 夜雨聆风
夜雨聆风最近我把一条 AI 音乐工作流跑通了,我先说结果
这段时间我一直在折腾一件事,能不能把 AI 音乐从一个“网页上点一下”的动作,真正变成一条能长期复用的创作流水线。
现在我手上的这套方案,大致已经跑顺了。
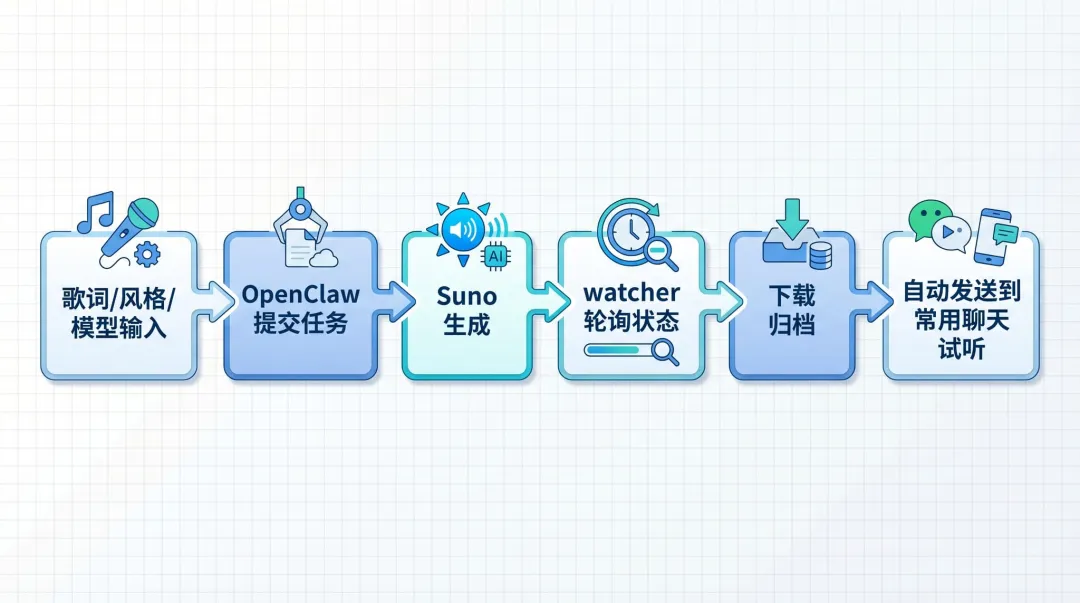
我负责给出歌词、风格、模型和标题,#OpenClaw 负责把这些输入整理成标准任务,调用本地脚本去请求 #EvoLink Music API,再由 EvoLink 对接 #Suno 去生成;生成过程中,系统会在后台盯住状态;结果出来之后,再自动下载、归档,最后把成品直接发到团队平时会看的聊天里,让大家第一时间试听。
对我来说,最重要的变化不是“更自动化了”这么简单。
而是 AI 音乐终于不再只停留在“生成结果”这个瞬间,而是开始像一个真实工作流那样,能往后继续流转。
这里说的“聊天”,不是特指某一个平台。
它可以是微信、飞书、钉钉、企业微信,也可以是你团队内部其他固定在用的聊天渠道。重点从来不是平台名,而是结果能不能在第一时间自动到达协作现场。
真正浪费时间的,从来不是“生成”那一下
很多人一提到 AI 音乐,脑子里浮现的流程通常都差不多。
写一点歌词,或者打一句描述,选一个模型,点生成,等结果出来,下载音频,再转发给别人听。
如果你只是偶尔玩一玩,这套动作完全够用。
但只要你开始高频用,很快就会发现,最烦人的地方其实不在“点生成”这一下,而在前后那些零碎动作上。
比如歌词要不要改格式,风格描述怎么写更稳定,标题和版本号记在哪里,生成中的任务要不要盯着,结果下来以后文件怎么命名,怎么归档,怎么重新发到聊天里,发出去的时候要不要再补一句“这是第几个版本,这次主要改了哪里”。
单独看,每一步都不难。
但只要你一天跑三首、五首、十首,这些细碎动作就会开始大量吃掉你的注意力。
尤其是下面这些场景,会把人工流程的低效放大得特别明显:
你想同时试几种风格,看看哪种方向更对 你需要把多个版本发给团队、客户或者朋友快速试听 你要保留每次生成时用的歌词、风格、模型和结果,方便回头比较 你不是只想“出一首歌”,而是想把 AI 音乐真正接进自己的内容生产流程
我后来越来越确定,问题根本不是“再换一个更强的模型”。
真正值得做的,是把整条链路自动化。
也就是把下面这些动作,从靠人手动搬运,变成由系统稳定接管:
标准化输入 提交生成任务 后台等待结果 下载音频 归档版本 自动分发到协作渠道
当这些事被系统接走之后,人才能把精力重新放回创作判断本身。
这套方案一句话怎么理解
如果要用一句最短的话来解释,我会这么说:
OpenClaw 像一个音乐工作流中枢,EvoLink Music API 是当前的接入层,Suno 是底层生成模型,系统在后台帮我盯任务、收结果、整理文件,再把成品自动发到团队常用聊天里试听。
所以它归根到底不是一个“让 AI 帮我写歌”的单点技巧。
它更像一个自动化制作助理。
我给它创作输入,它替我把后面那串重复但必要的流程跑完。
先把真实生成链路说清楚
这里有一个特别容易被误解的地方,我想先单独说清楚。
我现在这条已经真实跑通的音乐生成流程,并不是在 OpenClaw 里直接点某个现成的 Suno skill 包,然后就结束了。
当前真正跑起来的结构是:
OpenClaw -> 本地脚本 -> EvoLink Music API -> Suno 模型 -> 返回 task_id -> watcher 轮询 -> 拿到 audio_url -> 下载归档 -> 发到聊天也就是说,OpenClaw 负责的是工作流编排,本地脚本负责真正发 HTTP 请求,EvoLink Music API 负责接住这一层生成调用,而底层用到的模型是 Suno 系列。
如果再说得具体一点,目前这条链路主要跑的是 suno-v5,也兼容 suno-v4 和 suno-v4.5。
这也解释了为什么我更愿意把这件事叫成“API 工作流”,而不是简单叫成“某个技能包”。
它具体怎么跑,我拆成五步讲
第一步,先把输入变成标准化任务
这一步其实特别重要。
因为如果每次输入都很随意,后面的自动化就很难接。
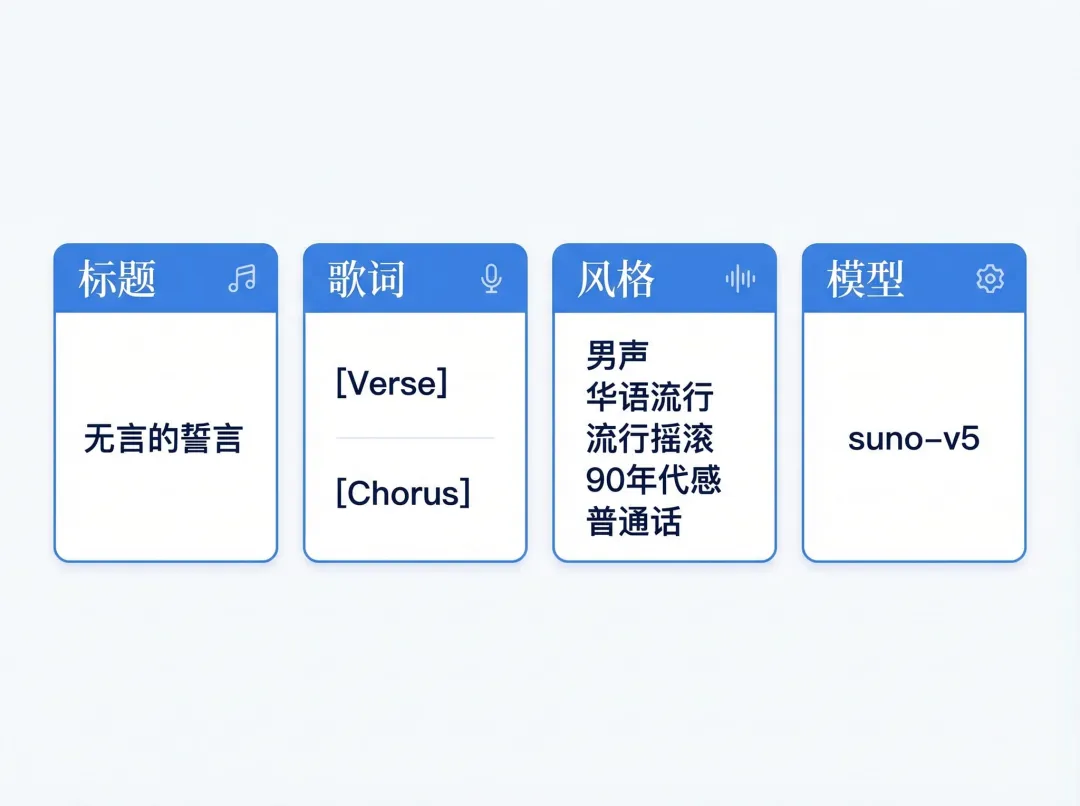
我现在会尽量把每次创作都整理成几项固定信息:
标题 歌词 风格描述 模型选择
比如一份最小输入,大致可以长这样:
title:无言的誓言model:suno-v5style:男声,华语流行,流行摇滚,90年代感,普通话lyrics:| [Verse 1] 夜色落在窗边 像没说完的话 [Chorus]我把沉默唱成海把告别藏进人海这里面最容易被低估的,通常是歌词结构和风格描述。
歌词如果只是随手一段散文,模型当然也能试,但如果你能明确写出 [Verse]、[Chorus] 这种结构标签,生成结果通常会稳定得多。因为模型更容易理解哪里是主歌,哪里是副歌,整首歌的起承转合也更容易成形。
风格描述也一样,不一定非要写得很“专业”,但最好把几个关键信息说清楚,比如人声类型、语言、流派、情绪、年代感。你写得越稳定,后面同风格复用和版本对比就越顺。
标题也别只把它当成一个展示文本。
在工作流里,标题往往还会参与文件命名、项目归档和消息发送文案。前面这一步做得越清楚,后面就越省事。
第二步,用 API 提交生成任务,而不是我手动盯网页
