 夜雨聆风
夜雨聆风从无状态到持久化:OpenClaw 4.5 的 Task Flow 到底解决了什么问题
OpenClaw 2026.4.5 发布了不少改动,但真正值得单独拿出来讲的只有一件事:Task Flow 复活了,而且这次回来的方式,和之前完全不同。它不是恢复了一个旧功能,而是补上了三块之前从未到位的基础设施——持久化流状态、编排层与插件层的解耦、以及一组可在命令行直接操作的运维原语。后台编排第一次具备了"跑挂了能查、能恢复、能独立于插件层操作"的能力。
但基础设施就绪不等于生产就绪。这个区别,是理解这次发布真实价值的关键。
发布了什么:Task Flow 复活,以及围绕它的三层变化
这次 Task Flow 相关的改动由三个 PR 构成,缺一不可:
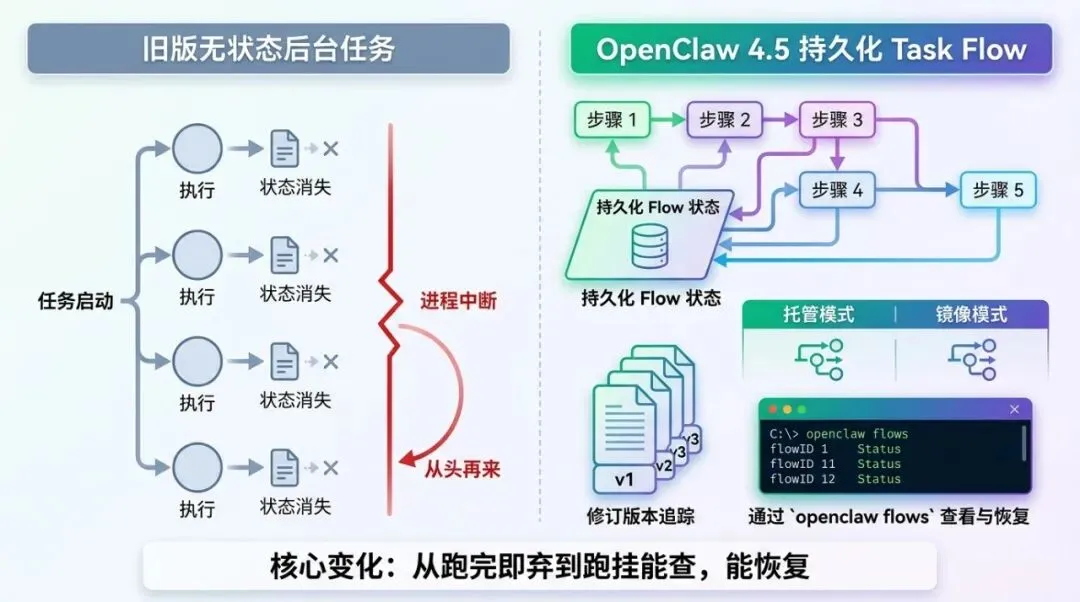
第一层,核心基座恢复(#58930)。Task Flow 重新作为独立子系统回归,带来了 managed 与 mirrored 两种同步模式、durable flow state 与 revision tracking(持久化流状态与修订追踪),以及 openclaw flows 这组检查和恢复原语。这意味着后台编排的每一步状态变迁都有迹可循,流程中断后不再是黑箱。
第二层,managed 子任务生成与 sticky cancel intent(#59610)。外部编排器现在可以向一个正在运行的 Task Flow 发出取消意图,Flow 不会粗暴中断,而是停止调度新的子任务,等待已经在跑的子任务自然结束,最终让父 Flow 优雅收敛到 cancelled 状态。这是编排系统最基本的生命周期管理能力,之前 OpenClaw 没有。
第三层,api.runtime.taskFlow 插件接缝(#59622)。插件和受信编排层可以直接从宿主上下文创建和驱动 Task Flow,不需要每次调用都传递 owner 标识。这条接缝的意义在于:插件开发者终于可以把 Task Flow 当作一个可编程的后台编排原语来用,而不是只能被动等待系统调度。
三条合在一起,才构成"持久化编排可运维"这个判断的事实基础。单拿任何一条出来,都只是局部改进。
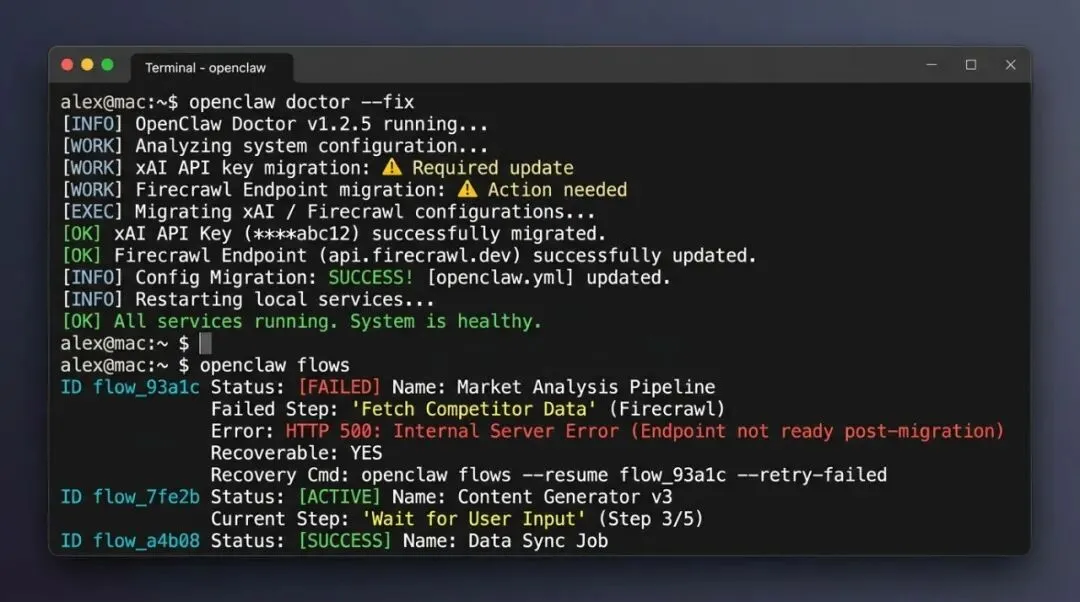
同时需要注意本版的另一条线:两个 breaking change。xAI 的 x_search 配置路径从 tools.web.x_search.* 迁移到了 plugins.entries.xai.config.xSearch.*,Firecrawl 的 web_fetch 配置从 tools.web.fetch.firecrawl.* 迁移到了 plugins.entries.firecrawl.config.webFetch.*。旧路径不会自动生效,必须通过 openclaw doctor --fix 手动迁移。如果你正在用这两个工具,升级后第一件事就是跑这条命令,否则工具调用会静默失败。
真正重要的变化:从"跑完即弃"到"跑挂能查、能恢复、能独立运维"
