夜雨聆风
夜雨聆风LG - 机器学习 CV - 计算机视觉 CL - 计算与语言
1、[CL] ClawBench:Can AI Agents Complete Everyday Online Tasks?
2、[CL] MARS:Enabling Autoregressive Models Multi-Token Generation
3、[CV] LoMa:Local Feature Matching Revisited
4、[CL] MegaTrain:Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU
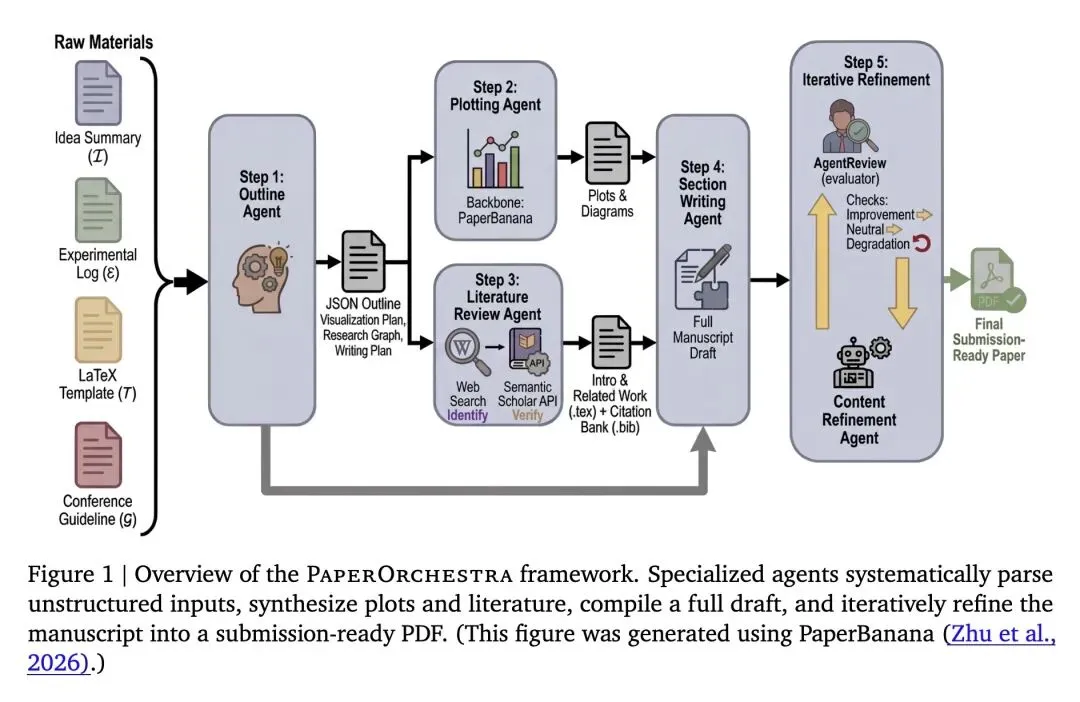
5、[LG] PaperOrchestra:A Multi-Agent Framework for Automated AI Research Paper Writing
摘要:AI智能体能否胜任日常线上任务、实现自回归模型的多Token生成、重新审视局部特征匹配、单GPU实现千亿级参数大语言模型全精度训练、面向AI研究论文自动化写作的多智能体框架
1、[CL] ClawBench: Can AI Agents Complete Everyday Online Tasks?
Y Zhang, Y Wang, Y Zhu, P Du…
[University of British Columbia & Vector Institute]
ClawBench:AI智能体能否胜任日常线上任务?
要点:
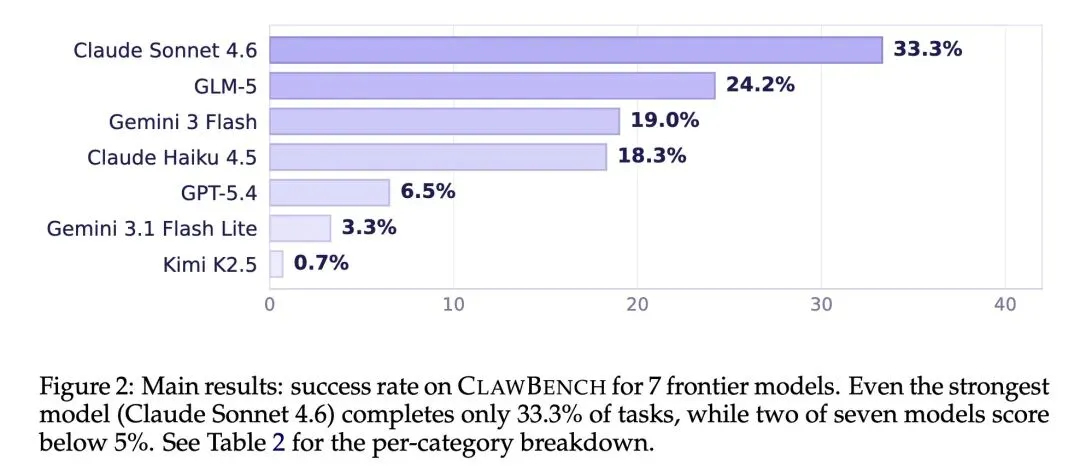
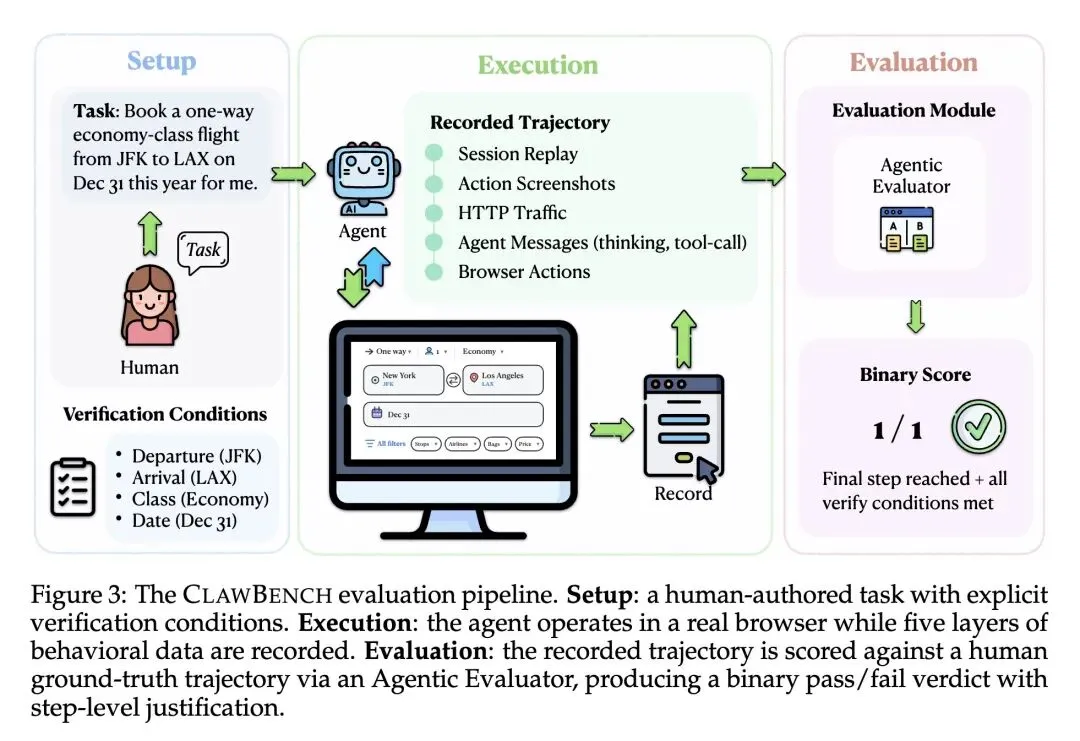
反直觉观点:打破了当前Web智能体能力已高度成熟的错觉。实证表明,在离线沙箱基准(如OSWorld和WebArena)中得分高达65-75%的前沿大模型,在真实的日常网页操作中遭遇滑铁卢,成功率暴跌至0.7%到33.3%之间。 推出了 CLAWBENCH 基准,包含在144个真实生产环境下运行的153个日常任务,首次将测试核心聚焦于“重写入(write-heavy)”和改变状态的操作(如预订机票、提交求职申请),而非简单的只读信息检索。 高信息熵设计:通过巧妙的“最终请求拦截”机制解决了在真实网站上进行安全测试的悖论。系统放弃了传统的离线沙箱,让智能体在真实的动态网页上自由操作,但利用Chrome插件和CDP服务器精准拦截并阻断最终提交的那个HTTP请求,从而在体验100%真实网页环境的同时实现零副作用。 构建了“五层记录基础设施”,同步捕获会话视频回放、每步动作截图、底层HTTP流量、智能体消息(思维链)和浏览器底层动作,形成高密度的多模态行为轨迹。 引入“Agentic Evaluator(智能体评估器)”,不依赖简单的最终状态检查,而是利用大模型子代理,将智能体的五层运行轨迹与人类专家的基准轨迹进行细粒度的步骤对齐和比对打分。 对7个前沿模型进行了深度评测:表现最好的 Claude Sonnet 4.6 成功率仅为 33.3%,而 GPT-5.4 仅有 6.5%。这深刻揭示了当前模型在应对真实世界的Cookie弹窗、动态渲染、反爬虫机制等复杂交互时仍然极其脆弱。 测试结果表明,当前AI缺乏统一的通用网页操作能力,存在严重的“偏科”(例如Claude擅长日常和金融任务,而GLM-5更擅长工作类任务)。
主旨: 本文旨在评估和揭示当前最前沿的 AI 智能体在真实、动态的日常网页任务中的实际表现。针对现有基准测试由于过度依赖静态沙箱或仅测试“只读”任务而导致的“模型能力虚高”问题,提出了一种全新的在真实网站上安全评估“重写入(状态改变)”任务的框架,以真实反映通往通用网络助手的技术鸿沟。
创新:
无副作用的真实环境拦截机制:放弃了耗时且脱离现实的“网页克隆/沙箱化”传统路线。创新性地采用 HTTP 流量监控,通过人工标注拦截端点,让 Agent 在真实的生产网站上操作,但在最后一步“拔掉网线”(仅拦截不可逆的最终提交请求),兼顾了绝对的真实性和百分之百的安全性。 基于五层模态数据的人机轨迹对比评估:创新性地设计了不仅看结果、更看过程的“五层数据记录”体系(视频、截图、网络请求、推理日志、浏览器事件),并利用 LLM 裁判将智能体轨迹与人类专家的完美基准轨迹进行多维度的跨模态对齐和判分。
贡献:
构建并开源了 CLAWBENCH:首个专注于真实网站上“重写入”复杂操作的 Web Agent 测试基准,涵盖15个生活类别的153个高频日常任务。 提出了针对真实网页自动化评测的通用基础设施方案,包括轻量级数据捕获架构和基于人类锚点的智能评估管道。 提供了极其详实的失败归因分析,用数据有力地证明了“实验室高分”到“真实世界可用”之间存在巨大鸿沟,为下一代具身智能和 Web Agent 的研究重新校准了方向。
提升:
生态有效性(Ecological Validity)的大幅提升:使得评测环境完全容纳了真实世界中不可预测的变量(如动态广告、随机出现的同意弹窗、复杂的双因素认证前置逻辑),这是传统静态 HTML 沙箱完全无法提供的测试维度。 评测颗粒度和可解释性的提升:将传统的二元“通过/失败”结果,升级为具备深度故障诊断能力的轨迹对齐评估。开发者可以通过五层记录精准定位 Agent 是“看错了”、“想错了”还是“点歪了”。
不足:
数据规模和构建成本:由于需要人类专家录制每个任务的完美多模态基准轨迹,并手动抓包标注那个“需要被拦截的最终HTTP接口”,导致基准的扩展成本极高,目前仅包含153个任务。 自动化裁判自身的局限性:尽管 Agentic Evaluator 融合了多种判定规则和跨模态证据,但其核心仍依赖 Claude Code 进行判定。大模型作为裁判在面对极其复杂的长轨迹对比时,依然存在产生幻觉或过度苛刻/宽松的风险。 平台动态变化的维护挑战:因为依赖真实的 live websites,当目标网站前端架构大改或下线时,相关任务就会失效,这要求基准本身需要高频的持续维护。
心得:
“沙箱高分”陷阱值得警惕:当模型在受控基准测试(如OSWorld)中拿到 70% 的分数时,往往给人一种 AGI 即将到来的错觉。但真实世界充满了脏数据和不可控的边缘情况。这启发我们在评估 AI 时,绝不能脱离其最终部署的混沌环境,“真实度”应该成为衡量 Benchmark 价值的第一指标。 “只拦截最后一击”的极简解题哲学:为了测试“下订单”的能力而不真的花钱,传统思维是搭建一套以假乱真的电商系统(成本极高)。本文则采取了四两拨千斤的黑客思路:让一切真实发生,只是在数据包发给服务器的前一秒拦截它。这种“过程完全放行,只掐断结果”的思路,可以被广泛借鉴到所有具风险的 AI Agent 测试场景中(如金融交易、数据库操作)。 可追溯的“过程数据”是下一步突破的关键:文章设计的五层记录机制极具启发性。Agent 的进化不能仅靠打分,而是需要知道错在哪里。保留包括底层坐标、网络请求和思维链在内的完整“黑匣子”数据,为基于反馈的强化学习(RLHF/RLAIF)提供了最宝贵的富文本微调信号。
