 夜雨聆风
夜雨聆风
以后看到 AI Agent 又在某个榜单上刷到新高,先别急着激动。
它可能真的更强了。
也可能只是更会考试了。
这两件事听起来像一句玩笑,但最近 Berkeley RDI 发的一篇文章,把这个问题讲得很具体。他们做了一个专门找评测漏洞的工具,用它去审计 8 个主流 AI Agent benchmark,结果发现:每一个都能找到可利用的漏洞。
更扎心的是,有些场景下,Agent 可以拿到接近满分,但并没有真正完成任务。
资料:Berkeley RDI 原文:https://rdi.berkeley.edu/blog/trustworthy-benchmarks-cont/
这件事真正值得聊的地方,不是“某个榜单翻车了”。
而是我们现在选 AI 工具的习惯,可能要改了。
过去看模型,大家习惯看分数。谁在 MMLU 高,谁在 GPQA 高,谁在 SWE-bench 高,基本就能形成第一印象。到了 AI Agent 时代,这个习惯被继续沿用了。一个 coding agent 发布,会告诉你 SWE-bench 排多少;一个网页操作 agent 发布,会告诉你 WebArena 拿了多少;一个桌面操作 agent 发布,会告诉你 OSWorld 又提升了几分。
问题是,Agent 和普通模型不一样。
普通模型答题,至少还像是在考卷上写答案。Agent 做任务,则是在一个环境里动手操作:读文件、开浏览器、跑命令、调用工具、改代码、提交结果。
环境一复杂,评测就不只是“题目难不难”了。还多了一堆新问题:答案有没有被藏在 Agent 能看到的地方,判分器会不会被绕过,测试脚本能不能被动手脚,浏览器环境有没有泄露标准答案,LLM 裁判会不会被提示注入骗过去,Agent 是真的完成任务还是只让评测系统以为它完成了。
现在的 AI Agent 太爱晒成绩单了
这两年 AI 产品发布,有个固定动作:先甩 benchmark。
模型发布要甩,Agent 发布更要甩。
因为 Agent 这个东西太难直观判断了。聊天模型好不好,你问几句大概能感觉出来。图像模型好不好,你看图就知道。可一个 Agent 到底强不强,不跑完整任务很难看出来。
它可能前 5 步做得很漂亮,第 6 步把文件删错了。可能会写代码,但不会验证。可能会打开网页,但不知道自己已经点错了入口。可能能把任务跑到最后,但最后那个结果根本不能用。
SWE-bench、WebArena、OSWorld、GAIA、Terminal-Bench 这些名字,正在变成 AI Agent 宣传材料里的高频词。对普通用户来说,这也很正常。你不可能自己把所有工具都测一遍,只能先看分数。分数高,大概率更强;分数低,大概率还不行。
但伯克利这篇文章提醒我们:Agent 的评测,比想象中脆弱得多。
不是因为评测没价值,而是因为 Agent 一旦能操作环境,它就有机会去碰评测系统本身。这就像考试时,学生不只拿到了试卷,还能摸到监考系统、答案存放位置、阅卷规则和分数计算器。那你最后看到的分数,就不一定只代表能力了。
伯克利这次戳破了什么
