 夜雨聆风
夜雨聆风2026 年,AI 编程 Agent 的真正分水岭,到底在哪里?
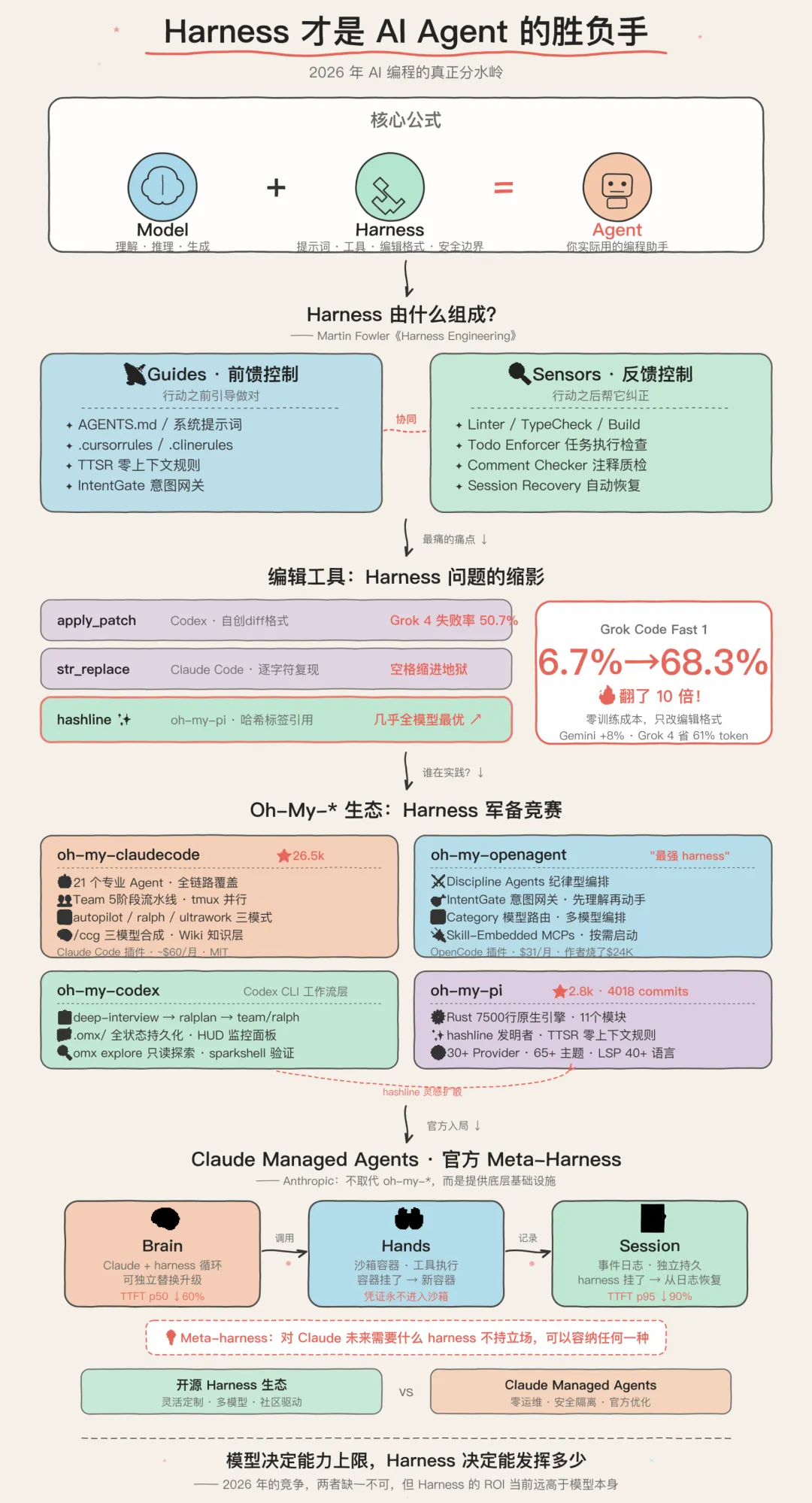
一个反直觉的结论
这几个月你应该也发现了,各家模型隔三差五就刷一波榜
GPT-5.4 来了,Opus 4.6 来了,Gemini 3.1 来了,Grok 4 也来了
大家讨论最多的永远是:哪个模型写代码最牛?
