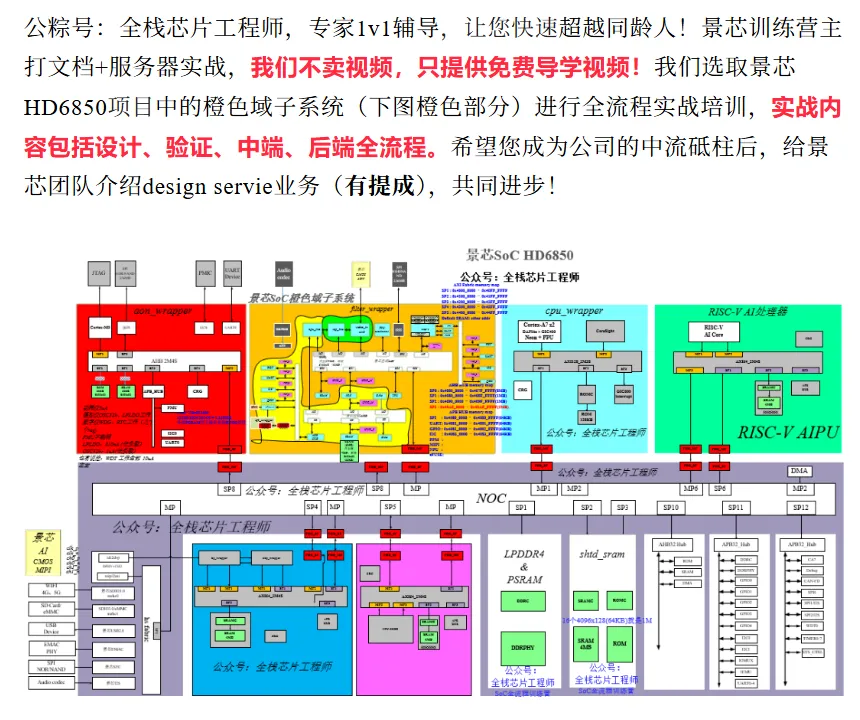
夜雨聆风
夜雨聆风边缘AI这几年火得一塌糊涂。以前跑个神经网络还得往云端送数据,现在好了,直接在单片机里塞个NPU,本地就能搞定人脸识别、语音唤醒、异常检测这些活儿。今天咱们就聊聊市面上那些真正带独立AI加速单元的MCU,不是那种只靠向量指令软优化的"伪AI芯片"。

先说说意法半导体的STM32N6,这货可能是目前最强的AI单片机之一。Cortex-M55核心配上Helium矢量扩展,关键是那颗叫Neural-ART的NPU,算力干到了600 GOPS。什么概念?在MCU上跑个实时人脸检测或者多路音频分离完全不在话下。官方给的数据是,相比纯CPU推理,速度快了600倍。而且ST的生态确实做得好,STM32Cube.AI工具链成熟,模型转换相对省心。
再看乐鑫的ESP32-P4,国产芯片里的一匹黑马。双核RISC-V跑到360MHz,独立NPU提供256 GOPS的INT8算力。最香的是它带了完整的视觉接口——ISP、JPEG编解码、MIPI CSI摄像头接口全都有,还集成了以太网。做那种带摄像头的小设备,比如智能门铃、人脸识别终端,用这个特别省BOM成本。另外他们家的ESP32-S31也挺有意思,虽然算力没P4那么猛,但胜在性价比高,语音唤醒、轻量级视觉任务完全够用。

Alif Semiconductor这个名字可能有些朋友不太熟,但这家的Ensemble系列绝对是宝藏。特别是E4/E6/E8这几款新出的,直接把Arm最新的Ethos-U85 NPU塞了进去,200+ GOPS的算力不说,还支持Transformer网络硬件加速。这意味着啥?以前只能在手机或者服务器上跑的小型语言模型(SLM),现在可以在纽扣电池供电的设备上本地运行了。他们官方演示的案例特别酷:一个视觉提示的小语言模型,能根据看到的东西给小朋友编故事,功耗才36mW。而且这芯片自带Cortex-A32应用处理器,能跑Linux,属于MCU和MPU的混血儿。
新唐的M55M1走的是务实路线,Cortex-M55配Ethos-U55,110 GOPS的算力,主打语音和异常检测。价格应该会比较友好,适合那些对成本敏感的工业监测设备。

