 夜雨聆风
夜雨聆风AI 时代真正先撞上的,不一定只是算力上限,而是内存怎么跟上、怎么共享、怎么不被白白浪费。
CXL 这波升温,表面看像协议之争,往深里看,其实是英特尔、AMD、英伟达、Google 都在回答同一个问题:大模型时代的“记忆系统”到底该怎么建。
文|Hive硅基秩序编辑|Hive硅基秩序来源|Hive硅基秩序封面来源|图片来源网络
1 内存墙危机,不是新问题,却被 AI 放大了
过去十年,数据中心一直卡着一个很基础、但越来越扎眼的矛盾:CPU 的算力涨得很快,内存带宽却没跟上。 原文把这件事概括成 memory wall,也就是“内存墙”。你可以把它理解成发动机一年比一年猛,但油路扩得没那么快,结果不是发动机不够强,而是油送不过去。
内存墙,简单说就是处理器越来越快,但“喂数据”的通道没跟上。放到大模型训练和推理里,这不是小堵车,而是整条高速都开始排队。
AI 把这个老问题放大了。原文提到,训练大语言模型时,内存需求可能到几 TB,甚至几十 TB。到了这个量级,传统 DDR 内存架构 的短板就全冒出来了: 主板上能插多少条内存有上限,单条内存容量也有物理边界。换句话说,机器不是不能继续堆,而是越往后越贵、越笨、越不灵活。
在 CXL 之前,行业不是没试过。IBM 推过 OpenCAPI,ARM 推过 CCIX,还有 Gen-Z,但最后都没真正跑成主流。原文给出的核心原因很直接:这些方案没有形成足够强的产业共识,尤其缺了头部玩家的站台。 对基础设施协议来说,技术不差只是入场券,生态才是决定它能不能活下去的门票。
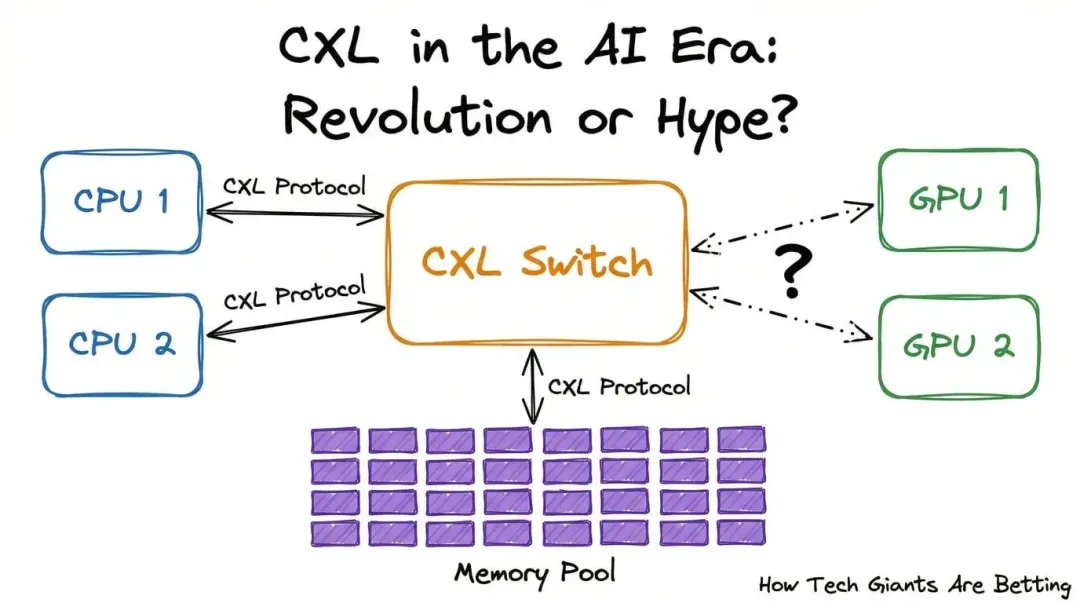
真正的转折点出现在 2019 年。Intel 把自家的互联规范捐出来,联合阿里、Cisco、Dell、Meta、Google、HPE、华为、微软等公司成立了 CXL Alliance。这套协议的思路并不浪漫,甚至有点“工程师务实主义”:它没有从零另起一套物理层,而是站在成熟的 PCIe 生态上,往上再加一层 cache coherency,也就是“让不同芯片看到的是同一份、同步过的内存状态”。
