 夜雨聆风
夜雨聆风
OpenClaw的现实安全风险

王文轩
中国人民大学信息学院讲师
人工智能治理研究院研究员
OpenClaw作为一个能听懂自然语言、自主调用工具、完成多步骤复杂任务的AI助手。它可以对接Gemini等大模型,支持终端操作、聊天界面交互,还能设置定时任务、后台心跳执行,实现7×24小时自动化运行,不用用户一直盯着。
其具有个性化agent的三个核心安全特性:
1、持续运行与长程交互
2、积累用户隐私信息
3、调用高权限工具
这三点核心特性放大了安全风险,使得它的安全风险从大语言模型的“非期望文本生成” 升级为“不安全操作执行”、“隐私资产泄露”,且攻击可跨阶段传播、长期留存。持续运行意味着攻击影响会不断累积,掌握私有信息意味着隐私泄露代价巨大,高权限工具则让攻击者有机可乘——一旦被操控,后果远不止 “生成错误内容”,而是真实的隐私窃取、资产损失、系统被篡改。如今,这类个性化 AI 代理正走进金融、医疗、日常办公等场景,它的安全风险越来越值得我们的关注。
随着OpenClaw爆火,其安全事件层出不穷。例如,Cisco 扫描了 31,000 个 Skill,发现超过四分之一存在安全漏洞;ClawHacvoc大规模恶意Skills投毒,一旦用户执行恶意安装步骤,攻击者便可获取 SSH 密钥、浏览器密码、加密货币钱包私钥、云服务 API 密钥等敏感数据;Meta 安全专家在测试OpenClaw 时,因 AI 处理大量邮件时遗忘 “未经确认不得操作” 的安全约束,批量删除其 200 多封工作邮件。为此,国家信息安全漏洞库(CNNVD)发布通报,2026年1月到3月9日,共采集到82个OpenClaw漏洞,存在极大的安全隐患。
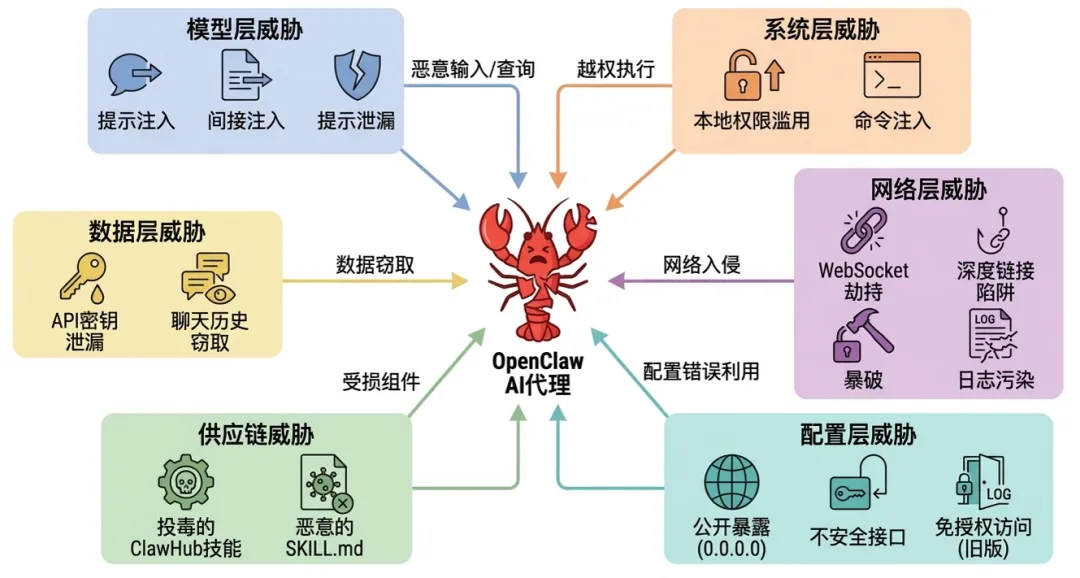
OpenClaw风险范围示意图
OpenClaw安全风险场景
在一项研究中,来自西电的研究团队围绕个性化 AI 的真实使用场景,设计了三大测试场景,几乎覆盖了日常使用这类OpenClaw的所有情况,而OpenClaw在每个场景中,都暴露出了明显的脆弱性。
场景 1:访问外部内容时,恶意指令会 “悄悄潜入”
