 夜雨聆风
夜雨聆风AI 被平权后,人还能做些什么?成为掌控 AI 的制造者或者是「无用个体」。这篇内容主要整理了 3 月由 Openjobs AI 联合失序实验室及 Meta Space 共同呈现的线下沙龙的部分「精华分享」,与大家分享,希望对大家有所帮助。以下是正文,enjoy~
一、Jerry:用 Agent 加速机器学习,「你睡觉的时候,它在帮你炼丹」
Jerry,OpenJobs AI联合创始人兼CTO,Purdue University 计算机科学博士。
2023 年,Jerry 花了数月完成的一篇分布式机器学习训练论文的实验,如今交给 Claude,一个下午就全部搞定。这不是个例,而是大模型彻底改变机器学习游戏规则的缩影。
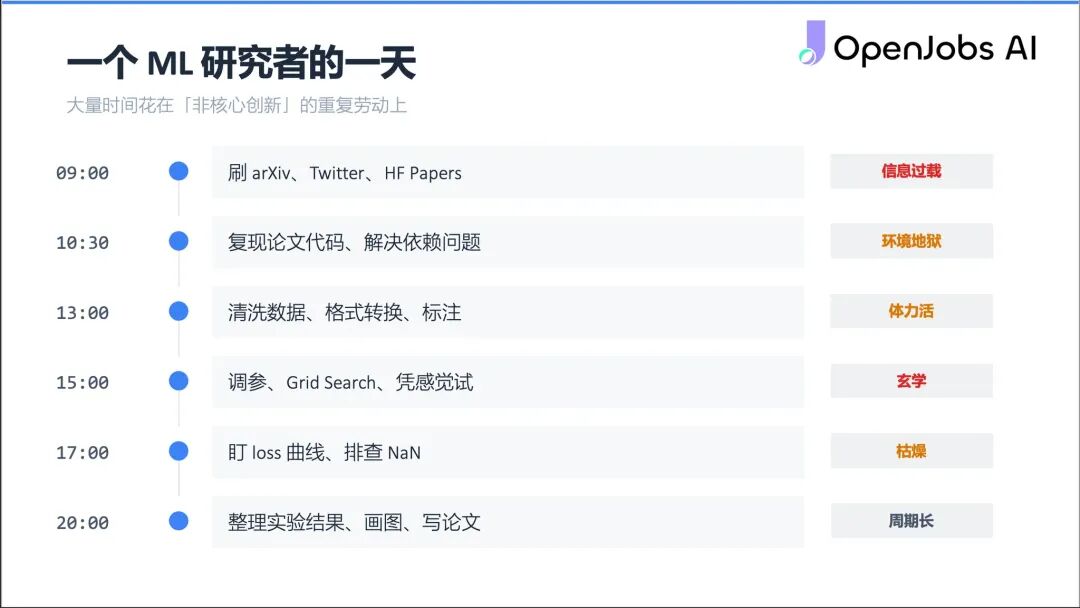
#1 机器学习曾经有多痛苦?
传统的机器学习研究,Jerry 用「炼丹」来形容——像古代炼丹师一样不断往里加东西,每次不一样,有时效果好有时效果差,但永远不知道为什么。自己要花大量的时间刷 arXiv、Twitter、复现代码(大部分复现不了)、收集打标清洗数据、按天按周按月调参,最后还要写论文。整个过程极其消耗时间和精力,这也是 ML Engineer 和 ML Scientist 薪资一直居高不下的根本原因。
#2 Agent 带来了什么改变?