这件事的重要性在于,CXL 从一开始就不是想发明一条完全新的路,而是想在已经修好的高速公路上,加一套让 CPU、GPU、内存扩展设备都能更顺畅协作的交通规则。它真正吸引巨头的,不是“更酷的新接口”,而是“尽量不推翻旧生态,却能重做资源组织方式”。
2 CXL 从 1.0 走到 4.0,升级的不是版本号,而是资源组织方式
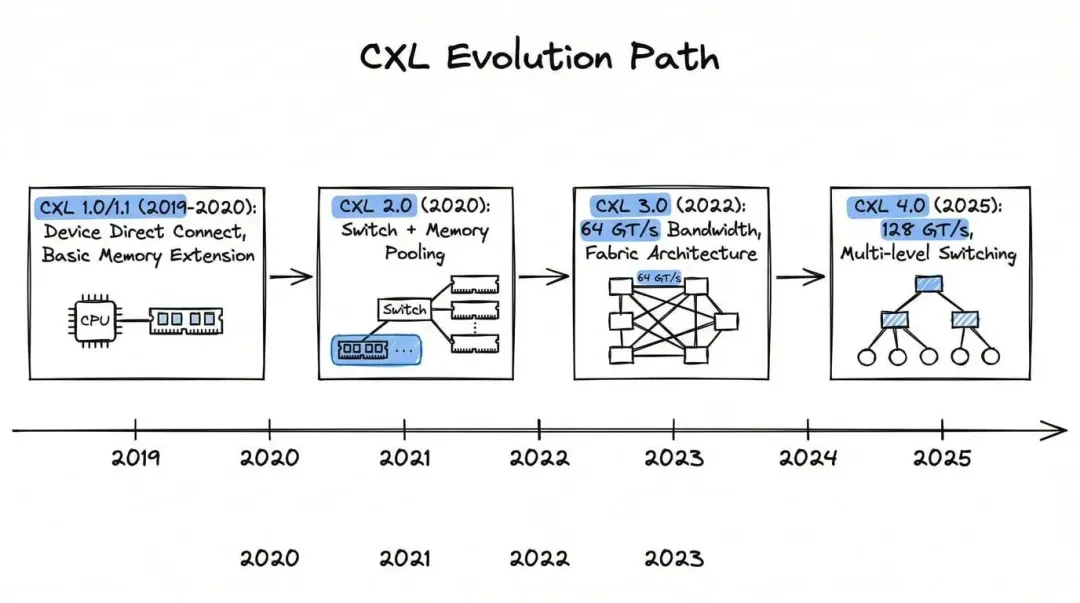
原文把 CXL 的发展拆成四段,这个顺序很关键,因为它对应的不是简单的“带宽越来越大”,而是 系统到底能把内存用到什么程度 的变化。
最早的 CXL 1.0 和 1.1,做的是基础设施打底。这里有三个核心协议:CXL.io 负责设备发现和配置,等于先让系统“认出你是谁”;CXL.cache 让设备可以访问主机内存;CXL.mem 则让主机去访问设备内存。翻成人话,这一阶段主要解决的是“先接上、先打通、先把内存扩出去”。
真正的分水岭是 CXL 2.0。原文把它定义成从 memory scaling 走向 memory pooling 的转折点,这个判断是成立的。所谓 memory pooling,你可以先理解成“把每台服务器自带的内存,改造成一个能共享的水库”。以前是哪台机器买了多少、就只能自己用多少;到这一步,内存开始有机会被当成独立资源,按需分给不同计算节点。
到了 CXL 3.0,重点从“一个池子”进一步走向“更大范围的连接”。原文提到它把带宽提升到 64 GT/s,并引入基于 Fabric 的更灵活互连能力,开始支持更大规模的内存池,甚至走向跨机架共享。你可以把它理解成,CXL 不再只是在一台服务器里折腾,而是在尝试把“共享内存”这件事扩到更大的集群层面。
再往后,原文写到 CXL 4.0 在 2025 年把速率再翻倍到 128 GT/s,并加入多级交换和动态设备管理能力。这一点和 CXL Consortium 在 2025 年发布的公开白皮书方向一致:CXL 4.0 继续强调 更高带宽、更复杂拓扑、同时尽量保持软件兼容。这说明 CXL 的目标已经很明确了,它不是只想服务一块扩展卡,而是想服务 AI 时代的大规模异构集群。
