 夜雨聆风
夜雨聆风
引言
单Agent写内容时,上下文窗口越来越膨胀,输出质量却越来越不稳定——这几乎是每一个尝试用AI做内容生产的开发者会遇到的天花板。当你的提示词从50行膨胀到200行,当同一个写作Agent在长对话中时而严谨时而敷衍,当你想同时生成多篇不同风格的文章却只能排队等待——这些问题并不是你调教得不够好,而是单Agent架构天然存在的瓶颈。
本篇文章介绍如何通过OpenClaw的AGENTS.md配置,将一个臃肿的单Agent拆解为多个职责清晰的Subagent,组成一条可复用、可扩展的AI内容创作流水线。我会覆盖从创建主控Agent、openclaw.json配置、再到AGENTS.md中工作流编排的详细讲解,最后提供生产级落地的实战经验。无论你是想提升内容产出质量,还是想降低多Agent并行时的Token消耗,这篇文章都能给你可操作的方案。
第一章:为什么单Agent写内容总有天花板
1.1 上下文窗口的隐形成本
很多开发者以为上下文窗口是免费资源,实际上它是Token消耗的核心来源。当你的对话历史累积到一定长度,每次API调用都需要将所有历史消息重新发送给模型——这直接导致两个问题:响应延迟增加、成本线性增长。
以一个典型的内容创作场景为例:假设你需要写一篇5000字的技术文章,单Agent方案可能需要多次往返对话来澄清需求、补充信息、修改细节。每次修改都基于完整的上下文进行,而随着对话深入,每轮的Token消耗都在攀升。相比之下,将任务分解给多个专注的子Agent,每个Agent只处理自己职责范围内的上下文,总消耗往往更低。
1.2 单Agent职责过重的典型表现
一个承担太多角色的单Agent,往往会在输出中暴露以下症状:
- 写作风格漂移:开头严肃专业,中段突然变得口语化,结尾又恢复了正式语气。
- 逻辑断层: 文章前后论点自相矛盾,或者在需要深度分析的地方突然浅尝辄止。
- 覆盖不均: 某些部分写得极为详尽,另一些同等重要的部分却一笔带过。
- 响应时间波动: 随着上下文增长,模型需要"回忆"的信息越多,生成速度明显下降。
这些问题的本质是:一个模型很难在单一上下文中同时扮演好研究者、规划者、写作者、编辑者等多个角色。每个角色对"什么样的输出是好的"有不同的判断标准,单Agent只能尽力平衡,而平衡的结果往往是各方面都打了折扣。
第二章:OpenClaw多Subagent协作核心概念梳理
2.1 Orchestrator(编排器)模式:主Agent如何派生与汇总子Agent结果
OpenClaw的多Subagent协作采用了经典的Orchestrator模式。在这种模式下,一个主Agent(称为Orchestrator)负责:
- 接收任务:从用户或外部系统获取内容创作需求。
- 拆解任务: 将整体需求分解为多个可并行的子任务。
- 派生子Agent:通过sessions_spawn启动多个子Agent处理子任务。
- 汇总结果: 收集各子Agent的产出,进行整合、润色、最终输出。
这种模式的核心优势在于:每个子Agent都可以是专注单一职责的"专家",而不是试图成为一个全能选手。Orchestrator不需要自己写内容,它只需要做好调度和汇总工作。
2.2 Subagent与Multi-agent routing的本质区别
很多人容易混淆Subagent和Multi-agent routing这两种概念,它们其实是不同的设计思路:
OpenClaw的Subagent机制更适合我们本文讨论的内容创作流水线场景——有明确的阶段划分和上下游依赖关系。
2.3 Agent teams团队协作系统的定位与边界
OpenClaw还提供了"Agent teams"的概念,它位于Subagent架构之上,提供了更高层次的抽象。Agent teams主要用于:
跨多个独立Agent的协作编排。 共享资源和状态。 统一的任务分配和追踪。
但对于大多数内容创作流水线场景,你其实不需要直接操作Agent teams。Orchestrator + Subagent的组合已经足够满足需求,引入teams反而会增加不必要的复杂度。只有当你需要管理非常大规模的Agent网络时,teams才有实质价值。