我们经常需要从网页、社区帖子或外部文档获取信息,而这些渠道也可能成为攻击者的突破口。即便你的操作本身完全无害,文档中隐藏的恶意指令也可能被无意间执行,导致系统采取错误操作。
例如,攻击者可能在普通网页中嵌入隐蔽指令,当系统读取这些内容时,可能会自动调用“发送邮件”功能,将敏感文件发往指定邮箱,或者运行未知程序,对设备造成潜在威胁。
场景 2:长期存储的记忆成“定时炸弹”
个性化AI的一大优势是有“长期记忆”,通常会保存用户的操作历史和偏好,这在提升体验的同时,也带来了安全隐患。攻击者可以通过“记忆投毒”,将恶意内容写入系统的长期存储,即使攻击结束,这些内容仍可能在后续操作中被触发,持续影响系统行为。
研究发现,长期存储的信息更容易被提取,意味着隐私泄露风险更高。同时,攻击者还可能修改系统记忆中的标记,使其在执行正常任务时违背用户意图,例如擅自修改文件或更改账户权限,这种影响甚至会跨会话持续存在。
场景 3:过度信任工具返回结果,风险链条放大
系统对各种插件、工具或外部服务的返回信息往往默认信任,这给了攻击者可利用的机会。通过篡改工具返回内容,攻击者可以植入恶意指令,诱导系统执行不安全操作。
例如,系统调用“数据导出”工具后,如果返回内容被篡改,可能进一步触发“云盘上传”等操作,将敏感数据上传到攻击者服务器,从而形成一条连锁攻击链。
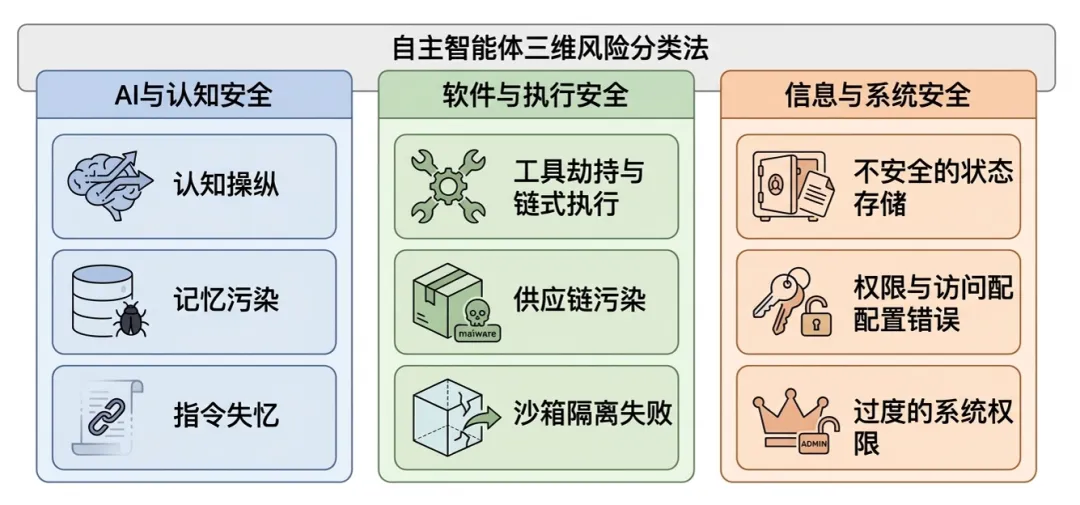
自主智能体的三维分类法
OpenClaw风险分类
过往研究将OpenClaw安全具体分成三个维度,从人工智能与认知维度,软件与执行维度到信息与系统维度,具体阐述了OpenClaw各类风险的理论风险要素和实际观测到的漏洞情形。
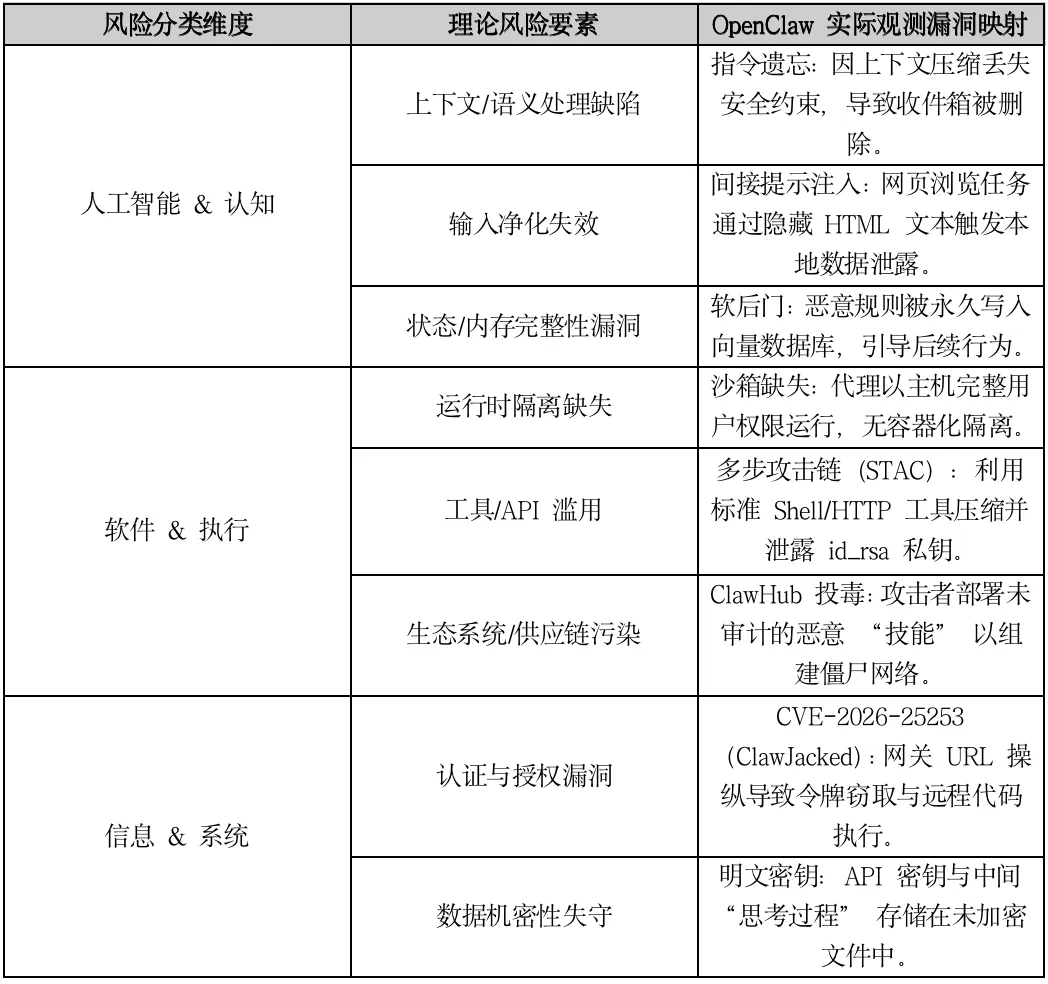
OpenClaw的三层风险分类及实际风险情形
第一层:AI与认知风险
这类风险源于大模型自身的认知缺陷,不是代码bug,而是模型本身“脑子不清醒”,模型在理解、执行指令时的逻辑漏洞,防不胜防。
上下文/语义处理缺陷:典型问题就是指令遗忘。AI在处理大量信息时,会因为上下文压缩,丢掉提前设置的安全约束,比如你明明禁止它删除重要文件,它却因为遗忘了安全规则,直接清空收件箱、删掉关键数据。
