

































































文档内容
软件工程
第1章 软件工程技术发展思索...........................................................................................................2
1.1 软件工程技术发展历程...........................................................................................................2
1.2 软件与软件特征.......................................................................................................................3
1.3 软件工程的主要研究内容.......................................................................................................3
1.4 软件技术的发展趋势...............................................................................................................7
第2章 传统的软件工程过程...............................................................................................................8
2.1 什么是软件生命周期...............................................................................................................8
2.2 软件生命周期的六个阶段......................................................................................................9
2.3 软件生命周期的模型............................................................................................................10
第3章 软件工程之面向对象技术概述................................................................................................12
第4章 面向对象软件工程方法学实践.............................................................................................14
4.1 是“设计主导”还是“程序主导”...........................................................................................14
4.2 面向对象方法与结构化方法比较.........................................................................................17
4.3 方法学是思路不是定律.........................................................................................................18
第5章 中间件技术................................................................................................................................19
第6章 JAVA EE 技术软件工程专题............................................................................................21
6.1 企业级 JAVA...........................................................................................................................21
6.2 J2EE 简介...............................................................................................................................22
6.2.1 J2EE的概念.......................................................................................................................23
6.2.2 J2EE 的四层模型...............................................................................................................24
6.2.3 J2EE 的结构.......................................................................................................................26
6.3 JAVA EE 5................................................................................................................................28
6.4 J2EE 探险者系列...................................................................................................................29
6.5 J2EE 最佳实践.......................................................................................................................30
6.6 J2EE 与 SOA.........................................................................................................................31
6.7 J2EE 与 WEB 2.0...................................................................................................................31
6.8 STRUTS VS SPRING 两种MVC框架比较....................................................................................33
第7章 面向方面编程AOP...............................................................................................................35
7.1 引言.........................................................................................................................................35
7.2 什么是方面.............................................................................................................................36
7.3 AOP:利与弊.........................................................................................................................37
7.4 SPRING AOP: SPRING之面向方面编程.................................................................................37
第8章 基于组件的软件工程-软件开发新挑战...............................................................................40
8.1 软件开发面临的挑战.............................................................................................................40
8.2 基于组件的开发中有几个危及其成功的不利因素.............................................................40
8.3 基于组件的软件工程.............................................................................................................41
8.4 组件规范.................................................................................................................................418.5 基于组件系统开发生命周期.................................................................................................42
8.6 软件体系和基于组件的开发.................................................................................................43
8.7 UML和基于组件的系统模型...............................................................................................44
8.8 CORBA与DCOM技术........................................................................................................44
8.8.1 分布式对象技术....................................................................................................................44
8.8.2 CORBA的设计模式.............................................................................................................46
8.8.3 DCOM技术........................................................................................................................50
8.8.4 CORBA与DCOM的主要异同.............................................................................................53
8.9 基于组件软件工程的未来.....................................................................................................55
第9章 软件测试新技术.....................................................................................................................56
9.1 正交试验设计.........................................................................................................................56
9.2 均匀试验设计.........................................................................................................................57
9.3 成对组合覆盖.........................................................................................................................57
9.4 软件测试的有效方法—确定软件测试技术.........................................................................58
9.6 软件测试自动化框架.............................................................................................................61
第10软件工程新视角............................................................................................................................63
10.1 业发展:SOA与云计算相结合............................................................................................63
10.2 AGILE SOFTWARE DEVELOPMENT(敏捷软件开发)...........................................................63
10.3 极限编程.................................................................................................................................65
10.4 可信软件.................................................................................................................................71
第 1 章 软件工程技术发展思索
1.1 软件工程技术发展历程
30多年来,软件工程的研究和实践取得了长足的进步,其中一些具有里程碑意义的进展
包括:
• 20世纪60年代末~70年代中期,在一系列高级语言应用的基础上,出现了结构化程序设
计技术,并开发了一些支持软件开发的工具.
• 20世纪70年代中期~80年代,计算机辅助软件工程(CASE)成为研究热点,并开发了一些
对软件技术发展具有深远影响的软件工程环境.
• 20世纪80年代中期~90年代,出现了面向对象语言和方法,并成为主流的软件开发技术;
开展软件过程及软件过程改善的研究;注重软件复用和软件构件技术的研究与实践.
软件是客观事物的一种反映,客观世界的不断变化促使软件技术的不断发展,这种事物发展
规律促使软件工程的产生和发展.我们仅从解决软硬件的异构性和各种软件之间的异构性角
度,就可窥见软件技术发展的一种途径.如,为屏蔽计算机硬件之间的异构性发展了操作系统,
为屏蔽操作系统之间和编程语言之间的异构性出现了支撑软件和中间件,为屏蔽不同中间件
之间的异构性发展了Web Services技术等等;随着解决问题的不断深入,易用性和适应性要求的不断提升,以及软件技术的不断发展,还会出现更新、更复杂的异构问题,它的解决会促
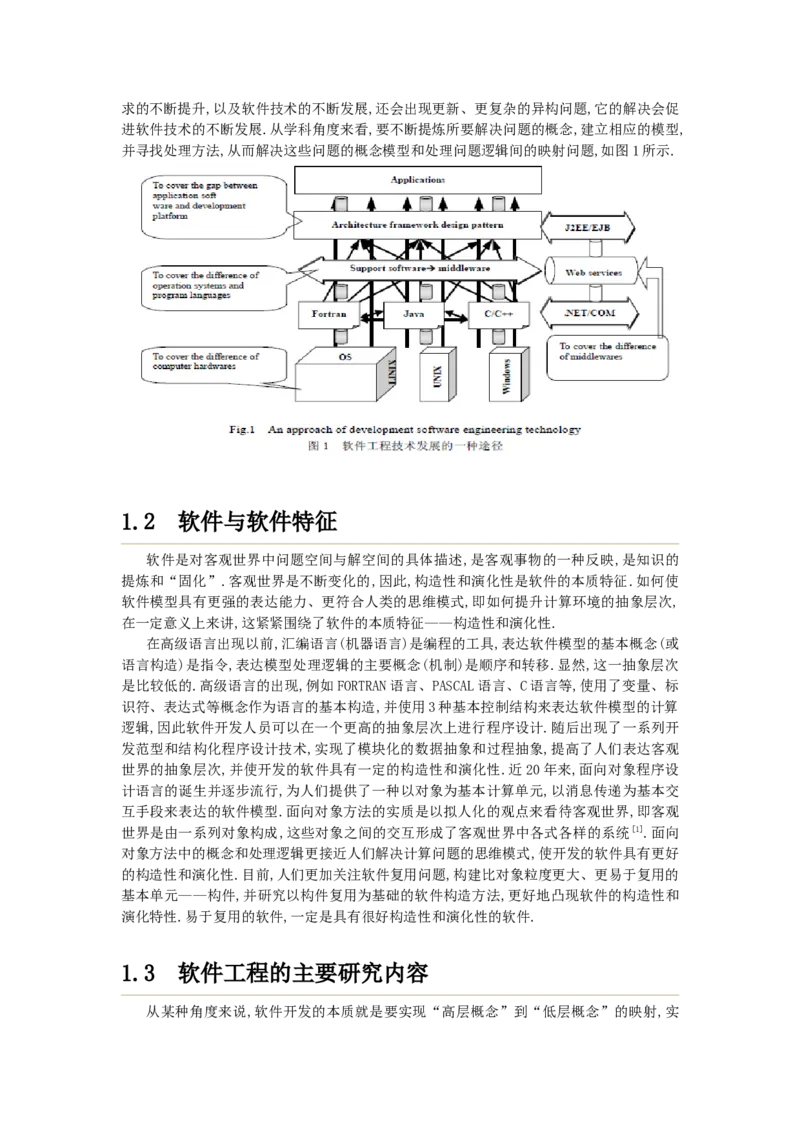
进软件技术的不断发展.从学科角度来看,要不断提炼所要解决问题的概念,建立相应的模型,
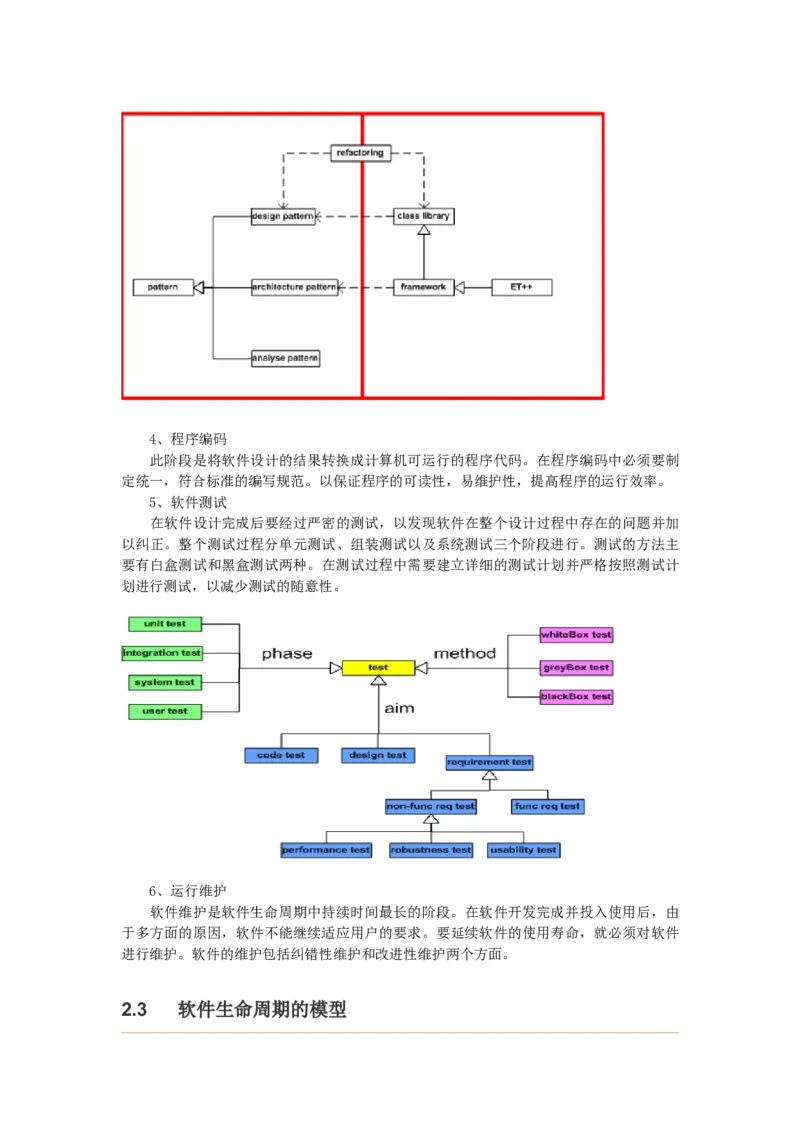
并寻找处理方法,从而解决这些问题的概念模型和处理问题逻辑间的映射问题,如图1所示.
1.2 软件与软件特征
软件是对客观世界中问题空间与解空间的具体描述,是客观事物的一种反映,是知识的
提炼和“固化”.客观世界是不断变化的,因此,构造性和演化性是软件的本质特征.如何使
软件模型具有更强的表达能力、更符合人类的思维模式,即如何提升计算环境的抽象层次,
在一定意义上来讲,这紧紧围绕了软件的本质特征——构造性和演化性.
在高级语言出现以前,汇编语言(机器语言)是编程的工具,表达软件模型的基本概念(或
语言构造)是指令,表达模型处理逻辑的主要概念(机制)是顺序和转移.显然,这一抽象层次
是比较低的.高级语言的出现,例如FORTRAN语言、PASCAL语言、C语言等,使用了变量、标
识符、表达式等概念作为语言的基本构造,并使用3种基本控制结构来表达软件模型的计算
逻辑,因此软件开发人员可以在一个更高的抽象层次上进行程序设计.随后出现了一系列开
发范型和结构化程序设计技术,实现了模块化的数据抽象和过程抽象,提高了人们表达客观
世界的抽象层次,并使开发的软件具有一定的构造性和演化性.近20年来,面向对象程序设
计语言的诞生并逐步流行,为人们提供了一种以对象为基本计算单元,以消息传递为基本交
互手段来表达的软件模型.面向对象方法的实质是以拟人化的观点来看待客观世界,即客观
世界是由一系列对象构成,这些对象之间的交互形成了客观世界中各式各样的系统[1].面向
对象方法中的概念和处理逻辑更接近人们解决计算问题的思维模式,使开发的软件具有更好
的构造性和演化性.目前,人们更加关注软件复用问题,构建比对象粒度更大、更易于复用的
基本单元——构件,并研究以构件复用为基础的软件构造方法,更好地凸现软件的构造性和
演化特性.易于复用的软件,一定是具有很好构造性和演化性的软件.
1.3 软件工程的主要研究内容
从某种角度来说,软件开发的本质就是要实现“高层概念”到“低层概念”的映射,实现“高层处理逻辑”到“低层处理逻辑”的映射.对于大型软件系统的开发,这一映射是相
当复杂的,涉及到有关人员、使用的技术、采取的途径以及成本和进度的约束,因此,我们可
以把软件工程定义为:
软件工程(software engineering)是应用计算机科学理论和技术以及工程管理原则和
方法,按照预算和进度,实现满足用户要求的软件产品的定义、开发、发布和维护的工程或
以之为研究对象的学科,软件工程与其他工程一样要有自己的目标、活动和原则,软件工程
框架可以概括为图2所示的内容.
软件工程的基本目标是生产具有正确性、可用性及开销合宜(合算性)的产品.正确性意
指软件产品达到预期功能的程度;可用性意指软件基本结构、实现及文档达到用户可用的程
度;开销合宜意指软件开发、运行的整个开销满足用户的需求.以上目标的实现不论在理论
上还是在实践中均存在很多问题有待解决,制约了对过程、过程模型及工程方法的选取.
软件工程活动是“生产一个最终满足用户需求且达到工程目标的软件产品所需要的步
骤”,主要包括需求、设计、实现、确认以及支持等活动.需求活动是在一个抽象层上建立
系统模型的活动,该活动的主要产品是需求规约,是软件开发人员和客户之间契约的基础,是
设计的基本输入.设计活动定义实现需求规约所需的结构,该活动的主要产品包括软件体系
结构、详细的处理算法等.实现活动是设计规约到代码转换的活动.验证/确认是一项评估活
动,贯穿于整个开发过程,包括动态分析和静态分析.主要技术有模型评审、代码“走查”以
及程序测试等.维护活动是软件发布之后所进行的修改,包括对发现错误的修正、对环境变
化所进行的必要调整等.
围绕工程设计、工程支持以及工程管理,提出以下软件工程基本原则:
第1条原则是选取适宜的开发风范.以保证软件开发的可持续性,并使最终的软件产品满
足客户的要求.
第2条原则是采用合适的设计方法.支持模块化、信息隐蔽、局部化、一致性、适应性、
构造性、集成组装性等问题的解决和实现,以达到软件工程的目标.
第3条原则是提供高质量的工程支持.提供必要的工程支持,例如配置管理、质量保证等
工具和环境,以保证按期交付高质量的软件产品.
第4条原则是有效的软件工程管理.仅当对软件过程实施有效管理时,才能实现有效的软
件工程.
由以上软件工程的概念和框架可以看出,软件设计的主要目标就是要实现好的结构,使
开发的软件具有良好的构造性和演化性.软件工程学科所研究的内容主要包括:软件开发范
型、软件设计方法、工程支持技术和工程管理技术.其中,软件开发范型涉及软件工程的
“方向”问题,研究正确的求解软件的计算逻辑;软件设计方法涉及软件工程的“途径”问
题,研究“高层概念模型和处理逻辑”到“低层概念模型和处理逻辑”的映射;工程支持技术和过程管理技术涉及工程过程质量和产品质量问题,研究管理学理论在软件工程中的应用.
如上所述,软件开发就是实施了一个从“高层概念模型”到“低层概念模型”的映射,从
“高层处理逻辑”到“低层处理逻辑”的映射,而且在这一映射中还涉及到人员、技术、成
本、进度等要素,那么就必须研究映射模式即软件生产模式
问题.
分析传统产业的发展,其基本模式均是符合标准的零部件(构件)生产以及基于标准构件
的产品生产(组装),其中,构件是核心和基础,“复用”是必须的手段.实践表明,这种模式是
软件开发工程化、软件生产工业化的必由之路[4].因此,软件产业的发展并形成规模经济,标
准构件的生产和构件的复用是关键因素.
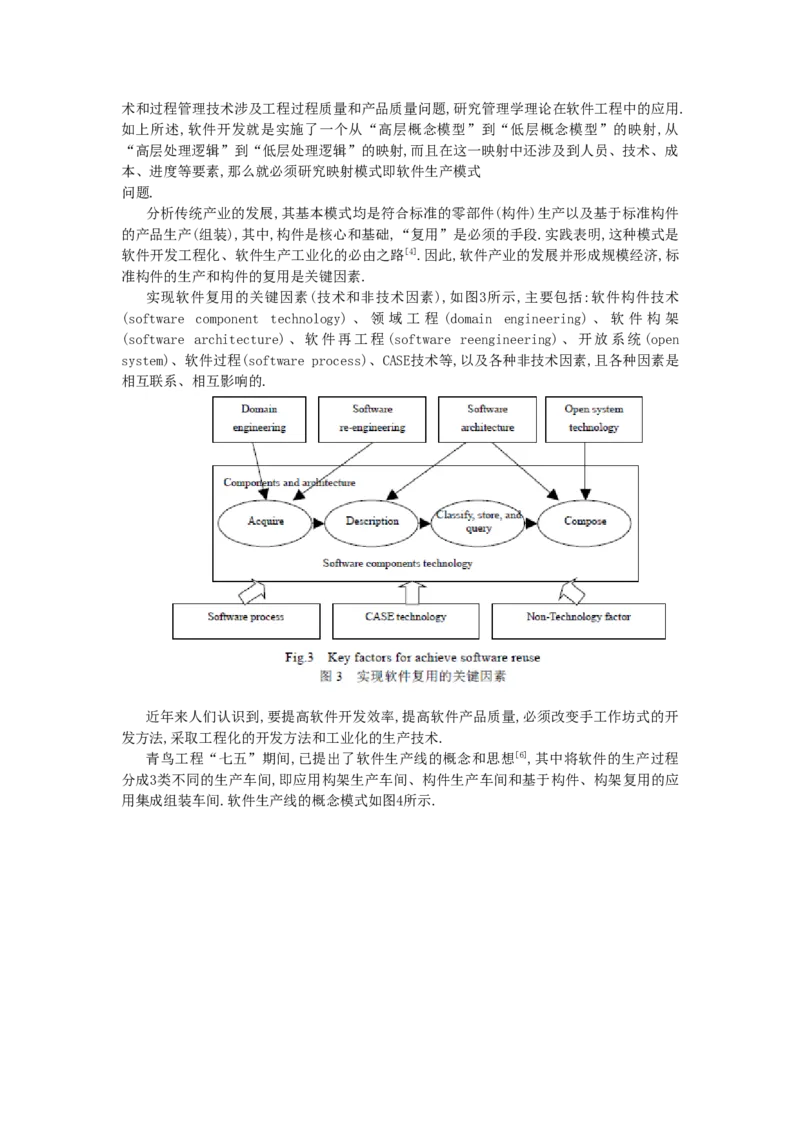
实现软件复用的关键因素(技术和非技术因素),如图3所示,主要包括:软件构件技术
(software component technology) 、领域 工程 (domain engineering) 、软件构架
(software architecture)、软件再工程(software reengineering)、开放系统(open
system)、软件过程(software process)、CASE技术等,以及各种非技术因素,且各种因素是
相互联系、相互影响的.
近年来人们认识到,要提高软件开发效率,提高软件产品质量,必须改变手工作坊式的开
发方法,采取工程化的开发方法和工业化的生产技术.
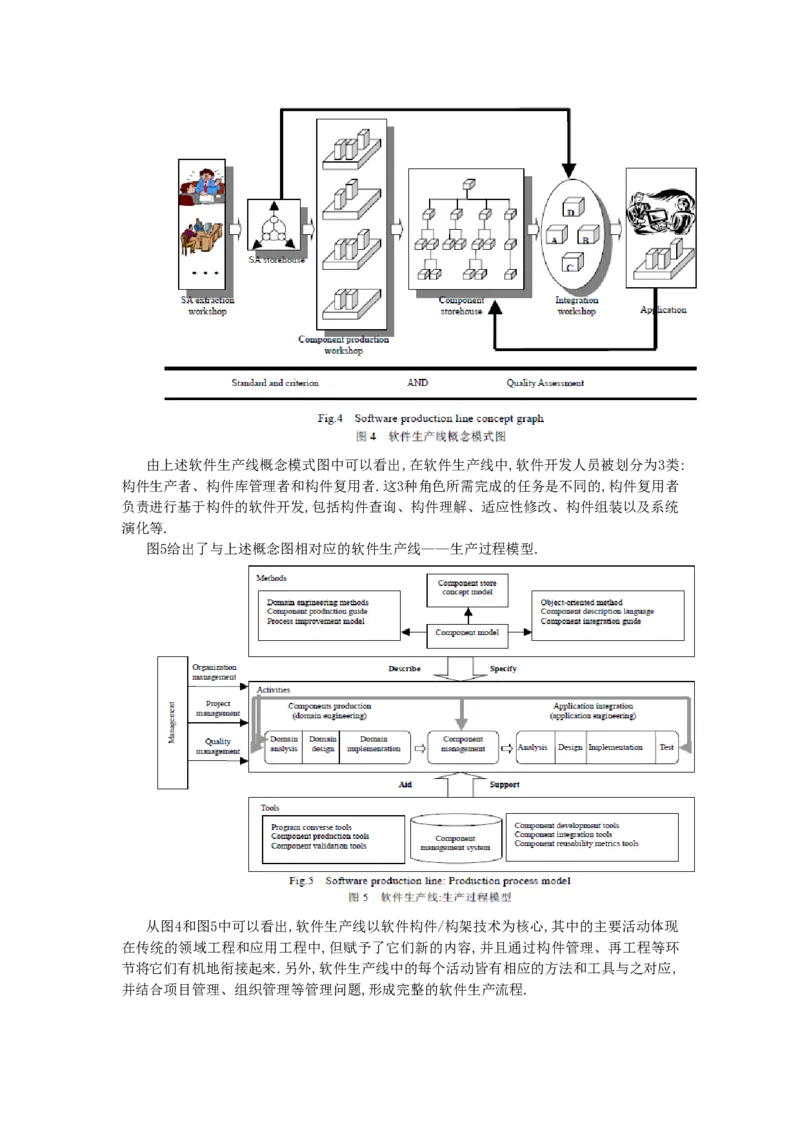
青鸟工程“七五”期间,已提出了软件生产线的概念和思想[6],其中将软件的生产过程
分成3类不同的生产车间,即应用构架生产车间、构件生产车间和基于构件、构架复用的应
用集成组装车间.软件生产线的概念模式如图4所示.由上述软件生产线概念模式图中可以看出,在软件生产线中,软件开发人员被划分为3类:
构件生产者、构件库管理者和构件复用者.这3种角色所需完成的任务是不同的,构件复用者
负责进行基于构件的软件开发,包括构件查询、构件理解、适应性修改、构件组装以及系统
演化等.
图5给出了与上述概念图相对应的软件生产线——生产过程模型.
从图4和图5中可以看出,软件生产线以软件构件/构架技术为核心,其中的主要活动体现
在传统的领域工程和应用工程中,但赋予了它们新的内容,并且通过构件管理、再工程等环
节将它们有机地衔接起来.另外,软件生产线中的每个活动皆有相应的方法和工具与之对应,
并结合项目管理、组织管理等管理问题,形成完整的软件生产流程.1.4 软件技术的发展趋势
Internet无疑是20世纪末伟大的技术进展之一,为我们提供了一种全球范围的信息基础
设施.这个不断延伸的网络基础设施,形成了一个资源丰富的计算平台,构成了人类社会的信
息化、数字化基础,成为我们学习、生活和工作的必备环境.如何在未来Internet平台上进
一步进行资源整合,形成巨型的、高效的、可信的和统一的虚拟环境,使所有资源能够高效、
可信地为所有用户服务,成为软件技术的研究热点.
Internet平台具有如下基本特征:无统一控制的“真”分布性;节点的高度自治性;节点
链接的开放性和动态性;人、设备和软件的多重异构性;实体行为的不可预测性;运行环境的
潜在不安全性;使用方式的个性化和灵活性;网络连接环境的多样性等.因此,Internet平台
和环境的出现,对软件形态、技术发展、理论研究提出新的问题,也提供了新的契机.
传统软件的开发基于封闭的静态平台,是自顶向下、逐步分解的过程,因此传统软件的
开发,基本都是首先确定系统的范围(即Scoping),然后实施分而治之的策略,整个开发过程
处于有序控制之下.而未来软件系统的开发所基于的平台是一个有丰富基础软件资源但同时
又是开放、动态和多变的框架,开发活动呈现为通过基础软件资源组合为基本系统,然后经
历由“无序”到“有序”的往复循环过程,是动态目标渐趋稳态.未来软件基本模型由于所
处平台的特性和开放应用的需求而变得比任何传统的计算模型都更为复杂,软件生命周期由
于“无序”到“有序”的循环而呈现出不同于传统生命周期概念的“大生命周期概念”,程
序正确性由于目标的多样化而表现为传统正确性描述的一个偏序集,软件体系结构侧重点从
基于实体的结构分解转变为基于协同的实体聚合,软件生产过程和环境的变化导致基于
Internet的面向用户的虚拟工厂的形成.
由于软件系统所基于的计算机硬件平台正经历从集中封闭的计算平台向开放的
Internet平台的转变,软件系统作为计算机系统的核心,随着其运行环境的演变也经历了一
系列的变革.目前,面向网络的计算环境正由Client/Server发展为Client/Cluster,并正朝
着Client/Network和Client/Virtual Environment的方向发展.那么,未来的基于Internet
平台的软件系统又将会呈现出一个什么形态呢?
从技术的角度来看,以软件构件等技术支持的软件实体将以开放、自主的方式存在于
Internet的各个节点之上,任何一个软件实体可在开放的环境下通过某种方式加以发布,并
以各种协同方式与其他软件实体进行跨网络的互连、互通、协作和联盟,从而形成一种与当
前的信息Web类似的Software Web. Software Web不再仅仅是信息的提供者,它还是各种服
务(功能)的提供者.由于网络环境的开放与动态性,以及用户使用方式的个性化要求,从而决
定了这样一种Software Web,它应能感知外部网络环境的动态变化,并随着这种变化按照功
能指标、性能指标和可信性指标等进行静态的调整和动态的演化,以使系统具有尽可能高的
用户信赖度.我们将具有这种新形态的软件称为网构软件(internetware).
网构软件是在Internet开放、动态和多变环境下软件系统基本形形态的独有的基本特征[1]:
(1) 自主性:是指网构软件系统中的软件实体具有相对独立性、主动性和自适应性.自
主性使其区别于传统软件系统中软件实体的依赖性和被动性;
(2) 协同性:是指网构软件系统中软件实体之间可按多种静态连接和动态合作方式在开
放的网络环境下加以互连、互通、协作和联盟.协同性使其区别于传统软件系统在封闭集中
环境下单一静态的连接模式;
(3) 反应性:是指网构软件具有感知外部运行和使用环境并对系统演化提供有用信息的
能力.反应性使网构软件系统具备了适应Internet开放、动态和多变环境的感知能力;
(4) 演化性:是指网构软件结构可以根据应用需求和网络环境变化而发生动态演化,主
要表现在其实体元素数目的可变性、结构关系的可调节性和结构形态的动态可配置性上;演化性使网构软件系统具备了适应Internet开放、动态和多变环境的应变能力;
(5) 多态性:是指网构软件系统的效果体现出相容的多目标性.它可以根据某些基本协
同原则,在动态变化的网络环境下,满足多种相容的目标形态.多态性使网构软件系统在网络
环境下具备了一定的柔性和满足个性化需求的能力.
综上所述,Internet及其上应用的快速发展与普及,使计算机软件所面临的环境开始从
静态封闭逐步走向开放、动态和多变.软件系统为了适应这样一种发展趋势,将会逐步呈现
出柔性、多目标、连续反应式的网构软件系统的形态.面对这种新型的软件形态,传统的软
件理论、方法、技术和平台面临了一系列挑战.从宏观上看,这种挑战为我们研究软件理论、
方法和技术提供了难得的机遇,使我们有可能建立一套适合于Internet开放、动态和多变环
境的新型软件理论、方法和技术体系.从微观的角度来看,Internet的发展将使系统软件和
支撑平台的研究重点开始从操作系统等转向新型中间件平台,而网构软件的理论、方法和技
术的突破必将导致在建立新型中间件平台创新技术方面的突破.
归结起来,网构软件理论、方法、技术和平台的主要突破点在于实现如下转变,即,从传
统软件结构到网构软件结构的转变,从系统目标的确定性到多重不确定性的转变,从实体单
元的被动性到主动自主性的转变,从协同方式的单一性到灵活多变性的转变,从系统演化的
静态性到系统演化的动态性的转变,从基于实体的结构分解到基于协同的实体聚合的转变,
从经验驱动的软件手工开发模式到知识驱动的软件自动生成模式的转变.建立这样一种新型
的理论、方法、技术和平台体系具有两个方面的重要性,一方面,从计算机软件技术发展的
角度,这种新型的理论、方法和技术将成为面向Internet计算环境的一套先进的软件工程方
法学体系,为21世纪计算机软件的发展构造理论基础;另一方面,这种基于Internet计算环境
上软件的核心理论、方法和技术,必将为我国在未来5~10年建立面向Internet的软件产业打
下坚实的基础,为我国软件产业的跨越式发展提供核心技术的支持.
当前的软件技术发展遵循软硬结合、应用与系统结合的发展规律.“软”是指件,
“硬”是指微电子,要发展面向应用,实现一体化;面向个人,体现个性化的系统和产品.软件
技术的总体发展趋势可归结为:软件平台网络化、方法对象化、系统构件化、产品家族化、
开发工程化、过程规范化、生产规模化、竞争国际化.