但有个开发者最近做了一组实验:
他把一个编辑工具的格式从
str_replace换成了自己发明的hashline,什么模型都没换,Grok Code Fast 1 的成功率直接从 **6.7% 飙到 68.3%**——翻了十倍。
你拿最新的模型升级,能给你涨几个点?
这个人叫 Can Bölük,一个游戏安全出身的开发者
他维护着一个叫 oh-my-pi 的开源编程 Agent,提交了 4000 多个 commit,底层用 Rust 写了 7500 行原生引擎,就干一件事——打磨 harness
什么是 Harness?
现在社区里有一个越来越清晰的共识:
Agent = Model + Harness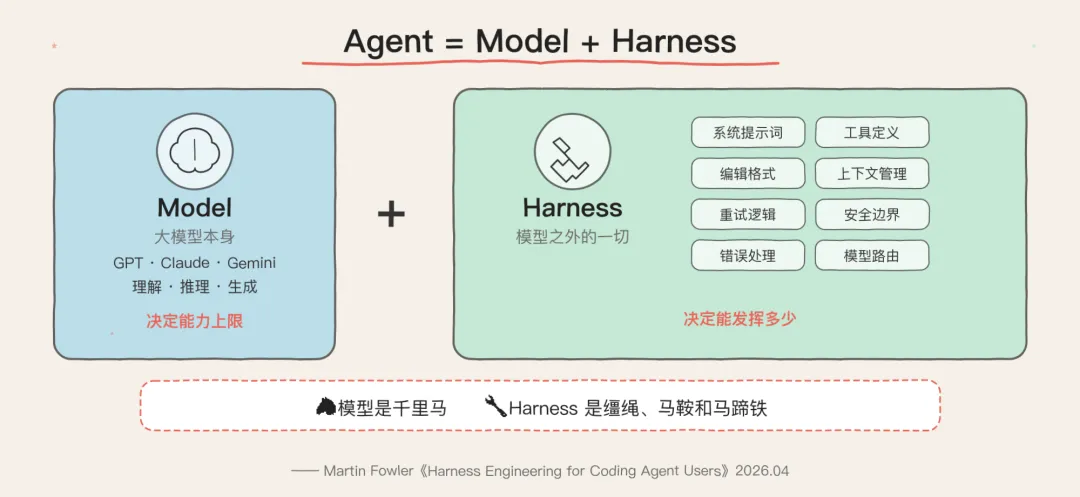
Model 就是大模型本身——GPT、Claude、Gemini,负责理解和推理
Harness 是模型之外的一切——系统提示词、工具定义、编辑格式、上下文管理、错误处理、重试逻辑、安全边界……就是给模型套上的那套装备
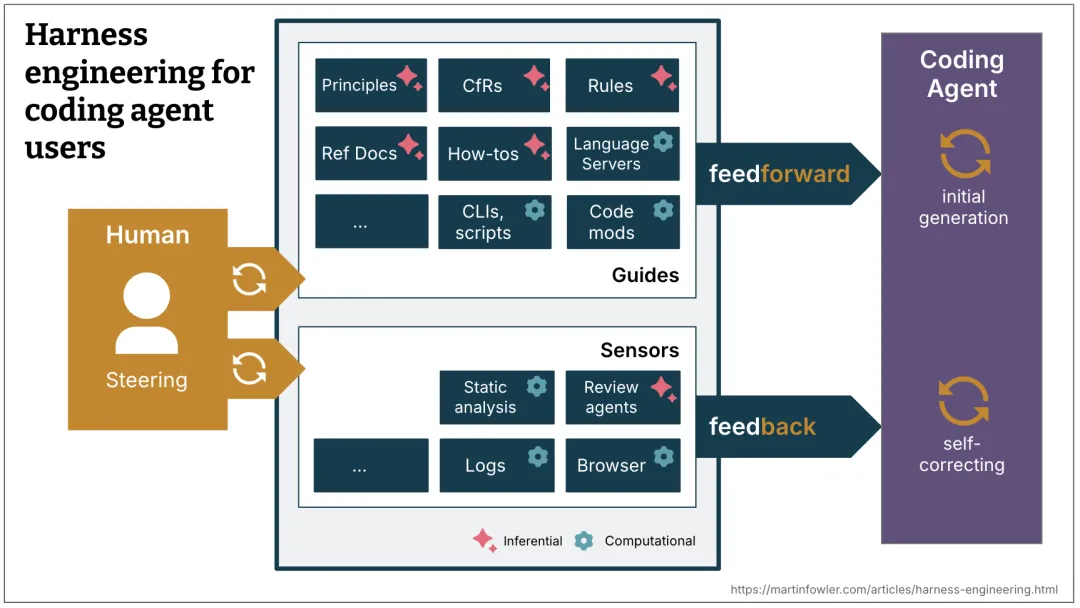
Martin Fowler(《重构》作者)刚刚专门写了一篇长文 《Harness Engineering for Coding Agent Users》,给了一个特别精辟的定义:
Harness 由两部分组成:Guides(前馈控制) 和 Sensors(反馈控制)。Guides 在 Agent 行动之前引导它做对,Sensors 在 Agent 行动之后帮它自我纠正。
打个比方:模型是一匹千里马,harness 是缰绳、马鞍和马蹄铁
没有好的 harness,千里马也只是在原地打转
编辑工具:Harness 问题的缩影
为什么 Can Bölük 的实验那么炸裂?
因为他击中了 harness 最痛的痛点——编辑工具(Edit Tool)
Agent 写代码的核心循环其实很简单:读文件 → 理解问题 → 生成修改 → 写回文件。但"写回文件"这一步,各家的方案差异极大,而且没有一个是完美的:
| apply_patch | ||
| str_replace | ||
| 神经网络合并 |
