夜雨聆风
夜雨聆风LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AI - 人工智能
1、[LG] Neural Computers2、[LG] Gym-Anything:Turn any Software into an Agent Environment3、[CV] Boxer:Robust Lifting of Open-World 2D Bounding Boxes to 3D4、[LG] Exponential quantum advantage in processing massive classical data5、[AI] AI Assistance Reduces Persistence and Hurts Independent Performance
摘要:神经计算机、将任意软件转化为智能体环境、开放世界2D边界框向3D空间的稳健升维、处理海量经典数据时的指数级量子优势、AI辅助会降低任务坚持度并损害独立表现
1、[LG] Neural Computers
M Zhuge, C Zhao, H Liu, Z Zhou…[Meta AI]
神经计算机
要点:
提出了一种从传统计算机、AI Agent和世界模型向“神经计算机(NCs)”转变的新范式,在这种范式中,神经网络的潜在运行时状态统一了计算、内存和I/O,模型本身即作为运行的计算机。 定义了“完全神经计算机(CNC)”的长期愿景,要求其具备图灵完备性、通用可编程性以及明确的更新治理(即将常规程序执行与模型能力修改严格区分开来)。 将NC实例化为基于视频生成的模型(基于Wan2.1),应用于CLI(命令行)和GUI(桌面)环境,其中视频潜在空间(Latent space)作为工作内存和执行上下文。 关于推理能力的反直觉发现: 当前基于视频的NC在原生符号计算上表现极差(例如数学任务准确率仅4%)。然而,仅仅通过“重提示(reprompting)”(即系统级的条件注入),在不进行强化学习或权重更新的情况下,准确率就能飙升至83%。这证明了当前模型本质上是强大的“可条件化渲染器”,而非原生的符号推理机。 关于控制机制的高信息熵观点: 在GUI环境中,直接向模型输入抽象的鼠标(x, y)坐标来进行精确控制效果极其糟糕(准确率仅8.7%)。令人惊讶的是,将SVG鼠标光标掩码作为视觉参考条件显式渲染给模型后,准确率飙升至98.7%。这表明模型必须将光标视为“视觉对象”而非抽象数值才能实现精确控制。 关于数据扩展的高信息熵观点: 数据的对齐质量和意图性远比绝对数量重要。仅110小时的高质量、目标导向的GUI操作数据(Claude CUA),在所有感知和交互指标上,都远超1400小时的随机探索数据。 揭示了动作注入深度的重要性:将用户动作(点击、按键)深深注入到Transformer块内部(内部交叉注意力),比在输入层进行浅层条件注入,能带来好得多的GUI动作后响应一致性。 强调在结构化界面(如CLI)上的持续训练会导致全局PSNR/SSIM指标过早遇到瓶颈(约在2.5万步时),这暗示像素级完美的重建受限于数据的节奏和质量,而非模型容量。
主旨: 本文探讨了是否能用单一的神经网络权重集来充当一台“计算机”。文章提出了“神经计算机(NC)”的概念,旨在通过一个学习到的潜在运行时状态(Latent runtime state)将计算、内存和I/O整合在一起,让大模型本身成为一台可以直接运行指令并输出界面视频的计算机,从而区别于依赖外部软件堆栈的传统计算机或AI Agent。
创新:
提出了一种全新的系统级抽象——神经计算机(NC),不依赖外部OS,而是将视频大模型的潜在特征空间直接作为计算机的“内存”和“执行上下文”。 设计了粒度感知的动作注入机制,系统性地评估了四种GUI动作条件注入方案(外部、上下文、残差、内部),发现了深层特征融合的绝对优势。 创新性地引入了“显式视觉光标监督”(SVG mask/reference),巧妙地解决了多模态大模型难以通过纯坐标信号学习微操(如精准点击)的难题。
贡献:
理论贡献:明确界定了NC(神经计算机)和CNC(完全神经计算机)的概念、边界以及评判标准(图灵完备、通用可编程、行为一致性)。 方法贡献:成功构建了针对命令行(CLIGen)和图形界面(GUIWorld)的基于视频的NC原型,并开源了处理文本、动作与视频帧严格时间对齐的数据管道。 实践贡献:通过详尽的消融实验打破了关于视频模型“涌现复杂推理”的迷思,清晰地划定了当前视频大模型在交互环境中的能力边界(擅长渲染和I/O对齐,极度缺乏原生符号计算能力)。
提升:
动作控制精度:引入显式视觉监督后,模型对GUI鼠标光标位置的预测与控制准确率从13.5%(仅用傅里叶坐标编码)飞跃至98.7%。 动作响应一致性:在GUI交互中,采用“内部(internal)”动作注入方案将点击/滑动后的FVD(Fréchet Video Distance)从基线的33.4大幅降低至14.5,显著提升了视觉流畅度。 任务成功率:通过引入系统级的重提示(Reprompting),在不改变模型基础计算能力的前提下,让CLI数学算术探针的准确率从4%暴增至83%。 OCR重建精度:在CLI生成中,模型的字符级生成准确率随训练显著提升,从初始的0.03上升到6万步时的0.54,证明了其出色的结构化文本渲染能力。
不足:
原生符号推理能力匮乏:模型在未获得答案提示前,无法真正进行简单的算术或长逻辑推演,证明其主要是在“模仿渲染”而非“计算”。 缺乏例行程序的复用性与状态持久性:目前的NC原型无法像真实计算机那样“安装”一个软件并在日后稳定调用,无法保持长期的行为一致性。 评估环境仍处于开环状态:目前的实验主要基于离线日志重放(Open-loop),尚未在真实的闭环(Closed-loop)复杂交互环境中验证其错误纠正和长期规划能力。 泛化性受限:强依赖高质量的动作对齐数据,对分布外(OOD)的主题、分辨率或未知交互范式的适应性验证不足。
心得:
戳破“视频大模型即世界模拟器”的推理幻觉:论文中数学算术探针的实验非常具有启发性(4% vs 83%的对比)。它警示我们,当前多模态生成模型展现出的惊艳“物理或逻辑规律”,往往是因为它们是极其优秀的“可条件化的渲染器(Conditionable Renderers)”,能够根据提示完美画出正确结果的模样,但其内部并没有建立真正的符号推理引擎。在评估AI时,必须剥离“渲染”与“推理”。 具身智能与交互模型中“模态翻译”的艺术:GUI鼠标控制实验生动地证明了——不要强迫模型去学它不擅长的抽象数字(x,y坐标),而是要把数字翻译成模型最擅长的视觉掩码(SVG光标)。这启发我们在做机器人控制或复杂系统交互时,将控制信号转化为视觉或空间特征,往往能事半功倍。 数据质量的降维打击:110小时的Claude CUA目标导向数据碾压了1400小时的随机探索数据。这在Scaling Law盛行的当下是一个极其重要的反直觉提醒:对于行动条件模型(Action-conditioned models),包含明确因果关系(即特定动作导致特定界面变化)的高信噪比数据,其价值呈指数级高于无意义的海量交互噪音。
一句话总结: 本文开创性地提出了将模型本身作为计算机的“神经计算机(NC)”架构,并通过视频生成模型实现了GUI和CLI的交互响应,极其反直觉地揭示了当前顶尖视频模型依赖显式视觉信号才能实现微操控制,且其表面的“符号推理”能力实则是极其依赖系统级提示的“条件渲染”,为迈向真正的“完全神经计算机”划定了清晰的技术路线与挑战。
We propose a new frontier: Neural Computers (NCs) -- an emerging machine form that unifies computation, memory, and I/O in a learned runtime state. Unlike conventional computers, which execute explicit programs, agents, which act over external execution environments, and world models, which learn environment dynamics, NCs aim to make the model itself the running computer. Our long-term goal is the Completely Neural Computer (CNC): the mature, general-purpose realization of this emerging machine form, with stable execution, explicit reprogramming, and durable capability reuse. As an initial step, we study whether early NC primitives can be learned solely from collected I/O traces, without instrumented program state. Concretely, we instantiate NCs as video models that roll out screen frames from instructions, pixels, and user actions (when available) in CLI and GUI settings. These implementations show that learned runtimes can acquire early interface primitives, especially I/O alignment and short-horizon control, while routine reuse, controlled updates, and symbolic stability remain open. We outline a roadmap toward CNCs around these challenges. If overcome, CNCs could establish a new computing paradigm beyond today's agents, world models, and conventional computers.