第 2 章 传统的软件工程过程
2.1 什么是软件生命周期
软件生命周期又称为软件生存周期或系统开发生命周期,是软件的产生直到报废的生
命周期,周期内有问题定义、可行性分析、总体描述、系统设计、编码、调试和测试、验
收与运行、维护升级到废弃等阶段,这种按时间分程的思想方法是软件工程中的一种思想
原则,即按部就班、逐步推进,每个阶段都要有定义、工作、审查、形成文档以供交流或
备查,以提高软件的质量。但随着新的面向对象的设计方法和技术的成熟,软件生命周期
设计方法的指导意义正在逐步减少。生命周期的每一个周期都有确定的任务,并产生一定规格的文档(资料),提交给下
一个周期作为继续工作的依据。按照软件的生命周期,软件的开发不再只单单强调“编
码”,而是概括了软件开发的全过程。软件工程要求每一周期工作的开始只能必须是建立
在前一个周期结果“正确”前提上的延续;因此,每一周期都是按“活动 ── 结果 ──
审核 ── 再活动 ── 直至结果正确”循环往复进展的。
2.2 软件生命周期的六个阶段
1、问题的定义及规划
此阶段是软件开发方与需求方共同讨论,主要确定软件的开发目标及其可行性。
2、需求分析
在确定软件开发可行的情况下,对软件需要实现的各个功能进行详细分析。需求分析
阶段是一个很重要的阶段,这一阶段做得好,将为整个软件开发项目的成功打下良好的基
础。"唯一不变的是变化本身。",同样需求也是在整个软件开发过程中不断变化和深入的,
因此我们必须制定需求变更计划来应付这种变化,以保护整个项目的顺利进行。
3、软件设计
此阶段主要根据需求分析的结果,对整个软件系统进行设计,如系统框架设计,数据
库设计等等。软件设计一般分为总体设计和详细设计。好的软件设计将为软件程序编写打
下良好的基础。4、程序编码
此阶段是将软件设计的结果转换成计算机可运行的程序代码。在程序编码中必须要制
定统一,符合标准的编写规范。以保证程序的可读性,易维护性,提高程序的运行效率。
5、软件测试
在软件设计完成后要经过严密的测试,以发现软件在整个设计过程中存在的问题并加
以纠正。整个测试过程分单元测试、组装测试以及系统测试三个阶段进行。测试的方法主
要有白盒测试和黑盒测试两种。在测试过程中需要建立详细的测试计划并严格按照测试计
划进行测试,以减少测试的随意性。
6、运行维护
软件维护是软件生命周期中持续时间最长的阶段。在软件开发完成并投入使用后,由
于多方面的原因,软件不能继续适应用户的要求。要延续软件的使用寿命,就必须对软件
进行维护。软件的维护包括纠错性维护和改进性维护两个方面。
2.3 软件生命周期的模型任何软件都是从最模糊的概念开始的:为某个公司设计办公的流程处理;设计一种商
务信函打印系统并投放市场。这个概念是不清晰的,但却是最高层的业务需求的原型。这
个概念都会伴随着一个目的,例如在一个“银行押汇系统”的目的是提高工作的效率。这
个目的将会成为系统的核心思想,系统成败的评判标准。1999年政府部门上了大量的OA
系统(办公自动化系统),学过一点Lotus Notes(Lotus Notes是功能强大的多界面的
Windows 软件,它使人们能高效地协同工作。使用Notes 人们可以突破平台技术组织和地
理的限制,Lotus Notes非常好用,通常要由许多应用程序来完成的任务,用Notes一次
即可完成。)的人都发了财(IBM更不用说了),但是更普遍的情况是,许多的政府部门
原有的处理模式并没有变化,反而又加上了自动化处理的一套流程。提高工作效率的初衷
却导致了完全不同的结果。这样的软件究竟是不是成功的呢?
从概念提出的那一刻开始,软件产品就进入了软件生命周期。在经历需求、分析、设
计、实现、部署后,软件将被使用并进入维护阶段,直到最后由于缺少维护费用而逐渐消
亡。这样的一个过程,称为“生命周期模型”(Life Cycle Model)。
典型的几种生命周期模型包括瀑布模型、快速原型模型、迭代模型。瀑布模型
(Waterfall Model)首先由温斯顿·罗伊斯(Winston Royce)提出。该模型由于酷似瀑
布闻名。在该模型中,首先确定需求,并接受客户和软件质量保证(SQA)小组的验证。然
后拟定规格说明,同样通过验证后,进入计划阶段…可以看出,瀑布模型中至关重要的一
点是只有当一个阶段的文档已经编制好并获得软件质量保证小组的认可才可以进入下一个
阶段。这样,瀑布模型通过强制性的要求提供规约文档来确保每个阶段都能很好的完成任
务。但是实际上往往难以办到,因为整个的模型几乎都是以文档驱动的,这对于非专业的
用户来说是难以阅读和理解的。想象一下,你去买衣服的时候,售货员给你出示的是一本
厚厚的服装规格说明,你会有什么样的感触。虽然瀑布模型有很多很好的思想可以借鉴,
但是在过程能力上有天生的缺陷。
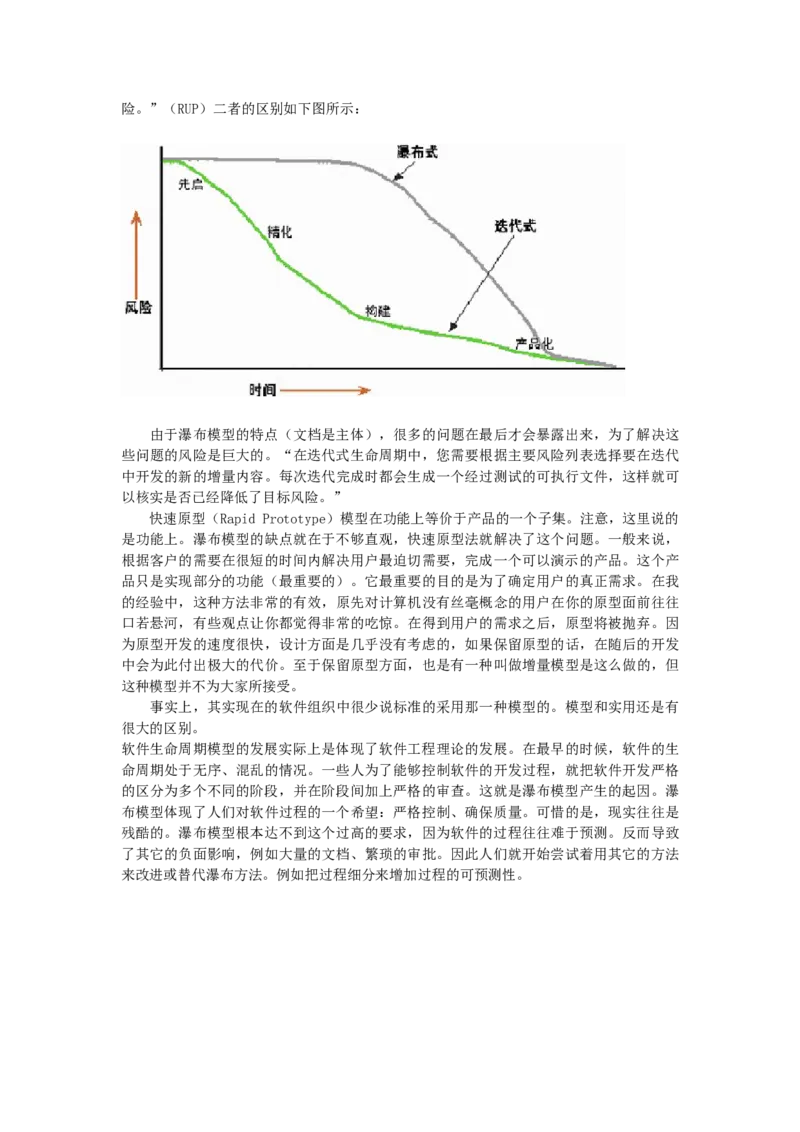
迭代式模型是RUP(Rational Unified Process,统一软件开发过程,统一软件过程)
推荐的周期模型。在RUP中,迭代被定义为:迭代包括产生产品发布(稳定、可执行的产
品版本)的全部开发活动和要使用该发布必需的所有其他外围元素。所以,在某种程度上
开发迭代是一次完整地经过所有工作流程的过程:(至少包括)需求工作流程、分析设计
工作流程、实施工作流程和测试工作流程。实质上,它类似小型的瀑布式项目。RUP认为,
所有的阶段(需求及其它)都可以细分为迭代。每一次的迭代都会产生一个可以发布的产
品,这个产品是最终产品的一个子集。迭代的思想如下图所示。
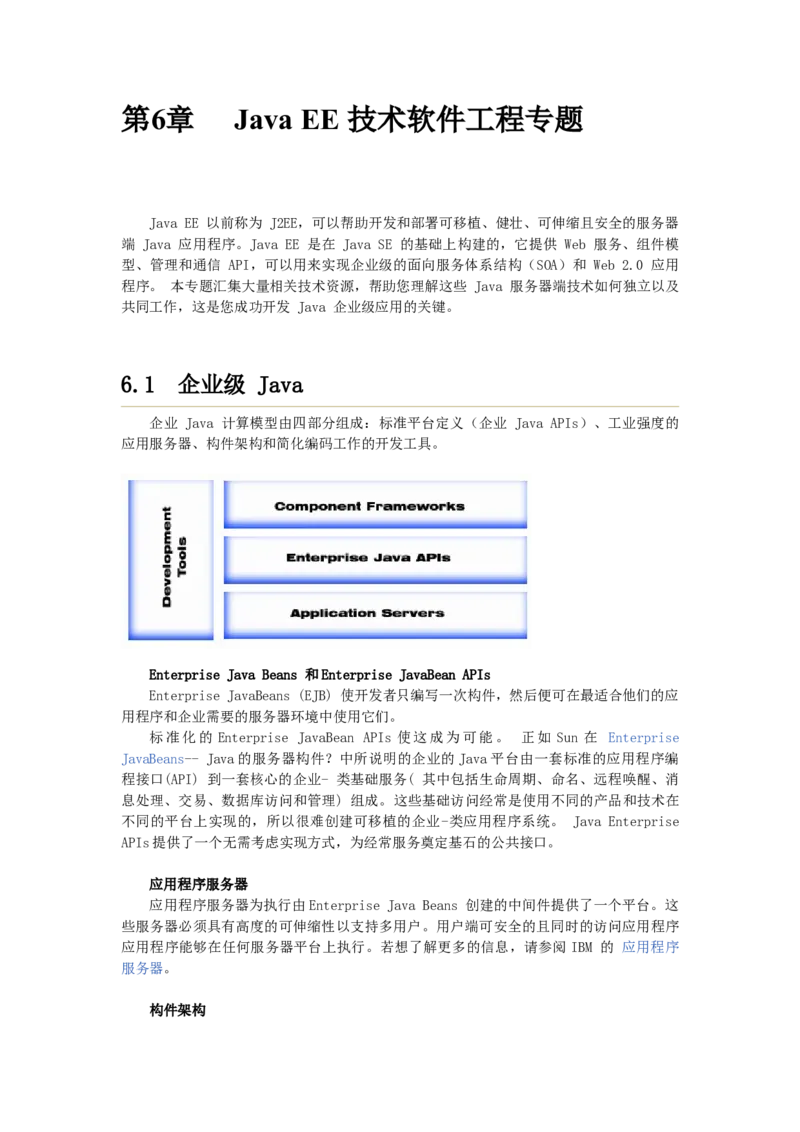
迭代和瀑布的最大的差别就在于风险的暴露时间上。“任何项目都会涉及到一定的风
险。如果能在生命周期中尽早确保避免了风险,那么您的计划自然会更趋精确。有许多风
险直到已准备集成系统时才被发现。不管开发团队经验如何,都绝不可能预知所有的风险。”(RUP)二者的区别如下图所示:
由于瀑布模型的特点(文档是主体),很多的问题在最后才会暴露出来,为了解决这
些问题的风险是巨大的。“在迭代式生命周期中,您需要根据主要风险列表选择要在迭代
中开发的新的增量内容。每次迭代完成时都会生成一个经过测试的可执行文件,这样就可
以核实是否已经降低了目标风险。”
快速原型(Rapid Prototype)模型在功能上等价于产品的一个子集。注意,这里说的
是功能上。瀑布模型的缺点就在于不够直观,快速原型法就解决了这个问题。一般来说,
根据客户的需要在很短的时间内解决用户最迫切需要,完成一个可以演示的产品。这个产
品只是实现部分的功能(最重要的)。它最重要的目的是为了确定用户的真正需求。在我
的经验中,这种方法非常的有效,原先对计算机没有丝毫概念的用户在你的原型面前往往
口若悬河,有些观点让你都觉得非常的吃惊。在得到用户的需求之后,原型将被抛弃。因
为原型开发的速度很快,设计方面是几乎没有考虑的,如果保留原型的话,在随后的开发
中会为此付出极大的代价。至于保留原型方面,也是有一种叫做增量模型是这么做的,但
这种模型并不为大家所接受。
事实上,其实现在的软件组织中很少说标准的采用那一种模型的。模型和实用还是有
很大的区别。
软件生命周期模型的发展实际上是体现了软件工程理论的发展。在最早的时候,软件的生
命周期处于无序、混乱的情况。一些人为了能够控制软件的开发过程,就把软件开发严格
的区分为多个不同的阶段,并在阶段间加上严格的审查。这就是瀑布模型产生的起因。瀑
布模型体现了人们对软件过程的一个希望:严格控制、确保质量。可惜的是,现实往往是
残酷的。瀑布模型根本达不到这个过高的要求,因为软件的过程往往难于预测。反而导致
了其它的负面影响,例如大量的文档、繁琐的审批。因此人们就开始尝试着用其它的方法
来改进或替代瀑布方法。例如把过程细分来增加过程的可预测性。第 3 章 软件工程之面向对象技术概述
八十年代末以来,随着面向对象技术成为研究的热点出现了几十种支持软件开 发的
面向对象方法。其中,Booch, Coad/Yourdon,OMT和Jacobson的方法在面向对象软件开
发界得到了广泛的认可,特别值得一提的是统一建模语言UML (Unified Modeling La
nguage),该方法结合了Booch, OMT, 和Jacobson方法 的优点,统一了符号体系,
并从其它的方法和工程实践中吸收了许多经过实际检验 的概念和技术。UML方法自去年
提出后到现在已发展到1.1版,并已提交给对象管 理集团OMG,申请成为面向对象方法
的标准。
面向对象方法都支持三种基本的活动:识别对象和类,描述对象和类之间的关 系,
以及通过描述每个类的功能定义对象的行为。
为了发现对象和类,开发人员要在系统需求和系统分析的文档中查找名词和名 词短
语,包括可感知的事物(汽车、压力、传感器);角色(母亲、教师、政治 家);事件
(着陆、中断、请求);互相作用(借贷、开会、交叉);人员;场所;组织;设备;和
地点。通过浏览使用系统的脚本发现重要的对象和其责任,是 面向对象分析和设计过程
的初期重要的技术。
当重要的对象被发现后,通过一组互相关联的模型详细表示类之间的关系和对 象的
行为,这些模型从四个不同的侧面表示了软件的体系结构:静态逻辑、动态逻 辑、静态
物理和动态物理。
静态逻辑模型描述实例化(类成员关系)、关联、聚集(整体/部分)、和一 般化
(继承)等关系。这被称为对象模型。一般化关系表示属性和方法的继承关 系。定义对
象模型的图形符号体系通常是从用于数据建模的实体关系图导出的。对设计十分重要的约
束,如基数(一对一、一对多、多对多),也在对象模型中表 示。
动态逻辑模型描述对象之间的互相作用。互相作用通过一组协同的对象,对象 之间
消息的有序的序列,参与对象的可见性定义,来定义系统运行时的行为。
Booch方法中的对象交互作用图被用来描述重要的互相作用,显示参与的对象和对
象之间按时间排序的消息。可见性图用来描述互相作用中对象的可见性。对象的可 见性
定义了一个对象如何处于向它发送消息的方法的作用域之中。例如,它可以是 方法的参
数、局部变量、新的对象、或当前执行方法的对象的部分。
静态物理模型通过模块描述代码的布局。动态物理模型描述软件的进程和线程 体系
结构。
八十年代末以来,随着面向对象技术成为研究的热点出现了几十种支持软件开 发的
面向对象方法。其中,Booch, Coad/Yourdon, OMT, 和Jacobson的方法在面 向对象
软件开发界得到了广泛的认可。特别值得一提的是统一的建模语言UML (Unified Mode
ling Language),该方法结合了Booch, OMT, 和Jacobson方法 的优点,统一了符
号体系,并从其它的方法和工程实践中吸收了许多经过实际检验 的概念和技术。UML方
法自去年提出后到现在已发展到1.1版,并已提交给对象管 理集团OMG,申请成为面向
对象方法的标准。
面向对象方法都支持三种基本的活动:识别对象和类,描述对象和类之间的关 系,
以及通过描述每个类的功能定义对象的行为。
为了发现对象和类,开发人员要在系统需求和系统分析的文档中查找名词和名 词短语,包括可感知的事物(汽车、压力、传感器);角色(母亲、教师、政治 家);事件
(着陆、中断、请求);互相作用(借贷、开会、交叉);人员;场 所;组织;设备;
和地点。通过浏览使用系统的脚本发现重要的对象和其责任,是 面向对象分析和设计过
程的初期重要的技术。
当重要的对象被发现后,通过一组互相关联的模型详细表示类之间的关系和对 象的
行为,这些模型从四个不同的侧面表示了软件的体系结构:静态逻辑、动态逻 辑、静态
物理和动态物理。
静态逻辑模型描述实例化(类成员关系)、关联、聚集(整体/部分)、和一 般化
(继承)等关系。这被称为对象模型。一般化关系表示属性和方法的继承关 系。定义对
象模型的图形符号体系通常是从用于数据建模的实体关系图导出的。对 计十分重要的约
束,如基数(一对一、一对多、多对多),也在对象模型中表 示。
动态逻辑模型描述对象之间的互相作用。互相作用通过一组协同的对象,对象 之间
消息的有序的序列,参与对象的可见性定义,来定义系统运行时的行为。
Booch方法中的对象交互作用图被用来描述重要的互相作用,显示参与的对象和对象
之间按时间排序的消息。可见性图用来描述互相作用中对象的可见性。对象的可 见性定
义了一个对象如何处于向它发送消息的方法的作用域之中。例如,它可以是 方法的参数、
局部变量、新的对象、或当前执行方法的对象的部分。
静态物理模型通过模块描述代码的布局。动态物理模型描述软件的进程和线程体系结
构。
第 4 章 面向对象软件工程方法学实践
两位研究面向对象软件工程的美国学者 (Stave Halladay和Michael Wiebel) 曾这样
说:“一般的面向对象编程(OOP)思路不过是一批乌合之众,把灵机一动、随机应变的技巧
用于他们绞尽脑汁抽象出来的‘对象’而已。即使是最优秀的 OOP 程序员,他们所能对付
的极限也莫过于中等规模的开发项目。倘若程序员经验不足,系统规模又很大,那么采用
OOP 只能把你引入漫无边际的泥沼之中。”
一方面是几乎没有一位软件工程学者认为 OOP 是完美无缺的,另一方面是 OOP 势
如破竹,近乎每一种最新推出的程序开发工具或语言都采用了 OOP 思路;一方面是越来越
多的“乌合之众”在毫无章法、随心所欲地处理着“对象”,另一方面是经过近 30 年的
积累已经拥有了最大多数用户的结构化软件方法的日渐萎缩……面对这一现实,研究软件
工程方法学的专家们纷纷指出:“当前摆在软件开发方法学面前的一个重要课题是:从理
论上理解 OOP 具有强大生命力的天然合理性,并完善面向对象软件工程方法学体系。”
一年来我们通过国内外一些实用系统的开发实践,对面向对象的软件工程方法进行了
较为深入的学习和探讨,特别是在北京市公路局计算机系统的一期工程实践中,借鉴国外
软件设计经验,较系统地采用了面向对象软件工程方法,受益匪浅。
4.1 是“设计主导”还是“程序主导”
在一个系统开发过程中是只采用 OOP 还是采用了OOSE(面向对象软件工程)方法,关键看整个开发过程是“设计主导”还是“程序主导”。
近年来,大量先进程序开发工具进入我国,这对提高软件开发效率无疑具有很大的作
用。然而,它们又往往使程序主导型软件开发人员在“以程序代系统”、“以算法代设
计”的误区里越陷越深。
一般的软件开发人员(包括那些只见程序不见系统的程序员)主观上都认为:软件开发
不应“系统设计主导”而应“程序算法主导”。但是用下面几个问题考察一下,结果往往
相反。
问题1 在进行软件设计和选择软件开发工具之前,是否进行开发方法学的选择?
所谓方法学是指组织软件生产过程的一系列方法、技术和规范。方法学是软件开发者
长年失败和成功经验的理论性总结,从软件重用的思路来说,方法学重用的价值远非某些
程序组件重用可比。
以北京市公路局系统为例。首先,在系统调查阶段我们了解到:这个系统要分期 (递
增式) 开发。由于处于机构改革时期,系统生存期内的用户需求和系统结构变因很多。这
表明目标系统应该具有较强的可维护性,即每期开发成果应在后续工程中具有较高的可重
用率。其次,一期工程的工作量相当大(最后成果包括 124 个模块、72 类报表、119个数
据库表、439 个窗口、912 个数据窗口),而开发者对公路局业务不了解,多为经验不足的
大学生,理解需求的能力较低。这表明采用的开发方法学必须能最大限度地减少重复劳动
实现开发过程中的成果共享和重用;必须能支持消除需求理解误差的调整工序,使下游成品
阶段的设计变更比较容易进行。
在开发此系统之前,我们承接了一个国外软件的下游开发任务。由于它采用了面向对
象的软件设计,使我们深刻认识到国内外软件开发方法学和技术上的差距,颇受启发。
参照我们承接的国外软件开发工作量计算方法,即仅下游120个模块 (含报表) 的编
码和测试为41人月,那么公路局系统从上游设计开始近200个模块和报表、100多个数据
库表的开发工作量至少也应在120人月以上。由于采用了面向对象的软件工程方法,尽管
开发人员大多经验不足,但是第一期工程总工时最终仍控制在 80 人月以内,降低成本
1/3左右。同时在系统可维护性、重用度及其他功能和性能指标上,均超过了我们以往采
用结构化方法开发的系统。
对停留在程序主导级开发的软件开发人员来说,他们选择 OOP 的原因也往往是被动的。
其实,在程序主导开发者的辞典中是找不到“方法学”这一词的,或者把“方法学”与
“程序算法”混为一谈。至于把 OOP 看成是 OOSE 的全部就更不足为怪了。
问题2 对象抽象的出发点是现实世界的问题描述,还是可执行的实例对象?
在现实世界早期抽象阶段,面向对象方法与其他方法区别并不大,都要从现实世界的
问题描述出发,即从用户接口、问题领域的知识和经验出发,构筑现实世界的问题模型,
也就是确定目标系统是“做什么的”。面向对象的问题分析模型从 3个侧面进行描述,即
对象模型 (对象的静态结构)、动态模型(对象相互作用的顺序)和功能模型(数据变换及功
能依存关系)。软件工程的抽象原则、层次原则和分割原则同样适用于面向对象方法,即对
象抽象与功能抽象原则是一样的,也是从高级到低级、从逻辑到物理,逐级细分。每一级
抽象都重复对象建模 (对象识别)→动态建模(事件识别)→功能建模(操作识别)的过程,直
到每一个对象实例在物理(程序编码)上全部实现。
对象抽象是从逻辑级还是物理级出发,与开发前是否进行方法学选择一样,也是区分OOSE
与 OOP 的试金石。由于许多工具或语言(如PB、C++、Motif) 都支持OOP,使一些程序级
系统开发人员可以很方便地不经过逻辑抽象就直接开发物理对象,在早期阶段意识不到从
物理层即实例对象出发进行系统开发的祸患,孰不知正是这种随心所欲的 OOP 不仅无法发
挥面向对象方法应有的优越性,而且还会给开发后期带来大量返工作业。和以往采用结构化方法一样,我们在系统设计阶段也引入了原型化方法,以便用系统
样品即原型与用户对话,求得对需求理解的勾通,避免或减少后期返工。大多 OOP工具都
为开发原型提供便利,问题在于原型与最终产品间的关系,即原型是逻辑对象还是物理对
象的样品。若是后者,那就等同于最终产品。在木已成舟时再让用户评审,若发现问题,
要么推倒重来,要么强迫用户削足适履。事实上,我们为设计评审而基于逻辑对象开发的
原型,相当部分被用户否决。但由于尚未进行对象实例即物理级开发,而是使用超类对象
原型统一模拟对象事件和操作,所以无论是对象模型、动态模型还是功能模型,修改起来
都不困难。
问题3 设计阶段是否先设计超类,是否在实例对象设计开始之前完成超类对象的实现?
面向对象方法开发出的软件具有较强的可重用性,这种重用包括开发项目内部的重用
和外部的重用。重用依存于超类设计,没有超类的对象系统好比“把洗衣机当米缸”,不
能物尽其用。超类设计的好与不好,首先看其内部重用率的高低,内部重用率高,必然外
部重用率也高。
由于系统开发工期紧、工作量大,而我们的开发队伍年轻,经验和人力都不足,内部
重用率高的超类开发无疑是我们的救星。它可以减少重复劳动,易于统一规格,对复杂问题
统一攻关、统一解决,便于统一维护。
对超类的抽象即实例对象的泛化原则,我们是从下面几个方面考虑的:
(1)寻找大多数实例对象的共同行为。
例如“打印报表”、“查询静态代码表”、“录入数据库表数据”等。
(2)超类的多态性设计要保证使用超类继承关系可以满足各子类的操作要求。
例如,继承同一个“数据录入”祖先窗口,可以完成不同结构数据库表的数据录入。
(3)利于信息的隐蔽性,不会破坏数据的完整性,利于将复杂问题简单化。
例如,对具有复杂关系、结构及相关存取操作的数据库表集的维护。如果不使用一个
泛化类将数据结构及其相关操作封装起来,下层程序员要想操作有关库表就必须对库表设
计有深入的了解,并且确保程序算法设计不得破坏数据的相关一致性,这将大大增加程序
设计和测试的难度,要求程序员有较丰富的经验。而采用这种泛化类 (公用函数、公用存
储过程) 后,程序员所要做的只是发“消息”和取“输出信息”了。
(4)有利于推行开发规范,统一界面风格。
我们在开发国外软件中受到的最大磨练是:国外对用户界面 (报表、屏幕) 一丝不荀
的严格要求。所有屏幕按钮的高、宽、起始位置都用精确到小数点后 3 位的 X、Y 座标进
行规定。这样出来的产品使人看上去就有赏心悦目之感。但是如果人人都做界面窗口、按
钮的精细调整,工作量势必成倍增长。采用屏幕界面模版超类的继承关系,结合特化处理
问题便可迎刃而解。
显然,超类的设计和实现必须在程序员普遍进行实例对象开发之前完成。也就是说,
OOSE 的上游系统设计人员必须文武 (设计与编程) 双全,能够担负起超类对象的程序实现
与测试任务,这与结构化方法的上层系统设计人员基本可以不编程有所不同。同时,超类
对象在下游开发过程中必须经常吸收特化过程中的反馈(包括来自用户的反馈),进行相应
的调整修改。所以OOSE担任超类对象设计与实现的设计人员很难像结构化方法那样进入编
程阶段后就可以稍事轻松,他们往往始终离不开编程现场。
如果设计阶段不预先设计和开发出超类对象,在同一项目的多数开发者之间没有可以
共同继承的祖先对象,甚至在各个开发人员自己的作用范围内都不使用继承关系,那么这
不仅不是OOSE,就连称之为OOP都很勉强。
问题4 如何处理对象模型面向对象关系数据库模式的映射?
面向对象的数据库设计方法可以用于各种数据库,如层次型、网络型、关系型,当然也包括面向对象型。OOSE 中的数据库设计无疑必须采用面向对象的数据库设计方法。
数据库设计也称数据库模式,基本上由3个层次的模式构成:从特定DB应用角度来看
待DB设计的外部模式;从组织或企业角度出发进行的 DB设计即概念模式;处理对应特定
DBMS 特征与局限性的DB设计即内部模式。具体而言,内部模式是数据库的SQL定义,逻
辑模式是表集合的逻辑定义,外部模式是从特定应用角度看的局部 DB。外部模式与逻辑模
式之间的接口是视图、存储过程或其他驻在服务器端的DB处理程序。
如果在抽象出的对象模型中,各个应用分别是一个或多个超类对象的子对象,那么,
选择适当细分层次的对象模型将其映射到概念模型,是数据库库表对象设计的关键。外部
模式与概念模式之间的接口越少、越简单越好,这样的程序设计简单,数据库和程序都易
于维护。也就是说,局部化是个重要的设计原则。
OOP多是数据库的后端处理,是基于既存数据库的。因此无论是否进行过问题世界的
对象建模,以及是否将对象模型合理地映射到数据库逻辑模式 (面向对象数据库设计),
OOP 都可以工作。
问题5 编程时是否先调查有无可重用 (继承) 对象,是否参与下层对象对上层对象、超类
对象的反馈?
埋头于自己分担的程序对结构化方法或许是必须的,但在面向对象方法中担任程序设
计的开发人员,应该先去调查对象数据辞典中有无其他开发人员已经完成、自己稍加特化
就可重用的对象。从总体上说,对象的共享、重用应该由上层设计人员统一管理,以便保
证对象风格的一致性,避免冲突。但是,对象的独立性、封装性和多态性都很便于重用,
这是结构化系统所不能比拟的,而重用是软件开发方法学的最重要思想之一。上层设计人
员往往不可能面面俱到,懂得软件设计理论的开发人员,即使只开发下层程序也应采用最
省力、最有效率的编程方法,即大量使用重用对象。
在继承超类对象和重用他人对象时,若发现有设计不合理的地方,应该及时反映给对
象开发的承担者。
对上层设计人员来说,一方面应该鼓励程序实现人员重用既存对象,另一方面应通过
开发人员共享对象数据辞典,使个别的对象重用能够立即反映到整体对象模型中,以保证
设计变更时的一致性。
4.2 面向对象方法与结构化方法比较
分析是问题抽象 (做什么),设计是问题求解 (怎么做),实现是问题的解 (结果)。任
何方法学对客观世界的抽象和求解过程都是如此。在问题抽象阶段,结构化方法面向过程
按照数据变换的过程寻找问题的结点,对问题进行分解。因此,与面向对象方法强调的对
象模型不同,描述数据变换的功能模型是结构化方法的重点。如果问题世界的功能比数据
更复杂或者更重要,那么结构化方法仍然应是首选的方法学。如果数据结构复杂且变换并
不多,那么如以过程主导分析和设计,一旦有系统变更就会给下游开发带来极大混乱。
由于对过程的理解不同,面向过程的功能细分所分割出的功能模块有时会因人而异。
而面向对象的对象细分,从同一问题领域的对象出发,不同人得出相同结论的比率较高。
在设计上,结构化方法学产生自顶向下、结构清晰的系统结构。每个模块有可能保持
较强的独立性,但它往往与数据库结构相独立,功能模块与数据库逻辑模式间没有映射关
系,程序与数据结构很难封装在一起。如果数据结构复杂,模块独立性很难保证。面向对
象方法抽象的系统结构往往并不比结构化方法产生的系统结构简单,但它能映射到数据库
结构中,很容易实现程序与数据结构的封装。
在软件工程基本原则中有一条“形式化原则”,即对问题世界的抽象结论应该以形式化语言 (图形语言、伪码语言等) 表述出来。结构化方法可以用数据流图、系统结构图、
数据辞典、状态转移图、实体关系图来进行系统逻辑模型的描述;而面向对象方法可以使用
对象模型图、数据辞典、动态模型图、功能模型图。其中对象模型图近似系统结构图与实
体关系图的结合,动态模型图类似状态迁移图,功能模型图类似数据流图。
公路局系统有 100 多个数据库表,但数据的加工 (变换) 很单纯,如果当初选择结构化
方法学,情况会怎么样?
