 夜雨聆风
夜雨聆风分析师 卡洛琳量子位智库 | 公众号 AI123All
第15周,我们不仅见证到算力架构(TPU对GPU)的正面交锋,也看到具身智能正式进入百亿级估值的资本收割期。
长期以来,英伟达凭NVLink保持垄断,但谷歌TPU v7展现出的超大规模阵列潜力,以及多位大客户的选择,证明在高效率、低成本的推理场景下,ASIC的性价比已具备代际压制能力。Terafab这类自研芯片项目获得获取更多业内合作,算力多元化变成可落地的成本优化策略。
本周热点显示,行业已攻克了低成本数据采集难题,具身智能模型的通用性正在等待数据喂养后的爆发。同时千寻智能站上估值200亿台阶,智平方、星海图等头部企业集体完成股份制改造,今年我们将迎来具身智能的上市元年,需关注那些拥有稳定量产能力且具备真实商业闭环的企业。
智谱GLM-5.1的发布与HermesAgent自进化框架的爆火,意味着模型竞争的维度已改变。随着一次生成到长时进化的模型范式转移,无法实现“跨会话能力积累”的模型将迅速失去其作为生产力工具的竞争力。
基础
英特尔加入Terafab,马斯克起诉OpenAI案升级
马斯克宣布英特尔加入其Terafab芯片项目,共同在德州建设超级晶圆厂,目标年产1太瓦算力,重点支撑太空AI及自动驾驶。英特尔将输出核心制造与封装技术,项目总投资200亿至250亿美元。
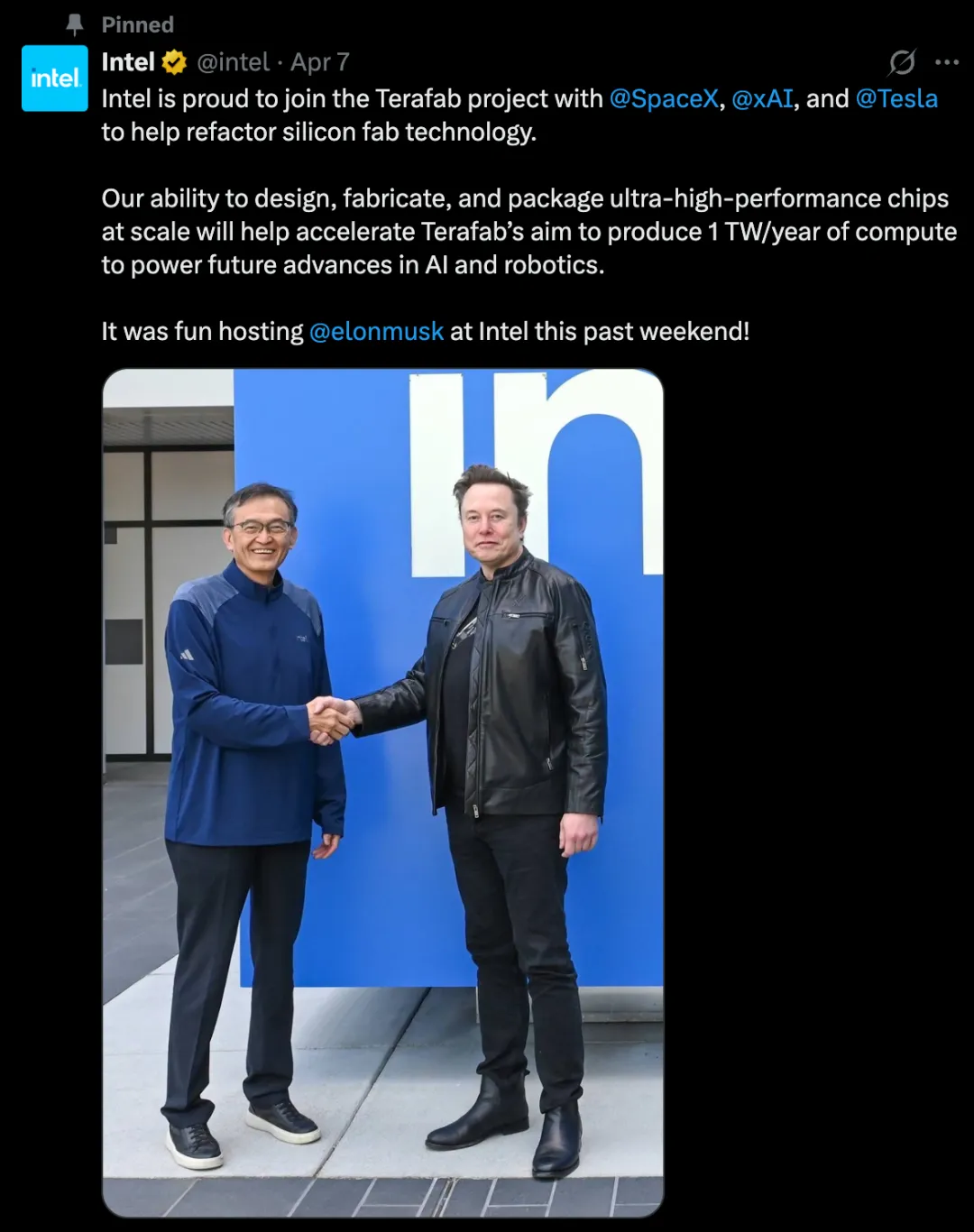
与此同时,马斯克升级了对OpenAI的诉讼,要求撤换奥特曼等高管并回归OpenAI非营利本质。此案源于2024年马斯克指控OpenAI违背非营利承诺、骗取其3800万美元捐赠的诉讼,定于4月27日在加州奥克兰开庭审理。OpenAI则反击此举为“嫉妒驱动的骚扰”,双方矛盾已演化为司法博弈。
博通谷歌签订五年TPU协议,Anthropic成合作首位买家
博通与谷歌达成至2031年的深度绑定协议,为其供应定制化TPU及网络组件。此举迅速吸引了大买家Anthropic,其决定采购3.5吉瓦的TPU算力,预计从2027年开始供应。Anthropic的订单仅今年就有可能给博通提供超过200亿美元的相关收入。