把输入交给 OpenClaw 之后,事情就不再只是“去网页上点一下生成”。
从工作流视角看,它其实是在创建一个完整任务。
这里真实发生的动作是:
OpenClaw 调本地脚本 本地脚本加载 .env.music读取里面的 EVOLINK_API_KEY用 HTTP 请求把歌词、模型、风格、标题发给 EvoLink Music API EvoLink 再去调用 Suno 模型生成
现在提交任务的核心接口是:
POST https://api.evolink.ai/v1/audios/generations请求里会带上这些关键信息:
prompt:歌词全文 model:比如 suno-v5style:风格说明 title:歌曲标题 custom_mode:是否自定义模式 instrumental:是否纯音乐
系统通常会同时做几件事:
记录这次任务的标题、风格、模型等元信息 保存一份歌词副本,避免后面改了又找不回原始版本 提交音乐生成请求 保存任务 ID,方便后续轮询和追踪 建立对应的项目目录或任务记录
也就是说,从点击提交开始,这首歌就已经被放进了一条自动生产线上。
你对外看到的是“我发起了一次生成”。
但系统内部看到的是“我现在接到一个有编号、有输入、有状态、有后续动作的音乐任务”。
这个差别很关键。
因为只有先把它当成任务,后面才有可能做状态管理、结果归档和自动分发。
第三步,后台 watcher 轮询任务状态,人不用一直守着
很多 AI 音乐产品的体验问题,恰恰出在“等待”这一步。
它不是秒回任务,所以人工处理的时候特别容易出现三类麻烦:
你得不断回来刷新 你得记住哪首歌对应哪个任务 你得在别的事情和“等结果”之间频繁切换注意力
这也是为什么我觉得 watcher 这一层特别值得做。
有了它以后,系统可以在后台自己做这些事情:
定时检查任务状态 判断任务是生成中、已完成、失败还是超时 把状态持续写进记录里 如果出错,保留对应的失败信息,方便后面排查
这一步对应的真实 API 查询接口是:
GET https://api.evolink.ai/v1/tasks/<task_id>也就是说,后台 watcher 并不是“猜它什么时候结束”,而是在拿着 task_id 去持续查任务状态。
这一步看起来不“酷”,但它非常实用。
因为它直接解决了一个现实问题,人不应该把注意力浪费在反复查进度这件事上。
你可以去写下一首的歌词,去处理别的内容任务,或者干脆先离开电脑。等结果真正回来时,系统再进入下一步。
第四步,拿到结果以后,不只是下载,而是顺手归档
这一段是很多人容易省掉,但我现在反而觉得很值钱的一段。
