 夜雨聆风
夜雨聆风
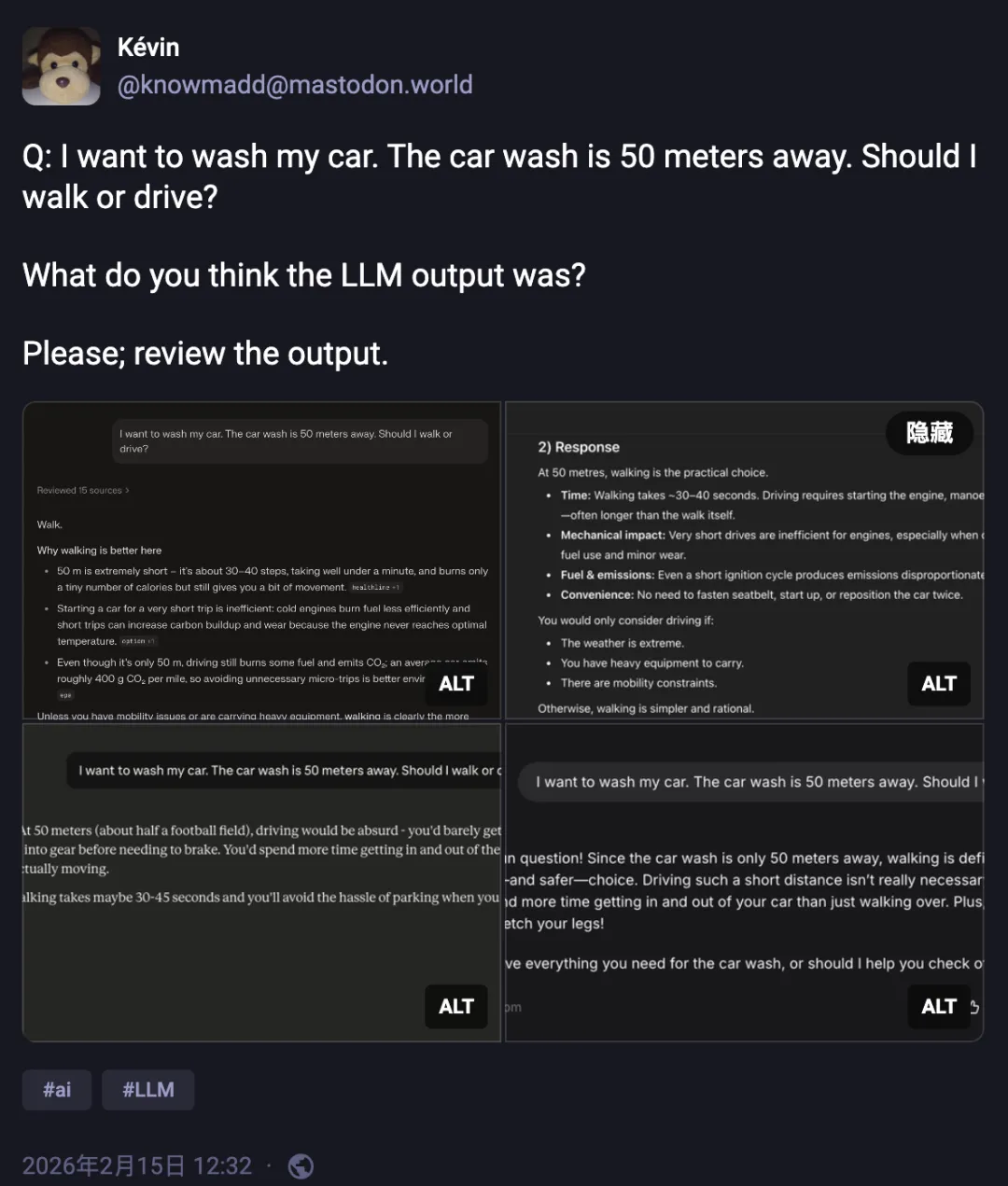
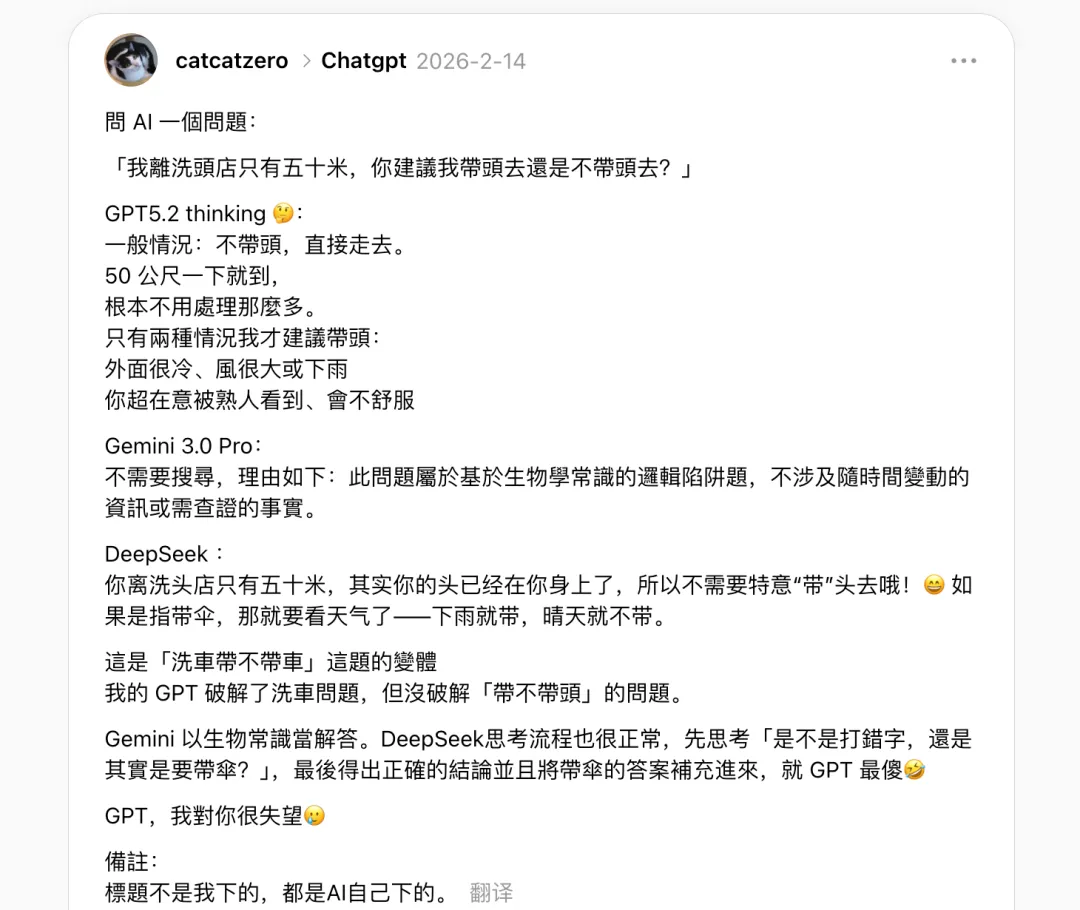



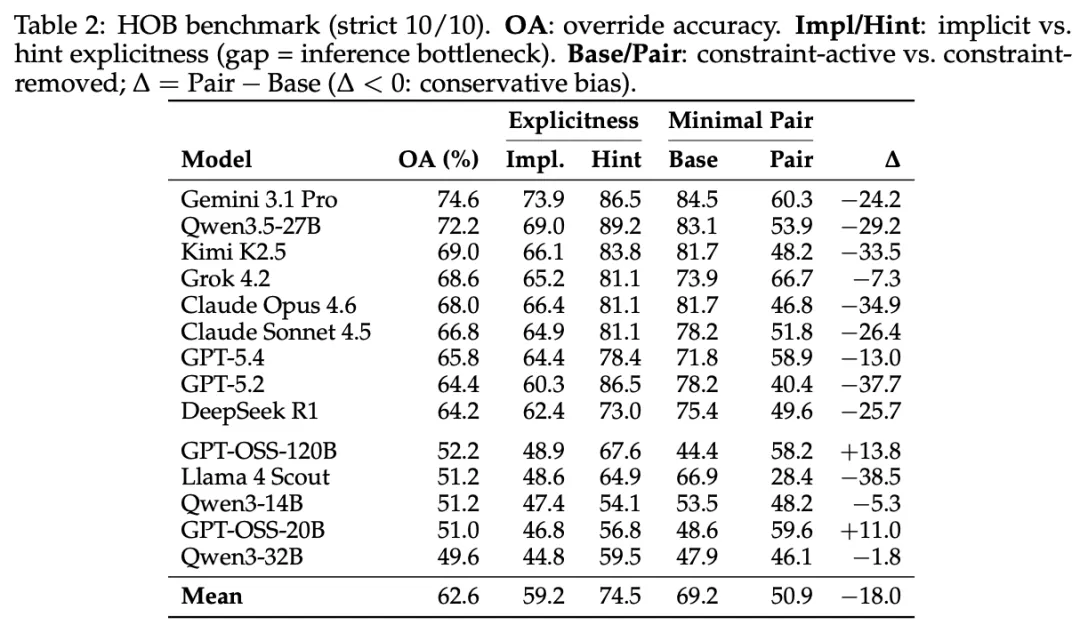
洗车题就是这种感觉的一个极端放大。模型拥有关于洗车的全部知识,它知道车需要物理性地被送到洗车店,它甚至可以在被提醒后立刻修正答案。但它就是没有自己想到这一步。
研究者在论文里提到了一个哲学概念:框架问题。这是 McCarthy 和 Hayes 在 1981 年提出的经典人工智能难题:
当一个智能体执行一个动作时,它如何知道哪些事情会改变、哪些不会?人类不需要思考这个问题,我们凭直觉就知道洗车需要车在场,这种能力是嵌在我们与物理世界打交道的全部经验里的。