从 1.0 到 4.0,CXL 真正升级的不是“线更快了”这么简单,而是数据中心开始试着把内存从“机器配件”变成“系统资源”。
如果说 1.0 解决的是“能不能接”,那 2.0 之后解决的就是“能不能共享、能不能调度、能不能大规模用起来”。
3 CXL 想要的,从来不只是“多插几条内存”
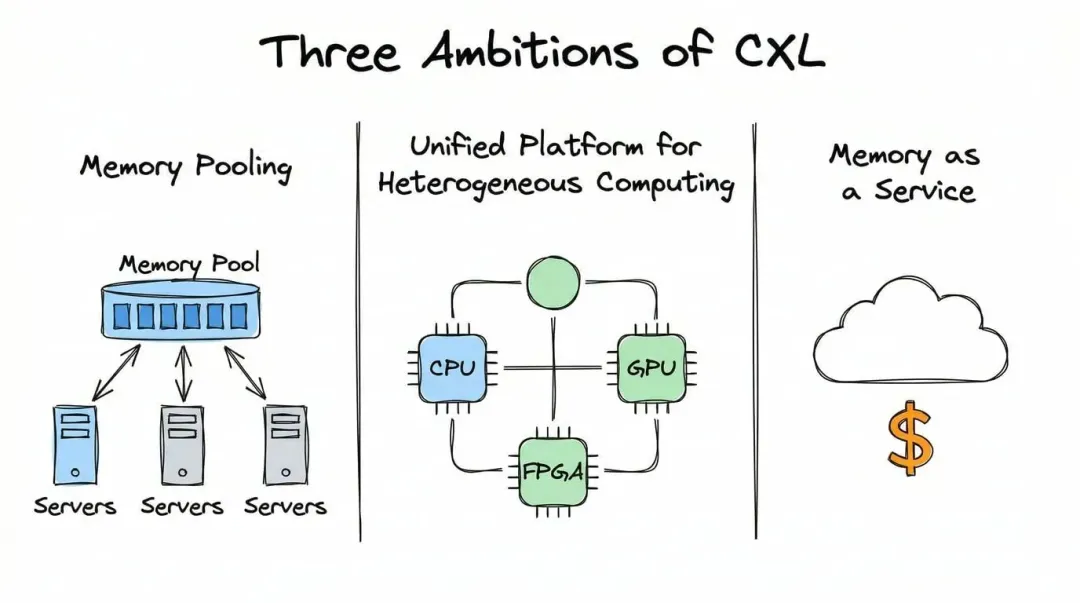
原文接下来讲得很直白:CXL Alliance 在推的,其实是三层 ambition,也就是三层野心。它们看起来都和“内存”有关,但关注点并不一样。
第一层是 内存池化。传统服务器的购买逻辑很死:买的时候配多少内存,未来很长一段时间大概率就只能这么用。买多了会闲置,买少了就可能整机替换。CXL 想做的,是把内存从服务器上拆出一点独立性,让它像共享资源池一样被重新分配。对企业来说,这背后不是一个“技术更先进”的抽象故事,而是很现实的 利用率和总拥有成本 问题。
第二层是 异构计算的统一平台。今天的数据中心里,CPU、GPU、FPGA、TPU 经常同时存在,但它们协作并不天然顺滑。原文提到,CXL 提供统一的缓存一致性框架,目的是让不同架构的芯片更高效地配合。大白话说,就是别让每一类芯片都带着自己一套“方言”和“规矩”,否则开发者最后最累,系统也最难扩。
第三层则更长线,也更像商业模式层面的想象:software-defined memory 和 memory as a service。前者可以理解成“内存不是焊死在机器里的固定资产,而是软件可以调度的资源”;后者更激进,意思是如果内存真的能按需分配、按使用计费,它未来可能像云上的计算资源一样被售卖。
memory as a service 听上去很诱人,但至少从现有公开部署情况看,它更像方向,而不是已经成熟的大规模现实。协议先到位,不等于商业模式立刻成立。
这也是看 CXL 时很重要的一点:它的故事不只是“让一台机器变强”,而是试图把整个数据中心里最贵、最难扩、最容易浪费的一类资源重新编排。说到底,CXL 争夺的不是一根总线,而是未来机房里“内存归谁调度”这件事。
