 夜雨聆风
夜雨聆风
零成本,本地跑通Gemma 4大模型(全程不到10分钟)建议收藏!
花了不到10分钟,在自己笔记本上跑通了谷歌最新的Gemma 4大模型。
总成本0元。不买API,不装Python,不折腾CUDA,下完模型文件之后拔网线照样用。
这篇把整个过程拆干净:你的电脑能不能跑、该选哪个版本、怎么一步装好、装完能干嘛、会踩什么坑。看完直接照着做。
先说Gemma 4是个什么?
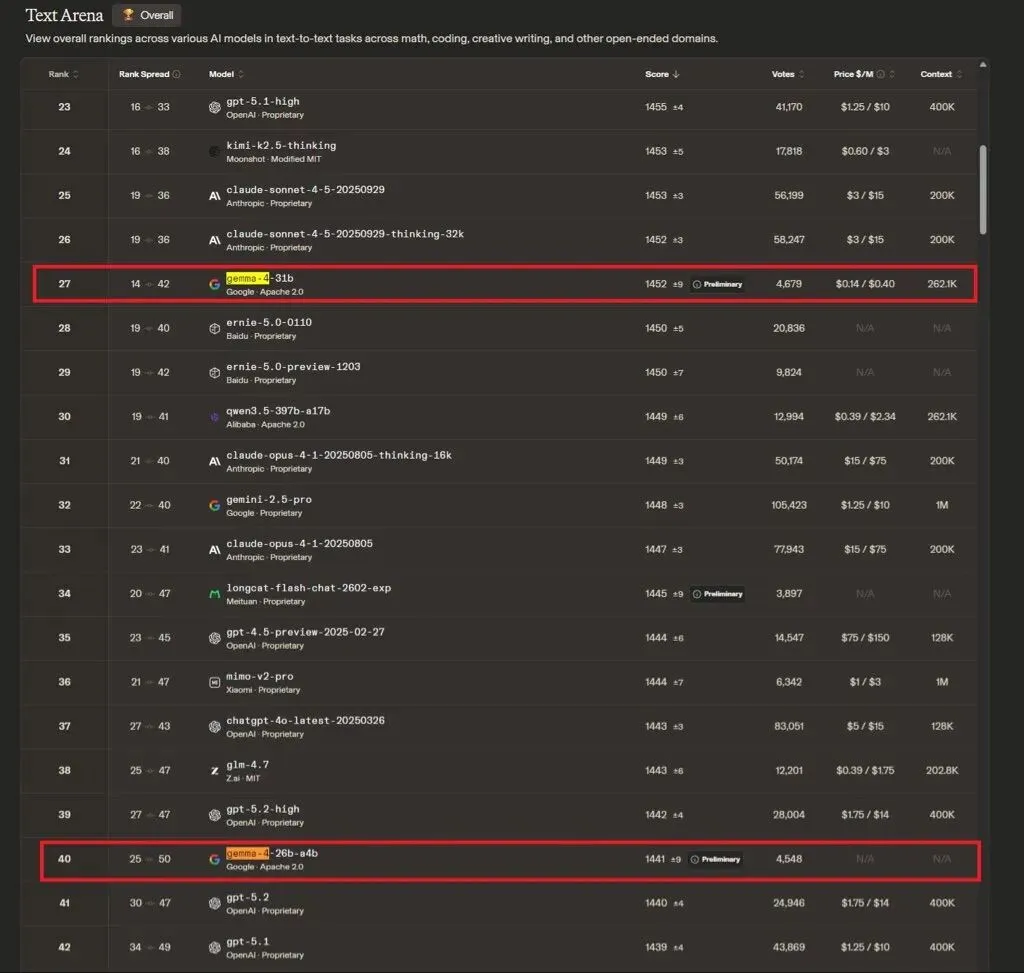
4月2号谷歌DeepMind开源的模型家族,在它发布48小时后Ollama上被拉了207万次。Arena AI开源排行榜第三名。Apache 2.0协议——可以商用、微调、再分发,随便搞绝对的开放。
跟你之前见过的开源模型最大的区别:它出了四个版本,精准卡住从手机到工作站的每一档硬件,基本任何设备都能跑。
第一步:你的电脑能跑哪个版本?