在问题抽象的最初阶段不会有太大差异。由于数据变换少,可以把对象和对象的操作
看成一一对应,即最初问题描述的对象模型与功能模型基本一致。以其中计划管理处子系
统为例,对象是计划管理员、规划管理员、概预算管理员、统计管理员,功能 (操作) 是
计划、规划、概预算、统计。
问题存在于下层抽象里。
首先,许多公共超类对象设计与结构化方法相悖,因为它破坏了过程的连续性及系统
结构的逻辑层次性,把一些下层模块及在过程分析中没有语义的对象,放在系统结构的上
层。因此如果采用结构化方法,须将继承关系改为下层模块调用关系。但是事实上,祖先
对象的一些状态 (属性值) 是从主控模块直接得到指示而确定的;从控制角度说,它的确处
于系统的上层地位。如果采用结构化方法,结果将是要么把系统结构变成网络状,失去结
构化特征,要么放弃这种统一完成重复性劳动的设计方案。
其次,应用对象模型向数据库概念模式的映射设计也是该系统采用面向对象方法的一
个标志。如果使用结构化方法,数据库模式可能映射客观世界的数据结构。由于公路、养
路单位、管理单位、路况、桥梁、隧道及道路上的绿化情况等各实体间客观存在着复杂的
多重关系,其结果可能定义出一个像蜘蛛网似的关系库结构,因而大大加重了数据库前端
应用编程和数据库维护的负担。
总之,该系统若使用结构化方法,系统结构和数据库结构都可能成为网状结构,且互
相无关。而目前采用的面向对象方法,系统结构和数据库结构都是多重继承结构,相互存
在映射关系。显然前者较后者复杂性高、可维护性差、内部重用难度大、重用率低。
其实,无论是用什么方法学开发软件,交给用户的都应该是满足用户当前需求的软件
用户在短期内不会发现开发者使用先进方法学给他们带来的益处,倒是开发者本身由于大
大减轻了开发负担而最先受益。但是随着时间的推移,获得最大收益的还是用户,因为软
件的长期质量(包括维护成本低和生存周期长)给用户带来的好处才是根本的。
4.3 方法学是思路不是定律
对于方法学,我们是这样理解的:
(1)方法学的目的是:使后人分享前人的成功,避开前人的失败,把注意力集中在尚未
开拓领域的创造性劳动上。所以方法学与开发人员的创造性是绝不冲突的。它既不能像法
律那样靠权威来界定是非边界,也不能像定律那样通过证明和推理给出普遍结论。如果一
定要做比喻的话,它好比人的世界观。
(2)没有放之四海而皆准的方法学,任何方法学都有其局限性,所以软件开发人员大可
不必拘泥于某种特定的方法学。
例如,面向对象方法的对象模型图,这种形式化语言远不如结构化方法的结构图和数
据流图简单明了,倘若把公路局系统全部用对象模型图表述出来,至少也要几十页。由于
最上层功能模型与对象模型是一致的,所以我们采用的是结构化方法的系统结构图。
(3)事实表明,由 OOP 带动的 OOSE 方法确实比结构化方法更能自然地抽象现实世界
而且一些 OOP 工具确实已相当成熟。相反,结构化方法及开放平台下的结构化程序开发工具,虽然不能说止步不前,但其近年来的进步是有限的。
(4)根据我们的体会,对实践 OOSE 有以下一些建议:
1 最好在选定方法学后,对全体开发人员进行一次关于面向对象方法学的培训。
2 由于有超类对象的提前开发工作,OOSE 的上游设计工作量比结构化方法的上游工作
负担重,时间和人力应该更充足一些。否则到下游开发后再追加或多次修改变更超类对象
容易造成混乱和无效劳动。
3 由于系统越大对象类越多,为了便于内部重用和共享,应该建立电子化的对象数据
辞典,以便对对象进行统一归类管理。
4 应该有严格的命名规则,如果可能,应将命名规则集成到数据辞典中。
5 下层开发铺开后,如果发现应该对某些实例对象泛化成新的超类对象,必须尽快进
行新超类追加的设计,变更越快越好。
6 子对象继承超类对象后,发现超类设计的缺陷是常有的事。开发队伍内部应有很畅
通的反馈渠道,使超类得到及时的修正。子对象切不可轻易将超类对象封杀掉,使系统失
去统一控制。遵从系统设计中定义的继承关系进行实例对象开发应该成为全体开发人员的
理念。
7 面向对象设计的好处越到后来越显著,特别是在系统维护和扩充方面。
第 5 章 中间件技术
一 什么是中间件
为解决分布异构问题,人们提出了中间件(middleware)的概念。中间件是位于平台(硬件和
操作系统)和应用之间的通用服务,如图1所示,这些服务具有标准的程序接口和协议。针对不
同的操作系统和硬件平台,它们可以有符合接口和协议规范的多种实现。
图1 中间件
也许很难给中间件一个严格的定义,但中间件应具有如下的一些特点:
满足大量应用的需要
运行于多种硬件和OS平台
支持分布计算,提供跨网络、硬件和OS平台的透明性的应用或服务的交互
支持标准的协议
支持标准的接口
由于标准接口对于可移植性和标准协议对于互操作性的重要性,中间件已成为许多标准化工
作的主要部分。对于应用软件开发,中间件远比操作系统和网络服务更为重要,中间件提供的程
序接口定义了一个相对稳定的高层应用环境,不管底层的计算机硬件和系统软件怎样更新换代,
只要将中间件升级更新,并保持中间件对外的接口定义不变,应用软件几乎不需任何修改,从而
保护了企业在应用软件开发和维护中的重大投资。
三、主要中间件的分类
中间件所包括的范围十分广泛,针对不同的应用需求涌现出多种各具特色的中间件产品。但
至今中间件还没有一个比较精确的定义,因此,在不同的角度或不同的层次上,对中间件的分类
也会有所不同。由于中间件需要屏蔽分布环境中异构的操作系统和网络协议,它必须能够提供分布环境下的通讯服务,我们将这种通讯服务称之为平台。基于目的和实现机制的不同,我们将平
台分为以下主要几类:
远程过程调用(Remote Procedure Call)
面向消息的中间件(Message-Oriented Middleware)
对象请求代理(Object Request Brokers)
它们可向上提供不同形式的通讯服务,包括同步、排队、订阅发布、广播等等,在这些基本
的通讯平台之上,可构筑各种框架,为应用程序提供不同领域内的服务,如事务处理监控器、分
布数据访问、对象事务管理器OTM等。平台为上层应用屏蔽了异构平台的差异,而其上的框架
又定义了相应领域内的应用的系统结构、标准的服务组件等,用户只需告诉框架所关心的事件,
然后提供处理这些事件的代码。当事件发生时,框架则会调用用户的代码。用户代码不用调用框
架,用户程序也不必关心框架结构、执行流程、对系统级API的调用等,所有这些由框架负责完
成。因此,基于中间件开发的应用具有良好的可扩充性、易管理性、高可用性和可移植性。
二 分类
1、远程过程调用
远程过程调用是一种广泛使用的分布式应用程序处理方法。一个应用程序使用RPC来“远
程”执行一个位于不同地址空间里的过程,并且从效果上看和执行本地调用相同。事实上,一个
RPC应用分为两个部分:server和client。server提供一个或多个远程过程;client向server发
出远程调用。server和client可以位于同一台计算机,也可以位于不同的计算机,甚至运行在不
同的操作系统之上。它们通过网络进行通讯。相应的stub和运行支持提供数据转换和通讯服务,
从而屏蔽不同的操作系统和网络协议。在这里RPC通讯是同步的。采用线程可以进行异步调用。
在RPC模型中,client和server只要具备了相应的RPC接口,并且具有RPC运行支持,
就可以完成相应的互操作,而不必限制于特定的server。因此,RPC为client/server分布式计
算提供了有力的支持。同时,远程过程调用RPC所提供的是基于过程的服务访问,client与
server进行直接连接,没有中间机构来处理请求,因此也具有一定的局限性。比如,RPC通常
需要一些网络细节以定位server;在client发出请求的同时,要求server必须是活动的等等。
2、面向消息的中间件
MOM指的是利用高效可靠的消息传递机制进行平台无关的数据交流,并基于数据通信来进
行分布式系统的集成。通过提供消息传递和消息排队模型,它可在分布环境下扩展进程间的通信,
并支持多通讯协议、语言、应用程序、硬件和软件平台。目前流行的MOM中间件产品有IBM的
MQSeries、BEA的MessageQ等。消息传递和排队技术有以下三个主要特点:
通讯程序可在不同的时间运行:程序不在网络上直接相互通话,而是间接地将消息放入消息
队列,因为程序间没有直接的联系。所以它们不必同时运行。消息放入适当的队列时,目标程序
甚至根本不需要正在运行;即使目标程序在运行,也不意味着要立即处理该消息。
对应用程序的结构没有约束:在复杂的应用场合中,通讯程序之间不仅可以是一对一的关系,
还可以进行一对多和多对一方式,甚至是上述多种方式的组合。多种通讯方式的构造并没有增加
应用程序的复杂性。
程序与网络复杂性相隔离: 程序将消息放入消息队列或从消息队列中取出消息来进行通讯,
与此关联的全部活动,比如维护消息队列、维护程序和队列之间的关系、处理网络的重新启动和
在网络中移动消息等是MOM的任务,程序不直接与其它程序通话,并且它们不涉及网络通讯的
复杂性。
3、对象请求代理随着对象技术与分布式计算技术的发展,两者相互结合形成了分布对象计算,并发展为当今
软件技术的主流方向。1990年底,对象管理集团OMG首次推出对象管理结构OMA(Object
Management Architecture),对象请求代理(Object Request Broker)是这个模型的核心组件。
它的作用在于提供一个通信框架,透明地在异构的分布计算环境中传递对象请求。CORBA规范
包括了ORB的所有标准接口。1991年推出的CORBA 1.1 定义了接口描述语言OMG IDL和支
持Client/Server对象在具体的ORB上进行互操作的API。CORBA 2.0 规范描述的是不同厂商
提供的ORB之间的互操作。
对象请求代理(ORB)是对象总线,它在CORBA规范中处于核心地位,定义异构环境下对象
透明地发送请求和接收响应的基本机制,是建立对象之间client/server关系的中间件。ORB使
得对象可以透明地向其他对象发出请求或接受其他对象的响应,这些对象可以位于本地也可以位
于远程机器。ORB拦截请求调用,并负责找到可以实现请求的对象、传送参数、调用相应的方
法、返回结果等。client对象并不知道同server对象通讯、激活或存储server对象的机制,也
不必知道server对象位于何处、它是用何种语言实现的、使用什么操作系统或其他不属于对象
接口的系统成分。
值得指出的是client和server角色只是用来协调对象之间的相互作用,根据相应的场合,
ORB上的对象可以是client,也可以是server,甚至兼有两者。当对象发出一个请求时,它是处
于client角色;当它在接收请求时,它就处于server角色。大部分的对象都是既扮演client角色
又扮演server角色。另外由于ORB负责对象请求的传送和server的管理,client和server之间
并不直接连接,因此,与RPC所支持的单纯的Client/Server结构相比,ORB可以支持更加复
杂的结构。
4、事务处理监控
事务处理监控(Transaction processing monitors)最早出现在大型机上,为其提供支持大
规模事务处理的可靠运行环境。随着分布计算技术的发展,分布应用系统对大规模的事务处理提
出了需求,比如商业活动中大量的关键事务处理。事务处理监控界于client和server之间,进行
事务管理与协调、负载平衡、失败恢复等,以提高系统的整体性能。它可以被看作是事务处理应
用程序的“操作系统”。总体上来说,事务处理监控有以下功能:
进程管理,包括启动server进程、为其分配任务、监控其执行并对负载进行平衡。
事务管理,即保证在其监控下的事务处理的原子性、一致性、独立性和持久性。
通讯管理,为client和server之间提供了多种通讯机制,包括请求响应、会话、排队、订阅
发布和广播等。
事务处理监控能够为大量的client提供服务,比如飞机定票系统。如果server为每一个
client都分配其所需要的资源的话,那server将不堪重负(如图2所示)。但实际上,在同一时
刻并不是所有的client都需要请求服务,而一旦某个client请求了服务,它希望得到快速的响应。
事务处理监控在操作系统之上提供一组服务,对 client请求进行管理并为其分配相应的服务进程,
使server在有限的系统资源下能够高效地为大规模的客户提供服务。第6章 Java EE 技术软件工程专题
Java EE 以前称为 J2EE,可以帮助开发和部署可移植、健壮、可伸缩且安全的服务器
端 Java 应用程序。Java EE 是在 Java SE 的基础上构建的,它提供 Web 服务、组件模
型、管理和通信 API,可以用来实现企业级的面向服务体系结构(SOA)和 Web 2.0 应用
程序。 本专题汇集大量相关技术资源,帮助您理解这些 Java 服务器端技术如何独立以及
共同工作,这是您成功开发 Java 企业级应用的关键。
6.1 企业级 Java
企业 Java 计算模型由四部分组成:标准平台定义(企业 Java APIs)、工业强度的
应用服务器、构件架构和简化编码工作的开发工具。
Enterprise Java Beans 和Enterprise JavaBean APIs
Enterprise JavaBeans (EJB) 使开发者只编写一次构件,然后便可在最适合他们的应
用程序和企业需要的服务器环境中使用它们。
标准化的 Enterprise JavaBean APIs 使这成为可能。 正如 Sun 在 Enterprise
JavaBeans-- Java的服务器构件?中所说明的企业的Java平台由一套标准的应用程序编
程接口(API) 到一套核心的企业- 类基础服务( 其中包括生命周期、命名、远程唤醒、消
息处理、交易、数据库访问和管理) 组成。这些基础访问经常是使用不同的产品和技术在
不同的平台上实现的,所以很难创建可移植的企业-类应用程序系统。 Java Enterprise
APIs提供了一个无需考虑实现方式,为经常服务奠定基石的公共接口。
应用程序服务器
应用程序服务器为执行由Enterprise Java Beans 创建的中间件提供了一个平台。这
些服务器必须具有高度的可伸缩性以支持多用户。用户端可安全的且同时的访问应用程序
应用程序能够在任何服务器平台上执行。若想了解更多的信息,请参阅 IBM 的 应用程序
服务器。
构件架构构件是可被用来构造其它应用程序系统的应用程序。在企业内部,重要的部件提供一
下的商业服务:交易、安全的数据库访问等等。构件可被方便的导入开发工具中并用来为
快速开发基于Java 的商业应用程序提供架构。它们被用来设置应用程序并由 Web服务器
或数据库系统执行。这些构件遵从Enterprise JavaBeans的规范。 若想了解更多的信息,
请参阅 IBM的构件架构。
开发工具
企业Java 开发工具为创建Java 兼容的应用程序、 applet 、servlets 和JavaBean
构件提供了一个途径。通过将Java 客户端自动连接到现存的服务器数据、交易和应用程
序上,客户便可以利用现存的商业应用程序和 web上日常的商业运作。
6.2 J2EE 简介
6.2.1 J2EE 的概念
目前,Java 2平台有3个版本,它们是适用于小型设备和智能卡的Java 2平台Micro
版(Java 2 Platform Micro Edition,J2ME)、适用于桌面系统的 Java 2平台标准版
(Java 2 Platform Standard Edition,J2SE)、适用于创建服务器应用程序和服务的
Java 2平台企业版(Java 2 Platform Enterprise Edition,J2EE)。
J2EE是一种利用Java 2平台来简化企业解决方案的开发、部署和管理相关的复杂问
题的体系结构。J2EE技术的基础就是核心Java平台或Java 2平台的标准版,J2EE不仅巩
固了标准版中的许多优点,例如"编写一次、随处运行"的特性、方便存取数据库的JDBC
API、CORBA技术以及能够在Internet应用中保护数据的安全模式等等,同时还提供了对
EJB(Enterprise JavaBeans)、Java Servlets API、JSP(Java Server Pages)以及
XML技术的全面支持。其最终目的就是成为一个能够使企业开发者大幅缩短投放市场时间
的体系结构。
J2EE体系结构提供中间层集成框架用来满足无需太多费用而又需要高可用性、高可靠
性以及可扩展性的应用的需求。通过提供统一的开发平台,J2EE降低了开发多层应用的费
用和复杂性,同时提供对现有应用程序集成强有力支持,完全支持 Enterprise
JavaBeans,有良好的向导支持打包和部署应用,添加目录支持,增强了安全机制,提高了
性能。
J2EE的优势
J2EE为搭建具有可伸缩性、灵活性、易维护性的商务系统提供了良好的机制:
保留现存的IT资产: 由于企业必须适应新的商业需求,利用已有的企业信息系统方面
的投资,而不是重新制定全盘方案就变得很重要。这样,一个以渐进的(而不是激进的,
全盘否定的)方式建立在已有系统之上的服务器端平台机制是公司所需求的。J2EE架构可
以充分利用用户原有的投资,如一些公司使用的BEA Tuxedo、IBM CICS, IBM Encina,、
Inprise VisiBroker 以及Netscape Application Server。这之所以成为可能是因为J2EE
拥有广泛的业界支持和一些重要的'企业计算'领域供应商的参与。每一个供应商都对现有
的客户提供了不用废弃已有投资,进入可移植的J2EE领域的升级途径。由于基于J2EE平台的产品几乎能够在任何操作系统和硬件配置上运行,现有的操作系统和硬件也能被保留
使用。
高效的开发: J2EE允许公司把一些通用的、很繁琐的服务端任务交给中间件供应商去
完成。这样开发人员可以集中精力在如何创建商业逻辑上,相应地缩短了开发时间。高级
中间件供应商提供以下这些复杂的中间件服务:
状态管理服务 -- 让开发人员写更少的代码,不用关心如何管理状态,这样能够更快
地完成程序开发。
持续性服务 -- 让开发人员不用对数据访问逻辑进行编码就能编写应用程序,能生成
更轻巧,与数据库无关的应用程序,这种应用程序更易于开发与维护。
分布式共享数据对象CACHE服务 -- 让开发人员编制高性能的系统,极大提高整体部
署的伸缩性。
支持异构环境: J2EE能够开发部署在异构环境中的可移植程序。基于J2EE的应用程
序不依赖任何特定操作系统、中间件、硬件。因此设计合理的基于 J2EE的程序只需开发一
次就可部署到各种平台。这在典型的异构企业计算环境中是十分关键的。J2EE标准也允许
客户订购与J2EE兼容的第三方的现成的组件,把他们部署到异构环境中,节省了由自己制
订整个方案所需的费用。
可伸缩性: 企业必须要选择一种服务器端平台,这种平台应能提供极佳的可伸缩性去
满足那些在他们系统上进行商业运作的大批新客户。基于 J2EE平台的应用程序可被部署到
各种操作系统上。例如可被部署到高端UNIX与大型机系统,这种系统单机可支持64至256
个处理器。(这是NT服务器所望尘莫及的)J2EE领域的供应商提供了更为广泛的负载平
衡策略。能消除系统中的瓶颈,允许多台服务器集成部署。这种部署可达数千个处理器,
实现可高度伸缩的系统,满足未来商业应用的需要。
稳定的可用性: 一个服务器端平台必须能全天候运转以满足公司客户、合作伙伴的需
要。因为INTERNET是全球化的、无处不在的,即使在夜间按计划停机也可能造成严重损失。
若是意外停机,那会有灾难性后果。J2EE部署到可靠的操作环境中,他们支持长期的可用
性。一些 J2EE部署在WINDOWS环境中,客户也可选择健壮性能更好的操作系统如 Sun
Solaris、IBM OS/390。最健壮的操作系统可达到99.999%的可用性或每年只需5分钟停机
时间。这是实时性很强商业系统理想的选择。
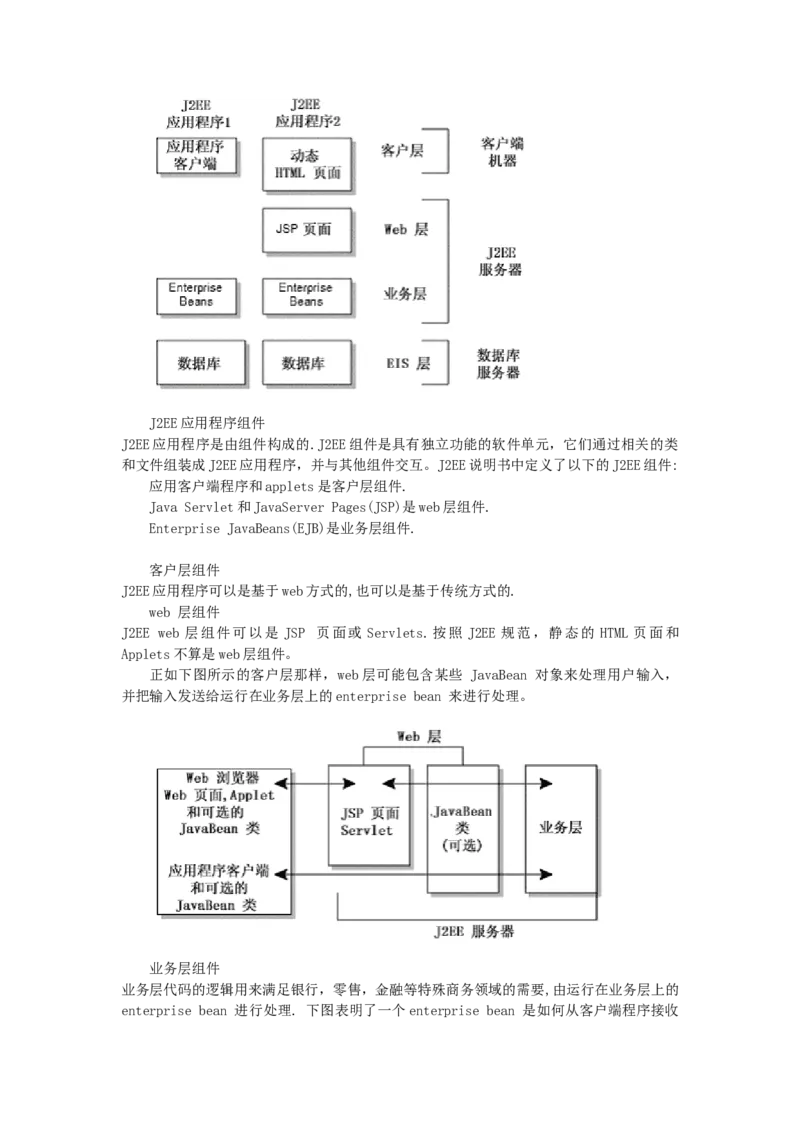
6.2.2 J2EE 的四层模型
J2EE使用多层的分布式应用模型,应用逻辑按功能划分为组件,各个应用组件根据他
们所在的层分布在不同的机器上。事实上,sun设计J2EE的初衷正是为了解决两层模式
(client/server)的弊端,在传统模式中,客户端担当了过多的角色而显得臃肿,在这种模
式中,第一次部署的时候比较容易,但难于升级或改进,可伸展性也不理想,而且经常基
于某种专有的协议�D�D通常是某种数据库协议。它使得重用业务逻辑和界面逻辑非常困
难。现在J2EE 的多层企业级应用模型将两层化模型中的不同层面切分成许多层。一个多
层化应用能够为不同的每种服务提供一个独立的层,以下是 J2EE 典型的四层结构:
运行在客户端机器上的客户层组件
运行在J2EE服务器上的Web层组件
运行在J2EE服务器上的业务逻辑层组件
运行在EIS服务器上的企业信息系统(Enterprise information system)层软件J2EE应用程序组件
J2EE应用程序是由组件构成的.J2EE组件是具有独立功能的软件单元,它们通过相关的类
和文件组装成J2EE应用程序,并与其他组件交互。J2EE说明书中定义了以下的J2EE组件:
应用客户端程序和applets是客户层组件.
Java Servlet和JavaServer Pages(JSP)是web层组件.
Enterprise JavaBeans(EJB)是业务层组件.
客户层组件
J2EE应用程序可以是基于web方式的,也可以是基于传统方式的.
web 层组件
J2EE web 层组件可以是 JSP 页面或 Servlets.按照 J2EE 规范,静态的 HTML 页面和
Applets不算是web层组件。
正如下图所示的客户层那样,web层可能包含某些 JavaBean 对象来处理用户输入,
并把输入发送给运行在业务层上的enterprise bean 来进行处理。
业务层组件
业务层代码的逻辑用来满足银行,零售,金融等特殊商务领域的需要,由运行在业务层上的
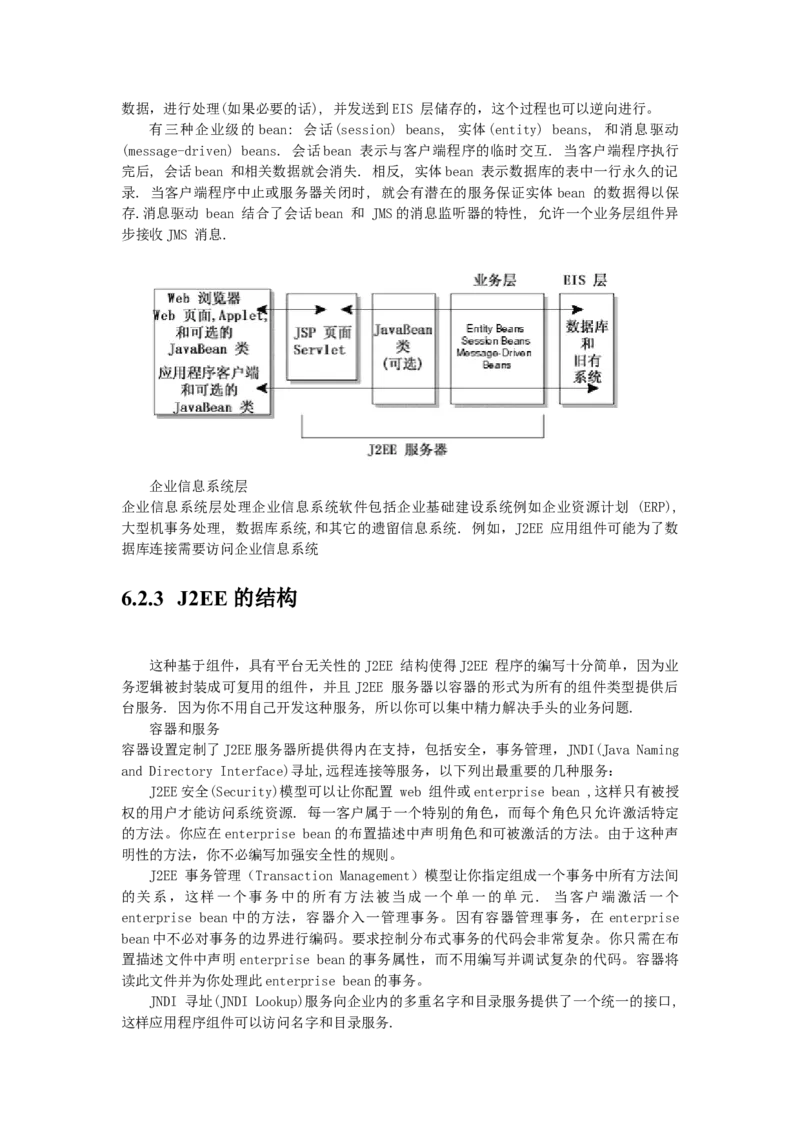
enterprise bean 进行处理. 下图表明了一个enterprise bean 是如何从客户端程序接收数据,进行处理(如果必要的话), 并发送到EIS 层储存的,这个过程也可以逆向进行。
有三种企业级的 bean: 会话(session) beans, 实体(entity) beans, 和消息驱动
(message-driven) beans. 会话bean 表示与客户端程序的临时交互. 当客户端程序执行
完后, 会话bean 和相关数据就会消失. 相反, 实体bean 表示数据库的表中一行永久的记
录. 当客户端程序中止或服务器关闭时, 就会有潜在的服务保证实体bean 的数据得以保
存.消息驱动 bean 结合了会话bean 和 JMS的消息监听器的特性, 允许一个业务层组件异
步接收JMS 消息.
企业信息系统层
企业信息系统层处理企业信息系统软件包括企业基础建设系统例如企业资源计划 (ERP),
大型机事务处理, 数据库系统,和其它的遗留信息系统. 例如,J2EE 应用组件可能为了数
据库连接需要访问企业信息系统
6.2.3 J2EE 的结构
这种基于组件,具有平台无关性的J2EE 结构使得J2EE 程序的编写十分简单,因为业
务逻辑被封装成可复用的组件,并且J2EE 服务器以容器的形式为所有的组件类型提供后
台服务. 因为你不用自己开发这种服务, 所以你可以集中精力解决手头的业务问题.
容器和服务
容器设置定制了J2EE服务器所提供得内在支持,包括安全,事务管理,JNDI(Java Naming
and Directory Interface)寻址,远程连接等服务,以下列出最重要的几种服务:
J2EE安全(Security)模型可以让你配置 web 组件或enterprise bean ,这样只有被授
权的用户才能访问系统资源. 每一客户属于一个特别的角色,而每个角色只允许激活特定
的方法。你应在enterprise bean的布置描述中声明角色和可被激活的方法。由于这种声
明性的方法,你不必编写加强安全性的规则。
J2EE 事务管理(Transaction Management)模型让你指定组成一个事务中所有方法间
的关系,这样一个事务中的所有方法被当成一个单一的单元. 当客户端激活一个
enterprise bean中的方法,容器介入一管理事务。因有容器管理事务,在 enterprise
bean中不必对事务的边界进行编码。要求控制分布式事务的代码会非常复杂。你只需在布
置描述文件中声明enterprise bean的事务属性,而不用编写并调试复杂的代码。容器将
读此文件并为你处理此enterprise bean的事务。
JNDI 寻址(JNDI Lookup)服务向企业内的多重名字和目录服务提供了一个统一的接口,
这样应用程序组件可以访问名字和目录服务.J2EE远程连接(Remote Client Connectivity)模型管理客户端和enterprise bean
间的低层交互. 当一个enterprise bean创建后, 一个客户端可以调用它的方法就象它和
客户端位于同一虚拟机上一样.
