 夜雨聆风
夜雨聆风昨天刷到一条消息,字节Seed团队发了Seeduplex,说是「原生全双工语音大模型」,豆包App已经全量上了。
全双工?这玩意儿终于有人搞出来了?

你平时跟语音助手聊天,Siri也好,小爱同学也好,以前的豆包也好,都是半双工。你说话它在听,它说话你等着,一问一答,回合制,打乒乓球一样。
但真人聊天不是这样啊。真人边听边说,对方说话的时候你接「对对对」,两个人可以同时发声,还能在对方没说完的时候就接上话茬。这叫全双工。
AI语音交互搞了这么多年,一直卡在半双工。不是不想做,是真的难。让模型同时听和说,背景噪音怎么搞?用户犹豫的时候怎么判断是停顿还是说完了?多人说话的时候怎么分清谁在跟AI说话?
Seeduplex这次直接上了,坦率的讲还是有点东西的。
它解决两个核心问题。
一个是精准抗干扰。
这个我太有体会了。你开车用语音助手,导航一直在响,收音机还在放,旁边可能还有人在说话,你跟AI说个「帮我查一下明天天气」,它可能把导航的声音也听进去了,给你回一句「好的,已为您导航到......」

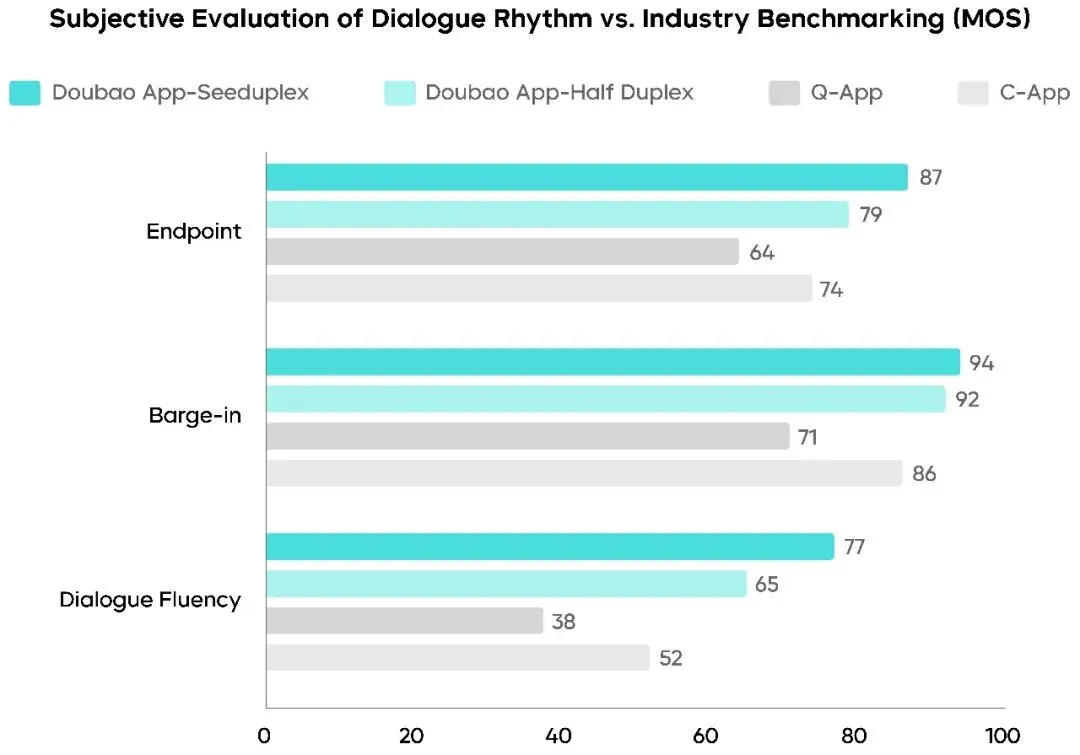
Seeduplex的做法是给模型装了一双持续「倾听」的耳朵。不是你说话它才听,是一直在听,持续感知整个声学环境。背景噪音、导航播报、旁边人闲聊,统统过滤掉,精准锁定你。官方数据,复杂场景下误回复率和误打断率比半双工模型少了一半。
一半。这数字还是挺硬的。
另一个是动态判停。
这个才是我觉得最厉害的。判停,就是判断用户什么时候说完了。听着简单,实际巨难。你自己说话,是不是经常「嗯......」「那个......」停顿半天?你是在思考,不是在等AI接话。但传统模型听到你停了,就默认你说完了,立马开始回。你话还没说完呢,它就开始抢话。
我之前用语音助手被这个问题烦得不行。稍微停顿一下想措辞,它就抢着回答了一个我没问的问题。然后还得说「不是,我还没说完」,它再道歉,一个简单的事搞了好几个来回。
Seeduplex的动态判停,是把语音特征和语义特征合在一起判断。不光看你停没停,还要理解你在说什么,你是不是真的说完了。你犹豫思考它耐心等,你说完了它秒速响应。抢话比例降了40%。
这两个能力加一块,人机语音交互终于不用再像对讲机了。
几个有意思的数据。
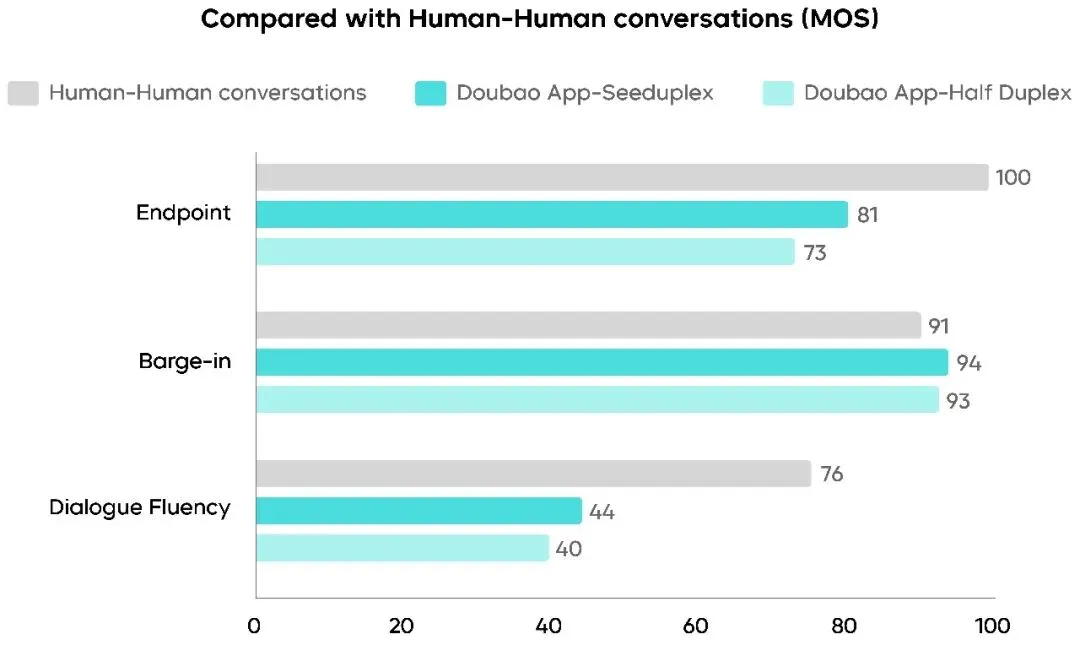
判停延迟降了约250ms,打断响应延迟缩了约300ms。什么概念?真人对话里,一个人说完到另一个人接话,平均间隔大概200-500ms。Seeduplex的打断响应已经略优于真人对话平均水平了,反应速度比真人还快一丢丢。
大规模A/B测试,整体通话满意度绝对值提了8.34%,对话流畅度MOS分提了12%。用户反馈里「抢话」「响应慢」「误打断」这几个词的提及比例明显下降,通话时长和留存也都正向。
还有个细节挺打动我的。Seeduplex能做环境感知联动,它能听到背景声音,把这些信息用到回复里。你开车有导航播报,它知道你在开车,回复会更简洁。你在咖啡厅跟朋友聊天中间插了一句问AI,它知道你不是专门跟它说话,会更聪明地判断该不该接话。

