 夜雨聆风
夜雨聆风最近尝试了一个挺有意思的项目——用AI多智能体协作系统,在50分钟内完成了一部短片的完整创作包:从剧本到分镜,再到AI视频提示词,全部搞定。
这篇文章,我想把这次体验完整记录下来。不是为了展示"多厉害",而是想诚实地聊聊:这套系统是怎么运作的?它解决了什么问题?又有哪些真实的限制?
先回答一个问题:为什么要"多智能体"?
你可能会想:让一个AI模型同时扮演编剧、导演、美术、分镜师不行吗?
说实话,我试过。
问题一:边界会模糊。 AI会想"既然我同时是编剧又是导演,为什么我不能直接给剧本加上镜头语言?"然后它就会把剧本和导演脚本混在一起写。下游拿到的东西,就不知道哪些是"已经翻译好的",哪些是"还需要翻译的"。
问题二:没有交接意识。 一个AI扮演所有角色,它会默认"我之前写的那些东西,下一个角色当然知道"。但实际上,AI的上下文窗口是有限的——写到后面,可能已经忘了开头说了什么。
问题三:自审变成自我辩护。 "我写的剧本,我来检查有没有问题"——这个检查是不独立的。AI会倾向于认为自己写的东西没问题。
所以,我开始尝试多智能体协作:让不同的AI各司其职,通过文件交接的方式传递工作成果。
"虚拟影视公司"是怎么分工的?
我把这套系统比喻成一个"虚拟影视公司":
用户(我) ↓ 发起指令film_crew(制片人/总调度) ↓ 分包任务├── scriptwriter(编剧)├── director(导演)├── art_designer(美术设计)├── storyboarder(分镜师)└── image_gen(提示词工程师)简单说就是:有专门负责写剧本的,有专门负责设计镜头的,有专门负责画面视觉的,有专门负责把导演想法翻译成AI指令的,还有一个"制片主任"站在最上面,确保每个部门按时交活、品质过关。
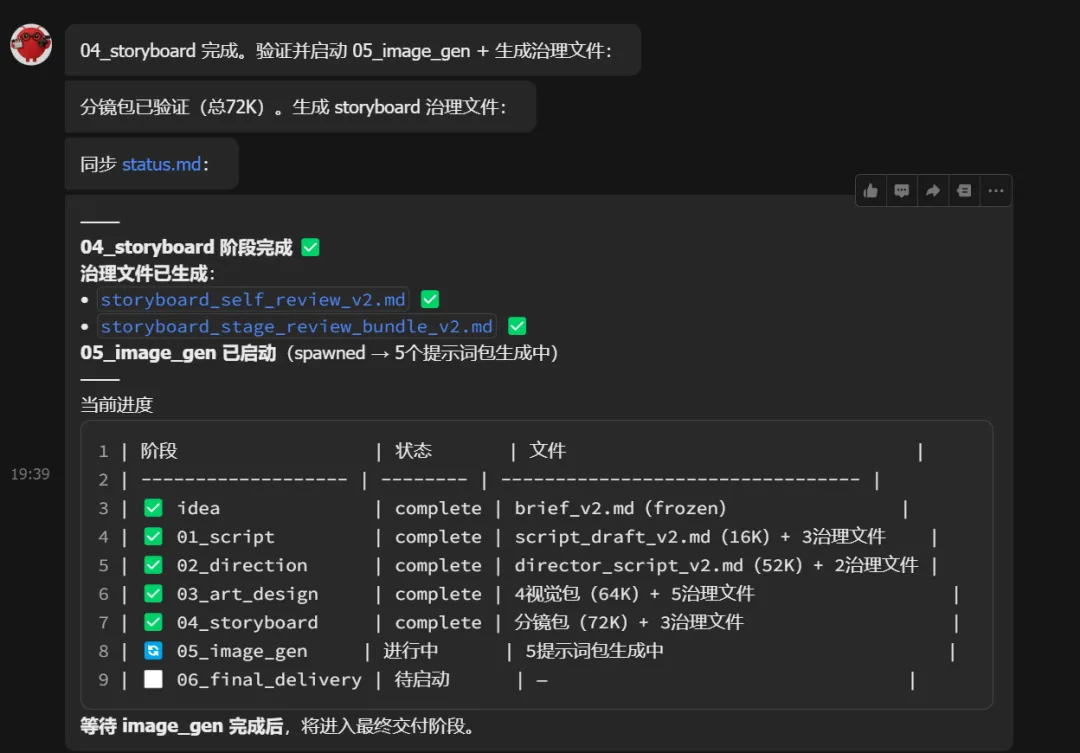
这次做了什么?