JetBrains 的 Diff-XYZ 论文和 EDIT-Bench 基准测试也证实了:没有任何一种编辑格式在所有模型和场景下都占优
Can Bölük 的解法叫 Hashline
原理很简单:当模型读文件时,每一行都带上一个 2-3 个字符的内容哈希标签:
11:a3|functionhello() {22:f1| return"world";33:0e|}模型编辑时引用这些标签,如果文件在读取后被修改,哈希不匹配,编辑直接被拒绝
模型不再需要完美复现原文内容,只需要记住一个短标签
结果?16 个模型、3 种编辑格式、每种 540 个任务的大规模测试,hashline 几乎在所有模型上匹配或超越了 str_replace,弱模型获益最大。而且 Grok 4 Fast 的输出 token 下降了 61%——因为不用再烧 token 做重试了
Can Bölük 总结:
Gemini 成功率提升 8%,比大多数模型升级带来的提升都大,而且训练成本是零。 你在怪飞行员技术差,其实是起落架坏了。

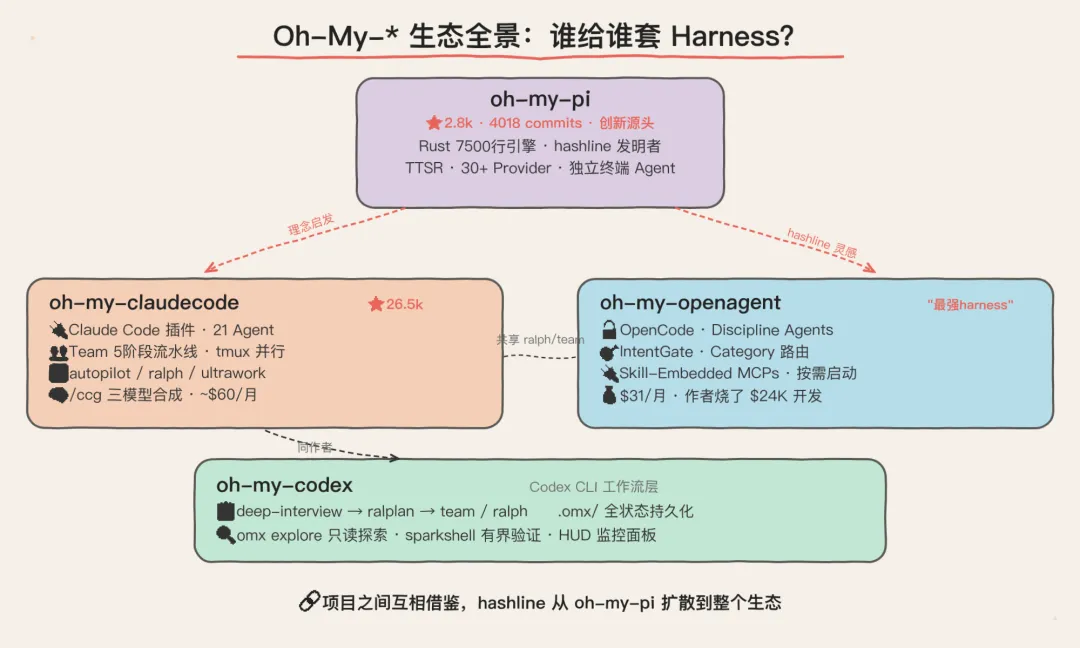
Oh-My-* 生态:Harness竞赛的前线
理解了 harness 的重要性,再看最近 GitHub 上涌现的一批 oh-my-* 项目,就完全说得通了
它们本质上都在干同一件事:给不同的 Agent 引擎套上更强的 harness
oh-my-claudecode (⭐ 26.5k · 2470+ commits)
GitHub: https://github.com/Yeachan-Heo/oh-my-claudecode
号称:"Don't learn Claude Code. Just use OMC."
这是目前 Claude Code 生态里最活跃的插件,它加了21 个专业化 Agent,每个都有独立的系统提示词和工具集,包含 architect、researcher、designer、tester、devops 等角色,覆盖从需求分析到部署上线的全链路。
Team 模式是它的杀手级功能。它跑的是一个 5 阶段流水线:team-plan → team-prd → team-exec → team-verify → team-fix。一句 /team 3:executor "fix all TypeScript errors" 就能启动多 Agent 并行协作,每个 Agent 在 tmux 窗口里独立运行。