4 Intel 和 AMD 支持 CXL,不只是因为它技术上说得通
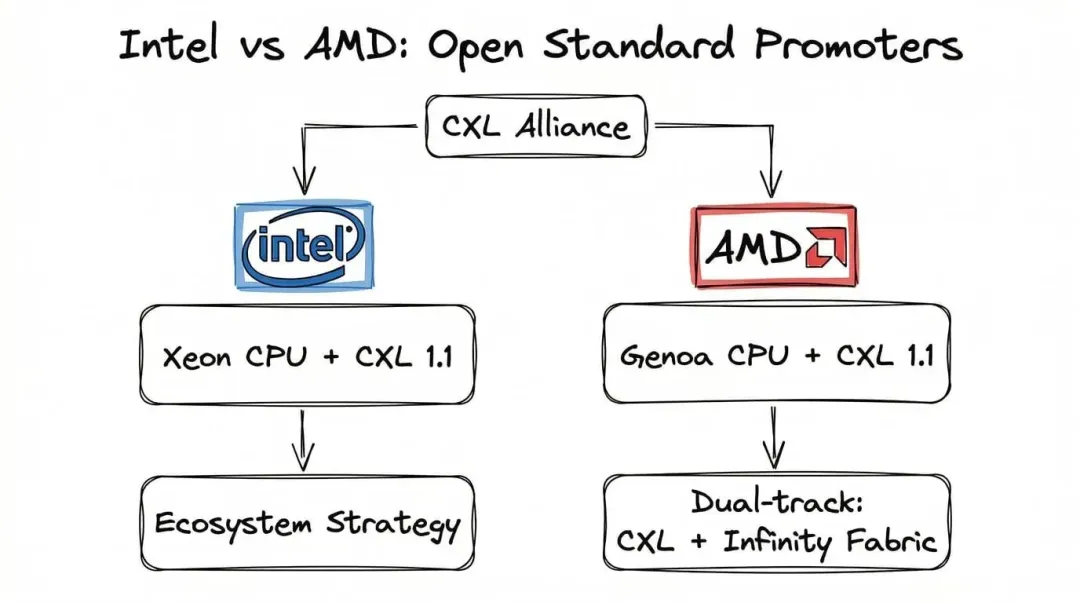
原文先讲 Intel 和 AMD,这个顺序也合理,因为 CXL 本来就是从 CPU 阵营长出来的。对 Intel 来说,推动 CXL 从来不只是做一个“行业公益项目”。原文已经点明了它的战略背景:在 CPU 市场,Intel 面对 AMD 和 ARM 的压力;在 AI 加速器市场,Nvidia 又已经占住了主导位置。于是,谁能定义数据中心里的互连规则,谁就还能保有一部分话语权。
这也是为什么 Intel 会把 CXL 当成一个生态位来经营。它希望 Xeon 不只是处理器本身有存在感,而是连带把整个数据中心的互连层、内存扩展层也拉进自己的影响半径里。技术标准和商业地盘,在这里其实是同一件事的两种说法。
原文提到,Intel 的 Sapphire Rapids 和 Emerald Rapids 都支持 CXL 1.1,但市场采用速度明显慢于最初预期,真正商业化比早期判断晚了两三年。这个观察很值得保留,因为它提醒我们:“支持标准” 和 “标准真的大规模落地” 之间,往往隔着一整条产业链。 设备、交换芯片、操作系统、软件栈、采购周期,一个都不能太掉队。
AMD 的姿态则更像典型的“两条腿走路”。一边加入 CXL Alliance,让 Genoa 处理器支持 CXL 1.1;另一边,它又没有放弃自家的 Infinity Fabric。原文把这理解成一种平衡,这个判断很稳。因为对 AMD 来说,开放标准可以帮它吃到生态红利,但完全把命运交给开放标准,也不符合它在高性能系统里的长期利益。
Intel 更像是在推动“大家都来用这套规则”,AMD 则更像“规则我愿意支持,但自己的看家本领我也不会丢”。
所以 Intel 和 AMD 都支持 CXL,不等于它们支持的动机完全相同。一个更像在守住互连层的话语权,一个更像在开放生态和自有技术之间保留回旋空间。
5 Nvidia 不是没看见 CXL,而是更想把路修在自己园区里
原文写 Nvidia 的态度是“相对保守”,这几乎可以说是客气了。更准确一点讲,Nvidia 并不是看不懂 CXL 的价值,而是 它已经有一套更想自己掌控的体系。