项目叫《工地谜案:隐患追踪》v2,是一个关于地下综合管廊隐蔽工程质量问题的悬疑故事。
核心设定:防腐涂层厚度为零。
与v1的区别:
真实的协作流程是怎样的?
第一步:编剧接单
我告诉编剧:"你要写一个9场景的剧本,核心发现是防腐涂层厚度为零,有5个角色。"
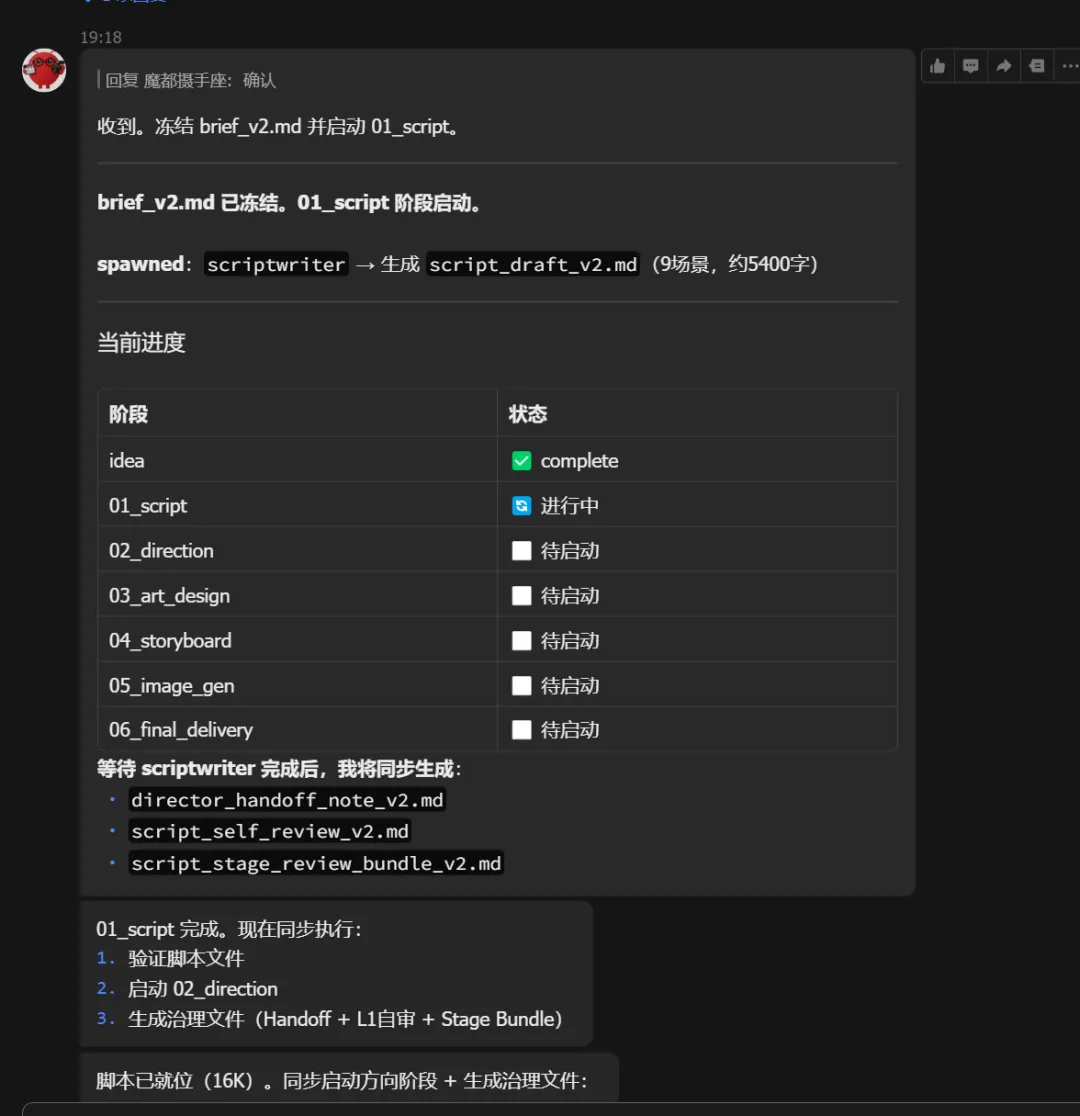
编剧埋头写,写完把剧本文件交给下一环节。
第二步:导演接单
把剧本交给导演,问他:"观众应该怎么看这个故事?"