根据Anthropic最新公告,其年化收入已突破300亿美元并首次超越OpenAI。目前,已有超过1000家企业客户每年向Anthropic支付超100万美元,该项数据不到两个月翻了一倍。本周Anthropic还流出消息,正在考虑自主设计芯片,并向CoreWeave租用算力。
博通向Anthropic出售的将是直接基于谷歌TPU v7 Ironwood的机架级系统,TPU在构建超大规模计算阵列方面,展现出超越英伟达GB200服务器的潜力。超节点规模可以扩张到9216颗芯片,理论最大规模可达40万颗芯片。Midjourney从GPU迁移到TPU v6e后,月度推理支出从210万美元骤降至70万美元,可见TPU的性价比。
TPU的崛起迫使英伟达重新审视其产品策略。GB200 NVL72通过NVLink将单域规模从过去几颗提升到576颗,正是对TPU架构的追赶。这也是为什么英伟达寄希望于COUPE并投资Lumentum、Coherent和Marvell。
台积电2026年Q1营收同比增长35%
台积电公布第一季度营收达1.134万亿新台币(约合357.1亿美元),同比增长35%,超出伦敦证券交易所集团分析师给出的1.125万亿新台币预期值,也符合公司此前346亿至358亿美元的业绩指引区间。公司将于4月16日发布完整财报并更新全年展望,其台北上市股票今年以来累计上涨29%,表现优于大盘。
台积电已超越单纯的芯片代工角色,成为AI时代不可或缺的基础设施层。其全球晶圆代工市场份额高达70.4%,在先进制程(7nm及以下)领域占比接近90%,形成事实上的技术垄断。
其营收爆发是全球AI基础设施投资狂潮的缩影。2026年全球数据中心资本支出预计突破5000亿美元,较2025年的6000亿美元基数继续攀升,其中AI服务器支出预计增长45%至3120亿美元。
智元开源AGIBOT WORLD 2026数据集
智元开源了包含100万条真实机器人轨迹、覆盖217个任务的庞大数据集。该数据基于真实物理环境采集,并引入了多层级标注体系,甚至记录了错误修正轨迹。
具身智能领域,数据缺乏与标准不一是两大痛点。智元通过推广自有标准来巩固其作为平台型公司的生态定位,为具身智能的规模化落地预设底层框架。
模型
阿里HappyHorse-1.0登顶Artificial Analysis视频生成榜单
