 夜雨聆风
夜雨聆风AI资讯要点
【要闻筛选】
- OpenAI:推出100美元 ChatGPT Pro订阅档位,相比plus会员提供5倍codex使用量
- Overworld:发布实时扩散世界模型Waypoint-1.5,可在消费级硬件上使用
其他AI资讯
【AI 创作】
- Figma:推出Figma Weave(节点式工作流画布)可创建和编辑图像、视频、3D模型等内容
【AI 应用/模型】
- Anthropic:Claude Cowork面向所有订阅用户开放,并上线企业管控功能
- Anthropic:推出“顾问工具”(advisor tool)的新API功能,实现“模型调用性价比最优解”
- Google :Gemini 可根据用户提问,生成可自定义的交互式可视化效果(如:动态图表,3D模型)
- MiniMax:发布MMX-CLI命令行工具,可调用全模态模型能力实现从资料搜集到视频制作自动化
- 阿里:开源VimRAG,支持图文视频混合内容的知识库检索系统
👇进群,不错过每日最新AI资讯噢~


💡主要内容
OpenAI:推出100美元 ChatGPT Pro订阅档位,相比plus会员提供5倍codex使用量
OpenAI 在现有 Go、Plus 和 200 美元 Pro 套餐之间新增 Pro 100 美元订阅,面向高强度工作者,提供更大的使用额度和高级模型访问。
用户权益:
- Codex使用量: 相较于现有的Plus计划,Pro档提供了5倍的Codex使用量,并且在限定时间内提供10倍的Codex使用量,以满足专业编码需求。
- GPT-5.4 Pro推理: 订阅用户可获得更高级的GPT-5.4 Pro模型推理能力。
- 无限GPT-5.3与文件上传: 提供对GPT-5.3模型的无限制访问以及文件上传功能。
- 图像生成: 享受无限次且更快速的图像生成服务。
- 消息限制: GPT-5.4模型每5小时可发送200-1000条本地消息;GPT-5.4-mini模型每5小时可发送600-3500条本地消息。

VV⭐使用地址:
https://chatgpt . com/zh-Hans-CN/pricing/Overworld:发布实时扩散世界模型Waypoint-1.5,可在消费级硬件上使用
Overworld公司发布实时扩散世界模型Waypoint-1.5,这一版本延续了此前的实时生成世界理念,重点提升画面质量并降低硬件门槛,使普通游戏电脑即可体验 AI 原生世界。
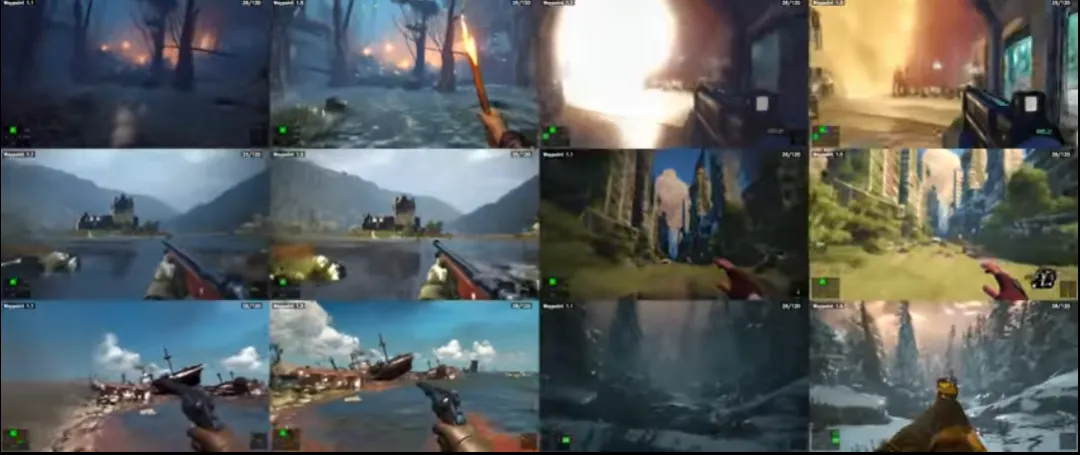
- 双模型规格:推出 720p 和 360p 两个版本,分别面向高性能设备和更广泛的游戏电脑,使实时生成环境可以在更大范围的消费级 GPU 上运行。
- 训练数据大幅增加:Waypoint‑1.5 的训练数据量是上一代的近 100 倍,提升了环境生成的连贯性和动作一致性。
- 实时性能优化:采用更高效的视频建模技术,减少帧间冗余计算,实现最高 720p60fps 的实时世界生成
用户体验方式:
- 通过Overworld Biome运行时在本地设备上运行(提供简易的EXE安装程序)
- 通过Overworld.stream服务在浏览器中即时访问和体验,无需任何本地设置。
1.5版本与1.0版本对比:
🌟项目地址:
https://over.world/blog/waypoint-1-5🤖️AI 创作
Figma:推出Figma Weave(节点式工作流画布)可创建和编辑图像、视频、3D模型等
Figma 收购 AI 内容平台 Weavy 并推出新产品 Figma Weave(节点式工作流画布),它将AI能力融入设计流程,使用户能够直接在Figma环境中创建、编辑和组合图像、视频、3D模型等多种媒体内容,从而实现从提示词到可扩展工作流的转变。