生存周期管理(Life Cycle Management)模型管理enterprise bean的创建和移除,
一个enterprise bean在其生存周期中将会历经几种状态。容器创建 enterprise bean,
并在可用实例池与活动状态中移动他,而最终将其从容器中移除。即使可以调用
enterprise bean的create及remove方法,容器也将会在后台执行这些任务。
数据库连接池(Database Connection Pooling)模型是一个有价值的资源。获取数据
库连接是一项耗时的工作,而且连接数非常有限。容器通过管理连接池来缓和这些问题。
enterprise bean可从池中迅速获取连接。在bean释放连接之可为其他bean使用。
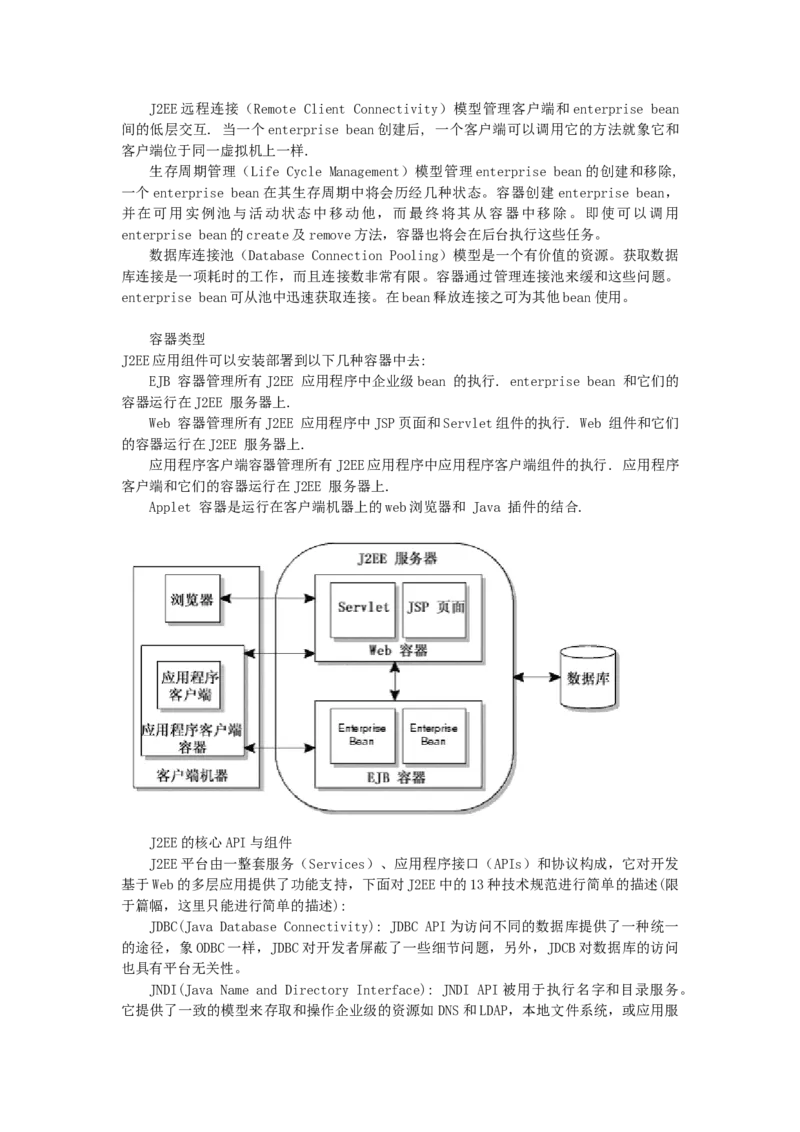
容器类型
J2EE应用组件可以安装部署到以下几种容器中去:
EJB 容器管理所有J2EE 应用程序中企业级bean 的执行. enterprise bean 和它们的
容器运行在J2EE 服务器上.
Web 容器管理所有J2EE 应用程序中JSP页面和Servlet组件的执行. Web 组件和它们
的容器运行在J2EE 服务器上.
应用程序客户端容器管理所有J2EE应用程序中应用程序客户端组件的执行. 应用程序
客户端和它们的容器运行在J2EE 服务器上.
Applet 容器是运行在客户端机器上的web浏览器和 Java 插件的结合.
J2EE的核心API与组件
J2EE平台由一整套服务(Services)、应用程序接口(APIs)和协议构成,它对开发
基于Web的多层应用提供了功能支持,下面对J2EE中的13种技术规范进行简单的描述(限
于篇幅,这里只能进行简单的描述):
JDBC(Java Database Connectivity): JDBC API为访问不同的数据库提供了一种统一
的途径,象ODBC一样,JDBC对开发者屏蔽了一些细节问题,另外,JDCB对数据库的访问
也具有平台无关性。
JNDI(Java Name and Directory Interface): JNDI API被用于执行名字和目录服务。
它提供了一致的模型来存取和操作企业级的资源如DNS和LDAP,本地文件系统,或应用服务器中的对象。
EJB(Enterprise JavaBean): J2EE 技术之所以赢得某体广泛重视的原因之一就是
EJB。它们提供了一个框架来开发和实施分布式商务逻辑,由此很显著地简化了具有可伸缩
性和高度复杂的企业级应用的开发。EJB规范定义了EJB组件在何时如何与它们的容器进
行交互作用。容器负责提供公用的服务,例如目录服务、事务管理、安全性、资源缓冲池
以及容错性。但这里值得注意的是,EJB并不是实现J2EE的唯一途径。正是由于J2EE的开
放性,使得有的厂商能够以一种和EJB平行的方式来达到同样的目的。
RMI(Remote Method Invoke): 正如其名字所表示的那样,RMI协议调用远程对象上方
法。它使用了序列化方式在客户端和服务器端传递数据。RMI是一种被EJB使用的更底层
的协议。
Java IDL/CORBA: 在Java IDL的支持下,开发人员可以将Java和CORBA集成在一起。
他们可以创建Java对象并使之可在CORBA ORB中展开, 或者他们还可以创建Java类并作
为和其它ORB一起展开的CORBA对象的客户。后一种方法提供了另外一种途径,通过它
Java可以被用于将你的新的应用和旧的系统相集成。
JSP(Java Server Pages): JSP页面由HTML代码和嵌入其中的Java代码所组成。服务
器在页面被客户端所请求以后对这些Java代码进行处理,然后将生成的HTML页面返回给
客户端的浏览器。
Java Servlet: Servlet是一种小型的Java程序,它扩展了Web服务器的功能。作为
一种服务器端的应用,当被请求时开始执行,这和 CGI Perl脚本很相似。Servlet提供的
功能大多与JSP类似,不过实现的方式不同。JSP通常是大多数HTML代码中嵌入少量的
Java代码,而servlets全部由Java写成并且生成HTML。
XML(Extensible Markup Language): XML是一种可以用来定义其它标记语言的语言。
它被用来在不同的商务过程中共享数据。XML的发展和Java是相互独立的,但是,它和
Java具有的相同目标正是平台独立性。通过将Java和XML的组合,您可以得到一个完美的
具有平台独立性的解决方案。
JMS(Java Message Service): MS是用于和面向消息的中间件相互通信的应用程序接
口(API)。它既支持点对点的域,有支持发布/订阅(publish/subscribe)类型的域,并且提
供对下列类型的支持:经认可的消息传递,事务型消息的传递,一致性消息和具有持久性的
订阅者支持。JMS还提供了另一种方式来对您的应用与旧的后台系统相集成。
JTA(Java Transaction Architecture): JTA定义了一种标准的API,应用系统由此可
以访问各种事务监控。
JTS(Java Transaction Service): JTS是CORBA OTS事务监控的基本的实现。JTS规
定了事务管理器的实现方式。该事务管理器是在高层支持Java Transaction API (JTA)规
范,并且在较底层实现OMG OTS specification的Java映像。JTS事务管理器为应用服务
器、资源管理器、独立的应用以及通信资源管理器提供了事务服务。
JavaMail: JavaMail是用于存取邮件服务器的API,它提供了一套邮件服务器的抽象
类。不仅支持SMTP服务器,也支持IMAP服务器。
JTA(JavaBeans Activation Framework): JavaMail利用JAF来处理MIME编码的邮件
附件。MIME的字节流可以被转换成Java对象,或者转换自Java对象。大多数应用都可以
不需要直接使用JAF。
6.3 Java EE 5Java EE 技术是 Java 语言平台的扩展,支持开发人员创建可伸缩的强大的可移植企
业应用程序。它为应用程序组件定义了四种容器:Web、Enterprise JavaBean(EJB)、应
用程序客户机和 applet。一个应用服务器规范详细描述了这些容器和它们必须支持的
Java API,这促使 Java EE 产品相互竞争,同时保证符合这个规范的应用程序可以在服务
器之间移植(参见 Java EE 简史)。
这个平台的最新版本 Java EE 5 已经于 2006 年 5 月发布。Java EE 5 主要关注提
高开发人员的生产率,它提供了更简单的编程模型,而没有牺牲平台的任何功能。更简单
的开发模型主要由两个机制提供 —— Java 注解和更好的默认行为。主要的功能性改进包
括改进了 Web 服务支持以及在平台中集成了 JavaServer Faces(JSF)和 Java Standard
Tag Library(JSTL)。
Web 服务技术
在 Java EE 5 中引入了注解(annotation)特性,这简化了复杂 Web 服务端点和客
户机的开发,与以前的 Java EE 版本相比,代码更少,学习过程更短了。注解(最早在
Java SE 5 中引入)是可以作为元数据添加到代码中的修饰性代码。它们并不直接影响程
序的语义,但是编译器、开发工具和运行时库可以通过处理它们生成额外的 Java 语言源
文件、XML 文档或其他工件和行为,这些对包含注解的程序起辅助作用(参见 参考资料)。
在本文后面,会看到如何通过添加简单的注解,将常规的 Java 类转换为 Web 服务。
Web 应用程序技术
除了现有的 JavaServer Pages 和 Servlet 规范,Java EE 5 引入了两种前端技术
— JSF 和 JSTL。JSF 是一组 API,支持以基于组件的方式开发用户界面。JSTL 是一组标
记库,支持在 JSP 中嵌入过程式逻辑、对 JavaBean 的访问方法、SQL 命令、本地化格式
指令和 XML 处理。JSF、JSTL 和 JSP 的最新版本支持一种统一表达式语言(expression
language,EL),这使这些技术更容易集成在一起(参见 参考资料)。
企业应用程序技术
有大量技术属于企业应用程序的范围,其中许多在 Java EE 5 中没有变化或者不适合
在本文中详细讨论。这里主要关注两个改进:对 EJB 开发的简化和新的持久化特性。
EJB 3.0
EJB 规范是 Java EE 平台的核心。它定义如何封装应用程序的业务逻辑,并以高度可
伸缩、可靠且感知事务的方式分布业务逻辑,确保并发的数据访问不会破坏数据。
管理和安全性
Java EE 5 需要三个与以前版本相同的管理和安全性规范:
Application Deployment 提供一个用于将组件和应用程序部署到 Java EE 容器的
API。工具可以通过这个 API 将代码部署到 Java EE 5 容器中,而不需要重新启动容器。
在开发期间,IDE 常常使用这个 API 支持快速的编写/测试/纠正循环。
Application Management 为容器管理的对象指定必需的属性和操作。它与多种行业标
准管理协议兼容。
Authorization Contract for Containers(Java ACC)定义安全策略提供者的语义,
以及如何授予对这个合约中的操作的访问权。它要求容器实现一些接口,使部署工具能够
管理授权角色。
6.4 J2EE 探险者系列
用 J2EE 开发企业应用程序时,它向人们提供了众多选项 — 使得为基础结构选择合
适的解决方案不是一件简单的任务。 J2EE 探险者 是专门针对 Java 技术经理、架构设计师和开发人员的系列文章。该系列中的每一篇文章都会向您展示一种或几种 J2EE 技术,
并经常对它们加以权衡,从而帮助您做出富有见识的决策。
用于无状态网络的 J2EE 技术
本文比较了两种用于无状态网络的 J2EE 技术:servlet 和 EJB 技术。
有状态网络的 J2EE 技术
J2EE 中的 Java servlet 和 Enterprise JavaBeans 组件都提供了有状态服务器端处理。
两种技术各有千秋,每种技术都比其它技术更加适合于某些应用程序设置。为了帮助您为
您的企业选择合适的解决方案,本文比较了这两种技术,并评估了它们在一些常见的有状
态应用程序方案中的性能。
持久数据管理,第 1 部分
J2EE 平台为管理企业数据持久性提供了一组丰富的选项,但如何选择适合于您体系结构的
选项呢?本文介绍了 J2EE 最佳的数据持久性技术 - 实体 bean、JDBC 和 JDO - 并在几
个不同环境中比较它们。
持久数据管理,第 2 部分
本文不再专门讨论比较成熟的 JDBC 技术和 EJB 技术,而是主要介绍 JDO。尽管这种技术
与其它技术相比还不成熟,但您会发现 JDO 有一些独一无二的优点。
用 JMS 进行企业消息传递
本文解释了为什么消息服务对于企业的体系结构来说是至关重要的,您的解决方案必须克
服什么类型的障碍,以及 除了 Java 消息服务(Java Message Service ,JMS)之外,还
有哪些替代的解决方案。
创建和管理有状态 Web 应用程序
本文对用于有状态 Web 应用程序开发的 4 种会话作用域的适当处理给予了关注。
隐式对象的多种用法序
接着上月对会话作用域的介绍,本文深入研究了 JSP 隐式对象的多种用法。接下来,将介
绍 9 个隐式对象,解释每个对象的用途(或者多种用途),最后给出一些怎样在 JSP 编
程中使用这些便利工具的最佳实践。
用五个容易的步骤实现 JSP 自定义标记
JSP 自定义标记为在动态 Web 页中将表示与业务逻辑分离提供了一种标准化的机制,使页
面设计者可以将注意力放到表示上,而应用程序开发人员编写后端的代码。在 J2EE 探索
者 的这篇文章中,介绍了 JSP 自定义标记的基本知识,并引导您完成将它们加入到 JSP
页面的五步过程。
用 JAAS 和 JSSE 实现Java 安全性
本文介绍了 Java 认证和授权服务(Java Authentication and Authorization Service,
JAAS)和 Java 安全套接字扩展(Java Secure Socket Extension,JSSE)。跟随作者去
发现如何结合这两个 API 以提供 J2EE Web 应用程序安全框架的核心功能:认证、授权和
传输层安全。
使用 Java Servlets 2.4 来执行过滤
Servlet API 很久以前就已成为企业应用开发的基石,而 Servlet 过滤器则是对 J2EE 家
族的相对较新的补充。在 J2EE 探索者 系列文章的最后一篇中,将向您介绍 Servlet 过
滤器体系结构,定义过滤器的许多应用,并指导您完成典型过滤器实现的三个步骤。
6.5 J2EE 最佳实践
在过去的几乎整整十年中,人们编写了很多有关 Java™ Platform, EnterpriseEdition (Java EE) 最佳实践的内容。现在有十多本书籍和数以百计(可能更多)的文章,
提供了关于应该如何编写 Java EE 应用程序的见解。事实上,这方面的参考资料如此之多,
并且这些参考资料之间往往还存在着一些矛盾的建议,以至于在这些混杂的内容中进行学
习本身也成为了采用 Java EE 的障碍。因此,为了给刚进入这个领域的客户提供一些简单
的指导,我们汇编了这个最重要的最佳实践列表,其中包括我们认为最重要和最有效的
Java EE 最佳实践。遗憾的是,我们无法仅在 10 大最佳实践中描述所有需要介绍的内容
因此,为了避免遗漏关键的最佳实践和尊重 Java EE 的发展,我们的列表中包含了“19
大”关键的 Java EE 最佳实践。
最重要的最佳实践
1. 始终使用 MVC 框架。
2. 不要做重复的工作。
3. 在每一层都应用自动单元测试和测试管理。
4. 按照规范来进行开发,而不是按照应用服务器来进行开发。
5. 从一开始就计划使用 Java EE 安全性。
6. 创建您所知道的。
7. 当使用 EJB 组件时,始终使用会话 Facade。
8. 使用无状态会话 Bean,而不是有状态会话 Bean。
9. 使用容器管理的事务。
10.将 JSP 作为表示层的首选。
11.当使用 HttpSession 时,尽量只将当前事务所需要的状态保存其中,其他内容不
要保存在 HttpSession 中。
12.充分利用应用服务器中不需要修改代码的特性。
13.充分利用现有的环境。
14.充分利用应用服务器环境所提供的服务质量。
15.充分利用 Java EE,不要欺骗。
16.安排进行版本更新。
17.在代码中所有关键的地方,使用标准的日志框架记录程序的状态。
18.在完成相应的任务后,请始终进行清理。
19.在开发和测试过程中遵循严格的程序。
6.6 J2EE 与 SOA
SOA 的引入首先对 Java EE 提出了挑战。在 SOA 中,交互通常产生很高的吞吐量,
并且由于要跨多个域到达服务端点,因此很可能会产生较高的延迟。一些交互可能还需要
得到操作人员的允许,而这种批准流程可能会产生几小时到几周的延迟。各种中间流程通
常会使延迟情况进一步恶化,SOA 的出现就是为了支持这些中间流程。
通过利用事务消息传递 API 并引入业务流程概念,Java EE 平台已经解决了延迟带来
的难题。SOAP-over-HTTP Web 服务调用模型和诸如 JMS 之类的消息传递服务之间一直不
太匹配。HTTP 使用同步请求/响应模型并且没有提供任何内置的可靠特性。诸如WS-
Notification、WS-Reliability、WS-ReliableMessaging 和 WS-ASAP 这些规范试图针对
部署在 B2B 环境中的 Web 服务解决这种错误匹配。但是对于 B2C 场景,通常部署的是富
应用程序客户机,因为这种客户机可以使用特定于场景的交互模式(相对于 Web 应用程
序)处理高延迟。6.7 J2EE 与 Web 2.0
很多成功的企业应用程序都是使用 Java EE 平台构建的。但是,Java EE 的设计原理
并不能够有效地支持 Web 2.0 应用程序。深入了解 Java EE 和 Web 2.0 原理之间的脱节
可帮助您制定明智的决策,从而使用各种方法和工具在一定程度上解决这种脱节。本文将
解答 Web 2.0 和标准 Java EE 平台缘何成为失败的组合,并演示为何由事件驱动的异步
架构更适合 Web 2.0 应用程序。本文还介绍了一些框架和 API,它们通过支持异步设计使
得 Java 平台更加适合 Web 2.0。
Java EE 平台的创建目的就是为企业到客户(B2C)和企业到企业(B2B)应用程序提
供支持。企业发现了 Internet 的价值之后就开始使用它增强与合作伙伴和客户之间的现
有业务流程。这些应用程序通常要与一个现有企业集成系统(EIS)进行交互。大多数常见
基准测试(测试 Java EE 服务器的性能和可伸缩性)— ECperf 1.1、SPECjbb2005 和
SPECjAppServer2004(参阅 参考资料)— 的用例都将这一点反映到了 B2C、B2B 和 EIS
中。类似地,标准的 Java PetStore 演示也是一个典型的电子商务应用程序。
Web 2.0 带来的巨变
Web 2.0 应用程序具有很多独特需求,因此,不适合将 Java EE 用于 Web 2.0 实现。
其中一个需求就是,Web 2.0 应用程序更多地通过服务 API 使用另一个 Web 2.0 应用程
序,而不是使用 Web 1.0 应用程序。Web 2.0 应用程序的一个更为重要的因素是,极度倾
向于用户到用户(C2C)交互:应用程序所有者只生成一小部分内容;用户负责生成大部分
内容。
SOA + B2C + Web 2.0 = 高延迟
在 Web 2.0 环境中,聚合应用程序经常使用通过 SOA 服务 API 公开的服务和提要
(参见 Java EE 迎合 SOA)。这些应用程序需要在 B2C 环境中使用服务。例如,一个聚
合应用程序可能从三个不同的数据源提取数据,如天气信息、交通信息和地图。检索这三
种独特数据所需的时间延长了总的请求处理时间。不管数据源和服务 API 的数量是否增加,
用户仍然期望得到具有高反应度的应用程序。
诸如缓存这类技术可以缓解延迟问题,但是不适用于所有场景。比如,可以缓存地图
数据来减少响应时间,但通常并不适合将搜索查询结果或者实时交通信息进行缓存。
服务调用本来就是一种高延迟过程,在客户机和服务器上通常只分配很小一部分 CPU 资源。
Web 服务调用的持续时间很大一部分用于建立连接和传输数据。因此,通常来讲,提升客
户端或服务器端的性能对于减少调用持续时间效果甚微。
更好的交互性
Web 2.0 对用户参与的支持引发了另外一大挑战,因为应用程序要处理来自每个活动
用户的更多数量的请求。下面这些理由证明了这一点:
因为大多数事件是由其他用户的操作引起的,因此会引发更多相关事件,并且用户
具备更强大的能力来生成事件。这些事件通常使用户能够更加积极地使用 Web 应
用程序。
应用程序为用户提供了更多的用例。Web 1.0 用户仅仅可以浏览类别、购买商品并
跟踪他们的订单处理状态。现在,用户可以通过论坛、聊天、聚合等等方法与其他
用户进行积极地交流,这将产生更高的通信负载。
如今的应用程序越来越多地使用 Ajax 改善用户体验。与普通 Web 应用程序的页
面相比,使用 Ajax 的 Web 页面加载要慢一些,因为页面是由一些静态内容、脚本(可能会非常大)和一些发往服务器的请求组成。加载完成后,Ajax 页面通常
会向服务器生成一些短小的请求。
与典型的 Web 1.0 应用程序相比,这些因素往往会生成更多的服务器通信量和请求数。
在高负载期间,这种通信量难于控制(然而,Ajax 也提供了更多的机会对通信量进行优化;
与支持相同用例的简单 Web 应用程序相比,Ajax 生成的通信量通常更少)。
更多内容
Web 2.0 的特征就是比上一代 Web 应用程序拥有更大量的内容和更大的规模。
在 Web 1.0 世界中,内容通常只有经过业务实体的明确允许后才被发布到公司网站。企业
需要控制所显示的文本的每个字符。因此,如果计划发布的内容超出了框架的大小限制,
则要对内容进行优化或将其分成几个较小的部分。
Web 2.0 站点的一个特性就是不会限制内容的大小或创建。大部分 Web 2.0 内容由用
户和社区生成。组织和企业仅仅提供工具实现内容创建和发布。由于使用了大量图像、音
频和视频,内容的大小也相应增加。
持久连接
建立客户机到服务器的新连接会耗费很多时间。如果某些交互在预期之中,则建立一
次客户机/服务器通信,然后重复使用该连接,这样做会获得更高的效率。持久连接对于发
送客户机通知也很有用。但是 Web 2.0 应用程序的客户机通常位于防火墙之后,一般很难
或不能直接建立服务器到客户机的连接。Ajax 应用程序需要发送请求轮询特定事件。要减
少轮询请求的数量,一些 Ajax 应用程序使用 Comet 模式(参见 参考资料):该服务器
被设计为在某个事件发生以前保持等待状态,然后发送应答,同时保持连接打开。
对等消息传递协议,如 SIP、BEEP 和 XMPP,逐渐使用持久连接。流式直播视频也从
持久连接中获益良多。
更容易发生 Slashdot 效应
Web 2.0 应用程序拥有大量的访客,这一点使某些站点更容易发生 “Slashdot 效
应” — 如果某个流行的 blog、新闻站点或社会型网站提及某个站点时,该站点的通信量
负载会猛增(参见 参考资料)。所有 Web 站点都应该准备好处理比普通负载高几个数量
级的通信量。这种情况下更重要的一点是,站点在如此高的负载下不会发生崩溃。
6.8 Struts VS Spring 两种 MVC 框架比较
基于Web的MVC framework在J2EE的世界内已是空前繁荣。TTS网站上几乎每隔一两
个星期就会有新的MVC框架发布。目前比较好的MVC,老牌的有Struts、Webwork。新兴的
MVC 框架有Spring MVC、Tapestry、JSF等。这些大多是著名团队的作品,另外还有一
些边缘团队的作品,也相当出色,如Dinamica、VRaptor等。这些框架都提供了较好的层
次分隔能力。在实现良好的MVC 分隔的基础上,通过提供一些现成的辅助类库,同时也
促进了生产效率的提高。
如何选择一个好的框架应用在你的项目中,将会对你的项目的效率和可重用是至关重
要的。本文将对目前最流行、最常用的两种framework进行介绍。
一、Struts
Struts是Apache软件基金下Jakarta项目的一部分。Struts框架的主要架构设计和
开发者是Craig R.McClanahan。Struts 是目前Java Web MVC框架中不争的王者。经过长达五年的发展,Struts已经逐渐成长为一个稳定、成熟的框架,并且占有了 MVC框架
中最大的市场份额。但是Struts某些技术特性上已经落后于新兴的MVC框架。面对Spring
MVC、Webwork2 这些设计更精密,扩展性更强的框架,Struts受到了前所未有的挑战。
但站在产品开发的角度而言,Struts仍然是最稳妥的选择。
Struts 有一组相互协作的类(组件)、Serlvet 以及 jsp tag lib 组成。基于
struts构架的web应用程序基本上符合JSP Model2的设计标准,可以说是MVC设计模式
的一种变化类型。根据上面对framework的描述,我们很容易理解为什么说Struts是一个
web framwork,而不仅仅是一些标记库的组合。但 Struts 也包含了丰富的标记库和独
立于该框架工作的实用程序类。Struts有其自己的控制器(Controller),同时整合了其
他的一些技术去实现模型层(Model)和视图层(View)。在模型层,Struts可以很容易
的与数据访问技术相结合,包括 EJB,JDBC和Object Relation Bridge。在视图层,
Struts能够与JSP, Velocity Templates,XSL等等这些表示层组件想结合。
Struts的体系结构
struts framework是MVC 模式的体现,下面我们就从分别从模型、视图、控制来看
看struts的体系结构(Architecture)。
从视图角度(View)
主要由JSP建立,struts自身包含了一组可扩展的自定义标签库(TagLib),可以简
化创建用户界面的过程。目前包括:Bean Tags,HTML Tags,Logic Tags,Nested Ta
gs,Template Tags 这几个Taglib。有关它们的详细资料请参考struts用户手册
从模型角度(Model)
模型主要是表示一个系统的状态(有时候,改变系统状态的业务逻辑操作也也划分到
模型中)。在Struts中,系统的状态主要有ActiomForm Bean体现,一般情况下,这些
状态是非持久性的。如果需要将这些状态转化为持久性数据存储,Struts本身也提供了
Utitle包,可以方便的与数据库操作
从控制器角度(Controller)
在Struts framework中, Controller主要是ActionServlet,但是对于业务逻辑
的操作则主要由Action、ActionMapping、ActionForward这几个组件协调完成(也许这几
个组件,应该划分到模型中的业务逻辑一块)。其中,Action扮演了真正的业务逻辑的实
现者,而ActionMapping和ActionForward则指定了不同业务逻辑或流程的运行方向。
对于Struts 如何控制、处理客户请求,让我们通过对struts的四个核心组件介绍来具
体说明。这几个组件就是:ActionServlet。Action Classes,Action Mapping(此处包
括ActionForward),ActionFrom Bean。
二、Spring
Spring 实际上是Expert One-on-One J2EE Design and Development 一书中
所阐述的设计思想的具体实现。在One-on-One 一书中,Rod Johnson 倡导J2EE 实用
主义的设计思想,并随书提供了一个初步的开发框架实现(interface21 开发包)。而Spring 正是这一思想的更全面和具体的体现。Rod Johnson 在interface21 开发包
的基础之上,进行了进一步的改造和扩充,使其发展为一个更加开放、清晰、全面、高效
的开发框架。
Spring是一个开源框架,由Rod Johnson创建并且在他的著作《J2EE设计开发编程
指南》里进行了描述。它是为了解决企业应用开发的复杂性而创建的。Spring使使用基本
的JavaBeans来完成以前只可能由EJB完成的事情变得可能了。然而,Spring的用途不仅
限于服务器端的开发。从简单性、可测试性和松耦合的角度而言,任何 Java应用都可以从
Spring中受益。
简单来说,Spring是一个轻量的控制反转和面向切面的容器框架。当然,这个描述有
点过于简单。但它的确概括出了Spring是做什么的。为了更好地理解Spring,让我们分
析一下这个描述:
1、轻量,从大小与开销两方面而言Spring都是轻量的。完整的Spring框架可以在一
个大小只有1MB多的JAR文件里发布。并且Spring所需的处理开销也是微不足道的。此外,
Spring是非侵入式的:典型地,Spring应用中的对象不依赖于轻量??从大小与开销两方面
而言Spring都是轻量的。完整的Spring框架可以在一个大小只有1MB多的JAR文件里发
布。并且Spring所需的处理开销也是微不足道的。此外,Spring是非侵入式的:典型地,
Spring应用中的对象不依赖于Spring的特定类。
2、控制反转??Spring通过一种称作控制反转(IoC)的技术促进了松耦合。当应用了
IoC,对象被动地传递它们的依赖而不是自己创建或者查找依赖对象。你可以认为 IoC与
JNDI相反??不是对象从容器中查找依赖,而是容器在对象初始化时不等被请求就将依赖传
递给它。
3、面向切面??Spring包含对面向切面编程的丰富支持,允许通过分离应用的业务逻
辑与系统服务(例如审计与事物管理)进行内聚性的开发。应用对象只做它们应该做的??