这是最关键的,选错了要么跑不起来要么卡的要死。
对照着看:
- E2B(有效参数2.3B)——下载7.2GB,吃内存约5GB。8GB内存的老笔记本就能跑。能聊天能看图,别指望深度推理,但体验流程够了。树莓派都能上。
- E4B(有效参数4.5B)——下载9.6GB,吃内存约6GB。16GB内存的笔记本流畅运行,这是大多数人的起点。编程benchmark(HumanEval)80分,Gemma 3同体量只有29分。不是进步,是换了个物种。
- 26B MoE(总参数252亿,每次只激活38亿)——下载18GB,推荐16GB以上显存。这个版本最骚:质量接近31B满血版,速度和资源消耗接近小模型。有个开发者双3090实测结论是"Gemma 26B强过Qwen 35B"。24GB显存的Mac或独显卡最合适。
- 31B Dense(全量307亿参数)——下载20GB,要24GB以上显存。Arena排行榜第三就是这个版本的成绩。RTX 4090或M系列Mac 32GB以上内存才能跑舒服。
拿不准的,就选E4B。16GB内存的电脑几乎都能跑,性价比最高。
第二步:装Ollama 超简单的!
Ollama就是本地AI的Docker,模型下载、推理引擎、API服务全包了。
先去 ollama.com 下载安装包。Windows双击exe装完,Mac拖进应用程序目录。Linux一行命令:
curl -fsSL https://ollama.com/install.sh | sh
装完打开终端输入 ollama --version,能显示版本号就成了。注意版本必须0.20以上,旧版不支持Gemma 4,这是个坑,好几个人栽在这了。
第三步:一条命令拉模型跑起来
终端输入你选的版本对应的命令:
ollama run gemma4:e4b
回车。第一次会自动下载模型文件,看网速,几分钟到半小时不等。下完直接进入对话界面,打字就能聊。
就这么简单。没了。
其他版本的命令备查:
- ollama run gemma4:e2b # 最小版,啥电脑都能跑
- ollama run gemma4:26b # MoE版,性价比之王
- ollama run gemma4:31b # 满血旗舰
装完能干什么?
跑起来之后Ollama在本地11434端口开了个API服务,格式兼容OpenAI。意思是——你原来调ChatGPT的代码,改一行base_url就能对接本地模型:
python# 把这行
base_url = "https://api.openai.com/v1"
改成这行
base_url = "http://localhost:11434/v1"
能看图。Gemma 4全系列支持图片输入,丢张截图让它分析、丢张表格让它提取数据,都行。
能当编程助手。接到OpenClaw或者其他代码编辑器里,代码审查、写测试、解释报错,六七成的日常编程任务本地就能干。有人在MacBook Air上跑这套组合,完全免费。
能断网用。模型文件下到本地之后,就做到跟云端没有任何关系,对数据敏感这是最优解了。
飞机上、高铁上、公司内网不让访问外部API的环境里——都能用。数据不出你的电脑。
怕命令行?还有图形界面方案。
装个LM Studio 桌面软件,直接搜索gemma4下载模型点击对话,全程鼠标操作都能完成呀。右侧实时显示显存占用,方便判断你的配置压力大不大。开发者模式还能一键起本地API服务,端口1234,同样兼容OpenAI格式,是不是更简单。
说说可能会踩的坑吧。
- 第一个坑:Ollama版本太旧。切记哦低于0.20的版本拉不下来Gemma 4,报错信息还贼不明显。先 ollama --version 确认一下,不够就去官网重新下载最新的。
- 第二个坑:选大了模型跑不动。16GB内存硬上31B,不是报错就是卡死。别逞强,E4B和26B MoE对大多数人够用了,一定量力而行啊兄弟们。
- 第三个坑:工具调用(function calling)的早期bug。很多人提说E4B在编程工具里不调用工具还瞎编。Ollama 0.20.3已经修了Gemma 4的工具调用格式问题,确保你用的是最新版。
- 第四个坑:31B量化版早期bug。Simon Willison测过,某些GGUF版本对每个prompt输出"---"可能会死循环。不过呢现在应该修了,但如果碰到了,换个量化版本或者等更新。
跟云端模型比到底差多少?
说句实话:差。大概差10%-15%。复杂的多文件重构、微妙的架构决策、需要极长上下文精确理解的任务,还是云端模型更稳。
其实在真实使用场景,能有多少任务真的需要那最后15%?
像我这种条件不允许的,最佳方案就是混着用。简单的事本地干,便宜是主要的,家庭条件就这样没办法啊,复杂的切云端。大概六七成的活根本不需要花钱啦。B站好几个博主的实测结论也差不多 Gemma 4本地跑日常够用,中文场景如果觉得差点意思呢,你可以配个Qwen3.5 27B,两个模型Ollama里能共存随时切。
想想
6GB内存。
Gemma 4 E4B在Unsloth Studio里用6GB内存就能搜索引用10多个网站、执行代码找最佳答案。6GB内存跑一个能搜网页写代码的AI Agent——两年前真的可能都不敢想。
你那台电脑的潜力,可能比你以为的大得多。
快试试吧,有什么问题关注我随时交流!
