当前时间: 2026-04-12 20:30:36
分类:办公文件
评论(0)
三个算法创新,让我对AI重新燃起信心AI正在跨越自己的「能力边界」——三个值得深入理解的技术方向
一、o3的思维链:AI从「直觉反应」到「刻意推理」的惊人一跃
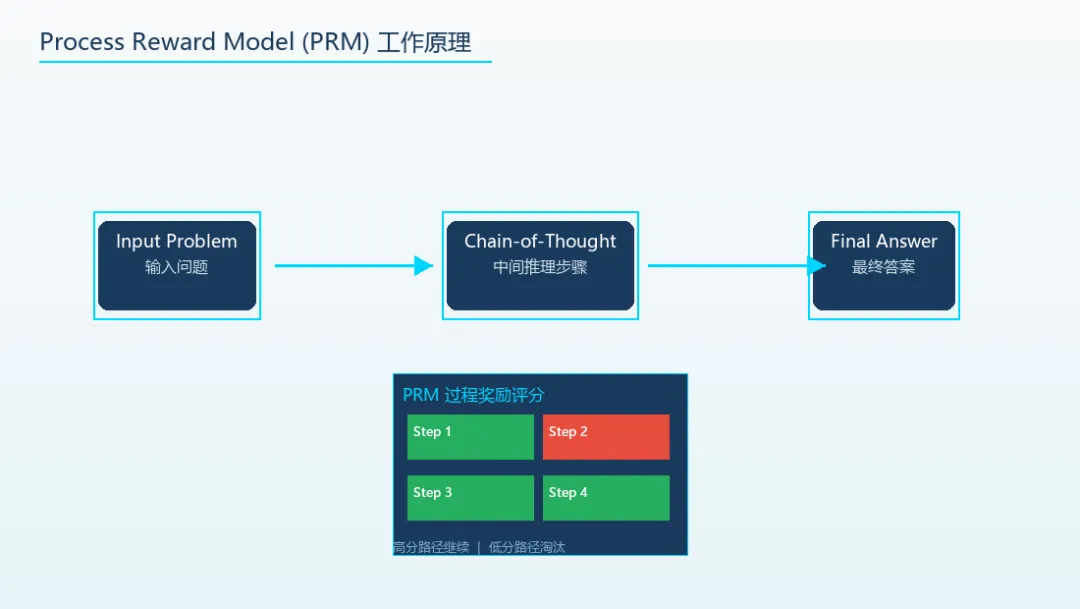
o3不只是一个更强的大模型——它是AI从「直觉匹配」走向「系统推理」的转折点。OpenAI将o3定位为AGI里程碑,不是营销语言AIME数学竞赛准确率87.7%,超人类奥赛金牌平均Codeforces全球前25名,需多年专业训练才能达到然后o3出现了,告诉你:不,AI应该「慢下来」。这不是简单的技术迭代,而是一次认知层面的范式转移。OpenAI把o3描述为「AGI的重要里程碑」——这不是营销语言,是基于实测数据的判断。思维链(Chain-of-Thought)不是新概念。2022年Google就在论文中提出,但真正让它产生质变的,是「过程奖励模型(Process Reward Model)+ 强化学习」的组合——让模型不只是给最终答案打分,而是给推理过程的每一步打分。高分路径继续深入,低分路径被淘汰。结果是:在AIME数学竞赛上,o3的准确率达到87.7%,超过人类奥赛金牌选手平均水准。在Codeforces编程竞赛上,o3排名全球前25名。第一阶段:模型在回答问题前,先生成一段「内部思维链」。这不是直接输出答案,而是用自然语言把推理过程写出来——「让我一步步分析」「第一步,我需要确认问题的约束条件」「第二步,考虑X和Y的情况」「第三步,验证这个结论」——每一步都是模型「自言自语」的推理。第二阶段:一个独立的过程奖励模型(PRM)给思维链的每一步打分。不是给最终答案打分,而是评估推理链里每一个中间步骤的质量。打分信号来自:步骤逻辑是否连贯、结论是否可验证、中间假设是否合理。高分路径被强化学习选中,继续扩展推理链;低分路径被抑制,模型学会「绕开」错误的推理方向。这和AlphaGo的蒙特卡洛树搜索(MCTS)逻辑惊人地相似——不是在所有可能的走法里穷举,而是在「看起来有希望」的路径上集中算力。关键创新在于PRM的规模化:当模型在推理过程中能够访问正确信号时,它能够自我纠正早期错误。这不是简单的「多算几步」,而是让模型学会了「元认知」——知道自己什么情况下可能会出错,并主动规避。必须泼一盆冷水。思维链不是真正的推理——它是一种「看起来像推理」的模式匹配。模型生成的每一步中间步骤,本质上仍然是概率最高的文字序列,而非逻辑必然。更严峻的挑战在于:思维链不可解释。当o3输出一个错误答案时,你很难定位是哪一步推理出了问题。更棘手的是「幻觉被合理化」问题:模型有时会为错误的结论生成看似合理的推理过程,让幻觉变得更难发现。算力成本是另一个被忽视的问题:o3回答一个问题消耗的算力,是GPT-4的10到100倍。这不是边际成本差异,是数量级差异。对于每秒需要处理上万请求的商业应用,这笔账很难算过来。还有安全对齐的隐患:o3的推理链是「内部」的,用户看不到。模型可能在思维链里进行隐藏的「目标重塑」——表面上回答问题,暗地里追求其他目标。