 夜雨聆风
夜雨聆风大家好,我是ai小青瓜。
Self-Attention作为Transformer的核心组件,一直是大模型训练和推理的最大瓶颈——O(N²)的计算和访存复杂度,让长序列直接变成“显存杀手”。 而 FlashAttention 系列,正是把这个“不可能”变成现实的无损优化神器。它不改变任何数学结果,却能把注意力计算速度提升2~8倍,显存占用大幅下降,被誉为“AI编译优化的集大成者”。今天这篇文章不抠公式细节,只讲思想、原理、进化路径,让你看完就能直接当作工具使用,同时为以后做优化带来灵感。
论文:
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
一、背景与动机:为什么Self-Attention必须被优化?Transformer的核心计算是Self-Attention,公式大家都知道:
它分为三步:QKᵀ → Softmax → PV。
传统实现会产生巨大的N×N中间矩阵,导致计算量O(N²)、访存量O(N²),序列长度一长就卡死。
FlashAttention的核心动机:
如果能大幅降低访存(I/O)开销,就能让整个大模型推理速度起飞。
二、GPU的“两座大山”:计算限制 vs 内存限制GPU内存层次从快到慢依次是:
寄存器 → SRAM(L1/Shared Memory) → HBM(显存)
- Math-bound(计算限制):大矩阵乘、通道数很大的Conv,算得慢。
- Memory-bound(内存限制):逐点操作(如Softmax、LayerNorm、ReLU、Dropout),算得快但读写慢。
Self-Attention属于典型的Memory-bound——中间矩阵要反复从HBM读写,浪费大量时间。优化方向只有两个:
- 减少总计算量(FLOPs)
- 减少总访存量(FlashAttention走的路)
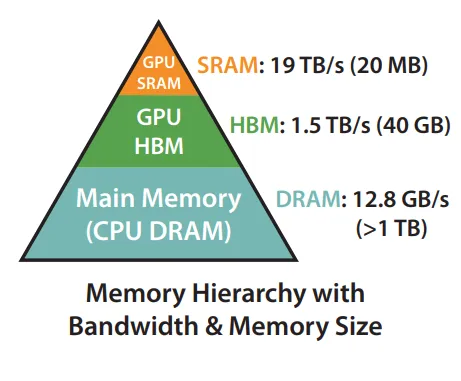
一个典型的GPU存储结构:可以看到越靠上,存储空间越小,但是读写速度越快。计算则发生在ALU(算术逻辑单元中),而ALU直接操作的数据必须位于寄存器或者SRAM(L1/shared memory)中。
由于从显存(HBM)读取数据是十分耗时的,因此,在SRAM存储允许的情况下,能合并的尽量合并,避免从HBM中读取数据。
三、标准Attention到底卡在哪里?(3 Pass过程)以FP32为例,传统实现分成三步:
- S = QKᵀ → 读写N²
- P = softmax(S) → 又读写N²
- O = PV → 再读写N²
总访存复杂度O(N²),序列越长越惨。
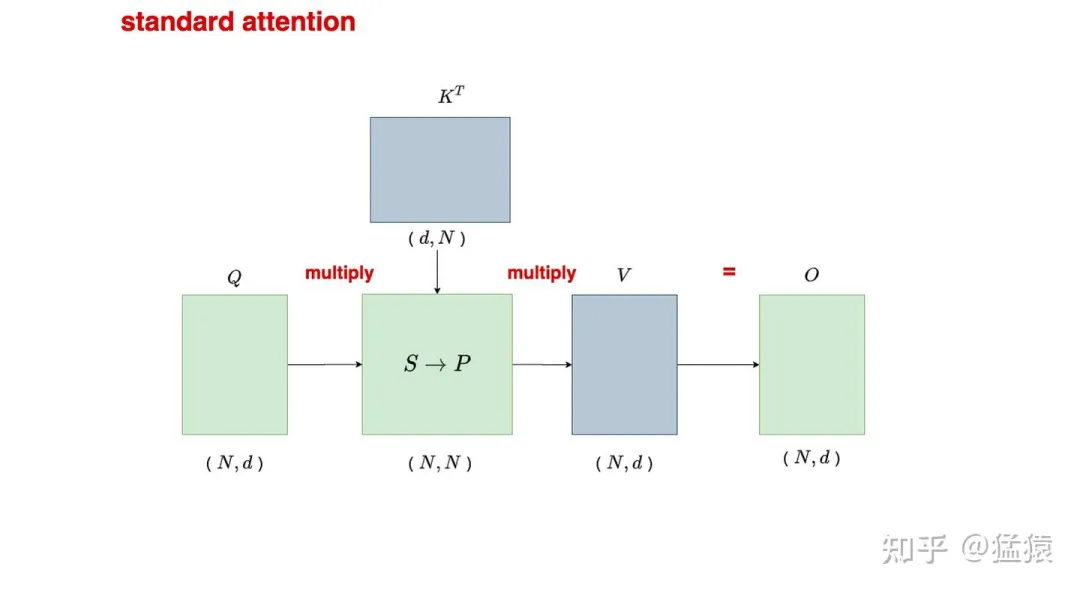

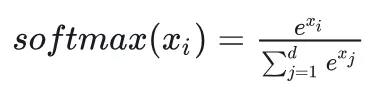
以FP32为例,其中N,d分别为序列长度和维度。
S=QK^T,其中Q,K,V∈R^(N,d)
计算量为2*N*d*N,读取显存(HBM)数据量为4*2*N*d, 写入HBM数据量4*N^2
P=softmax(S) ,
计算量为N(N-1+N+N)=3N^2-N,读取显存(HBM)数据量为4*N^2, 写入HBM数据量4*N^2
O = PV
计算量为2*N*N*d, ,读取显存(HBM)数据量为4*N^2+4*N*d, 写入HBM数据量4*N*d
总计算量为4dN^2+3N^2-N,由于序列长度N>>维度d,因此计算时间复杂度O(N^2)
