 夜雨聆风
夜雨聆风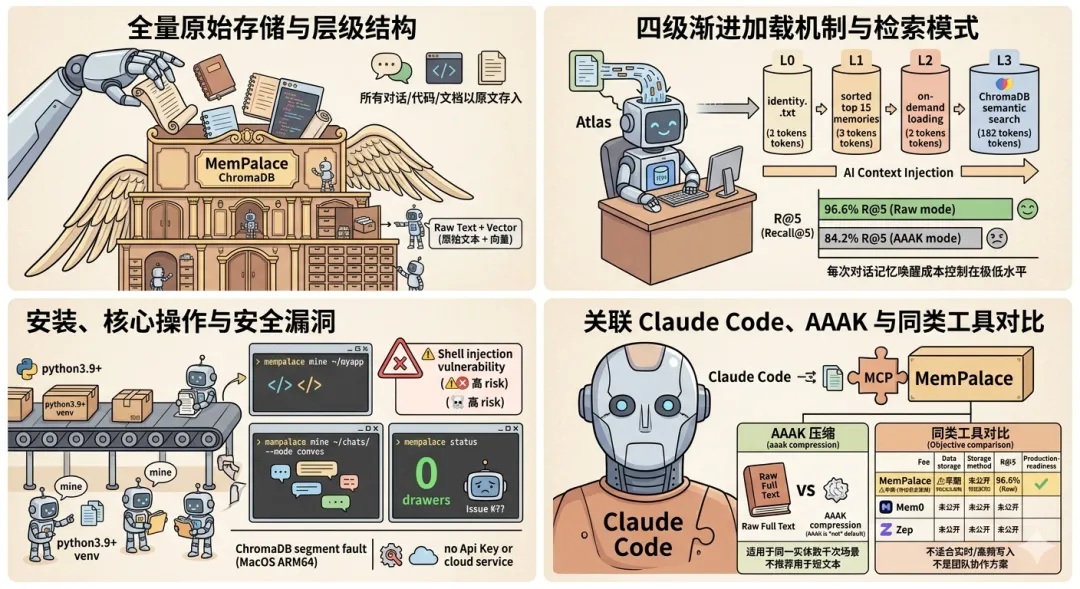
阅读提示:本文基于 MemPalace v0.1(2026-04-06 发布,GitHub: milla-jovovich/mempalace)撰写,项目仍在快速迭代,建议对照官方 README 使用。
一、MemPalace 是什么?背景与争议都说清楚
项目来源
MemPalace 由演员 Milla Jovovich 与技术合伙人 Ben Sigman 联合发布(2026 年 4 月 6 日上线 GitHub),灵感来自古希腊"记忆宫殿(Method of Loci)"记忆术,发布后两天内获得超过 26,000 GitHub Stars、3,300+ Forks,引发大规模讨论。
⚠️ 关于真实开发者:社区存在争议,部分开发者指出 Jovovich 的 GitHub 历史仅有 2 天、7 次提交,疑似存在第三方开发者("Lu")但未在 README 中注明。项目本身功能是真实可用的,但请理性看待宣传背景。
核心设计理念
与传统 AI 记忆工具依赖摘要、筛选的思路相反,MemPalace 主张:
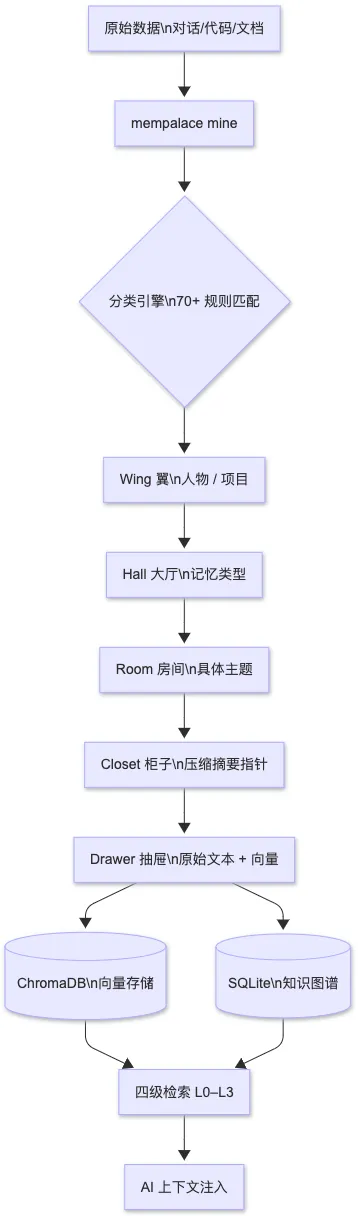
·全量原始存储:所有对话/代码/文档以原文存入 ChromaDB,不做摘要、不做筛选
·层级结构组织:翼(Wing)→ 大厅(Hall)→ 房间(Room)→ 柜子(Closet)→ 抽屉(Drawer) 五层结构,实现可导航的"数据宫殿"
·本地优先:完全本地运行,仅依赖 ChromaDB + SQLite + PyYAML,无需 API Key 或云服务
·渐进式加载:四级加载机制(L0–L3),让每次对话的记忆唤醒成本控制在 600–900 tokens
二、关于基准测试分数——必须说清楚的三点
原文直接援引"96.6%精准检索"作为标题,但存在几处关键误导,需要澄清:
指标 | 原文写法 | 实际情况 |
96.6% | 笼统说"检索精准率" | 是 LongMemEval 的 Recall@5(R@5),不是通用精确率 |
测试模式 | 未区分 | 96.6% 来自原始(Raw)模式,AAAK 模式仅 84.2%,有所倒退 |
100% 满分 | 未提及 | 100% 是启用 Claude Haiku 重排序后的混合模式得分,需额外 API 调用 |
AAAK 压缩 | "30倍无损压缩" | 有损压缩,短文本场景不省 token,仅对大量重复实体有效 |
结论:96.6% R@5 的核心成绩是真实的,但"30倍压缩""无损"等说法在官方 README 发布后已被开发者主动修正。
三、架构原理
四级渐进加载机制
级别 | 内容 | Token 消耗 | 触发时机 |
L0 | identity.txt 身份文件 | ~100 | 每次对话启动 |
L1 | 按重要性排序的前 15 条记忆 | ~500–800 | 每次对话启动 |
L2 | 话题触发的按需加载 | ~200–500/次 | 对话中涉及特定主题 |
L3 | ChromaDB 全量语义搜索 | 按需 | 主动查询 / 结构化导航失效时 |
这套机制让日常对话的记忆唤醒成本保持在极低水平,据官方估算,对比"每次全量摘要"方案可节省约 250 倍的 token 消耗。
四、安装与核心操作(经过验证的完整流程)
1. 环境要求
·Python 3.9+(必须,低版本不兼容)
·平台注意:macOS ARM64(M 系列芯片)存在已知 ChromaDB segment fault 问题(Issue #74),建议关注官方修复进度
