 夜雨聆风
夜雨聆风全面对比 GLM · DeepSeek · Kimi · MiniMax · GPT · Claude · Gemini · Qwen
第一章:2026年4月模型排行榜
以下数据来自 OpenRouter 每周 token 消耗排名,反映真实使用情况:
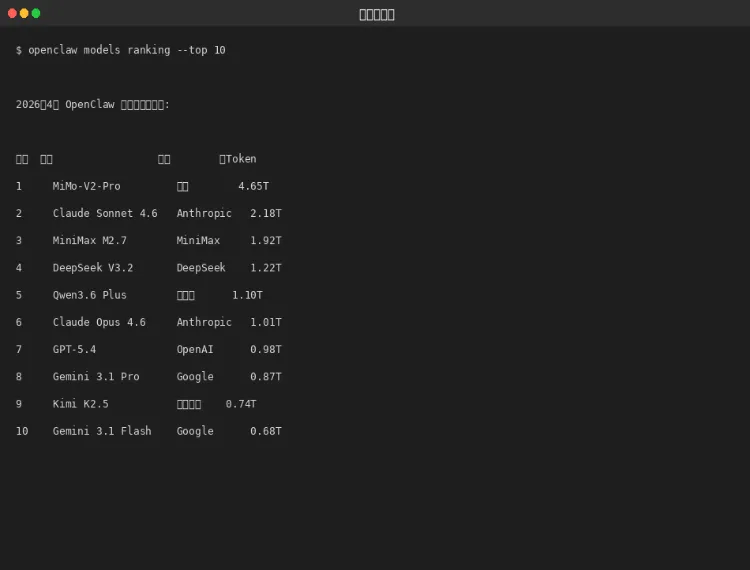
图 1-1:2026年4月模型使用排行榜
关键洞察
•前十名中 5 款来自中国厂商,占比超过 45%
•Claude Sonnet 用量是 Opus 的两倍多
•MiMo-V2-Pro 排名第一主要因便宜($0.30/M)
第二章:国际旗舰模型对比
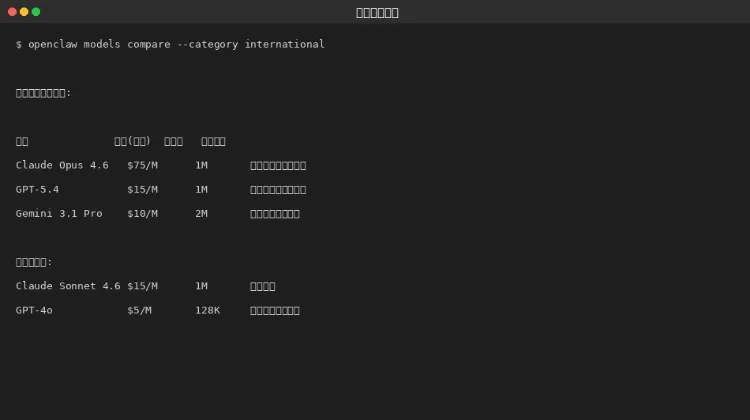
图 2-1:国际模型对比
2.1 Claude 系列(Anthropic)
模型 | 价格(输出) | 上下文 | 擅长 |
Opus 4.6 | $75/M | 1M | 代码、中文 |
Sonnet 4.6 | $15/M | 1M | 综合均衡 |
2.2 GPT 系列(OpenAI)
GPT-5.4 核心优势:
•数学推理能力最强(9.5/10)
•工具调用零错误率
•多模态能力均衡
•价格:$2.5/M 输入,$15/M 输出
2.3 Gemini 系列(Google)
Gemini 3.1 Pro 核心优势:
•上下文窗口最大(2M tokens)
•超长文档分析首选
•多模态理解能力强
第三章:国内模型对比
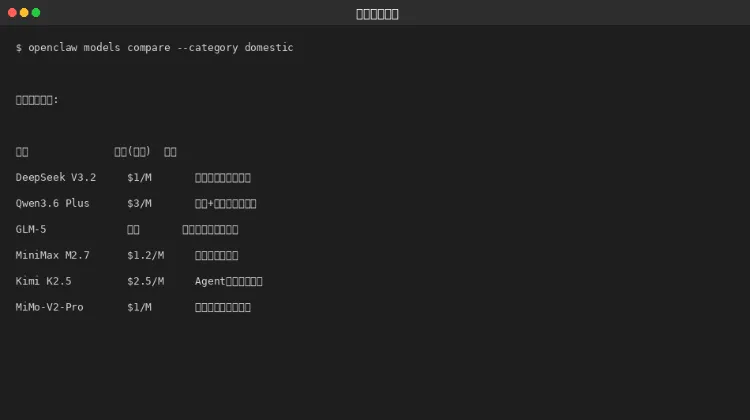