用户可为不同 AI 模型创建节点,根据任务需要选择模型并连接节点,生成、分支、混合和优化产出,Weave支持将AI提示词转化为可扩展的工作流,例如:
- 图像风格融合: 结合两张图片定义新的风格指南。
- 多比例变体生成: 根据品牌风格生成不同长宽比的图像变体。
- 多重扭曲效果探索: 对同一图像应用多种扭曲效果,快速找到最佳视觉呈现。
- 图像转3D模型: 将任何物理参考图像转换为可自由旋转的3D模型。
- 视频元素合成: 将动画元素合成到视频渲染中,并导出生产。
⭐项目地址:
https://www.figma.com/blog/five-figma-weave-workflows/🤖️AI 模型/应用
Anthropic:Claude Cowork面向所有订阅用户开放并上线企业管控功能
Anthropic 宣布 Claude Cowork 正式结束“研究预览”阶段,面向所有付费用户开放,并推出多项企业级管控功能。
其中企业管控功能包括:
- 基于角色的访问控制: 企业管理员现在可以根据用户组(手动或通过SCIM)分配自定义角色,精细控制不同团队成员对Claude功能的访问权限。
- 团队消费限额: 管理员可以在管理控制台中设置每个团队的预算,实现可预测的成本管理。
- 使用分析: Claude Cowork的活动数据现在可在管理仪表板和分析API中查看,管理员可以跟踪会话、活跃用户、技能和连接器调用等,以评估采用情况和优化工作流程。
- 扩展OpenTelemetry支持: Claude Cowork现在会发出工具和连接器调用、文件读写、技能使用等事件,并与标准SIEM管道兼容,增强了可观测性。
- 工具连接器控制: 管理员可以限制每个MCP连接器在组织范围内的可用操作,例如只允许读取而不允许写入。
⭐相关信息:
https://claude.com/blog/cowork-for-enterpriseAnthropic:推出“顾问工具”(advisor tool)的新API功能,实现“性价比最优解”
Anthropic推出名为“顾问工具”(advisor tool)的全新API功能,其核心理念是让成本较低的模型(如Sonnet或Haiku)作为执行者处理日常任务,当遇到复杂问题时,再由成本较高的模型(如Opus)作为顾问提供策略指导,从而在平衡智能与成本之间实现最优解。
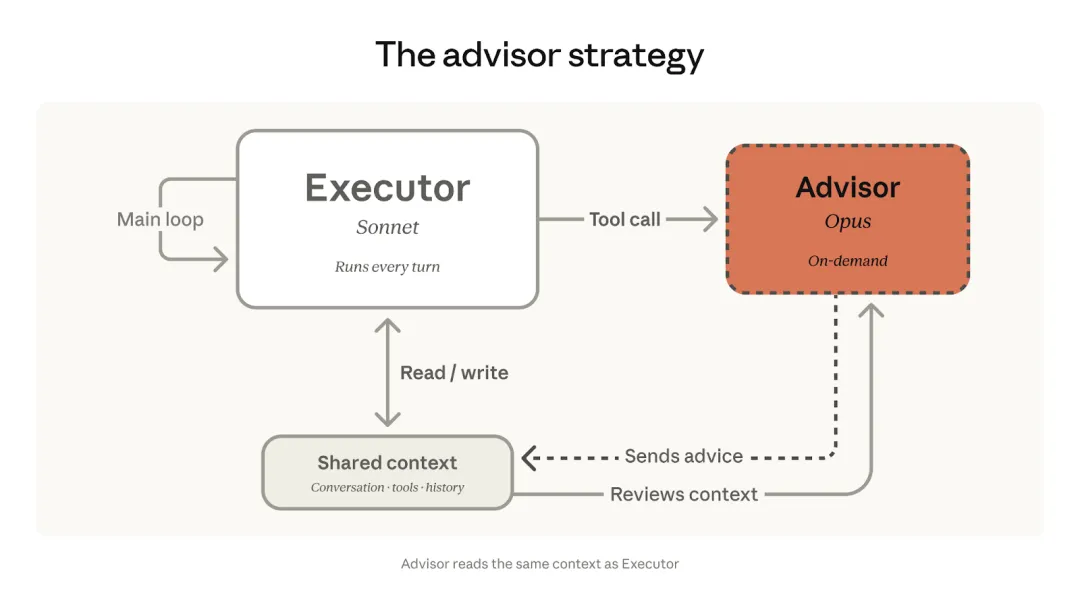
工作机制:执行模型在生成过程中可调用更强大的顾问模型,顾问会读取完整对话,输出约 400‑700 字的计划或纠错建议,然后执行模型继续任务。
适用场景:适合 长程代理任务(如编码代理、电脑操作、多步骤研究流程),大部分步骤由成本低的模型完成,但关键规划由高智力模型提供。
成本控制:相比直接使用高端模型,组合模式在保持质量的同时降低了总体开销;需要在请求头中加入 advisor-tool-2026-03-01 beta 标记。
模型搭配:有效的执行与顾问模型组合,例如 Sonnet + Opus、Haiku + Opus 等。
⭐阅读更多:
https://claude.com/blog/the-advisor-strategyGoogle :Gemini 可根据用户提问,生成可自定义的交互式可视化效果
Google Gemini现在能够根据用户的提问生成可自定义的交互式可视化效果,包括互动图表和3D模型,使用户能够更直观、深入地探索复杂概念,从而将文本问答转化为动态的、可操作的学习体验。
- 互动图表: 用户可以生成各种图表,并通过调整滑块或输入精确数值来实时查看变量如何影响结果,例如模拟月球绕地球轨道的参数变化。
