 夜雨聆风
夜雨聆风专利编号:US 20260086624 A1 申请人:Apple Inc. 公开日:2026年3月26日 发明人:Puja Gupta, Andrei Dorofeev 关键词:CLPC, Per-TG Power Limiter, PID Controller, DVFS, big.LITTLE |
用一个故事开始:为什么你的导航会卡?
想象一下这个场景:
你正在开车,手机同时运行着导航和音乐 App。突然,音乐 App 出了 Bug,CPU 占用率飙升,功耗急剧上升,芯片开始发烫。
传统做法是什么?系统发现温度过高或功耗过大,启动系统级限流器(System-Level Limiter)——直接把整个 SoC 的频率压下来。结果:
·音乐 App:被限流了(符合预期)
·导航 App:也被限流了!地图卡顿、路线刷新变慢
·屏幕亮度:也被降低了!
·后台同步:也被延迟了!
一个 App 的错误,惩罚了所有 App。 这就是传统功耗管理的根本缺陷。
Apple 这个专利要解决的,就是这个问题。
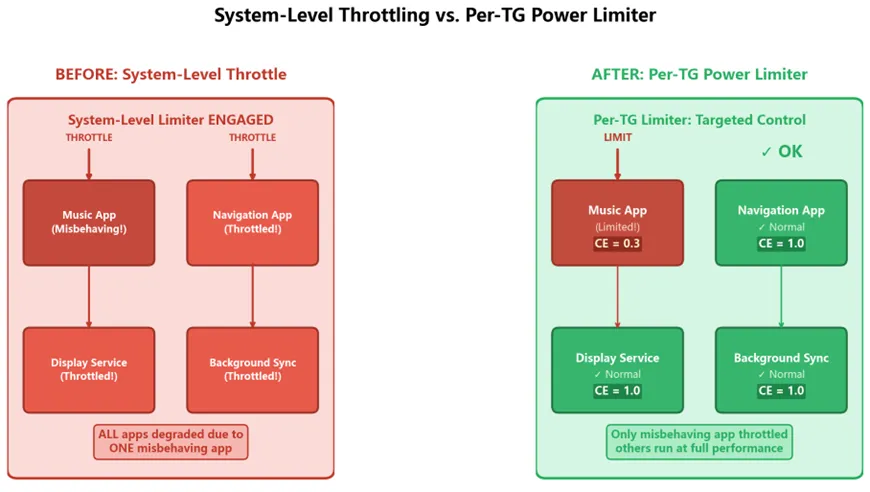
图 1:传统系统级限流 vs. Apple Per-TG Power Limiter —— 只有"犯错"的 App 被限制
核心概念:什么是Thread Group(TG)?
在理解这个专利之前,先要理解一个关键概念:Thread Group(线程组)。
应用程序└── Thread Group (TG)├── Thread 1 (主线程)├── Thread 2 (渲染线程)├── Thread 3 (网络线程)└── ...
·一个应用程序对应一个或多个 Thread Group
·同一个 TG 中的线程共享一个"共同目标"(比如:播放音乐、渲染导航地图)
·Apple 的 CLPC(Closed Loop Performance Controller)以 TG 为单位来追踪性能指标和功耗
关键洞察:如果我们能以 TG 为粒度追踪功耗,就能以 TG 为粒度控制功耗。