输入净化失效:在执行工具进行浏览网页、读取文档时,Agent会被隐藏在HTML文本、PDF里的恶意指令诱导,不知不觉执行本地数据窃取操作,产生可能偷偷把你的隐私文件打包外发的危险行为。
状态/内存完整性漏洞:攻击者可能通过向量数据库植入恶意规则,使Agent记忆有“毒”,长期遵循不安全指令,形成潜在的“长期内鬼”,影响系统安全。
第二层:软件与执行风险
这一层是OpenClaw最核心的架构缺陷,运行环境完全不隔离,权限失控,攻击者轻易就能突破。
运行时隔离缺失:OpenClaw执行如果没有沙箱保护,相当于直接在你的电脑上裸奔,没有容器化隔离,一旦被控制,攻击者就能获得和你一样的系统权限,掌控整个设备,相当危险。
工具/API滥用:Agent的工具组合使用能力会被利用,攻击者使用序列式工具攻击链,单个操作看似无害,比如压缩文件、发起网络请求,但组合起来,Agent就能用系统自带的Shell、HTTP工具,打包窃取你的私密密钥(比如id_rsa私钥),导致隐私泄露。
供应链污染:OpenClaw支持安装第三方拓展技能,因此攻击者可以试图上传未审计的恶意技能,伪装成实用工具,在安装后控制你的设备发起攻击。
第三层:信息与系统风险
涉及数据存储、账号权限的基础安全,OpenClaw一样存在安全隐患。
认证与授权漏洞:存在CVE-2026-25253(ClawJacked)高危漏洞。通过操纵网关URL,就能窃取登录令牌,实现远程代码执行,直接接管整个OpenClaw代理。
数据机密性失守:API密钥、Agent的思考过程、中间处理数据,如果存储在未加密的文件里,任何人拿到文件,都能直接查看你的核心隐私和账号凭证。
总结
像OpenClaw这样的个性化智能助手未来必将深度地融入工作和生活,而真正可靠的系统,需要在研发、部署、运行的每个环节都把安全作为核心设计原则。只有这样,系统才能成为高效的助手,而不是潜在的安全隐患。
OpenClaw的问题反映了一个普遍趋势:当系统具备自主决策和执行能力时,带来的便利也伴随着新的风险。我们必须清楚认识到,能力的扩展同时意味着风险边界的扩大,但自主化不意味着放任,而是要在安全框架下释放价值。
未来,随着自主智能体系统在各行各业的广泛应用,安全将成为其规模化部署的前提。只有正视潜在风险,才能确保AI技术发展稳健、可持续。

图片来源于网络,如有侵权,请联系删除