AI视频模型HappyHorse-1.0以匿名之姿横扫Video Arena排行榜,在多项赛道刷新纪录。官方确认该模型是阿里旗下ATH创新事业部正在内测中的产品。

技术层面,HappyHorse-1.0或采用Transfusion统一多模态架构,将离散文本建模与连续视觉信号深度整合,实现音视频的高度同步。视频生成已跨越单纯的画面拼接,进入了物理逻辑与声画对齐深度较量的“后Sora”时代。
智谱发布GLM-5.1,长时推理能力成编码模型竞争新焦点
智谱AI推出旗舰模型GLM-5.1,在SWE-Bench Pro基准测试中以58.4%的准确率取得领先成绩,较上一代GLM-5的55.1%有明显进步。
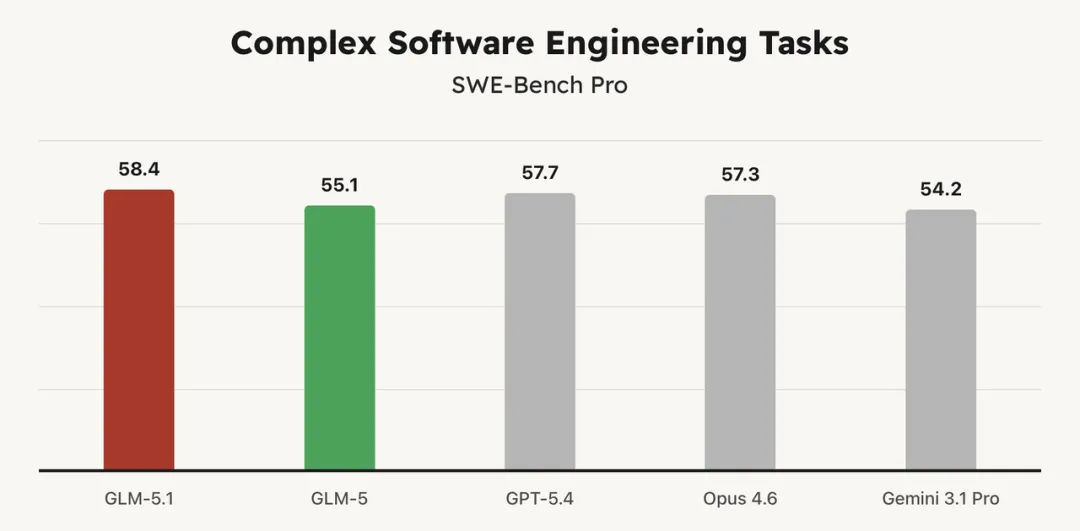
其核心优势在于长时推理,能在上千次交互和迭代中持续优化性能,而非陷入传统的“输出平台期”。这种“元认知”能力的工程化,解决了复杂软件开发中多轮调试的痛点。
MiniMax M2.7开源,Music2.6上线
MiniMax开源M2.7,该模型于3月18日发布,此次开源兑现了之前的承诺。开源首日,华为昇腾、摩尔线程、沐曦、昆仑芯、NVIDIA等海内外芯片厂商,以及Together AI、Fireworks、Ollama等推理平台均完成模型接入与推理适配。MiniMax在生态合作上做了充分准备。

其音乐模型升级至Music 2.6,大幅提升生成延迟、音乐控制与声学品质,并面向全球创作者开启为期14天的免费内测。最直观的体验升级体现在速度上——首包延迟降至20秒以内。模型的Cover功能支持创作者上传一段自唱音频,提取旋律特征后可进行跨风格迁移。
当前AI音乐赛道集中突破可控性与低延迟两大需求。
Meta超级智能实验室首个AI模型Muse Spark发布
Meta正式发布Muse Spark,这是超级智能实验室(Meta Superintelligence Labs)推出的首款AI模型,Meta的AI重心正式从Llama系列转向Muse家族。
Muse Spark是一款原生多模态推理模型,支持工具调用、视觉思维链和多智能体协同。该模型具备深度思考模式,在视觉推理及健康领域表现尤为出色,部分得分已超越行业顶尖对手。