系统架构全景:CLPC + Per-TG Power Limiter
这个专利的核心架构可以用下面这张图来概括:
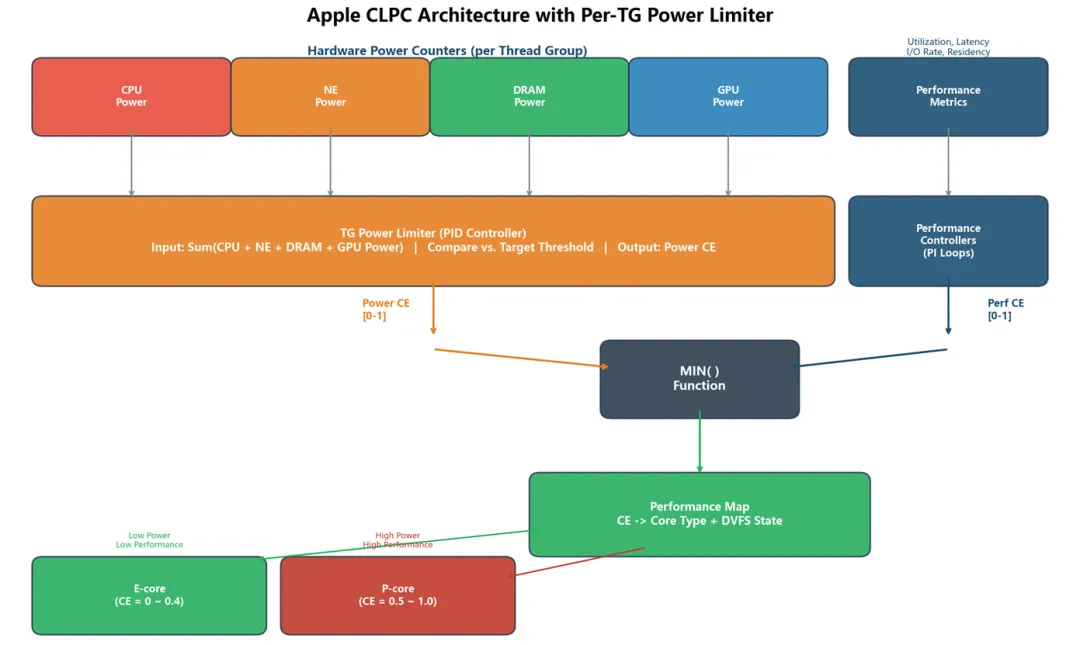
图 2:Apple CLPC 架构全景 —— 性能控制器与功耗限制器协同工作
整个系统的工作流程可以分为 4 层:
第 1 层:功耗采集(硬件计数器)
Apple 利用硬件计数器,在线程切换(active/idle)时自动测量每个 TG 消耗的功耗,覆盖 4 个维度:
功耗维度 | 含义 | 测量方式 |
CPU Power | TG 在 CPU 核上消耗的能量 | 硬件能量计数器差值 |
NE Power | TG 使用 Neural Engine 的能量 | 硬件能量计数器差值 |
DRAM Power | TG 访问内存的能量 | 硬件能量计数器差值 |
GPU Power | TG 使用 GPU 的能量 | 硬件能量计数器差值 |
例如,当 TG1 上 CPU 核时,读取能量计数器 E1;下核时读取 E2。E2 - E1 就是这段时间 TG1 的 CPU 功耗。
这个设计非常巧妙——它完全基于硬件计数器,不需要额外的功耗传感器,且精度达到了 per-TG 级别。
第 2 层:功耗判断(TG Power Limiter)
将上述 4 个维度的功耗加总,送入 TG Power Limiter:
TG_Power = CPU_Power + NE_Power + DRAM_Power + GPU_Power
如果 TG_Power > Target_Threshold(比如 1W),则限制器介入(engage)。
这个限制器本质上是一个 PID 控制器:
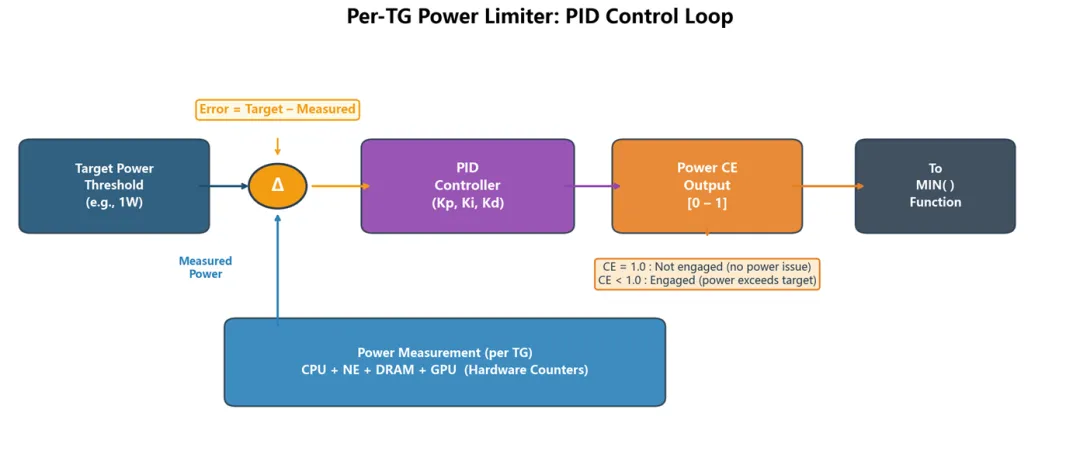
图 3:TG Power Limiter 的 PID 控制闭环 —— 自动收敛到目标功耗
PID 控制器的输出是一个称为 Control Effort (CE) 的值。
第 3 层:CE 是如何工作的?
CE (Control Effort) 是整个系统中最核心的抽象概念:
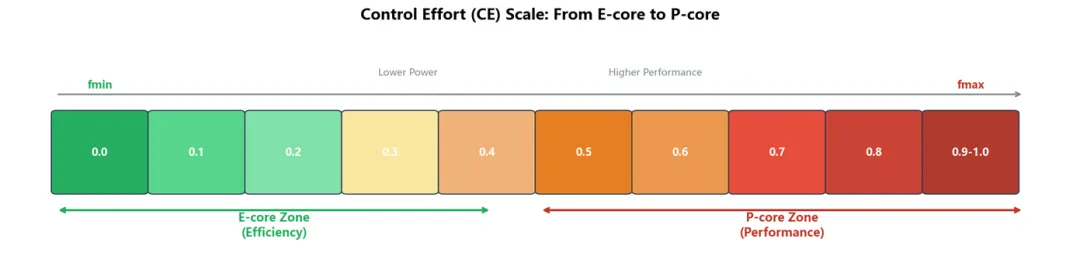
图 4:Control Effort 量表 —— 从 E-core 最低频到 P-core 最高频的连续映射
·CE = 0:E-core 最低频率(fmin)—— 最省电
·CE = 1:P-core 最高频率(fmax)—— 最高性能
·中间值:DVFS 状态的连续映射
TG Power Limiter 输出的是 Power CE:
·未介入时:Power CE = 1.0(不限制,功耗由性能需求决定)
·介入时:Power CE < 1.0(比如 0.3,意味着限制到 E-core 低频)
同时,性能控制器(Performance Controller)也会输出一个 Performance CE(基于利用率、调度延迟、I/O 速率等指标)。
最终系统取两者的最小值:
Final_CE = MIN( Performance_CE,Power_CE )
这个设计的精妙之处在于:
·当功耗没问题时,Power CE = 1.0,MIN 取 Performance CE → 功耗限制器"透明"
·当功耗超标时,Power CE < 1.0,MIN 取 Power CE → 功耗限制器主导
第 4 层:核心分配与 DVFS
Final CE 通过 Performance Map 映射为:
·核心类型:E-core 还是 P-core
·DVFS 状态:具体的频率和电压
每个 TG 独立完成这个映射。不同 TG 可以同时运行在不同的核心类型和频率上。
实战场景:限流过程的时间线
让我们用一个具体的时间线来看这个系统是如何工作的:
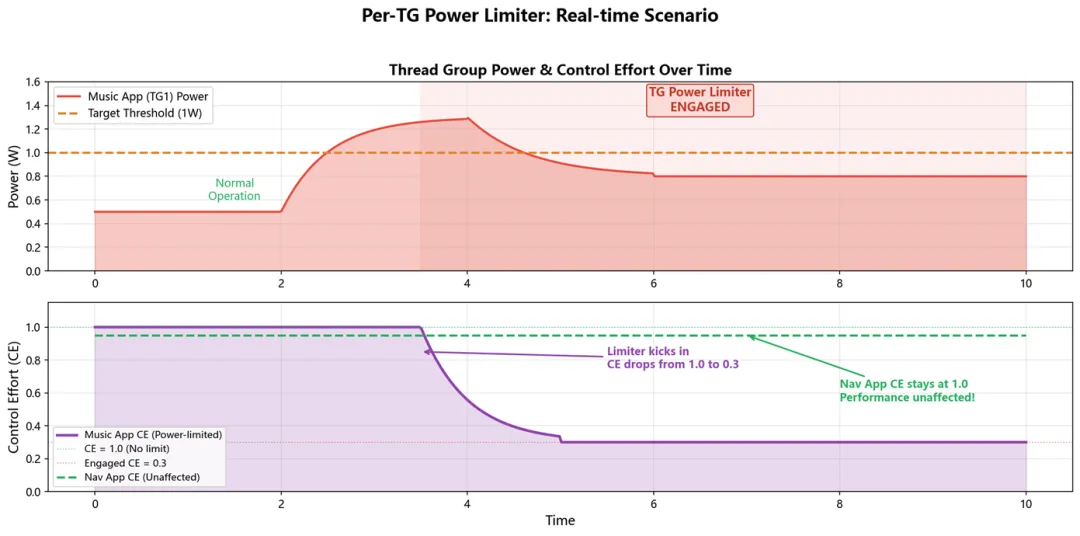
图 5:实战场景 —— 音乐 App 功耗超标时,TG Power Limiter 的介入过程
时间段 | 音乐 App (TG1) | 导航 App (TG2) |
0 – 2s | 正常运行,功耗 0.5W | 正常运行 |
2 – 3.5s | Bug 触发,功耗飙升 | 正常运行 |
3.5s | 功耗超过 1W → Limiter 介入 | 不受影响 |
3.5 – 5s | PID 收敛,CE: 1.0 → 0.3 | CE 保持 0.95 |
5s+ | 稳定在 E-core 低频运行 | P-core 正常运行 |
核心观察:导航 App 的 CE 自始至终保持在 0.95 附近,完全不受音乐 App 功耗异常的影响。
技术深潜:PID控制器的数学
对于 PPA 工程师来说,值得深入了解一下 PID 控制器的数学表达:
u(t) = Kp·e(t) + Ki·∫e(τ)dτ + Kd·de(t)/dt
其中:
·Kp:比例增益 —— 决定对当前误差的响应强度
·Ki:积分增益 —— 消除稳态误差(确保功耗最终收敛到目标值)
·Kd:微分增益 —— 抑制振荡(防止 CE 来回跳动)
·e(t) = Target_Power − Measured_Power
专利中提到,PID 参数可以按应用类型进行调优:
·游戏类 App:可能允许更高的功耗阈值和更慢的收敛速率
·后台服务:更低的功耗阈值和更快的收敛
·用户可编程阈值:通过配置来定义每个 App 的功耗上限
与系统级限流器的协同
一个重要的设计细节:Per-TG Limiter 并不替代系统级限流器(CEL),而是与其协同工作。
系统架构的层次关系:
层级 | 名称 | 职责 | 反应粒度 |
第一道防线 | Per-TG Power Limiter | 在 TG 级别限制功耗(精准打击) | 每个应用 TG |
第二道防线 | System-Level CEL | 在系统级别限制(全局保护) | 整个 SoC |
Per-TG Limiter 的目标是尽可能在第一道防线就解决问题,避免触发系统级限流。只有当 Per-TG Limiter 无法控制住整体功耗时,系统级 CEL 才会介入。
与传统方案的全面对比

图 6:传统系统级方案 vs. Apple Per-TG Power Limiter 的全面对比
维度 | 传统方案 | Apple Per-TG |
粒度 | 整个 SoC | 每个应用的 Thread Group |
影响范围 | 所有应用 | 仅违规应用 |
控制方式 | On/Off 二值 | PID 连续曲线 |
功耗追踪 | 系统温度/功耗 | 每 TG: CPU+NE+DRAM+GPU |
核心迁移 | 全局 DVFS | 每 TG 独立的 P↔E 迁移 |
用户体验 | 全局降级 | 精确隔离 |
对 PPA 工程师的启示
8.1 设计启示
1. Per-Context 功耗追踪是可行的
Apple 证明了用硬件计数器实现 per-TG 功耗追踪的可行性,这个思路可以推广到 GPU 的 per-context、per-stream、甚至 per-kernel 功耗追踪。
2. PID 控制器用于功耗管理
传统的功耗管理多是 threshold-based(超过就限流),Apple 使用 PID 实现了连续、平滑、可调的功耗控制,这是一个重要的思路转变。
3. MIN(Performance, Power) 的解耦设计
将性能控制和功耗控制解耦为两个独立的 CE 通道,通过 MIN 函数组合,既保证了功耗安全又最大化了性能。这种设计模式值得在其他 PPA 优化场景中借鉴。
8.2 适用场景
·移动 SoC:智能手机、平板电脑上的多应用功耗隔离
·云端多租户 GPU:在多用户共享 GPU 时隔离"噪声邻居"
·汽车 SoC:在热压力下优先保障 ADAS 应用的性能
·Edge AI:按推理任务隔离 NPU 功耗
8.3 值得关注的开放问题
·硬件计数器的精度和粒度能否满足 per-TG 追踪的需求?
·PID 参数的自适应调优如何实现?
·在极端多线程场景下(数百个 TG),系统开销如何?
·跨芯片(multi-die)场景下,Per-TG Power Limiter 如何扩展?
总结
Apple 的 US 20260086624 A1 专利提出了一种前所未有的 per-application 功耗隔离方案。其核心创新可以用一句话概括:
用硬件计数器追踪每个 Thread Group 的 CPU/NE/DRAM/GPU 功耗,通过 PID 控制器输出 Control Effort,与性能控制器取 MIN 后映射到核心类型和 DVFS 状态——让功耗管理从"惩罚所有人"进化到"只惩罚违规者"。 |
对于 PPA 工程师来说,这个专利最大的价值在于:它展示了一种将功耗管理粒度从系统级精细化到应用级的完整方法论,并且完全基于硬件计数器实现,工程上具有高度可行性。
本文基于专利 US 20260086624 A1 的技术内容进行分析,仅供技术学习和讨论使用。