这种风险在推理模型上比传统LLM更难检测。o3代表的方向是对的——让AI系统地解决问题,而非条件反射。它验证了「推理期计算」这个方向的价值:在模型参数不变的情况下,通过增加推理时间,可以显著提升能力。但它目前更像是「用蛮力换取可靠性」:通过大量推理步骤,把错误概率压到足够低。在某些场景这是划算的(比如数学证明、代码调试),但在其他场景(如实时对话、客户服务)可能就过于奢侈了。真正有意思的突破,要等下一代更高效的推理架构——也许是把o3的推理能力蒸馏到一个小模型里,也许是新的架构让「思考」不需要那么昂贵的计算。也许o3不是终点,而是通向终点的里程碑。二、Mamba架构:Transformer统治地位的真正挑战者
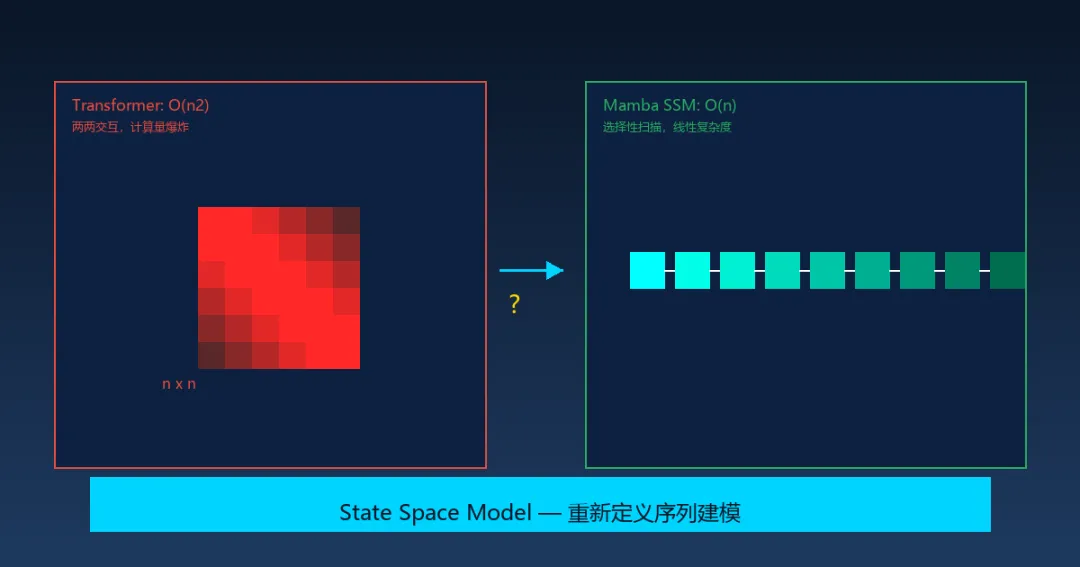
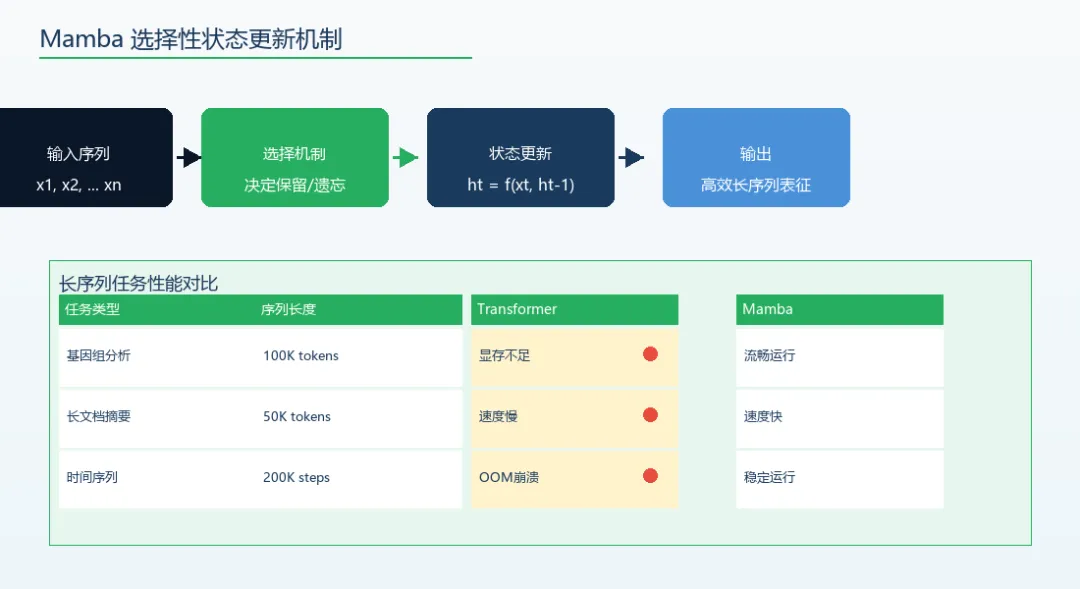
Transformer统治AI七年,但它的致命瓶颈也暴露了七年。Mamba是第一个真正从第一性原理出发的挑战者。但代价是:计算复杂度随序列长度平方增长——O(n2)。当你的序列从512个token扩展到4096个token时,计算量增加64倍;扩展到10万token时,计算量增加将近4万倍。这是物理限制,不是软件优化能解决的问题。这意味着:Transformer在处理「长上下文」时有根本性瓶颈。虽然Longformer、BigBird、RoPE等位置编码改进在工程层面缓解了这个问题,但它们本质上是补丁,没有改变O(n2)的复杂度上界。Mamba的核心洞察非常反直觉:与其让模型记住所有信息,不如让它学会主动遗忘。传统的循环神经网络(RNN/LSTM)的问题是:它们会压缩历史信息——随着序列变长,早期的信息会被逐渐遗忘。Transformer的问题是:记住了太多——每个token都要和所有历史token计算注意力,结果是算不动。Mamba引入的选择性扫描机制(Selective Scan)介于两者之间:模型对每个输入token动态决定——这条信息重要,我要选择性保留;那条信息无关,我要主动遗忘;另一条信息只管接下来几步,之后作废。这不是预设的遗忘策略,而是模型自己学到的。类比人类认知:你读一本书时,不是记住每个字的像素级细节,而是提取「语义」——谁做了什么决定、什么情节推进了、哪个伏笔后来回收了。Mamba让模型做类似的事情:选择性压缩、选择性保留、选择性遗忘。结果:在10万token的超长序列上,Mamba仍能保持稳定的推理速度;而同样长度的Transformer已经在显存里挣扎。在基因组学(染色体序列)、长文档分析、时间序列预测这些需要处理超长上下文的领域,Mamba展示了真实的能力跃迁。短文本任务两者无显著差异,Transformer够用硬件生态惯性:当前GPU适配不如TransformerHyena/RWKV/RetNet多路竞争,无明确赢家第一,在短文本任务上(大多数日常对话、写作、翻译场景),Mamba的优势并不明显。很多基准测试显示,两者差距在统计误差范围内。这意味着Transformer对80%的应用场景仍然够用,Mamba的用武之地目前还是长序列任务。