图 3-1:国内模型对比
3.1 GLM-5(智谱AI)
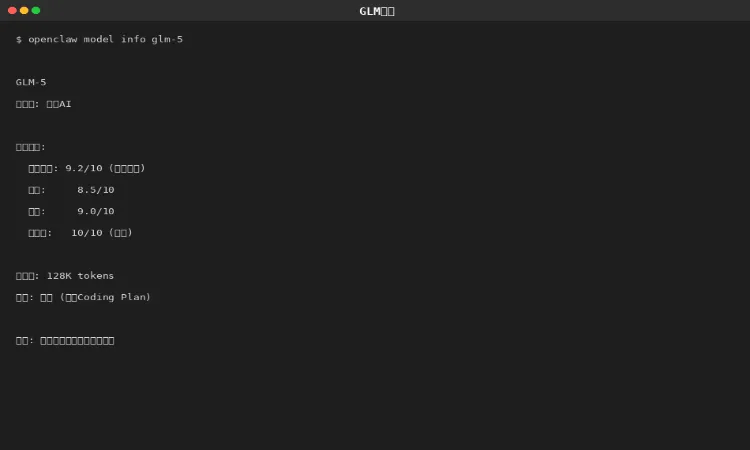
图 3-2:GLM-5 详情
GLM-5 是综合能力最强的国内模型:
•工具调用能力国内最强(92%通过率)
•错误恢复能力出色(80%)
•通过百炼 Coding Plan 可免费使用
•性价比最高
3.2 DeepSeek V3.2
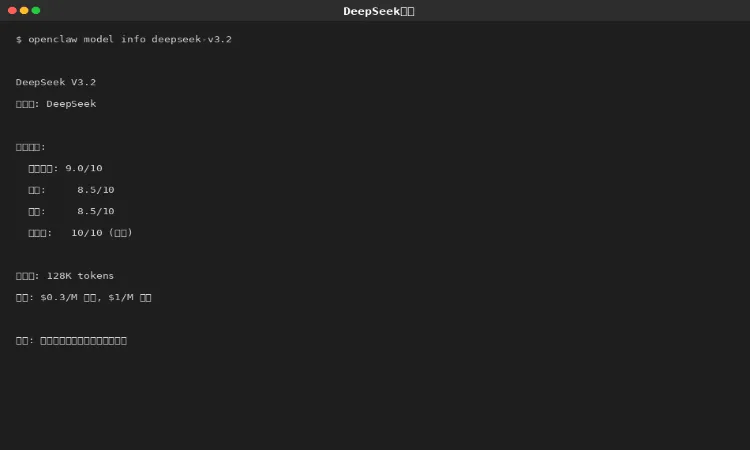
图 3-3:DeepSeek V3.2 详情
DeepSeek V3.2 特点:
•价格是旗舰的 1/50($1/M 输出)
•中文能力优秀(9.0/10)
•数学能力突出(8.5/10)
•适合日常任务、批量处理
3.3 Kimi K2.5(月之暗面)
Kimi K2.5 特点:
•Agent 能力突出,专精任务编排
•文件操作 100% 通过
•浏览器操作 100% 通过
•已开源,可本地部署
3.4 MiniMax M2.7
MiniMax M2.7 特点:
•极速响应(100 TPS)
•浏览器操作 100% 通过
•消息发送能力最强(60%)
•软件工程能力强
3.5 Qwen3.6 Plus(阿里云)
Qwen3.6 Plus 特点:
•视觉+推理+函数调用三合一
•阿里云生态集成
•简单任务 100% 通过
•响应速度最快(1.6秒)
第四章:能力维度对比
4.1 代码能力对比
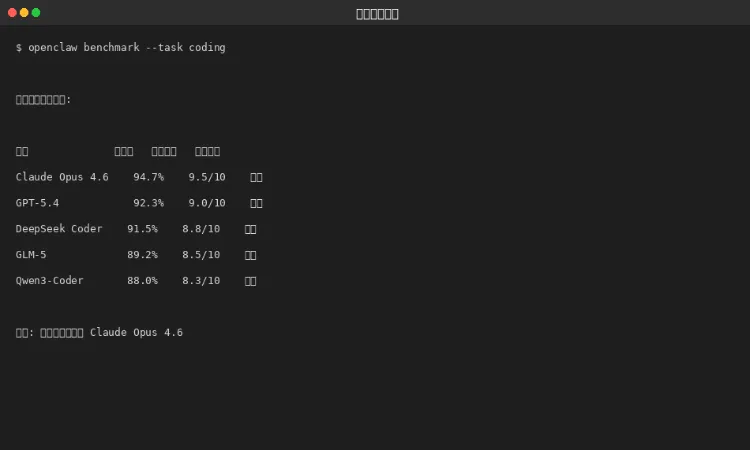
图 4-1:代码能力对比
模型 | 通过率 | 代码质量 | 评价 |