先看互连。原文的核心判断没问题:在 GPU 互连这件事上,Nvidia 手里本来就有 NVLink 这张牌,而且性能远高于通用 PCIe/CXL 路线。只是这里的带宽数字最好拆开看,别混成一个概念。面向 Grace Hopper 这类 CPU-GPU 紧耦合系统的 NVLink-C2C,Nvidia 官方公开带宽是 900GB/s;更大规模 NVLink Switch 域里的总聚合带宽,则是另外一个系统级数字,已经到 TB/s 量级。它们不是一回事,但都在说明同一个现实:Nvidia 没什么动力把最核心的 GPU 互连层让给开放标准。
原文还提到,Nvidia 在 2025 年 9 月收购了 Enfabrica 核心团队,而 Vera CPU 支持 CXL 3.1。这一点很有意思,因为它说明 Nvidia 不是完全不看 CXL,而是更像把它当作“可选拼图”,而不是主航道。
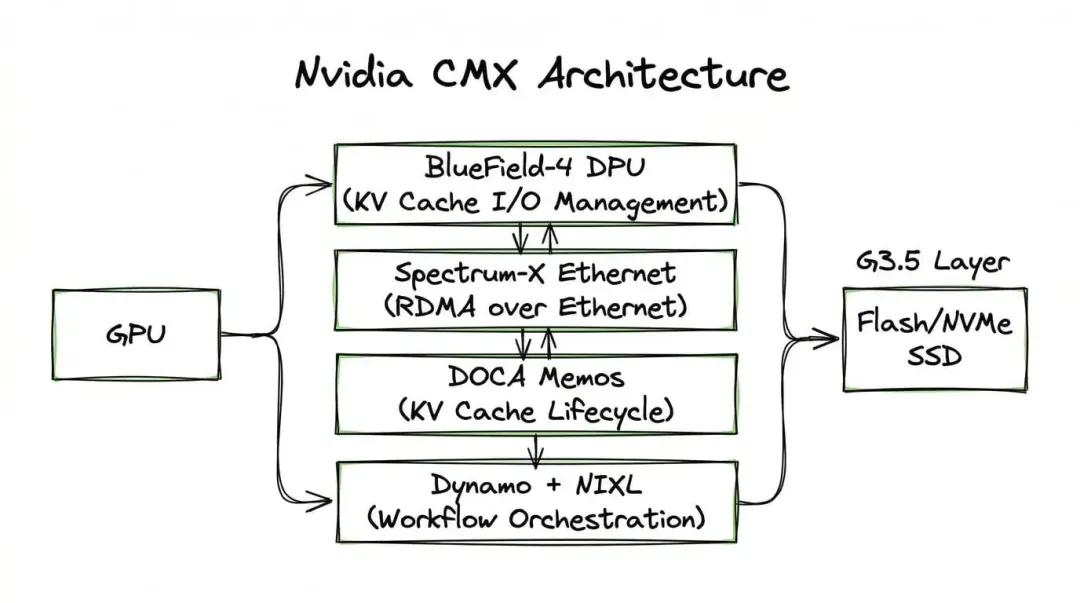
真正能看出 Nvidia 思路的,还是原文后面展开的 CMX。CMX(Context Memory eXtension) 是 Nvidia 面向 AI 推理设计的一层新存储层,重点不是传统数据库,不是长期存储,而是处理 长上下文、多轮对话、Agent 工作流 里越来越大的 KV cache。
KV cache,可以先理解成模型推理时临时存下来的“上下文记忆”。它不是长期档案库,更像模型工作台上的草稿纸,接下来马上还要继续翻着用。
问题在于,这类临时记忆越来越大。原文写得很清楚:上下文窗口被推到百万 token 级别后,KV cache 需求会线性上涨,而重算成本涨得更快。HBM 当然最快,但贵,而且容量有限;传统对象存储又太慢,不适合装这种“很快要用、也很快会失效”的数据。于是 Nvidia 的办法不是走 CXL DRAM 扩展,而是在 GPU 内存和传统存储之间,再塞进一个 G3.5 层。
按照原文和 Nvidia 公开产品页,这层 CMX 的核心组件包括 BlueField-4 DPU、Spectrum-X Ethernet、DOCA Memos 以及负责推理编排的 Dynamo/NIXL。翻译一下就是:一部分负责数据搬运和 I/O 管理,一部分负责高带宽低延迟网络,一部分负责 KV cache 生命周期和共享,一部分负责把推理过程里的预取、传输和调度串起来。
这里最值得看的,是 CMX 和 CXL 的取舍差异。原文说得很到位:CMX 更偏向 Flash/NVMe SSD,延迟在微秒级,但便宜、容量大;CXL 更偏向 DRAM,延迟在百纳秒级,更快,但贵,而且容量通常还是 TB 级。 所以它们不只是“谁更先进”的竞争,更像两条针对不同场景的路线。长上下文、多轮对话、Agent 推理,CMX 这种“便宜、够大、靠预取补延迟”的路更合适;而实时性更高的推理和数据库类场景,CXL 这种更低延迟的内存扩展仍然有优势。
原文最后给出的判断也值得保留:CXL 强调 cache coherency,也就是严格的一致性;但 KV cache 本质上是临时数据,没必要为它付出那么重的一致性成本。对 Nvidia 来说,自己做一整套从网络、DPU、软件框架到存储层的全栈方案,既更贴合场景,也能继续把生态控制权握在手里。
Nvidia 不是不想扩内存,它只是更想用“对自己最有利的方式”去扩,而且尽量不把关键控制权交给开放标准。
不过,态度也不是完全铁板一块。Enfabrica 团队和 Vera CPU 对 CXL 3.1 的支持,至少说明 Nvidia 没把 CXL 从牌桌上彻底划掉。只是从现有公开动作看,CMX 仍然是它眼下更重视的主线。
6 Google 值得单独看,但公开信息其实也只到这里
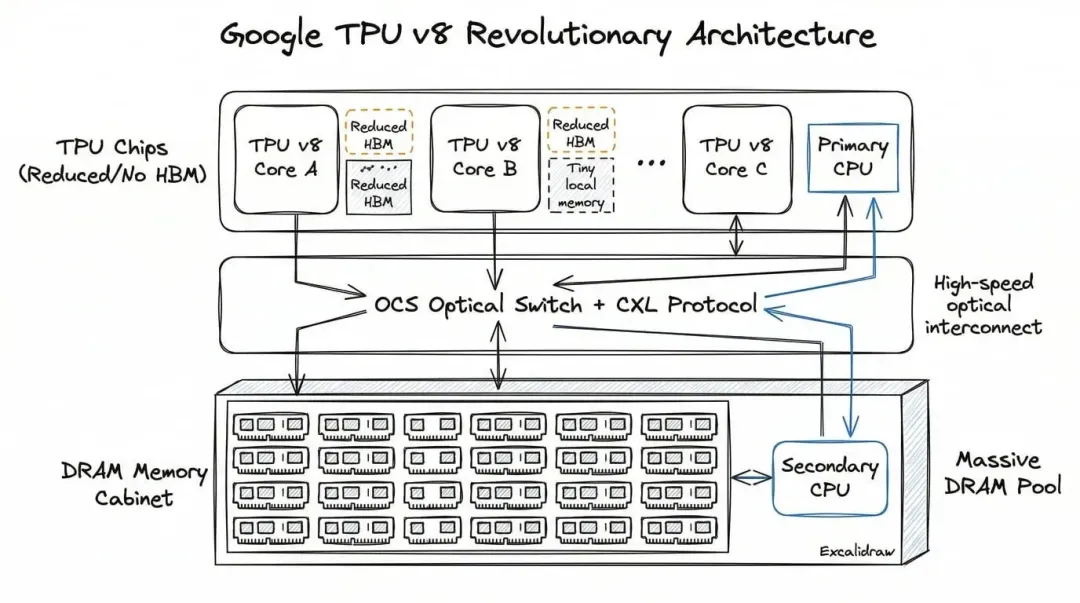
原文在这里进入了 “Google: Revolutionary TPU + CXL Solution” 这一节,但公开可见的正文也刚好在这里被截断了。这个边界需要说清楚,所以这一段只能做 保守补全:我们能写的是公开能确认的方向,不能把图里的每一个细节都当成 Google 已经正式披露的量产方案。