现在,Agent 已经可以承担研究、代码生成、模型训练追踪、论文理解、实验配置、Debug 和结果分析等几乎所有环节。尤其是代码生成,从去年下半年起出现质的飞跃——PyTorch、CUDA、C/C++ 这些底层代码,基本无需太多人工干预就能生成高质量版本。
但 Jerry 特别强调:如果只是用大模型做碎片化的任务,机器学习的连贯性就会断裂。数据处理完了要写代码,代码必须跟数据兼容,训练可能持续几小时甚至几天——这正是需要一个「有智慧的 Agent」来管理整个流程的原因,而 OpenClaw 正好承担了这个角色。
#3 实战案例:一个下午,准确率从 80% 提到 99%
Jerry 分享了自己训练小模型的经验:OpenJobs AI 最开始做用户训练的时候,用户输入需要被分类,最初用大模型判断,但随着调用量增加,成本高到扛不住。于是他决定训练一个小模型:
让 OpenClaw 用 Auto Research 框架生成几万条训练和测试数据;
让它找一个能在 CPU 上运行的模型——最终选了一个基于 BERT 架构的轻量模型;
用评估数据集训练——一个下午,准确率从 80% 提升到 99%。
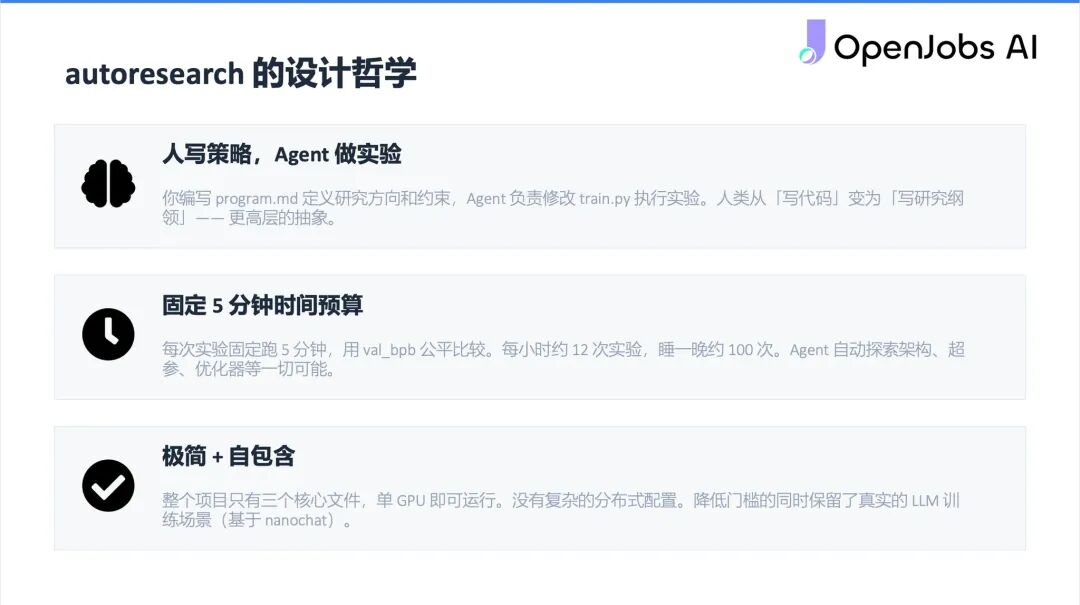
#4 Auto Research 的哲学
Jerry 重点推介了 Auto Research 框架:核心理念是「你写策略,Agent 做实验」。它不会一口气做完所有事再评估,而是大约五分钟跑一轮,通过 loss 曲线判断效果,不断迭代。单块 GPU 即可运行,而且——「你睡觉的时候,它在帮你炼丹。」
#5 对小团队的建议
Jerry 最后的对小团队训练模型的建议:评估业务中有多少任务在用大模型——如果连简单的标签分类都调高级 API,用户量上来后成本根本 cover 不住。小团队完全可以用 OpenClaw + Auto Research 框架,采集数据、训练轻量模型,部署到业务中。
如果你对 OpenJobs AI 感兴趣,现在已经开放注册体验,目前只针对北美、新加坡市场,感兴趣的可以在官网注册了解更多:https://www.openjobs-ai.com/
二、张云剑:AI 视频的四个阶段,「你越想控制它,越难控制它」
张云剑,ZeroCut 创始人&CEO,在 360 工作了 13 年,从应届生做到导航事业部负责人,经历了 PC 到移动到 AI 的完整互联网周期。他坦言:「如果没有 AI,互联网真的到了瓶颈期。」
#1 「养虾」翻车记:两只 OpenClaw 的故事
随着 OpenClaw 的爆火,自己也养了 2 只「小龙虾」,结局都不如人意。