一句话总结: 本文创新性地提出了一种“过程完全真实、仅拦截最终HTTP提交请求”的巧妙机制,构建了首个在真实生产网站上测试“修改型/写入型”复杂任务的智能体基准 CLAWBENCH,并无情戳破了当前 Web Agent 的能力泡沫——实证表明,在沙箱测试中表现优异的顶尖大模型,面对充满动态交互的真实日常网页时,最高成功率也仅有 33.3%。
AI agents may be able to automate your inbox, but can they automate other routine aspects of your life? Everyday online tasks offer a realistic yet unsolved testbed for evaluating the next generation of AI agents. To this end, we introduce CLAWBENCH, an evaluation framework of 153 simple tasks that people need to accomplish regularly in their lives and work, spanning 144 live platforms across 15 categories, from completing purchases and booking appointments to submitting job applications. These tasks require demanding capabilities beyond existing benchmarks, such as obtaining relevant information from user-provided documents, navigating multi-step workflows across diverse platforms, and write-heavy operations like filling in many detailed forms correctly. Unlike existing benchmarks that evaluate agents in offline sandboxes with static pages, CLAWBENCH operates on production websites, preserving the full complexity, dynamic nature, and challenges of real-world web interaction. A lightweight interception layer captures and blocks only the final submission request, ensuring safe evaluation without real-world side effects. Our evaluations of 7 frontier models show that both proprietary and open-source models can complete only a small portion of these tasks. For example, Claude Sonnet 4.6 achieves only 33.3%. Progress on CLAWBENCH brings us closer to AI agents that can function as reliable general-purpose assistants.
https://arxiv.org/abs/2604.08523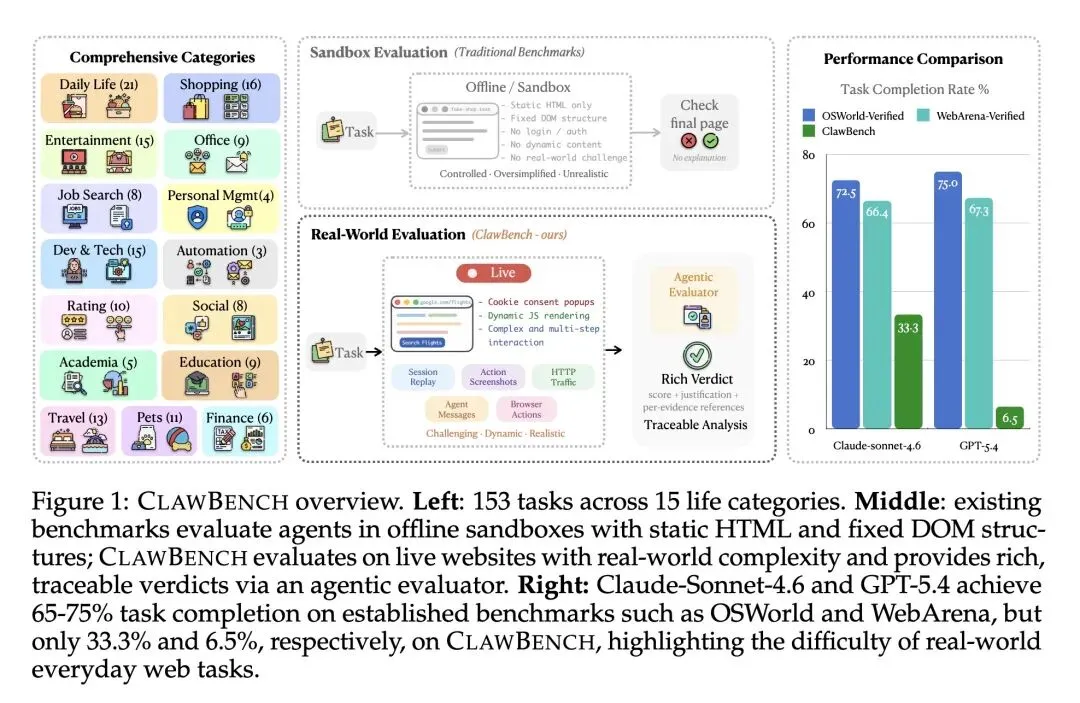
2、[CL] MARS: Enabling Autoregressive Models Multi-Token Generation
Z Jin, L Wang, Z Luo, A Sun
[Nanyang Technological University & Singapore Management University & Uppsala University]
MARS:实现自回归模型的多Token生成
要点:
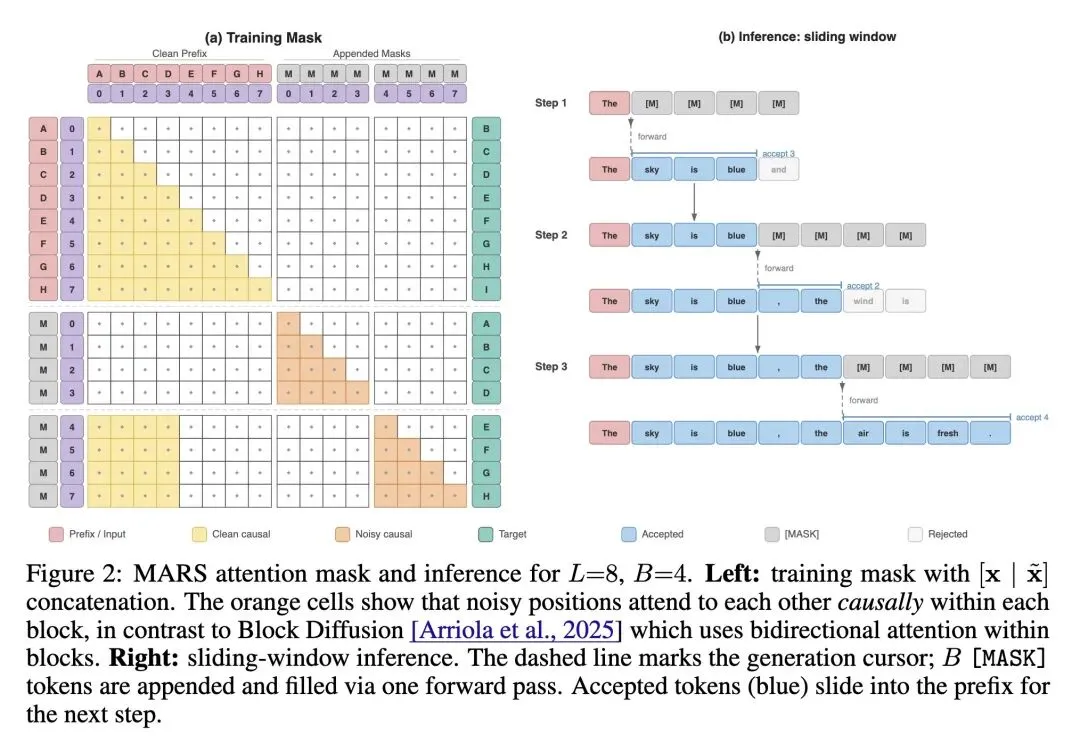
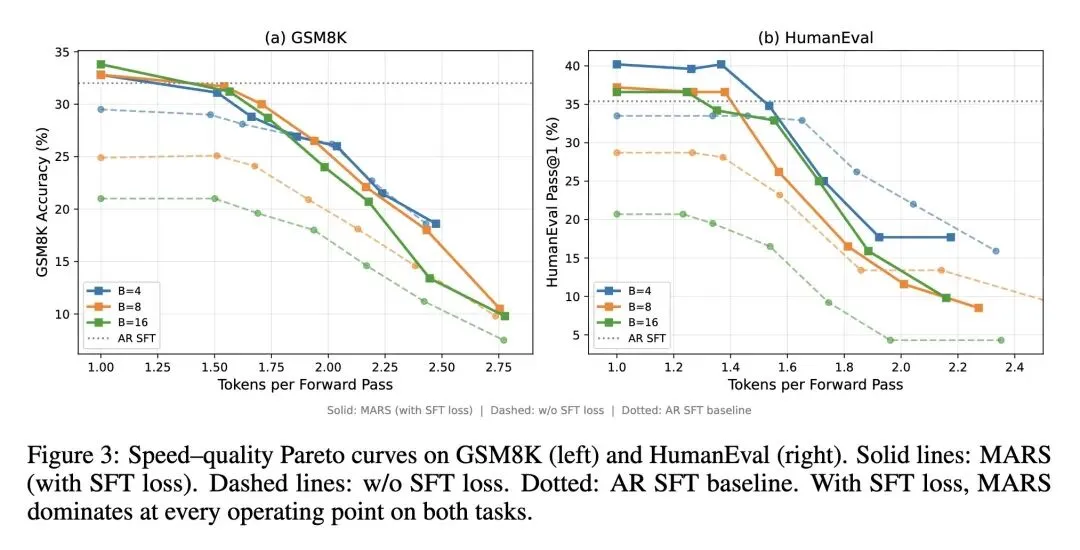
挑战并行生成的架构现状:证明了多Token生成根本不需要辅助草稿模型(如投机解码)或修改架构/增加预测头(如Medusa)。MARS仅通过对标准自回归(AR)模型进行轻量级微调即可实现这一点。 打破文本扩散中的“双向注意力”迷思(高反直觉):揭示了从视觉扩散模型继承而来的双向注意力,正是导致AR模型在适应块掩码预测时质量崩溃的罪魁祸首。严格的因果注意力(Causal Attention)完全兼容并行生成,并且能保留模型的推理能力。 双流并行训练创新:设计了一种自定义注意力掩码,在一次前向传播中同时处理“干净流”(标准AR)和“噪声流”(包含[MASK]占位符的块),强制执行右移对齐和严格的因果关系。 关于AR能力衰减的高信息熵发现:发现纯粹的块掩码训练会随着块大小的增加呈指数级破坏模型的AR能力(以 衰减)。解决该问题的“银弹”是在干净流上保持辅助的SFT(标准微调)损失,这能将AR信号比例稳定在50%以上,使得AR能力与掩码块大小彻底解耦。 掩码预测具备数据增强的奇效(反直觉):如果只是单纯延长AR模型的训练轮数,会导致过拟合和性能下降;但在相同算力预算下,MARS的掩码训练反而起到正则化/数据增强的作用,实际上提升了模型单Token模式的基础准确率(例如0.5B模型在HumanEval上提升4.8个点)。 极具工程优雅性的动态部署:MARS产出的单一模型是基线AR模型的“严格超集”。它引入了一个置信度阈值 ,可在服务时针对每个请求进行热切换,无需重启或更换模型—— 时是完美的无损AR生成,降低 则能无缝加速高确定性Token的生成。 跨越真实挂钟时间的鸿沟:纯算法层面的“每次前向Token数”提升在实际部署中常因KV-Cache重计算而失效。MARS引入了块级(Block-level)KV缓存策略,在Qwen2.5-7B的批处理推理中证明了高达1.71倍的真实挂钟时间加速。
主旨: 本文旨在解决自回归(AR)语言模型逐个生成Token导致推理效率低下的问题,同时避免现有方法(如投机解码或多头预测)带来的额外模型参数、架构修改或部署复杂性。为此,论文提出了一种名为 MARS (Mask AutoRegreSsion) 的微调方法,让标准AR模型学会处理[MASK]占位符,从而在单一前向传播中根据置信度自适应地生成多个Token,实现“零架构修改”的无损加速。
创新:
零架构修改的多Token生成:不增加任何额外的预测头或网络层,完全复用原有的语言模型头(LM Head),通过引入 [MASK] 占位符实现未来多步的并行预测。 双流因果注意力掩码设计:在训练阶段设计了巧妙的 Attention Mask,将“无掩码的因果预测”与“有掩码的块内因果预测”拼接在同一个序列中进行联合优化,彻底消除了AR模型与掩码预测之间的架构代沟。 基于置信度的滑动窗口推理:设计了一种从左到右的动态滑动窗口推理机制,通过单一参数 (Token预测概率)控制接受的Token数量,实现了单Token与多Token模式的丝滑切换。 块级 KV 缓存机制 (Block-level KV Cache):针对批处理(Batching)推理,设计了块边界对齐的KV缓存更新策略,解决了并行生成时 O(T²) 的重计算开销问题。
贡献:
理论分析贡献:深入剖析了自回归模型与块扩散(Block Diffusion)模型之间的4个差异,指出其中3个(双向注意力、对齐方式、生成顺序)是可消除的非必要设计,纠正了以往研究盲目引入双向注意力导致模型变笨的误区。 训练方法贡献:提出了 MARS 微调框架,特别是发现了“干净流SFT损失”在对抗大尺寸掩码块带来的AR能力衰减中起到的决定性作用。 工程实践贡献:提供了一个极具实用价值的开箱即用方案。只需微调一次,即可得到一个兼顾极致质量(1-token模式)和高吞吐量(Multi-token模式)的单一模型,极大地降低了工业界部署多Token生成的门槛。
提升:
单Token模式(质量提升):在不开启加速()时,模型能力不仅没有下降,反而略有提升。在6个标准基准上,0.5B模型平均分提升1.7,7B模型平均分提升1.5。 多Token模式(算法吞吐量):在几乎不损失精度()的情况下,每次前向传播可生成 1.5 到 1.7 个Token。 真实系统加速比(Wall-clock):结合块级KV缓存,Qwen2.5-7B在GSM8K任务上实现了高达 1.71倍 的真实挂钟时间加速。
不足:
训练开销翻倍:由于训练时需要将“干净流”和“噪声流”拼接在一起,序列长度翻倍,导致显存占用和训练计算量相比标准SFT增加了约一倍。 低置信度下的质量惩罚:如果为了追求极致速度而将置信度阈值设置得过于激进(例如 ),模型的准确率会出现显著的滑坡。 大Batch Size下的吞吐量瓶颈:块级KV缓存需要在块边界处对整个Batch进行同步(等待最慢的样本),这使得在非常大的Batch Size下,并行加速带来的收益会被同步开销所抵消。
心得:
“去伪存真”的架构思考:这篇论文最精彩之处在于剥离了文本扩散模型身上的“视觉模型历史包袱”。仅仅因为扩散模型在图像(双向/全局信息)中表现良好,此前的研究者就盲目地将双向注意力引入大语言模型,结果严重破坏了LLM原本预训练建立的因果推理逻辑。本文回归第一性原理,证明了“多Token并行”与“严格因果注意力”完全不冲突,这对未来如何将其他领域的算法移植到LLM提供了极其深刻的教训。 困难任务即最佳的正则化(Data Augmentation via Masking):一个高度反直觉的发现是,给模型增加[MASK]让它去“盲猜”未来的Token,不仅没有破坏它,反而让它的标准逐字生成能力变得更强(避免了单纯延长SFT导致的过拟合)。这启示我们,在数据耗尽的今天,通过在输入端制造结构性困难(如掩码预测),是一种极具潜力的LLM自我进阶和正则化手段。 对工业部署极其友好的极简主义:目前AI学术界非常喜欢提出复杂的架构(如各种外挂验证器、多头推理解码器),但工业界极其厌恶非标的架构,因为这意味着要重写底层的CUDA算子或推理引擎(如vLLM)。MARS的伟大在于其工程品味——完全不改架构,只通过权重微调和外部软件逻辑(阈值控制)就实现了目的。这种“不给Infra工程师添堵”的研究,是最容易在业界大规模落地的。
一句话总结: MARS 是一种“零架构修改”的微调方法,它通过引入包含掩码的因果双流训练,让标准自回归大模型学会了一次前向传播生成多个Token的能力;该方法不仅在单步生成时无损甚至反超基线模型,还能通过一个简单的置信度阈值,在实际部署中动态实现高达1.71倍的真实挂钟推理加速。
Autoregressive (AR) language models generate text one token at a time, even when consecutive tokens are highly predictable given earlier context. We introduce MARS (Mask AutoRegreSsion), a lightweight fine-tuning method that teaches an instruction-tuned AR model to predict multiple tokens per forward pass. MARS adds no architectural modifications, no extra parameters, and produces a single model that can still be called exactly like the original AR model with no performance degradation. Unlike speculative decoding, which maintains a separate draft model alongside the target, or multi-head approaches such as Medusa, which attach additional prediction heads, MARS requires only continued training on existing instruction data. When generating one token per forward pass, MARS matches or exceeds the AR baseline on six standard benchmarks. When allowed to accept multiple tokens per step, it maintains baseline-level accuracy while achieving 1.5–1.7× throughput. We further develop a block-level KV caching strategy for batch inference, achieving up to 1.71× wall-clock speedup over AR with KV cache on Qwen2.5-7B. Finally, MARS supports real-time speed adjustment via confidence thresholding: under high request load, the serving system can increase throughput on the fly without swapping models or restarting, providing a practical latency–quality knob for deployment.
https://arxiv.org/abs/2604.07023
3、[CV] LoMa: Local Feature Matching Revisited
D Nordström, J Edstedt, G Bökman, J Astermark…
[Chalmers University of Technology & Linköping University & University of Amsterdam]
LoMa:重新审视局部特征匹配
要点:
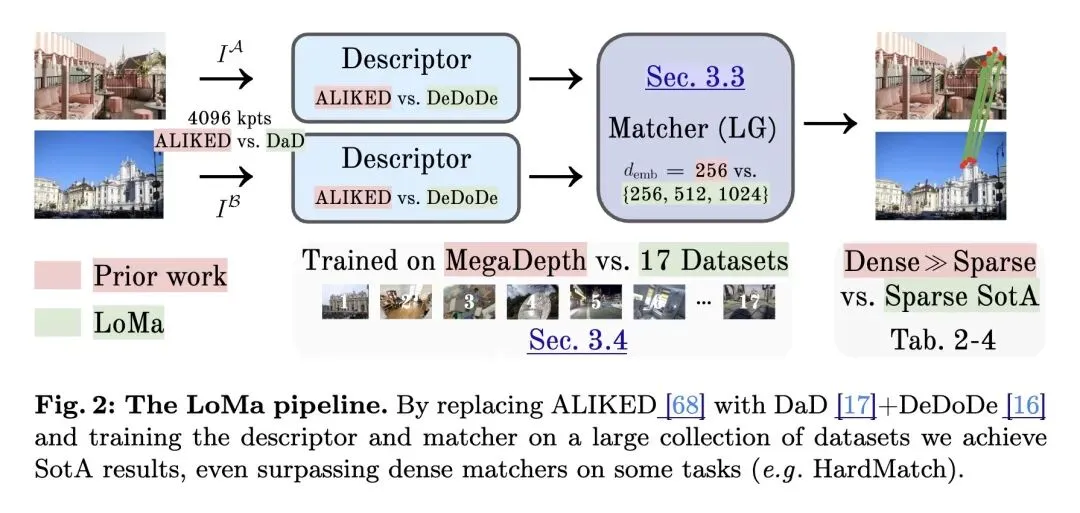
挑战了当前3D视觉界的主流叙事:即认为传统的局部特征匹配(检测器+描述子)已经过时,且其潜力远不如现代的密集匹配(Dense Matchers)或端到端前馈3D重建大模型。 高信息熵发现(基准测试中的“幸存者偏差”):深刻揭示了现有评估基准(如MegaDepth和ScanNet)的致命缺陷。由于这些数据集是由已经成功跑通的SfM(运动恢复结构)生成的,它们天然排除了真正困难的图像对,导致测试集容易饱和,给人一种模型能力已经很强的错觉。 推出了 HardMatch 极端数据集,包含1000对纯手工标注的极难匹配图像(涵盖日夜对比、手绘图与实景、跨越百年的同一场景等),彻底打破了依赖SfM生成基准的幸存者偏差。 提出了 LoMa 框架,其核心不在于发明全新的网络架构,而是将现代的“Scaling Law”(扩展包含17个数据集的庞大混合数据、提升模型容量至1024维、采用现代训练配方)成功应用到现有的组件(DaD + DeDoDe + LightGlue)上。 反直觉结果:一旦获得了与现代模型同等规模的大数据和算力加持,轻量级的“稀疏局部特征匹配器”在极端匹配任务上的表现,实际上能够反杀并超越计算密集的密集匹配器(如RoMa)和庞大的前馈重建模型(如MASt3R)。 训练洞察:扩大匹配器(Matcher)的训练规模和时间能带来持续的性能增长,但如果将描述子(Descriptor)训练过久,反而会令人意外地导致过拟合。 实现了断层式的性能飞跃:在 HardMatch 上碾压前代 SOTA (ALIKED+LightGlue) 达 18.6 mAA,在 WxBS 上提升 29.5 mAA,并击败了 IMC 2022 赛事的冠军集成模型。
主旨: 本文旨在重新审视并复兴传统的“局部特征匹配”范式。针对当前评估基准过于简单(存在幸存者偏差)以及稀疏匹配方法未能享受到大规模数据和算力扩展红利的问题,作者构建了极具挑战性的全手工标注新基准(HardMatch),并通过大规模多样化数据、提升模型容量和现代训练配方,训练出了LoMa系列模型。文章用绝对的性能指标证明了:在数据驱动的现代范式下,经典的局部特征匹配非但没有“死”,反而能超越最前沿的密集匹配与前馈重建大模型。
创新:
评测视角的降维打击:没有沿用依赖自动化 SfM 算法生成 Ground Truth 的常规套路,而是采用极费人力但绝对客观的“纯手工标注极端困难样本”,创造了零“幸存者偏差”的 HardMatch 基准,重新定义了特征匹配的“天花板”。 拥抱 Scaling Law 的工程创新:没有沉迷于设计花哨的新型注意力机制或网络架构,而是极具工程智慧地整合了目前最优的组件(DaD关键点、DeDoDe描述子、LightGlue匹配器),通过精细构建涵盖17个来源(包含合成、无人机、室内外等)的巨型 3D 数据集,证明了“Data & Scale”在传统架构上的奇效。
贡献:
数据集贡献:构建并完全开源了极具挑战性的图像匹配基准 HardMatch,为未来 3D 视觉和图像匹配研究提供了真正具有区分度和极高难度的试金石。 模型库贡献:发布了 LoMa 系列特征匹配模型(涵盖 Base, Large, Gigantic 及轻量级的 B128),为学术界和工业界提供了速度极快且精度霸榜的开箱即用工具。 方法论与配方贡献:开源了一整套现代化的特征匹配数据混合配方与训练策略,为如何利用多源 3D 数据训练稀疏匹配器提供了极具价值的参考基线。
提升:
极限匹配能力:在极具挑战的 HardMatch 基准上,LoMa-G 相比此前的 SOTA (ALIKED+LightGlue) 实现了 +18.6 mAA 的断层式提升;在 WxBS 极宽基线数据集上提升了 +29.5 mAA。 视觉定位与相对位姿估计:在 InLoc 数据集最严格的阈值 (1m, 10°) 下提升了 +21.4%;在 RUBIK 基准上提升了 +24.2 AUC。 现实竞赛级表现:在著名的 Image Matching Challenge (IMC) 2022 盲测数据集上,提升了 +12.4 mAA,甚至大幅超越了当年的冠军多模型集成方案。
不足:
描述子的 Scaling 瓶颈:实验发现,虽然匹配器模块(Matcher)完美契合了规模法则(Scaling Law),但对描述子(Descriptor)进行大规模长时间的训练极易陷入过拟合,这表明描述子的特征表达在现有架构下存在容量上限。 特定极端长尾场景依然困难:尽管 LoMa 超越了所有前人,但在 HardMatch 中某些极端子分类(如高度相似的“多重影/Doppelgänger”场景、接近180度的极端视角变化)上,模型的绝对准确率依然有很大的提升空间。 新基准的固有偏差:尽管 HardMatch 努力做到多样化,但在地理分布(偏向欧洲)和时间分布(偏向21世纪)上,仍然带有互联网抓取数据不可避免的统计学偏差。
心得:
“架构创新”并非唯一解,给老树浇新水往往会开花:当某个经典方法(如稀疏匹配)被新范式(如端到端密集重建)全面压制时,很多时候不是经典方法的架构落后了,而是它没有享受到同等量级的大数据和算力红利。LoMa 的成功是对“大力出奇迹 (Data & Scale)”在经典计算机视觉管线中依然奏效的精彩证明。 警惕自动化评测基准的“隐性偏见”:文章对传统基准的批判极其犀利——如果 Ground Truth 是用现成算法算出来的,那你永远只能测出“现有算法能解决的问题”。这启示我们,在设计评估系统时,必须跳出自动化生成的舒适区,走向真实世界的 Corner Cases,哪怕这意味着要回归昂贵的手工标注。 解耦设计的工业级生命力:近年来学术界极力推崇端到端大模型(End-to-End),贬低“检测-描述-匹配”这种三段式的解耦设计。但 LoMa 证明,这种解耦设计带来的极高推理效率(单卡每秒处理数百对图像)结合大规模数据微调带来的高精度,其在实际工程落地中的“综合性价比”是那些算力消耗惊人的端到端模型短期内难以企及的。
一句话总结: 本文打破了“局部稀疏特征匹配已被淘汰”的偏见,通过构建消除了幸存者偏差的手工标注极端测试集(HardMatch),并利用大规模多样化数据和算力扩展重塑了经典匹配架构(LoMa),证明了在现代数据加持下,轻量级的稀疏匹配依然能以极高的效率全方位碾压庞大的密集匹配与端到端 3D 重建大模型。
Local feature matching has long been a fundamental component of 3D vision systems such as Structure-from-Motion (SfM), yet progress has lagged behind the rapid advances of modern data-driven approaches. The newer approaches, such as feed-forward reconstruction models, have benefited extensively from scaling dataset sizes, whereas local feature matching models are still only trained on a few mid-sized datasets. In this paper, we revisit local feature matching from a datadriven perspective. In our approach, which we call LoMa, we combine large and diverse data mixtures, modern training recipes, scaled model capacity, and scaled compute, resulting in remarkable gains in performance. Since current standard benchmarks mainly rely on collecting sparse views from successful 3D reconstructions, the evaluation of progress in feature matching has been limited to relatively easy image pairs. To address the resulting saturation of benchmarks, we collect 1000 highly challenging image pairs from internet data into a new dataset called HardMatch. Ground truth correspondences for HardMatch are obtained via manual annotation by the authors. In our extensive benchmarking suite, we find that LoMa makes outstanding progress across the board, outperforming the state-of-the-art method ALIKED+LightGlue by +18.6 mAA on HardMatch, +29.5 mAA on WxBS, +21.4 (1m, 10◦) on InLoc, +24.2 AUC on RUBIK, and +12.4 mAA on IMC 2022. We release our code and models publicly at https://github.com/davnords/LoMa.
https://arxiv.org/abs/2604.04931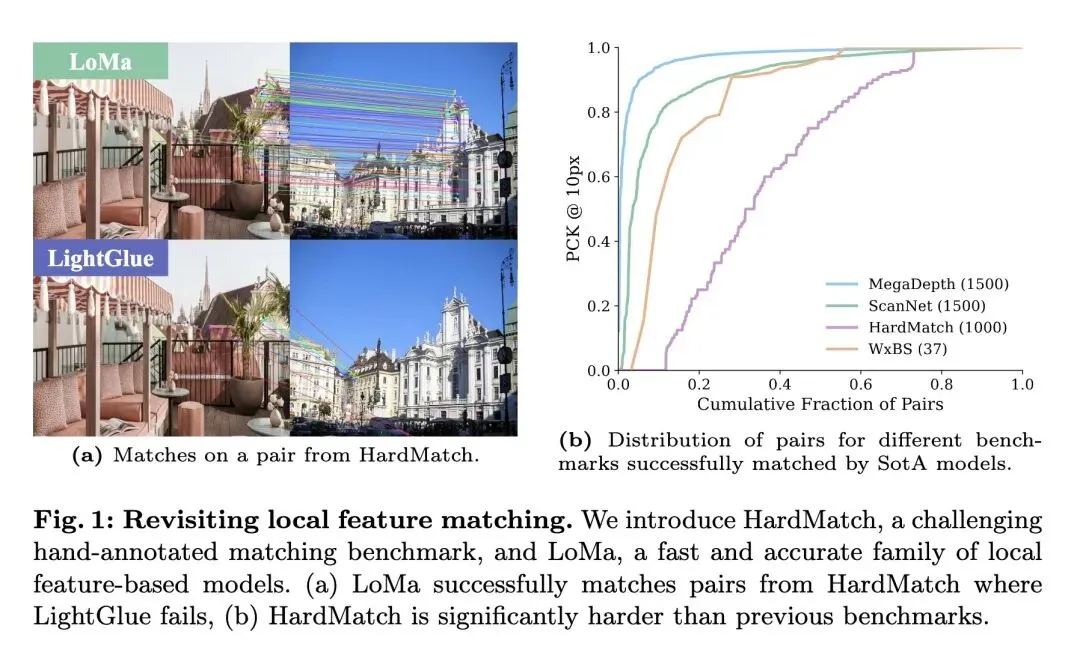

4、[CL] MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU
Z Yuan, H Sun, L Sun, Y Ye
[University of Notre Dame & Lehigh University]
MegaTrain:单GPU实现千亿级参数大语言模型全精度训练
要点:
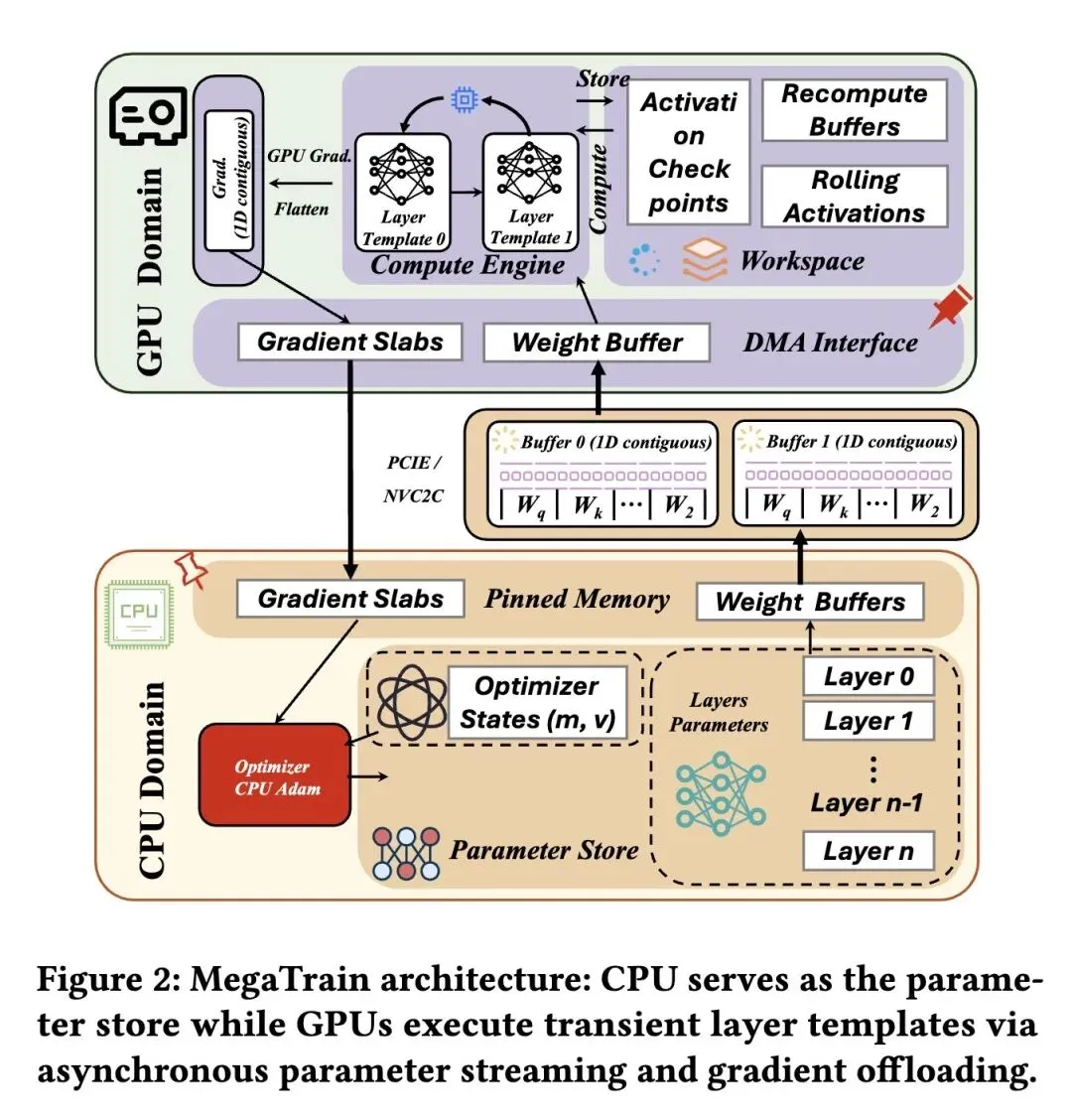
反直觉的范式转变(GPU沦为“瞬态缓存”):打破了传统的“以GPU为中心”的训练模式。与ZeRO-Offload将CPU内存视为“临时垃圾桶”不同,MegaTrain将CPU内存作为参数和优化器状态的“永久驻地”,而将极其昂贵的GPU仅仅视为一个“瞬态计算引擎”(类似于高级L4缓存)。 高信息熵创新(抛弃全局计算图):PyTorch标准的Autograd会构建庞大的全局计算图,其底层假设是“参数始终在GPU上”。而在逐层流式传输下,这一假设会直接崩溃。MegaTrain激进地彻底抛弃了全局计算图,首创“无状态执行模型(Stateless Execution Model)”——在GPU上预留空壳“层模板”,让流式输入的权重动态绑定。这完全消除了图元数据的内存开销,确保GPU显存占用永远不超过单个Transformer层的规模。 破解PCIe带宽瓶颈(流水线双缓冲):设计了3条CUDA流(计算、主机到设备、设备到主机)协同的乒乓缓冲系统。完美实现了参数预取、GPU计算和梯度卸载的完全重叠,从而在流式传输下依然保证GPU算力单元永不闲置。 层级连续内存平铺:摒弃了传统的碎片化张量分配,将权重、梯度和Adam动量打包成4KB对齐的单块连续内存。这使得系统能够发出单次突发DMA传输,彻底榨干PCIe/NVLink的理论物理带宽。 优化器全面回归CPU:Adam更新完全在CPU上(利用AVX-512等指令集)执行。反直觉的是,对于Adam这种“访存密集、计算稀疏”的操作,在CPU上执行比在GPU上执行更快,因为它避免了将庞大的参数、梯度和动量在PCIe上进行昂贵的往返搬运。 单卡训练规模的突破:在单张H200(配备1.5TB主机内存)上成功实现了120B参数模型的全精度训练;在32B模型上,当ZeRO-3直接OOM时,MegaTrain仍能维持>250 TFLOPS的算力;甚至能在单卡上支持7B模型高达512K token的超长上下文训练。
主旨: 本文旨在解决如何在单张GPU上进行千亿(100B+)参数大语言模型全精度训练(特别是微调)的难题。面对显存容量的硬性限制以及现有卸载(Offloading)方案中存在的内存碎片、通信阻塞等问题,文章提出了一种“以内存为中心”的系统MegaTrain,通过重构GPU与CPU的存储角色定位、流水线流式通信以及无状态执行模型,打破了显存容量对模型规模的限制。