完成业务逻辑??仅此而已。它们并不负责(甚至是意识)其它的系统关注点,例如日志或
事物支持。
4、容器??Spring包含和管理应用对象的配置和生命周期,在这个意义上它是一种容
器。你可以配置你的每个bean如何被创建??基于一个配置原形为你的bean创建一个单独
的实例或者每次需要时都生成一个新的实例??以及它们是如何相互关联的。然而,Spring
不应该被混同于传统的重量的EJB容器,它们经常是庞大与笨重的,难以使用。
框架:Spring使由简单的组件配置和组合复杂的应用成为可能。在Spring中,应用
对象被声明式地组合,典型地是在一个XML文件里。Spring也提供了很多基础功能(事务
管理、持久性框架集成等等),将应用逻辑的开发留给了你。
所有Spring的这些特征使你能够编写更干净、更可管理、并且更易于测试的代码。它
们也为Spring中的各种子框架提供了基础。第 7 章 面向方面编程 AOP
7.1 引言
软件设计因为引入面向对象思想而逐渐变得丰富起来。“一切皆为对象”的精义,使
得程序世界所要处理的逻辑简化,开发者可以用一组对象以及这些对象之间的关系将软件
系统形象地表示出来。而从对象的定义,进而到模块,到组件的定义,利用面向对象思想
的封装、继承、多态的思想,使得软件系统开发可以向搭建房屋那样,循序渐进,从砖石
到楼层,进而到整幢大厦的建成。应用面向对象思想,在设计规模更大、逻辑更复杂的系
统时,开发周期反而能变的更短。自然其中,需要应用到软件工程的开发定义、流程的过
程控制,乃至于质量的缺陷管理。但从技术的细节来看,面向对象设计技术居功至伟。然
而,面向对象设计的唯一问题是,它本质是静态的,封闭的,任何需求的细微变化都可能
对开发进度造成重大影响。
可能解决该问题的方法是设计模式。GOF将面向对象软件的设计经验作为设计模式纪
录下来,它使人们可以更加简单方便地复用成功的设计和体系结构,帮助开发人员做出有
利于系统复用的选择。设计模式解决特定的设计问题,使面向对象设计更灵活、优雅,最
终复用性更好。然而,设计模式虽然给了我们设计的典范与准则,通过最大程度的利用面
向对象的特性,诸如利用继承、多态,对责任进行分离、对依赖进行倒置,面向抽象,面
向接口,最终设计出灵活、可扩展、可重用的类库、组件,乃至于整个系统的架构。在设
计的过程中,通过各种模式体现了对象的行为,暴露的接口,对象间关系,以及对象分别
在不同层次中表现出来的形态。然而鉴于对象封装的特殊性,“设计模式”的触角始终在
接口与抽象中大做文章,而对于对象内部则无能为力。
Aspect-Oriented Programming(面向方面编程,AOP)正好可以解决这一问题。它允
许开发者动态地修改静态的OO模型,构造出一个能够不断增长以满足新增需求的系统,就
象现实世界中的对象会在其生命周期中不断改变自身,应用程序也可以在发展中拥有新的
功能。AOP利用一种称为“横切”的技术,剖解开封装的对象内部,并将那些影响了多个
类的行为封装到一个可重用模块,并将其名为“Aspect”,即方面。所谓“方面”,简单
地说,就是将那些与业务无关,却为业务模块所共同调用的逻辑或责任,例如事务处理、
日志管理、权限控制等,封装起来,便于减少系统的重复代码,降低模块间的耦合度,并
有利于未来的可操作性和可维护性。
面向方面编程(AOP)是施乐公司帕洛阿尔托研究中心(Xerox PARC)在上世纪90年
代发明的一种编程范式。但真正的发展却兴起于近几年对软件设计方兴未艾的研究。由于
软件系统越来越复杂,大型的企业级应用越来越需要人们将核心业务与公共业务分离。AOP
技术正是通过编写横切关注点的代码,即“方面”,分离出通用的服务以形成统一的功能
架构。它能够将应用程序中的商业逻辑同对其提供支持的通用服务进行分离,使得开发人
员从重复解决通用服务的劳动中解脱出来,而仅专注于企业的核心商业逻辑。因此,AOP
技术也就受到越来越多的关注,而应用于各种平台下的AOP技术也应运而生。但由于AOP
技术相对于成熟的OOP技术而言,在性能、稳定性、适用性等方面还有待完善,同时 AOP
技术也没有形成一个统一的标准,这使得AOP技术的研究更具有前沿性的探索价值。7.2 什么是方面
在考虑对象及对象与其他对象的关系时,我们通常会想到继承这个术语。例如,定义
某一个抽象类 — Dog 类。在标识相似的一些类但每个类又有各自的独特行为时,通常使
用继承来扩展功能。举例来说,如果标识了 Poodle,则可以说一个 Poodle 是一个 Dog,
即 Poodle 继承了 Dog。到此为止都似乎不错,但是如果定义另一个以后标识为 Obedient
Dog 的独特行为又会怎样呢?当然,不是所有的 Dogs 都很驯服,所以 Dog 类不能包含
obedience 行为。此外,如果要创建从 Dog 继承的 Obedient Dog 类,那么 Poodle 放在
这个层次结构中的哪个位置合适呢?Poodle 是一个 Dog,但是 Poodle 不一定
obedient;那么 Poodle 是继承于 Dog 还是 Obedient Dog 呢?都不是,我们可以将驯服
看作一个方面,将其应用到任何一类驯服的 Dog,我们反对以不恰当的方式强制将该行为
放在 Dog 层次结构中。
在软件术语中,面向方面的编程能够独立于任何继承层次结构而应用改变类或对象行
为的方面。然后,在运行时或编译时应用这些方面。举一个关于 AOP 的示例,然后进行描
述,说明起来比较容易。首先,定义四个关键的 AOP 术语,这很重要,因为我将反复使用
它们:
接合点 (Joinpoint) — 代码中定义明确的可识别的点。
切点 (Pointcut) — 通过配置或编码指定接合点的一种方法。
通知 (Advice) — 表示需要执行交叉切割动作的一种方法
混入 (Mixin) — 通过将一个类的实例混入目标类的实例引入新行为。
为了更好地理解这些术语,可以将接合点看作程序流中定义好的一点。说明接合点的
一个很好的示例是:在代码调用一个方法时,发生调用的那一点被认为是一个接合点。切
点用于指定或定义希望在程序流中截获的接合点。切点还包含一个通知,该通知在到达接
合点时发生。因此,如果在一个调用的特定方法上定义一个切点,那么在调用该方法或接
合点时,AOP 框架将截获该切点,同时还将执行切点的通知。通知有几种类型,但是最常
见的情况是将其看作要调用的另一个方法。在调用一个带有切点的方法时,要执行的通知
将是另一个要调用的方法。要调用的这个通知或方法可以是对象中被截获的方法,也可以
是混入的另一个对象中的方法。我们将在后面进一步解释混入。
7.3 AOP:利与弊
一种常见的误解是认为 AOP 是截获,事实并非如此。但是,它确实运用了截获来应用
通知以及组合行为。有一些 .NET 代码示例通过 ContextBoundObject 以一种 AOP 翻版风
格说明截获。可是用 ContextBoundObject 来说明截获并不合适,因为使用这种方法的先
决 条 件 是 所 有 需 要 进 行 截 获 的 类 都 必 须 从 ContextBoundObject 继 承 。 像
ContextBoundObject 这样带有先决条件的 AOP 方法会带来需求产生的负面影响,所以在
AOP 中被视为重方法,应该避免使用。重方法在系统中遗留的大量“足迹”会潜在地影响
每个类,阻碍将来更改或修改系统的功能。
我创建了一个名为 Encase 的轻量型框架。用“轻量型”这个术语的意义是整体上对
系统没有影响。系统的不同部分仍然受 AOP 影响,但是选择轻量型框架并应用良好的编程实践可以减轻大部分负面问题。Encase 框架的用途是简化切点、混入和方面组合。开发人
员能够通过代码在 Encase 中应用方面,从而代替大多数其他轻量型 AOP 框架使用的配置
文件(例如 XML)。
重量型框架阻碍了 AOP 的应用,但是防碍 AOP 广泛应用的罪魁祸首是目前可用的
AOP 示 例 几 乎 都 都 包 含 以 下 内 容 : 执 行 方 法 前 先 截 获 , 并 应 用 执 行
Trace.WriteLine("Method entered.") 的方面。与普遍看法相反,除了日志记录、安全、
规范以及这类性质的事情外,AOP 对于解决其他问题也很有用。
7.4 Spring AOP: Spring 之面向方面编程
面向方面编程 (AOP) 提供从另一个角度来考虑程序结构以完善面向对象编程
(OOP)。 面向对象将应用程序分解成 各个层次的对象,而 AOP将程序分解成各个方面
或者说 关注点 。 这使得可以模块化诸如事务管理等这些横切多个对象的关注点。(这些
关注点术语称作 横切关注点。)
Spring 的一个关键组件就是 AOP 框架。 Spring IoC 容器(BeanFactory 和
ApplicationContext)并不依赖于AOP, 这意味着如果你不需要使用,AOP你可以不用,AOP
完善了Spring IoC,使之成为一个有效的中间件解决方案,。
AOP在Spring中的使用:
提供声明式企业服务,特别是作为EJB声明式服务的替代品。这些服务中最重要的是
声明式事务管理,这个服务建立在Spring的事务管理抽象之上。
允许用户实现自定义的方面,用AOP完善他们的OOP的使用。
这样你可以把Spring AOP看作是对Spring的补充,它使得Spring不需要EJB就能提
供声明式事务管理;或者 使用Spring AOP框架的全部功能来实现自定义的方面。
如果你只使用通用的声明式服务或者预先打包的声明式中间件服务如pooling,你可
以不直接使用 Spring AOP,并且跳过本章的大部分内容.
AOP概念
让我们从定义一些重要的AOP概念开始。这些术语不是Spring特有的。不幸的是,
Spring的术语 不是特别地直观。而且,如果Spring使用自己的术语,这将使人更加迷惑。
方面(Aspect): 一个关注点的模块化,这个关注点实现可能 另外横切多个对象。
事务管理是J2EE应用中一个很好的横切关注点例子。方面用Spring的 Advisor或拦截器
实现。
连接点(Joinpoint): 程序执行过程中明确的点,如方法的调 用或特定的异常被抛
出。
通知(Advice): 在特定的连接点,AOP框架执行的动作。各种类 型的通知包括
“around”、“before”和“throws”通知。通知类型将在下面讨论。许多AOP框架 包括
Spring都是以拦截器做通知模型,维护一个“围绕”连接点的拦截器 链。
切入点(Pointcut): 指定一个通知将被引发的一系列连接点 的集合。AOP框架必须
允许开发者指定切入点:例如,使用正则表达式。
引入(Introduction): 添加方法或字段到被通知的类。 Spring允许引入新的接口
到任何被通知的对象。例如,你可以使用一个引入使任何对象实现 IsModified接口,来
简化缓存。
目标对象(Target Object): 包含连接点的对象。也被称作 被通知或被代理对象。AOP代理(AOP Proxy): AOP框架创建的对象,包含通知。 在Spring中,AOP代理可
以是JDK动态代理或者CGLIB代理。
织入(Weaving): 组装方面来创建一个被通知对象。这可以在编译时 完成(例如使
用AspectJ编译器),也可以在运行时完成。Spring和其他纯Java AOP框架一样, 在运
行时完成织入。
各种通知类型包括:
Around通知: 包围一个连接点的通知,如方法调用。这是最 强大的通知。Aroud通知
在方法调用前后完成自定义的行为。它们负责选择继续执行连接点或通过 返回它们自己的
返回值或抛出异常来短路执行。
Before通知: 在一个连接点之前执行的通知,但这个通知 不能阻止连接点前的执行
(除非它抛出一个异常)。
Throws通知: 在方法抛出异常时执行的通知。Spring提供 强类型的Throws通知,因
此你可以书写代码捕获感兴趣的异常(和它的子类),不需要从 Throwable 或Exception
强制类型转换。
After returning通知: 在连接点正常完成后执行的通知, 例如,一个方法正常返回,
没有抛出异常。
Around 通知是最通用的通知类型。大部分基于拦截的 AOP 框架,如 Nanning 和
JBoss4,只提供 Around通知。
如同AspectJ,Spring提供所有类型的通知,我们推荐你使用最为合适的通知类型来
实现需 要的行为。例如,如果只是需要用一个方法的返回值来更新缓存,你最好实现一个
after returning 通知而不是around通知,虽然around通知也能完成同样的事情。使用
最合适的通知类型使编程模型变 得简单,并能减少潜在错误。例如你不需要调用在
around通知中所需使用的的MethodInvocation的 proceed()方法,因此就调用失败。
切入点的概念是AOP的关键,使AOP区别于其它使用拦截的技术。切入点使通知独立
于OO的 层次选定目标。例如,提供声明式事务管理的around通知可以被应用到跨越多个
对象的一组方法上。 因此切入点构成了AOP的结构要素。
Spring AOP的功能
Spring AOP用纯Java实现。它不需要特别的编译过程。Spring AOP不需要控制类装
载器层次, 因此适用于J2EE web容器或应用服务器。
Spring目前支持拦截方法调用。成员变量拦截器没有实现,虽然加入成员变量拦截器
支持并不破坏 Spring AOP核心API。
成员变量拦截器在违反OO封装原则方面存在争论。我们不认为这在应用程序开发中是
明智的。如 果你需要使用成员变量拦截器,考虑使用AspectJ。
Spring提供代表切入点或各种通知类型的类。Spring使用术语advisor来 表示代表
方面的对象,它包含一个通知和一个指定特定连接点的切入点。
各种通知类型有 MethodInterceptor (来自 AOP 联盟的拦截器 API)和定义在
org.springframework.aop 包 中 的 通 知 接 口 。 所 有 通 知 必 须 实 现
org.aopalliance.aop.Advice标签接口。 取出就可使用的通知有 MethodInterceptor、
ThrowsAdvice、 BeforeAdvice和 AfterReturningAdvice。我们将在下面详细讨论这些通
知类型。
Spring 实 现 了 AOP 联 盟 的 拦 截 器 接 口 (
http://www.sourceforge.net/projects/aopalliance). Around通知必须实现AOP联盟的org.aopalliance.intercept.MethodInterceptor 接口。这个接口的实现可以运行在
Spring或其他 AOP联盟兼容的实现中。目前 JAC实现了 AOP联盟的接 口,Nanning和
Dynaop可能在2004年早期实现。
Spring实现AOP的途径不同于其他大部分AOP框架。它的目标不是提供及其完善的
AOP实现( 虽然Spring AOP非常强大);而是提供一个和Spring IoC紧密整合的AOP实
现,帮助解决企业应用 中的常见问题。因此,例如 Spring AOP的功能通常是和Spring
IoC 容器联合使用的。AOP 通知是用普通 的 bean 定义语法来定义的(虽然可以使
用"autoproxying"功能);通知和切入点本身由Spring IoC 管理:这是一个重要的其他
AOP实现的区别。有些事使用Spring AOP是无法容易或高效地实现,比如通知 非常细粒
度的对象。这种情况AspectJ可能是最合适的选择。但是,我们的经验是Spring针对J2EE
应 用中大部分能用AOP解决的问题提供了一个优秀的解决方案。
Spring中AOP代理
Spring默认使用JDK动态代理实现AOP代理。这使得任何接口或 接口的集合能够被代
理。
Spring也可以是CGLIB代理。这可以代理类,而不是接口。如果业务对象没有实现一个接
口, CGLIB被默认使用。但是作为一针对接口编程而不是类编程良好实践,业务对象 通
常实现一个或多个业务接口。
也可以强制使用CGLIB:我们将在下面讨论,并且会解释为什么你会要这么做。
Spring 1.0后,Spring可能提供额外的AOP代理的类型,包括完全生成的类。这将不
会影响 编程模型。
第 8 章 基于组件的软件工程-软件开发新
挑战
8.1 软件开发面临的挑战
我们目睹了软件在商业、工业、管理和研究领域日益膨胀的应用。软件已不再处于技
术体系的边缘,已成为许多应用领域中的重要因素。软件的功能而不是其他特性的系统特
征,在竞争中日渐成为市场上的决定性因素,如在汽车行业、服务行业和教育领域等。日
益增长的软件用户并不都是专家,这些趋势对软件提出了新的要求。可用性、稳健性、易
于安装和集成性正变为软件最为重要的特征。由于软件可用性涉及领域很广,不同领域中
对集成的要求呈现增长趋势。我们把在不同管理层次的数据和过程集成方式称为垂直统一
管理,把来于不同领域的相类似的数据类型和过程的集成称为横向结合。例如,在工业自
动化处理中,采自管理的最低层面(田疃管理)中处理过程的数据被直接控制,然后在车
间层面(加工管理)被综合,最后进行更进一步的处理。这种处理主要是分析和结合市场提供的数据进行整合,最后在网络上发布(商务管理)。
这一系列变动导致了软件变得越来越庞大和复杂。传统上,软件开发致力于处理日益
增长的复杂性和作为一个系统对外部软件、交付期限和资金预算的依赖,往往忽略了系统
进化或升级方面的要求。这已导致了一系列的问题:大多数项目不能在交付期限内完成,
超出了预算,不能达到质量要求和持续增长的软件维护费用。为了应对这样的挑战,软件
开发应该能够处理软件的复杂性,并能迅速的接受新的挑战。如果新的软件产品在开始开
发时就是乱写(没有规划和分析),那么他们肯定达不到最后的目标。解决这类问题的关
键是可重用性。从这个角度上看,基于组件的软件开发(CBD)应该是最好的解决途径。这
包括对软件复杂性更有效率的管理,快速地推向市场,更高的生产力(开发效率),提高
的质量,更为连贯的一致性和更为广泛的可用性。
8.2 基于组件的开发中有几个危及其成功的不利因素
开发组件所需要的时间和精力。在所有阻碍可重用组件开发的因素中,比较重要的是
对时间和精力增长的需求。构建一个可重用的组件需要三至五倍于开发满足特定需要组件
的时间和精力。
不确定和模糊的需求。通常,需求管理是开发过程中一个重要的方面。其主要目的是
定义一个一致和完整的组件需求。可重用组件被定义,然后应用在项目中,其中一些应用
和需求难以预见,包括功能性和非功能性的。
可用性和可重用性的冲突。为了更为广泛的应用,一个组件必须足够的全面综合、可
升级和易于维护,这导致了组件更为复杂(给使用也带来了一定的难度),对计算资源更
多的消耗需求(使用所需要的花费也上升了)。对可重用性的需求可能导致转向其他的开
发途径,如采用一个新的较为抽象的开发层次,这会减少弹性和可微调性,但更好的实现
了简洁性。
组件维护所需的花销。应用软件维护所需要的花费可能会很低,但组件维护所需要的
花费会很高。这是因为组件必须和在不同环境下的不同应用的不同需求相一致,这包括不
同的可依赖性的需求和可能需要不同级别维护支持的需求。
可靠性和对挑战的灵敏性。由于组件和应用软件有独立的生命周期和不同种类的需求,
所以存在组件不能完全满足应用软件需求或可能具有某些应用软件开发者也不确定的隐藏
特征的风险。在介绍应用程序级别的挑战中(比如操作系统的更新,其他组件的更新,应
用软件的挑战等等),以上介绍的挑战可能导致系统崩溃的风险。为了充分利用他的优点
并努力避免风险和问题,我们需要一个系统化途径去实现在不同处理过程和技术层次中基
于组件的软件开发.
8.3 基于组件的软件工程
通过组件开发软件的这个观念并不是新出现的。对一个复杂软件系统的传统设计总是
从定义组成子系统的部件和模块等开始的,其中包括更低层次的模块,类,过程等等。软
件开发中的重用机制已经被使用了很多年了。但是,最近出现的基于组件开发的新技术已
进一步地增加了利用可重用组件来构建系统和应用软件的可能性。客户和供应商都对 CBD
(基于组件开发)开发模式有很高的期望,但他们的期望并不总是得到满足。经验证明,
基于组件的软件开发需要一个系统性方法,需要致力于软件开发中的组件方面。传统的软
件工程学科必须要适应这种新的方法,新的处理过程也必须得以开发。基于组件的软件工程已作为一个新的软件工程子学科受到认可。
基于组件的软件工程的主要的目的是对软件开发所提供的支持,这种开发将系统作为
组件集成体,将组件作为可重用实体来看待,通过定制和更换组件来实现维护和更新。系
统由组件来构建和满足不同系统应用的组件开发需要成熟的方法学和处理过程,这种处理
不仅与开发和维护等方面相关,而且与组件和系统的整个生命周期中包括组织、市场、法
律和其他因素在内的方面相关。对应用软件来说,在基于组件的开发中除了一些具体的基
于组件的软件工程目标如组件规格、综合约束和技术外,还有一些其他的软件工程学科和
处理需要详细的方法和规范。其中许多方法学还没有在应用中成熟,一些甚至还没有开发
出来。未来不久的软件开发过程将会更多地取决于CBSE(基于组件的软件工程)的成功确
立,这已得到工业界和学术界双方的认可。现在很多涉及CBSE和CBSE实现等方面的议程
软件工程会议召开的越来越频繁。引用Gartner Group的话说,就是“截至2002年,所有
新应用软件的70%将会采用基于组件的开发模式来构建软件的模块。”
8.4 组件规范
为了对基于组件的开发有一个整体的理解,我们应该先弄清的一个要点究竟什么是组
件而什么称不上是组件。作为一个术语,它的概念相当清晰--组件是一个系统的一个组成
部件,但这个概念因为太含糊而对人理解起来没什么用处。尽管组件的定义已被广泛的讨论
过,我们将采用广为人们使用的Szyperski's的说法:软件的组件是一个综合体的一个单
元,这个单元只有约定的指定接口和对外部环境的依赖。一个软件的组件可以被独立地配
置,它受第三方组合的制约。
组件最重要的特征是具有独立于应用的接口。这种独立不同于我们常见的那些编程语
言(如ADA或Modula-2)中定义和执行的独立,也不同于那些面向对象的编程语言中类的
定义和类的执行相互独立。我们要确保组件被集成综合到一个应用软件与组件的开发生命
周期相互独立,同时在应用软件更新一个组件时,相关组件不需要重新编译或者连接加载
就可以使用。独立的另一个重要特色是组件的执行只有通过它的接口才可见,这对于由第
三方发布的组件来说尤其重要。这意味着对组件具有详细完整的规范有相当的要求,这些
规范包括功能性和非功能性的,用例,测试等等。尽管现在的基于组件开发技术成功了实
现了对功能性接口的管理,但对组件其他方面规范的管理并没有达到另人满意的程度。
以上采用的组件定义关注组件的应用。它对组件如何定义,应用和如何规范组件涉及
较少,但是我们可以参考那些关注组件其他方面的基于组件的开发。例如,OOP(面向对象
编程)与组件有很强的联系。组件模型(或者称为组件规范)COM/DCOM,.NET,EJB(企业
级Java Beans)和CCM(CORBA组件模型)的组件接口都与类的接口有联系。组件采用了
面向对象原则的方法和数据封装的原理。Cheesman and Daniels认为一个组件在其生命周
期中可以有以下几种存在方式:组件规范详述(组件的特点和方法),组件接口(规范的
一个方面,是组件行为的定义),组件的执行(组件规范的实现),组件的生成(组件执
行的配置实例)和组件对象(已生成对象的实例)。并不是所有的研究者都认为组件是
OOP(面向对象编程)的扩展。相反,他们认为组件和对象之间的差别在于对象有声明,是
实例的个体,而组件没有独立的声明,是配置个体。
在学术界和工业界,对CBD也有不同的理解。学术界的研究者把组件看为定义良好的实体
(常常较小,有容易理解的功能性和非功能性的特点);而工业界把组件视为一个系统的
可重用部件,它不必定义为具有清晰的接口和与组件类型高度的一致性。一个组件可以是
系统无组织的部件,但它的改动可能需要不少精力。鉴于组件越大,它们在被重用时可能
表现出来的性能就越好,这样的组件(或叫可重用实体)很重要。组件规范仍然作为一个话题在研究。组件标准主要集中在接口定义上,非功能属性在
独立文档中被非正式定义(如果全部指定了的话)。通过收集功能性特色和设计特性,在
本方面上的一些改进促使了微软的组件模型.NET的产生。
8.5 基于组件系统开发生命周期
CBSE强调需求、挑战和类似于其他软件工程方法中也常遇到的问题。很多方法、工具
和软件工程准则可以采用同样或类似的方法在其他软件系统开发中得以应用,但应该注意
的一个不同是CBSE包含了组件开发和系统采用组件开发。在需求和商业想法上这两种情况
下有略微的不同,而这种不同的方法确是必需的。当然,在开发组件时,其他的组件可以
(常常必须)合成一体,但主要的重点还是在重用性上:组件是为在很多应用软件中被采
用和重用而开发,其中一些应用软件甚至还不知道是什么,或者根本不存在。一个组件必
须有良好定义,易于理解,足够的综合,易于改进和展开,并要易于取代。组件的接口一
定要尽量简单和相对于应用软件的严格独立(无论是物理上还是逻辑上)。鉴于开发成本
必须在将来的赢利中考虑赚回,市场因素在其中也扮演了很重要的角色,这对COTS(用户
定单跟踪系统)来说尤其如此。但是在开发组件时最主要的问题还是需求和 COTS选择的获
取,因为这个过程包含了基于多方标准做的决定。如果处理过程从需求的选择开始,就很
可能发现一个满足所有要求的COTS是不可能存在。如果组件在处理过程中被过早地选择,
所得的系统很可能不满足所有的要求。
组件的开发集中精力于重用实体和实体间关系的识别上,开始于系统需求的获取。早
期的设计过程包含两个非常重要的步骤:首先,对系统体系在功能性组件和他们之间交互
关系方面的详述,这为我们提供了对系统体系的宏观把握;第二,系统体系在物理组件方
面的规范详述。
软件工程中建立的不同的生命周期模型可以在 CBD中被采用。这些模型将被修正以强
化以组件为中心的活动。让我们试想如果瀑布模型极端地采用了基于组件的方法将会怎样
图一显示了瀑布模型和相关阶段的描述。识别需求和瀑布过程在发掘和选择组件时结合起
来。设计包含了系统体系设计和组件识别/选择。
基于组件的系统开发过程不同处如下:
发掘可以为本系统所采用的组件。所有可能的组件在这里被列出来,以备将来调查研
究使用。为了更好地处理这个过程,必须要有大量能使用并可能被采用的侯选组件和用以
寻找它们的工具。这不单是技术问题,还是商业问题。
选择那些满足系统需求的组件。通常不是所有的要求都能得到满足,这时就需要综合
权衡来协调软件系统体系以调整软件的需求,好尽可能地采用现有的组件。
可选的,创建一些只为本系统使用的组件。在基于组件的开发过程中,这个过程需要较少
的精力和时间,也乏吸引性。但由于含有产品核心功能的组件要提供具有竞争性优点的产
品,它们趋于在内部开发。
改编选中的组件以让它们适应现存的组件模型和需求规范。一些组件可能会被直接集
成到系统中,一些可能在含参数处理过程中被改进,还有一些可能需要为改编附加一些代
码。采用组件专用的框架排版并配置这些组件。往往由组件模型来提供这些服务。
用新版本的组件代替旧版本的组件。这和系统维护相对应。漏洞将会降低,并会加进
新的特色。
还有很多CBD其他方面需要特定的特殊的方法,技术和管理。例如,开发环境工具,
组件模型及其应用支持,软件配置管理,测试,软件美感,法定发行,项目管理,开发过
程,事务规范和确认等等。在这些领域的详细讨论超出了本文的范畴,下文我们将会介绍软件体系和CBD之间的关系。
8.6 软件体系和基于组件的开发
软件体系和组件有密切的联系。所有软件系统都有一个可视为将系统分解成组件及其
关系的体系。一个常见的软件体系的定义是:“一个项目或计算系统的软件体系结构是系
统体系的系统结构,这一系统结构含有软件的组件及这些组件尽可能可见的属性和其间关
系。”一般来说,软件体系结构在前期设计阶段处于中心位置,前期整个系统结构被设计
来满足功能性和非功能性需求。在单个大型应用中,在设计过程中的体系规范在执行期间
作为可执行代码隐藏起来。组件技术致力于在接近或正值执行期间合成和配置。在一个基
于组件的系统中,体系结构在应用和执行期间仍然可辨。基于组件的软件工程包含组件和
基于组件系统的整个生命周期,而各处理过程正好包含在这些生命周期中。
传统上,软件的设计开始时先决定它的体系,从小的部件来构建系统,并尽可能的独
立来完成这些工作。构建的第一个阶段是功能性体系的设计。第二个阶段是软件体系的评
估,在此阶段软件的体系结合相应质量需求被估值。一旦软件体系被定义了,组成系统的
组件必须被开发或者选择。我们可以结合系统的需求来区分不同的组件种类:特定用途的
组件,本系统已开发的特定组件,精简的组件,内部开发的多用组件和终态商业组件
(COTS)。预存的组件往往要在集成到系统前用特定的衔接代码连接,要么组件本身要做
一些修正。这种自上向下的开发方法保证了需求的满足和实现,至少能对需求的实现起到
更好的控制作用。但是,这种途径并不鼓励重用预存的组件,特别是商业组件,因为很可
能发生现存的组件不能很好适应系统的情况。另一种方法是自下向上和自顶向下方法的结
合,这种方法开始于系统需求和对可能的侯选组件分析。组件规范和选择对最后的需求和
系统机构有一定的影响。这种情况下,软件体系主要关心识别优化给定组件之间关系的方
式。既然对系统体系和组件技术来说基本的成品是组件,那么他们的组合很自然地就会合
并,这要通过一些常用技术,方法和工具。体系描述语言 ADLS如ACME,可以用来设计基
于组件的系统,并应用于现存的组件模型中。
软件体系常和协定和分析过程相关。经验证明,很多大型软件系统的属性主要存在系
统软件体系中。在这些系统中,质量品质的程度更多的取决于整个软件体系,而非编程方
面如编程语言的选择,详细设计,算法,数据结构,测试等等。这样的分析有以下几种方
法,例如SAAM(软件体系分析方法)和ATAM(体系折中分析方法)。ATAM和SAAM都基于
特定的方法。但是,ATAM专注于多种质量属性(修正,可用,安全和性能),它的目的是
查找定位并分析协定软件体系,这不同于SAAM。组件有预先定义的属性,其中一些只为组
件所有;但有一些在组件合成时才显现出来。平衡分析可以帮助选择合适的组件并预见组
件合成时其他属性。同时,含有现存组件为分析可能生效的范围限定了范围。例如,一个
侯选组件的特点可以是高度的可重用性,但可能会有低下的性能。而其他的一些侯选组件
可能会有较高的性能,但可重用性不高。体系分析可以在我们选择组件时帮助我们作决定。
软件体系和CBD在软件生产线开发中得到成功应用,并发布了很多种类的产品。代表
产品含有一套核心组件和一系列附加组件。基于组件的方法和系统设计在产品配置管理中
发挥了重要的作用。
8.7 UML 和基于组件的系统模型
正如[21]所示,UML(统一建模语言)可以被用于组件和系统建模。组件驱动设计致力于接口定义和组件通过接口的协作。设计过程接下来是采用物理组件的系统建模,其中物
理模型不一定要和逻辑结构相一致。或许会有现存的组件,这些组件有详细说明的接口,
但或许需要包装。在第一设计阶段识别的逻辑组件可能含有几个物理组件。最终,形成了
一个配置方面的问题,在这里组件在分布式应用中会在不同的电脑中运行。在非基于组件
的开发方法中,第一阶段即设计阶段是非常重要的,在概念和执行层次之间的映射是直接
映射;对整个应用软件来说,配置阶段也是一样的。理论上,UML可以被用来为设计基于
组件的系统提供以上各个方面的支持。接口表现为多用子系统(或称多用接口可以被子系
统实现),这说明了在不改变接口的情况下改变执行是可能的。一个接口可以通过以下两
种形式表示(如图2),其中第二个途径是比较常见的。
图3展示了系统结构的三个方面。概念体系是对系统自上而下分析和设计的结果,至
少第一步和非基于组件设计没什么不同。在概念部分,组件被 UML包用<> 套用表达。在执
行体系部分,物理组件用UML组件和<> 套用表达。注意,执行部分并不是对概念层次唯一
改进的地方,结构也可能被改变。例如,不同的包可以含有同样的物理组件,也可能出现
组件选择需要改进概念体系的情况。
尽管如此,UML并不是专门为CBD设计的,而标准UML(如名字协定,原型)也需要进
行一些扩展。组件接口不能像直接使用时一样在用 UML描述时达到如此详细的程度。正因
为如此,UML存在扩展,如Catalysis[33]。对UML应用到CBSE,更进一步的工作要做。下
一主要的UML版本(UML2.0)包含了对一些扩展的建议,如EJB,数据模型实体,实时组
件,XML组件等等。很多这些都直接和CBSE相关。
8.8 CORBA 与 DCOM 技术
8.8.1 分布式对象技术
1. 微软的COM/DCOM
在20世纪90年代初 ,微软就提出了功能强大的对象链接与嵌入(Object Linking
and Embedding, OLE)标准,并立即意识到要想有效地发展 OLE技术,需要一种包装组
件的标准。跨语言互操作性依然是至关重要地,为了保证这些组件能够运行在不同的语言
环境中,并最终整合为任意的风格,微软创建了组件对象模型(Component Object
Model,COM),COM为实现OLE可视化提供了基础设施。随着时间的推移,COM演变为
多种技术的基础。依赖 COM 的最重要的新技术之一就是 OCX 控件(OLE Custom
Control)。
1996年微软宣布:ActiveX将成为主要基于COM的这类技术的新名称。从此微软将名
词ActiveX与先前的OCX联系在一起。COM在非Windows平台上的应用进展缓慢。因为
平台支持的有限,COM更多地被看成是严格组件体系结构,而不是一个远程体系结构。
到1996年底,微软又引入分布式组件对象模型DCOM(Distributed Component Object
Model)。DCOM是一套基于RPC机制的COM技术扩展,它使COM对象具有分布式功能。
它扩展了组件对象模型技术(COM),使其能够支持在局域网、广域网甚至Internet上不同
计算机的对象之间的通讯。由于COM位置透明性的特性,对于已有的COM组件无须更改
一行代码就可以转变成DCOM组件,只须修改COM组件服务器的信息。转化为DCOM组件时,对于原先的本地可执行组件,可以在远程计算机上启动,而远程启动并调动DLL组
件,则需要一个额外的DLL代理(COM提供了一个默认DLL代理dllhot.exe),DLL组件就被
运行在该DLL代理的地址空间中;另外DCOM必不可少的有接口调度问题。[8.1]
由于DCOM是COM的直接发展 ,所有的基于COM的应用程序、构件、工具和知
识都可以不加任何变化的直接使用。DCOM具有如下特点 :
(1)规模可变;
(2)在构件之间提供丰富的、均衡的通信;
(3)很容易扩展新的功能;
(4)拥有大量现成的构件;
(5)有效使用网络带宽 ,给最终用户提供良好的响应;
(6)固有的安全性;
(7)自动的负载平衡和容错能力;
(8)容易进行有效的配置和管理;
(9)支持任何网络协议;
(10)使用TCP /IP协议。
2. CORBA
CORBA(Common Object Request Broker Architecture, 公共对象请求代理体系结
构)是由OMG(对象管理组织,Object Management Group)提出的应用软件体系结构
和对象技术规范,其核心是一套标准的语言、接口和协议,以支持异构分布应用程序间的
互操作性及独立于平台和编程语言的对象重用。由于这是个平台无关的对象交互标准,所
以得到了业界的广泛认同。
OMG是一个由业界七百六十多个公司组成的工业协会,这些公司成立 OMG的目的就
是为了共同制定出一个大家都遵循的分布式对象计算标准。OMG的目的则是为了将对象和
分布式系统技术集成为一个可相互操作的统一结构,此结构既支持现有的平台也将支持未
来的平台集成。而这一切所有努力的结果就是现在大家所见到的对象管理体系(OMA)。