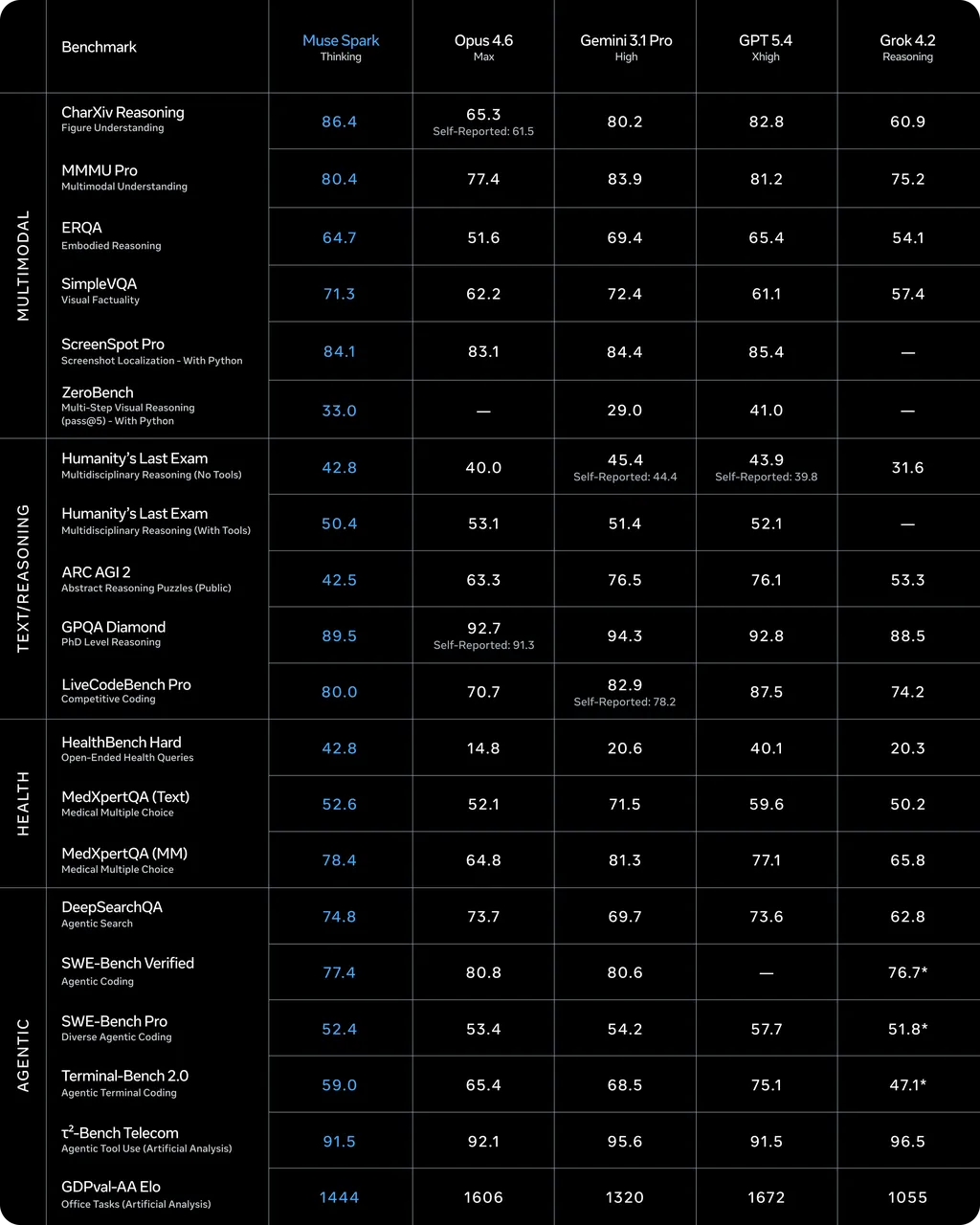
目前Muse Spark为封闭权重,但Meta承诺未来将推出开源版本,并计划将其深度整合至旗下全线硬件与社交产品中,构建全新的多模态生态。
李飞飞World Labs发布Marble 1.1系列模型
World Labs发布了Marble 1.1系列3D世界生成模型,包含Marble 1.1与Marble 1.1-Plus。Marble 1.1侧重于画质与光影一致性的优化,而Plus版则专注于超大规模场景的自动扩展。
该系列支持多模态输入并生成可交互的3D空间,目前已开放API接入。空间智能领域模型的产品化提速,让通过简单提示词构建复杂、动态的3D虚拟世界成为现实商业可能。

蔡浩宇Anuttacon公开视频生产模型LPM 1.0
蔡浩宇创立的AI公司Anuttacon发布论文,公开其首个视频模型LPM 1.0(Large Performance Model)。
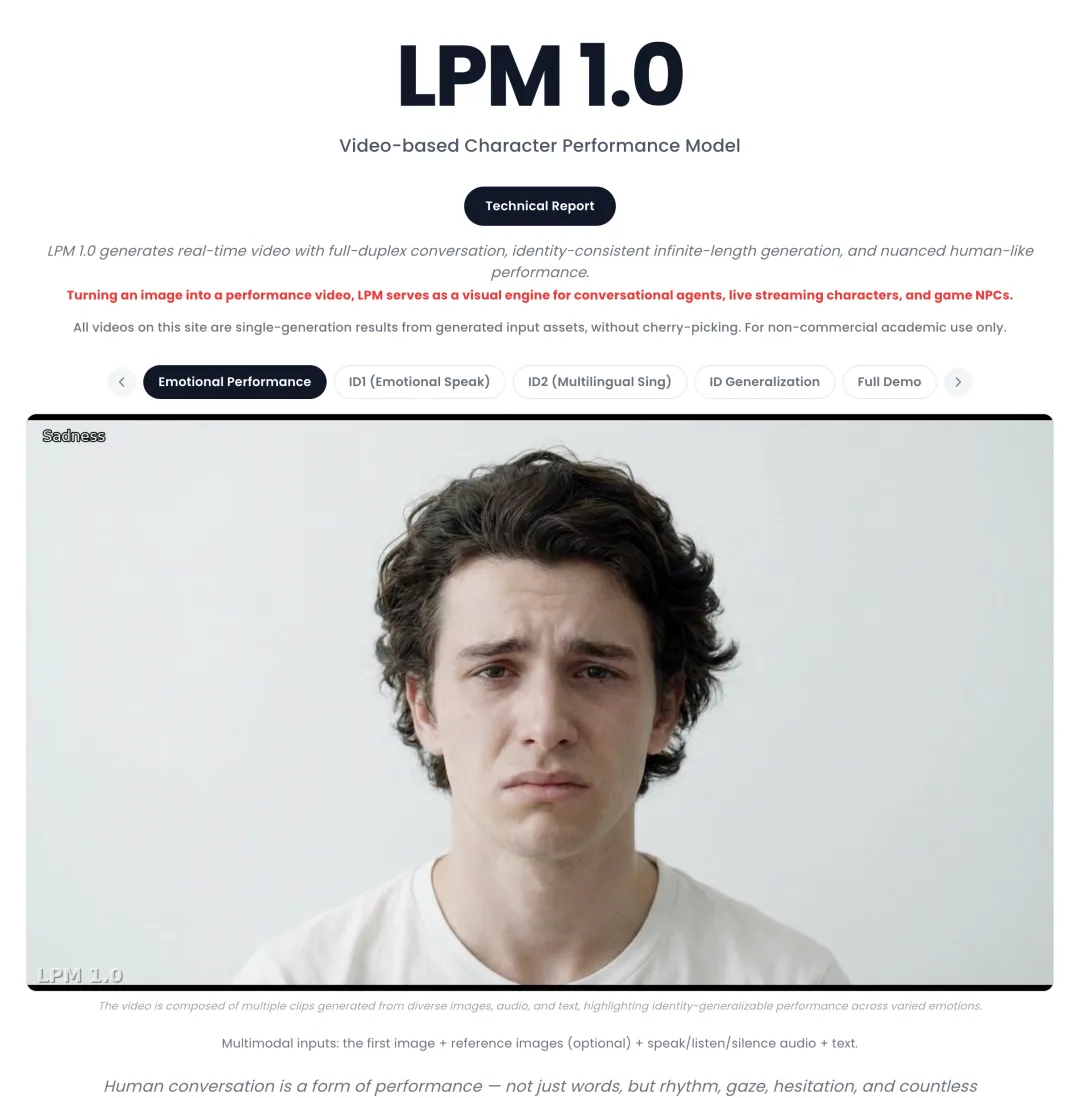
该模型基于170亿参数扩散Transformer架构,核心能力是角色表演生成,可在对话、直播、游戏NPC等场景中实现实时、身份稳定的无限长度视频生成。
视频生成与世界模型当前的主流方向是通用场景生成,LPM 1.0的角色表演和无限长度值得关注。该技术可直接应用于Anuttacon后续的游戏开发。
马斯克同步xAI新进展,透露Claude模型参数规模
马斯克在社交平台披露xAI的Colossus 2超算正在同时训练7个大模型,包括2个1万亿参数模型、2个1.5万亿参数模型、1个6万亿参数模型以及1个10万亿参数模型。
在回应网友关于Grok 4.2参数规模的提问时,马斯克表示Grok 4.2总参数量为0.5万亿,并称其规模仅为Sonnet的一半、Opus的十分之一,间接透露Claude Sonnet参数量约为1万亿、Opus约为5万亿。
这一信息引发外界对Anthropic长期保密策略的关注,此前Anthropic从未公开披露过Claude系列模型的具体参数规模,网友主要通过推理成本反推、性能基准对标、内部文件泄露及架构特性分析等方法进行推测。
Generalist发布机器人模型Gen-1,Scaling Law仍有效果