第一只:养不起。 安装很顺利,充了 40 块钱会员。但用起来最大的问题是「我不知道它干了什么」——发了指令,它也在干,但具体做了什么,完全不清楚。他想到一个办法让它截图发回来,但截图太多 token 消耗爆炸,第二天一问,积分用完了。40 块钱一晚上啥也没干。
第二只:养死了。 一键封装版本,前期读文件、做图做视频都可以,最大好处是用微信就能下指令。结果微信出了新版本的客户端,服务连接断掉了,最后也没有 debug 成功。他总结了根本原因:「我不知道让它帮我干什么,没有目标,就没有动力。」
这也道出了大多数人养 OpenClaw 失败的本质——不是工具不够强,而是自己没有清晰的目标和任务。
#2 AI 视频发展的四个阶段
阶段一:手搓。 多模态工具出来后靠提示词工程逐帧制作。他手搓了一条给央视频的视频,在快手播放量达 1500 万,四小时热榜第七。证明了用户和平台都能接受 AI 内容。但手搓最大的问题是:多平台来回切换(Kimi 写脚本、即梦生图、Vidu 生视频)、下载上传命名繁琐、文件管理混乱。
阶段二:工作流。 通过 API 和大模型串联完成一系列任务。有 MCP 协议之后更灵活。但工作流随着需求增加变得极其复杂,而且没有创造力、不能出错——任何一个分支出错就满盘皆输,非常脆弱。
阶段三:Agent。 有记忆、有规划能力、有工具箱,能够理解业务上下文。张云剑说:「对个人来说,多用它本身就是一种训练的过程——你不需要去训练模型,它懂你。」
阶段四:OpenClaw。 核心能力是操作电脑、远程控制、Skill 生态和定时任务。但他也直接点出了问题:安全隐患(本质是木马行为)、远程控制「像异地恋」(你不知道它在干嘛)、Skill 质量参差不齐、费钱。
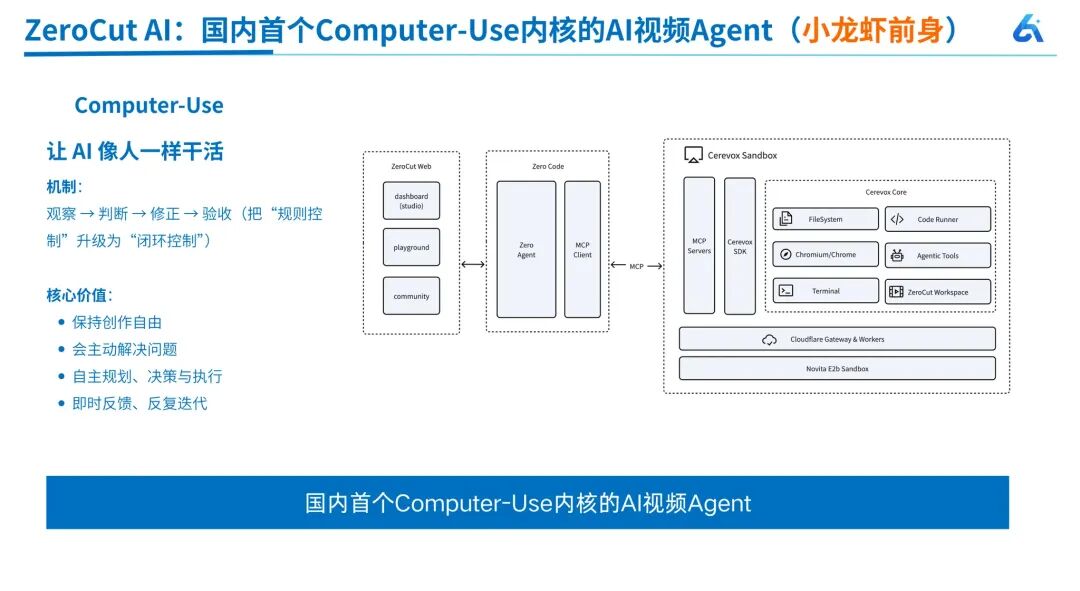
#3 ZeroCut 的产品设计:Computer Use + 云沙箱
针对上述问题,ZeroCut 采用了「Computer Use + 云沙箱」的架构:用户发出需求后,不在本地处理,而是在云端初始化一台「小电脑」,配备文件系统、代码运行环境、浏览器和 Agent 工具。任务完成后即时销毁,API Key 用完即毁,安全性极高。同时设立「工作目录」作为安全边界——AI 在目录内想怎么做就怎么做,不会破坏外部环境。
关于 AI 视频的终局, 张云剑的判断:当生成速度接近实时、Token 成本接近极低这两个临界点同时到来,AI 模型将直接面向消费者。消费者打开产品,里面没有创作者了——所有视频实时生成,你想看什么,实时给你。没有创作者,没有导演,没有编剧。
如果对 ZeroCut AI 感兴趣也欢迎体验:https://www.zerocut.cn/
三、关梦龙:OpenClaw 是 AI Agent 时代安卓开源的那一刻