第三章:实战——搭建一条内容创作流水线
3.1 创建独立的主控Agent
在命令行终端输入: openclaw agents add blog_orchestrator。
openclaw会自动创建一个新的独立的Agent, Id 为 blog_orchestrator,它将是创作内容的主控Agent,或者叫编排器Agent。Openclaw在创建Agent时会做一些必要的初始化,比如生成默认的:SOUL.md, AGENTS.md, IDENTITY.md,MEMORY.md等等。
3.2 修改openclaw.json
openclaw.json是Openclaw的全局配置文件,当我们创建一个新的Agent之后,需要在这里增加一些配置,另外有些subagent的全局配置也需要在该文件设定。
"agents":{"defaults":{"subagents":{"maxConcurrent":10,//subagents最大并发数量"maxSpawnDepth":2,//最大委派深度"runTimeoutSeconds":1800,//subagent最长运行时间"archiveAfterMinutes":60//当子代理完成任务后,系统会在设定的时间后自动归档并清理其会话记录},"model":{"primary":"minimax/MiniMax-M2.7"//所有agent默认使用的LLM模型}, ...},"list":[ ...{"id":"blog_orchestrator",//我们新增的内容创作编排器Agent"name":"blog orchestrator","workspace":"~/.openclaw/workspace/blog_orchestrator","agentDir":"~/.openclaw/agents/blog_orchestrator/agent","tools":{//工具许可配置,下面的配置依次许可了:网络工具、文件工具、session管理工具和记忆工具"allow":["group:web","group:fs","group:sessions","group:memory"]},"subagents":{"allowAgents":["*"]//允许派生任意subagent}}]},"bindings":[ ...//为新建的agent绑定消息通道,这里简单绑定了webchat。你也可以绑定飞书或者钉钉,作为和主控agent的消息通道{"type":"route","agentId":"blog_orchestrator","match":{"channel":"webchat"}}],3.3 在AGENTS.md中定义核心工作流
AGENTS.md 是 OpenClaw 中 代理(Agent)最核心的操作手册(Operating Manual / Procedural Rules) 文件。我们会把新建的 Orchestrator Agent的工作流定义在这个文件中。下面是我们需要在AGENTS.md中默认内容后新增的部分:
...## Core Workflows### Workflow: 技术博客创作 Workflow**ID**: blog-creation-workflow **描述**: 端到端技术博客创作流水线(AI、编程、云计算、机器学习等领域)。主 Agent 仅负责协调,所有具体环节必须通过 spawn_subagent 委派独立子 Agent 完成。主 Agent 禁止直接执行研究、写作、审查、编辑或合成工作。**触发条件**: 用户提供主题关键词、目标受众、技术深度、字数目标等。 **输出**: 完整 Markdown 技术博客(含标题、正文、代码示例、图片占位、SEO 元数据、参考文献)。 **迭代限制**: 每个环节最多允许 1 次 refine 反馈(由主 Agent 发起)。 **失败处理**: 子 Agent 失败时,自动 spawn 同类型备用 Agent 或进入 human_in_loop。#### spawn_subagent 统一模板(必须严格遵守) ```json { "action": "spawn_subagent", "subagent_role": "角色名称", "input": { ... }, "timeout": 1200, "max_tokens": 30000, "temperature": 0.65, "require_approval": false, "thinkingLevel": "medium", "refine_request": null } ```#### 环节定义(每个环节必须使用 spawn_subagent)**环节1: 主题深化与研究**- Subagent Role: TechnicalResearcherAgent - Goal: 深入调研,输出结构化研究笔记、标题建议、关键参考。 - Input:user_query(必填)、target_audience(默认“技术工作者”)、tech_depth(默认“intermediate”)、keywords(自动提取或补充)。- Output: selected_topic, research_notes, key_references**环节2: 详细大纲生成**- Subagent Role: BlogOutlineAgent - Goal: 生成 SEO 友好标题 + 完整层级大纲(含预计字数、必须元素)。 - Input: research_notes + 字数要求 - Output: outline (title, meta_description, sections)**环节3: 初稿撰写**- Subagent Role: TechnicalWriterAgent - Goal: 严格按大纲撰写完整初稿,代码准确。 - Input: outline + research_notes - Output: draft, code_snippets_verified- **写作风格注入规则**(主控必须严格执行): 主控 Agent 在调用 spawn_subagent 时,必须在 input 中完整传递以下写作风格指令: - 语气:专业、友好、指导性,像一位经验丰富的开发者在分享实战干货。 - 语言风格:清晰通俗、严谨但不晦涩,避免夸张词、网络流行语和过多感叹号。 - 结构要求:逻辑流畅、善用小标题、列表、加粗关键点、自然过渡句。 - 代码处理:每段重要代码后必须配以详细解释(这段代码做什么、为什么这样写、实际使用时的注意事项)。 - 读者导向:以中高级开发者为目标,让读者读完后感到“学到了可立即应用的内容”。- Input JSON 示例(主控需构造):``` json { "outline": {...}, "research_notes": "...(结构化研究内容)", "writing_style": { "tone": "专业、友好、指导性,像一位经验丰富的开发者在分享实战干货", "language": "清晰通俗、严谨但不晦涩,避免夸张词和网络流行语", "structure": "逻辑流畅、善用小标题、列表、加粗关键点、自然过渡句", "code_explanation": "每段重要代码后必须配以详细解释(做什么、为什么这样写、注意事项)", "forbidden": ["夸张词", "网络流行语", "惊人", "颠覆"] }, "word_count_target": 3500 } ```**环节4: 技术准确性审查**- Subagent Role: TechReviewerAgent - Goal: 校验技术事实、代码正确性,给出修正建议。 - Input: draft - Output: issues, verified**环节5: 语言编辑与优化**- Subagent Role: EditorialAgent - Goal: 优化流畅性、连贯性、可读性,保持技术准确。 - Input: 审查后稿件 - Output: polished_draft, readability_score**环节6: 视觉元素生成**- Subagent Role: VisualDesignerAgent - Goal: 为需要视觉的位置生成精确的图像生成 prompt,并提供 Markdown 插入占位代码。 - Input: polished_draft + og_image_prompt - Output: images (section, image_prompt, alt_text, markdown_placeholder)**环节7: 最终合成与发布准备**- Subagent Role: PublisherAgent - Goal: 合并所有输出,生成最终 Markdown,添加参考文献等。 - Input: 所有前序输出 - Output: final_blog_md, publish_ready, suggested_platforms**执行顺序:**严格按 1→7 顺序执行。每个环节完成后,将结果传递给下一个环节。3.4 在AGENTS.md中定义其它约束
为了避免 orchestrator Agent以预期之外的方式来写作,我们还需要再定义一些其它规则。
...## Subagent 管理规则- 所有subagent 通过 spawn_subagent 机制以临时方式调用。- 主 Agent 只负责参数解析、风格注入、结果合并与流程控制,不得替代任何 subagent 的具体工作。## 通用规则- 始终优先使用文件系统持久化信息。- 保持上下文精简,只加载当前 workflow 需要的部分。- 如果用户需求模糊,主控 Agent 可先澄清必要信息后再启动 workflow。## 铁律:写作任务必须走 Workflow**所有写作类任务(技术博客、文章、文档等)必须严格遵循 blog-creation-workflow,禁止跳过任何中间环节。**每次接收到写作任务时:1. 立即识别为 blog-creation-workflow 触发2. 按顺序执行 环节1→7,不漏环节、不合并环节3. 主 Agent 只协调,不自己写内容第四章:实际运行效果
下达指令后的响应:

启动工作流:

完成时的汇报
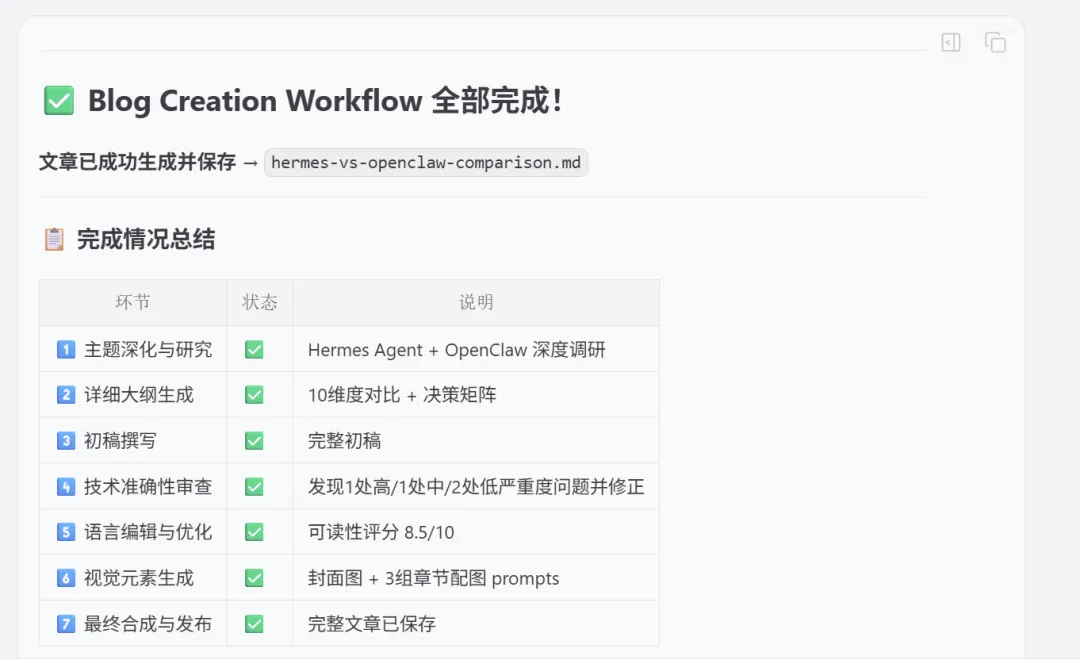
第五章:不足之处
openclaw 的 blog_orchestrator agent在写作完一篇文章后,虽然各个sub agent已经完成任务,并且终止了,但它们的session还残留在系统中。 写了几篇文章之后,openclaw的web界面中,session选择框内会有一大堆无效的session,而且openclaw似乎没有(也可能是我没有找到)清除这些session的指令,这使Openclaw的Web界面看起来很别扭。 不过,我最终还是找到了一个不那么自动化的办法去清除这些session。具体做法如下:
先找到并进入 ~.openclaw/agents/<agentId> 目录 然后打开其中的sessions目录 再用文本编辑器打开 目录中的sessions.json文件 在文本编辑其中搜索文件中所有的subagent的session节点,用subagent做关键字在文件内搜索,类似于“agent: :subagent:0e6a15aa-76bd-400d-81d5-7e10591cd024” 这样的节点就是subagent的session节点 删除这些session节点,然后保存
这样你就能彻底删除sub agent相关的session了。
结尾
如果你按照本文的步骤实操,应该能够在半天内跑通一条基础的内容创作流水线。研究Agent负责素材搜集,提纲Agent负责初稿大纲生成,写作Agent负责初稿生成,编辑Agent负责润色,终审Agent负责质量把控——每个环节各司其职,通过Orchestrator串联成一条高效的内容生产链路。在后续迭代中,你可以基于生产数据持续优化每个Agent的配置,逐步提升流水线的能力边界。