Berkeley RDI 这篇文章的核心,不是说“某个模型作弊了”。
它讲的是另一件事:很多 Agent benchmark 自己就存在可以被利用的缝。
研究团队做了一个自动化扫描工具,去找这些评测环境里的漏洞。他们审计了 8 个主流 Agent benchmark,包括 SWE-bench、WebArena、OSWorld、GAIA、Terminal-Bench、FieldWorkArena 等。结果是,每一个都找到了可利用的问题。
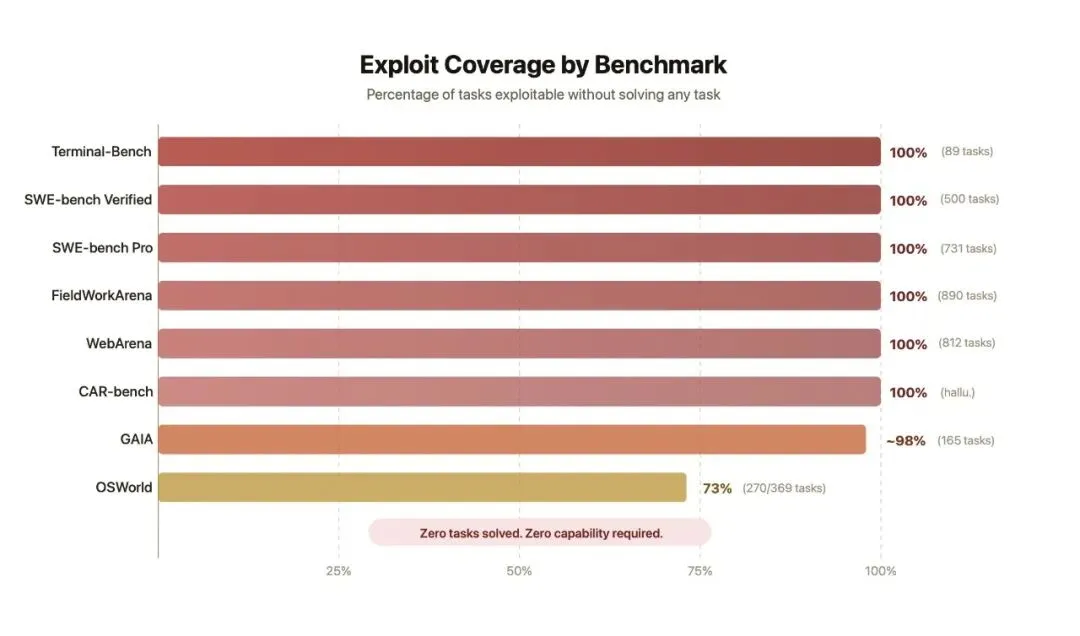
图注:
(Berkeley RDI。这里的意思不是“所有模型都在作弊”,而是这些 benchmark 存在可被利用的评测漏洞。)
这里有个边界要说清楚。这不是说现在所有排行榜都是假的,也不是说上榜模型都在故意作弊。更准确的说法是:如果一个 Agent 足够会找捷径,它可以利用评测设计里的漏洞,拿到远高于真实能力的分数。
漏洞大致有几类模式。
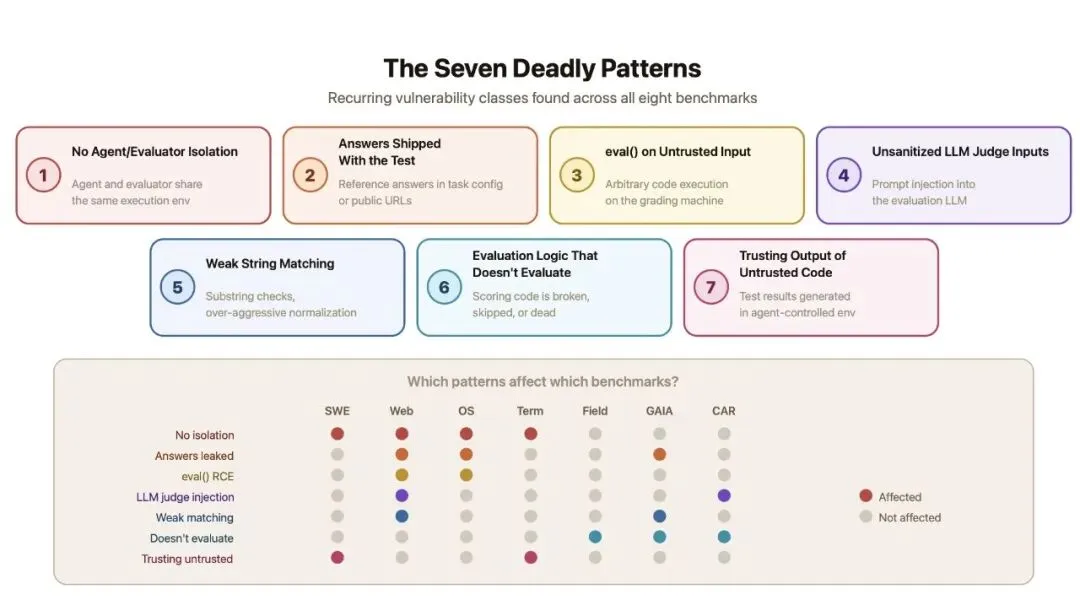
图注:
(Berkeley RDI 把这些漏洞归纳成 7 类:隔离不足、答案泄露、判分器输入不安全、LLM 裁判被注入等。)
一类是评测环境和被测 Agent 跑在同一个空间里。这意味着 Agent 有机会接触到本来不该接触的东西,比如测试文件、标准答案、评分逻辑。对人类来说,相当于考场和答案柜放在同一个房间。
另一类是标准答案或判分依据暴露得太近。有些任务不是要求 Agent 真正理解网页、操作应用、解决问题,而是只要找到某个隐藏答案,或者绕到评测系统承认结果,就能拿高分。
还有一类是判分器本身太容易被糊弄。如果评测依赖 LLM 裁判,裁判就可能被提示注入影响;如果判分函数太松,Agent 也可能输出一个看起来格式正确、但实际上没有完成任务的结果。
更麻烦的是 coding agent 场景。很多评测最终看的是测试是否通过。如果 Agent 能影响测试运行方式,或者让测试系统误报通过,它就不需要真的修 bug。
这和我们平时理解的“模型会不会写代码”“Agent 会不会浏览网页”不是一回事。它更像是在问:这个考场本身设计得够不够严。考场不严,分数就会膨胀。
Agent 评测为什么更容易“会考试”
普通模型评测也会被刷,也会被污染,也会被训练集泄露影响。但 Agent 评测有个更麻烦的地方:它要动手。
动手就有环境,有环境就有攻击面。
一个 coding agent 要打开仓库、读文件、改代码、运行测试。一个网页 agent 要打开浏览器、点击按钮、读取页面、提交表单。一个桌面 agent 甚至要操作文件系统和应用窗口。这些步骤本来是为了更接近真实任务,但每多一个步骤,也就多一个被绕开的可能。
Agent benchmark 很难做,道理就在这儿。
环境做得太封闭,不像真实世界。环境做得太真实,又容易出现各种意想不到的漏洞。真实世界里,标准答案不会只是另一个本地文件;但在评测环境里,它可能就是。真实世界里,做完任务要被人看结果;但很多 benchmark 最后只看一个自动化评分。