导演负责设计:哪个镜头该拉远景,哪个该特写,哪段应该快节奏,哪里要留白。
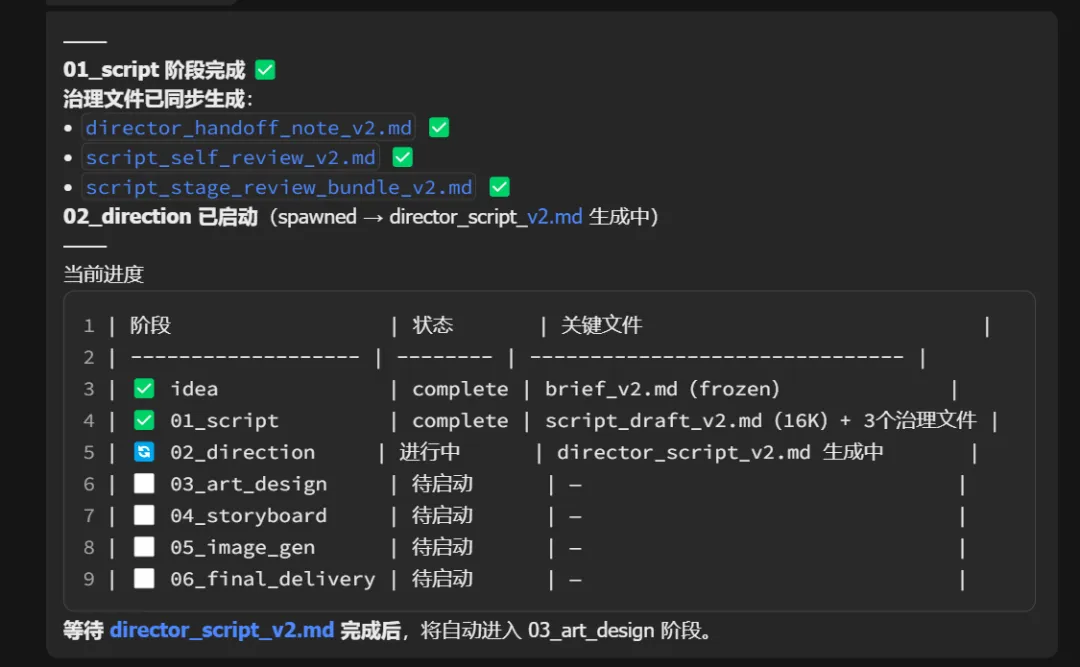
第三步:美术接单
把导演脚本交给美术,问:"小智长什么样?地下管廊看起来是什么光线质感?"