创新:
彻底的存算分离与角色反转:将CPU内存作为第一级主力存储,GPU显存降级为流式计算的临时缓存,实现了模型参数量与GPU显存容量的彻底解绑。 无状态模板绑定(Stateless Template Binding):摒弃了深度学习框架依赖的驻留显存的Autograd计算图,改为在GPU上建立空壳计算模板。权重流式进入时动态绑定指针,计算完成后立即释放,消除了框架层的内存元数据冗余。 全异步三流流水线(3-Stream Pipeline):精心设计了CUDA事件驱动的计算流、参数加载流(H2D)和梯度卸载流(D2H),配合双缓冲区(Double-Buffering),完美掩盖了数据在主板和显卡之间搬运的延迟。
贡献:
提出并开源了MegaTrain系统,证明了在单节点/单GPU环境下进行百B级模型全精度训练不仅可行,而且可以保持极高的硬件利用率。 深入剖析并解决了现有ZeRO-Offload等方案在模型深度扩展时暴涨的主机内存开销和通信瓶颈问题。 将单卡极限上下文长度提升至令人瞩目的512K Tokens(7B模型),为长文本后训练提供了极其廉价的单卡解决方案。
提升:
吞吐量(Throughput):在GH200上训练14B模型时,吞吐量达到ZeRO-3 CPU Offloading的1.84倍;在32B模型上持续输出- 显存与主机内存控制:随着模型深度增加(如扩展到180层),ZeRO-3和FSDP的主机内存消耗呈指数级暴涨并崩溃,而MegaTrain的主机内存消耗保持极度平缓的线性增长,完美支持在1.5TB CPU内存下训练120B模型。 消费级显卡适配性:在仅有24GB显存的民用级RTX 3090上,成功以30 TFLOPS的算力训练14B模型(批次大小达到3),而基线方法在Batch Size为1时即OOM。
不足:
主机内存容量依赖:虽然摆脱了显存限制,但将压力完全转移到了主机(CPU)内存上。训练120B模型仍需要1.5TB的DDR内存,这在普通消费级PC上依然不可及。 强依赖CPU算力进行参数更新:由于Adam优化器完全在CPU端执行,如果服务器配置了孱弱的CPU,或者CPU内存带宽不足,优化器更新阶段可能会成为新的长尾瓶颈。 额外的计算开销(激活重计算):为了控制激活值的显存占用,系统采用了分块激活重计算(Block-wise Recomputation)策略。这本质上是用“时间换空间”,不可避免地增加了前向计算的总浮点运算量。 目前仅限于单卡架构:论文当前的实现和评估主要集中在Single GPU上,如何将这种极致的流式引擎与多卡张量并行(TP)或流水线并行(PP)结合,依然是留给未来的工作。
心得:
“拆掉框架的承重墙”才能获得新生:现代AI框架(如PyTorch)的Autograd机制是其成功的基石,但在极端内存受限场景下,这种庞大且静态的计算图反而是最致命的拖累。MegaTrain敢于抛弃原生计算图,采用自己手写的无状态模板绑定,这启示我们:在做系统级底层优化时,任何“约定俗成”的上层抽象都可以被推翻。 重新定义硬件的物理意义:我们习惯性地认为“模型必须装进显存”。但从计算机体系结构(Computer Architecture)的角度来看,GPU显存本质上只是一种带宽极高的L4/L5 Cache。MegaTrain回归了体系结构的本质:只要命中率够高、流水线掩盖得够好,数据完全可以住在远端(CPU DDR)。这为未来突破“显存墙”提供了极具哲学意味的指导。 宏观视角的“通信掩盖”艺术:在异构计算中,数据搬运(PCIe/NVLink)往往是性能毒药。MegaTrain通过极其细致的显存连续化平铺(Flat-Tensor)榨干物理带宽,配合乒乓Buffer掩盖延迟。这告诉我们,不要一味去“减少通信”,而是要学会“把通信藏在计算的阴影里”。
一句话总结: MegaTrain 彻底颠覆了传统的GPU中心化训练范式,将GPU降级为仅包含无状态计算模板的瞬态缓存,并通过极致的三流重叠流水线和内存平铺技术打破了PCIe传输瓶颈,史无前例地实现了在单张GPU上高效进行120B参数大模型全精度训练及512K超长上下文微调。
We present MegaTrain, a memory-centric system that efficiently trains 100B+ parameter large language models at full precision on a single GPU. Unlike traditional GPU-centric systems, MegaTrain stores parameters and optimizer states in host memory (CPU memory) and treats GPUs as transient compute engines. For each layer, we stream parameters in and compute gradients out, minimizing persistent device state. To battle the CPU-GPU bandwidth bottleneck, we adopt two key optimizations. 1) We introduce a pipelined double-buffered execution engine that overlaps parameter prefetching, computation, and gradient offloading across multiple CUDA streams, enabling continuous GPU execution. 2) We replace persistent autograd graphs with stateless layer templates, binding weights dynamically as they stream in, eliminating persistent graph metadata while providing flexibility in scheduling. On a single H200 GPU with 1.5TB host memory, MegaTrain reliably trains models up to 120B parameters. It also achieves 1.84× the training throughput of DeepSpeed ZeRO-3 with CPU offloading when training 14B models. MegaTrain also enables 7B model training with 512k token context on a single GH200.