瑞萨的RA8系列用了Cortex-M85核心,配合自家的DRP-AI硬件加速器。瑞萨在工业控制领域底子厚,这颗芯片也是冲着实时控制+轻量CNN去的,工厂里的预测性维护、视觉质检用它挺合适。
TI的MSPM0G5187属于另一个极端,主打超低功耗。Cortex-M0+配TinyEngine NPU,虽然只有2.56 GOPS,但人家功耗低啊,做那种电池供电的传感器节点,偶尔跑跑AI推理检测下异常,能用好几年不换电池。
再说几个值得关注的。Nordic的nRF54系列也集成了Axon NPU,配合他们家的无线连接优势,做可穿戴设备的边缘AI很有意思。Ambiq的Apollo系列则是把低功耗玩到极致,亚阈值功率优化技术(SPOT)加持,Apollo510据说推理能效比传统MCU高了300倍,智能手表、健康监测设备用这类芯片再合适不过。

国产厂商里,嘉楠的K230不得不提。自研KPU架构,1 TOPS的算力,双核RISC-V跑到1GHz。这芯片在开源社区挺火,价格香,资料全,学生党做视觉AI项目首选。地平线那边虽然主打的是更高阶的边缘SoC,但旭日3轻量版其实也可以在一些MCU级项目里用上,毕竟5 TOPS的算力做复杂模型推理要从容得多。
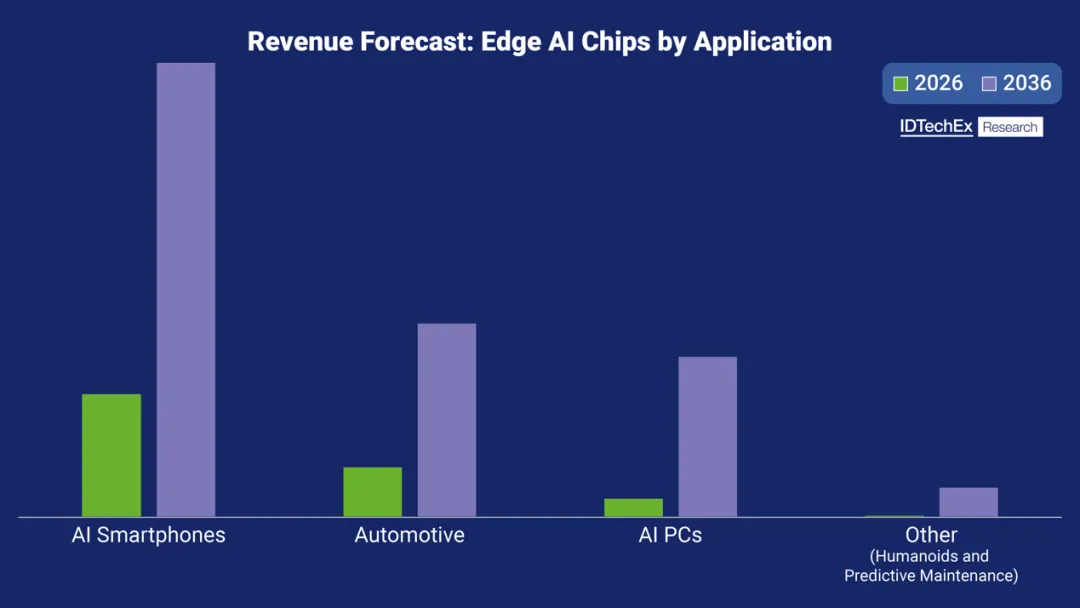
选型建议这块,其实主要看场景。要做高性能视觉AI,STM32N6和ESP32-P4是首选;想要跑Transformer或者生成式AI,Alif的E系列是目前为数不多的选择;超低功耗场景看看TI的MSPM0或者Ambiq;工业级稳定性要求高的话,瑞萨和NXP更稳;预算紧张又要玩AI,嘉楠K230和新唐M55M1值得考虑。
这几年边缘AI芯片的进化速度确实快,从最初几GOPS到现在几百GOPS,甚至能跑大语言模型。对于嵌入式工程师来说,这意味着以前不敢想的本地智能功能,现在用一颗单片机就能搞定了。不用折腾复杂的Linux板子,不用考虑云端延迟,就在MCU上把AI跑起来,这才是真正的边缘智能。