 夜雨聆风
夜雨聆风最近在升级OpenClaw后发现一个很有意思的新功能:梦境模式
如果你把大多数 AI 助手的记忆系统拆开来看,会发现一个很现实的问题,它们会“记住一些东西”,但并不真正会“消化这些东西”。
今天聊过的事情,可能会被存进某个记忆文件。昨天反复提过的偏好,可能也会在下一次检索里被命中。但从“记录”到“理解”,从“保存”到“沉淀”,中间其实还差一个关键环节。
OpenClaw 在这件事上做了一个非常有意思,也非常工程化的设计,叫Dreaming System,梦境系统。

它不是为了给 AI 套上一层浪漫化的包装,而是在认真回答一个很硬核的问题,一个长期运行的 Agent,怎样把每天涌入的大量短期信息,整理成真正有用的长期记忆,并且从中发现模式?
一,为什么 AI 也需要“做梦”
人类的记忆,并不是“写进去就永远保留”。认知科学里,睡眠承担着非常关键的整理功能。浅睡眠回放白天经历,深度睡眠巩固重要内容,REM 快速眼动阶段则更像一个模式发现器,会把分散的碎片重新连接,形成联想、洞察,甚至直觉。
OpenClaw 直接把这套思路映射成了一套运行时机制:
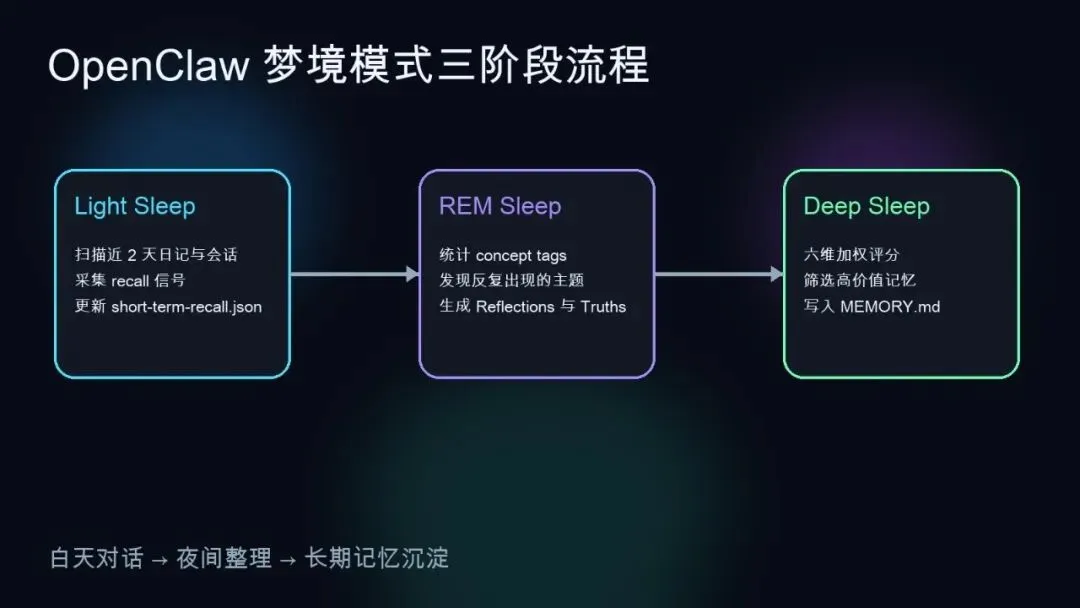
白天发生的对话,先沉入每日记忆文件和会话转录
Light Sleep 扫描近期内容,采集 recall 信号
REM Sleep 统计概念标签,发现反复出现的主题
Deep Sleep 再把真正高价值的信息晋升进 MEMORY.md
这背后解决的是三个非常现实的问题,信息过载、价值模糊、记忆孤岛。很多系统能存,但不会筛。很多系统能回忆,但不会联想。很多系统能检索,但不会长期沉淀。梦境模式的意义就在这里,它把“记忆整理”从一个模糊概念,做成了一条真实运行的后台流水线。
二,它不是一个单点功能,而是一条完整的数据链路
很多产品做记忆系统时,重点放在“怎么存”。OpenClaw 更进一步,它在调研文档里呈现出来的是一条完整的数据流:
用户交互形成每日记忆文件 memory/YYYY-MM-DD.md
会话原始记录沉淀成 session corpus
Light Sleep 负责短期 recall 信号采样
REM Sleep 负责跨记忆模式发现
Deep Sleep 负责长期记忆晋升
必要时还会生成 DREAMS.md 这种人类可读的梦境日记

更重要的是,这条链路并不是一个孤立模块。它与 OpenClaw 已经很成熟的主动执行系统直接接轨。梦境任务会通过Cron + Heartbeat协同触发,默认由一个 managed cron job 在设定时间注入 system event,再通过 next-heartbeat 唤醒主会话执行。
也就是说,这不是“在 prompt 里让模型自己想一想”,而是原生嵌入调度系统、执行系统和存储系统的一套能力。
三,最值得研究的,是它的三阶段睡眠模型
1)Light Sleep,像前哨站,先收集信号