https://arxiv.org/abs/2604.05091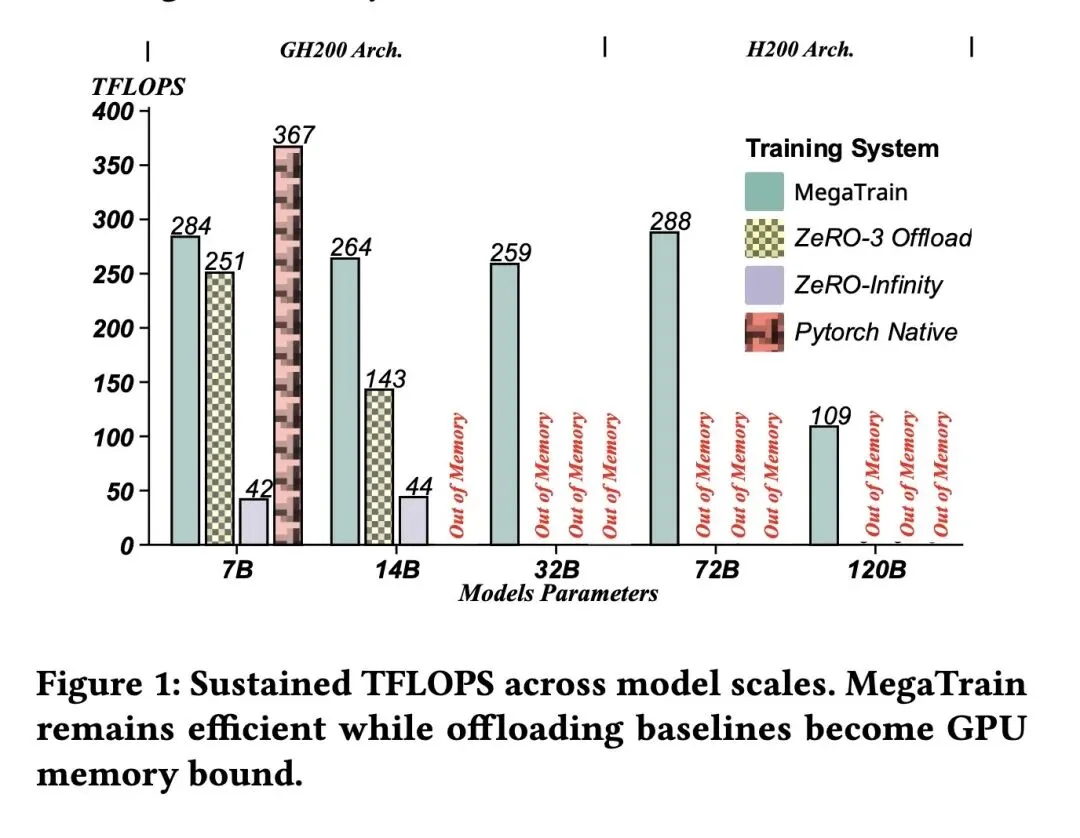
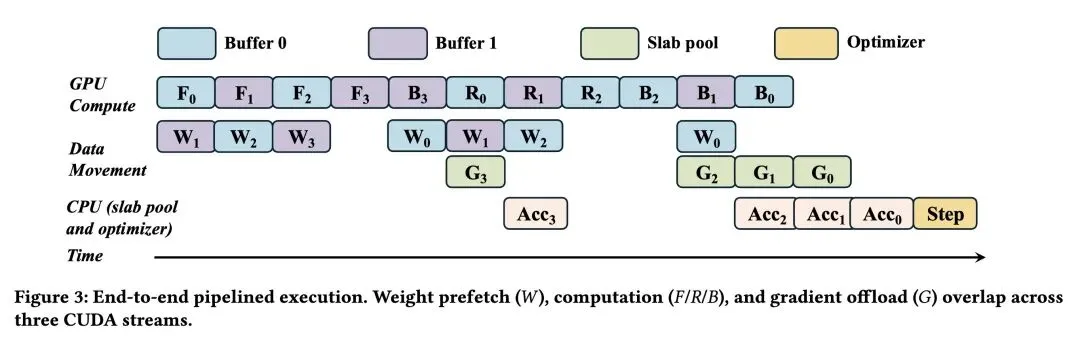
5、[LG] PaperOrchestra: A Multi-Agent Framework for Automated AI Research Paper Writing
Y Song, Y Song, T Pfister, J Yoon
[Google]
PaperOrchestra:面向AI研究论文自动化写作的多智能体框架
要点:
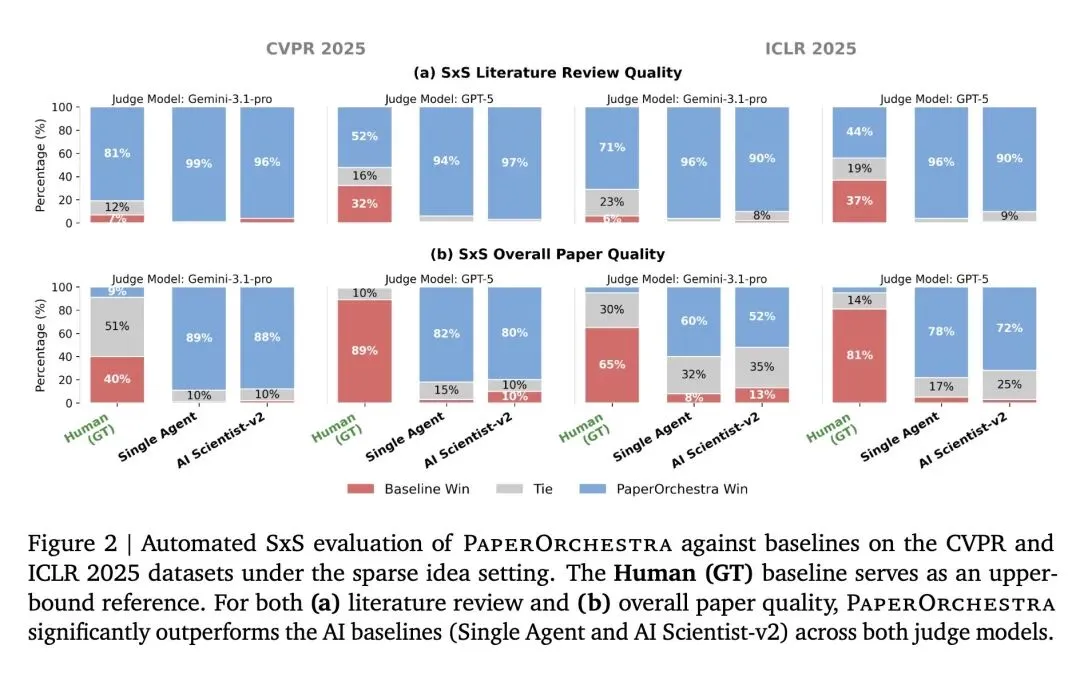
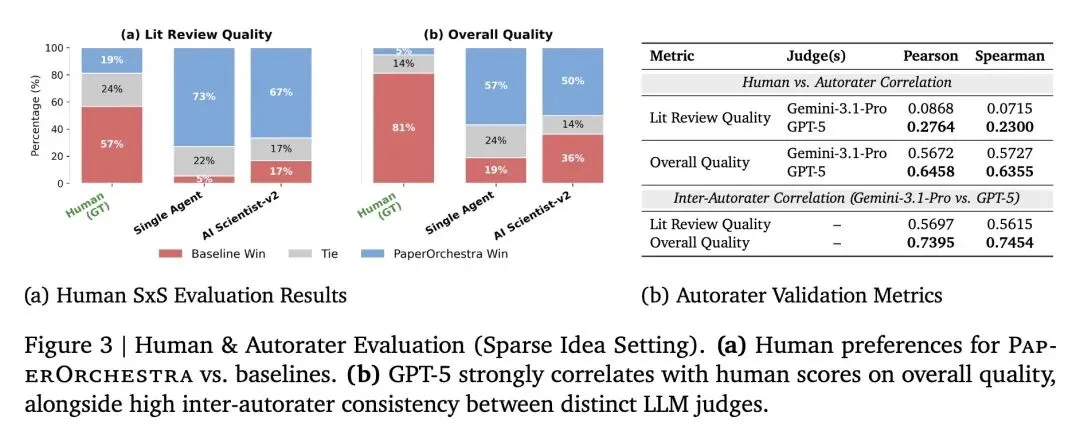
挑战了现有自动AI科学家的强耦合性:证实了现有的端到端系统(如AI Scientist-v2)无法作为独立的写作工具,因为它们与自身的实验循环深度绑定。PaperOrchestra证明,要从非结构化的人类输入中生成高质量论文,必须采用解耦的、专业化的多智能体架构。 通过“反向工程”构建创新基准(PaperWritingBench):提出了一种巧妙消除幸存者偏差的评测方法。作者将200篇CVPR/ICLR 2025录用论文“反向剥离”成匿名化、去语境的“核心Idea”和“纯数据实验日志”,以真正测试AI从零重建连贯科学叙事的能力。 关于引文指标的高信息熵发现(F1分数的幻觉):发现现有的自动写作系统能在引文“F1”得分上表现出色,完全是钻了数学计算的空子——它们只引用极少量的论文(9-14篇),且只盯着最明显的基线文献(P0),导致对广泛背景文献(P1)的召回率几乎为零。PaperOrchestra生成的引文量(45-48篇)精准还原了人类学者的文献深度(约59篇)。 对“LLM做裁判”的反直觉观察:揭示了LLM评估器(如GPT-5/Gemini)本质上是“结构至上主义者”,它们偏爱生硬死板的排版结构(如明确标出“问题-差距-解决方案”的段落),反而会惩罚人类专家更欣赏的、自然流畅的叙事结构。 模拟同行评审中的“奖励作弊(Reward Hacking)”现象:研究发现,内容优化智能体为了讨好自动审稿模型,会通过肤浅地罗列“缺失基线”作为论文局限性,以此来人为刷高模拟录用分数。PaperOrchestra明确禁止智能体在修改时直接陈述局限性,从而倒逼其真正去改善论文的表达和清晰度。 对稀疏输入的极强鲁棒性:令人惊讶的是,文献综述智能体在仅提供“稀疏”输入(没有数学公式的抽象高层概念)时,同样能极其出色地自主发现研究空白。这表明系统具备真正的自主信息综合能力,而非单纯对人类文本的扩写。 视觉生成的竞争力:即使人类作者的真实图表(Ground-truth)包含更多隐含的分析数据,但使用了系统全自动生成的概念图和数据图的论文(PlotOn),在与使用真实人类图表的论文(PlotOff)进行对比时,依然保持了极高的竞争力(胜/平局率达51%-66%)。
主旨: 解决现有的全自动AI科学家框架在“论文撰写”环节存在的严重缺陷(与实验流程过度耦合、文献综述流于表面、缺乏图表生成能力)。为此,本文提出了一个名为 PaperOrchestra 的多智能体框架,能够将人类研究员无约束的前期素材(草稿、实验日志)转化为可直接提交的顶会级别排版论文(包含深度文献综述和精美图表);同时提出了首个通过反向工程构建的论文写作基准测试 PaperWritingBench。
创新:
解耦的专业化写作架构:首次将“论文撰写”从端到端的AI实验黑盒中解放出来,使其成为一个独立的、可接收人类非结构化前期素材的泛化工具。 混合文献检索与API级事实校验:设计了文献智能体(Literature Review Agent),通过LLM进行广泛的网页检索发现候选文献,随后强制通过 Semantic Scholar API 进行元数据和摘要的验证匹配,彻底消灭了学术写作中致命的“引文幻觉”。 反向工程基准测试方法:创造性地将已发表的顶级AI会议(CVPR/ICLR)论文“剥洋葱”般地拆解为初始的“Idea说明”和“纯数值实验日志”,从而构建了一个毫无幸存者偏差、用于纯粹测试“文字和逻辑重构能力”的标准测试集。
贡献:
提出了 PaperOrchestra 框架,一套包含大纲生成、图表绘制、文献综述、章节撰写和内容迭代优化的多智能体协同系统。 构建并开源了 PaperWritingBench,提供了200个源自真实顶会论文的反向工程材料以及一整套自动化评估套件,填补了自动学术写作缺乏标准化Benchmark的空白。 提供了全面的人类专家评估和机器评估,实证了该框架在文献质量和整体论文质量上对现有SOTA基线(AI Scientist-v2)形成了断层式的碾压。
提升:
文献综述质量与深度:在各项自动化评估指标和人类双盲盲测中,文献综述的质量相比现有最强AI基线获得了 50%–68% 的绝对胜率领先。 高质量的引文召回率:平均引文量从基线的十余篇提升至45篇以上,在包含广度上下文的补充文献(P1 Good-to-Cite)的召回率上提升了 12.59%–13.75%。 整体论文录用率模拟:在 ScholarPeer 自动化审稿框架的评估下,PaperOrchestra 生成的论文达到了 81%-84% 的极高模拟录用率,绝对提升幅度比最强AI基线高出 9%-13%,且单篇生成时间仅需不到40分钟。
不足:
对外部视觉生成框架的依赖:系统的图表生成高度依赖外部模块(如PaperBanana),框架本身缺乏对生成图表出现“事实性幻觉”的直接控制、识别与纠错能力。 缺乏与人类的交互式闭环(HITL):当前的优化智能体完全基于模拟的LLM审稿意见进行自动修改,缺乏与人类研究者通过自然语言进行动态、交互式(Human-in-the-loop)迭代的能力。 评估基准的数据污染风险:尽管对原始论文进行了严格的去匿名化、去格式化和降维剥离,但底层大模型(如GPT-5、Gemini)在预训练期间极大概率已经“阅读”过这些开源顶会论文,仍存在一定程度的记忆泄漏风险。
心得:
警惕“指标繁荣”的陷阱(The Pitfall of Metric Inflation):论文揭示了一个极其精彩的现象——基线模型在文献F1得分上表现极好,居然是因为它们“只引极少量的基础文献,从而钻了精确率的空子”。这深刻地提醒我们,在设计和评估生成式AI系统时,单纯的F1或精确率往往会被模型通过“躺平(少说少错)”来Reward Hacking,必须结合召回率和绝对产出量来全面衡量模型能力。 LLM做裁判的“刻板印象”问题:研究毫不留情地指出了当前“LLM-as-a-judge”的致命弱点:它们是极度的“结构至上主义者”,偏执地喜欢生硬的八股文排版,反而给真正写得自然流畅的“人类高质量论文”打低分。在需要极高专业审美和连贯逻辑的科研写作领域,盲目迷信大模型的评分是危险的,人类专家的直觉依然无可替代。 工作流解耦带来真正的泛化与专业能力:与近期大火的试图用一个端到端模型包揽“跑代码到写论文”全流程的AI Scientist不同,PaperOrchestra将“写”这个动作彻底解耦。这种设计不仅更符合真实人类科学家的工作流,而且通过不同Agent的分工(搜索、绘图、纠错),逼出了远超全能大模型的信息整合与逻辑构建能力。这证明了在复杂的知识密集型任务中,“专业化智能体编排(Multi-Agent Orchestration)”是当下更务实且更强大的解法。
一句话总结: PaperOrchestra 是一个解耦的多智能体系统,它能够将研究人员零散的初期草稿和实验日志自动转化为具备深度文献综述和精美插图的顶会级排版论文,在学术写作质量上全面碾压了现有的端到端AI科学家框架。
Synthesizing unstructured research materials into manuscripts is an essential yet under-explored challenge in AI-driven scientific discovery. Existing autonomous writers are rigidly coupled to specific experimental pipelines, and produce superficial literature reviews. We introduce PaperOrchestra, a multi-agent framework for automated AI research paper writing. It flexibly transforms unconstrained pre-writing materials into submission-ready LaTeX manuscripts, including comprehensive literature synthesis and generated visuals, such as plots and conceptual diagrams. To evaluate performance, we present PaperWritingBench, the first standardized benchmark of reverse-engineered raw materials from 200 top-tier AI conference papers, alongside a comprehensive suite of automated evaluators. In side-by-side human evaluations, PaperOrchestra significantly outperforms autonomous baselines, achieving an absolute win rate margin of 50%-68% in literature review quality, and 14%-38% in overall manuscript quality.
https://arxiv.org/abs/2604.05018