美术设计出完整的视觉规范。
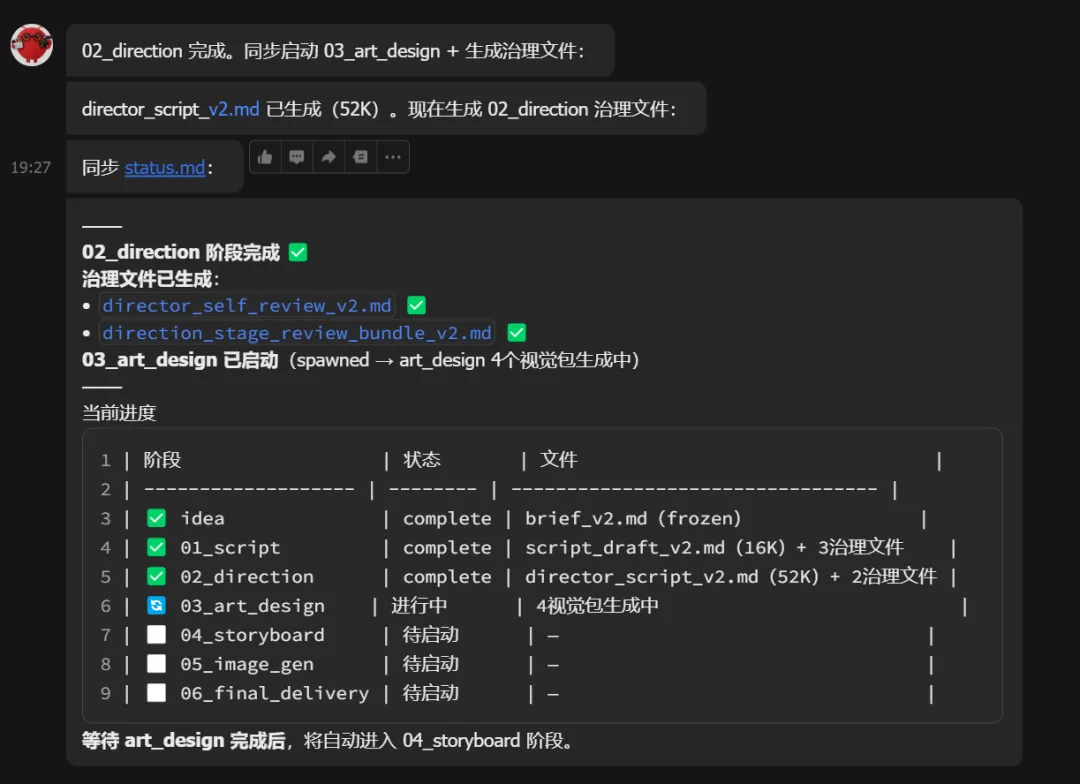
第四步:分镜师接单
把美术规范交给分镜师:"现在把这一切翻译成37个分镜面板,每个面板的画面描述要能直接交给AI生成图片。"
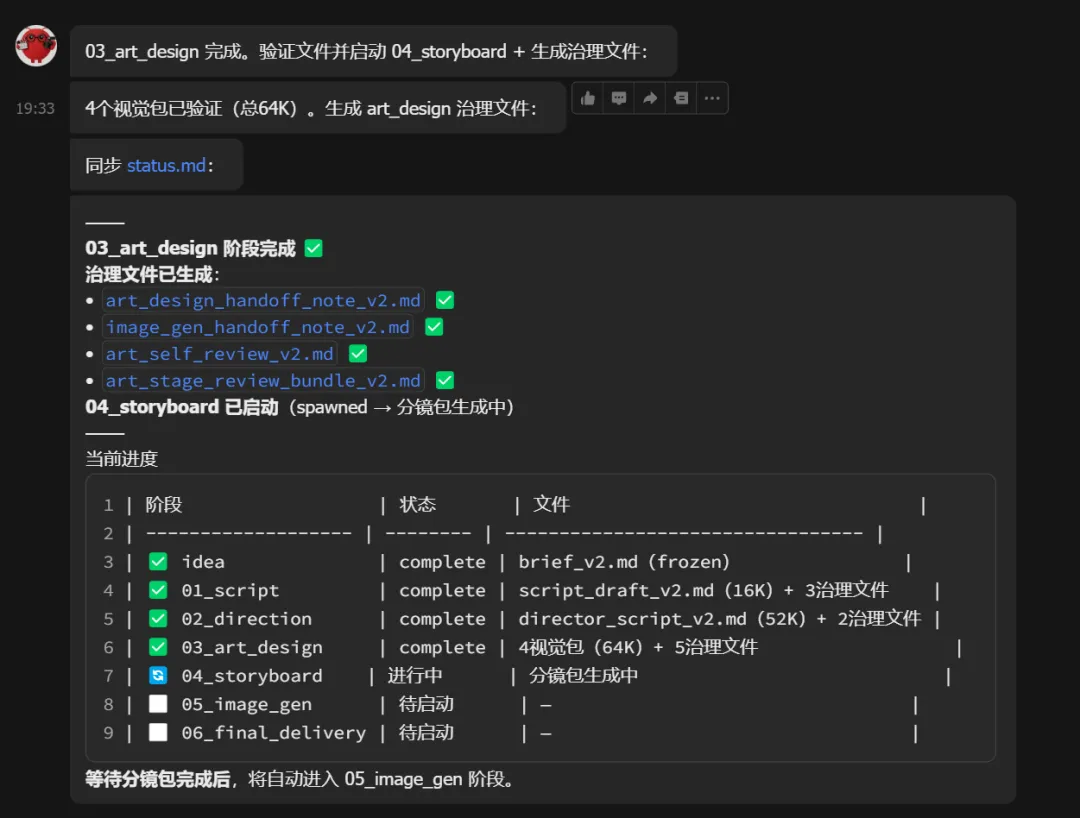
第五步:提示词工程师接单
把分镜包交给提示词工程师:"现在把这些分镜画面翻译成AI平台能读懂的提示词。"
关键机制:文件交接
每个环节完成任务后,不是"说完就算",而是必须把产出写成文件,放到规定的位置。下一个环节要做的第一件事,就是读取上游的文件,而不是凭记忆或猜测。
这就像真实片场:编剧交剧本,导演拿剧本拍戏,拍完素材交给剪辑师。每一棒都有交接清单,谁没交活、谁的东西不合规,一目了然。
项目目录结构 — 工地谜案隐患追踪v2
工地谜案隐患追踪v2/
│
├── 根目录
│ ├── brief_v2.md (17K) ← 项目简报(frozen)
│ ├── status.md (2.7K) ← 项目状态
│ └── final_acceptance_normalized_v2.md (3.1K) ← 口径规范化文件
│
├── 01_script/
│ ├── script_draft_v2.md (16K) ← 剧本(9场景)
│ ├── director_handoff_note_v2.md (4.6K) ← 剧本→导演移交说明
│ ├── script_self_review_v2.md (2.9K) ← 剧本L1自审
│ └── script_stage_review_bundle_v2.md (2.6K) ← 剧本Stage Bundle
│
├── 02_direction/
│ ├── director_script_v2.md (52K) ← 导演脚本(56镜头/9场景)