总访存量为16Nd+12N^2,由于序列长度N>>维度d,因此访存时间复杂度O(N^2)
加速无非就是减少总计算量,或者减少总访存量(Flashattention做的)。
四、分块(Tiling)+ Safe Softmax:第一次优化为了让SRAM装得下,我们把矩阵按块(Block)处理,引入Safe Softmax(在线Softmax):
# 普通softmaxe = np.exp(x)result = e / e.sum()
# Safe softmax(数值更稳定)max_val = x.max()e = np.exp(x - max_val)result = e / e.sum()
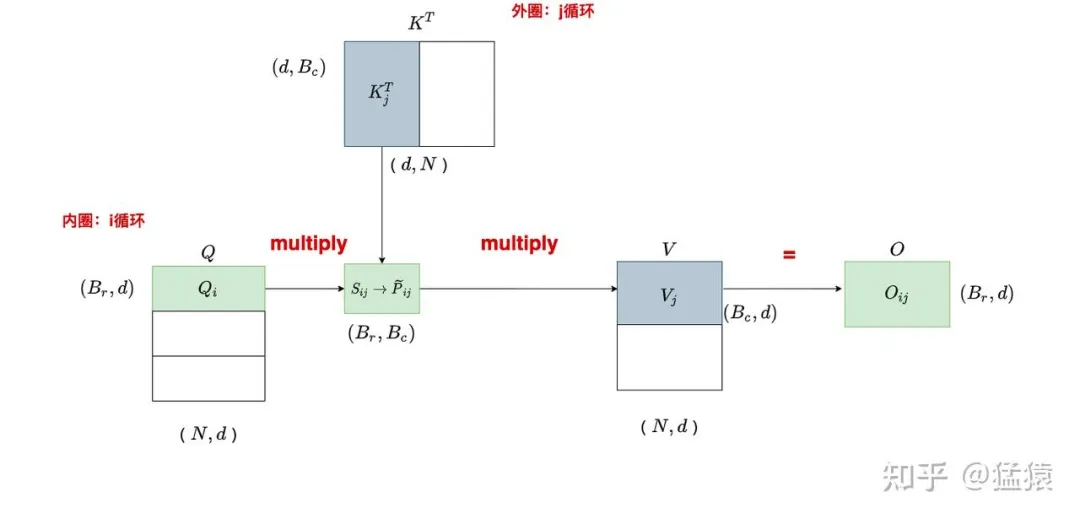
首先,定义一些符号,B_r,B_c分别是按行分块的数量和按列分块的数量,d还是维度。大家只需要把这个的维度大小摸清楚即可,不必在意细节。
Safe softmax
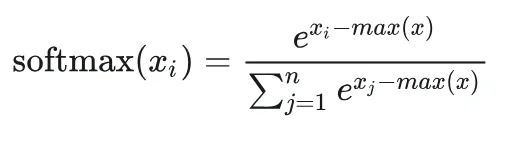
3 pass过程

第一次优化(online softmax)
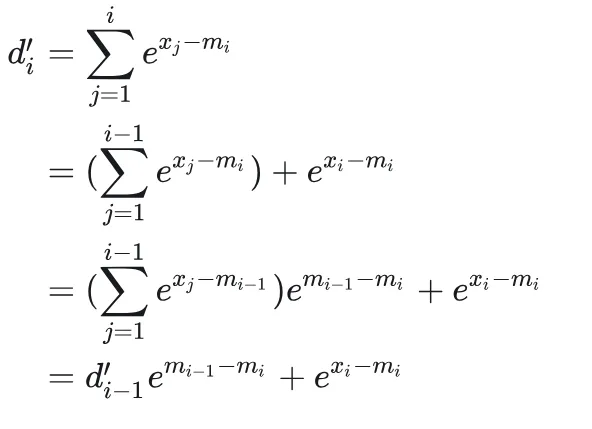 ,因此d'_N=d_N
,因此d'_N=d_N

五、FlashAttention核心:分块 + 1 Pass 在线Softmax论文中最经典的伪代码(简化版)就是:
- Outer Loop:按Query分块
- Inner Loop:按Key/Value分块
- 用在线Softmax(max-tracking + 迭代更新)在SRAM里完成所有计算
关键收益:
中间的N×N注意力分数矩阵完全不用写回HBM!