浅睡眠阶段不负责最终决策,它最核心的工作是“先看、先记、先暂存”。它会扫描最近几天的每日记忆文件,也会摄入 session 转录,然后把候选片段写入memory/.dreams/short-term-recall.json。
真正让我觉得这个设计靠谱的,是它不是只记一句“这条出现过”,而是为每条片段维护一整组统计字段,比如:
recallCount,被回忆了多少次
dailyCount,被日常摄入了多少次
totalScore 和 maxScore,累计与最高相关性分数
queryHashes,在哪些查询语境下被触发过
recallDays,跨哪些日期重复出现
conceptTags,从文本中抽取出的概念标签
这意味着 Light Sleep 更像一个高质量的预处理层,它为后续判断准备的是“信号”,而不是一堆没整理过的原始文本。
另外它还用了Jaccard 相似度去重。当两个片段语义高度接近时,系统不会让它们重复占满候选位,而是合并统计信息。这个细节非常重要,因为它直接影响后续评分的稳定性。
2)REM Sleep,不急着存,而是先试着“看出规律”
REM 阶段是我觉得最有启发性的部分。大多数 AI 的记忆系统,顶多做到“能找回”,但 OpenClaw 在这里往前推了一步,它会基于 concept tags 的统计,识别哪些主题正在多天、多场景、跨来源地反复浮现。
最后它会产出两类内容,Reflections和Possible Lasting Truths。前者是系统级反思,后者是那些可能具有长期稳定性的候选事实。
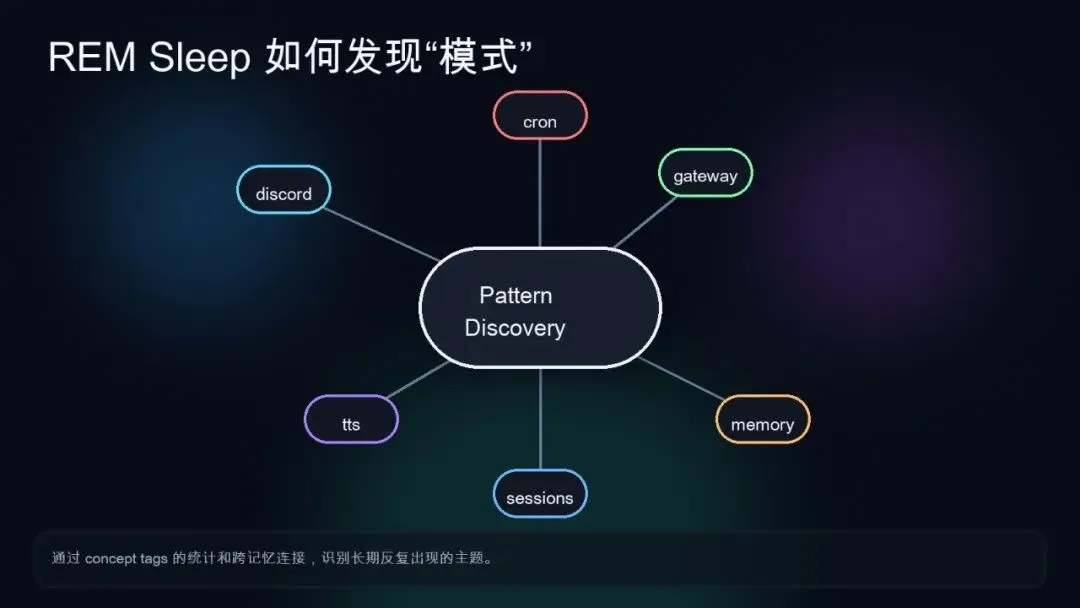
更关键的是,它不是一句“模型觉得这条重要”,而是有置信度计算。候选真理的置信度至少会综合 averageScore、recallStrength、consolidation 和 conceptual richness 等因素。也就是说,它在努力用统计信号证明“这件事不只是出现过,而是反复、有质量地出现过”。
3)Deep Sleep,真正决定什么进入长期记忆
如果说 Light 是采样层,REM 是联想层,那么 Deep Sleep 就是决策层。
这里最值得看的,是它没有用那种简单粗暴的阈值判断,而是做了一整套多维加权评分模型。默认权重大致是:
frequency:0.24
relevance:0.30
diversity:0.15
recency:0.15
consolidation:0.10
conceptual:0.06
最后再叠加来自 Light / REM 的 phase boost,也就是阶段增强信号。

换句话说,它不是“提到三次就永久保存”,而是在看:
有没有在多个查询上下文中出现
有没有跨天重复出现
是否仍然足够新鲜
片段本身的语义密度高不高
前面阶段是否已经把它识别成高价值候选
最终通过筛选的候选,才会写进MEMORY.md。并且每条都有 marker、评分信息和来源位置,既能避免重复晋升,也方便后续回查和解释。