CORBA说明了OMA的基础——“对象请求中介”(ORB)标准,在ORB标准中,不仅
提供了CORBA基础架构说明并且还提供了一系列服务,例如安全、交易和消息传递等。
CORBA从一开始的目标就是为了解决机器间通信的问题,因此它是一种远程体系结
构。CORBA规范概括了在相同或不同机器上的进程间进行通信的基础设施。方法以透明
的方式调用CORBA对象,因此调用者并不知道被调用程序的具体位置。在 CORBA的早
期版本中,组件的保证并不是首要目标,但是,CORBA的确提供了跨语言、跨平台、甚
至跨开发商的互操作性。因为许多开发商在如大型机、UNIX和基于Windows的平台商实
现了CORBA规范,所以CORBA已经成为了目前使用的主流远程体系结构。
为了提供丰富的服务器组件框架,针对 CORBA模型的规范还将提供到 Enterprise
JavaBeans (Sun公司的基于Java的服务器端组件模型)的映射。这种映射使得Enterprise
JavaBeans能够在一个CORBA组件容器内使用,该容器提供激活、事务处理、安全性、事
件以及持久性等服务。
CORBA使应用程序能够使用一个共同的接口,这个接口可以在多种平台和多个开发
工具中用接口定义语言(IDL)来说明。OMG IDL是平台和语言无关的;而数据及调用格
式的转换则是由ORB透明地完成。所有的CORBA对象接口,以及接口中相关的数据类型,
都可以由接口定义语言(IDL)说明。这种对接口的公共定义方法使应用程序能够在不涉
及到对象的具体运行方式时对对象进行操作。
从客户端角度来看,一个CORBA对象是十分模糊的,所以某个对象的执行地点和执行细节对于使用它的应用程序来讲都是不可见的。一般来讲,一个CORBA客户仅仅需要
知道怎样通过一些公共的对象接口,例如查询对象接口,来发现或者创建自己的需要使用
的对象。[2]这种情况下,客户程序很可能对对象的执行地点是一无所知的,而作为客户使
用对象的调用依据并不是对象的具体地点,而是各个对象在 CORBA命名服务[COSS 97]中
的对象别名。所以,客户程序所仅能知道的,就是CORBA对象的公共接口,通过这个接
口,客户程序就可以调用对象的方法和功能。CORBA还支持运行时的对象接口动态定义、
通过它的接口库(IR)进行接口选择调用、以及动态调用接口(DII)。不过,虽然这些特
点为程序在运行时访问CORBA对象提供了几乎是完全的动态配置能力,但是在实用中由
于语义上的障碍,这些特性实际上仅在少数场合才有其用武之地。
3. IBM的SOM/DSOM
IBM早在20世纪90年代初就引入了系统对象模型(System Object Model, SOM)。
与微软的COM类似,SOM是一个能够提供跨语言互操作的、具有包装组件标准机制的组
件体系结构。随后在SOM中还加入了网络扩展功能。最终产生了分布式SOM(Distributed
SOM, DSOM)。
但在IBM之外,SOM作为组件体系结构从来没有得到过广泛的认可。主要原因有以
下两点。首先,IBM的OS/2不是主流操作系统。其次,IBM的SOM在基于Windows的操
作系统上无法与微软的COM/OLE相抗衡。
8.8.2 CORBA 的设计模式
CORBA在提高组件重用性、增强分布计算功能方面具有的突出特点:
(1)引入中间件作为事务代理;
(2)客户程序与服务器程序完全分离;
(3)与面向对象的建模概念相结合;
(4)引入接口定义语言描述服务对象功能。
CORBA规范只是描述了CORBA系统中各个构件的基本情况以及构件在系统中承担的
任务,并没有从功能实现的细节上规定必须如何建立一个基于CORBA规范的软件系统产
品。这样,对于基于CORBA的软件产品开发而言,程序设计人员可以自由地选择实现方
式,但前提是遵循规范中各个构件的实现原则。在本节中,将详细介绍CORBA中各个构
件的主要内容。
1.对象请求代理(ORB)
目前已有许多支持CORBA标准的ORB产品出现。OMG为解决分布计算系统的
异构性提出了对象管理架构OMA ,其核心是提供一条软件总线来规范和容纳不同软件模
块之间的通信与协作 ,这条软件总线就是对象请求代理。其作用是透明地为对象请求找出
路径 ,准备对象的实现以接受请求 ,与提出请求所需的数据进行通信。对位于本地或远方的
请求 ,ORB能透明地予以响应 ,不需要客户关心服务对象在什么地方 ,以及有关对象的通
信、激活和存储的机制。这为异构环境下分布对象的互操作奠定了基础。ORB由接口给
予定义 ,可以有多种实现。
(1)对象请求代理(ORB,Object Request Broker)的作用
在传统的基于客户机/服务器模式的应用程序开发过程中,项目开发人员遵循公开的标
准或自由设计模块间的协议,这样的协议依赖于网络类型、实现语言、应用方式等。引入ORB后,客户只要遵循服务对象的对外接口标准向服务对象提出业务请求,由ORB在分
布式对象间建立客户-服务对象关系。总结起来,ORB的作用包括:
① 接受客户发出的服务请求,完成请求在服务对象端的映射;
② 自动设定路由寻找服务对象;
③ 提交客户参数;
④ 携带服务对象计算结果返回客户端。
客户(Client)向服务对象的实现(Object Implementation)发出事务请求,其中客
户是欲对服务对象发出方法请求的实体,服务对象应包括该方法的数据资源以及实现代码
对象请求代理的作用就在于定位服务对象,接收客户发出的服务请求并将服务对象的执行
结果返回给客户。请求发出后,客户对象采用轮询等方式以获取服务对象计算的结果。
(2)ORB的结构及类型
ORB通过一系列接口和接口定义中说明的要实现操作的类型,确定提供的服务和实现
客户与服务对象通信的方式。通过 IDL接口定义、接口库或适配器(Adapter)的协调,
ORB可以向客户机和具备服务功能的对象实现(Object Implementation)提供服务。作
为CORBA体系结构的核心,ORB可以实现如下三种类型的接口:
① 对于所有的ORB实现具有相同的操作;
② 针对特定类型对象的操作;
③ 与对象实现类型有关的操作。
基于ORB实现的不同类型接口,一个客户端请求可以同时访问多个由不同 ORB实现
通信管理的对象引用。在实际应用中,只要遵循公共的ORB体系结构,程序设计可以选择
ORB的多种实现方式,其中包括:
a.客户和实现驻留(Client-Implementation Resident)ORB:采用驻留在客户和
服务对象实现程序的方式实现ORB。在这种实现方式下,客户端可以通过存根
(Stub)程序,以位置透明的方式向具体的实现对象提出服务请求,实现客户与
服务对象的通信。
b.基于服务(Server-based)ORB:客户对象和实现对象均可以与一个或多个服务
对象进行通信,服务对象的功能是将请求从客户端发送到对象实现。在这种方
式中,ORB的作用是完成客户对象与实现对象的通信,为对象之间的交互提供
服务。
c.基于系统(System-based)ORB:在这种实现方式中,ORB被操作系统认为是
系统所提供的一项基本服务。由于操作系统了解调用方与服务对象的位置,因
而可以充分地实现ORB功能的优化。
d.基于库(Library-based)ORB:如果认为对象实现可以共享,则可以将实现功能
放入实现库(Implementation Repository)中,从而创建基于库的ORB。
(3) ORB中的主要方法
客户端和服务对象端均可以自由选择使用ORB对象中定义的方法来实现操作。下面举
例说明ORB对象中的重要方法:
① ORB ORB_init(inout arg_list argv,in ORBid orb_identifier)
作用:ORB初始化方法。
② String object_to_string(in Object obj)
作用: 将对对象的引用转换成客户可以用字符串方式存储的对象信息。
③ Object string_to_object(in String str)
作用:上述方法的逆过程。将以字符串方式存储的对象转换成对对象类型的引用。
④ Object resolve_initial_references(in ObjectID identifier)作用:获取初始对象引用。
⑤ Policy get_policy(in PolicyType policy_type)
作用:返回指定类型的服务策略对象。
作为公共对象请求代理体系结构中的核心内容,ORB提供了相当丰富的方法。读者可
以查阅相关资料详细了解ORB中的方法。[8.4]
2.服务请求的实现方式
关于对象请求的实现方式,CORBA规范中定义客户程序可以用动态调用接口(DII,
Dynamic Invocation Interface)方式或通过OMG IDL文件经编译后在客户端生成的存
根(Stub)方式提出服务请求。这两种实现方式的区别在于通过 OMG IDL 存根
(Stub)文件方式实现的调用请求中,客户能够访问的服务对象方法取决于服务对象所支
持的接口;而动态调用接口调用方式则与服务对象的接口无关。尽管实现调用请求的方式
有所区别,但客户发出的请求服务调用的语义是相同的,服务对象不去分析服务请求提出
的方式。
ORB通过IDL客户存根(Stub)方式或动态调用接口(DII)方式定位服务对象的实现
代码、传递服务对象应用参数以及完成对请求传送方式的控制。服务对象的实现(Object
Implementation)通过对象适配器(Object Adapter)提供对客户请求的服务。
服务对象接口的定义在整个CORBA系统服务功能的实现中起着相当重要的作用。那
么如何实现服务对象的功能接口呢?CORBA规范中定义了两种接口实现方式:第一种形
式是利用OMG IDL接口定义语言对接口进行描述。IDL语言有详细的语法规则(讲座将
在第五讲对该语言的语法规则进行详细讲解)。这样,经过对所实现功能的系统分析,利
用IDL,依据服务对象可能实现的服务以及服务中需要的参数,对接口进行定义。另外一
种方式是将接口放入接口仓库(Interface Repository)中,在运行期间对接口库中的接
口进行访问。
CORBA引入接口仓库(Interface Repository)的目的在于使服务对象能够提供持久的
对象服务。将接口信息存入接口仓库后,如果客户端应用提交动态调用请求(Dynamic
Invocation),ORB可以根据接口仓库中的接口信息及分布环境下数据对象的描述,获取请
求调用所需的信息。接口仓库作为CORBA系统的组成部分,管理和提供到OMG IDL映
射接口定义的访问。接口仓库中信息的重要作用是连接各个 ORB,当请求将对象从一个
ORB传递给另一个ORB时,接收端ORB需要创建一个新对象来代表所传递的对象,这就
需要在接收端ORB的接口仓库中匹配接口信息。通过从服务请求端 ORB的接口仓库中获
得接口标识,就可以在接收端的接口仓库中匹配到该接口。
接口仓库由一组接口仓库对象组成,代表接口仓库中的接口信息。接口仓库提供各种
操作来完成接口的寻址、管理等功能。在实现过程中,可以选择对象永久存在还是引用时
再创建等方式。
在接口仓库的实现形式中,接口仓库中对象定义的形式是公开的,库中对象定义的信
息可以供客户端和服务端使用。应用程序开发人员可以在如下方面使用接口功能:
(1)管理接口定义的安装和部署;
(2)提供到高级语言编译环境的接口信息;
(3)提供终端用户环境的组件。
① 接口仓库的管理
接口仓库包含对象请求调用时所需的对象信息。一旦信息装入库中,客户端存根
(Stub)程序就依赖接口仓库提供对象的信息,因此,必须选择相应的策略以保证接口仓
库中信息的一致性和完整性。
接口仓库中内容的一致性通常表现为一组有效的 OMG IDL定义。由于在接口加载过程中通信延迟等原因,有可能导致接口名字冲突或方法定义冲突等问题。在分布式环境下
为了解决这种问题,通常采用复制技术来增加接口信息的一致性和可用性。另外,接口仓
库对象通常采用服务对象定义的事务处理和并发控制方法来完成对接口仓库的更新。[5]
② 接口仓库对象
接口仓库对象提供的特征及方法取决于具体的CORBA产品,开发人员应视产品的不
同选择使用。在接口仓库中包括如下对象,各对象提供相应的方法用于管理接口仓库中的
对象信息:
a.Repository:表示接口仓库细节;
b.ModuleOf:模块定义对象;
c.InterfaceOf:接口定义对象;
d.ValueOf:值类型定义;
e.ExceptionOf: 由操作引发异常的定义。
③ 对象适配器
对象适配器(Object Adapter)是为服务对象端管理对象引用和实现而引入的。CORBA
规范中要求系统实现时必须有一种对象适配器。对象适配器完成如下功能:
a. 生成并解释对象的引用,把客户端的对象引用映射到服务对象的功能中;
b.激活或撤消对象的实现;
c. 注册服务功能的实现;
d. 确保对象引用的安全性;
e. 完成对服务对象方法的调用。
作为CORBA设计中常用的对象适配器——基本对象适配器(BOA,Basic Object
Adapter),在分布式应用程序设计中是必要的元素。ORB将服务请求的参数及操作控制权
传递给BOA,由BOA将执行结果返回给ORB。BOA用服务对象骨架(Skeleton)将ORB
和对象实现中的方法联系在一起,服务对象骨架中相应的方法将对BOA方法的请求调用映
射为服务对象中的方法。
④ 动态调用接口
动态调用接口(DII,Dynamic Invacation Interface)允许在客户端动态创建和调用对
服务对象的请求。一个请求包括对象引用、操作和参数列表。其中参数列表的定义如下:
typedef unsigned long Flags;
struct NamedValue
{ Identifier name;
Any arguments;
Long len;
Flags arg_modes;}
其中 name表示传递的参数名;arguments表示传递的参数;len表示参数长度;
arg_modes代表参数模式标识。
⑤ 上下文对象
上下文对象(Context)包含客户机、运行环境或者在请求中没有作为参数进行传递的信
息,上下文对象是一组由标识符和相应字符串对构成的列表,程序设计人员可以用定义在
上下文接口上的操作来创建和操作上下文对象。
上下文对象可以以永久或临时方式存储,客户机应用程序用上下文对象来获取运行环
境;而ORB用上下文对象中的信息来决定服务器的定位及被请求方法激活。下面介绍上下
文对象中的方法:
a. oid get_default_context(out Context ctx)作用:创建上下文对象;
方法参数:获得的上下文对象。
b. oid get_values( in Identifier start_scope,
in Flags op_flags,
in Identifier prop_name,
out NVList values )
作用:返回上下文对象中的特征值;
返回类型:返回特征值;
方法参数:start_scope为搜索范围标识;op_flags为操作标志;prop_name为特
征名;values为相应的特征值。
8.8.3 DCOM 技术
下面讨论用DCOM实现分布式应用中的几个主要问题
负载平衡
一个分布式应用系统越成功,由于用户数量的增长而给应用系统中的所有组件带来的
负载就越高。一个经常出现的情况是即使是最快的硬件的计算能力也无法满足用户的需求。
这一问题的一个无法避免的解决方案是将负载分布到多个服务器中去。在“可扩展性”部
分简要地提到了DCOM怎样促进负载平衡的几种不同的技术:并行配置,分离关键组件和连
续进程的pipelining技术。“负载平衡”是一个经常被使用的名词,它描述了一整套相关
技术。DCOM并没有透明地提供各种意义上的负载平衡,但是它使得完成各种方式的负载平
衡变得容易起来。
(1) 静态负载平衡
解决负载平衡的一个方法是不断地将某些用户分配到运行同一应用的某些服务器上。
因为这种分配不随网络状况以及其它因素的变化而变化,所以这种方法称为静态负载平衡。
基于DCOM的应用可以很容易地通过改变登记入口将其配置到某些特定的服务器上运行。
顾客登记工具可以使用Win32的远程登记函数来改变每一个客户的设置。在Windows NT
5.0中,DCOM可以使用扩展的目录服务来完成对分布的类的储存,这使得将这些配置改变
集中化成为可能。 在Windows NT 4.0中,应用系统可以使用一些简单的技术达到同样的
效果。一个基本的方法是将服务器的名字存到诸如数据库和一个小文件这样的众所周知的
集中环境中。当组件想要和服务器相连接时,它就能很轻易地获得服务器的名字。对数据
库或文件内容的改动也就同时改变了所有的用户以及有关的用户组。 一个灵活得多的方法
使用了一个精致复杂的指示组件。这个组件驻留在一台为大家所共知的服务器中。客户组
件首先和此组件连接,请求一个指向它所需服务的索引。指示组件能够使用DCOM的安全性
机制来对发出请求的用户进行确认,并根据发出请求者的身份选择服务器。指示组件并不
直接返回服务器名,它实际上建立了一个到服务器的连接并将此连接直接传递给客户。然
后DCOM透明地将服务器和客户连接起来,这时指示组件的工作就完成了。我们还可以通过
在指示组件上建立一个顾客类代理店之类的东西而将以上机制对客户完全屏蔽起来。 当用
户需求增加时,管理员可以通过改变组件而为不同的用户透明地选择不同的服务器。此时
客户组件没有做任何改动,而应用可以从一个非集中式管理的模式变为一个集中式管理的
模式。DCOM的位置独立性以及它对有效的指示的支持使得这种设计的灵活性成为可能。
(2) 动态负载平衡静态负载平衡方法是解决不断增长的用户需求的一个好方法,但它需要管理员的介入,
并且只有在负载可预测时才能很好地工作。 指示组件的思想能够提供更加巧妙的负载平衡
方法。指示组件不仅可以基于用户ID来选择服务器,它还可以利用有关服务器负载、客户
和可用服务器之间的网络拓朴结构以及某个给定用户过去需求量的统计数字来选择服务器。
每当一个客户连接一个组件时,指示组件将其分配给当时最合适的可用的服务器。当然,
从客户的观点看来,这一切都是透明发生的。这种方法叫做动态负载平衡法。 对某些应用
来说,连接时的动态负载平衡法可能仍然是不充分的。客户不能被长时间中断,或者用户
之间的负载分布不均衡。DCOM本身并没有提供对这种动态重连接以及动态的方法分布化的
支持,因为这样做需要对客户进程和组件之间相互作用的情况非常熟悉才行,此时组件在
方法激活过程中保留了一些客户的特殊的状态信息。如果此时DCOM突然将客户和在另一台
机器上的另一个不同的组件再连接,那么这些信息就丢失了。 然而,DCOM使得应用系统
的设计者能够很容易地将这种逻辑结构清楚地引入到客户和组件之间的协议中来。客户和
组件能够使用特殊的界面来决定什么时候一个连接可以被安全地经过再寻径连接到另一台
服务器上而不丢失任何重要的状态信息。从这一点看来,无论是客户还是组件都可以在下
一个方法激活前初始化一个到另一台机器上的另一个组件的再连接。DCOM提供了用来完成
这些附加的面向特殊应用的协议的所有的丰富的协议扩展机制。 DCOM结构也允许将面向
特殊组件的代码放到客户进程中。无论什么时候客户进程要激活一个方法时,由真实组件
所提供的代理组件在客户进程中截取这一调用,并能够将其再寻径到另一台服务器上。而
客户根本无需了解这一过程,DCOM提供了灵活的机制来透明的建立这些“分布式组件”。
有了以上独特的特性,DCOM使得开发用来处理负载平衡和动态方法寻径的一般底层结构成
为可能。这种底层结构能够定义一套标准界面,它可以用来在客户进程和组件之间传递状
态信息的出现和消失情况。一旦组件位于客户端的部分发现状态信息消失,它就能动态地
将客户重连接到另一台服务器上。
DCOM提供了一个用来完成动态负载平衡的强大的底层结构。简单的指示组件在连接时
可以用来透明地完成动态服务器分配工作。用来将单一的方法调用再寻径到不同的服务器
的更尖端的机制也能够轻易地完成,但是它需要对客户进程和组件之间的相互作用过程有
更为深入的了解。微软的完全基于DCOM建立的事务服务器(“Viper”)提供了一个标准
的编程模型用来向事务服务器的底层结构传递面向这一附加的特殊应用的有关细节问题,
它可以用来执行非常高级的静态和动态的重配置与负载平衡。
2. 容错性
容错性对于需要高可靠性的面向关键任务的应用系统来说是非常重要的。对于错误的
恢复能力通常是是通过一定量的硬件、操作系统以及应用系统的软件机制来实现的。 DCOM
在协议级提供了对容错性的一般支持。前面的“应用系统间的共享式连接管理”部分所描
叙的一种高级pinging机制能够发现网络以及客户端的硬件错误。如果网络能够在要求的
时间间隔内恢复,DCOM就能自动地重新建立连接。 DCOM使实现容错性变得容易起来。一
种技术就是上一部分所说的指示组件的技术。当客户进程发现一个组件出错时,它重新连
接到建立第一个连接的那个指示组件。指示组件内有哪些服务器不再有效的消息,并能提
供在另一台机器上运行的这一组件的一个新的实例。当然,在这种情况下应用系统仍然需
要在高级别上(一致性以及消息丢失问题等)处理错误的恢复问题。 因为DCOM可以将一
个组件分别放到服务器方和客户方,所以可以对用户完全透明地实现组件的连接和重连接
以及一致性问题。
另一技术经常被称为“热备份”。同一服务器组件的两个复本并行地在不同的机器上
运行,它们处理相同的信息。客户进程能够明确地同时连接这两台机器。DCOM的“分布式
组件”通过将处理容错性的服务代码放到客户端使得以上过程对用户应用完全透明。另一种方法是使用另一台机器上运行的一个协作组件,由它代表客户将客户请求发送给那两个
服务器组件。当错误发生时试图将一个服务器组件转移到另一台机器上经事实证明是失败
的。Windows NT组的最初版本使用了这一方法,当然它可以在应用级完成。DCOM的“分布
式组件”使得完成这一机能更容易了,并且它对用户隐蔽了实现细节。 DCOM使得完成高
级的容错技术变得更为容易。使用DCOM提供的部分在客户进程中运行的分布式组件技术能
够使解决问题的细节对用户透明。开发者无需改动客户组件,甚至客户机进行重新配置就
能够增强分布式应用系统的容错性。 轻松配置 如果不容易安装和管理的话,即使是最好
的应用系统也是没有用的。对于分布式应用来说,能够集中管理和尽可能简单的客户安装
过程是非常关键的。同时,提供一些办法使系统管理员能够在潜在的错误造成任何损害之
前尽可能早的发现它对于分布式应用也是非常必要的。 DCOM提供了什么技术能够让一个
应用更加易于管理呢?
3. 安装
简化客户端安装的一种普遍方法可以概括为一个词“稀薄的客户”,意思是驻留在客
户端的机能越少,安装以及可能发生的维护问题也就越少。 然而,客户组件越“稀薄”,
整个应用的用户友好度就越低,对网络和服务器的需求也就越高。稀薄的客户还不能充分
利用当今桌面办工系统所能得到的强大的计算能力,而由于诸如字处理软件以及电子表格
软件这些桌面生产应用系统本身就具有统一而庞大的特性,所以大多数用户对于这种系统
的强大的计算能力的需求也不会减弱。因此在正确的级别实现“浓厚”对于分布式应用的
设计来说是一个非常重要的决定。DCOM通过让开发者甚至管理员来选择每个组件的位置来
促进配置的简单性和灵活性之间的平衡。可以通过对配置的简单改动使同一个事务组件
(例如数据登录检查组件)分别在服务器和客户端执行。应用能够动态地选择所使用的用
户界面组件(服务器上的HTML产生器或者客户端的ActiveX控件)。 保持“肥胖的”客
户的一个最大的问题是将这些客户更新到最新版本的问题。现在通过对代码下载的支持,
微软的Internet Explorer 3.0提供了解决这一问题的一个非常优雅的办法。只要用户在
浏览一页页面,微软的Internet Explorer就会检查页面中所使用的ActiveX控件,并在
必要时自动对其进行更新。应用也可以在不明确使用浏览器的时候使用这一被微软直接支
持的特性(Active CoCreateClassFromURL函数)。 在Windows NT 5.0中,代码下载的
概念将被扩展到本地COM类库中。这一类库将使用扩展目录来储存组件的配置信息和到实
际代码的索引,它改变了当前使用的本地登记概念。这个类库将向Intranet(扩展目录)
和Internet(代码下载,Internet路径搜索)提供代码仓库,并使它们对已存在的应用完
全透明。 安装和更新服务器组件通常不是一个严重的问题。然而,在一个高度分布化的应
用中,同时更新所有的客户一般来说是不太可能的。DCOM的健壮的版本化支持允许服务器
在保持向后兼容的基础上加入新的功能。服务器组件既可以处理旧客户进程,又可以处理
新客户进程。一旦所有的客户都被更新,组件就可以停止对新客户所不需要的功能的支持。
使用代码下载技术以及以后它的扩展技术,类库、管理员能够有效而安全地集中安装和更
新客户,并能在不用削减太多功能的情况下将“肥胖的”客户变为灵巧的客户。DCOM对于
健壮性版本化的支持使得无需先更新所有客户就可以更新服务器程序。
4.管理
安装和更新客户组件的部分工作是对这些组件的配置和对这些配置的保持。DCOM所涉
及的最重要的配置信息是运行客户所需组件的服务器的消息。 使用代码下载和类库技术,
我们可以在一个集中位置管理配置信息。对配置信息和安装包的一个简单改动就能够透明
地更新所有的客户。 管理客户配置的另一种技术是“负载平衡”部分所描述的指示组件技
术。所有客户都连接到指示组件,指示组件中包含所有的配置信息,它向每个客户返回合
适的组件。只需改动指示组件就可以改变所有的客户。 一些组件,特别是服务器组件,需要附加的特殊组件配置。这些组件能够使用DCOM来显示允许改变配置和恢复现有配置的界
面。开发者可以使用DCOM的安全性底层框架使得这些界面只能被有合适访问权限的管理员
使用。对于加速开发过程的工具的广阔的支持使我们能够很容易地写出使用管理界面的前
端界面。同样的界面可以用诸如Visual Basic Script或Java Script这样的简单剧本语
言写的代码来完成自动的配置变换。 代码下载和类库技术可用于集中配置组件,而指示组
件方法是一种使配置信息更加集中化的方法。某些组件可以使附加的DCOM界面只能被管理
员看到并使用,这就使同样的DCOM底层结构能够被用来进行组件的配置和管理。
5.平台无关性
分布式应用系统经常要把不同的平台集成到客户端以及服务器端。开发者经常要面对
那些平台之间在许多方面的重要差别:不同的用户界面原理,不同的系统服务甚至是整套
网络协议的不同。这一切使得使用和综合多平台变得十分困难。 这个问题的一个解决办法
是所有平台重最特殊的一个并使用一个抽象层来保存基于所有平台的简单代码。这一方法
被传统的跨平台开发框架系统所使用,例如Java虚拟机环境。它的实现依赖于对于所有可
支持平台都适用的一个代码集甚至二进制代码。 然而,这种简单化是要付出代价的。抽象
层的引入带来了额外的开支,并且不能使用与平台有关的一些强大的服务和优化。对于用
户界面组件来说,这一方法意味着与别的应用在界面上相似程度会非常少,从而导致使用
起来更加困难以及要花更多的钱来进行培训。对服务器组件来说,这一方法对任一平台来
说牺牲了协调重要组件的执行性能的能力。 DCOM技术对于所有的跨平台开发工作都是公
开的。它不排斥基于特殊平台的服务和优化,也不会专门适用于某些系统。 DCOM结构允
许将平台无关性框架和虚拟机环境(Java)以及高执行性能、平台优化的顾客组件综合到
一个分布式应用中。
1.协议无关性
许多分布式应用需要集成到一个顾客或者公司的现存的网络结构中。这时可能需要一
个特殊的网络协议,而这需要更新所有潜在的客户,这在大多数情况下是不可能的。因此
应用的开发者需要小心地是应用对下面的网络底层结构尽可能的保持独立性。 DCOM使得
这一过程变得透明了:因为DCOM能够支持包括TCP/IP、UDP、IPX/SPX和NetBIOS在内的
任何一种传输协议。DCOM提供了基于所有这些无连接和面向连接的协议的一个安全性框架。
开发者能够轻易地使用DCOM提供的特性并可以确信他们的应用系统是完全对协议无关的。
2.平台二进制标准
从某一方面来说,DCOM定义了一个平台二进制标准,因此顾客和开发者可以将使用由不
同卖主提供的工具开发的组件互相混合和匹配起来,甚至可以在不同的 DCOM运行库中使
用它们。虽然DCOM运行库的细节可能随着完成时间的不同而改变,但是运行库和组件以
及组件之间的相互作用是标准化的。与其它更加抽象的对象摸型不同,使用 DCOM可以将
一个二进制版本的组件分布到一个运行着所有其它组件和运行库的平台上去。
8.8.4 CORBA 与 DCOM 的主要异同
1.CORBA与DCOM的相同点
CORBA与DCOM都完全支持面向对象技术 ,系统中的软件元素以对象形式出现 ,
相互间的交互采用对象技术。两者提供的某些服务是相同的 ,如命名服务 ,对象的永久存
储服务 ,版本服务等。都以对象部件为提供服务的基础。都支持多平台 ,CORBA本身
是由OMG组织提出的 ,它一直支持多种计算平台 ,目前基本上所有主流平台上都有CORBA的实现。DCOM是由Micorsoft自行提出的 ,它原本只支持 32位Wi
ndows平台 ,即Windows95和WindowsNT ,后由其合作伙伴Soft
ware AG公司扩展到其他平台上 ,包括Solaris,HP -UX ,AIX等。支
持客户 服务器工作模式。以中间件作为达到互操作的基本工具。用接口来定义中间件 ,客
户通过接口向对象提出服务请求 ,采用专门的“接口定义语言”。二者语言中立 ,都以二
进制兼容。
DCOM和CORBA都采用客户 服务器体系结构。DCOM对象提供了客户进程和
服务器进程之间通过接口实现通信的方法。客户进程可以是任何包含指定的服务器对象函
数指针的代码 ,它能通过这些指针来调用接口的具体实现代码 ,服务器进程则是对应于类
标识符对象的运行实例。有 3种对象可以作为服务器对象 ;进程内服务器、本地进程外服
务器和远端进程外服务器。在创建时 ,客户端调用CoCreateInterface
()函数 ,给出被请求对象的类标识符和接口标识符 ,该函数将把接口的指针返回给客户。
服务器创建对象实例 ,查询被调用接口并且调用AddRef()函数增加对象引用计数。
在调用时 ,客户可以通过接口来调用其所指向的函数 ,就好像调用对象自己内存空间内的
函数。如果客户需要调用该对象其它接口的方法 ,必须先调用QueryInterfa
ce()方法来给出被调用接口的接口标识符 ,获得了接口指针后 ,再通过同样的方法来实
现调用。客户不再需要对象接口的方法时 ,可以调用Release()方法来减少对象的
引用计数。DCOM把客户 服务器模式推广到分布式环境中。它是基于分布式计算环境
(DCE)下的远端过程调用 (RPC :RemoteProcessCall)。为了在异
构网络中实现数据传输 ,DCOM采用网络数据表示法 (NDR : 定义 ,派生接口可以象
使用自己的接口元素一样来使用基接口的元素。
2. CORBA与DCOM的不同点
(1) 结构和规范性。
CORBA是一个通用的分布式对象的规范说明 ,它没有给出参考的实现方案 ,所以
为实现提供了极大的灵活性 ,而DCOM有明确的实现背景 ,规范 ,不利于优化。
(2) 跨平台能力。
CORBA本身不是由厂商 ,而是由标准制定组织提出的 ,所以它从一开始就是平台
中立 ;DCOM原本由Microsoft一家提出 ,只限于Win32平台 ,只是随后由
SoftwareAG将其扩展到其他平台 ,所以DCOM的跨平台受到初始设计的局限 ,
一些测试也证明非Windows平台上的DCOM在可靠性和性能方面不尽人意。目前
ActiveX DCOM基本用于微软操作系统———Windows 95和Windo
wsNT ,虽然已有支持Unix系统的DCOM实现的测试版本 ,但还需要进一步完善。
而符合CORBA规范的产品支持广泛的平台 ,几乎可用在所有的操作系统上。
(3) 安全性。
所有的分布计算必然包括通信。如果分布计算是在分布式网络上 ,那么在传输数据时 ,
数据的安全性和完整性都有危险。安全性必须保证用户不受破坏代码的侵害。DCOM使
用远程调用 (RPC)在相距异地的对象间通信。它没有在分布式的数据网络如Inter
net上提供安全保证。使用DCOM实现的ActiveX控件不含严格的安全性检查
或资源权限检查 ,控件具有其资源的所有权限。这样就缺乏固有的安全性。而OMG已经
为基于CORBA的系统指定了广阔范围的安全服务 ,该服务不仅提供了保密性和认证机
制 ,而且实现了非否认机制 (用于确保参加者在以后不能否认他们的许诺 )。CORBA
的大多数服务均为OMG自行定义 ,而DCOM的传输和安全服务则基于DCE的标准。
CORBA中对象之间的通信机制为基于ORB的消息传递 ,而DCOM中则使用ORP
C ,它是对DCERPC的扩展 ,其中增加了一种新的数据类型 ,即对象引用类型。(4) 跨语言支持能力。
DCOM实现中所用的编程语言几乎都是C ++,而对其它编程语言的支持有障碍。而
CORBA具有语言中立性 ,可以包容多种编程语言在写规范时 ,OMG已经采纳了用C、
C ++、ADA和Smalltalk语言使用CORBASM机制的规范。CORBA具
有很大的跨平台能力。DCOM的IDL中所有界面都从一个共同的类IUnknown
继承而来 ,而CORBA中则无此共同的超类。DCOM为分布式对象系统提供灵活的运
行二进制标准 ,而CORBA重点是静态的体系结构观点。CORBA提供大量的抽象 ,
封装机制 ,而DCOM牺牲这方面利益代之以更灵活的运行环境。而CORBA中方法允
许返回任何合法类型而DCOM方法只允许返回 32位结果
(5) 对象调用及对象析构
COM 的出错处理机制是基于HRESULT返回值的。而CORBA在IDL内支持用户自定义的
异常类型。COM支持分布式的引用计数和垃圾回收(即,客户影响服务器的引用次数)。
CORBA的引用次数在客户机与服务器上被分开维护(即导致很难保证服务器对象被合理撤
消)。
8.9 基于组件软件工程的未来
很明显CBD和CBSE处于他们生存期的第一阶段。CBD被视为能革命性------至少能深
深地------改变常用软件开发和软件应用的新的有力途径。我们相信,组件和基于组件的
服务将会在非编程人员开发他们的应用中得到广泛应用。由组件整合来开发这样的系统的
工具不久就会开发出来。当今在因特网上已存在的很多应用中组件的自动更新,将会成为
系统改进的标准途径。我们可以发现的其他趋势是在接口层次上特定领域组件的标准化。
这就使从不同供应商处购买组件来开发应用系统成为可能。特定领域的组件标准化需要特
定过程的标准化。在不同领域中广泛的标准化工作已提上日程,(一个典型的例子是 OPC
Foundation[35],它是系统/设备和商业/办公应用软件领域中促使自动控制应用中相互协
调的标准接口开发)。在因特网上组件、应用软件和系统之间信息交换的一系列支持也很
快会发展起来。XML相关的工作将会在不久展开。
当今CBSE面临很多挑战,其中很多可以总结为如下:
可信组件-因为趋势是组件以二进制形式发布,而组件的开发过程不受组件用户的控制,
与组件可信性的相关问题变得很重要。但是,可信性的意思是严格定义的。尽管与可信性
相关的很多属性都有正式的定义(如可依赖性和健壮性),对可信性这个词却没有正式的
定义和理解,没有标准的测量和可信的说法。对系统属性不同程度的可信性究竟各有什么
影响目前还不清楚。
组件认证-归纳组件的一个途径是对它们进行认证。尽管一般观点认为认证意味着绝对
的可信,事实上这只表明了测试的结果和对当时的测试环境进行的描述。在很多领域认证
是一个标准的处理过程,在一般来说软件尤其是软件组件上它还没有建立。
可预见组合-就算我们假定我们可以限定组件的所有相关属性,我们仍然不知道这些属性是
如何决定他们所组合成的系统的相关属性。从组件属性中生成系统属性的理想途径目前仍
然是研究的课题。还有一个问题-“是否所有的衍生都是可能的?或者我们是否应该专注于
组件属性的测量上?”