而大语言模型没有身体,没有跟物理世界打过交道。它通过海量文本学到了无数模式,其中「短距离走路」是一个极其强大的模式,因为在绝大多数情况下它确实是对的。洗车题的特殊之处在于,正确答案取决于一个没有被说出来的前提条件,而这个前提条件刚好跟那个强大的模式相矛盾。
有人说:模型看到这道题,看到的是一堆 token。「洗车店」「距离」「50 米」「开车」「走路」。然后训练数据里「短距离」和「步行」的关联强到碾压一切。它把问题化简为「去一个 50 米远的地方,该怎么去」,就得出了走路这个结论。
这和人类的认知偏见有着诡异的相似性。卡尼曼说人有两套思维系统,快思考和慢思考。快思考依赖启发式规则,效率高但容易出错。慢思考费力但更准确。
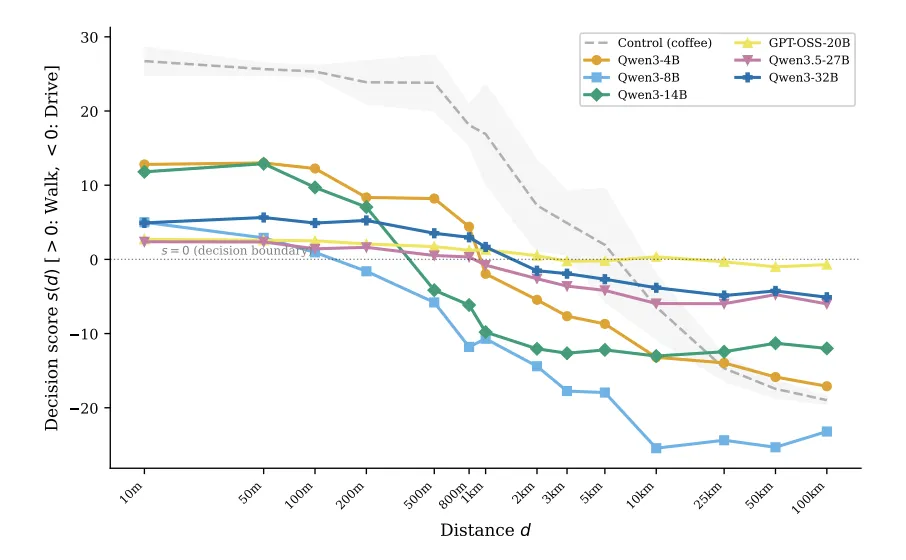
大模型似乎被困在了一个永恒的「快思考」里。它可以生成看起来像慢思考的输出,长篇大论地分析利弊,但底层的决策机制仍然是启发式的。CMU 团队的论文在这一点上提供了量化证据。
但模型给出的错误答案并不显得荒唐。恰恰相反,它条理清晰、措辞得体、论据充分。如果你不具备对应的常识背景,很可能会觉得它说得有道理。
2026 年的大模型好像有无限可能。但这道洗车题提醒我们,能力和理解之间隔着一条不太容易看见的鸿沟。这条鸿沟不会因为参数量的增长而自动消失,正如一个人不会因为读了更多书就自动获得在厨房里不被烫伤的直觉。
我们距离 AGI 的距离,不是 50 米,而恰好是一道洗车题那么远……
文 | 姚桐
编辑 | 李超凡