理解这次发布的价值,需要两个对比维度。
第一个维度:状态持久化 vs 无状态。在 4.5 之前(包括 Task Flow 缺席的时期),OpenClaw 的后台任务本质上是"跑完即弃"的。一个多步任务启动后,中间状态不持久化,进程中断就意味着从头再来,你甚至无法确认它跑到了哪一步。4.5 引入的 durable flow state 和 revision tracking 改变了这个局面:每一步的状态变迁被记录,流程中断后可以通过 openclaw flows 查看当前状态,尝试从断点恢复。
第二个维度:编排层与插件层解耦 vs 混合。旧版的编排逻辑和插件代码是混在一起的。要调试一个后台任务为什么卡住,你得钻进插件内部去看;要手动干预一个失控的流程,你得理解插件的实现细节。4.5 把 Task Flow 作为独立基座暴露出来,插件通过 api.runtime.taskFlow 接缝驱动编排,编排状态可以独立于插件进行检查和操作。这不是架构洁癖,而是运维的基本前提——你不应该需要读懂每个插件的源码才能知道后台任务跑到了哪里。
用一个现实场景来说明这两个维度的组合效果:假设你用 OpenClaw 编排一条多步数据处理流水线——抓取、清洗、入库,三个步骤分别由不同的插件或工具完成。在旧版中,如果清洗步骤因为上游数据格式异常而失败,整条流水线沉默中断,你只能从头跑。4.5 的持久化状态让你可以通过 openclaw flows 查到清洗步骤失败的具体状态;sticky cancel intent 让你可以阻止入库步骤继续调度;managed 子任务机制让你只需要重跑清洗这一个分支,而不是整条流水线。
这是从"能跑"到"能运维"的区别。听起来不性感,但任何在生产环境跑过后台任务的人都知道,"能跑"和"跑挂了能救"之间隔着一道深沟。
适合谁、不适合谁:别把基础设施就绪当成生产就绪
适合现在就关注的场景有两类:
一是已经在用 OpenClaw 做多步后台任务、长期苦于中断不可恢复的团队。Task Flow 的持久化状态和 openclaw flows 检查原语,直接解决了"跑挂了只能从头来"这个痛点。如果你之前为此写过大量的状态记录和断点恢复逻辑,现在可以评估是否用原生能力替代。
二是正在考虑用 OpenClaw 替代简单的 cron + 脚本编排的开发者。Task Flow 的 managed 子任务和 cancel intent 提供了比裸脚本更好的生命周期管理——至少你不用自己写进程信号处理和状态文件了。
不适合或不急的场景同样清楚:
纯前端对话场景、不涉及后台编排的用户,Task Flow 对你没有直接影响,这次发布和你的日常使用基本无关。
已经在用 Temporal、Prefect 等成熟工作流引擎跑复杂编排的团队,需要冷静评估。Task Flow 目前没有条件分支、没有可配置的重试策略、没有可视化界面、没有 DAG 定义能力。它提供的是最基础的持久化状态追踪和生命周期管理,和专业编排引擎之间的能力差距不是一个版本能补上的。