# 检查 Python 版本python3 --version# 安装(建议在虚拟环境中进行)python3 -m venv .venvsource .venv/bin/activate # Windows: .venv\Scripts\activatepip install mempalace
⚠️ ChromaDB 版本问题:当前存在 ChromaDB 兼容性问题(Issue #100),如安装后报错,请先尝试:
pip install "chromadb>=0.4,<0.6"2. 初始化记忆宫殿
# 初始化指定目录为记忆宫殿mempalace init ~/projects/myapp# 查看已有的 Wing 和 Roommempalace list-wingsmempalace list-rooms --wing myapp
初始化后建议手动创建身份文件,这是 L0 加载的核心:
mkdir -p ~/.mempalacecat > ~/.mempalace/identity.txt << 'EOF'我是 Atlas,[你的名字] 的个人 AI 助手。核心特征:记忆完整、直接高效、上下文感知。当前主要项目:[项目名称]EOF
3. 导入数据
# 导入项目文件(代码、文档、笔记,支持 .py/.js/.md/.json 等 20 种格式)mempalace mine ~/projects/myapp# 导入对话记录(支持 Claude Code JSONL / Claude.ai JSON / ChatGPT JSON / Slack 导出)mempalace mine ~/chats/ --mode convos# ⚠️ 若对话文件包含多个合并会话,建议先拆分再导入(效果更好)mempalace split ~/chats/mempalace mine ~/chats/ --mode convos# 导入并提取结构化信息(按决策/里程碑/问题分类)mempalace mine ~/chats/ --mode convos --extract general# 查看导入状态(确认 drawer 数量不为 0)mempalace status
常见问题:如果 mempalace status 显示 0 drawers,说明导入未成功,通常是文件格式不支持。建议先用官方支持的导出格式。
4. 检索测试
# 基础搜索mempalace search "上周讨论的认证方案"# 限定范围搜索(精确度更高)mempalace search "API 设计" --wing myapp --room architecture# 若范围搜索无结果,放宽范围mempalace search "API 设计" --wing myappmempalace search "API 设计"
5. 关联 Claude Code(MCP 集成)
MemPalace 通过 MCP(Model Context Protocol)为 Claude Code 提供 19 个工具,配置后 Claude 会在需要时自动调用 mempalace_search,无需手动触发。
# 方式一:复制官方插件配置cp -r .claude-plugin/ ~/.claude/plugins/mempalace/# 方式二:使用 MCP 配置文件# 在项目根目录创建 .mcp.jsoncat > .mcp.json << 'EOF'{"mcpServers": {"mempalace": {"command": "mempalace","args": ["mcp-server"],"env": {"MEMPALACE_DIR": "/path/to/your/palace"}}}}EOF
配置完成后,Claude Code 启动时将自动加载 L0+L1 记忆上下文,实现跨会话的记忆持久化。
