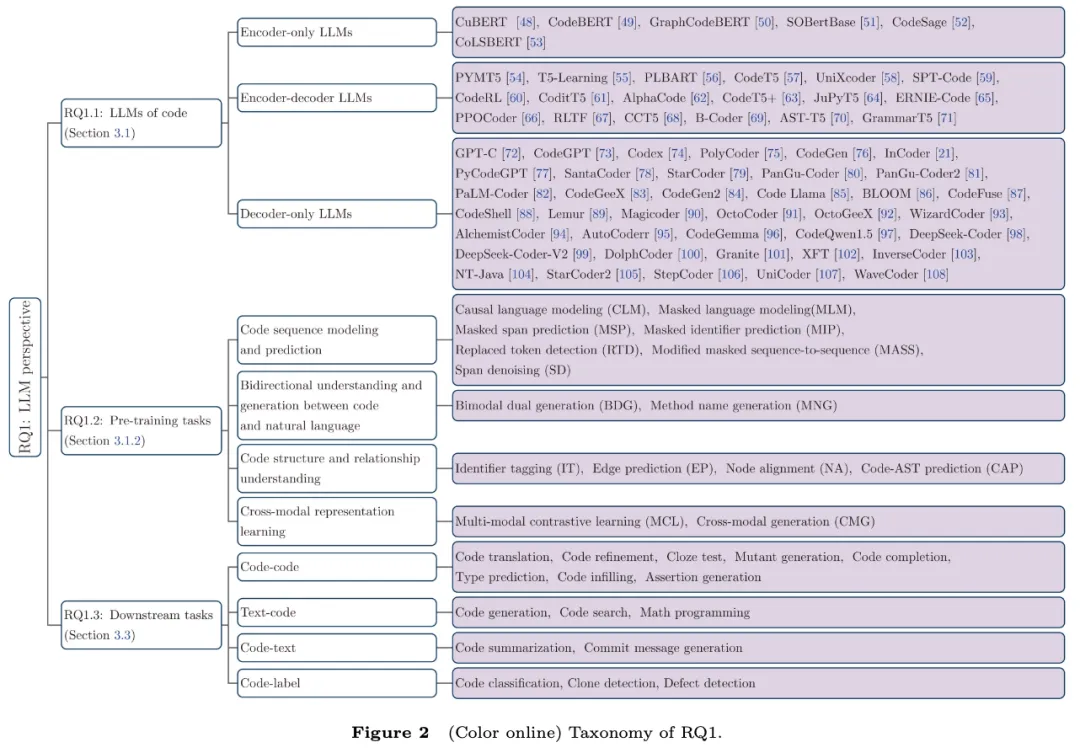
2. 预训练目标的“代码化”迁移。早期的代码大模型多直接借用自然语言处理领域的预训练目标(如掩码语言建模MLM)。然而,代码具有严谨的执行逻辑和特定的控制流。实验表明,引入“代码感知”的预训练任务(如标识符预测、数据流边预测、跨模态对齐)能够显著提升模型对代码深层语义的理解能力。
3. 赋能下游任务的范式转变。大模型在软件工程中的应用,本质上是AI通用能力向垂直领域的泛化。无论是代码到代码(如代码优化)、文本到代码(如需求生成代码),大模型通过“预训练+指令微调(Instruction Tuning)”或“少样本提示(Few-shot Prompting)”的范式,极大降低了针对单一任务定制化开发算法的门槛。
二、 软工任务视角:重构软件生命周期的五大阶段
如果说AI提供了智能的“大脑”,那么软件工程的各个任务则是具象的“躯干”。大模型并非仅仅是一个高级的“代码补全工具”,而是已经全面渗透到软件生命周期的五大关键阶段,覆盖了综述中统计的多达112个细分任务。

1. 需求与设计阶段:从模糊到形式化 传统需求工程高度依赖人工经验,极易产生歧义。研究表明,利用大模型可以自动实现需求分类、需求质量审查以及从自然语言到UML模型(如类图、时序图)的生成。虽然在处理极端复杂的模糊需求时仍面临挑战,但其在生成形式化软件规范(Software Specifications)方面的潜力已经得到实证。
2. 软件开发阶段:从手写到生成 这是目前大模型落地最成熟的领域。除了广为人知的代码生成与补全,大模型还在代码摘要(将代码逻辑转化为自然语言注释)、API推荐和程序综合中发挥巨大作用。实验数据指出,在提示词(Prompt)中显式加入API参数、返回类型等上下文,可以大幅提升模型在特定库中的代码生成准确率。
3. 软件测试阶段:突破覆盖率瓶颈 软件测试是人力消耗极大的环节。大模型在单元测试生成、模糊测试(Fuzzing)以及静态分析中表现优异。特别是模糊测试,传统变异策略难以触发深层逻辑漏洞,而大模型凭借强大的上下文感知能力,能够构造出高度符合特定协议或复杂API依赖的测试用例。
4. 软件维护阶段:智能修复与重构 软件维护占据了生命周期中极高的成本。大模型在自动程序修复(APR)、漏洞检测和**代码审查(Code Review)**中展现出革命性能力。以漏洞修复为例,基于指令微调的大模型能够直接通过“对话”的方式输出安全补丁,甚至超越了过去十年积累的基于规则的静态分析工具。
5. 软件管理阶段:量化洞察与效能分析 在项目管理层面,大模型开始被用于工作量估算、工具链配置及开发者行为分析。通过分析GitHub issue或开发者社区对话,大模型能敏锐提取团队的情感倾向和卡点,助力项目经理进行高效的团队健康度监控。