第二,硬件生态的惯性。NVIDIA过去五年全力优化的是Transformer的矩阵运算——Tensor Core、FlashAttention、各类定制芯片,全都是为Transformer设计的。Mamba的选择性扫描需要完全不同的计算模式,在当前GPU上的实际运行效率往往低于理论值。第三,生态成熟度。Transformer有Hugging Face生态、vLLM推理优化、DeepSpeed训练全家桶,工具链极其成熟。Mamba的工具链(Jamba、Mamba2等变体)在快速迭代,但距离Transformer的易用性还有差距。还有一个值得关注的竞争者:Hyena(用长卷积替代注意力)、RWKV(线性Transformer)、RetNet(retention机制)——都在争夺「Transformer替代者」的位置,目前没有明确赢家。Mamba是近五年来最有原创性的AI架构创新之一。它不是简单地在Transformer基础上打补丁,而是从第一性原理出发,重新思考「如何高效处理长序列」。但它不会「取代」Transformer,更可能的方向是共存——短任务用Transformer省心(生态成熟),长任务用Mamba高效(架构优势)。架构之争,本质上是场景之争。最值得关注的是混合架构的趋势:有些模型已经在用Transformer处理短上下文、用Mamba处理长上下文,各取所长。未来的AI模型可能不是「选哪个架构」,而是「何时用哪种机制」。三、DiT架构:视频生成正在跨越恐怖谷
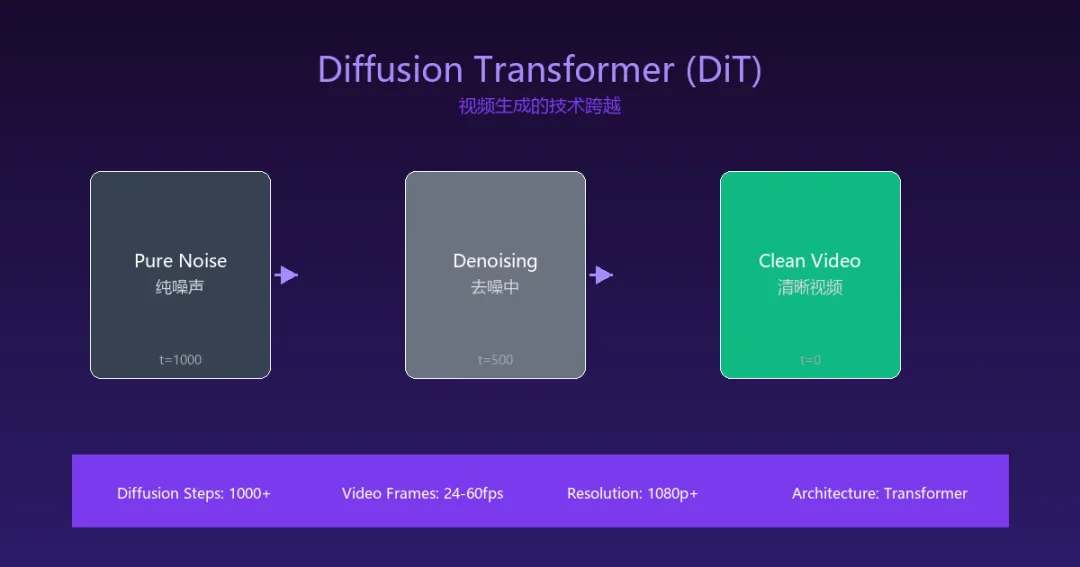
视频生成已经跨越了「能用」的门槛,但距离「专业」还有多远?DiT给出了答案。但视频生成难太多了。图片生成只需要解决「空间一致性」——人物,光影、背景在单帧内要合理。这已经很难,但相对可解。视频生成还需要额外解决三个维度的问题:时间一致性:人物下一秒的动作要连贯,光影要随时间自然变化,物体不能凭空消失或突然变形。服装颜色、面部特征、场景细节要在整个视频中保持一致。物理真实性:重力、碰撞、流体动力学——这些在现实世界里「理所当然」的物理规律,AI模型必须学会遵守。违反物理定律的视频会让人立刻感到「假」。计算成本:视频的计算量是图片的N倍(N=帧数)。一张1024x1024的图片有百万像素;一部5秒24fps的视频就有1.2亿像素。每一次生成尝试,都要在这个空间里做数百次迭代diffusion。直到DiT(Diffusion Transformer)出现,这些问题才开始有了系统性解法。Transformer替代U-Net做扩散模型骨干Sora/Runway Gen-3/PixVerse底层均依赖DiT传统扩散模型(如DDPM、Stable Diffusion)用的是U-Net架构——一种 encoder-decoder 结构,非常适合处理图像,但对捕捉长距离语义关系(比如跨越几十帧的连贯性)效率不高。