需求管理和组件选择-需求管理是一个复杂的处理过程。需求管理的一个问题是需求往
往是不全面的,不精确的甚至互相矛盾的。在内部开发中,主要的目标是开发一个尽可能
地在一个受不同约束的特定框架内满足所有需求的系统。在基于组件的开发中,基本的途
径是现存组件的重用。鉴于可能的侯选组件常常缺失一个或几个严格满足系统需求的特征工程需求的处理要复杂的多。另外,即使一些组件个别性地和系统相符,在和系统其他的
组件相互协同时,它们并不一定能表现出良好的性能-甚至可能一点都不良好。这些限制可
能需要需求工程中其他的途径采用其他方法-与组件可用相关的系统可行性需求分析和由此
引发的需求改进。由于在组件选择过程中有很多不确定性因素,对组件选择和演化过程的
风险管理就显得必要了。
基于组件系统长期的管理-由于基于组件系统包含子系统和拥有独立生命周期的组件,
系统进化的问题变得特别复杂。有很多不同的问题因此产生了:技术问题(一个系统可以
被技术更新还是被其他组件替代?),管理和组织问题(哪些组件可能更新,应该或者必
须更新的问题),法定问题(谁对系统崩溃负责,系统和组件的制作者的问题)等等。
CBSE是一个崭新的方法,但我们对这样系统的可维护性并没有多少经验。这就存在着维护
困难的风险。
开发模式-尽管现存的开发模式要求更有力的技术,他们仍有很多模糊的特性,这导致它们
不完整,很难使用。
组件配置-复杂系统可能包括很多组件,而这些组件反过来也包含很多组件。在很多情
况下,组件的组合将会作为组件来看待。当我们开始着手处理复杂的结构时,结构配置方
面的问题就出现了。例如,两个相同的组合可能含有同一个组件。这些组件是被作为两个
不同的实体看待还是作为一个相同的实体呢?如果这些组件有不同的版本,你会选择哪个
版本呢?如果这些版本不兼容你又该怎么办?组件的动态更新问题我们已经知道了,但它
们的解决方案仍然作为课题在研究。
可靠的系统和CBSE-CBD在安全性要求较高的领域,实时系统和其他不同的过程控制系统等
一系列可靠性需求很严格的情况下,CBD的使用面临着特别的挑战。CBD中一个主要的问题
是确保质量和组件的其他非功能性属性问题,以及我们在确保特定系统属性时的乏力。工
具支持-软件工程的目的是为现实问题提供可行的解决方案,并且适当工具的存在对于
CBSE性能的成功发挥有重要的作用。开发工具如Visual Basic已被证明极其成功,但很
多其他工具还没出现如组件选择和进化工具,组件仓库和仓库管理工具,组件测试工具,
基于组件设计工具,运行时系统分析工具,组件配置工具等。CBSE的目标是由组件简单而
高效地构建系统,而这只有通过扩展工具的支持来达到。
当今CBSE面临很多的挑战。CBSE的目标是对支持与CBD相关活动的所有规则的标准化
和正式化。CBD的成功途径直接依赖于CBSE的进一步研究和应用。
第 9 章 软件测试新技术
9.1 正交试验设计
在一项试验中,把影响试验结果的量称为试验因素,简称因素。因素可以理解为试验过
程中的自变量,试验结果可以看成因素的函数。在试验过程中,每一个因素可以处于不同的
状态或状况,把因素所处的状态或状况,称为因素的水平,简称水平[1 ] 。正交试验设计是
利用正交表来安排与分析多因素试验的一种设计方法。它是由试验因素的全部水平组合中,
挑选部分有代表性的水平组合进行试验的,通过对这部分试验结果的分析了解全面试验的情况,找出最优的水平组合。例如,要考察正常值、错误值和边界值对某软件界面的影响。每
个因素设置3 个水平进行试验。A 因素是正常值,设A1 、A2 、A33 个水平;B 因素是错误
值,设B1 、B2 、B33 个水平;C 因素为边界值,设C1 、C2 、C33 个水平。这是一个3 因
素3 水平的试验,各因素的水平之间全部可能组合有27 种。全面试验:可以分析各因素的
效应,交互作用,也可选出最优水平组合。但全面试验包含的水平组合数较多,工作量大,在
有些情况下无法完成[2 ] 。若试验的主要目的是寻求最优水平组合,则可利用正交表来设
计安排试验。正交试验设计的基本特点是:用部分试验来代替全面试验,通过对部分试验结
果的分析,了解全面试验的情况。
正因为正交试验是用部分试验来代替全面试验的,它不可能像全面试验那样对各因素效
应、交互作用一一分析;当交互作用存在时,有可能出现交互作用的混杂。虽然正交试验设
计有上述不足,但它能通过部分试验找到最优水平组合,因而很受实际工作者青睐.
如对于上述3 因素3 水平试验,若不考虑交互作用,可利用正交表L9 (34) 安排,试验
方案仅包含9个水平组合,就能反映试验方案包含27 个水平组合的全面试验的情况,找出
最佳的生产条件。
9.2 均匀试验设计
试验设计是部分因子设计的主要方法之一,和正交试验设计相比,均匀设计给试验者
更多的选择,从而有可能用较少的试验次数获得期望的结果。均匀设计也是电脑仿真试验
设计(computer experiments)的重要方法之一,同时也是一种稳健试验设计(robust
experiments design).
正交试验设计是部分因子设计的主要方法之一,由于它使用方便,深受使用者的欢
迎。但任何方法都有其局限性,当实际需要超过基局限性时,人们追求其他的试验设计方
法。
设一个试验中有s个因素,它们各自取了q个水平。若用正交试验设计法来安排这
一试验,欲估计某一因素的主效应,在方差模型中占q-1个自由度,s个因素共有s(q-1)
个自由度。如果进一步考虑任两个因素的交互作用,每个占(q-1)^2个自由度。上述两项
自由度之和为s(q-1)+1/2s(s-1)(q-1)^2.若高阶交互作用可以忽略,其试验数n必须大于
s(q-1)+1/2s(s-1)(q-1)^2。
9.3 成对组合覆盖
组合覆盖测试技术是一种设计测试用例的方法,它利用组合产生能够覆盖规定组合
的测试用例。根据覆盖程度的不同,可以分为单因素覆盖、成对组合覆盖、三三组合覆盖
等。这种方法力求用尽可能少的测试用例,覆盖尽可能多的影响因素。
下面重点讨论成对组合覆盖测试用例的生成方法。
基本用例选择方法:首先确定出1个基本测试用例,基本用例由每个因素中最重要的
水平值组合而成。根据预先定义的标准,如最常用的、最简单的、最小的、最可能使用的
等找出最重要的水平值。
成对组合(Pair-Wise),又称两两组合、对对组合,它是将所有因素的水平按照两两
组合的原则而产生的。成对组合覆盖的概念是Mandl于1985年在测试Ada编译程序时提出
的。Cohen等人应用成对覆盖测试技术对Unix中的“sort”命令进行了测试,测试结果:
模块覆盖率93.5%,判断覆盖率为83%。由此可见,运用成对组合覆盖技术设计出的测试用例具有经济有效的特点。
假设某功能有3个因素(或者叫输入项),每个因素(输入项)有2个不同的取
值,分别为:
【A1,A2】、 【B1,B2】 、 【C1,C2】
引入成对组合的概念之后,我们可以用成对组合集合来表示通常的测试用例集。对于
给
定的测试用例,它能覆盖一定数量的成对组合元素。例如:
测试用例(A1,B1,C1)覆盖了(A1,B1),(A1,C1),(B1,C1)3个成对组合
元素。
测试用例(A1,B1,C2)覆盖了(A1,B1),(A1,C2),(B1,C2)3个成对
组合元素。
所谓测试设计,,就是设计出一组测试用例以依之对软件进行测试;显然,不同的
测试用例集所覆盖的成对组合元素数量是不同的。在同样大小的测试用例集条件下,覆盖
的成对组合元素数量越多,表明该测试用例集的测试效果越好。因此,如何选择测试用例
集是一个值得研究的问题。对于上例,有8个成对组合元素需要覆盖,如何从8个候选测
试用例中挑选出最少的测试用例,达到100%的成对组合覆盖,选择方案如下:
【A1,B1,C2】、【A1,B2,C1】、【A2,B1,C1】、【A2,B2,C2】
9.4 软件测试的有效方法—确定软件测试技术
应用系统属性的存在、质量及其真实性的一种手段。
测试过程尽量做到结构化。
1、应用程序的有效性取决于该应用程序与其所在环境的适应性。
适应性:指应用程序在帮助用户执行其日常工作方面的使用、帮助合意义的程度。适
应性有如下所述的四个要素:
(1)数据:数据的可靠性、及时性、一致性、可用性;
(2)人员:良好技能、相应培训、悟性、兴趣;
(3)结构:提高技术、满足需求的恰当的开发方法;
(4)规则:按照一定规程处理数据。
应用系统必须与业务环境中的这四个要素相适应。
2、测试技术/工具的选择过程
2.1、结构测试与功能测试
基于结构分析的测试,其目的是为了发现程序“编码”过程中的错误;基于功能分析
的测试是为了发现实现需求或者设计规格说明时的错误。
功能测试确保应用系统恰当地满足了需求;结构测试用于保证对各功能实现进行了充
分的测试。
2.2、动态测试与静态测试
动态测试基于测试用例运行程序,执行的结果与期望结果值进行比较,看是否一致。
静态测试不需要执行程序,其手段如语法检查等。
静态测试主要用于需求和设计阶段,动态测试主要用于测试阶段。
2.3、人工测试与自动测试由人所执行的测试称为人工测试,由机器执行的测试称为自动测试。
开发过程越是自动化,测试过程的自动化也就越容易。
3、测试技术/工具的选择
过程:选择测试因素-->确定SDLC阶段-->明确测试标准-->选择测试类型-
(系统结构或功能)->选择技术-->选择测试方法-->动态或静态
->单元测试技术-->选择测试方法-->动态或静态
4、测试技术与测试工具的区别
测试工具是执行测试过程的一个设备;测试技术是确保应用系统某方面或单元的功能
正确的过程。
5、结构化系统测试技术:用于验证所开发的系统及程序的运行情况。目标是要确保产品设
计在结构上合理,功能上正确。为确定实现的配置及其各功能共同作用以完成特定任务
提供了一种机制。结构化测试技术由以下几种:
(1)压力测试:确定系统以期望的容量执行。
举例:分配了足够的磁盘空间;有充分的通信渠道。
压力测试技术用于检查系统面对意外情况下的大数据量时是否可以正常运行。所涉及
的方面包括输入事务、内部表、磁盘空间、输出、通信、计算机容量以及人机交互等。
当应用系统所能正常处理的工作量并不确定时需要使用压力测试。压力测试意图通过
对系统施加超负载事务量来达到破坏系统的目的。弱点在于准备测试的时间与在测试的实
际执行过程中所消耗的资源数量都非常之大,通常在应用程序投入使用之前这种技术是无
法进行的。
(2)执行测试:系统能达到期望的熟练性。
举例:事务轮转时间充分;软硬件使用良好。
执行测试技术用于检查系统是否达到了预期在产品状态下的成熟度。执行测试可以验
证系统的响应时间、轮转时间及设计性能。
在开发过程的早期就应该进行执行测试,尽早制定已经完成的系统没有达到性能指标
是非常有价值的。在关键时间点进行。关键时间点指的是当前的结果会影响甚至改变系统
结构的时间点。
(3)恢复测试:系统失效之后可以恢复到可操作状态。
举例:引入失败;评估备份数据的充分性。
恢复测试技术用于确保系统在经历灾难后可以继续正常运行,它不仅可以验证恢复过
程,而且可以验证过程各组件的有效性。
当用户认为系统操作的连续性对于其所涉及领域的某些功能至关重要时,需要进行恢
复测试。
(4)操作测试:系统以正常操作状态执行。
举例:确定系统可以依据文档进行运行;JCL(工作控制语言)充分。
操作测试技术主要用于检查系统在正常的操作状态下是否可以执行。操作测试可以与
其它测试联合执行。
任何应用程序在成为产品之前都应进行操作测试。
(5)(与过程的)一致性测试:系统的开发与标准和规程相一致。
举例:按标准执行;文档完整。
一致性测试技术用于验证应用程序的开发是否与信息技术指标、过程及准则相一致。
一致性测试最有效的方法是过程审查。
系统开发标准和过程的一致性程度依赖于管理层对于所需遵循的特定过程和执行标准
的重视程度。(6)安全性测试:根据组织的重要性对系统进行保护。
举例:访问拒绝;规程适当。
安全性测试技术用于评价保护性程序及安全对策的充分性。安全性缺陷不如其它类型
的缺陷那么明显。安全性测试是测试过程中高度专业化的部分。分物理安全性(针对利用
物理方法收集信息的手段)和逻辑安全性(针对使用计算机处理和通信能力进行非法活动
信息的手段)。
当系统保护信息和资产对于组织来说意义重大时,需要进行安全性测试。
6、功能性系统测试技术
功能性系统测试用于确保系统需求与定义都得到了满足。该过程通常包含创建用于评
价应用程序正确性的测试条件。
用于执行功能测试的几种测试技术包括:
(1)需求测试:系统按制定方式执行。
举例:证明系统需求;与政策、规则相一致。
需求测试技术验证系统是否正确执行其功能,并且能保证在相当长的一段时间内保持
其正确性。需求测试的执行主要通过执行创建的测试条件以及功能检查单来完成,
通过需求得到测试条件,然后以类似于SDLC这种特定的方式表现,生成用于评价
实现的应用系统的测试数据。
任何应用程序都应该对需求进行测试,此过程应该开始于需求阶段,并一直持续到系
统运行和维护阶段。
(2)回归测试:验证系统中没有改变的部分仍能正确运行。
举例:未变更的部分正常运行;未变更的人工规程正确。
回归测试技术对已经测试过的部分进行重新测试,以保证它们在应用程序其它部分发
生变更之后仍能正常运行。
当变更会对应用程序中没有变更的部分产生高风险的影响时需要进行回归测试。
(3)错误处理测试:错误可以得到防止或检测,并被修复。
举例:将错误引入测试;错误的再次注入。
人工系统与自动系统之间差别的特点之一就是预定义的错误处理特性。错误处理测试
技术用于检查应用系统正确处理发生异常的能力。错误处理测试需要一组知识丰富的人员
来预见应用系统可能发生的错误。它是测试错误的引入、错误的处理,控制条件以及条件
的再次正确输入。
在系统整个生命周期中都应该进行错误测试。在开发过程中,应该识别错误带来的问
题并且采取相应的措施将错误减少到可以接受的程度。
(4)人工支持测试:人机交互有效。
举例:具备人工规程;人员接受过培训。
人工支持测试技术主要包括人员在准备数据以及使用来源于自动程序数据的过程中执
行所有功能。
在生命周期的全过程都应该验证人工系统功能的正确性。
(5)系统间测试:数据可以正确地在系统间传递。
举例:系统间参数变化;系统间文档更新。
系统间测试技术用于保证应用程序间相互管理的正确性。系统间测试的一个最好的工
具是集成测试工具,它允许在产品环境下进行测试,可以以最小的代价测试系统间的耦合
性。
在应用系统间的参数发生变更时需要进行系统间的测试。测试的程度和类型依赖于与
出错的参数相关联的风险情况。(6)控制测试:将系统风险控制降低到可以接受的级别。
举例:文件一致性规程正常;人工控制正确。
控制测试技术包括数据确认、文件完整性控制、评审追踪、备份和恢复、文档,以及
与系统完整性相关的其它方面。主要用于确保对系统特定功能的检查。可以用于控制测试
的一个方法是生成风险矩阵。
控制测试是系统测试中的一个完整的部分,占测试时间的很大比例。
9.6 软件测试自动化框架
自动化测试在过去的20年中已经有了很大的发展。最初的测试工具只提供了简单的捕
捉/回放功能:记录并播放键盘按键,然后捕捉和比较屏幕。这些测试方法虽然最容易应
用,但是几乎不可能维护。录制回放工具最终被功能和灵活性更强的测试脚本工具代替。
但是,脚本工具也有自己的问题。他们实现起来需要很强的开发技术和经验,同时,
不确定它们是一定可以维护的。更糟糕的是高度个性化的脚本工具技术.加上没有什么文
档记录,最后的结果经常是重写包含成千上万行代码的脚本库,成本开销巨大。
后来,一种新的自动化测试产品——自动化测试框架出现了,它可以减少实现和维护
的成本,使测试人员可以把精力集中在应用程序的测试用例设计上,而不是开发测试。
常用的自动化测试框架
所谓自动化测试框架,是由一些假设,概念和为自动化测试提供支持的实践组成的集
合。接下来将描述一下几种比较常用的自动化测试框架:
1.录制/回放的神话
每一家自动化测试工具厂商都会宣传,他们的工具非常容易使用,没有技术背景的测
试人员只要简单录制测试的操作过程,然后播放录制好的测试脚本,就可以轻松自动化所
有的测试。这样的说法是非常不负责的。
现在我们来分析一下自动化测试不能单单只依靠录制/回放来完成的原因。
通过录制建立的脚本,基本上都是用脚本语言以硬编码的方式编写的,当应用程序变
动时,这些硬编码也随之需要更改。因此,维护这些录制好的脚本,成本是非常高的,高
到几乎不能接受。
所有的测试脚本都必须是在应用程序可以正确执行时才能录制,如果在录制过程中发
现缺陷,测试人员必须向缺陷管理机制报告,等到该缺陷修正了,整个录制脚本的动作才
能继续下去。在这样的情况下,如果仅仅依靠录制脚本来进行测试,效率是十分低下的。
同时,这些录制好的脚本不是非常可靠,甚至在应用程序完全没有变动的情况下直接
播放,也可能因为一些意外状况而无法执行。如果录制脚本时测试人员使用了错误的脚本
语言,则脚本就必须重新录制。
综上所述,通过录制的方式来建立自动化测试脚本的方式看似容易,但实际上会遇到
下列问题:①测试人员大多不具备技术背景,难以完全掌握测试工具;②应用程序必须达
到一定的稳定性,才能开始录制测试脚本;③录制的测试脚本与测试数据耦合得太紧密;
④维护自动化测试脚本的成本非常高。
因此,仅仅依靠录制/回放来完成自动化测试是远远不够的,我们应找到一种能解决
上述问题并能很好地执行自动化测试的方法。2.数据驱动的自动化测试框架
数据驱动的自动化测试是针对上述开发与测试之间紧密耦合问题提出的测试方法。通
过建立测试与开发定义的软件元数据的关联——元数据映射表.在测试与开发之间建立松
耦合关系。不论测试人员修改测试脚本,还是开发人员修改软件,只需要修改元数据映射
表,既可以满足测试与开发同步进行。这样,可以减少测试脚本调试的工作量,更好的实
现自动化测试。
什么是数据驱动的自动化测试框架
数据驱动的自动化测试框架是这样的一个框架,从某个数据文件(例如ODBC源文件、
Excel文件、Csv文件、ADO对象文件等)中读取输入,输出的测试数据,然后通过变量传
入事先录制好的或手工编写的测试脚本中。其中,这些变量被用作传递(输入/输出)用来
验证应用程序的测试数据。在这个过程中,数据文件的读取、测试状态和所有测试信息都
被编写进测试脚本里;测试数据只包含在数据文件中,而不是脚本里,测试脚本只是一个
“驱动”,或者说是一个传送数据的机制。
数据驱动脚本
数据驱动脚本就是那些和应用程序相关联的脚本。这些脚本通过录制或手工编写写进
自动化工具私有的语言.然后对其中的变量赋予合适的数值,作为测试数据的输入。这些
变量作为一些关键应用程序输入的媒介.使脚本能通过外部的数据来驱动应用程序。
1)可变数据,硬编码组件标志
这些数据驱动的脚本经常包含硬编码的数据.有时是一些窗口组件中非常脆弱的识别
字符串。出现这种情况时,脚本很容易由于程序的更改而失去作用。
2)高度技术化的、重复的测试设计
数据驱动脚本的另一个共同特点就是,所有在测试设计上所作的努力最终都体现在自
动化工具的脚本语言中,或者复制到手工和自动化测试脚本中。这意味着每个和自动化测
试开发或执行有关的人必须对测试环境和自动化工具的编程语言非常精通。
优点与缺点
1)优点:①在应用程序开发的同时就可以同步建立测试脚本,而且当应用功能变动时,
只需要修改业务功能部分的脚本;②利用模型化的设计,避免重复的脚本,减少建立或维
护脚本的成本;③测试输入数据,验证数据和预期的测试结果与脚本分开.存放在另外的
数据文件里.利于测试人员修改和维护;④透过判断功能回传值是“True”或“Fslse”,
可作错误处理,增加了测试脚本的健壮性;⑤自动化测试开发人员创建数据驱动的测试过
程.测试员创建测试数据;⑥在测试的过程中收集测试结果,并在输入数据的语境中表示
测试结果,这样可以简化手工结果分析。
2)缺点:①对自动化测试工具里的脚本语言必须非常精通;②每个脚本都会对应多个
数据文件,这些数据文件需要根据脚本的功能类别存放在各自的目录中,增加了使用的复
杂性;③测试人员除了需要根据具体测试数据维护相应的测试计划,还要将这些数据写入
各个需求不同的数据文件中;④在编辑数据文件时,必须注意测试脚本所要求的传输格式
否则会在处理脚本时产生错误。如由专门的技术人员对其进行维护,依赖于数据驱动脚本
的自动化测试框架实现起来更简单、快捷。但是,维护工作困难,而且还需要保持这种数
据驱动的模式,这样,即便长时间的维持也会导致失败。
3.关键字驱动的自动化测试
关键字驱动的自动化测试(也称为表驱动测试自动化),是数据驱动自动化测试的变种,
可支持由不同序列或多个不同路径组成的测试。它是一种独立于应用程序的自动化框架,在处理自动化测试的同时也要适合手工测试。关键字驱动的自动化测试框架建立在数据驱
动手段之上,表中包含指令(关键词),而不只是数据。这些测试被开发成使用关键宇的数
据表,它们独立于执行测试的自动化工具。关键字驱动的自动化测试是对数据驱动的自动
化测试的有效改进和补充。
第 10 软件工程新视角
10.1 业发展:SOA 与云计算相结合
云计算在很大一部分与SOA有交叉的地方。许多SOA厂商正在进入云计算领域。已经
进入云计算领域的大多数厂商是传统的软件厂商。它们已经把自己的产品推向“...作为一
项服务”的领域。
SOA与云计算趋势如何?