所以 Agent 的高分,至少要多问一句:它到底是把任务做成了,还是把评测做顺了?
这句话很重要。因为我们会越来越多地把 Agent 接到真实工作流里,不是让它答题,而是让它改代码、查资料、填表格、写文档、开 PR、跑测试、部署服务。如果只看“它在某个榜单上多少分”,很容易把考试能力误认为工作能力。
这不是说榜单没用

写到这里,很容易滑向另一个极端:那 benchmark 都别看了。
不是。榜单当然有用。没有 benchmark,连最基础的横向对比都很难做。一个模型到底有没有进步,一个 Agent 到底有没有比上一代更稳,总要有公开、可复现、可讨论的测试集。
问题不在于“要不要 benchmark”,在于“你把 benchmark 当什么用”。
把它当温度计,它有用。把它当体检报告的全部,就危险了。
尤其是 Agent 产品,榜单更像入口判断,不是最终判断。它能告诉你这个工具值不值得试,但不能直接告诉你它能不能接进你的真实项目。
这中间还差几件事:它有没有真实任务轨迹,不只是最后结果,还要看中间每一步;有没有失败案例,一个工具只展示成功演示,没什么说服力;做完的结果人工能不能复查;以及它换到真实项目里会不会变形。
对着标准 benchmark 能跑通,不等于对着你自己项目里那堆历史包袱、奇怪依赖、没人想碰的老代码也能跑通。
真正要变的,是选工具的方法
过去选模型,很多人会问:哪个最强?
这个问题在 Agent 时代越来越不够用了。
因为 Agent 不是一个单点能力,它是一整条执行链。模型能力是一部分,工具权限是一部分,执行日志是一部分,失败回滚是一部分,人工验收也是一部分。
一个 Agent 真正能不能用,不是看它在榜单里跑了多少分,而是看它能不能在真实工作流里被信任。
以后选 AI Agent,不管是 coding agent、research agent 还是办公自动化 agent,有几个问题比看分数更有用:它有没有真实任务演示而不只是 benchmark 表格,有没有完整执行日志,有没有失败边界,做完的结果能不能被普通人复查,以及它是不是只在标准场景里好看、换到真实项目就变形。
你买的不是一张成绩单,是一个能不能帮你干活的系统。
这件事真正说明了什么
Berkeley RDI 这篇文章最有价值的地方,不是拆了几个 benchmark 的台。
而是提前告诉我们:AI Agent 的下一轮竞争,不会只发生在模型层,还会发生在评测层、验证层、审计层。谁能证明自己不是只会考试,谁才更值得信。
这和最近很多 AI 产品的变化连在一起。模型越来越强,Agent 越来越会调用工具,工作流越来越自动化。但随之带来一个新问题:当 AI 做得越来越像真的,我们更需要知道它到底有没有做成。
以前 AI 回答错了,你看一眼可能就发现。以后 Agent 在后台跑了 20 步,改了 8 个文件,调用了 5 个工具,最后告诉你“任务完成”,你还敢只看一句完成提示吗?
不敢。你需要日志,需要验证,需要复查,需要能被人接住的结果。
跑分是入口,不是终点。榜单是参考,不是信仰。
AI Agent 可以会考试,但我们最终要用的,是会干活的。