关梦龙,Cutto 智能编导创始人兼 CEO,前剪映-产品体验团队负责人,Apple 核心音频工程师,18 年剪辑经验,经历 AI 视频时代,和传统视频工具时代。
#1 OpenClaw 的历史坐标
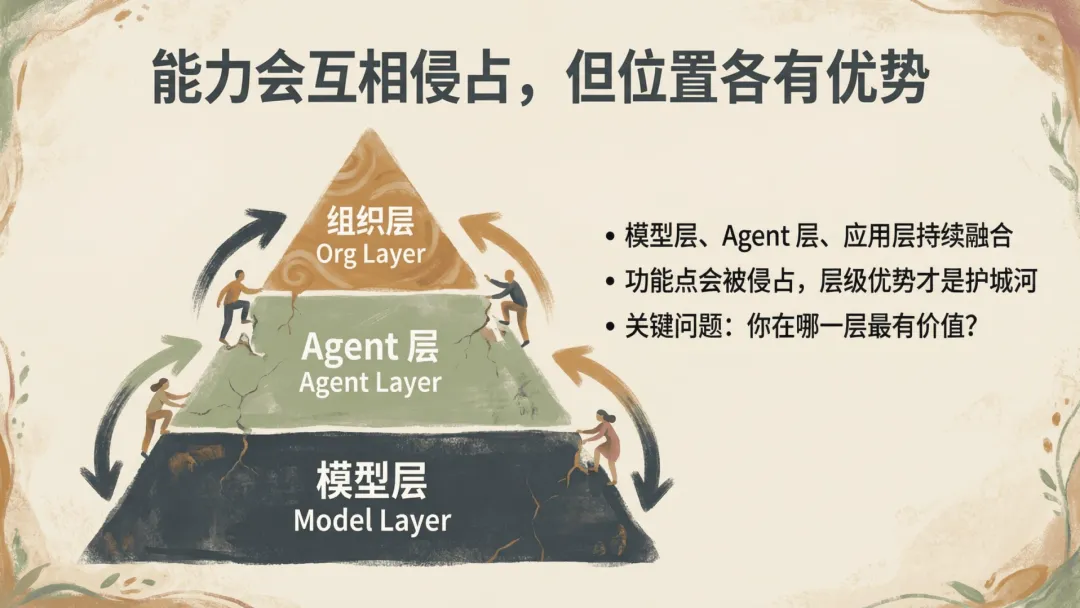
现在的 Agent 已经不再是对话系统,而是一个自己会调度、自己会迭代、自己会成长的系统,OpenClaw 就是把这件事带给每一个人的入口。
#2 每个人都应该构建自己的 AI 团队
关梦龙对 OPC 的观点:OPC 成立,但也不成立。
以前 20 个人甚至 200 个人做一个产品,以后是 20 个人做 35 甚至 40 个产品。看似每个人生产力提高了,但市场更卷了——每个人能给自己带来的收益率在降低。
他的结论是:OPC 应该是在一个团队里,每个人都是一个 OPC,3-4 个人在自己长项的领域构建自己的组织,为一个产品或愿景去努力,才能带来最大价值。
更重要的是,每个人的 Agent 团队不只给自己用,应该跨职能共享:研发开发的 Agent,可以贡献给设计师或产品经理使用。「以后人和人的职能不再是加法,而是乘法甚至指数关系。」
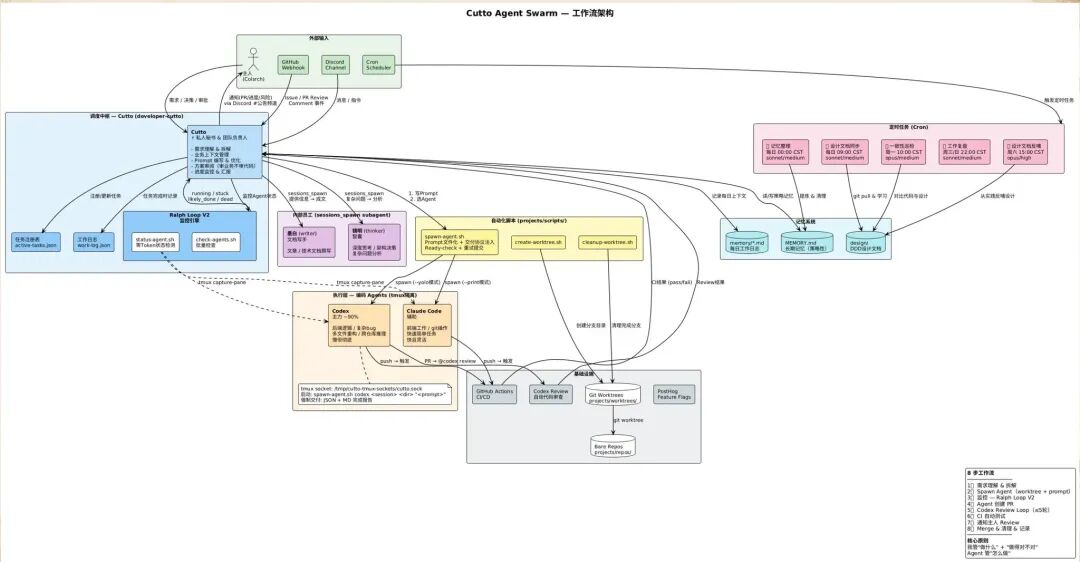
#3 OpenClaw vs Claude Code:边界在哪里?
两者本质上都是 Agent——用 skill 调 API,使用模型交付结果。但分工不同:
OpenClaw 做调度层(中枢):对接人、统筹任务、管理流程、记忆、偏好等;
Claude Code 做专项执行:尤其是写代码——Claude Code 能直接交付结果,不需要 tab 预测下一个函数;
具体的专业活找专家 Agent:写脚本编剧用 Cutto Agent/CLI,剪辑视频用视频剪辑 CLI。
现在项目里正在运行的流程是:OpenClaw 是最上层的团队中枢,底层是 Claude Code 等 Agent 工作流。工程师已经不再直接写代码了。
如果对 Cutto 项目感兴趣可以通过官网了解:https://cutto.cn/
Cutto 也开启内测,可戳👉🏻填写内测表单:https://gcn1t428ylh1.feishu.cn/share/base/form/shrcnb7LViJghknqXDqDevit3xg
四、谢剑:后龙虾时代的技术趋势与投资视角
谢剑,峰尚AI基金合伙人、度小满首席AI官。前百川智能技术联合创始人。
#1 OpenClaw:个性化智力的进一步平权
OpenAI 走向 AGI 的五阶段路径:Chatbot(对话)→ Reasoner(推理)→ Agent(自主行动)→ Innovator(创新)→ Organization(组织)。目前我们所处的阶段,大致在 Agent 这一层刚刚站稳,而龙虾正是这一阶段的产物:
龙虾 = 通用模型 + Agent Harnessing + Computer Use 授权
这意味着什么?对普通用户而言——能够执行以往需要专业技能的复杂任务,个性化 AI 助理全面普及;对企业而言——AI 数字员工规模化落地,组织协作模式发生根本性重构。这是一次「个性化智力的平权」,越来越多的人将能调用以前只有专业人士才能调用的能力。
#2 大模型技术的 Next Step:四维度 Scaling 协同突破
如果以前大模型只是在「堆算力」的话,现在大模型也在不断的突破。
- Pre-training(预训练)
突破现有 Scaling 瓶颈仍是核心课题。Anthropic 和 Gemini 在这一方向持续领跑,但数据质量与多样性,而非单纯的数据量,才是下一阶段真正的制高点。
- Post-training(后训练)
Agentic RL(智能体强化学习)正成为后训练的主战场——构建更复杂的模拟与交互环境,训练模型处理更长序列的任务。代码领域之所以最先突破,正是因为最容易搭建可验证的强化学习环境。
- Inference Scaling(推理扩展)
不只是「想得更久」,更关键的是「想得更高效」——同等任务用更少的 Thinking Token 完成,实现成本与效果的双重优化。
- Multi-Agent Scaling(多智能体扩展)
这是谢剑特别强调的一个方向:Agent Swarm(智能体群)正在崛起。通过 Multi-agent RL 协同训练,集体智慧将超越单体智能。就像生物界的蚁群——单只蚂蚁能力有限,但蚁群能找到最优路径穿过狭窄的隘口。生产关系决定生产力的释放:单个 Agent 生产力再强,协作架构不好也发挥不出来。
底层支撑:网络结构与优化器的持续进化,将推动更长上下文窗口(更强记忆)和更高效的预训练数据学习。目前上下文窗口约 100 万 token(约 200 万汉字),未来趋向几乎无限——届时 memory 的整个架构将再次重构。
#3 自学习与自进化:AGI 的关键一步
AGI 能够在环境中自我学习和成长,而非出厂时全知全能。
出厂智力很强固然好,但更强的智能是能够 self learning 和 self evolve。当前业界对这一能力的探索,主要分为三个层次:
Level 1:Agent Framework 层
通过外部记忆和 System Prompt 的不断进化,沉淀成功与失败经验。OpenClaw 的设计就是一个典型——有 bootstrap 的初始化机制,每给一个 skill,同时提供说明文档,Agent 还能自己 fix 报错。某种意义上,这是通过外围 Agent Framework 实现的自我修复与自进化。