如果结果出来以后,你只是把 mp3 下载到桌面,那短时间里可能没问题。
但只要项目一多,你很快就会遇到这些情况:
这首歌当时用的是什么风格,忘了 哪个版本是团队最喜欢的,找不到了 这首成品到底是哪个模型跑出来的,不确定 原始歌词和最后生成结果,已经对不上了
实际流程走到这里时,不是凭空就有一个 mp3 文件。
而是先从任务结果里拿到 audio_url,再把音频真正下载回本地。
也就是:
提交任务 -> 返回 task_id -> 查询任务状态 -> 提取 audio_url -> 下载 mp3所以现在我会把“下载”理解成归档流程的一部分,而不是终点。
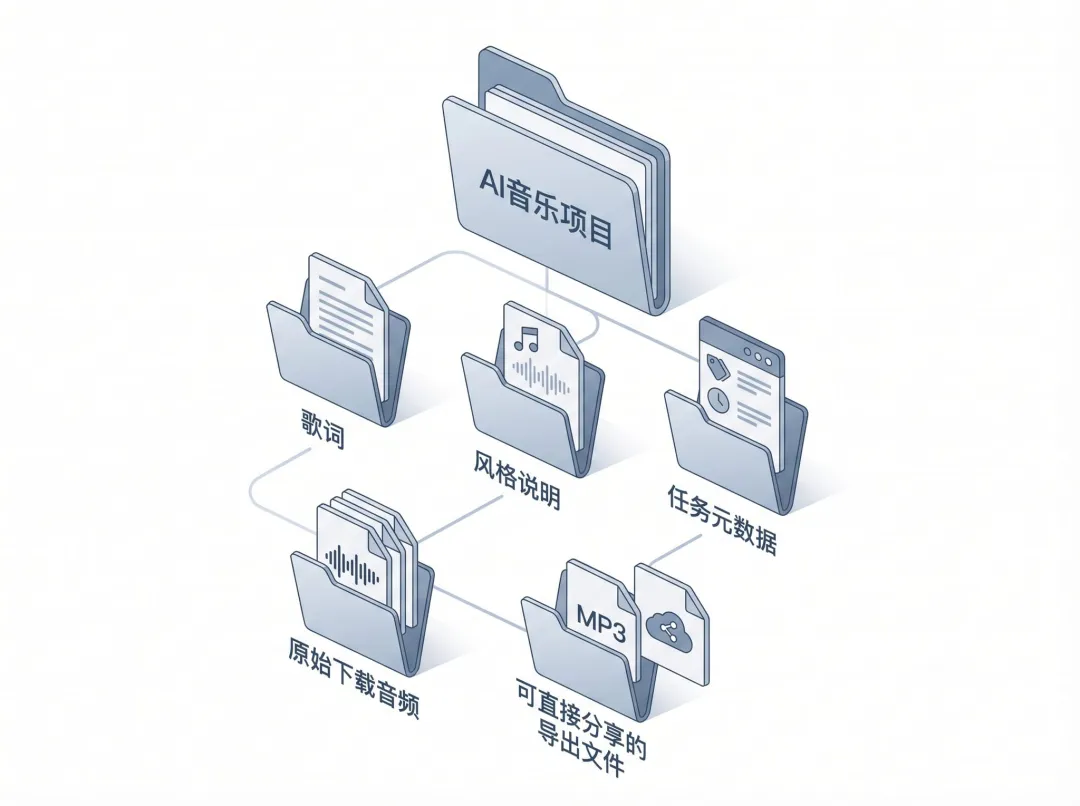
大致上,系统会把一首歌相关的内容尽量放进同一个项目结构里。你可以粗略理解成这样:
一个音乐项目目录├─ 歌词├─ 风格说明├─ 任务元数据├─ 原始下载音频└─ 可直接分享的导出文件这样做最大的好处,不是看起来整齐,而是你后面真的还能继续用。
你可以回看,可以比较版本,可以继续二次迭代,也可以后续重新发布。AI 音乐才会从一次性结果,慢慢变成真正可管理的内容资产。
第五步,最后一跳是把成品自动发到常用聊天里
这一步是我最想强调的,也是我觉得整套方案最像“工作流升级”的地方。
以前我做这件事时,最后总要经历一串很碎的动作:
先下载音频,再打开聊天,再上传文件,再补一句说明,告诉大家这是哪个版本、这次试的是什么风格、想听什么反馈。
你偶尔做一次,不会觉得怎样。
但如果这是你每天都在重复的动作,它会变成特别典型的低价值劳动。
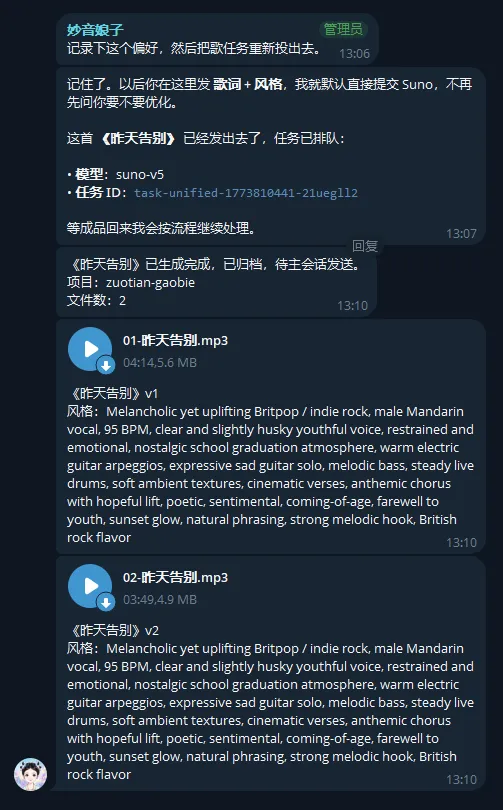
现在我的做法是,音乐一生成完,系统就把成品直接发到指定聊天里。
这里的聊天可以是飞书聊天、钉钉聊天、企业微信聊天、微信聊天,或者团队内部其他固定在用的聊天。关键点不是发到哪里,而是它能不能自动进入大家平时真的会看的地方。
而且发送的时候,不是只丢一个文件过去。
通常还可以顺带附上几条对协作很重要的信息,比如:
这首歌叫什么名字 这是什么风格 当前是第几个版本 这次主要想验证什么 希望大家重点听哪一段
这样别人打开聊天,就不是面对一个孤零零的音频文件,而是能直接进入你的创作上下文。
为什么“自动发到聊天里”不是小功能,而是关键节点
很多人第一次听到这套流程时,会直觉觉得最厉害的是“自动生成”。
但如果真的放进协作环境里,我反而觉得最关键的常常是最后这个分发动作。
因为音乐的价值,不是停留在“我自己本地听到了”。
它真正要进入的,是后面的这些环节:
试听 反馈 选版本 修改 再生成
而“自动发到聊天里”,其实是在把结果直接送进这条链路。