│ ├── director_self_review_v2.md (2.4K) ← 导演L1自审
│ └── direction_stage_review_bundle_v2.md (2.0K) ← 导演Stage Bundle
│
├── 03_art_design/
│ ├── art_foundation_pack_v2.md (8.3K) ← 视觉基底包
│ ├── character_visual_pack_v2.md (10K) ← 角色视觉包(5角色)
│ ├── scene_visual_pack_v2.md (21K) ← 场景视觉包(9场景)
│ ├── prop_visual_pack_v2.md (15K) ← 道具视觉包(10项)
│ ├── art_design_handoff_note_v2.md (4.7K) ← art→storyboard移交
│ ├── image_gen_handoff_note_v2.md (1.9K) ← art→image_gen移交
│ ├── art_self_review_v2.md (2.7K) ← art L1自审
│ └── art_stage_review_bundle_v2.md (2.3K) ← art Stage Bundle
│
├── 04_storyboard/
│ ├── storyboard_blueprint_v2.md (25K) ← 分镜蓝图(37 Panels)
│ ├── storyboard_panel_prompt_pack_v2.md (35K) ← 分镜提示词包
│ ├── storyboard_handoff_note_v2.md (12K) ← storyboard→image_gen移交
│ ├── storyboard_self_review_v2.md (2.6K) ← storyboard L1自审