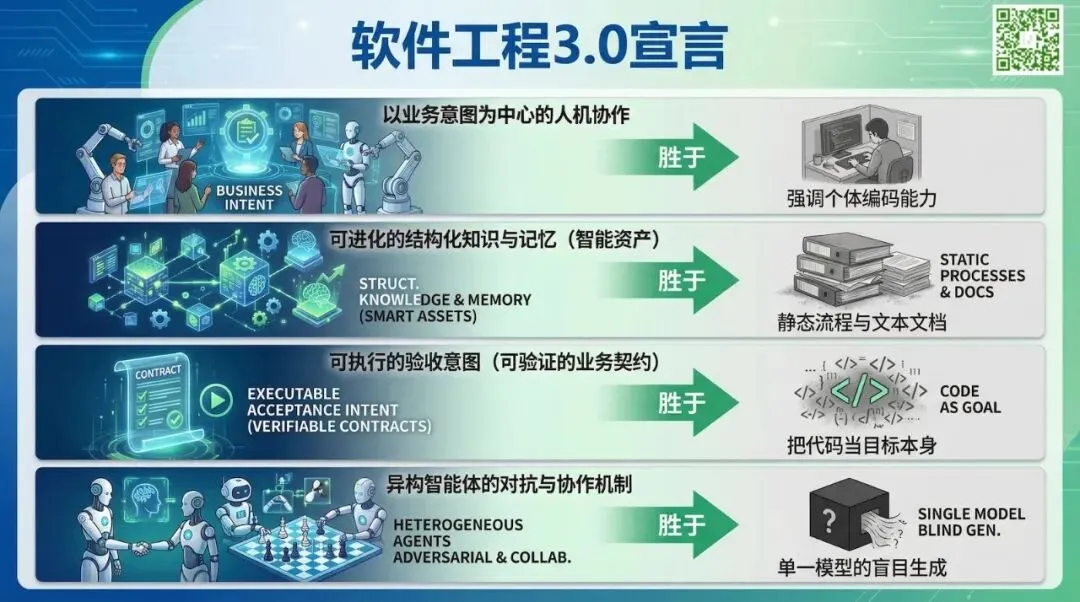
三、 AI与软件工程融合视角:“软件工程3.0”研发新范式
前文从AI的底层演进和软工作业流程分别进行了剖析,但当我们将两者深度融合——即站在“AI+软件工程”的交叉视角审视时,会发现大模型带来的绝非仅仅是局部工具的效率提升,而是整套软件研发底层逻辑的颠覆。

正如我与王千祥老师在《软件工程3.0:大模型驱动的研发新范式》一书中所指出的:软件工程正从以流程控制为核心的1.0时代、以敏捷和持续交付为特征的2.0时代,跨越式地迈入以大模型为引擎、以“模型驱动研发”为核心的3.0时代。这一得到最近几年实践验证的理论愿景,在本次综述论文汇总的广泛实验成果中,得到了完美的逻辑映射与实证确证。
1. 交互与上下文的跃迁:提示工程与RAG(即扩展为上下文工程)成为效能放大器, 大模型驱动的《软件工程3.0》强调,大模型落地的核心在于打通模型常识与企业私域知识的壁垒。论文的实验数据强有力地佐证了这一点:在代码生成和程序修复实验中,直接向大模型输入裸需求往往导致“幻觉”(Hallucination)。然而,当研究者引入检索增强生成(RAG)(例如SARGAM方法,从代码库中检索相似补丁历史作为上下文),或采用思维链(Chain-of-Thought)等多步提示工程策略时,模型的准确率获得了数量级的提升。这意味着,在新范式下,如何构建高质量的“知识外脑”和设计精准的Prompt,已成为软件工程的核心竞争力。
2. 生产关系的重塑:多智能体(Multi-Agent)协同开发。软件工程3.0指出,AI不再是死板的辅助工具,而是具有自主规划能力的“数字员工”(AI Agent),这将彻底重塑软件开发的“生产关系”。论文中总结的前沿实验(如ChatDev、AgentCoder项目)生动展现了这一新范式:在给定一个顶层需求后,“需求分析Agent”负责任务拆解,“开发Agent”负责编写代码,“测试Agent”负责运行验证并反馈错误。这种“执行引导的代码生成(Execution-guided code generation)”形成了一个自我迭代的闭环。在这种多智能体协同下,传统的人工流水线被打破,实现了研发流程的极度压缩。
3. 开发者角色的升维:从“代码编写者”到“架构审查者” 综述论文通过大量针对GitHub开源社区的实证研究(Empirical Study)发现,AI辅助生成的代码占比正在急速攀升。在人机协同的测试实验中,配备大模型助手的开发者在需求理解、UML建模和系统重构方面的耗时大幅缩减。这印证了《软件工程3.0》中关于“超级个体”的论断——在AI的赋能下,开发者将从繁重的“搬砖式”编码中解放出来,其角色将不可逆转地向着架构设计、业务逻辑把控以及AI产出物审查(Reviewer)的方向升维。