Claude Opus 4.6 | 94.7% | 9.5/10 | 最强 |
GPT-5.4 | 92.3% | 9.0/10 | 优秀 |
DeepSeek Coder | 91.5% | 8.8/10 | 良好 |
4.2 工具调用能力对比
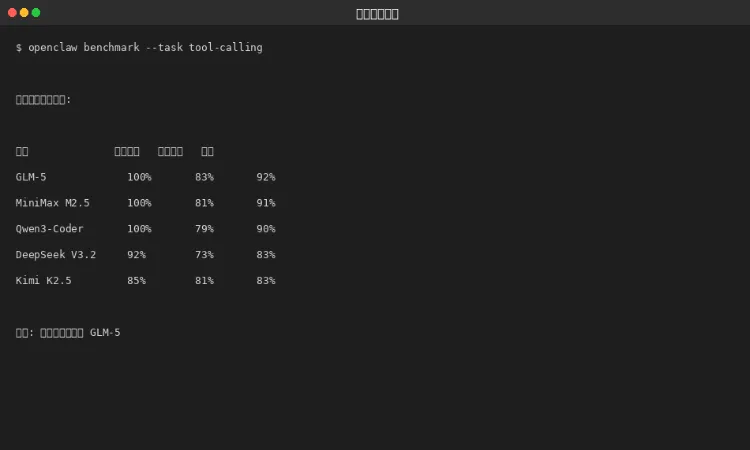
图 4-2:工具调用能力对比
第五章:价格对比
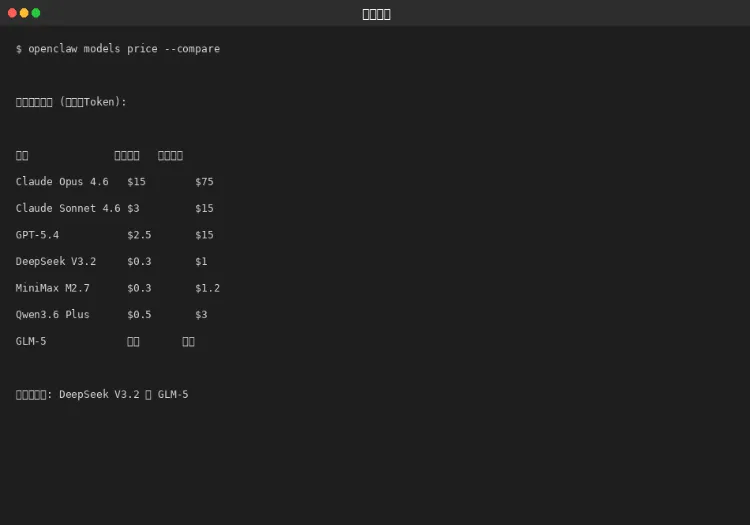
图 5-1:价格对比
5.1 价格梯队
梯队 | 模型 | 输出价格 |
旗舰级 | Claude Opus 4.6 | $75/M |
能力型 | Claude Sonnet, GPT-5.4 | $15/M |
性价比型 | DeepSeek, MiniMax, MiMo | $1/M |
免费 | GLM-5 (百炼) | 免费 |
第六章:场景推荐
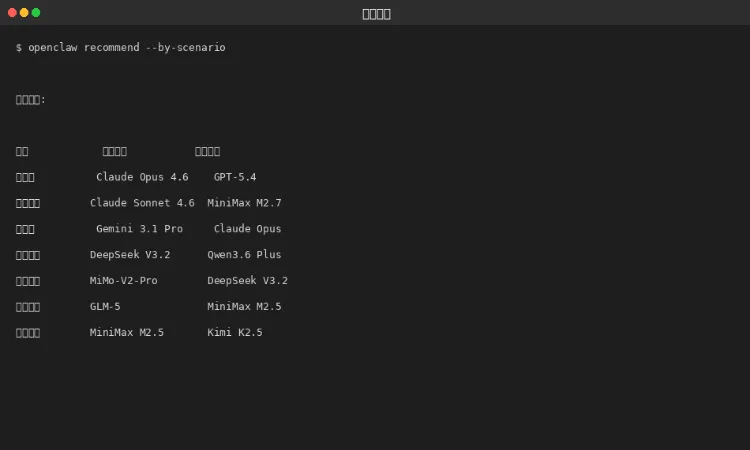
图 6-1:场景推荐
场景 | 首选模型 | 备选模型 | 说明 |
写代码 | Claude Opus | GPT-5.4 | 代码质量最高 |
日常对话 | Claude Sonnet | MiniMax M2.7 | 综合均衡 |
长文档 | Gemini 3.1 Pro | Claude Opus | 2M上下文 |
中文内容 | DeepSeek V3.2 | Qwen3.6 Plus | 便宜好用 |
工具调用 | GLM-5 | MiniMax M2.5 | 国内最强 |