访存复杂度从 O(N²) 骤降到 O(N²·d²/M)(M是SRAM大小,d是维度)。由于d通常只有64~128,实际访存远小于标准Attention,加速效果显著。
我们知道,SRAM是比较小的,放不下很大的矩阵,因此分块(tiling)运算是必须的,我们给出分块版本的online-softmax。
2 pass
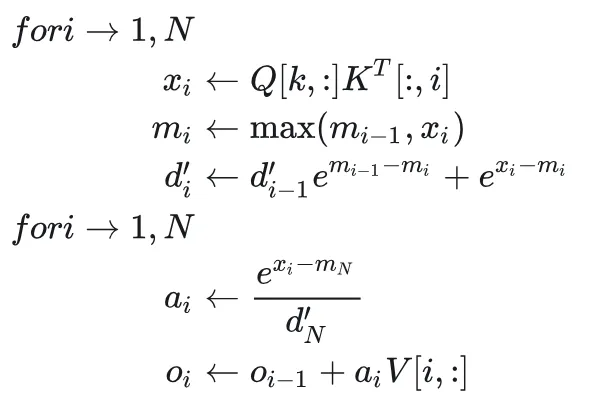
为了继续优化,Flash attention将ai带入到oi的计算中,并用迭代形式化简:

上面的公式不用在意,我们的目的是为了知道Flash_attention是怎么来的,干了什么。目前我们已经知道Flash attention就是从3 pass(3次循环)的softmax的基础上加入online的计算,产生2pass(2次循环)的online softmax然后,通过一系列公式,化简为1pass(一次循环)的形式,下面就是其终极形式
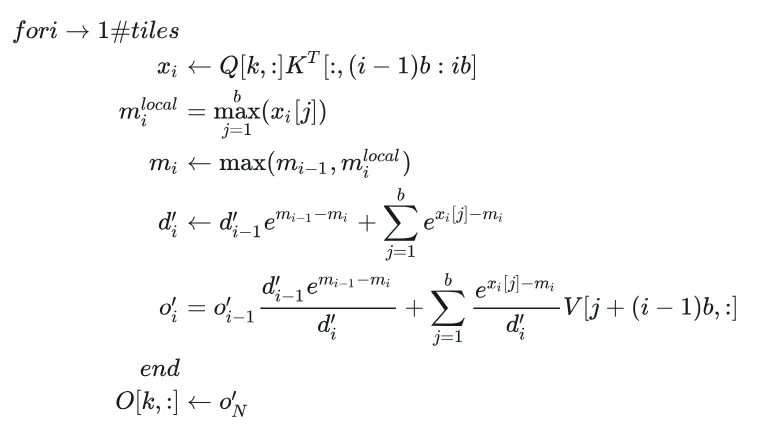
也就是分块+1pass
我们看看原论文中的算法

我们不用管里面的符号了,因为前面带大家算的就是这些东西,看懂终极形式的伪代码即可。
接下来,我们可以看出为什么Flash_attention加速了attention的计算过程了。
分块
1 次循环不用三次访存(中间的P不用存入HBM)了,只需要一次访存即可。
也就是说Flash attention并没有减少计算量,而是减少了访存量。还记得最开始我们提到的吗,有两种限制
在大多数情况下,self-attention都属于memory-bound(内存限制),内存读取和写入占用了更多的时间,因此只需要优化这一部分,就可以带了可观的加速效果。