这里必须说清楚一个边界:别高估这个版本的即战力。Task Flow 复活是基座层的补全,不是开箱即用的工作流产品。openclaw flows 目前是 CLI 检查和恢复原语,不是 dashboard;managed 与 mirrored 两种同步模式的选择依据和调优文档尚不充分;插件侧的 taskFlow 接缝刚刚开放,围绕它的编排模式和最佳实践还没有形成。它解决的是"能不能做"的问题,不是"好不好用"的问题。把基础设施层的能力补全直接等同于"OpenClaw 可以替代工作流引擎了",是对这次发布最常见的误读。
现在该怎么动:升级顺序、旧用法迁移和最小试用路径
不管你是否关心 Task Flow,升级到 4.5 后第一步都一样:跑 openclaw doctor --fix。xAI x_search 和 Firecrawl web_fetch 的配置路径迁移是 breaking change,旧配置路径已经失效。这一步和 Task Flow 完全无关,但不做会直接导致现有的搜索和网页抓取工具调用失败。优先级最高,没有商量余地。
第二步,如果你有后台编排需求,先用 openclaw flows 观察。不要急着把现有编排迁移到 Task Flow 上,先在新建的小规模任务上试用,观察持久化状态追踪的实际效果,理解 managed 模式(Task Flow 自己管理子任务生命周期)和 mirrored 模式(外部系统的状态映射到 Task Flow)的区别。这两种模式的选择会直接影响你的编排架构,在文档补全之前,小范围试探比全量迁移安全得多。
第三步,如果你是插件开发者,值得关注两个新接缝的组合。api.runtime.taskFlow(#59622)让插件可以直接创建和驱动持久化流程;before_agent_reply 钩子(#20067)让插件可以在 LLM 回复前插入合成响应。两个能力组合起来,可以实现一种之前做不到的异步交互模式:插件拦截用户请求,启动一个后台 Task Flow,立即返回一条占位回复("正在处理,稍后更新"),等 Flow 完成后再更新对话。这对需要长时间运行的后台任务场景很有价值。
不急着动的部分:Android assistant 入口(#59596)、Feishu Drive 评论流(#58497)、Matrix m.mentions 规范化(#59323)、provider replay hook(#59143)等改动,除非你正好在对应平台做开发,否则不影响核心工作流,可以等后续版本稳定后再关注。
收束到一句话:这个版本最值得试的,是用 openclaw flows 在小范围任务上观察持久化状态追踪的实际效果;最该立刻做的,是 openclaw doctor --fix 迁移旧插件配置;最不用急的,是把 Temporal 或 Prefect 上跑着的成熟编排替换成 Task Flow。
Task Flow 的复活是 OpenClaw 后台编排能力从零到一的关键一步。但从一到能用,还需要文档、生态和工具链跟上来。现在是观察和小范围试探的窗口,不是全量迁移的时机。