第一,它让反馈速度变快。
歌一出来,聊天里的协作对象就能立刻听到。有人觉得副歌不够抓耳,有人觉得氛围对了,有人觉得前奏太长,这些反馈会在最热的时候发生,而不是拖到你想起来再去发。
第二,它让每个版本都带着上下文出现。
它不是只发一个文件过去,通常还会顺带带上标题、版本、风格、用途,以及这次希望大家重点听哪一段。这样收到的人不是“随便听听”,而是更容易围绕同一个问题给出反馈,反馈也会更聚焦。
第三,它把创作者从低价值搬运里解放出来。
创作者更应该花时间做的是判断和迭代,而不是上传、重命名、补说明。自动化把这些杂活接走之后,人才能把精力重新放回内容本身。
所以对我来说,自动发到聊天里不是锦上添花。
它其实是在把 AI 音乐从“生成行为”,变成“协作行为”。
高频创作为什么必须流程化
如果你只是偶尔体验一下 AI 音乐,手动点生成完全没问题。
但如果你属于下面这些情况,这套方式会明显更顺手:
经常给短视频找配乐,想快速比较不同情绪版本的人 会反复调歌词、调风格、调模型,持续试版本的人 需要把作品快速发给团队、客户或朋友试听的人 同时在跑多个音乐项目,怕任务和文件混乱的人 想把 AI 创作真正接进内容工作流,而不是停留在试玩层的人
它其实也不只适合“完整歌曲”。
像短视频配乐 demo、品牌提案样曲、直播或播客片头、创作者内部试听流,这些场景都很适合。
因为它解决的不是某一种内容类型,而是高频创作里普遍存在的几个老问题:
不用手动盯生成进度 不用自己搬运文件 每次版本都有记录 结果会自动到协作现场 反馈链路会明显变短
频率越高,这种流程化带来的差别就越明显。
为什么归档是 AI 内容生产里最容易被低估的一环
很多人一开始会觉得,归档像是在做“后勤”。
但只要你真的开始连续做版本、反复调方向,很快就会发现,归档不是附属动作,而是创作本身的一部分。没有归档,你就很难回看,很难比较,也很难知道某个结果到底是怎么来的。
AI 内容生产一旦开始高频化,最后拼的就不只是会不会生成,而是你有没有能力把每一轮输入、结果和判断都留住。前面那一步看起来最不显眼,后面往往最值钱。
如果你也想自己搭,不要先盯界面,先把这五件事做好
如果你也想做一套类似的东西,我自己的建议是,先别急着追求很复杂的前端界面。
先把流程骨架搭起来,价值会来得更快。
最值得优先做的,通常是下面五件事。
1. 先把输入标准化
至少先固定住标题、歌词、风格、模型这几项。
输入一旦稳定,后面的自动提交、任务记录、归档和分发才接得起来。
2. 先把 API 接入层跑通
这个点特别现实。
你不一定非要直接连模型官网,但一定要有一层稳定的 API 接入,能完成提交任务、查询状态和拉取结果。
