 夜雨聆风
夜雨聆风哈佛重磅研究:给AI加情绪提示词,真的有用吗?结论颠覆行业认知
本文约2000字 | 精读哈佛2026顶刊论文 | 附全量实验图表
关键词:大模型 | 情绪提示词 | EmotionRL | 自适应Prompt
在日常使用ChatGPT、豆包等大模型时,你一定试过情绪加持:
「求求你帮我写,很急!」「我超开心能得到你的解答!」「这个问题太难了,我快崩溃了」。
全网疯传的「情绪Prompt魔法」,号称能让AI答题准确率暴涨、逻辑更严谨。但哈佛大学最新研究直接打破这个神话:固定情绪提示词几乎无效,盲目加情绪甚至会拖垮模型性能。
2026年4月,哈佛团队发布《Do Emotions in Prompts Matter?》,覆盖6大核心任务、3款顶尖大模型、6类人类基础情绪,用百万级实验数据,彻底厘清「情绪」对大模型的真实影响,并提出EmotionRL自适应情绪框架,首次实现情绪提示的稳定增益。
一、实验全景:史上最全面的情绪Prompt测试
研究团队摒弃「正负情绪二分法」,基于心理学经典理论,锁定快乐、悲伤、恐惧、愤怒、厌恶、惊讶6类核心情绪,构建了全维度测试 pipeline(图1)。
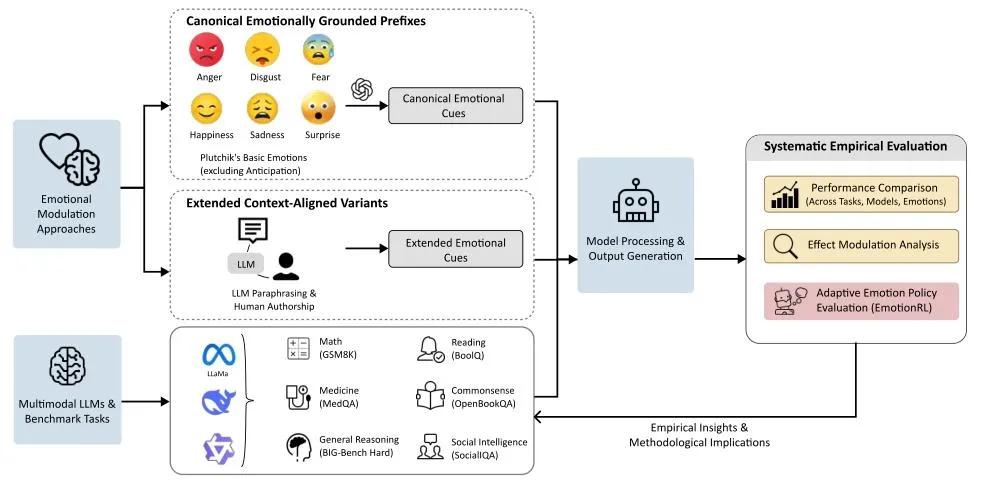
▲ 图1 实验总流程:情绪注入→多模型测试→自适应优化
核心实验配置