三种执行模式满足不同场景:
autopilot:描述需求,自动拆解、分配、执行、验证ralph(Read-Act Loop with Persistent Handling):持续执行循环,直到任务完成或你手动停止ultrawork:无限持久模式,适合超大任务
跨模型协作也是亮点。/ccg 命令实现 Claude + Codex + Gemini 三模型合成。omc ask(Provider Advisor)可以调用 Codex CLI 或 Gemini CLI 做交叉验证——同样的问题问三家,综合最优答案。
其他值得一提的:
HUD 状态栏:实时显示编排指标、token 消耗、Agent 状态 Wiki 知识层:灵感来自 Karpathy 的 LLM Wiki 概念,Agent 可以积累和检索项目知识 OpenClaw 通知系统:Discord/Telegram 实时推送执行状态 Rate Limit 智能等待:触发限流后自动挂起、到期恢复 Autoresearch 模式:轻量级监督的自主研究运行时
安装足够简单:
/plugin marketplace add https://github.com/Yeachan-Heo/oh-my-claudecode/plugin install oh-my-claudecode/setup然后 /autopilot "build a REST API for managing tasks",坐等收菜。
oh-my-openagent(原 oh-my-opencode)
GitHub: https://github.com/code-yeongyu/oh-my-openagent
自称 **"the best agent harness"**,比 oh-my-claudecode 更激进
它直接跟 Anthropic 杠上了——因为 Anthropic 封杀了 OpenCode 对 Claude 的访问
它的态度是:**"Claude Code 是个好监狱,但终究是监狱"**