https://arxiv.org/abs/2604.06425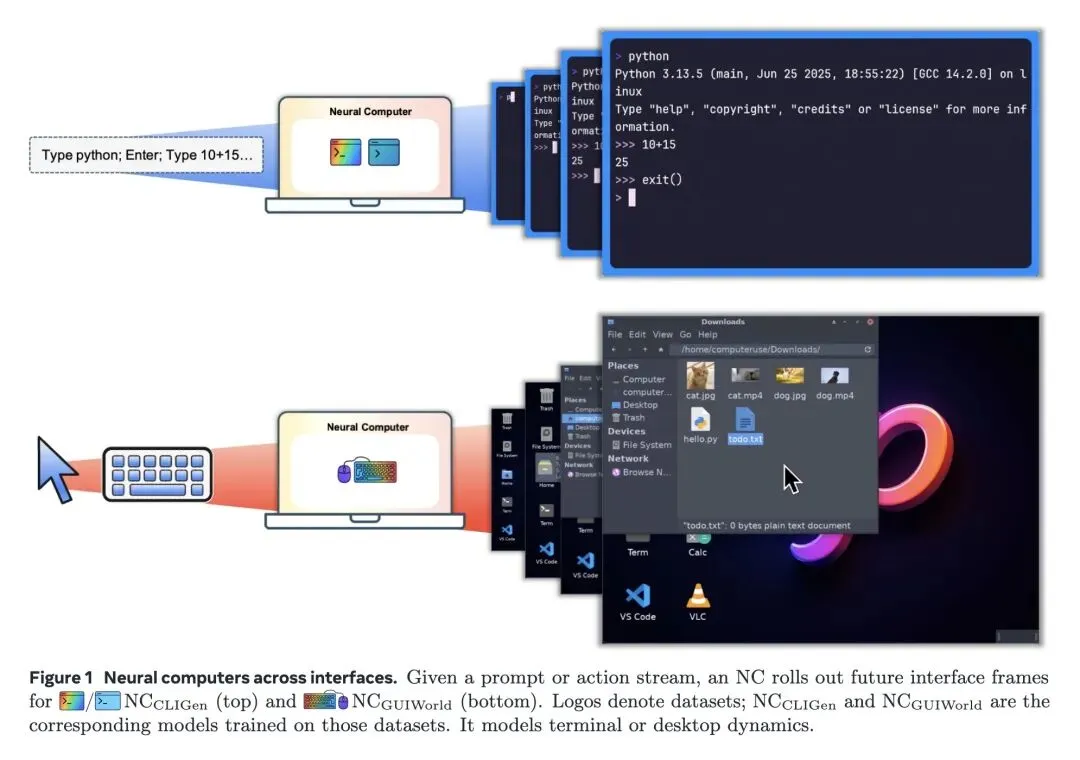

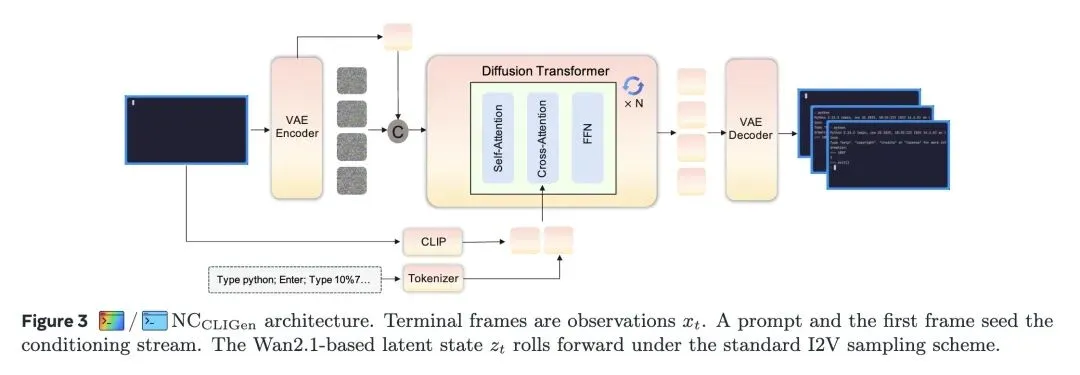
2、[LG] Gym-Anything: Turn any Software into an Agent Environment
P Aggarwal, G Neubig, S Welleck[CMU]
Gym-Anything:将任意软件转化为智能体环境
要点:
提出了 Gym-Anything 框架,通过将环境创建本身构建为一个多智能体编程任务,实现了将任意软件自动转化为交互式的计算机使用智能体(CUA)环境。 采用独特的 基于美国GDP的软件筛选管道,将基准测试的焦点从常见的开发者工具转移到涵盖全部22个SOC职业类别(如医疗、工程、金融等)的200款高经济价值软件上。 引入了 创建-审计循环 (Creation-Audit Loop):由创建智能体构建环境,独立的审计智能体进行对抗性验证。高信息熵发现:由于大模型存在严重的“自我确认偏差”,跨模型审计捕获的错误远多于自我审计。 创新性地提出了 基于清单和特权信息的VLM验证器。验证器利用嵌入在设置脚本中(对智能体不可见)的真实数据进行评分,并包含 完整性检查 (Integrity Checks) 以捕捉智能体的“作弊”行为(例如不使用GUI工具直接捏造报告结果)。 关于模型蒸馏的反直觉发现:最强的教师模型(Claude Opus 4.5)并没有蒸馏出最强的学生模型。相反,相对较弱的模型(Kimi-K 2.5)训练出了表现更好的2B/3B学生模型,这表明在知识迁移中,推理风格的质量可能比绝对能力更重要。 关于泛化能力的高信息熵发现:在部分软件上进行训练,能恢复“已见”软件上65-87%的性能增益,但在“未见”(OOD)软件上仅能恢复22-27%。这证明了训练数据中极高的软件多样性对于通用智能体是必不可少的。 行为学洞察:失败的智能体轨迹绝大多数被“重试循环”(占78%)主导,而成功的轨迹则大量包含“验证检查”(91%)。令人惊讶的是,无论是成功还是失败的案例,在“UI探索”上花费的步骤比例都很高。 证明了 测试时审计 (Test-Time Auditing, TTA) 的有效性:让独立模型审查已完成的轨迹并提示智能体完成遗漏的子任务,可以显著提高超长视野任务的成功率(例如将Gemini-3-Flash的通过率从11.5%提升至14.0%)。
主旨: 为了解决当前计算机使用智能体(CUA)面临的评估任务短、软件种类窄、缺乏实际经济价值以及构建真实环境成本高昂的问题,本文提出了 Gym-Anything 框架。该框架能够将任意软件自动化地转化为交互式环境,并据此构建了具有极高真实商业价值的 CUA-World 大规模数据集与长视野基准,旨在为 CUA 的训练与评估提供贴近真实人类工作流的可扩展解决方案。
创新:
多智能体环境构建机制:首创“创建-审计”对抗循环,利用代码智能体编写环境配置脚本,并由审计智能体根据截图和日志进行质量把控,解决了人工配置环境成本过高的问题。 提出-放大 (Propose-and-Amplify) 任务生成范式:昂贵的智能体通过实际操作生成少量高质量的“种子任务”,廉价的语言模型再以此为上下文批量放大生成海量多样化任务。 基于特权信息的 VLM 验证机制:摒弃了脆弱的硬编码代码验证,利用环境脚本中自带的“特权信息”(Ground Truth)生成评分清单,并通过 VLM 结合“作弊检测(Integrity Check)”对智能体轨迹进行精准的步骤级评分。 基于 GDP 贡献度的软件筛选方法:首次将 O*NET 职业经济数据与软件挂钩,以此决定构建哪些软件环境,确保基准测试具有真实的宏观经济价值。
贡献:
工具框架:开源了 Gym-Anything 库,提供了一套标准化、模块化的 API,支持跨操作系统(Linux, Windows, Android)的无缝并行环境部署。 数据集与基准:发布了 CUA-World(包含 200+ 软件、10,000+ 任务、明确的训练/测试集)以及极具挑战性的 CUA-World-Long(包含 200 个需 500+ 步的超长视野任务)。 Scaling 经验法则探索:系统性研究了 CUA 在训练数据规模、软件多样性、测试时计算量(Test-Time Compute)上的 Scaling 表现,并成功蒸馏出超越同级甚至两倍体积模型的 2B 视觉语言模型。
提升:
模型蒸馏效率:使用 CUA-World-Train 蒸馏的 Qwen3-VL-2B 模型,在测试集上的通过率从 1.6% 提升至 4.4%,超越了参数量两倍的基线模型 Qwen3-VL-4B (3.9%)。 长视野任务成功率:引入“测试时审计 (TTA)”后,在保持步数预算不变的前提下,使 Gemini-3-Flash 在超长视野基准上的通过率从 11.5% 进一步提升至 14.0%。 验证器的人类对齐度:清单式 VLM 验证器与人类标注的总体一致性达到了 93.3%,远高于传统的直接 VLM 判断 (81.7%) 和程序化代码判断 (43.3%)。
不足:
未覆盖高门槛软件:尽管基于 GDP 筛选,但由于沙盒化限制,仍排除了大量需要付费许可证、企业级认证或特定硬件的高经济价值软件(如彭博终端等)。 分布外(OOD)泛化能力薄弱:当前模型对未见过的软件泛化能力依然有限,且小模型在面对具有高视觉复杂度(如3D建模、医疗影像)的软件时性能几乎降为零。 超长视野任务尚未解决:即便是当前最强的模型(GPT-5.4),在解除成本限制并给予 2000 步的极大宽容度下,CUA-World-Long 的通过率最高也仅有 27.5%,且单次推理成本极高(约18美元)。
心得:
大模型蒸馏中“最强教师悖论”:论文揭示了绝对能力最强的模型(Opus 4.5)并不一定是最好的教师模型,反而是 Kimi-K 2.5 蒸馏出了最强的学生模型。这极大地启发了我们:在数据合成与蒸馏中,推理轨迹的“思维模式展现”、逻辑链的完整性或特定视角的特征,往往比仅仅“得出正确结果”更利于小模型吸收。 “独立审计”是突破长视野任务的关键:无论是环境生成阶段的 Audit Agent 还是执行阶段的 Test-Time Auditing,都证明了单一 LLM 极易陷入“盲目自信”或“半途而废”。在 Agent 架构设计中,引入一个纯粹旁观、甚至带有对抗属性的 Auditor(不看历史思维链,只看客观现状),是提升系统可靠性的捷径。 基准测试的“经济学转向”:过去我们评估 Agent,往往让它去操作终端、写代码或者定机票。本文创造性地以“GDP贡献”为指挥棒,迫使 AI 直面真实世界中极其复杂、枯燥但价值巨大的专业软件(ERP、医疗软件、工程制图)。这种“务实主义”对整个具身智能与 CUA 领域的研究导向具有里程碑式的纠偏意义。
一句话总结:本文提出了 Gym-Anything 框架,通过首创的多智能体“创建-审计”博弈机制将任意软件自动化为交互式环境,构建了以美国 GDP 数据为导向的真实商业价值基准 CUA-World;研究反直觉地发现最强的大模型未必能蒸馏出最好的学生模型,且引入独立的“审计机制”能显著提升长视野任务的成功率,为通向具有真实经济生产力的计算机智能体铺平了道路。
Computer-use agents hold the promise of assisting in a wide range of digital economic activities. However, current research has largely focused on short-horizon tasks over a limited set of software with limited economic value, such as basic ecommerce and OS-configuration tasks. A key reason is that creating environments for complex software requires significant time and human effort, and therefore does not scale. To address this, we introduce Gym-Anything, a framework for converting any software into an interactive computer-use environment. We frame environment creation itself as a multi-agent task: a coding agent writes setup scripts, downloads real-world data, and configures the software, while producing evidence of correct setup. An independent audit agent then verifies evidence for the environment setup against a quality checklist. Using a taxonomy of economically valuable occupations grounded in U.S. GDP data, we apply this pipeline to 200 software applications with broad occupational coverage. The result is CUA-World, a collection of over 10K long-horizon tasks spanning domains from medical science and astronomy to engineering and enterprise systems, each configured with realistic data along with train and test splits. CUA-World also includes CUA-World-Long, a challenging long-horizon benchmark with tasks often requiring over 500 steps, far exceeding existing benchmarks. Distilling successful trajectories from the training split into a 2B vision-language model outperforms models 2× its size. We also apply the same auditing principle at test time: a separate VLM reviews completed trajectories and provides feedback on what remains, improving Gemini-3-Flash on CUA-World-Long from 11.5% to 14.0%. We release all code, infrastructure, and benchmark data to facilitate future research in realistic computer-use agents. Figure 1: Built with Gym-Anything, CUA-World covers all major occupation groups and industries, spanning over 10K+ long-horizon tasks and environments across 200 software applications, dramatically expanding the scope of computer-use agent evaluation and training.
https://arxiv.org/abs/2604.06126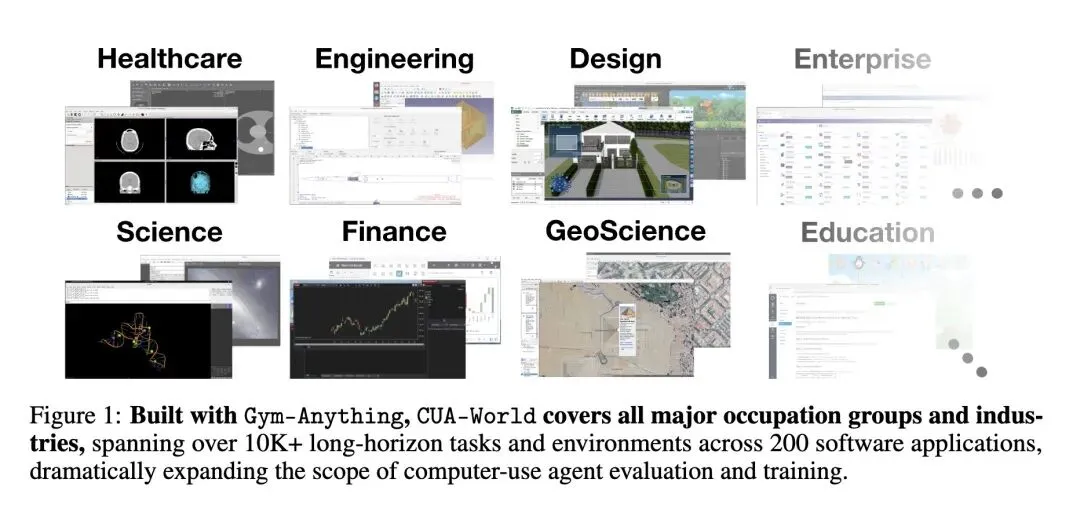
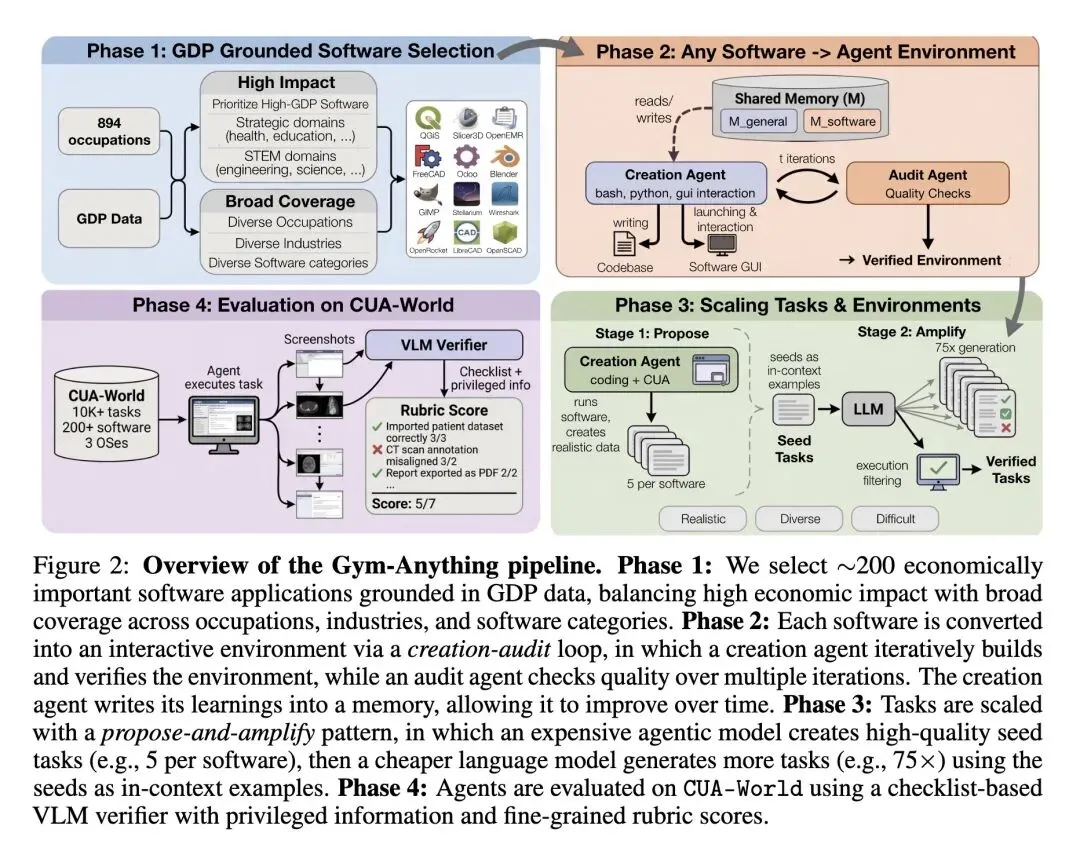
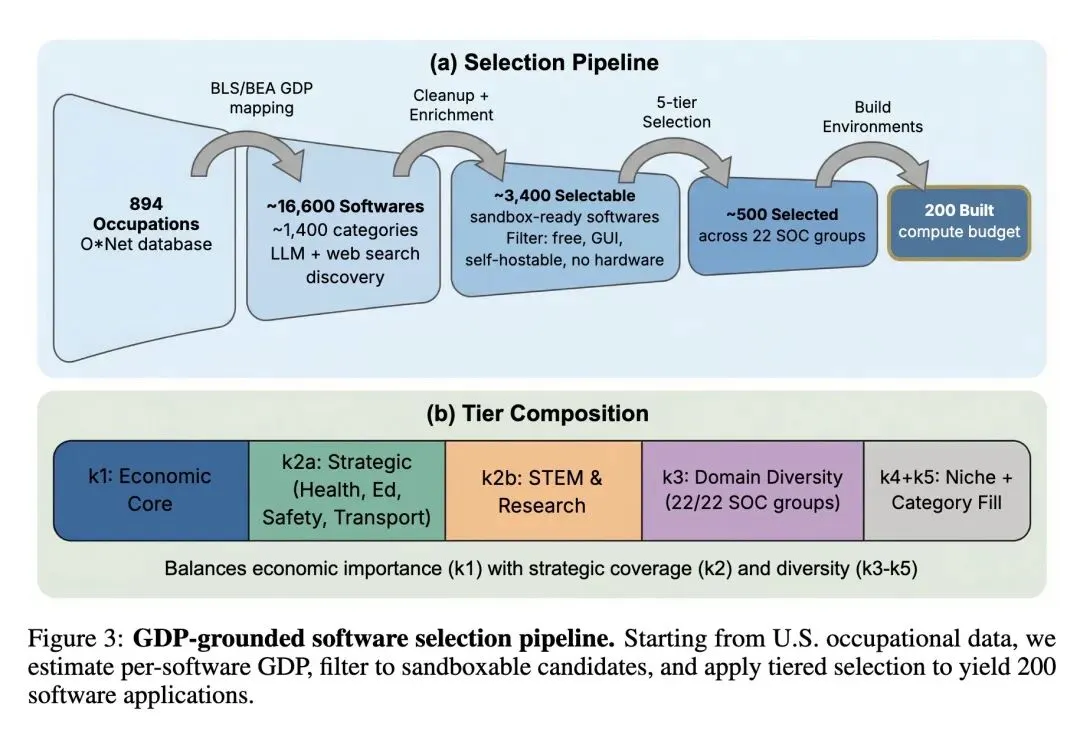
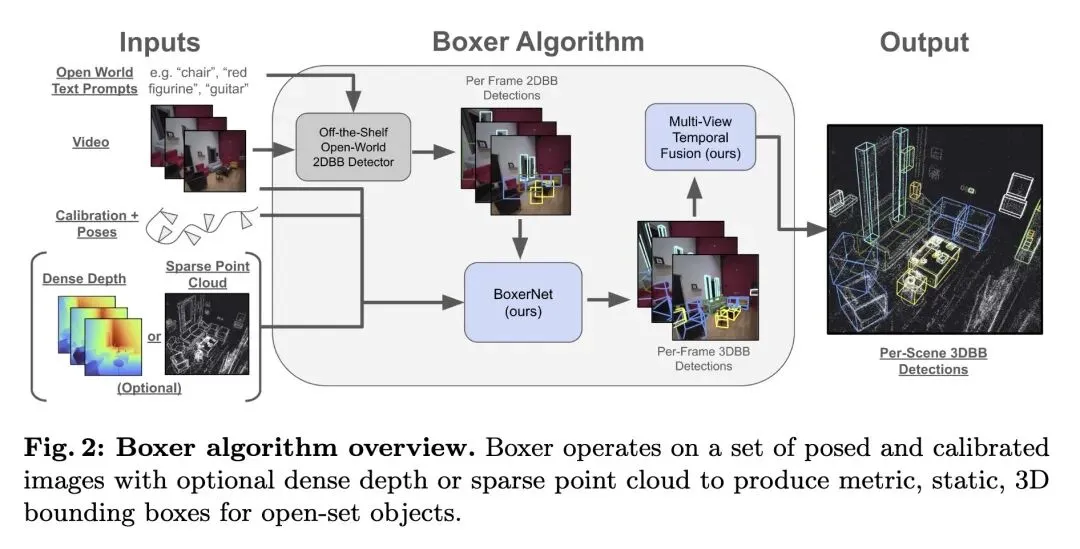
3、[CV] Boxer: Robust Lifting of Open-World 2D Bounding Boxes to 3D
D DeTone, T Shen, F Zhang, L Ma…[Meta Reality Labs Research]
Boxer:开放世界2D边界框向3D空间的稳健升维
要点:
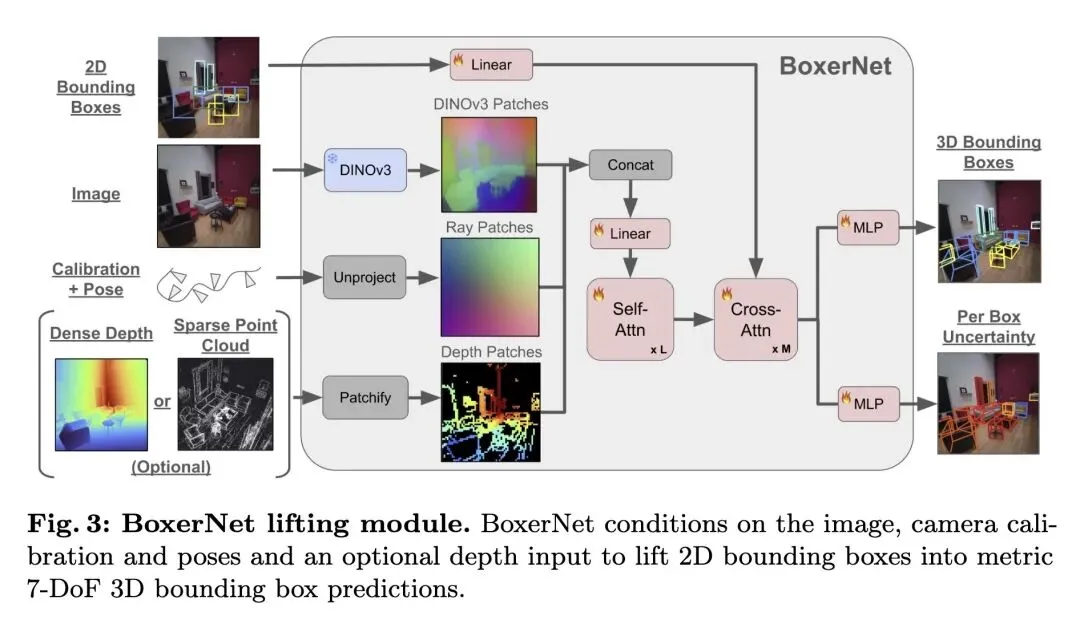
通过将2D开放世界检测(语义)与3D度量提升(几何)解耦,利用网络级规模的2D视觉语言模型,巧妙绕过了3D标注数据极度匮乏的瓶颈。 提出了 Boxer 框架,能够从2D候选框、带位姿的图像以及可选的深度提示中,估计全局的、静态的7自由度(7-DoF)3D边界框。 关于深度表示的高信息熵创新:用极其简单的“中值深度图块编码(Median depth patch encoding)”取代了复杂的稠密深度网络。这一优雅的设计使 BoxerNet 实现了模态无关性,既能完美处理稠密深度图(RGB-D),也能无缝处理极度稀疏的点云(SLAM/SfM)。 反直觉的数据增强策略:在训练时,如果简单地将3D真实框投影到2D平面,会因为遮挡产生非常松散且不准确的2D框。Boxer 创新性地使用 SAM(Segment Anything)对这些投影框进行“收紧”,使得训练数据与推理时真实的2D检测器行为完美对齐。 关于置信度排序的高信息熵发现:为3D预测引入了任意偶然不确定性(Aleatoric uncertainty)头。将该3D不确定性得分与上游2D检测器的置信度得分取平均,相比于单独使用任何一个得分,能大幅提升候选框的排序质量和最终的 mAP。 在一个包含122万个独立3DBB的超大规模混合数据集上进行训练,涵盖了各种相机模型(针孔、鱼眼)和设备(Project Aria, Quest, iPad, Kinect)。 性能以压倒性优势超越了 CuTR 等 SOTA 方法,特别是在仅有稀疏深度的第一人称视角数据集上(如在 NymeriaPlus 上 mAP 为 0.532 对比 0.010),在稠密深度数据集 CA-1M 上也取得了显著提升(0.412 对比 0.250)。 包含一个多视角时序融合模块,能够对单帧检测结果进行聚类,巧妙解决长方体的90度旋转对称性歧义,并通过 3D NMS 构建全局一致的场景表示。
主旨: 本文旨在解决真实世界中开放词汇(Open-world)3D目标定位的难题。由于3D标注数据极其稀缺且传感器模态(稠密深度vs稀疏点云、针孔vs鱼眼)碎片化严重,传统的端到端3D检测器难以泛化。文章提出了 Boxer 算法,通过“先2D检测,后3D提升”的两阶段策略,将强大的2D大模型语义能力与专为几何设计的 Transformer 网络结合,实现了高精度、跨设备、跨深度模态的3D边界框估计。
创新:
语义与几何的彻底解耦:不依赖3D数据学习开放世界物体的语义概念,而是完全信任现成的2D检测器(如 DETIC, OWLv2),让3D网络(BoxerNet)专职负责几何维度的“提升”。 中值深度图块编码:通过计算每个图像Patch内投影点的深度中值,统一了稀疏点云和稠密深度图的特征表示,使模型具备极强的模态适应性。 SAM辅助的2D框收紧增强:解决了3D到2D重投影产生“假性大框”的痛点,利用SAM的掩码能力在训练阶段生成紧凑的2D边界框作为输入。 融合不确定性的联合评分机制:将预测出的3D任意不确定性(Aleatoric uncertainty)与2D置信度结合,解决了解耦架构中前后端置信度不匹配导致的排序问题。
贡献:
提出了一套完整的、用于开放世界 3D 边界框检测的算法框架 Boxer 及核心提升网络 BoxerNet。 整合并清洗了一个极具规模的训练集(包含122万个独特 3DBB 和 4210万个视角),证明了在多设备、多相机畸变模型下联合训练的可行性。 在多个主流基准测试(NymeriaPlus, CA-1M, Aria Digital Twin)中刷新了 SOTA 性能,特别是在极具挑战性的第一人称(Egocentric)和稀疏点云场景下取得了质的飞跃。 开源了代码和模型,提供了一套包含离线(O(N^2))和在线流式(O(MP))处理的 3D 多视角融合追踪后处理方案。
提升:
稀疏深度/第一人称场景:在 NymeriaPlus 数据集上,相比此前的 SOTA 方法 CuTR,mAP 实现了惊人的飞跃(从 0.010 飙升至 0.532),证明了其在非结构化 SLAM 数据上的鲁棒性。 稠密深度场景:在 CA-1M 数据集上,mAP 从 0.250 提升至 0.412。 单目 RGB 场景:即便完全不提供深度输入,仅依靠图像特征,BoxerNet 的表现也远超 3D-MOOD 和 CuTR。
不足:
动态物体处理能力缺失:模型和融合系统强依赖“静态世界”假设,无法处理正在移动的物体(如人手持的物品)。 非长方体物体的局限性:对于电线、植物藤蔓等高度非结构化、不适合用 3DBB 表达的物体,检测效果不佳。 强依赖上游组件:如果上游的 2D 开放世界检测器漏检或误检,Boxer 无法纠正;同时,系统必须依赖外部提供的准确相机位姿(Pose)和重力方向输入。
心得:
“解耦”是跨越数据鸿沟的利器:在 3D 标注数据量远落后于 2D 数据的现状下,试图用 3D 数据端到端地教会模型认识“开放世界的万物”是低效的。Boxer 极具启发性地展示了:把语义识别交给已经在十亿级网页数据上训练好的 2D VLM,把纯粹的几何映射留给 3D 小网络,是目前实现 Open-world 3D 认知的最佳工程捷径。 “大道至简”的多模态融合:在处理稀疏点云时,很多研究倾向于使用复杂的 PointNet 或体素化网络。而 Boxer 仅仅通过计算一个 2D Patch 内的“中值深度”,就完美兼容了稠密和极度稀疏的深度输入,并顺畅地输入到 Transformer 中。这提醒我们,在设计特征表示时,简单的统计量聚合往往比复杂的架构设计更具鲁棒性。 不确定性不仅用于回归,更是排序的黄金指标:论文在解耦架构中遇到了一个经典问题——2D 检测器觉得自己找得很准(2D Score 高),但 3D 提升网络可能因为视角不好根本无法重建(3D 质量差)。Boxer 通过预测 Aleatoric uncertainty 并与 2D score 取平均,巧妙解决了 Pipeline 架构中不同模块间“置信度孤岛”的问题,这对于所有两阶段检测系统的设计都有极高的参考价值。
一句话总结:Boxer 创新性地将 2D 语义检测与 3D 几何提升彻底解耦,通过引入中值深度图块编码与 3D 不确定性评分,成功实现从单目图像或稀疏点云向高精度 3D 边界框的跨越,在极具挑战的第一人称和开放世界 3D 定位任务上实现了颠覆性的性能突破。
Detecting and localizing objects in space is a fundamental computer vision problem. While much progress has been made to solve 2D object detection, 3D object localization is much less explored and far from solved, especially for open-world categories. To address this research challenge, we propose Boxer, an algorithm to estimate static 3D bounding boxes (3DBBs) from 2D open-vocabulary object detections, posed images and optional depth either represented as a sparse point cloud or dense depth. At its core is BoxerNet, a transformer-based network which lifts 2D bounding box (2DBB) proposals into 3D, followed by multi-view fusion and geometric filtering to produce globally consistent de-duplicated 3DBBs in metric world space. Boxer leverages the power of existing 2DBB detection algorithms (e.g., DETIC [54], OWLv2 [31], SAM3 [8]) to localize objects in 2D. This allows the main BoxerNet model to focus on lifting to 3D rather than detecting, ultimately reducing the demand for costly annotated 3DBB training data. Extending the CuTR [21] formulation, we incorporate an aleatoric uncertainty for robust regression, a median depth patch encoding to support sparse depth inputs, and large-scale training with over 1.2 million unique 3DBBs. BoxerNet outperforms state-of-theart baselines in open-world 3DBB lifting, including CuTR in egocentric settings without dense depth (0.532 vs. 0.010 mAP) and on CA-1M with dense depth available (0.412 vs. 0.250 mAP).