Seeduplex不是凭空冒出来的,豆包上一代端到端语音模型的升级,背后是字节自研LLM底座、海量语音预训练数据、架构层面的创新和推理优化。字节说用投机采样和量化优化解决了高并发卡顿,能扛住亿级用户。
这次直接全量上线,不是灰度,不是白名单,所有人更新豆包就能用。这种信心还是挺足的。
回到行业格局这块,全双工语音大模型这条赛道2026年以来一下子热闹了。
腾讯开源了70亿参数的Covo-Audio,分层三模态架构,冲着GPT-4o语音能力的开源替代去的。阿里云有Qwen3-Omni,语音交互延迟低至211ms,走全模态融合路线。面壁智能的MiniCPM-o 4.5,9B参数就搞出了全双工全模态交互。智源研究院也开源了RoboBrain-Audio,原生全双工架构。
各家路径不一样,终点都指向一个,让人机对话无限逼近人与人之间的自然交流。
不过Seeduplex有一点其他人目前还没做到,规模化落地。技术再好,实验室里跑得通不算数,得上到亿级用户才算真正跑通了。豆包月活在那摆着,全量上线就是最大的差异化。
我自己对全双工语音交互这事一直挺关注的。不是因为觉得它多酷炫,是因为我总觉得这可能是AI真正融入日常生活的关键一步。
你想想,现在跟AI交互,大部分时候还是打字。打字,等回复,再打字。这种交互方式,说到底还是用一种不自然的方式跟机器沟通。语音不一样,语音是人类最自然、最本能的交流方式。如果一个AI能像真人一样跟你打电话,你不需要等它说完才能说话,你可以随时打断,它会听、会等、会判断,那这种体验会彻底改变人和AI的关系。
从半双工到全双工,听着只是技术参数的提升,但交互体验上,这是从「对讲机」到「打电话」的质变。
字节官方也提了后续方向,要引入视觉模态,语音助手从「听和说」进化到「听、看、想、说」多维协同,往通用智能体方向走了。
最后说怎么体验。更新豆包App到最新版,对话框里选「打电话」进语音通话界面就行。目前需要选「桃子音色」,应该还在逐步放开其他音色的全双工支持。
我去试了一下,确实跟之前不一样了。说话中间停顿思考它不会抢话,稍微嘈杂的环境下也能准确识别我说了什么。离完美的真人对话体验还有距离,但方向是对的。
你觉得全双工语音交互会改变什么?评论区聊聊。
技术更新太快,一个人追不过来?关注 「AI小集市」,我帮你筛选最有价值的AI开源项目与实战技巧,每周还有AI科技周报总结。
更多往期精选:
