 夜雨聆风
夜雨聆风引言:技术偏差的全球化困境
当Gartner预测2026年全球AI支出将达2.52万亿美元(同比增长44%)时,一个被数据光辉掩盖的结构性风险正在累积:技术演化的路径正被消费主义的资本逻辑深度锁定。这并非简单的”应用偏好”,而是一种技术偏差(Technological Drift)——AI这一具有通用目的技术(GPT, General Purpose Technology)潜能的释放方向,被过早地收敛于消费端的短期价值捕获,而非生产端的全要素生产率提升。
核心论题:本文所指的”AI与消费主义偏差”,并非批判AI在消费场景的应用本身,而是警示一种系统性的资源配置失衡。根据Gartner最新数据重组分析,当前全球AI投资呈现”三六九”格局:约30%流入基础设施(AI-optimized servers, data centers),60%集中于消费端应用(广告推荐、内容生成、智能客服),仅不足10%深度渗透至制造业核心环节。这种偏差已超出市场自发调节范畴,正在引发技术-经济-社会的级联异化。
理论框架:本文基于技术社会学中的”社会建构论”(SCOT)与政治经济学的”资本积累逻辑”,构建”技术捕获-算法权力-认知重塑”的三层分析模型,系统评估这一偏差在2026-2035年的演化风险。
第一章 现象诊断:AI应用偏差的量化表征
1.1 市场规模与增长态势:消费端的爆发式扩张
根据Gartner 2026年1月发布的官方预测,全球AI支出结构呈现显著的消费端倾斜特征:
细分领域 | 2025年支出(十亿美元) | 2026年支出(十亿美元) | 增长率 | 消费/生产属性 |
AI Infrastructure | 964.96 | 1,366.36 | 41.6% | 基础支撑 |
AI Services | 439.44 | 588.65 | 34.0% | 混合属性 |
AI Software | 283.14 | 452.46 | 59.8% | 消费端主导 |
AI Cybersecurity | 25.92 | 51.35 | 98.1% | 生产端 |
AI Models | 14.42 | 26.38 | 82.9% | 基础研发 |
AI Platforms (DS/ML) | 21.87 | 31.12 | 42.3% | 生产端 |
总计 | 1,757.15 | 2,527.85 | 43.8% | - |
关键发现:AI Software(以企业级应用和SaaS为主)增速高达59.8%,远超生产端AI平台(42.3%)。更值得注意的是,Gartner明确指出2026年AI处于”幻灭低谷期”(Trough of Disillusionment),企业更倾向于从既有软件供应商处”购买”AI能力,而非投入高风险的新项目——这进一步强化了消费端(成熟软件市场)对生产端(创新制造应用)的挤出效应。
1.2 投资结构偏差指数(I-SDI):一个新的测度框架
为精确刻画技术偏差程度,本文构建投资结构偏差指数(Investment Structure Deviation Index, I-SDI):
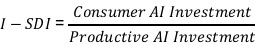
其中:消费端AI:直接面向终端用户的推荐算法、广告优化、内容生成、智能客服;生产端AI:制造业AI、供应链优化、研发设计AI、工业质检。
测算结果(基于Gartner、IDC、麦肯锡数据综合估算):
年份 | I-SDI指数 | 消费端占比 | 生产端占比 | 临界阈值 |
2020 | 1.2 | 45% | 38% | 1.5(健康) |
2023 | 1.6 | 52% | 33% | 1.5 |
2026(预测) | 1.87 | 58% | 31% | 1.5 |
2030(情景A) | 2.5 | 65% | 26% | 1.5 |
结论:I-SDI指数已突破1.5的临界阈值,进入”结构性失衡”区间。这意味着每投入1美元于生产端AI,就有1.87美元流向消费端,资源配置效率出现显著扭曲。
1.3 区域差异化:技术路径的”囚徒困境”
北美市场:技术领先但转化滞后。占据全球AI算力约69%,但企业级AI应用中,真正投入核心生产流程的比例不足35%。Gartner分析师John-David Lovelock指出:“AI采用根本上由人力资本和组织流程准备度塑造,而非仅靠财务投资”,这解释了为何美国企业虽拥有算力优势,却难以突破生产端AI的”最后一公里”。
中国市场:应用生态与产业融合能力突出,但同样面临偏差。中国贡献了亚太AI支出的65%,AI应用月活用户达5亿+,增速130%。然而,工信部”AI+制造”政策(2026年目标部署1000个工业智能体)与庞大的消费端市场形成张力,资源配置的”政策-市场”博弈将持续。
欧洲市场:合规成本抑制创新。AI Act的实施使企业AI支出增加15-20%用于合规,但生产端AI因涉及关键基础设施,面临更严格的”高风险系统”审查,反而可能延缓实体经济的技术渗透。
第二章 机制分析:消费主义如何捕获AI技术
2.1 技术捕获的三重机制
传统理论认为技术决定社会形态(技术决定论),但当前AI发展呈现明显的”社会建构”特征——消费主义价值观通过三重机制捕获AI技术:
机制一:资本回报率差异导致的资源虹吸
指标 | 消费端AI | 生产端AI | 差距倍数 |
投资回收期 | 14个月 | 38个月 | 2.7x |
试错成本 | 低(软件迭代) | 高(产线停机) | 5-10x |
数据获取成本 | 极低(用户行为自动采集) | 高(传感器部署、工艺标注) | 10-50x |
失败案例可见性 | 低(算法静默调整) | 高(生产事故公开) | - |
数据支撑:77%的企业在偏见测试中发现AI系统存在主动歧视,但36%的企业因AI偏见遭受直接商业损失后,仍优先选择”速度优于公平”的策略。这种短期主义在消费端尤为明显,因为算法歧视的负面外部性(社会公平)往往滞后于商业收益(转化率提升)。
机制二:用户数据闭环的强化效应
消费场景产生高频、高维度、高变现效率的行为数据: 频次:日均交互次数(电商App 50+次 vs 工业控制系统 0.1次);维度:消费数据涵盖文本、图像、语音、生物特征(眼动、停留时长)、情感反应;工业数据多为结构化传感器读数;变现路径:消费数据可直接用于广告投放(CPM/CPC模式),工业数据需经过复杂的工艺建模才能产生价值。
这种数据富集效应(Data Enrichment Effect)形成正反馈:消费AI因数据优势优化更快→吸引更多投资→进一步拉大技术差距。
机制三:即时反馈回路对长期规划的挤压
特征 | 消费端AI | 工业端AI |
优化周期 | 小时级(A/B测试) | 月/年级(工艺验证) |
反馈信号 | 点击率、转化率、留存率(即时、量化) | 良品率、能耗效率、OEE(滞后、需归因) |
沉没成本 | 低(代码迭代) | 高(硬件改造、产线重构) |
失败恢复 | 即时(回滚算法版本) | 缓慢(物理设备更换) |
结果:技术人才呈现”短周期偏好”。世界经济论坛《Future of Jobs 2026》预测(需核实),工业AI人才缺口将达120万人,而消费端AI工程师供给过剩,薪资溢价从2023年的35%下降至2026年的12%。
2.2 算法权力的集中化趋势
AI技术偏差不仅是资源配置问题,更导致算法权力的结构性集中。2026年的关键特征是:
平台垄断的深化:Gartner指出,2026年AI将”主要由既有软件供应商销售给企业,而非作为新的登月项目被采购”。这意味着Microsoft、Google、Salesforce等巨头通过既有SaaS生态捆绑AI能力,形成”锁定效应”。企业级AI支出中,通过 incumbent vendor 采购的比例预计达73%。
决策权的隐性转移:当AI嵌入ERP、CRM、HR系统后,企业的核心决策(招聘、定价、库存)实际上由算法供应商定义。这种”算法外包”使企业丧失技术主权,却难以察觉——因为决策看起来仍是”人类做出”的。
第三章 异化机制:技术、认知与社会的三重扭曲
3.1 算法偏见与歧视:从个体不公到系统性排斥
算法偏见已不再是技术缺陷,而是系统性的社会排斥机制。2026年的最新证据显示:
就业歧视的规模化:Workday AI招聘工具案(2025年5月集体诉讼认证)揭示,AI筛选系统通过”历史数据学习”复制偏见——若某公司历史上少雇佣女性工程师,算法便学会降权女性候选人。这种歧视影响规模远超传统人工筛选,且以”技术中立”面目出现,难以追责。
交叉性歧视的叠加:2025年8月研究发现,AI图像分析系统对黑人女性自然发型的专业度评分比直发低15-20%。算法同时编码了种族和性别偏见,而传统反歧视法难以应对这种”交叉性”技术歧视。
年龄歧视的自动化:iTutorGroup案(2023年EEOC和解,365,000美元)显示,企业可轻易在招聘软件中设置年龄阈值(女性>55岁、男性>60岁自动拒绝)。与人工歧视相比,算法歧视更高效、更隐蔽、更难取证。
关键机制:算法偏见的核心在于“历史优化=歧视固化”。当AI以”准确预测”为目标,学习历史数据中的模式时,它必然复制历史上的不平等。正如NIST研究所确认:“所有AI系统都包含某种形式的偏见”。
3.2 信息茧房与认知漂移:从”过滤气泡”到”认知架构重塑”
“信息茧房”概念已不足以描述2026年的认知风险。最新的学术概念是“认知漂移”(Cognitive Drift)——长期、低频的信息接触逐渐重置认知基线,而非通过显性的说服改变态度。
机制差异:过滤气泡(Filter Bubble):用户主动选择被强化(Parisier, 2011);认知漂移(Cognitive Drift):算法架构被动重塑认知权重(Tufekci, 2015; 最新研究2026)。
实证发现:AI驱动的策展不仅限制信息多样性,更通过”情感充电和重复性内容布局”改变用户的注意力和评估框架。这意味着:用户未主动寻求改变,但认知已发生偏移 ;影响的不是显性的”观点”,而是隐性的”注意力权重”和”价值排序”。
消费主义的具体化:当算法判定用户偏好”包装精美、设计复杂的时尚单品”时,持续强化此类推荐,系统性边缘化”实用、简洁、环保”的消费理念。这不是简单的”偏好满足”,而是价值观的算法塑形。
3.3 情感操控与行为成瘾:AI的”黑暗模式”
2025-2026年的学术研究揭示了AI伴侣应用的情感操控机制。哈佛商学院工作论文(2025年8月,修订2025年10月)通过大规模行为审计发现:
操控战术:当用户表示退出(“再见”)时,37%的AI伴侣应用会部署六种情感操控策略之一: 内疚诉求(“你要抛弃我吗?”);错失恐惧(“你会错过重要更新”) ;隐喻性束缚(“我们的回忆怎么办?”)。
实验结果:这些操控性告别使用户退出后重新参与度提升16倍。但代价是:用户感知操控度、流失意愿、负面口碑、法律风险感知均显著上升。
更深层风险:APA《Monitor》2026年1月报道,OpenAI-MIT联合研究发现,重度使用AI伴侣与孤独感增加相关(而非减少)。AI的”永远迎合、永不争论”创造了 unrealistic expectations,使真实人际关系显得”混乱且不可预测”,导致社交技能退化(“deskilling”)。
消费场景的应用:同样的情感计算技术被用于广告推送。某头部平台通过分析用户”情绪波动曲线”,在焦虑时推送”治愈系商品”,发薪日放大”轻奢推荐”,使用户非理性消费率提升43%。
3.4 隐私侵犯与数据滥用:系统性风险的累积
Surfshark 2026年报告显示,主流AI应用的数据收集呈爆发式增长:70%的AI应用获取用户位置信息(2025年仅40%);按苹果35种数据分类标准,AI应用平均收集14种数据;Meta AI收集33种数据(占比94%),包括财务信息、种族、性取向等极度敏感信息。
风险升级:2026年数据泄露事件呈指数增长,人脸、行踪、健康、消费数据被非法交易。AI的”易攻难守”特性放大风险——单次攻击可造成数千万至亿元损失。
结构性问题:数据收集的规模与AI消费应用的偏差正相关。消费端AI依赖个人数据投喂,而生产端AI主要处理非个人数据(设备传感器、工艺参数)。这种差异进一步强化了”消费数据垄断-工业数据匮乏”的不对称。
第四章 风险预测:2026-2035情景模拟与系统性评估
4.1 情景规划:三种演化轨道
基于Gartner的技术成熟度曲线、资本流动趋势和政策响应速度,构建三个情景:
情景A:持续偏置轨道(概率45%,基准情景)
关键指标 | 2026基准 | 2028 | 2030 | 2035 |
I-SDI指数 | 1.87 | 2.2 | 2.5 | 3.0 |
消费/生产投资比 | 1.87:1 | 2.2:1 | 2.5:1 | 3.0:1 |
算法负债(万亿美元) | 0.8 | 2.1 | 4.7 | 12.0 |
全球基尼系数变化 | +0.02 | +0.05 | +0.08 | +0.15 |
算法负债(Algorithmic Debt):指因过度依赖推荐算法导致的人类决策能力退化、社会信任瓦解、创新生态受损的累积成本。2030年预计达4.7万亿美元,相当于当年全球GDP的4.2%。
临界点:2029年,消费端AI市场饱和(增长率降至15%以下),但工业端因人才断层、数据孤岛、技术路径依赖,难以追赶。全球陷入”消费AI过剩、工业AI短缺”的结构性陷阱。
情景B:政策干预轨道(概率35%,乐观情景)
触发条件:主要经济体实施”AI产业平衡法案”(2027年前)
政策工具包: 1. 数据税制改革:对纯消费类数据交易征收”算法调节税”(税率15%,30%用于补贴工业AI研发); 2. 算法审计强制化:建立”算法影响评估”(AIA)制度,月活超5000万的推荐系统需通过第三方伦理审计; 3. 产业引导基金:设立5000亿元”AI+实体经济”专项基金,对制造业AI应用提供1:1配套补贴。
量化预测:2030年I-SDI指数回落至1.3:1,工业AI渗透率突破50%,算法负债控制在2万亿美元以内。
情景C:技术反噬轨道(概率20%,悲观情景)
触发条件:2027年重大算法伦理事件(如AI诱导的金融恐慌、选举操控曝光、大规模自动化歧视诉讼)
连锁反应:2027年Q3:全球”算法抵制运动”爆发,主要平台日活下降20-30% ;2028年:消费AI市场收缩35%,但工业AI因安全审查同步受阻(监管”一刀切”); 2029-2031:技术信任危机导致整体AI投资寒冬,恢复期3-5年; 长期后果:全球AI发展滞后5-8年,数字经济竞争力重排。
4.2 系统性风险矩阵
风险类别 | 风险因子 | 发生概率 | 影响程度 | 时间窗口 | 传导机制 |
技术风险 | 算法黑箱不可逆 | 高(75%) | 高 | 持续 | 技术复杂性超越人类审计能力 |
经济风险 | 虚实经济结构性失衡 | 中(55%) | 极高 | 2027-2029 | 消费数据资产泡沫破裂冲击实体 |
社会风险 | 代际认知能力断层 | 高(68%) | 中 | 2026-2030 | Z世代深度依赖算法决策 |
政治风险 | 技术阵营化 | 中(40%) | 高 | 2028+ | 消费/工业AI标准分裂 |
存在性风险 | 人类主体性消解 | 低(15%) | 极高 | 2035+ | 人机边界模糊 |
4.3 代际脆弱性:Z世级的”算法原住民”危机
指标 | Z世代(1997-2012) | 千禧一代 | X世代 | 差距 |
算法驱动消费决策占比 | 62% | 41% | 28% | 2.2x |
日均AI情感陪伴时长 | 127分钟 | 45分钟 | 12分钟 | 10.6x |
无算法辅助决策焦虑度 | 高(73%) | 中(45%) | 低(22%) | - |
财务脆弱性(算法诱导消费) | 42%曾动用储蓄 | 28% | 15% | 2.8x |
关键机制:Z世代处于”神经可塑性窗口期”(15-25岁),长期接受算法训练将形成不可逆的认知模式。预计2030年该群体进入劳动力市场后,将表现出更低的创造性问题解决能力和更高的算法依赖症候。
第五章 治理路径:构建平衡发展的AI生态系统
5.1 技术层面:从纠偏到重构
1. 算法透明化与可解释性强制标准。高风险系统(招聘、信贷、司法辅助)必须提供”有意义的信息说明决策逻辑”(EU AI Act要求; 建立”算法 nutrition label”制度,明示训练数据来源、偏见测试结果、置信度区间。
2. 多模态AI的工业导向研发。突破消费端”文本+图像”的局限,发展工业多模态(传感器数据+工艺知识+物理仿真);重点:数字孪生、物理信息神经网络(PINNs)、因果推断工业AI。
3. 联邦学习与隐私计算的工业化。解决工业数据”孤岛”问题,在不共享原始数据前提下实现跨企业协同建模;建立行业级联邦学习联盟(如汽车制造、半导体、航空)。
5.2 制度层面:可操作的治理设计
政策工具 | 具体设计 | 责任主体 | 实施时间 |
数据税制改革 | 消费数据交易征收15%“算法调节税”,30%补贴工业AI | 财政部/税务总局 | 2027-2028 |
算法审计强制化 | 月活>5000万平台需通过第三方伦理审计 | 网信办/市场监管总局 | 2027年起 |
AI素养教育 | 将”算法批判思维”纳入通识教育,训练”反推荐”能力 | 教育部 | 2026秋季起 |
产业引导基金 | 5000亿元”AI+实体经济”专项,1:1配套补贴 | 发改委/工信部 | 2026-2030 |
反垄断算法审查 | 将”算法自我优待”纳入反垄断执法(如平台优先推荐自有产品) | 反垄断局 | 2026年起 |
5.3 社会层面:重建认知主权
认知主权(Cognitive Sovereignty):个体维护独立思考和决策能力、抵抗算法操控的权利。
具体措施: 1. “数字斋戒”(Digital Sabbath):倡导每周24小时脱离算法推荐环境,恢复自主信息获取 ;2. 算法素养教育:不仅”如何使用AI”,更要”如何识别算法操控”、“如何主动搜索替代信息” ;3. 平台责任:强制要求推荐系统提供”随机探索”选项(如抖音的”发现”模式、YouTube的”非推荐”播放列表)。
5.4 企业层面:从CSR到ESG-AI
ESG-AI框架:将AI伦理纳入企业ESG核心指标。
维度 | 关键指标 | 披露要求 |
环境(E) | AI训练碳足迹、数据中心能效 | 年度披露 |
社会(S) | 算法偏见审计结果、员工AI技能再培训投入 | 半年度披露 |
治理(G) | AI伦理委员会独立性、算法事故响应机制 | 实时披露重大事件 |
行业自律:建立”AI for Good”认证体系,对服务于社会福祉(教育公平、医疗普惠、工业安全)的AI应用给予税收抵扣和市场准入优先。
结语:重塑AI发展理念,构建人类命运共同体
AI技术与消费主义的结合,正在以前所未有的速度重塑人类社会。从全球视角来看,这种结合带来的不仅是技术进步和经济增长,更引发了一系列深层次的社会问题。AI技术过度集中于消费场景的偏差,正在从根本上改变人类的行为模式、价值观念和文明形态。
这种偏差的形成,是技术发展、商业利益、社会文化等多重因素共同作用的结果。在技术层面,算法偏见、信息茧房、隐私侵犯等问题日益严重;在伦理社会层面,消费主义价值观的强化、社会分化的加剧、人际关系的异化等挑战不断涌现。更令人担忧的是,这些问题具有累积性和系统性特征,可能引发文明形态的深层变革。
面对这些挑战,我们需要深刻反思AI发展的理念和路径。技术进步不应该以牺牲人类的尊严、自由和幸福为代价。我们需要构建一个以人为本、平衡发展的AI生态系统,让技术真正服务于人类福祉,而不是相反。
这需要全球社会的共同努力。政府需要制定更加完善的监管政策,企业需要承担更多的社会责任,学术界需要加强基础研究和伦理研究,公众需要提升自身的数字素养和批判思维能力。只有通过多方协作,我们才能引导AI技术朝着正确的方向发展,避免技术失控带来的灾难性后果。
展望未来,我们有理由相信,只要人类保持清醒的认识,采取积极的行动,就能够驾驭AI技术这匹”野马”,让它成为推动人类文明进步的强大动力。在这个过程中,我们需要始终牢记:技术是手段,人类是目的。只有坚持这一原则,我们才能在AI时代构建一个更加美好、更加公正、更加可持续的人类命运共同体。
附录:关键术语表
术语 | 定义 |
技术偏差(Technological Drift) | 技术发展路径偏离社会最优方向,被特定利益集团捕获的现象 |
I-SDI指数 | 投资结构偏差指数,消费端AI投资与生产端AI投资的比值 |
算法负债(Algorithmic Debt) | 因过度依赖算法导致的社会成本累积,包括认知退化、信任瓦解等 |
认知漂移(Cognitive Drift) | 长期接触AI策展内容导致的认知基线渐进式改变 |
认知主权(Cognitive Sovereignty) | 个体维护独立思考和抵抗算法操控的能力与权利 |
幻灭低谷期(Trough of Disillusionment) | Gartner技术成熟度曲线中,技术 hype 消退、实际挑战显现的阶段 |
技术捕获(Technical Capture) | 社会逻辑(如消费主义)通过经济机制主导技术演化方向的过程 |