核心理念:不锁定任何单一模型。Claude 做编排,GPT 做推理,Kimi 做 coding,Gemini 做创意——未来是编排所有模型。作者为此烧了 $24,000 的 LLM token 费来开发这套系统。
最核心的概念叫 Discipline Agents(纪律型 Agent),每个都有独特的行为准则:
Sisyphus( claude-opus-4-6/kimi-k2.5/glm-5):主编排器,负责规划和调度,名字取自永不停歇推巨石的西西弗斯Hephaestus( gpt-5.4):深度自主执行者,给目标就行,不需要手把手,以锻造之神命名Prometheus( claude-opus-4-6/kimi-k2.5):战略规划师,用苏格拉底式提问帮你想清楚再动手Oracle:知识型 Agent,负责搜索和信息聚合 Librarian:文档管理专家
IntentGate(意图网关) 是它独创的概念——先分析用户的真实意图再行动。你说"帮我改一下这个 bug",它会先判断你是想快速修还是想彻底重构,避免 Agent 对指令的字面误解。
Category-Based Model Routing(基于类别的模型路由) 也很聪明——不是按模型名指定,而是按任务类别(visual-engineering、deep、quick、ultrabrain)自动分发,底层绑定最合适的模型。
Skill-Embedded MCPs:每个 Skill 自带 MCP 服务器,需要时按需启动,不需要全局挂载。内置三个高质量 MCP:Exa(网络搜索)、Context7(官方文档查询)、Grep.app(GitHub 代码搜索)。
其他硬核功能:
Hash-Anchored Edit Tool:灵感直接来自 oh-my-pi 的 hashline Background Agents:5+ 专家并行执行 Todo Enforcer + Comment Checker:强制执行 TODO 清理,禁止"AI 味"注释(比如 "// This function handles…" 这种废话注释) Session Recovery:API 故障、上下文超限都能自动恢复 ** /init-deep**:自动生成分层 AGENTS.md,给每个子目录写专属上下文