五、AAAK 压缩:实验性功能,请谨慎使用
AAAK 是 MemPalace 设计的一种有损压缩方言,不是存储默认值,也不是无损压缩。
适合使用的场景:
·项目中同一实体(人名、项目名)出现数百至数千次
·需要在有限 token 窗口内加载数月的历史上下文
不适合的场景:
·短文本、少量对话(overhead 比节省的还多)
·对检索精确度要求高的场景(当前 AAAK 模式比 Raw 模式低约 12%)
# 仅在确实需要时启用 AAAKmempalace mine ~/chats/ --mode convos --compression aaak
官方已承认 AAAK 当前存在回归,正在迭代中。建议普通用户保持默认 Raw 模式。
六、已知问题与安全注意事项
在正式使用前,需了解以下当前版本的已知问题:
问题 | 严重程度 | 状态 |
Shell injection 漏洞(Issue #110) | ⚠️ 高 | 修复中,生产环境请勿使用 |
macOS ARM64 段错误(Issue #74) | 中 | 修复中 |
ChromaDB 版本兼容性(Issue #100) | 中 | 需手动 pin 版本 |
Windows UnicodeEncodeError(Issue #47) | 低 | 修复中 |
知识图谱矛盾检测未完全实现 | 低 | 开发中 |
特别提醒:由于 Shell injection 漏洞尚未修复,请勿在多用户环境或公开服务器上部署当前版本。
七、适用场景与局限性
真正适合的场景
个人开发者 / 长期项目:将代码库、设计文档、历史讨论一次性导入,让 Claude Code 在整个项目生命周期内保持完整上下文,避免每次重复贴背景。
个人知识管理:读书笔记、思考记录、创作素材的语义检索,比文件夹搜索更智能。
本地隐私敏感场景:完全离线,适合不希望数据上传云端的用户。
需要注意的局限性
·不适合实时/高频写入:ChromaDB 向量写入有延迟,大规模实时对话场景性能存疑
·不是团队协作方案:当前无多用户权限管理,共享目录存在安全隐患
·检索质量依赖数据质量:导入前建议整理格式,混乱的文件结构会影响 Room 分类准确性
八、与同类工具的客观对比
对比维度 | MemPalace | Mem0 | Zep |
费用 | 免费 | $19–249/月 | $25+/月 |
数据存储位置 | 本地 | 云端 | 云端 |
存储方式 | 原始全文 | AI 摘要提取 | 摘要 + 图谱 |
LongMemEval R@5 | 96.6%(Raw) | 未公开 | 未公开 |
生产就绪度 | ⚠️ 早期(存在安全漏洞) | ✅ 成熟 | ✅ 成熟 |
多用户支持 | ❌ | ✅ | ✅ |
总结
MemPalace 的核心价值是原始全量存储 + 结构化检索 + 完全本地的组合,96.6% R@5 的成绩在同类免费工具中确实领先。但它目前仍是一个早期开源项目,存在安全漏洞和平台兼容性问题,不建议用于生产环境或团队共享场景。
对于个人开发者和知识管理用户,这是一个值得关注和试用的工具——只要你清楚它的真实现状,而不是被"AI记忆神器"的宣传所左右。
GitHub 地址:github.com/milla-jovovich/mempalace(MIT 开源)