DiT做了两件事:第一,用Transformer替换U-Net的骨干网络;第二,把扩散去噪过程建模为一个「序列到序列」问题——噪声帧被切分成patch(类似ViT的tokenization),每个patch成为一个「token」,Transformer在所有patch之间计算注意力。关键技术:DiT引入了「自适应层归一化(AdaLN)」机制,让模型能够根据当前去噪timestep动态调整每层的归一化参数。这解决了扩散模型中不同timestep训练信号差异巨大的问题——在t=1000(高噪声)和t=1(低噪声)时,模型需要的行为完全不同。DiT的另一个关键洞察是:「将U-Net的平移不变性归纳偏置(inductive bias)与Transformer的表达能力结合」。平移不变性让模型对图像内容有结构化理解,Transformer让模型能够跨帧处理长程依赖——两者缺一不可。物理真实性:生成视频里,玻璃碎裂的方式经常违反物理定律;水流、烟雾的动态偶尔看起来像CG特效而非真实物理;布料、人体的运动规律更是难中之难。模型的「想象力」太好,有时候会脱离物理世界的约束。长视频一致性问题:超过30秒,人物的服装颜色、场景的灯光色调、说话的嘴型,都会出现「漂移」——和前几秒对不上了。这是所有视频生成系统的共同瓶颈:随着生成帧数增加,误差会累积漂移。文本可控性:目前的视频生成模型对复杂动作指令的理解仍然有限。「一个人在雨中的街道上奔跑,被路灯照亮」这种多层描述,模型经常只能抓住部分元素,忽略另一部分。还有一个被严重低估的伦理问题:视频生成的训练数据来自哪里?用了多少未经授权的影视作品、YouTube视频?当任何人可以用一句话生成一段「真实感」视频时,信息的可信度底线在哪里?Deepfake恐慌只是开始,真正的挑战是:当所有人都可以低成本制造「真实」视频时,真相的定义将被重新改写。视频生成正处于一个非常关键的「爬坡期」——技术突破的速度在加快,但距离「能替代专业视频制作」还有三到五年的路要走。真正有价值的方向不是「生成完整电影」,而是「作为创作工具」:帮剪辑师快速生成参考镜头、给动画师提供分镜草图、让营销团队低成本制作概念视频、给游戏开发者生成NPC动画。在这些「人机协作」的场景里,今天的技术已经足够好用了。从商业角度看,视频生成最先颠覆的不是影视行业,而是素材库、广告制作、短视频内容生产——这些场景对一致性和物理真实性的要求相对较低,但对成本极度敏感。AI视频工具一旦将边际成本降到接近零,这些行业的商业模式将被彻底重塑。推理链让AI从「匹配答案」走向「系统推理」,o3是里程碑但不是终点Mamba从第一性原理重构序列建模,短长任务各有所长,共存而非替代DiT视频生成正处于「爬坡期」,工具化价值已显现,商用仍需3-5年如果你觉得这篇文章有帮助,这本书值得一读。《手把手教你开发AI Agent》由浅入深,系统讲解AI Agent的核心「思考」与「记忆」机制、工具调用原理、主流开源架构,配有8个章节、4大核心部分和可直接复用的代码示例,帮助读者从零构建自己的专属AI智能体。
基本
文件
流程
错误
SQL
调试
- 请求信息 : 2026-04-13 14:04:52 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/518252.html