我现在这条链路实际接的是 EvoLink Music API,关键配置放在工作区的 .env.music 里,核心环境变量是:
EVOLINK_API_KEY所以你的工作流最好从一开始就把“怎么拿 key、怎么加载 key、谁来发请求”这几个问题说清楚,而不是临时手动 export。
3. 把任务状态写下来
不要只做“提交成功”这一步。
至少要能分清已提交、生成中、已完成、发送成功、失败或超时。只要状态记录清楚,整套系统的可用性就会高很多。
4. 把结果归档到清晰目录
哪怕一开始还没有数据库,也没关系。
先把歌词、参数、结果文件、时间和任务信息,放进一个明确的项目目录里。这个动作看起来朴素,但它会直接决定你后面能不能复盘、能不能继续迭代。
5. 打通最后的分发渠道
这一条非常值得尽早做。
因为只要结果能自动发进团队日常在用的沟通渠道,AI 生成就不再是一个孤立动作,而会自然进入协作流程。
说到底,工作流真正发挥价值的地方,往往不是最前面的生成,而是最后那一下有没有真正送达。
为什么 AI 真正有价值的是“会流转”,不只是“会生成”
如果让我总结这次折腾最让我满意的一点,那不是模型更强了,也不是一次能出多少惊艳结果。
真正让我觉得方向对了的,是 AI 音乐终于不再卡在“生成完成”这一步。
它可以继续往下走。
可以归档,可以分享,可以进入聊天,可以被反馈,可以被二次修改,也可以沉淀成下一轮创作的素材。
这件事听起来好像没有“又做出一首歌”那么显眼,但它更接近真实工作。
因为内容的价值,从来不只是被生成出来。
它还要能被听见,被讨论,被筛选,被修改,被复用。
而一旦你把这条链路接起来,AI 在创作里的角色就会发生变化。
它不再只是一个给你结果的工具,而是开始成为一个能参与流程、推动流转的助手。
最后一句
如果要用一句话概括我最近这套实践,我会这么说:
我现在做 AI 音乐,已经不是手动去网页点生成了,而是把 OpenClaw 当成一个音乐工作流中枢:我负责写歌词和定风格,它负责提交任务、等待结果、下载归档,再把成品自动发到团队聊天里试听。
对我来说,这件事最值得兴奋的地方,不只是效率变高了。
而是 AI 创作终于开始从“会做内容”,走向“会跑工作流”。
我觉得这一步,可能比再多会一两个 prompt 技巧都更重要。
如果你也对这条线感兴趣,可以先关注我。
这篇我先把“真实生成链路”和“为什么要把它做成工作流”讲清楚。后面的文章里,我会继续把这套 AI 音乐生成自动化技能包整理出来,看看它到底怎么接、怎么用、适合什么场景。
如果你自己也在折腾类似流程,或者你觉得哪一段还值得继续展开,也欢迎在评论区告诉我。你们提的问题和建议,我后面也会继续往下写。