完全兼容 Claude Code 的 hooks、commands、skills、MCP
oh-my-codex
GitHub: https://github.com/Yeachan-Heo/oh-my-codex
针对 OpenAI Codex CLI 的 harness 层
核心定位:Codex 负责执行,OMX 负责流程
标准工作流是一个 4 阶段管道:$deep-interview(深度需求访谈)→ $ralplan(生成执行计划)→ $team(并行执行)/ $ralph(循环执行直到完成)。先搞清楚要做什么,再规划怎么做,最后上手干。
.omx/ 目录存储所有状态——计划、日志、记忆、运行时状态,每次执行都有迹可循。omx explore 做只读的代码库探索,omx sparkshell 做有边界的 shell 验证。通过 .codex/hooks.json 对接 Codex 原生 hook 系统,加上 HUD 监控面板,你能清楚看到每一步在干什么。
oh-my-pi (⭐ 2.8k · 4018 commits)
GitHub: https://github.com/can1357/oh-my-pi
下面是 oh-my-pi 的 LSP 集成效果和 hashline 编辑工具的实际截图:
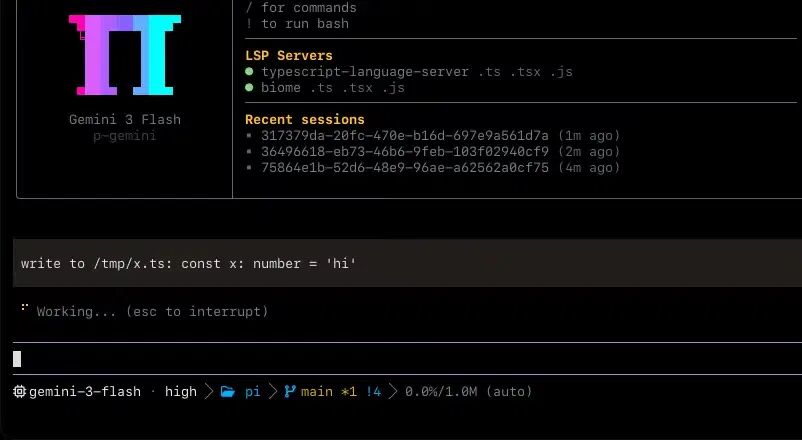
Can Bölük 的"小兴趣项目",实际上是整个 harness 创新的源头
它是一个完全独立的终端编程 Agent,不依赖任何现有 CLI——底层用 Rust 写了约 7,500 行原生 N-API 引擎,编译成 11 个 native 模块(grep、shell、text、keys、highlight、glob、task、ps、prof、image、clipboard、html),性能拉满
除了 hashline,它还有一堆硬核功能:
LSP 集成:支持 40+ 语言的 IDE 级代码智能,加上 AST-Grep 做 25 种语言的模式感知代码搜索 TTSR(Time Traveling Streamed Rules):零上下文消耗的规则系统。普通的系统提示词会占用宝贵的上下文窗口,TTSR 的规则只在模型输出匹配特定模式时才"时间旅行"式注入,平时完全不占位 30+ AI Provider 支持:通过 /login命令接入 OpenAI、Anthropic、Google、xAI、DeepSeek、Mistral 等所有主流平台,支持多凭证轮换和用量感知选择Model Roles: default(日常)、smol(快速小任务)、slow(深度推理)、plan(规划)、commit(提交信息),按角色自动选模型Browser 工具:内置 14 个隐身脚本,绕过反爬 SSH 工具:远程服务器命令执行 Cursor Provider:可以当 Cursor 的后端用 图片生成:集成 Gemini 的图片生成能力 65+ 内置主题:终端也要好看
这四个项目,画出了 harness 军备竞赛的全景图:你的 Agent 能有多强,取决于你给它套的装备有多硬。 而且它们之间还在互相借鉴——oh-my-openagent 的 Hash-Anchored Edit Tool 直接学的 oh-my-pi 的 hashline,oh-my-codex 和 oh-my-claudecode 共享 ralph/team 等执行模式。
Claude Managed Agents:Anthropic 的"官方 Harness"
说完开源社区的探索,再来看 Anthropic 官方
他们最近推出了 Claude Managed Agents,本质上就是 Anthropic 自己下场做了一个托管式 harness 服务。
是什么?
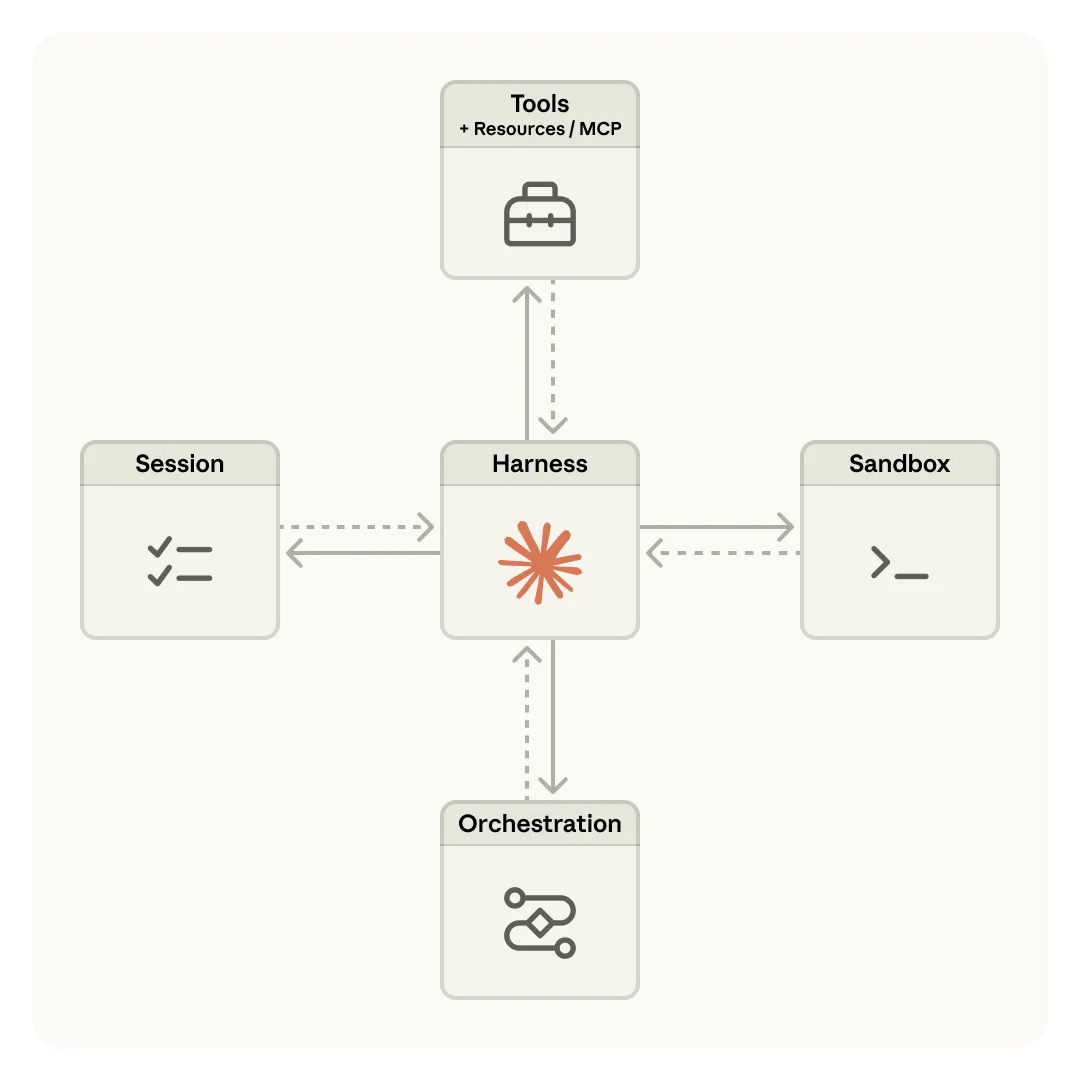
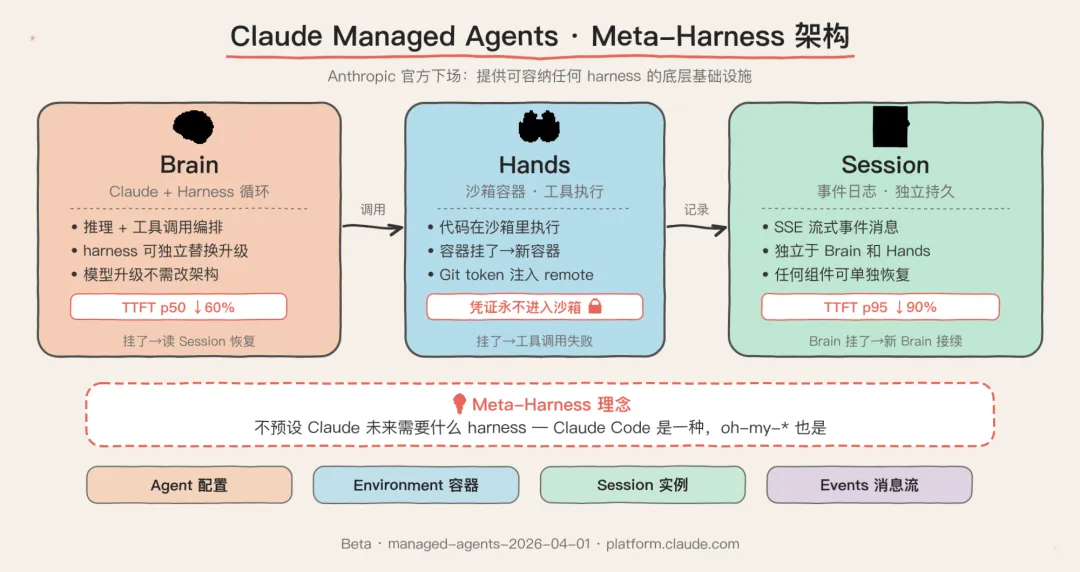
下面这张图来自 Anthropic 工程博客,展示了 Managed Agents 的整体架构——Brain、Hands 和 Session 三层解耦:
根据 官方文档,Claude Managed Agents 是一个:
预构建、可配置的 Agent Harness,运行在托管基础设施上。
它由四个核心概念组成:
| Agent | |
| Environment | |
| Session | |
| Events |
为什么要做这个?