Generalist发布了基于50万小时动捕数据训练的机器人模型GEN-1,物理任务成功率从前代的64%上升至99%。
该模型在未训练场景中展现出“物理常识”,能够在垫圈松动、物体变形时自动调整策略。严格来讲,对于Gen-1目前所展示的工业流水线场景,如折包装盒、打包手机等,超越预设程序的即兴智能并不是最有价值的。
但是随着数据规模的倍增,GEN-1学习新任务的效率提升十倍,任务可靠性大幅提升,且在此基础上有更强的泛化能力,意味着我们可以期待GEN-3或许能有GPT-3的表现。
并且GEN-1的低成本数据采集模式正逐渐成为行业共识。
应用
DeepSeek上线专家模式
DeepSeek在网页端引入“快速”与“专家”模式的分层设计。快速模式侧重日常交互,专家模式则擅长复杂问题处理,支持深度思考和智能搜索,但目前牺牲了响应速度与多模态支持。
业内普遍猜测专家模式可能搭载传闻中的DeepSeek V4模型或其轻量版本,但官方尚未明确回应,仅表示专家模式由下一代混合专家模型(MoE)架构支撑,核心底座为DeepSeek-V3.2或其后续版本,并融合了DeepSeek-R1的强化学习成果。
此外,处于灰度测试的Vision模式预示着产品矩阵的持续扩张。这种模式分层反映了模型供应商在平衡推理算力成本与用户体验之间的策略权衡。
星动纪获Benjie竞赛第一,打破PI记录
星动纪元在由前谷歌机器人专家Benjie Holson发起的Benjie’s Humanoid Olympic Games中,凭借自研VLA具身模型,在剥橘子、开锁、翻袜子三项任务中获得全球第一,打破Physical Intelligence此前保持的赛事纪录。
在剥橘子任务中,星动纪元实现首个无工具纯手剥操作,用时1分47秒,比PI借助削皮刀完成的2分46秒快35%;在开锁任务中,星动纪元以49秒完成,较PI的66秒提升25%;在翻袜子任务中,星动纪元使用120个样本、用时较PI提升30%,样本使用量减少32%。
该赛事被科学美国人杂志视为机器人终极挑战,采用严格的打榜制,选手必须超越前冠军成绩至少25%方可夺牌,星动纪元是唯一上榜的中国具身企业。
Anthropic:推出Claude Managed Agents托管式智能体开发平台,限制Claude Mythos预览版推广
Anthropic推出企业级托管平台,降低了部署复杂智能体的技术门槛,直接竞争OpenAI及其他开源框架。Salesforce Agentforce、Google Gemini Enterprise等平台也在争夺这一市场。
首批采用者包括Notion、Rakuten、Asana、Vibecode和Sentry等企业,应用场景涵盖代码开发、文档处理、数据分析等领域。产品按会话时长计费,每小时0.08美元,同时保留模型调用的常规token计费模式。
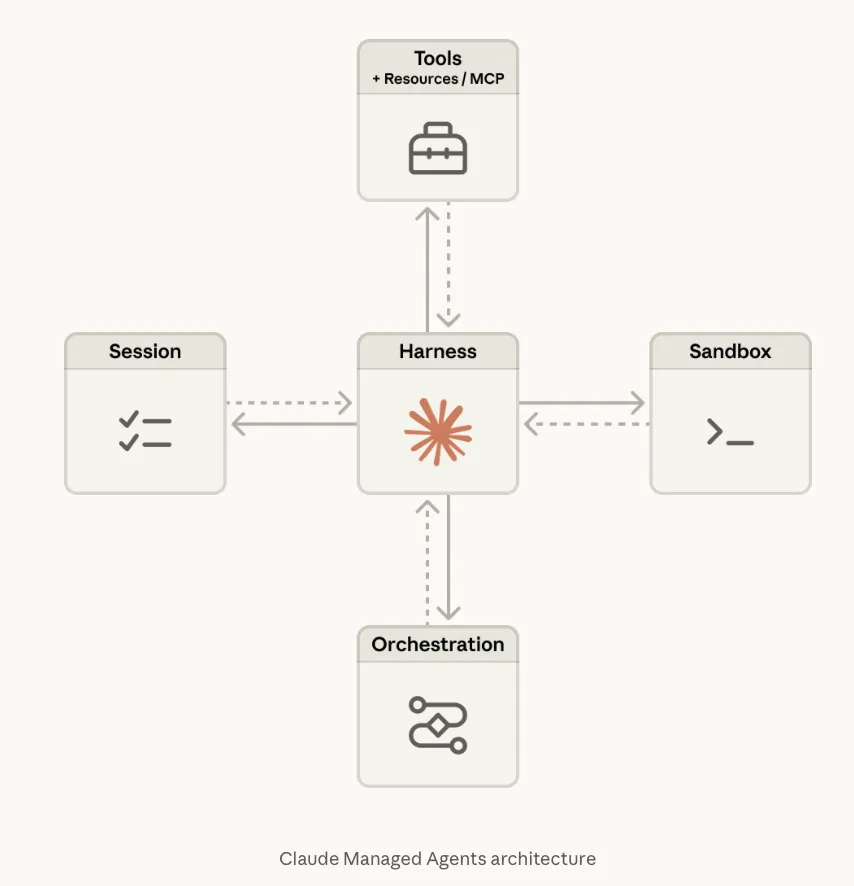
与此同时,针对具备“核弹级”漏洞发现能力的Claude Mythos系统,Anthropic实施了严格的访问限制。这一举措凸显了AI网络安全能力的双刃剑属性:在显著提升关键基础设施防御效率的同时,必须极度审慎地防范其被用于自动化网络攻击的巨大风险。
HermesAgent爆火,自进化AI框架挑战OpenClaw
开源框架HermesAgent凭借“模型内生进化”路线在GitHub迅速走红,两个月内GitHub星标突破33000,且在OpenRouter的AI应用和Agent的使用量排名中以619%的周增长率位居第一。该框架以Python构建,其核心优势在于Agent能跨会话生成并优化复用技能。
相比之下,OpenClaw因Anthropic收费政策调整导致成本骤增,且面临严峻的安全隐患。技术层面,OpenClaw的TypeScript架构和第三方技能市场暴露出系统性安全隐患,截至2026年3月已披露82个CVE,ClawHub发现超820个恶意技能。
两者分别代表“外部系统编排”与“模型内生进化”两种技术路线,用户对成本与安全性的敏感度正重塑市场份额。
米拉·乔沃维奇跨界开源AI记忆系统MemPalace
《生化危机》主演米拉·乔沃维奇跨界开发的MemPalace利用“记忆宫殿法”重构AI记忆系统,检索效率提升34%,且成本远低于传统方案。
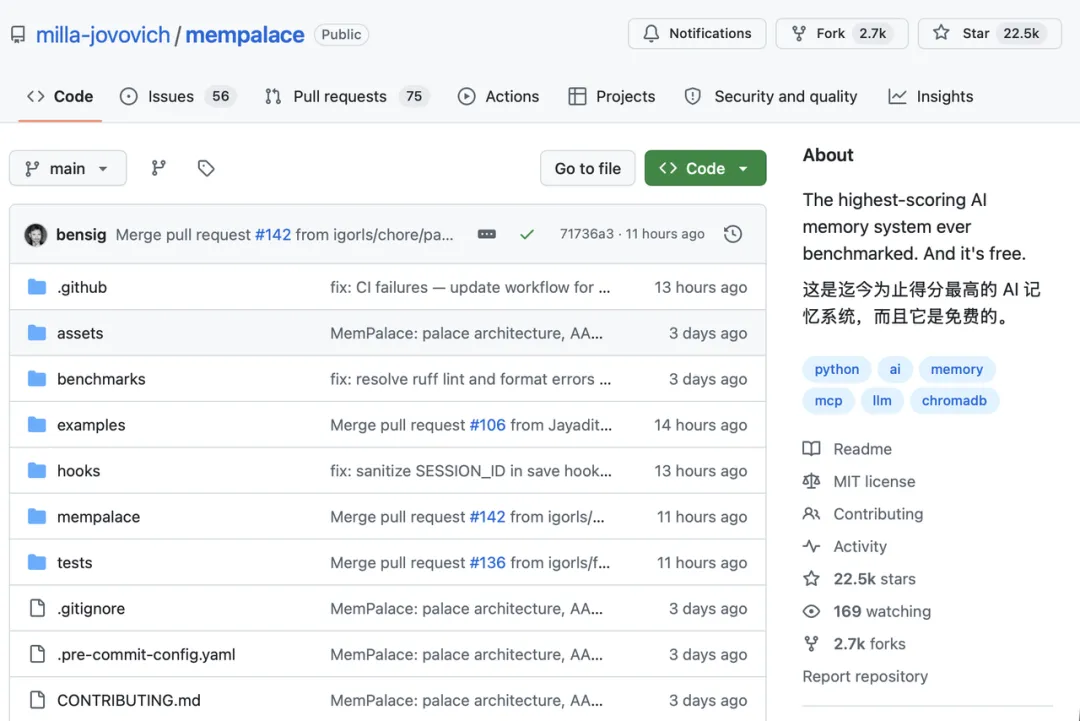
该系统在多项长期记忆测试中刷新纪录,LongMemEval中取得96.6%的公开可查最高分,同时在ConvoMem和LoCoMo测试中分别获得92.9%和100%的成绩。
项目开源后迅速获得社区热捧,已衍生出社区开发的前端界面,且支持全本地化处理以确保隐私。这种源于跨界需求的创新,为长文本记忆问题提供了具备落地价值的新路径。
投资
智平方完成股份制改造,冲刺IPO
成立仅两年的智平方完成股改,投后估值破百亿人民币,已成为深圳具身智能领域的首个独角兽。凭借自研全域全身VLA大模型及Alpha Bot系列机器人,智平方已推出模块化具身智能服务空间“智魔方”,计划在三年内落地千个服务点位。

此次股改并非孤例,今年以来星海图、众擎机器人、灵心巧手等同行相继完成股改,具身智能赛道正整体从实验室研发阶段跨向规模化交付期,IPO冲刺潮临近。
千寻智能完成10亿元融资,估值突破200亿
千寻智能在短短30天内累计融资达30亿元,估值翻倍至200亿大关,稳居国内具身智能第一梯队。公司通过自研可穿戴设备显著降低了数据采集成本,并已获取20万小时交互数据。其Moz机器人已在智慧零售场景落地,显示出极强的商业闭环能力。海量真实数据与商用场景是当前具身智能企业获融资的底层逻辑。
零次方机器人获润泽集团领投超亿元融资
零次方机器人完成超亿元融资,且在成立仅一年后便实现百台稳定量产,月营收达千万级。该公司由清华大学AI&Robot实验室核心成员闵宇恒、程颐等00后极客于2025年1月创立。

公司提出“伪通用—去通用—真通用”的演进路径,目前聚焦特定商业场景的高动态交互。这种以商业闭环反哺技术进化的策略,让零次方在具身智能的激战中迅速确立了生存与扩张的先手优势。目前订单突破亿元、营收达数千万级别,并在合肥、北京、深圳等地十余处地标场景完成落地验证。
首形科技完成数亿元A1轮融资
首形科技完成数亿元人民币A1轮融资,由华控基金及某互联网企业联合领投,嘉御资本、鹏瑞基金、亦庄国投、上海半导体产投、南山战新投及多家老股东跟投。本轮资金将主要用于多模态具身交互系统与情绪基座模型的迭代升级,仿生面部核心部件的规模化优化,以及全球市场拓展。
该公司上一轮融资的领投方之一是蚂蚁集团。
生数科技完成近20亿元B轮融资,阿里云领投加码通用世界模型