1. 测试模型:Qwen3-14B、Llama 3.3-70B、DeepSeek-V3.2(覆盖开源主流大模型) 2. 六大任务:数学推理(GSM8K)、医疗问答(MedQA)、阅读理解、常识推理、社会推理 3. 变量控制:情绪强度(轻微/中度/极端)、撰写来源(人工/AI生成)、提示词位置
这是目前行业内最严谨、覆盖最广的情绪提示词研究,结论具备绝对的工业级参考价值。
二、颠覆性结论1:固定情绪提示,99%场景无效
全网吹捧的「情绪魔法」,在硬核数据面前彻底失效。
研究核心结果如图3所示:所有固定情绪前缀,对模型准确率的影响几乎趋近于0。
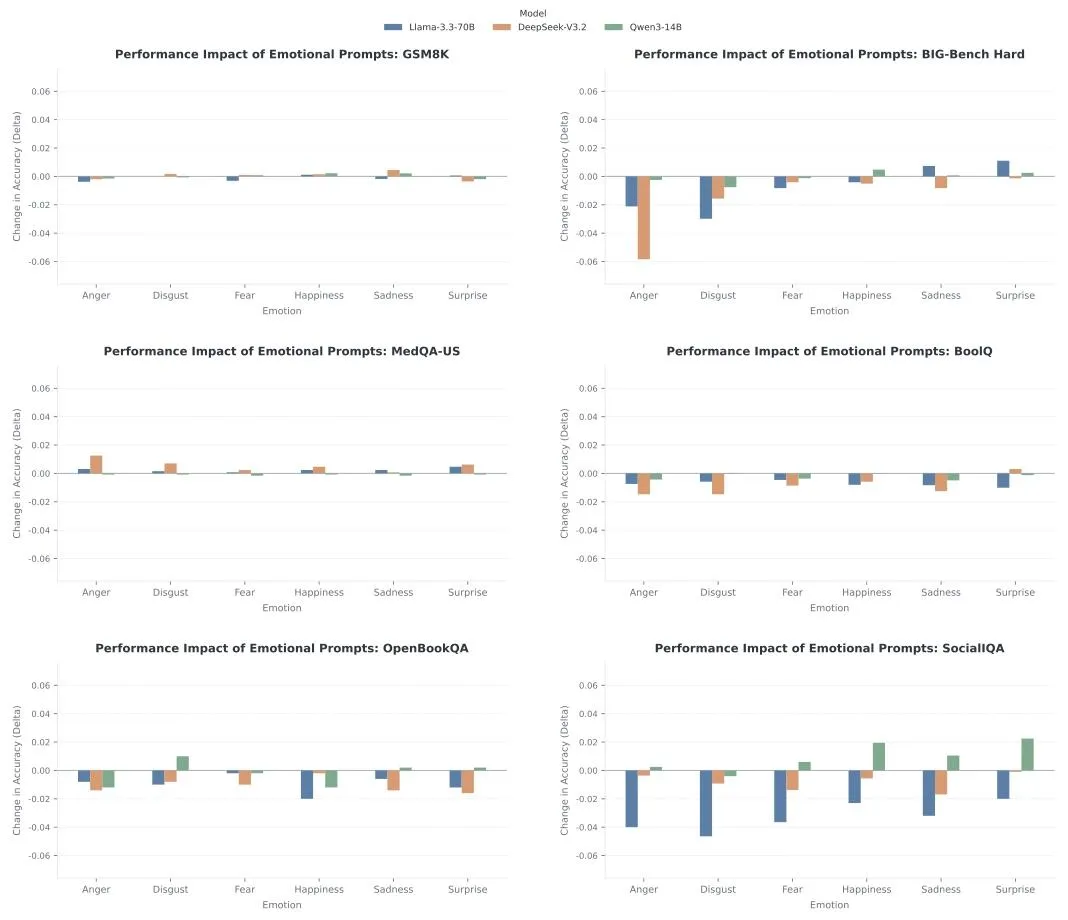
▲ 图3 6类情绪对6大任务的准确率影响(波动接近0)
关键发现
1. 数理/专业任务完全免疫:数学、医疗问答中,情绪提示词无法带来任何提升,模型性能纹丝不动; 2. 仅社交任务微弱波动:只有社会推理(SocialIQA)出现小幅波动,但无统一正向效果; 3. 无万能情绪:不存在「快乐/愤怒」能通杀所有任务,同一种情绪可能帮A模型、害B模型。
一句话总结:给Prompt加固定情绪,不是魔法,只是无效噪音。
三、颠覆性结论2:情绪越强、人工写,照样没用
为了排除变量干扰,团队做了两组极限验证,结果再次打脸固有认知。
1. 情绪强度拉满,性能依旧无变化
团队将情绪强度分为「轻微→中度→极端」,测试医疗问答任务(图4):
哪怕用「极度愤怒、极度恐惧」等强烈措辞,模型准确率依旧平稳,无显著下降或提升。