- 3D模型: 能够生成3D模型,例如旋转分子结构或模拟复杂的物理系统,用户可以自由旋转和探索这些模型。
这一功能改变了以往仅限于文本和静态图表的响应模式,提供了功能性的模拟,帮助用户更好地理解所提问的主题。
该功能正在全球范围内向所有Gemini应用用户推出。用户可以在gemini.google.com上选择Pro模型,并通过“show me”或“help me visualize”等提示词来体验。
⭐阅读更多:
https://blog.google/innovation-and-ai/products/gemini-app/3d-models-charts/MiniMax:发布MMX-CLI命令行工具,调用全模态模型能力,实现从资料搜集到视频制作自动化
MiniMax发布了MMX-CLI命令行工具,这是一个专为AI Agent设计的多模态命令行工具,旨在让Agent能够更便捷地调用MiniMax的全模态模型能力,从而实现从资料搜集到视频制作等一系列自动化工作流。

仅需两行代码即可完成MMX-CLI的安装和调用。
npx skills add MiniMax-AI/cli -y -gnpm install -g mmx-cli同时,MMX-CLI无缝接入MiniMax Token Plan,可以显示套餐用量。
要点:
- 全模态能力支持: Agent可以通过MMX-CLI调用MiniMax最新的编程、视频生成、语音合成、音乐创作等全模态模型,实现“资料搜集—生成文案—合成语音旁白—配图配乐—视频制作”等完整自动化工作流。
为了保障 Agent 在自动化运行中的稳定性和解析的准确性,我们在 MMX-CLI 的底层设计上做了针对Agent友好型优化:
- 输出隔离与纯数据模式: 将进度条、模型状态等人类友好的提示信息输出到stderr,而stdout仅输出干净的文件路径或JSON数据,确保Agent获取的结果纯净,易于解析。支持--quiet和--output json彻底切断交互式界面。
- 语义化状态码: 失败时返回数字代号,Agent无需阅读英文报错即可判断错误类型并决定是否重试,支持鉴权失败、参数错误、超时、网络异常等独立退出码。
- 非阻塞与异步任务控制: 参数不全时直接退出,避免任务卡死;长耗时任务支持--async一键转后台,满足Agent并行处理多任务的需求。
⭐阅读更多:
https://mp.weixin.qq.com/s/d067bWUdhqYwvfehoYKtVw阿里:开源VimRAG,支持图文视频混合内容的知识库检索系统
阿里巴巴通义实验室正式开源了VimRAG项目,这是一个创新的多模态知识库检索系统,能够高效处理图文视频混合内容,并实现跨模态的信息提取与问答,为企业级知识助手的构建提供了坚实的基础设施。
VimRAG旨在解决传统RAG(检索增强生成)系统在处理多模态长上下文任务时的局限性,通过“结构化记忆”机制,让AI能够像人类一样理解和利用混合模态信息。
亮点:
- 动态记忆图: 引入动态记忆图,使检索过程可回溯、可试错,提高了检索的准确性和灵活性。
- 视觉能量分配: 智能分配视觉处理资源,实现“该省省,该花花”的效率优化,确保关键视觉信息的有效利用。
- 图引导优化: 通过图结构引导模型学习“记重点”,提升了模型在复杂多模态数据中提取核心信息的能力。
⭐项目地址:
https://bailian.console.aliyun.com/cn-beijing/?tab=app#/knowledge-basevhttps://github.com/Alibaba-NLP/VRAG⚠️部分内容由AI生成,可能存在偏差
💗有任何疑问,请提前联系邮箱:alolg@163.com