四,它最厉害的地方,是把“记忆整理”做成了系统工程
如果只谈概念,很多团队都会说“我们也在做 AI 记忆”。真正拉开差距的,是你有没有把这些话落成一个可运行、可调试、可恢复的系统。
从调研文档看,OpenClaw 的梦境模式至少具备四个成熟系统才会有的特征:
有调度,通过 Cron 和 Heartbeat 协同驱动,而不是零散触发
有分层持久化,short-term recall、phase signals、event journal、DREAMS、MEMORY 各司其职
有并发与恢复,包括文件锁、原子写入、stale lock 回收、Deep Sleep Recovery
有可观察性,recall.recorded、promotion.applied、dream.completed 都会写入事件日志
这意味着它不再是一个“看起来很聪明”的小技巧,而是一套可持续演进的运行时能力。
五,为什么说它对下一代 Agent 很重要
我越来越觉得,下一阶段 Agent 的竞争,不会只发生在模型能力上。模型当然重要,但如果大家都能接近同等级模型,那么真正拉开体验差距的,往往是运行时。
尤其是这些能力:
长期记忆是不是稳定
多天、多周、多月的信息能不能自然沉淀
系统能不能自动发现用户偏好和重复模式
后台有没有真正自主运行的整理机制
当记忆变多以后,系统会不会越来越乱,而不是越来越聪明
OpenClaw 的梦境模式给出的答案是,Agent 不应该只有“对话时刻的聪明”,还应该拥有“离线时刻的成长”。
今天很多 AI 产品在用户面前表现得很聪明,但用户离开之后,系统几乎什么都不做。它不整理、不复盘、不提炼,也不真正形成长期结构。而梦境模式代表的是另一种范式,白天负责交互,夜里负责整理,长期负责进化。
六,它也不是没有代价
当然,这条路也不是零成本的。首先,梦境系统会消耗额外的后台执行资源,尤其在涉及 REM 分析和叙事生成时,会带来额外的 LLM 成本。其次,再聪明的评分也仍然可能误判。最后,这类系统对配置、日志和长期维护能力的要求都很高。
但这恰恰说明,它触达的是一个真正重要的问题,长期记忆,不只是存储问题,而是治理问题。
七,最后总结一句
看完这份关于 OpenClaw 梦境模式的调研,我最大的感受不是“这个名字很酷”,而是,终于有人开始把 Agent 的长期记忆,当成一个完整运行时问题来设计了。
它有阶段模型,有评分机制,有后台调度,有持久化,有恢复,有观察性,甚至还有一种克制但不轻浮的梦境叙事。
这不是一个孤立的 feature,而是在给 Agent 补上一块长期以来都很缺的能力版图。
如果说很多 AI 系统现在还停留在“会说”,那 OpenClaw 想做的,显然已经更进一步了。它在尝试让 Agent 学会如何回想、如何筛选、如何联想、如何沉淀,以及如何在没有用户盯着它的时候,悄悄变得更好。
这大概就是“梦境模式”最迷人的地方。它不是让 AI 看起来像人,它是在认真思考,怎样让 AI 拥有一点点接近“长期成长”的能力。