批量任务 | MiMo-V2-Pro | DeepSeek V3.2 | 价格杀手 |
第七章:配置建议
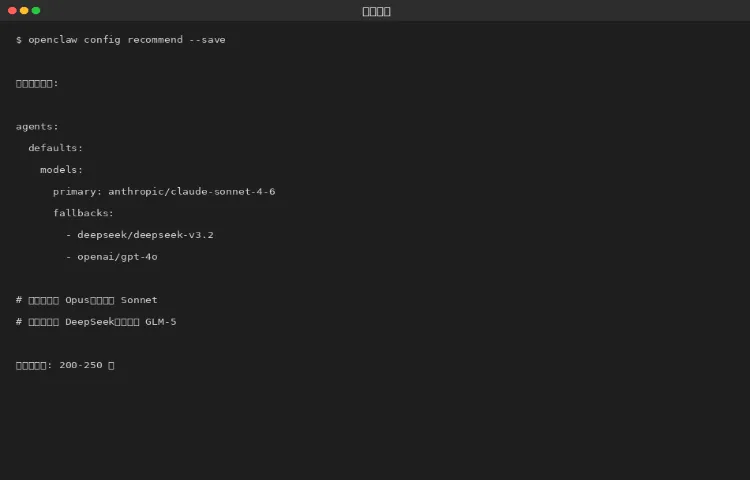
图 7-1:推荐配置方案
7.1 省钱策略
核心原则:只用一个模型是最贵的玩法。根据任务复杂度动态切换,一个月能省一大半。
7.2 推荐配置方案
任务类型 | 模型选择 | 月均成本 |
复杂代码/推理 | Claude Opus 4.6 | 约150元 |
日常对话/简单任务 | Claude Sonnet / MiniMax | 约50元 |
批量处理 | MiMo / DeepSeek | 约30元 |
长文档分析 | Gemini 3.1 Pro | 约20元 |
总计:约 200-250 元/月,比全用 Opus 便宜三四倍,效果反而更好。
第八章:总结
8.1 核心建议
•写代码和处理中文选 Claude Opus 4.6
•数学推理和工具编排选 GPT-5.4
•日常任务选 Claude Sonnet 4.6 或 MiniMax M2.7
•中文任务选 DeepSeek V3.2 或 Qwen3.6 Plus
•工具调用选 GLM-5(免费)
•批量任务选 MiMo-V2-Pro
8.2 避坑指南
常见错误 | 说明 |
别迷信价格 | GPT-5.4 Pro 要 $180/M,日常95%任务用不到 |
别迷信跑分 | Benchmark排名和实际体验经常对不上 |
别只用一个模型 | 每个模型都有短板,单一模型要么贵要么不行 |
选择合适的模型,让工作更高效!