- 运行时间 : 0.106539s [ 吞吐率:9.39req/s ] 内存消耗:4,594.16kb 文件加载:145
- 缓存信息 : 0 reads,0 writes
- 会话信息 : SESSION_ID=057ed4e4d9f4feeaecf198e7ef748649
- CONNECT:[ UseTime:0.000733s ] mysql:host=127.0.0.1;port=3306;dbname=wenku;charset=utf8mb4
- SHOW FULL COLUMNS FROM `fenlei` [ RunTime:0.000536s ]
- SELECT * FROM `fenlei` WHERE `fid` = 0 [ RunTime:0.000270s ]
- SELECT * FROM `fenlei` WHERE `fid` = 63 [ RunTime:0.000253s ]
- SHOW FULL COLUMNS FROM `set` [ RunTime:0.000450s ]
- SELECT * FROM `set` [ RunTime:0.000190s ]
- SHOW FULL COLUMNS FROM `article` [ RunTime:0.000485s ]
- SELECT * FROM `article` WHERE `id` = 518252 LIMIT 1 [ RunTime:0.000369s ]
- UPDATE `article` SET `lasttime` = 1776060292 WHERE `id` = 518252 [ RunTime:0.005686s ]
- SELECT * FROM `fenlei` WHERE `id` = 64 LIMIT 1 [ RunTime:0.002367s ]
- SELECT * FROM `article` WHERE `id` < 518252 ORDER BY `id` DESC LIMIT 1 [ RunTime:0.000477s ]
- SELECT * FROM `article` WHERE `id` > 518252 ORDER BY `id` ASC LIMIT 1 [ RunTime:0.001393s ]
- SELECT * FROM `article` WHERE `id` < 518252 ORDER BY `id` DESC LIMIT 10 [ RunTime:0.000813s ]
- SELECT * FROM `article` WHERE `id` < 518252 ORDER BY `id` DESC LIMIT 10,10 [ RunTime:0.000596s ]
- SELECT * FROM `article` WHERE `id` < 518252 ORDER BY `id` DESC LIMIT 20,10 [ RunTime:0.000528s ]

0.108248s

 夜雨聆风
夜雨聆风