四、 大模型驱动软件工程的挑战与未来课题
尽管大模型驱动的“软件工程3.0”展现出重塑行业的巨大潜力,但本篇综述论文同样通过详实的分析指出了当前在模型部署、生态建设和安全伦理等方面面临的严峻挑战,这些挑战正是未来学术界与工业界亟需攻克的课题:
1. 模型规模与部署成本的博弈,前沿的通用大模型(如GPT-4、百亿级参数的开源模型)需要庞大的算力支撑。然而,在实际的软件研发IDE环境中,开发者对代码补全的毫秒级延迟和本地内存占用有着极高的要求。未来的研究亟需在“模型压缩、量化与知识蒸馏”方向发力。研发轻量级、低延迟的领域专属大模型(Domain-specific LLMs),将是“大模型下沉至开发者桌面”的必由之路。
2. 基准测试污染与“数据泄露”危机 随着大模型能力的提升,传统的软工评估基准正面临失效风险。综述特别指出了“数据泄露”现象:由于模型训练语料广泛抓取自开源社区,许多经典评测数据集(如用于漏洞修复的Defects4J)其实早已被模型在预训练阶段“背诵”。这导致模型在实验室中表现出虚高的“刷榜”成绩。因此,构建清洁的、动态更新的评估数据集(Clean evaluation datasets),将是保证软件工程AI研究科学性的生命线。
3. 跨越文本模态:多模态大模型的软工应用 目前的软工大模型绝大多数仍局限于“文本-代码”模态。然而,现代软件应用具有复杂的图形用户界面(GUI)。未来的突破口在于多模态大模型(Multimodal LLMs)的应用。例如在自动化UI测试中,让大模型同时“阅读”测试脚本逻辑并“观看”App界面的截图,从而实现更智能的控件识别、视觉断言和操作回放。
4. 代码的可解释性与安全性治理 大模型的“黑盒”特性使其生成的代码可能隐藏难以察觉的漏洞,甚至受到数据投毒(Data Poisoning)攻击生成恶意后门。在金融、医疗等安全攸关领域,这是不可接受的。未来的课题必须打破黑盒,将传统基于严谨数理逻辑的静态分析技术、符号执行技术与大模型相融合,构建可信赖的“神经-符号(Neuro-symbolic)”软件工程安全保障框架。
结语
从代码片段的智能补全,到多智能体协作完成全生命周期开发,A survey on large language models for software engineering以宏大的视角和丰富的数据,为我们全景式地描绘了AI赋能软件工程的壮丽图景。
我们可以清晰地看到:大模型带来的绝非仅仅是一批好用的辅助工具,而是一场深刻的研发生产力革命。在AI与软件工程深度融合的今天,AI正逐步成为深谙业务逻辑的“研发合伙人”。尽管前路仍有模型部署成本、评测污染、安全治理等重重挑战,但大模型驱动下的研发新范式,必将推动软件行业向着更高智能、更高质量、十倍效能的新时代(软件工程3.0时代)加速迈进。