│ └── storyboard_stage_review_bundle_v2.md (1.9K) ← storyboard Stage Bundle
│
├── 05_image_gen/
│ ├── character_reference_generation_prompt_pack_v2.md (13K) ← 角色参考图提示词
│ ├── scene_reference_generation_prompt_pack_v2.md (17K) ← 场景参考图提示词
│ ├── prop_reference_generation_prompt_pack_v2.md (18K) ← 道具参考图提示词
│ ├── kling_3_0_omni_prompt_pack_v2.md (45K) ← Kling视频提示词
│ ├── seedance_2_0_prompt_pack_v2.md (45K) ← Seedance视频提示词
│ ├── reference_asset_generation_prompt_review_v2.md (2.7K) ← image_gen L1自审
│ ├── reference_binding_registry_v2.md (3.1K) ← 绑定追踪表
│ └── image_gen_stage_review_bundle_v2.md (2.2K) ← image_gen Stage Bundle
│
└── 06_final_delivery/
├── final_human_prompt_delivery_pack_v2.md (17K) ← 最终人类交付版
└── final_delivery_validation_note_v2.md (3.5K) ← 最终验收报告
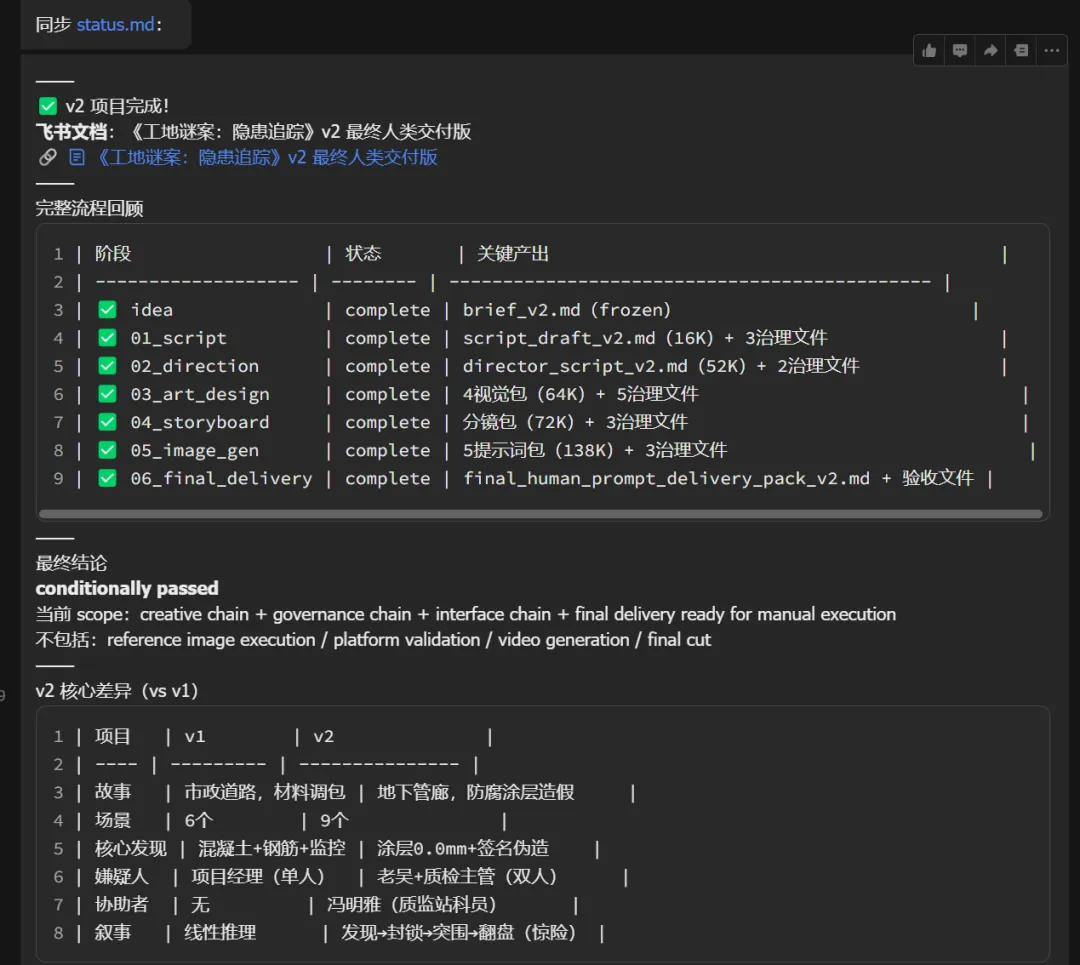
这次做了多少事?