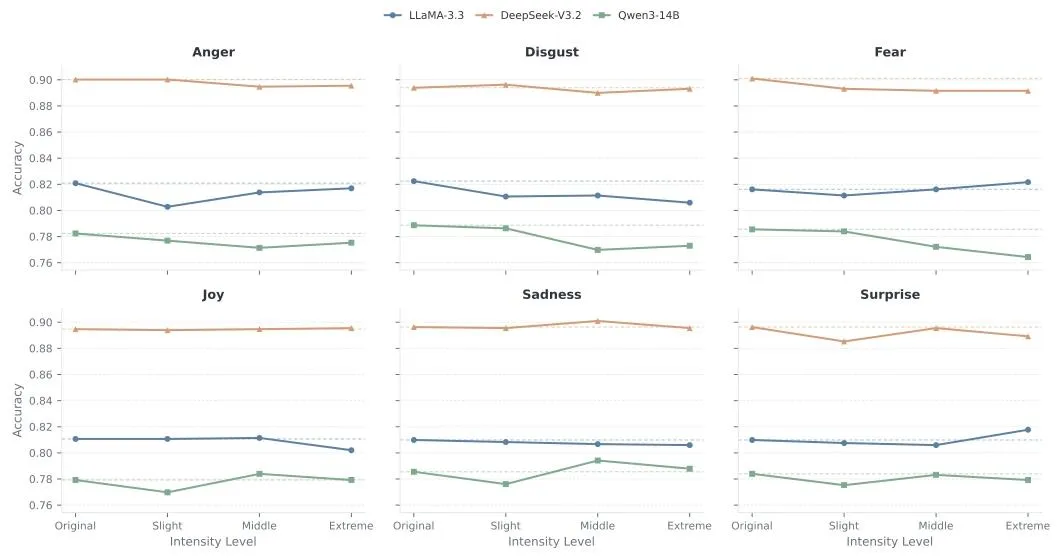
▲ 图4 情绪强度对模型性能无实质影响
2. 人工撰写 vs AI生成,效果完全一致
很多人认为「人工写的情绪话术更自然,效果更好」,但实验数据直接否定:
人工手写、GPT-4o生成的情绪前缀,准确率曲线高度重合,无任何优势(图5)。
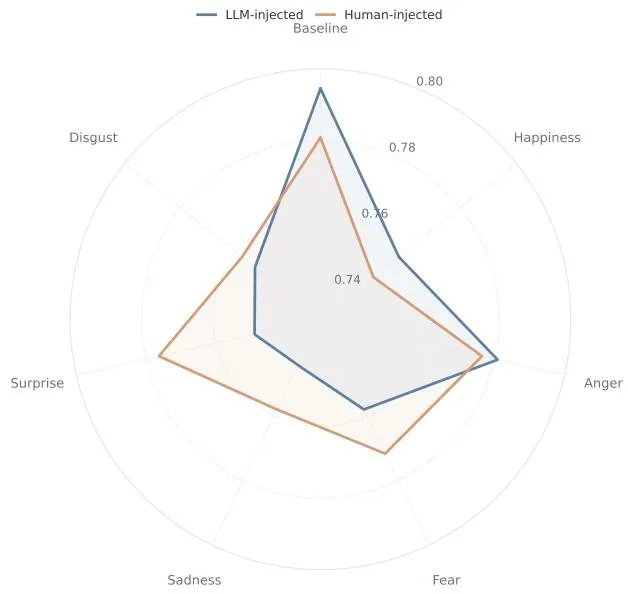
▲ 图5 人工/AI情绪前缀效果无差异
论文还给出了直观示例(表B1),同一医疗问题下,人工与AI的情绪表达风格不同,但模型输出质量完全一致。
四、破局方案:EmotionRL,自适应情绪才是正确答案
固定情绪无效,不代表「情绪」毫无价值。
哈佛团队提出EmotionRL自适应框架,核心逻辑:不固定一种情绪,给每个问题匹配最优情绪(图2)。
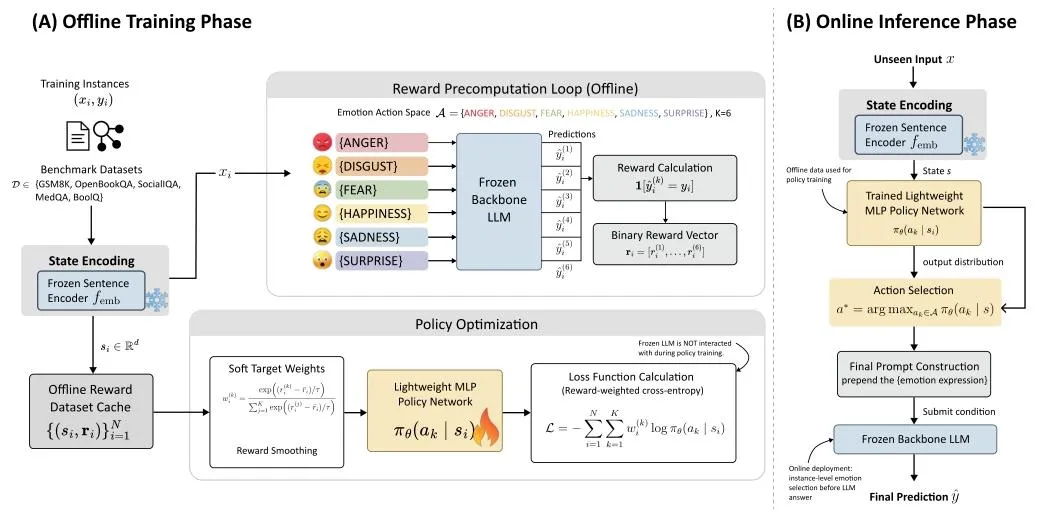
▲ 图2 EmotionRL 离线训练+在线推理全流程
技术核心
1. 离线训练:为每个问题测试6种情绪,记录最优收益; 2. 语义编码:用向量表征问题特征,学习「问题-情绪」匹配规律; 3. 在线推理:自动为新问题选择专属最优情绪,一键生成Prompt。
效果碾压固定提示词
如图6所示,EmotionRL彻底扭转了固定情绪的劣势:
在5大核心任务中全量正向增益,最高提升1.10%,彻底消除负面效果,成为唯一稳定有效的情绪方案。
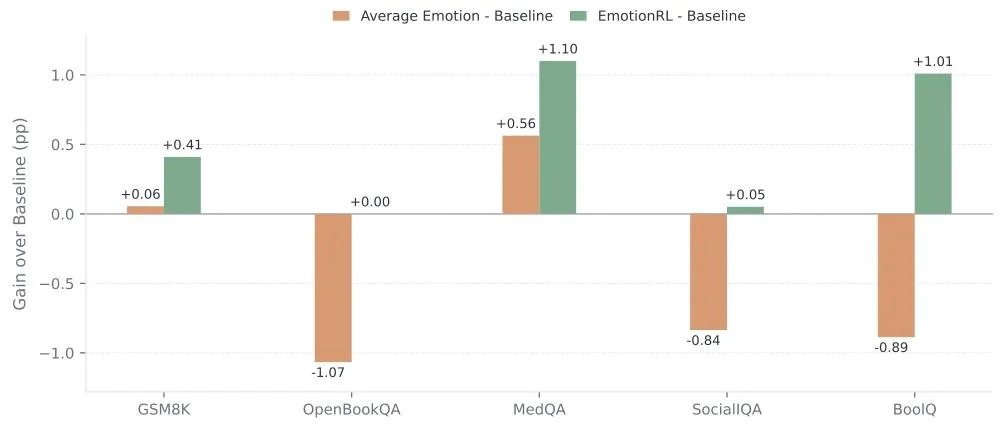
▲ 图6 EmotionRL vs 固定情绪提示,全面碾压
五、行业启示:我们该如何正确使用情绪Prompt?
这篇哈佛论文,给所有AI使用者、开发者划清了3条铁律:
1. 放弃「万能情绪Prompt」
不要无脑加「求求你、我很着急」,数理、代码、医疗等专业场景,纯中性提示词效果最优。2. 社交/创作场景可轻量用情绪
仅在聊天、文案创作、社会推理等场景,情绪能带来微弱体验提升,无需高强度措辞。3. 工业落地首选自适应方案
企业级应用不要手动加情绪,接入EmotionRL类自适应框架,实现「千人千面」的情绪匹配,兼顾性能与体验。
结语
大模型的能力边界,从来不在「花里胡哨的Prompt技巧」,而在对模型行为的科学认知。
哈佛这项研究告诉我们:情绪不是大模型的增益开关,而是需要精准匹配的微调信号。盲目跟风情绪话术,不如回归问题本身;放弃玄学魔法,拥抱数据驱动的自适应优化,才是AI落地的正道。
当我们不再神化Prompt技巧,才算真正读懂了大模型。
**论文来源**:https://arxiv.org/pdf/2604.02236
**作者团队**:哈佛大学、布林莫尔学院
**全文数据**:6大任务×3模型×6情绪,百万级推理验证
**核心结论**:固定情绪无效,自适应情绪才是最优解