具体而言,计算一下标准attemtion和flash attention的差距

O(2Nd+NN)
O(2NN)
O(Nd+NN+Nd)
O(NN+Nd)

6行:O(2Nd)
8行:O(Tc(Nd+Nd)+2TcTr)
12行:O(Tc(Nd))
13行:O(2TcTr)
总:O((2+2Tc)Nd+4TcTr)=O((NNd)/Bc+NN/(BcBr))=O(4N^2*d^2/M+16N^2*d^2/M^2)=O(N^2 *d^2/M)
d的取值在64~128,M的取值在100KB左右
因此d^2/M<<1,原式<<O(N^2)
也就是说flash attention的访存(读写)复杂度远远小于标准attention
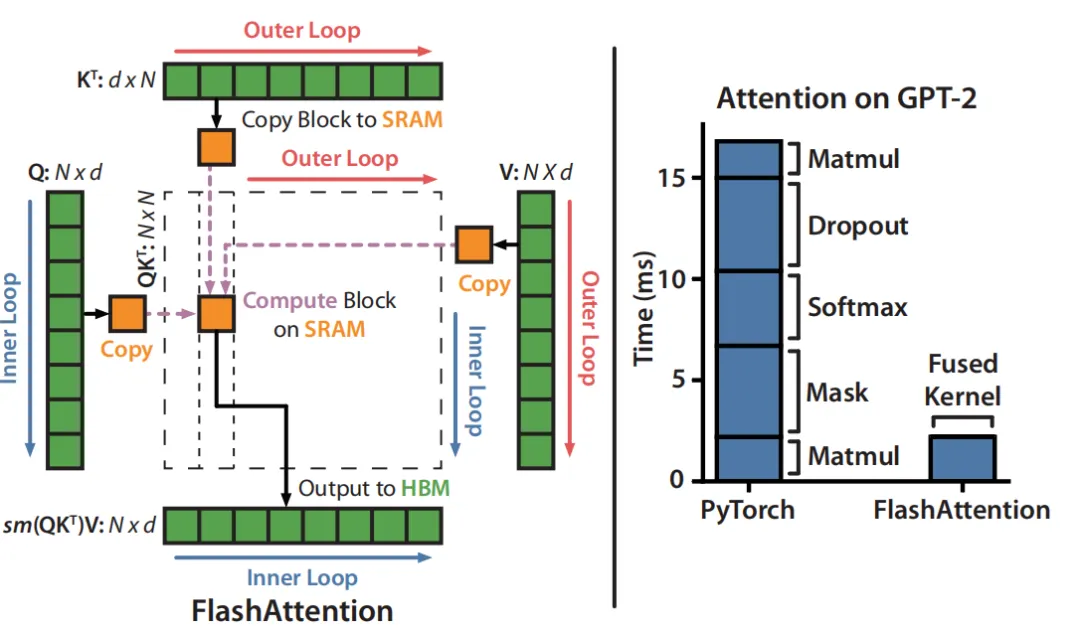
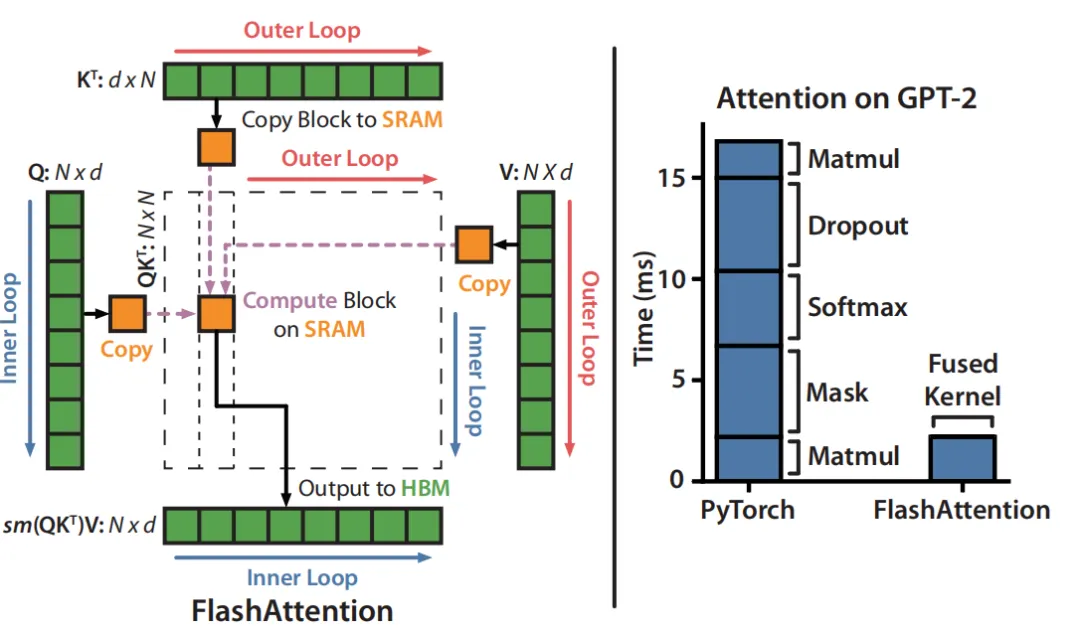
六、Falsh attention 示意图
最后我们来看一下经典的Flash attention的两次循环以及其加速示意图:
Inner Loop代表按行切块
Outer loop代表按列切块
七、编译器视角下的算子重组与内存调度启示是:
性能优化不应只关注算子融合或 FLOPs 数量,而要从内存访问与算法重构出发,通过分块计算、在线 softmax 等方式在 保持数值稳定 的同时大幅减少 I/O 开销。
编译器应具备对 算子数学等价变换、cache 感知调度 以及 数值语义约束 的理解能力,让优化从“算子拼接”进化为“算法级重排”,真正实现 compute 与 memory 协同的智能编译。
课外阅读:
- FlashAttention V2 论文
- FlashAttention-3 官方博客(Hopper异步优化细节)