先看图本身。06.webp 画出来的是一种很明确的架构意图:上层是 TPU 核心和主 CPU,下层是一大块外部 DRAM Memory Cabinet,中间通过 OCS Optical Switch + CXL Protocol 连接,旁边还有辅助 CPU 协同。这个思路翻成人话,就是尽量别把所有昂贵内存都焊死在每颗加速器旁边,而是用高速互连把一大池外部内存接进来,按需要喂给不同计算单元。
这件事为什么值得看?因为 Google 过去公开过的 TPU 路线,确实长期在押注 可重构互连。例如 Google 在 2023 年公开的 TPU v4 论文里就明确提到,系统采用 optical circuit switches,也就是光路交换,来动态重构集群互连拓扑,以提升规模、可用性和利用率。它当然不能直接证明“Google 已经公开发布了 TPU v8 + CXL 方案”,但至少说明一个大方向:Google 对“把互连做得更灵活、把系统级资源调度做得更大”这件事,是有连续投入的。
所以更稳妥的理解是,06.webp 这张图展示的,并不是一句“Google 已经证明 CXL 必赢”,而更像一种架构押注:当 HBM 越来越贵、容量也越来越难跟上时,把部分内存能力外置成更大的资源池,再通过高速互连接回加速器,可能会成为一种越来越值得研究的路线。
但边界也要说清楚:至少从现有公开材料看,我们还不能把图里的 TPU v8、CXL、光互连、外部 DRAM 池 的组合,直接等同于 Google 已经对外完整披露、并且量产落地的官方方案。
也正因为如此,Google 这一节最有价值的,不是“它已经做成了什么”,而是它提醒我们:AI 基础设施竞争,正在从“谁的芯片更强”,慢慢转向“谁更会重组内存、互连和系统资源”。
【结尾】
从现有公开信息看,CXL 既不是一场已经兑现的革命,也不是一句可以轻易打发掉的炒作。
它更像一块正在被不同巨头以不同方式争夺的拼图: Intel 和 AMD 想把它做成开放底座,Nvidia 选择绕路自建,Google 则让人看见了另一种更激进的系统级想象。
真正值得继续盯着的,不只是 CXL 会不会赢,而是谁会先把“内存从配件变成资源”这件事真正做成。