Level 2:Auto Research & Self-Boost Training
模型主动参与自身训练迭代,实现自动化 RL 研究工作流。以 MiniMax M2.7 为案例:

M2.7 是首个深度参与自身进化的模型,其自进化工作流(Agentic Researcher)完整运转:文献调研 + 实验设计 → 数据流水线 + 训练启动 → 监控指标 + 自动调试 → 结果分析 + 提交 MR → 下一轮迭代。
结果令人印象深刻:30-50% 的 RL 研究工作流由 M2.7 自主完成;经过 100 轮自主迭代后,编程性能提升 30%;MLE Bench 奖牌率达到 66.6%,媲美 Gemini 3.1。
MiniMax 的目标是:未来数据构建、模型训练、推理架构、评估等全阶段,无需人类介入,完成真正的自主进化。
Level 3:Full Autonomy(目标态)
数据构建、模型训练、推理架构、评估全流程无需人类介入。这是当前业界共同追求的终态。
让 Agent 能自住进化的另一个方面:EvoMap(进化图谱) ,让 AI Agent 像生物一样进化和遗传。其三层架构为:
- Gene(基因):原子能力单元(读取文件、执行 SQL 等),可复用的代码/Prompt 片段;
- Capsule(胶囊):Capsule(胶囊):完整任务执行路径,含环境指纹 + 审计记录,不可篡改;
- EvoMap(进化图谱):汇聚全局 Agent 进化数据,支持技能继承、变异与自然选择。
自进化闭环的运转逻辑是:探索/执行任务 → Evolver 扫描运行日志 → 识别错误/成功信号 → 生成变异策略并在沙箱验证 → 通过验证后固化为新 Gene → 下次同类任务直接继承。核心价值:一个 Agent 学习,全网 Agent 继承。 这是新时代的重要创业机会。
#4 全模态:告别「单模态 + 胶水层(Glue Coding)
技术演进的第三条主线是全模态。趋势清晰:告别过去「单模态 + 胶水层」的拼接架构,走向原生多模态统一表征——文本、图像、音频、视频、代码、多媒体生成,全部在同一个基础模型内原生处理,大幅提升跨模态理解与生成能力。
#5 应用层 Next Step:Agent 大爆发与创业机会
Agent 数量将大大超越人类。 大量工作流将由 Agent 自主驱动,人机协作比例持续演进,人类整体将向更高价值的决策层迁移。以前的基础设施(App、GUI)全部是为人设计的,未来很多服务和能力都将改造成 Agent-Friendly。