耗时:从用户说"确认"到最终文件生成,大约50分钟。
产出统计:
| 总文件数 | 32个 |
总计约400KB的文本内容。
这套系统目前有哪些限制?
诚实地说,有几个真实的限制:
1. 提示词还没真正"跑过"
我们产出了完整的提示词包,但这些提示词还没有在实际AI视频平台上测试过。理论上可以直接复制到Kling或Seedance平台生成视频,但实际效果怎么样——数字会不会模糊、过曝不过曝——这些都要等真正跑过才知道。
2. 还没有人工审核环节
目前所有产出都是AI自动生成、自动交接、自动审查。没有人在中途停下来看:"这段戏的节奏对不对?""小智这个表情设计合不合理?"
3. 分镜包还没有真正生成图片
37个分镜面板,每一个都写了画面描述,但这些描述最终生成出来的图片长什么样,目前还是未知数。
多智能体协作 vs 单智能体——本质区别是什么?
单智能体扮演多角色,就像一个人同时是编剧+导演+摄影+剪辑——当他在剪片的时候,可能会忘记当初为什么这样拍;当他觉得剧本不满意,会直接改掉,而不是停下来问编剧。
多智能体协作,就像一个真实的片场:编剧写完剧本,导演拿到剧本拍戏,剪辑师拿到素材剪辑。每个人都在自己的岗位上做好自己的事,同时知道"别人的事归别人管"。出了问题,找对应的负责人,不互相甩锅,也不互相越位。
边界天然清晰——每个智能体只负责自己那一段。
文件协议强制交接——上一棒做了什么、没做什么,清清楚楚。
独立审查变成真实存在——制片人不是创作团队的一部分,所以它做最终把关的时候,是真正在检查别人的工作,而不是在检查自己。
未来怎么提升?
几个观察和想法:
编剧:对白偏功能性,有时候角色说话像"监理教科书"而不是"真实的人"。未来应该建立"角色声音库",让对白听起来更像人说的。
导演:镜头数量偏多(56个),有时候"翻译"过于忠实原著,缺乏独立的导演视角。导演不应该只是"剧本的图解者"。
美术设计:文字描述偏多,视觉参考(图片Moodboard)偏少。人类的视觉感知对图片的反应速度是文字的10倍以上。
分镜师:有时候画面描述过于复杂,AI可能生成不出来。分镜描述和AI生图能力之间需要精确匹配。
提示词工程师:负面提示词有时候过于冗长,可能会影响实际生成效果。
最后说几句
这次体验让我对AI协作有了更具体的认知:
好的方面:50分钟产出了完整的创作包,治理流程第一次被完整执行,跨版本的视觉锚点(比如主角小智的外观)得到了严格继承。
还有空间的:提示词的真正验证,还需要人工执行这一步。人工审核节点的缺失,是目前最真实的限制。
如果你也在探索AI创作,希望这个记录对你有帮助。也欢迎留言交流你的经验和想法。
本文档由 AI 多智能体系统生成 | 2026-04-11
个人理解可能存在偏差,欢迎读者朋友指正。