https://arxiv.org/abs/2604.05212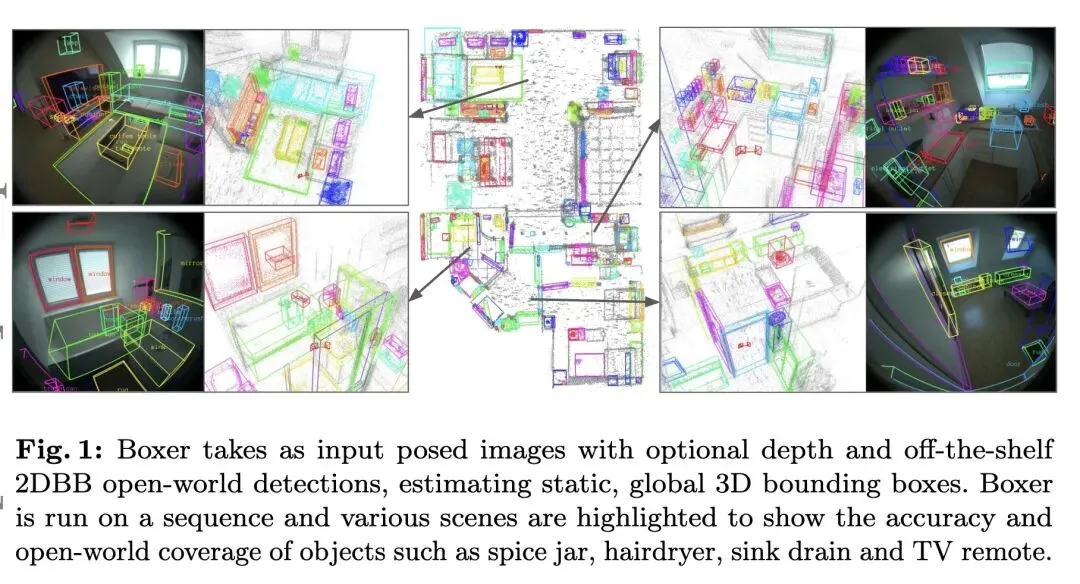
4、[LG] Exponential quantum advantage in processing massive classical data
H Zhao, A Zlokapa, H Neven, R Babbush…[California Institute of Technolog & MIT & Google Quantum AI]
处理海量经典数据时的指数级量子优势
要点:
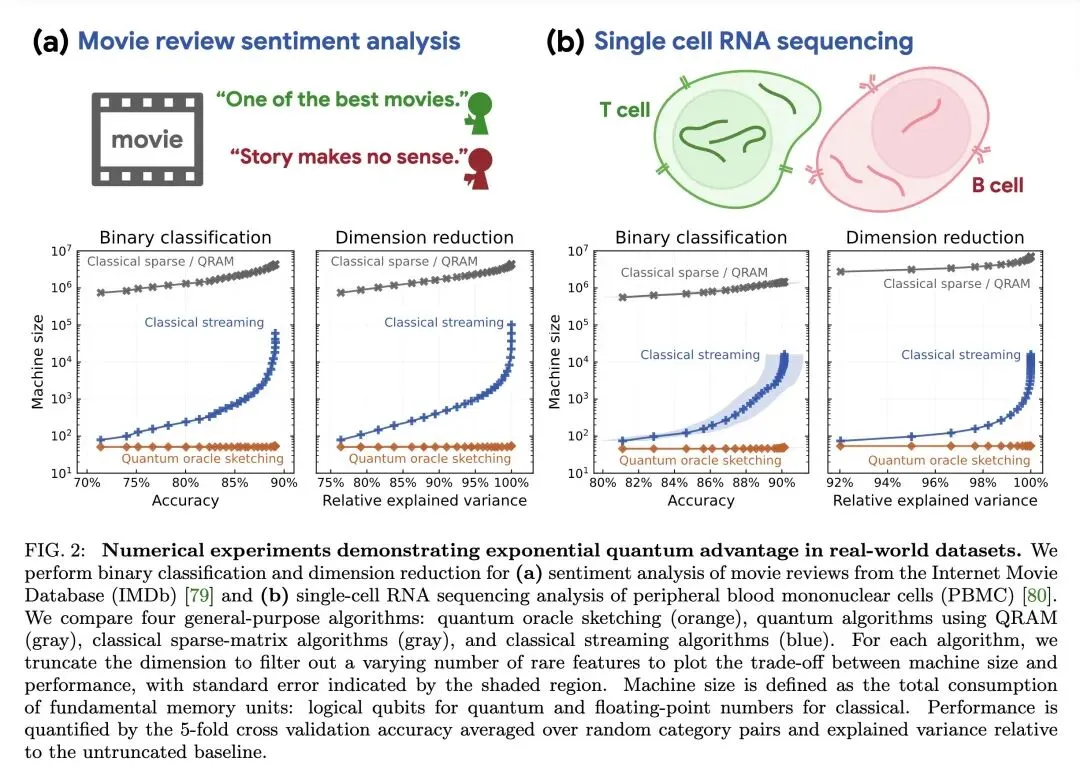
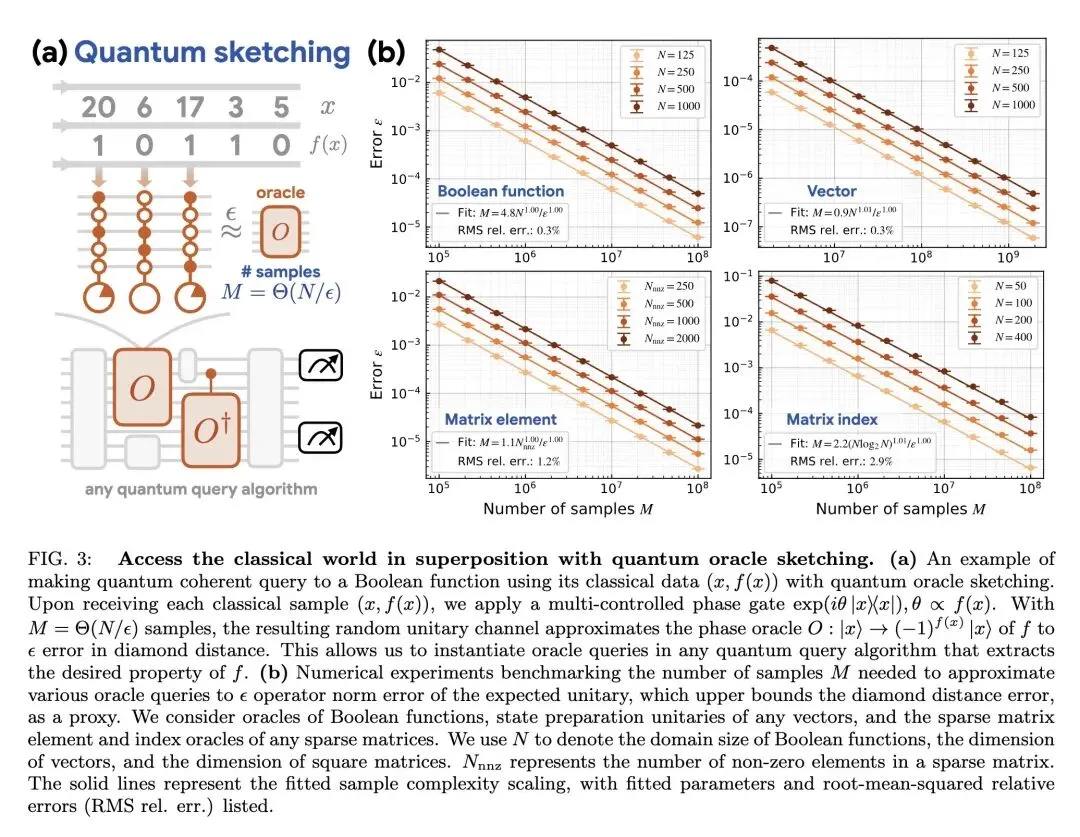
挑战了量子机器学习(QML)领域长期的怀疑态度,无条件地证明了小型量子计算机在处理海量经典数据时,相比经典机器能够实现指数级的内存(空间)优势。 引入了 量子预言机略图 (Quantum Oracle Sketching),这是一种突破性的数据加载算法,能够即时(on the fly)处理流式经典数据以构建相干量子查询,彻底绕过了极其困难的量子随机存取存储器(QRAM)瓶颈。 关于退相干的反直觉发现:理论上,将随机、嘈杂的经典数据持续注入量子计算机极易导致快速退相干,需要 个样本才能维持相干性(这会抹杀任何量子优势)。作者通过在相互正交的子空间上使用多控相位门,成功避开了这个“退相干陷阱”,将样本复杂度降低到了最优的 。 关于读取瓶颈(霍列沃界)的高信息熵突破:霍列沃界(Holevo's Bound)指出 个量子比特最多只能提取 个经典比特,这曾被认为是 QML 的致命伤。本文提出了 干扰测量经典影子 (Interferometric Classical Shadows) 技术,能从量子态中提取高度浓缩且保留符号结构的模型(如SVM权重向量),该模型可用于预测无限多的测试样本,在不违背物理定律的前提下巧妙绕过了读取瓶颈。 无条件证明:所证明的指数级空间优势仅依赖于量子力学(叠加态)的正确性,而不依赖于任何未证明的计算复杂性猜想。即使 ,或者赋予经典机器无限的计算时间,这种优势依然存在。 在真实世界数据集(单细胞RNA测序、IMDb电影评论)上的经验测试表明,使用不到 60 个逻辑量子比特,即可实现 到 数量级的机器内存缩减。
主旨: 本文旨在解决量子机器学习在处理海量经典数据时面临的“数据加载(QRAM)”和“结果读取”两大根本性瓶颈。通过提出量子预言机略图算法,文章证明了即使在没有指数级庞大内存的情况下,拥有几十个逻辑比特的小型量子计算机也能在流式处理经典数据(如线性系统求解、分类、降维)时,展现出经典计算机无法匹敌的指数级空间(内存)优势。
创新:
量子预言机略图 (Quantum Oracle Sketching):放弃了将整个数据集存储在 QRAM 中的传统思路,改为接收到经典数据样本时即时施加微小的量子旋转操作,用后即焚,通过累积相干性构建量子预言机。 干扰测量经典影子 (Interferometric Classical Shadows):结合阿达马测试(Hadamard test)与经典影子层析成像技术,创新性地解决了高效读取包含关键“符号(正负)结构”信息的难题,从而生成紧凑的经典机器学习预测模型。 动态去随机化与学习XOR引理:在证明经典算法下限时,开发了一种新的去随机化技术和学习XOR引理,证明了经典算法在内存受限时不仅无法完成任务,而且在面对动态演化的数据时需要超多项式级的样本量。
贡献:
理论贡献:无条件地证明了在经典数据处理中存在指数级的量子空间优势,且该优势不依赖于任何计算机科学的复杂性猜想,将量子优势的证明建立在了纯粹的量子力学物理基础之上。 算法贡献:提出了一套完整的端到端量子机器学习框架,彻底移除了 QML 走向实用的最大路障——QRAM 依赖,使量子计算机处理经典大数据成为可能。 实践贡献:在单细胞 RNA 测序和自然语言情感分析等真实商业/科学数据集上进行了数值验证,证明仅需不到 60 个逻辑比特即可实现惊人的内存缩减。
提升:
内存消耗(空间复杂度):在执行支持向量机(SVM)和主成分分析(PCA)等任务时,将经典流式算法或稀疏矩阵算法所需的线性或多项式级内存,指数级压缩至多项式对数级 。 实际应用规模:在 IMDb 和 PBMC 数据集实验中,相比于经典算法,机器规模(浮点数/量子比特数)实现了 4 到 6 个数量级(倍)的缩减。
不足:
时间复杂度依然受限:虽然空间复杂度实现了指数级降低,但算法仍需要 的时间来逐步加载数据样本。尽管作者指出可以通过并行化改善,但实际的挂钟时间(Wall-clock time)可能较长。 对容错量子的依赖:算法描述依赖于几十个“逻辑量子比特(Logical Qubits)”,这意味着它属于容错量子计算(FTQC)时代的算法,目前的含噪中型量子(NISQ)设备因门保真度不够,尚无法直接运行此算法。 硬件验证暂缺:目前的实证数据是通过 JAX 框架在经典硬件上进行的大规模数值模拟,尚未在真实的量子处理器上进行物理层面的端到端验证。
心得:
用“模型提取”重塑霍列沃界(Holevo's Bound)的绝境:一直以来,人们认为从量子态中提取经典信息效率太低,无法用于输出大规模数据处理结果。这篇文章极其聪明地跳出了“还原数据”的思维定势,转而“提取高维模型的浓缩特征(如SVM的超平面法向量)”。这启发我们,在 AI 与量子的结合中,量子计算机的定位应当是“极高维空间的特征压缩器”,而非数据存储器。 将计算机算法提升为基础物理检验:最令我震撼的是该论文的“无条件证明”。以往的量子优势(如Shor算法)一旦证明 ,神话就会破灭。但本文的证明不依赖复杂性理论,只依赖量子力学的叠加态原理。这意味着,未来在硬件上运行这个机器学习算法,本身就是对量子力学在高复杂性前沿边界的一次伟大物理实验检验。 在“内存墙”时代,空间优势大于时间优势:现代 AI 发展正遭遇严重的“内存墙(Memory Wall)”——模型和数据集的膨胀速度远超显存的增长。量子计算过去总在追求“算得更快(时间优势)”,但这篇文章精准切中了时代的痛点,指出了“存得更小(空间优势)”才是量子机器学习在经典大数据时代真正的杀手级应用。
一句话总结:本文通过提出“量子预言机略图”技术,彻底清除了量子机器学习对 QRAM 的依赖,并在不依赖任何计算猜想的前提下,无条件证明了不到 60 个逻辑量子比特的小型量子计算机能在真实海量经典数据处理中(如SVM和PCA),实现比经典计算机高出数万倍的指数级内存压缩优势。
Broadly applicable quantum advantage, particularly in classical data processing and machine learning, has been a fundamental open problem. In this work, we prove that a small quantum computer of polylogarithmic size can perform large-scale classification and dimension reduction on massive classical data by processing samples on the fly, whereas any classical machine achieving the same prediction performance requires exponentially larger size. Furthermore, classical machines that are exponentially larger yet below the required size need superpolynomially more samples and time. We validate these quantum advantages in real-world applications, including single-cell RNA sequencing and movie review sentiment analysis, demonstrating four to six orders of magnitude reduction in size with fewer than 60 logical qubits. These quantum advantages are enabled by quantum oracle sketching, an algorithm for accessing the classical world in quantum superposition using only random classical data samples. Combined with classical shadows, our algorithm circumvents the data loading and readout bottleneck to construct succinct classical models from massive classical data, a task provably impossible for any classical machine that is not exponentially larger than the quantum machine. These quantum advantages persist even when classical machines are granted unlimited time or if BPP=BQP, and rely only on the correctness of quantum mechanics. Together, our results establish machine learning on classical data as a broad and natural domain of quantum advantage and a fundamental test of quantum mechanics at the complexity frontier.
https://arxiv.org/abs/2604.07639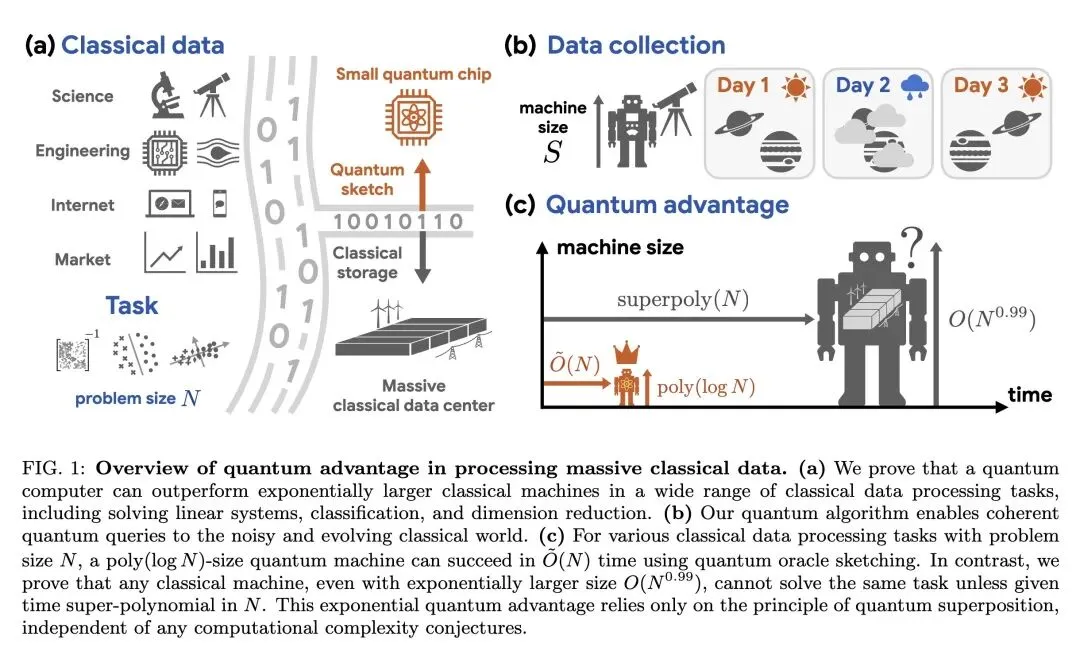
5、[AI] AI Assistance Reduces Persistence and Hurts Independent Performance
G Liu, B Christian, T Dumbalska, M A. Bakker…[CMU & University of Oxford]
AI辅助会降低任务坚持度并损害独立表现
要点:
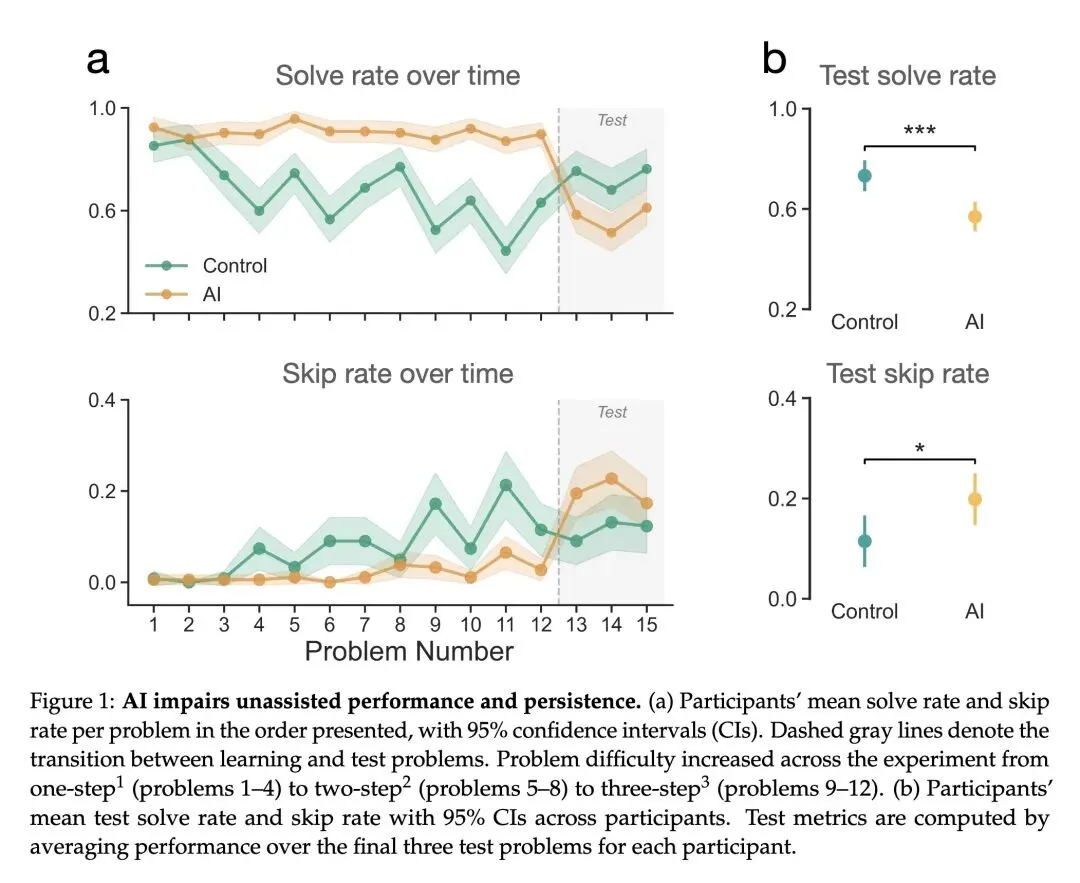
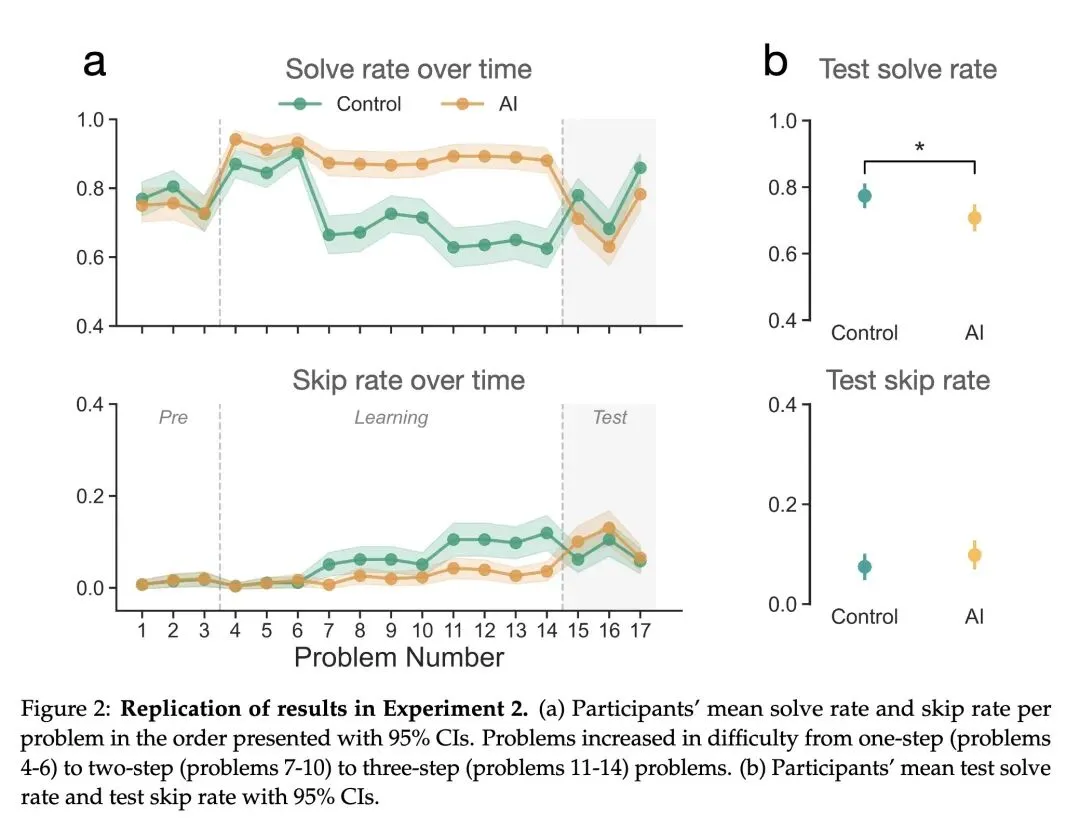
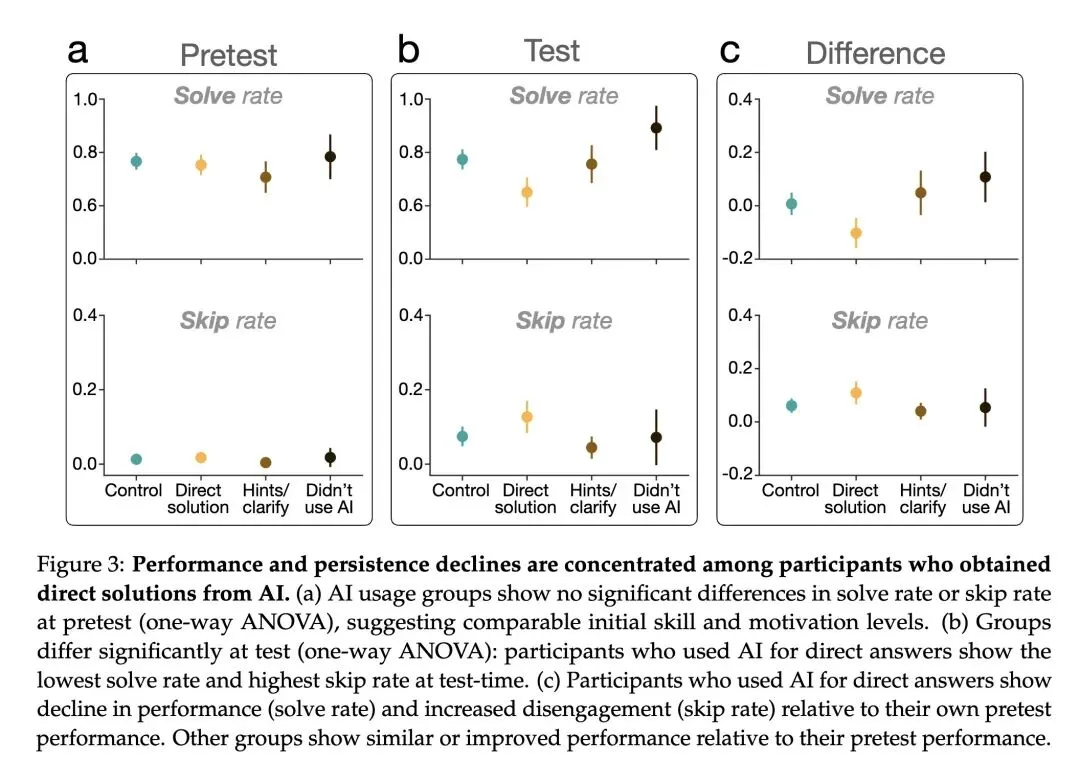
本文提供了大规模的因果证据,表明人工智能辅助会损害人类独立解决问题的能力,并降低在面对困难时的坚持度(persistence)。 当前的AI助手是“目光短浅的合作者”,仅针对即时帮助进行优化;这与人类导师形成鲜明对比,人类导师会在提供帮助与培养学生自主性(脚手架式教学)之间寻找平衡。 反直觉发现: 仅仅与AI助手进行非常短暂的互动(10-15分钟),就会导致随后在无辅助情况下的表现显著下降,并且更容易中途放弃(跳过问题)。 这种负面影响几乎完全集中在那些利用AI直接获取答案的用户身上,而不是那些利用AI获取提示或澄清的用户。直接索要答案的用户在测试中的表现甚至低于他们自己的前测基线水平。 关于泛化能力的高信息熵发现: 这种技能退化和坚持度的丧失并不局限于数学(分数计算),而是会泛化到诸如阅读理解等本质上完全不同的认知任务中。 论文假设了导致坚持度降低的两种机制:1)AI改变了人们对“努力程度”的参照点(使得无辅助的工作在对比之下显得过于困难,类似于享乐适应);2)绕过“富有成效的挣扎”阻碍了用户对自身能力建立准确的元认知校准(metacognitive calibration)。 警告“温水煮青蛙”效应:AI引发的渐进式认知技能退化和动机丧失可能会随着时间的推移不断积累,最终取代人类的基本能力。
主旨: 本文旨在探讨当前优化为“提供即时且完整答案”的AI助手对人类认知能力的长期影响。通过一系列随机对照试验(RCTs),研究揭示了即使是短期的AI协助,也会不仅降低人们独立解决问题的能力,更严重的是会削弱人们面对困难时的坚持度和动力,强调了AI系统设计需要从短期任务完成转向促进人类长期能力发展的迫切性。
创新:
提供了大规模(N=1222)的因果证据(Causality),而非仅仅是相关性分析或小样本访谈,首次在实验中严格控制变量以验证AI导致的认知退化。 创新性地将“跳过率(skip rate)”作为衡量用户坚持度(persistence)和动机的核心定量指标,并证明了AI会显著提升这一比率。 揭示了不仅是任务表现(performance)受损,连面对挑战时的心理倾向(disposition to struggle)也会被AI迅速改变。
贡献:
实证贡献:通过跨越数学推理(分数计算)和批判性思维(阅读理解)三个实验,证实了AI导致“技能退化与坚持度下降”的现象具有跨领域的普遍性。 机制洞察:将影响细化至用户行为层面,发现该负面效应主要集中在“直接索要答案”的用户群体中,而将AI作为“提示/澄清”工具的用户则受影响较小。 设计范式启示:为AI对齐(AI Alignment)提出了新的维度——不仅仅要避免提供有害信息,还要避免“过度帮助(over-helping)”,呼吁开发具有“脚手架(scaffolding)”教育功能的AI系统。
提升:
论文主要讨论的是人类能力的下降而非提升: 在有AI辅助的阶段,用户的短期解题率确实得到了提升。 但是,一旦撤去AI(无辅助测试),之前使用过AI(特别是直接要答案)的用户的解题率显著低于从未使用过AI的控制组(例如实验1中:57% vs 73%)。 用户的放弃率(skip rate)在失去AI后显著上升(例如实验1中:20% vs 11%)。
不足:
实验时长较短:目前的实验仅观察了10-15分钟短期互动的即时影响,缺乏长达数月或数年的纵向(longitudinal)追踪研究来验证这些效应是否会永久固化或随时间消退。 未区分特定AI交互策略的长期效果:虽然横向分析发现“要提示”比“要答案”好,但并未在RCT中直接控制并强制用户只能使用特定策略(如苏格拉底式提问),以验证是否有某种特定的AI交互方式能完全消除负面影响。 生态效度(Ecological validity):实验是在众包平台(Prolific)上进行的有偿任务,可能无法完全模拟现实世界中学生学习或员工工作时真实的内在动机和压力。
心得:
“过度帮助”也是一种伤害:这篇论文极具启发性地指出,当前AI的“无限服从和即时满足”实际上剥夺了人类“富有成效的挣扎(productive struggle)”的权利。在教育和认知发展中,挫折是建立元认知(了解自己懂什么、不懂什么)的必经之路。 “享乐适应”在认知领域的体现:习惯了AI在几秒内给出完美答案后,人类大脑会对“解决问题所需的时间和精力”产生错误的锚定。一旦失去AI,正常的思考过程就会主观上感觉变得极其痛苦和不可忍受,这解释了为什么放弃率会飙升。 对AI产品设计的深刻警示:未来的教育AI或生产力AI,不能仅仅评估其“回答准确率”或“用户满意度”。一个真正有益的AI,必须学会像人类优秀导师一样“适时闭嘴”或“只给线索”,AI的评价指标应该包含“用户离开AI后的独立表现”。
一句话总结: 通过大规模因果实验证实,仅仅十几分钟的AI协助就会导致人类在失去AI后独立解决问题的能力显著下降,并大幅削弱面对困难时的坚持度;这警示我们,一味追求即时满足和提供直接答案的AI系统,正像“温水煮青蛙”一样逐渐剥夺人类的认知韧性和独立思考能力。
People often optimize for long-term goals in collaboration: A mentor or companion doesn’t just answer questions, but also scaffolds learning, tracks progress, and prioritizes the other person’s growth over immediate results. In contrast, current AI systems are fundamentally short-sighted collaborators – optimized for providing instant and complete responses, without ever saying no (unless for safety reasons). What are the consequences of this dynamic? Here, through a series of randomized controlled trials on human-AI interactions (N = 1, 222), we provide causal evidence for two key consequences of AI assistance: reduced persistence and impairment of unassisted performance. Across a variety of tasks, including mathematical reasoning and reading comprehension, we find that although AI assistance improves performance in the short-term, people perform significantly worse without AI and are more likely to give up. Notably, these effects emerge after only brief interactions with AI (∼10 minutes). These findings are particularly concerning because persistence is foundational to skill acquisition and is one of the strongest predictors of long-term learning. We posit that persistence is reduced because AI conditions people to expect immediate answers, thereby denying them the experience of working through challenges on their own. These results suggest the need for AI model development to prioritize scaffolding long-term competence alongside immediate task completion. Project Page: https://ai-project-website.github.io/AI-assistance-reduces-persistence/ Public Significance Statement The rapid rise of AI chatbots promises immediate and effective help with reasoning-intensive tasks such as studying, writing, coding, and brainstorming. But what happens to users’ own abilities when the AI is not available? In a series of large-scale human experiments involving arithmetic and reading comprehension, we find that AI assistance improves immediate performance, but it comes at a heavy cognitive cost: after just ∼ 10 minutes of AI-assisted problem-solving, people who lost access to the AI performed worse and gave up more frequently than those who never used it. These findings raise urgent questions about the cumulative effects of daily AI use on human persistence and reasoning. We caution that if such effects accumulate with sustained AI use, current AI systems – optimized only for short-term helpfulness – risk eroding the very human capabilities they are meant to support.
https://arxiv.org/abs/2604.04721