生数科技宣布完成近20亿元B轮融资,由阿里云领投,中网投、九安海棠、好未来、光合创投等战略投资,原有股东星连资本、达泰资本、建发新兴投资、BV百度风投、卓源亚洲等持续追加投资。本轮融资将用于持续夯实通用世界模型底层能力,加速技术攻关与产业落地。

其数字世界产品Vidu系列视频模型已实现声画同出、16秒长时长、高时空一致性与电影级视觉品质,ViduQ3在国际权威AI基准测试机构ArtificialAnalysis榜单中位居全球第一。物理世界产品Motus模型于2025年12月开源,为首个基于视频生成大模型的统一架构世界行动模型。
Sand.ai完成5000万美元融资,产品VidMuse ARR超千万美元
Sand.ai旗下视频生成产品VidMuse上线仅2个月,ARR已突破千万美元。公司同期完成新一轮约5000万美元融资。这家公司由智源研究院的研究员曹越创立,曹越还曾在微软亚洲研究院任职,主要研究方向是视觉计算,并以此为起点在通用视觉模型等方面取得成果,代表作有Swin Transformer(ICCV 2021马尔奖)等。
VidMuse的特色是“Music in Video Out”功能,以音频驱动视频创作,底层技术依托Sand.ai自研的音视频原生架构。因此其产品主要面向音乐人、视频创作者和营销团队等,也是典型的通过SaaS订阅,覆盖高成本市场成本敏感型用户的商业逻辑。
终端通用Agent创企Poke获2500万美元融资
Poke作为一款嵌入即时通讯工具、无需安装App的通用AI Agent,凭借极低的使用门槛获得2500万美元融资,用户数激增10倍。其多模型架构及自定义配方功能赋予了产品极高的灵活性。
面壁智能完成数亿轮融资,端侧战略持续获支持
面壁智能完成数亿元人民币融资,由深创投和汇川产投联合领投,道禾长期投资、国泰君安创新投、武岳峰科创等跟投。今年年初,公司已完成由中国电信领投的一轮融资,一季度累计融资规模预计超10亿元,持续领跑端侧大模型赛道。
其MiniCPM系列以极低训练开销实现了卓越性能,并在模型轻量化上筑起技术护城河。相比云端大模型,端侧模型提供了更灵活的授权与软硬结合模式 。
-👑 「2026年中国AI应用全景图谱报告」征集启动-

— 联系作者 —

— 完 —
【量子位智库】原创内容,未经账号授权,禁止随意转载。
点这里👇关注我,记得标星哦~