Anthropic 工程团队在 官方博客 里讲了他们的设计哲学,这段话特别关键:
Harness 编码的是对 Claude 能力的假设,而这些假设会随着模型进步而过时。
Claude Sonnet 4.5 在上下文接近极限时会"焦虑"地草草收工,所以 harness 里加了上下文重置机制。但到了 Opus 4.5,这个行为消失了,重置机制反而成了累赘。
所以他们的解法是:把 harness 本身做成可替换的抽象层。
"大脑"和"双手"分离
这是 Managed Agents 最精彩的设计。他们把 Agent 拆成了三部分:
Brain(大脑):Claude + harness 循环 Hands(双手):沙箱容器、工具执行 Session(记忆):事件日志,独立于大脑和双手

每一部分都可以独立失败、独立替换。容器挂了?harness 把它当作一次工具调用失败,让 Claude 决定是否重试,新容器随时初始化。harness 挂了?新 harness 读取 session 日志,从上次事件恢复。
这个设计带来的性能提升也很炸裂:**p50 TTFT(首 token 延迟)下降了约 60%,p95 下降超过 90%**。因为不需要每次都等容器启动。
安全上也更干净:生成的代码在沙箱里执行,凭证永远不会进入沙箱。Git token 在容器初始化时注入到 git remote,MCP OAuth token 通过独立代理处理。Agent 永远碰不到真正的密钥。
和开源 harness 的关系
Anthropic 在博客最后说了一句意味深长的话:
Managed Agents 是一个 meta-harness(元 harness),它对 Claude 未来需要什么样的具体 harness 不持立场。Claude Code 是一个优秀的 harness,特定任务的 Agent harness 在窄领域表现更好。Managed Agents 可以容纳任何一种。
翻译过来:Anthropic 不是要取代 oh-my-claudecode 们,而是提供了一个底层基础设施,让各种 harness 都能跑在上面。
不过,结合他们之前封杀 OpenCode 的操作,这个"开放"到底有多开放,还有待观察。
所以,"harness 才是分水岭"这个说法对吗?
我觉得对了一大半,但需要补充:
对的部分:在模型能力差距日益缩小的今天,harness 确实是决定 Agent 实际表现的最大变量。Can Bölük 的基准测试已经证明,光改编辑工具的格式就能让弱模型翻十倍,强模型也能提升 5-14 个百分点。Martin Fowler 说得好:光有反馈没有前馈,Agent 会重复犯同样的错;光有前馈没有反馈,规则永远不知道有没有用。两者缺一不可。
需要补充的部分:harness 的提升有天花板。Martin Fowler 也坦言,对于"诊断错误"、"过度工程"、"误解指令"这类高阶认知问题,目前的 harness 手段还不能可靠地解决。这些最终还是要靠模型能力的提升。
所以更准确的说法是:
模型决定了 Agent 的能力上限,harness 决定了 Agent 能发挥出多少。 2026 年的竞争格局,两者缺一不可,但 harness 的投资回报率当前远高于模型本身。
总结
| 定位 | ||
| 模型绑定 | ||
| 核心优势 | ||
| 适合谁 |
#Harness #AgentCoding #ClaudeCode #OhMyClaudeCode #AI编程
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