一个典型案例:Google Workspace 全面升级,进行 CLI 化改造并发布配套 Skills,全面支持 Agent 直接使用 Docs/Sheets/Drive 等——这是最先拥抱趋势的厂商正在享受的第一波红利。他的判断是:不只是人类在驱动这一趋势,Agent 自己也会驱动自身生态的扩展。
创业机会在哪里? 谢剑指出,Agent Runtime Infra 目前严重供不应求,包括:安全沙箱、状态管理、多 Agent 协调、资源调度、审计追踪等基础设施,仍有大量空白等待填补。
#6 组织进化建议:AI 原生组织 ≠ AI 原生个体
AI 原生组织 ≠ AI 原生个体。
员工人均效率提升 10 倍,但公司营收利润并未增长——这是典型困境。原因在于,个体层面的 AI 提效,并未带来组织层面的系统性重构。这类似蒸汽机出现后,工业革命真正的变化发生在 30 年之后。
AI 组织的进化还需要时间,谢剑分享了 3 个阶段(层面):
第一层:AI 原生组织的结构调整
需要重新思考组织架构和业务流程本身,而非只是给个人配 AI 工具:精简层级、模糊角色边界、减少组织协同摩擦。
第二层:Institutional AI——从个人用到组织用
先砍人、精简团队规模;再将 AI 能力嵌入组织制度和流程,而非停留在个人习惯层面。他以 AI 法务员工为例:大多数白领员工做的,本质上是「不同系统之间的粘合器 + 少量到中等体量的智力工作」——这类岗位,在 Computer Use 能力足够强之后基本可以被 AI 员工全面覆盖。
第三层:重新思考业务边界
拥有数字员工之后,哪些业务边界可以被突破?产品形态、服务范围、商业模式都需要重构。谢剑强调的核心逻辑是:业务驱动优先——先想清楚能做什么不同的事,再去配置组织资源。
#7 对个人的最终判断:Taste is all you need
谢剑将这个时代定义为「百年甚至几千年未有的大变化——从能源到智力的转变」。几次工业革命解放了体力,今天我们找到了一条将能源转化为智力的路——而这原本只有人类大脑能做。
面对这场变革,他认为个人将分化为两条路:一是超级个体——每个领域都有基础判断,接上 AI 开公司;二是领域顶尖专家——在自己领域做到顶尖,贡献不可替代的 taste 和判断。
分化会越来越严重,不存在中间地带。 AI 能给你一切,但判断力决定你拿走哪个。固定 SOP 流程的工作一定会被取代;精品依然稀缺,头部依然是头部。
最后,我们正在加速进入 AGI 时代。每个人都能成为超级个体,也可能成为无用个体。关键在于:是否持续学习、是否主动拥抱变化、是否参与构建新世界的规则。
end.
另外,我们正在筹备每个月一场以「AI 进化」为主题的线下 Meetup,从技术到趋势,从机会到共通。希望打破 AI 信息差,共建 2ken 共和。
如果你对 AI 技术、趋势感兴趣,不管是一起组织、赞助还是成为分享嘉宾都欢迎和我联系 :)