第一,随着企业从部门问题领域向整个企业推广,企业将把更多的重点集中在整个企
业范围的SOA。因此,这个重点是在性能和伸缩性、共享的服务和各个领域之间的信息媒
介方面。虽然项目级SOA正在成为现实,但是,那些推动企业架构的人们正在努力把 SOA
作为他们企业中的一个全面的概念。确实,SOA的普及越深,SOA的价值越大。
第二,SOA治理:它是什么?我们如何创建它?什么是正确的技术?这里有许多混淆概念。
我确实要在这方面指责一些厂商,他们都在利用不同的信息向不同的方向发展。SOA治理
对于SOA确实是非常重要的。然而,你确实需要把重点放在人员和流程方面,然后放在技
术方面。没有一个策略,技术永远不能解决任何问题,特别是SOA治理等复杂的技术。
第三,现在的重点是放在节省资金的短期迅速获胜方面,而不是放在长期的战略优势
方面。不能责备他们,因为所有的地方都在削减预算。你没有理由不把一个 SOA项目与企
业关键的取胜策略结合在一起。这将对企业的盈亏底线有明显的积极的影响。这些类型的
项目要证明SOA的价值还有很长的路要走。
另一个观点是SOA与云计算的结合。Linthicum说,虽然我认为这个联系是很明显的,
但是,大多数人对这个关系仍然不清楚。简单地说,SOA为接近企业架构提供一个框架,
同时在SOA环境中使用云计算资源提供额外的价值。确实,SOA为IT基础设施提供了灵活
性,并且通过创建必要的接口让企业准备好使用云计算。
这些概念之间共生的关系能够让企业达到这样一种状态,就是根据企业的需求在防火
墙内部和外部运行服务和流程。实际上,这将在需要的时候和地方把你的 SOA向外扩展到
网络平台,以减少成本和利用互联网提供的资源。这些资源提供预制的流程和服务的访问
以及访问以服务方式提供的平台。
把SOA与云计算分开,你将发现企业没有良好的设备把流程推向云计算。通过把两者结合
起来,我们将能够利用使用服务等颗粒机制的计算资源创建一个把信息和流程放在企业防
火墙内部和外部的架构。如果我们实现这个目标,这将是一个非常好的事情。
10.2 Agile Software Development(敏捷软件开发)
敏捷软件开发是一种从1990年代开始逐渐引起广泛关注的一些新型软件开发方法,是一种应对快速变化的需求的一种软件开发能力。它们的具体名称、理念、过程、术语都不
尽相同,相对于“非敏捷”,更强调程序员团队与业务专家之间的紧密协作、面对面的沟
通(认为比书面的文档更有效)、频繁交付新的软件版本、紧凑而自我组织型的团队、能
够很好地适应需求变化的代码编写和团队组织方法,也更注重做为软件开发中人的作用。
对于企业应用软件开发领域来说,2001年是一个分水岭。在这一年,以Kent Beck、
Martin Fowler、Robert.C Martin 为首的16位极具号召力软件行业专家共同提出了敏捷
软件开发宣言:
1. 个体和交互胜过过程和工具
2. 可工作软件胜过面面俱到的文档
3. 客户合作胜过合同谈判
4. 响应变化胜过遵循计划
虽然右项也具有价值,但是我们认为左项具有更大的价值。
比较有影响力的敏捷软件开发方法:
1. Extreme Programming (XP)
2. Scrum
3. Crystal family of methodologies
4. Feature-Driven Development
5. Agile Modeling (AM)
6. Adaptive Software Development
7. Dynamic System DevelopmentModel (DSDM)
敏捷软件开发的原则:
1. 我们最优先要做的是通过尽早的、持续的交付有价值的软件来使客户满意
2. 即使到了开发的后期,也欢迎改变需求。敏捷过程利用变化来为客户创造竞争优势
3. 经常性地交付可以工作的软件,交付的间隔可以从几星期到几个月,交付的间隔越
短越好
4. 在整个项目开发期间,业务人员和开发人员必须天天都在一起工作
5. 围绕被激励起来的个体构建项目。给他们提供所需环境和支持,并且信任他们能够
完成工作
6. 在团队内部,最具有效果并且富有效率的传递信息的方法,就是面对面的交谈
7. 工作的软件是首要的进度度量标准
8. 敏捷过程提倡可持续的开发速度。责任人、开发者和用户应该能够保持长期恒定的
开发速度
9. 不断地关注优秀的技能和好的设计会增强敏捷能力
10. 简单——使未完成的工作最大化的艺术——是根本的
11. 最好的构架、需求和设计出自于自组织的团队
12. 每隔一定时间,团队在如何更有效地工作方面进行反省,然后对自己的行为进行
调整
敏捷软件需求管理:
1. 强调软件需求不是事先设计好的,而是通过和用户反馈总结出来的。因为很多时
候客户自己也不清楚需求,要求客户事先明确需求是不现实的,只能通过和客户的多
次反馈,不断的总结和提炼需求。2. 软件尚未开发之前,就必须让最终用户参与进来,最终用户的参与时间越早,参与
程度越深,软件的成功把握就越大,而不是等到开发阶段才让用户参与。
3. 软件需求管理要贯彻软件的整个生命周期,并非只在开发的早期阶段进行,即使到
软件测试验收阶段,也随时可能更改需求进行软件开发的迭代。
敏捷软件迭代:
1. 强调24小时响应能力,特别是对于SAAS类型的软件,一旦客户提出新的合理功
能要求,或者发现bug,应该能够在24小时之内修复bug,完成新功能的上线。
2. 每天都有新的功能改进;每周都有新的功能推出;每月软件都有大的进化,软件开
发过程贯穿软件全部的生命周期,软件永远beta 版,这也是SAAS软件的一个特征之
一。
3. 只实现功能最简单的版本,不浪费一丝一毫的多余力气,不要过度设计,不要预先
假设客户需要的功能。
10.3 极限编程
ExtremeProgramming(极限编程,简称 XP)是由 KentBeck 在 1996 年提出的。
KentBeck在九十年代初期与WardCunningham共事时,就一直共同探索着新的软件开发方
法,希望能使软件开发更加简单而有效。Kent仔细地观察和分析了各种简化软件开发的前
提条件、可能行以及面临的困难。1996年三月,Kent终于在为DaimlerChrysler所做的一
个项目中引入了新的软件开发观念——XP。
XP是一个轻量级的、灵巧的软件开发方法;同时它也是一个非常严谨和周密的方法。
它的基础和价值观是交流、朴素、反馈和勇气;即,任何一个软件项目都可以从四个方面
入手进行改善:加强交流;从简单做起;寻求反馈;勇于实事求是。XP是一种近螺旋式的
开发方法,它将复杂的开发过程分解为一个个相对比较简单的小周期;通过积极的交流、
反馈以及其它一系列的方法,开发人员和客户可以非常清楚开发进度、变化、待解决的问
题和潜在的困难等,并根据实际情况及时地调整开发过程。
什么是软件开发
软件开发的内容是:需求、设计、编程和测试!
需求:不仅仅是用户需求,应该是开发中遇到的所有的需求。比如,你首先要知道做
这个项目是为了解决什么问题;测试案例中应该输入什么数据……为了清楚地知道这些需
求,你经常要和客户、项目经理等交流。
设计:编码前,肯定有个计划告诉你要做什么,结构是怎样等等。你一定要按照这个
来做,否则可能会一团糟。
编程:如果在项目截止日,你的程序不能跑起来或达不到客户的要求,你就拿不到钱
测试:目的是让你知道,什么时候算是完成了。如果你聪明,你就应该先写测试,这
样可以及时知道你是否真地完成了。否则,你经常会不知道,到底有哪些功能是真正完成
了,离预期目标还差多远。
软件开发中,客户和开发人员都有自己的基本权利和义务。
客户:
定义每个用户需求的商业优先级;
制订总体计划,包括用多少投资、经过多长时间、达到什么目的;
在项目开发过程中的每个工作周,都能让投资获得最大的收益;通过重复运行你所指定的功能测试,准确地掌握项目进展情况;
能随时改变需求、功能或优先级,同时避免昂贵的再投资;能够根据各种变化及时调
整项目计划;
能够随时取消项目;项目取消时,以前的开发工作不是一堆垃圾,已开发完的功能是
合乎要求的,正在进行或未完成的的工作则应该是不难接手的。
开发人员:
知道要做什么,以及要优先做什么;
工作有效率;
有问题或困难时,能得到客户、同事、上级的回答或帮助;
对工作做评估,并根据周围情况的变化及时重新评估;
积极承担工作,而不是消极接受分配;
一周40小时工作制,不加班。
这就是软件开发,除此之外再还有其它要关心的问题!
灵巧的轻量级软件开发方法
一套软件开发方法是由一系列与开发相关的规则、规范和惯例。重量级的开发方法严
格定义了许多的规则、流程和相关的文档工作。灵巧的轻量级开发方法,其规则和文档相
对较少,流程更加灵活,实施起来相对较容易。
在软件工程概念出现以前,程序员们按照自己喜欢的方式开发软件。程序的质量很难
控制,调试程序很繁琐,程序员之间也很难读懂对方写的代码。1968年,EdsgerDijkstra
给CACM写了一封题为GOTOStatementConsideredHarmful的信,软件工程的概念由此诞生。
程序员们开始摒弃以前的做法,转而使用更系统、更严格的开发方法。为了使控制软件开
发和控制其它产品生产一样严格,人们陆续制定了很多规则和做法,发明了很多软件工程
方法,软件质量开始得到大幅度提高。随着遇到的问题更多,规则和流程也越来越精细和
复杂。
到了今天,在实际开发过程中,很多规则已经难于遵循,很多流程复杂而难于理解,
很多项目中文档的制作过程正在失去控制。人们试图提出更全面更好的一揽子方案,或者
寄希望于更复杂的、功能更强大的辅助开发工具(CaseTools),但总是不能成功,而且开
发规范和流程变得越来越复杂和难以实施。
为了赶进度,程序员们经常跳过一些指定的流程,很少人能全面遵循那些重量级开发
方法。
失败的原因很简单,这个世界没有万能药。因此,一些人提出,将重量级开发方法中
的规则和流程进行删减、重整和优化,这样就产生了很多适应不同需要的轻量级流程。在
这些流程中,合乎实际需要的规则被保留下来,不必要的复杂化开发的规被抛弃。而且,
和传统的开发方法相比,轻量级流程不再象流水生产线,而是更加灵活。
ExtremeProgramming(XP)就是这样一种灵巧的轻量级软件开发方法。
为什么称为“Extreme”(极限)
“Extreme”(极限)是指,对比传统的项目开发方式,XP强调把它列出的每个方法
和思想做到极限、做到最好;其它XP所不提倡的,则一概忽略(如开发前期的整体设计
等)。一个严格实施XP的项目,其开发过程应该是平稳的、高效的和快速的,能够做到一
周40小时工作制而不拖延项目进度。
XP的软件开发是什么样
1极限的工作环境
为了在软件开发过程中最大程度地实现和满足客户和开发人员的基本权利和义务,XP
要求把工作环境也做得最好。每个参加项目开发的人都将担任一个角色(项目经理、项目监督人等等)并履行相应的权利和义务。所有的人都在同一个开放的开发环境中工作,最
好是所有人在同一个大房子中工作,还有茶点供应;每周 40小时,不提倡加班;每天早晨,
所有人一起站着开个短会;墙上有一些大白板,所有的 Story卡、CRC卡等都贴在上面,
讨论问题的时候可以在上面写写画画;下班后大家可以一起玩电脑游戏……。
2极限的需求
客户应该是项目开发队伍中的一员,而不是和开发人员分开的;因为从项目的计划到
最后验收,客户一直起着很重要的作用。开发人员和客户一起,把各种需求变成一个个小
的需求模块(UserStory),例如“计算年级的总人数,就是把该年级所有班的人数累
加。”;这些模块又会根据实际情况被组合在一起或者被分解成更小的模块;它们都被记
录在一些小卡片(StoryCard)上,之后分别被程序员们在各个小的周期开发中
(Iteration,通常不超过3个星期)实现;客户根据每个模块的商业价值来指定它们的优
先级;开发人员要做的是确定每个需求模块的开发风险,风险高的(通常是因为缺乏类似
的经验)需求模块将被优先研究、探索和开发;经过开发人员和客户分别从不同的角度评
估每个模块后,它们被安排在不同的开发周期里,客户将得到一个尽可能准确的开发计划
客户为每个需求模块指定验收测试(功能测试)。
每发布一次开发的软件(经过一个开发周期),用户都能得到一个可以开始使用的系
统,这个系统全面实现了相应的计划中的所有需求。而在一些传统的开发模式中,无论什
么功能,用户都要等到所有开发完成后才能开始使用。
3极限的设计
从具体开发的角度来看,XP 内层的过程是一个个基于测试驱动的开发
(TestDrivenDevelopment)周期,诸如计划和设计等外层的过程都是围绕这些展开的。每
个开发周期都有很多相应的单元测试(UnitTest)。刚开始,因为什么都没有实现,所以
所有的单元测试都是失败的;随着一个个小的需求模块的完成,通过的单元测试也越来越
多。通过这种方式,客户和开发人员都很容易检验,是否履行了对客户的承诺。XP提倡对
于简单的设计(SimpleDesign),就是用最简单的方式,使得为每个简单的需求写出来的
程序可以通过所有相关的单元测试。 XP 强调抛弃那种一揽子详细设计方式
(BigDesignUpFront),因为这种设计中有很多内容是你现在或最近都根本不需要的。XP
还大力提倡设计复核(Review)、代码复核以及重整和优化(Refectory),所有的这些过
程其实也是优化设计的过程;在这些过程中不断运行单元测试和功能测试,可以保证经过
重整和优化后的系统仍然符合所有需求。
4极限的编程
既然编程很重要,XP就提倡两个人一起写同一段程序(PairProgramming),而且代
码所有权是归于整个开发队伍(CollectiveCodeOwnership)。程序员在写程序和重整优化
程序的时候,都要严格遵守编程规范。任何人都可以修改其他人写的程序,修改后要确定
新程序能通过单元测试。
5极限的测试
既然测试很重要,XP就提倡在开始写程序之前先写单元测试。开发人员应该经常把开
发好的模块整合到一起(ContinuousIntegration),每次整合后都要运行单元测试;做任
何的代码复核和修改,都要运行单元测试;发现了BUG,就要增加相应的测试(因此XP方
法不需要BUG数据库)。除了单元测试之外,还有整合测试,功能测试、负荷测试和系统
测试等。所有这些测试,是XP开发过程中最重要的文档之一,也是最终交付给用户的内容
之一。
XP中的重要惯例和规则
1项目开发小组(Team)在XP中,每个对项目做贡献的人都应该是项目开发小组中的一员。而且,这个小组中
必须至少有一个人对用户需求非常清晰,能够提出需求、决定各个需求的商业价值(优先
级)、根据需求等的变化调整项目计划等。这个人扮演的是“客户”这个角色,当然最好
就是实际的最终用户,因为整个项目就是围绕最终用户的需求而展开的。程序员是项目开
发小组中必不可少的成员。小组中可以有测试员,他们帮助客户制订验收测试;有分析员
帮助客户确定需求;通常还有个Coach(教练),负责跟踪开发进度、解决开发中遇到的
一些问题、推动项目进行;还可以又一个项目经理,负责调配资源、协助项目内外的交流
沟通等等。项目小组中有这么多角色,但并不是说,每个人做的工作是别人不能插手或干
预的,XP鼓励每个人尽可能地为项目多做贡献。平等相处,取长补短;这就是最好的 XP
开发小组。
2计划项目(PlanningGame)、验收测试、小规模发布(SmallReleases)
XP开发小组使用简单的方式进行项目计划和开发跟踪,并以次预测项目进展情况和决
定未来的步骤。根据需求的商业价值,开发小组针对一组组的需求进行一系列的开发和整
合,每次开发都会产生一个通过测试的、可以使用的系统。
计划项目
XP的计划过程主要针对软件开发中的两个问题:预测在交付日期前可以完成多少工作;
现在和下一步该做些什么。不断的回答这两个问题,就是直接服务于如何实施及调整开发
过程;与此相比,希望一开始就精确定义整个开发过程要做什么事情以及每件事情要花多
少时间,则事倍功半。针对这两个问题,XP中又两个主要的相应过程:
软件发布计划(ReleasePlanning)。客户阐述需求,开发人员估算开发成本和风险。
客户根据开发成本、风险和每个需求的重要性,制订一个大致的项目计划。最初的项目计
划没有必要(也没有可能)非常准确,因为每个需求的开发成本、风险及其重要性都不是
一成不变的。而且,这个计划会在实施过程中被不断地调整以趋精确。
周期开发计划(IterationPlanning)。开发过程中,应该有很多阶段计划(比如每三
个星期一个计划)。开发人员可能在某个周期对系统进行内部的重整和优化(代码和设
计),而在某个周期增加了新功能,或者会在一个周期内同时做两方面的工作。但是,经
过每个开发周期,用户都应该能得到一个已经实现了一些功能的系统。而且,每经过一个
周期,客户就会再提出确定下一个周期要完成的需求。在每个开发周期中,开发人员会把
需求分解成一个个很小的任务,然后估计每个任务的开发成本和风险。这些估算是基于实
际开发经验的,项目做得多了,估算自然更加准确和精确;在同一个项目中,每经过一个
开发周期,下一次的估算都会有更过的经验、参照和依据,从而更加准确。这些简单的步
骤对客户提供了丰富的、足够的信息,使之能灵活有效地调控开发进程。每过两三个星期
客户总能够实实在在地看到开发人员已经完成的需求。在 XP里,没有什么“快要完成了”、
“完成了90%”的模糊说法,要不是完成了,要不就是没完成。这种做法看起来好像有利
有弊:好处是客户可以马上知道完成了哪些、做出来的东西是否合用、下面还要做些什么
或改进什么等等;坏处是客户看到做出来的东西,可能会很不满意甚至中止合同。实际上
XP的这种做法是为了及早发现问题、解决问题,而不是等到过了几个月,用户终于看到开
发完的系统了,然后才告诉你这个不行、那个变了、还要增加
哪个内容等等。
验收测试
客户对每个需求都定义了一些验收测试。通过运行验收测试,开发人员和客户可以知
道开发出来的软件是否符合要求。XP开发人员把这些验收测试看得和单元测试一样重要。
为了不浪费宝贵的时间,最好能将这些测试过程自动化。
频繁地小规模发布软件(SmallReleases)每个周期(Iteration)开发的需求都是用户最需要的东西。在XP中,对于每个周期
完成时发布的系统,用户都应该可以很容易地进行评估,或者已经能够投入实际使用。这
样,软件开发对于客户来说,不再是看不见摸不着的东西,而是实实在在的。XP要求频繁
地发布软件,如果有可能,应该每天都发布一个新版本;而且在完成任何一个改动、整合
或者新需求后,就应该立即发布一个新版本。这些版本的一致性和可靠性,是靠验收测试
和测试驱动的开发来保证的。
3简单设计,PairProgramming,测试驱动开发,重整和优化
XP程序员不但做为一个开发小组共同工作,还以两个人为一个小开发单元编写同一个
程序。开发人员们进行简单的设计,编写单元测试后再编写符合测试要求的代码,并在满
足需求的前提下不断地优化设计。
简单设计
XP中让初学者感到最困惑的就是这点。XP要求用最简单的办法实现每个小需求,前提
是按照这些简单设计开发出来的软件必须通过测试。这些设计只要能满足系统和客户在当
下的需求就可以了,不需要任何画蛇添足的设计,而且所有这些设计都将在后续的开发过
程中就被不断地重整和优化。
在XP中,没有那种传统开发模式中一次性的、针对所有需求的总体设计。在XP中,
设计过程几乎一直贯穿着整个项目开发:从制订项目的计划,到制订每个开发周期
(Iteration)的计划,到针对每个需求模块的简捷设计,到设计的复核,以及一直不间断
的设计重整和优化。整个设计过程是个螺旋式的、不断前进和发展的过程。从这个角度看
XP是把设计做到了极致。
PairProgramming
XP中,所有的代码都是由两个程序员在同一台机器上一起写的——这是XP中让人争
议最多、也是最难实施的一点。这保证了所有的代码、设计和单元测试至少被另一个人复
核过,代码、设计和测试的质量因此得到提高。看起来这样象是在浪费人力资源,但是各
种研究表明事实恰恰相反。——这种工作方式极大地提高了工作强度和工作效率。
很多程序员一开始是被迫尝试这点的(XP也需要行政命令的支持)。开始时总是不习
惯的,而且两个人的效率不会比一个人的效率高。这种做法的效果往往要坚持几个星期或
一两个月后才能很显著。据统计,在所有刚开始PairProgramming的程序员中,90%的人在
两个月以后都很认为这种工作方式更加高效。
项目开发中,每个人会不断地更换合作编程的伙伴。因此,PairProgramming不但提
高了软件质量,还增强了相互之间的知识交流和更新,增强了相互之间的沟通和理解。这
不但有利于个人,也有利于整个项目、开发队伍和公司。从这点看,PairProgramming不
仅仅适用于XP,也适用于所有其它的软件开发方法。
测试驱动开发
反馈是XP的四个基本的价值观之一——在软件开发中,只有通过充分的测试才能获得
充分的反馈。XP中提出的测试,在其它软件开发方法中都可以见到,比如功能测试、单元
测试、系统测试和负荷测试等;与众不同的是,XP将测试结合到它独特的螺旋式增量型开
发过程中,测试随着项目的进展而不断积累。另外,由于强调整个开发小组拥有代码,测
试也是由大家共同维护的。即,任何人在往代码库中放程序(CheckIn)前,都应该运行一
遍所有的测试;任何人如果发现了一个BUG,都应该立即为这个BUG增加一个测试,而不
是等待写那个程序的人来完成;任何人接手其他人的任务,或者修改其他人的代码和设计
改动完以后如果能通过所有测试,就证明他的工作没有破坏愿系统。这样,测试才能真正
起到帮助获得反馈的作用;而且,通过不断地优先编写和累积,测试应该可以基本覆盖全
部的客户和开发需求,因此开发人员和客户可以得到尽可能充足的反馈。重整和优化(Refactoring)
XP强调简单的设计,但简单的设计并不是没有设计的流水账式的程序,也不是没有结
构、缺乏重用性的程序设计。开发人员虽然对每个USERSTORY都进行简单设计,但同时也
在不断地对设计进行改进,这个过程叫设计的重整和优化(Refactoring)。这个名字最早
出现在MartinFowler写的《Refactoring:ImprovingtheDesignofExistingCode》这本书中。
Refactoring主要是努力减少程序和设计中重复出现的部分,增强程序和设计的可重
用性。Refactoring的概念并不是XP首创的,它已经被提出了近30年了,而且一直被认为
是高质量的代码的特点之一。但XP强调,把Refactoring做到极致,应该随时随地、尽可
能地进行Refactoring,只要有可能,程序员都不应该心疼以前写的程序,而要毫不留情
地改进程序。当然,每次改动后,程序员都应该运行测试程序,保证新系统仍然符合预定
的要求。
4频繁地整合,集体拥有代码(CollectiveCodeOwnership),编程规范
XP 开发小组经常整合不同的模块。为了提高软件质量,除了测试驱动开发和
PairProgramming以外,XP要求每个人的代码都要遵守编程规范,任何人都可以修改其他
人写的代码,而且所有人都应该主动检查其他人写的代码。
频繁地整合(Integration)
在很多项目中,开发人员往往很迟才把各个模块整合在一起。在这些项目中,开发人
员经常在整合过程中发现很多问题,但不能肯定到底是谁的程序出了问题;而且,只有整
合完成后,开发人员才开始稍稍使用整个系统,然后就马上交付给客户验收。对于客户来
说,即使这些系统能够通过终验收测试,因为使用时间短,客户门心里并没有多少把握。
为了解决这些问题,XP提出,整个项目过程中,应该频繁地,尽可能地整合已经开发
完的USERSTORY(每次整合一个新的USERSTORY)。每次整合,都要运行相应的单元测试和
验收测试,保证符合客户和开发的要求。整合后,就发布一个新的应用系统。这样,整个
项目开发过程中,几乎每隔一两天,都会发布一个新系统,有时甚至会一天发布好几个版
本。通过这个过程,客户能非常清楚地掌握已经完成的功能和开发进度,并基于这些情况
和开发人员进行有效地、及时地交流,以确保项目顺利完成。
集体拥有代码(CollectiveCodeOwnership)
在很多项目开发过程中,开发人员只维护自己的代码,而且很多人不喜欢其他人随意
修改自己的代码。因此,即使可能有相应的比较详细的开发文档,但一个程序员却很少、
也不太愿意去读其他程序员的代码;而且,因为不清楚其他人的程序到底实现了什么功能
一个程序员一般也不敢随便改动其他人的代码。同时,因为是自己维护自己的代码,可能
因为时间紧张或技术水平的局限性,某些问题一直不能被发现或得到比较好的解决。针对
这点,XP提倡大家共同拥有代码,每个人都有权利和义务阅读其他代码,发现和纠正错误,
重整和优化代码。这样,这些代码就不仅仅是一两个人写的,而是由整个项目开发队伍共
同完成的,错误会减少很多,重用性会尽可能地得到提高,代码质量是非常好。
为了防止修改其他人的代码而引起系统崩溃,每个人在修改后都应该运行测试程序。
(从这点,我们可以再次看到,XP的各个惯例和规则是怎样有机地结合在一起的。)
编程规范
XP开发小组中的所有人都遵循一个统一的编程标准,因此,所有的代码看起来好像是
一个人写的。因为有了统一的编程规范,每个程序员更加容易读懂其他人写的代码,这是
是实现CollectiveCodeOwnership的重要前提之一。
5Metaphor(系统比喻),不加班
XP过程通过使用一些形象的比喻让所有人对系统有个共同的、简洁的认识。XP认为加班是不正常的,因为这说明关于项目进度的估计和安排有问题。
Metaphor(系统比喻)
为了帮助每个人一致清楚地理解要完成的客户需求、要开发的系统功能,XP开发小组
用很多形象的比喻来描述系统或功能模块是怎样工作的。比如,对于一个搜索引擎,它的
Metaphor可能就是“一大群蜘蛛,在网上四处寻找要捕捉的东西,然后把东西带回巢
穴。”
不加班
大量的加班意味着原来的计划是不准确的,或者是程序远不清楚自己到底什么时候能
完成什么工作。而且,开发管理人员和客户也因此无法准确掌握开发速度;开发人员也因
此非常疲劳。XP认为,如果出现大量的加班现象,开发管理人员(比如 Coach)应该和客
户一起确定加班的原因,并及时调整项目计划、进度和资源。
XP中一些基本概念的简介
UserStory:开发人员要求客户把所有的需求写成一个个独立的小故事,每个只需要几
天时间就可以完成。开发过程中,客户可以随时提出新的 UserStory,或者更改以前的
UserStory。
StoryEstimates和开发速度:开发小组对每个UserStory进行估算,并根据每个开发
周期(Iteration)中的实际情况反复计算开发速度。这样,开发人员和客户能知道每个星
期到底能开发多少UserStory。
ReleasePlan和ReleaseScope:整个开发过程中,开发人员将不断地发布新版本。开
发人员和客户一起确定每个发布所包含的UserStory。
Iteration(开发周期)和IterationPlan:在一个Release过程中,开发人员要求客
户选择最有价值的UserStory作为未来一两个星期的开发内容。
TheSeed:第一个开发周期(Iteration)完成后,提交给客户的系统。虽然这不是最
终的产品,但它已经实现了几个客户认为是最重要的Story,开发人员将逐步在其基础上
增加新的模块。
ContinuousIntegration(整合):把开发完的UserStory的模块一个个拼装起来,一
步步接近乃至最终完成最终产品。
验收测试(功能测试):对于每个UserStory,客户将定义一些测试案例,开发人员
将使运行这些测试案例的过程自动化。
UnitTest(单元测试):在开始写程序前,程序员针对大部分类的方法,先写出相应
的测试程序。
Refactoring(重整和优化):去掉代码中的冗余部分,增加代码的可重用性和伸缩性。
小结
XP的一个成功因素是重视客户的反馈——开发的目的就是为了满足客户的需要。XP方
法使开发人员始终都能自信地面对客户需求的变化。XP强调团队合作,经理、客户和开发
人员都是开发团队中的一员。团队通过相互之间的充分交流和合作,使用 XP这种简单但有
效的方式,努力开发出高质量的软件。XP的设计简单而高效;程序员们通过测试获得客户
反馈,并根据变化修改代码和设计,他们总是争取尽可能早地将软件交付给客户。XP程序
员能够勇于面对需求和技术上的变化。
XP很象一个由很多小块拼起来的智力拼图,单独看每一小块都没有什么意义,但拼装
好后,一幅美丽的图画就会呈现在你面前。
10.4 可信软件1. 软件可信性度量
研究软件缺陷与可信性的内在联系、软件缺陷预测和缺陷分布规律;研究多维可信属
性的多尺度量化指标系统、度量和评估机制及测评体系;研究可信属性之间的交互关系及
可能的涌现特征,包括多个属性/综合属性的局部/全局相容与失配等;建立可信软件度量
的技术标准或管理标准方案。
2. 软件可信性的演化与预测
研究软件可信性相关数据的收集、分析和知识挖掘方法;研究软件在环境和自身演化
下可信性的演化规律,以及软件在线演化的基础理论;研究基于软件行为的软件可信性增
长和面向威胁的在线评估与预测理论。
3.可信软件的风险及过程管理
研究可信软件生命周期的风险识别、评估、管理和控制模式及方法;研究可信软件过
程的属性和度量框架以及相应的量化控制和度量评估方法;研究适应分布性、敏捷性和过
程资产复用性等需求的可信软件过程建模、定制、仿真和优化方法;研究可信软件中“人-
信息系统”交互作用及优化机理。
(二)可信软件的构造与验证
1. 可信软件的程序理论与方法学
研究软件行为可信特征空间的概念模型及形式化体系,包括程序的近似和渐近正确性
理论,以及刻画软件的近似可信性与演化可信性理论;针对可信软件形态的多样性、动态
性和协同性,特别是数据与控制同时动态变化的新特征,研究网络环境下的可信软件系统
形式化模型;研究软件系统集成的基础理论以及对可信性的影响的推理基础;从风险和病
态角度,研究可信约束下的软件病态特征提取技术、软件病态及环境间的关系,以及相应
的预测理论与控制方法;建立可信软件全周期开发方法学。
2. 可信软件的需求工程
研究面向可信性的需求分析方法;研究基于社会的可信模型的需求工程方法;研究风
险分析和可信性分析技术;研究软件可信性的性质获取与形式规约;研究多维异质非功能
需求的冲突消解与完整性表述方式;探索基于领域知识的可信性分析方法和理论。
3. 可信软件设计、构造与编译
研究可信软件设计的系统化科学体系,包括基于构件的可信软件的建模、构造方法与
代码生成技术,面向服务的可信软件的建模、构造方法与代码生成技术,基于“面向方面
技术”的可信软件的构造方法和代码生成技术;研究支持软件自演化的可信软件体系结构
研究可信程序设计的基础要素和语言设计,以及可信编译技术;研究算法可信性度量和可
信算法设计的数学基础,针对典型科学计算问题,研究误差可控计算的基础算法等。
4. 可信软件的验证与测试
研究复杂环境下嵌入式软件和开放环境中网络软件的形式建模和分析技术,以及可信
软件的模型自动抽取技术;研究多层次可信软件可扩展形式验证方法和错误定位方法;研
究面向可信性的测试策略和基于控制理论的自适应测试方法;研究基于模型和规约的可信
软件测试技术;研究可信软件验证与测试的集成方法,以及基于测试和验证数据的可信性
评估和预测方法。
(三)可信软件的演化与控制
1. 可信软件运行监控机理
研究软件运行时环境变化和软件变化对可信性的影响;研究复杂开放环境下基于运行
监控的可信软件模型和体系结构;研究面向可信软件演化特性的软件运行监控与保障机制。2. 软件可信性动态控制方法
研究软件运行时的行为监控与可信性监测、诊断、恢复方法,以及基于虚拟化环境软
件系统故障范围控制和快速恢复方法与机制,包括基于动态控制更改的可信软件运行的自
主管理机制和代码热维护关键技术、多维度监控的关注点分离技术,以及基于运行监控的
可信性动态评估机制;研究网络计算环境的高可信支撑软件技术。
(四)可信环境的构造与评估
1. 可信环境的数学理论与信任传递理论
研究支持可信计算的数学模型、形式化模型,构建可信计算的理论体系;研究可
信网络计算的形式化模型,形成完整性保护的理论体系;研究信任链的建立与信任的传递
机理,重点研究支持信任链建立与扩展的无干扰模型。
2. 可信计算环境构造机理及方法
研究基于可信硬件层灵活扩展信任边界的体系结构,以及可信计算平台的完整性收集、
度量、验证的体系结构和网络连接与认证的体系结构;研究可信计算与虚拟技术结合的新
型可信虚拟平台架构,重点探索基于可信平台模块的虚拟平台安全体系结构以及可信平台
模块的虚拟化技术;研究可信的安全多方计算环境的构造方法。
3. 可信计算环境测评
研究适用于可信计算平台的安全评估模型;研究可信平台模块协议检测方法,包括可
信计算平台安全功能测试、标准符合性测试、穿透性测试等技术,对认证、授权和平台证
明协议的正确性、安全性和性能的验证提供支持。
