 夜雨聆风
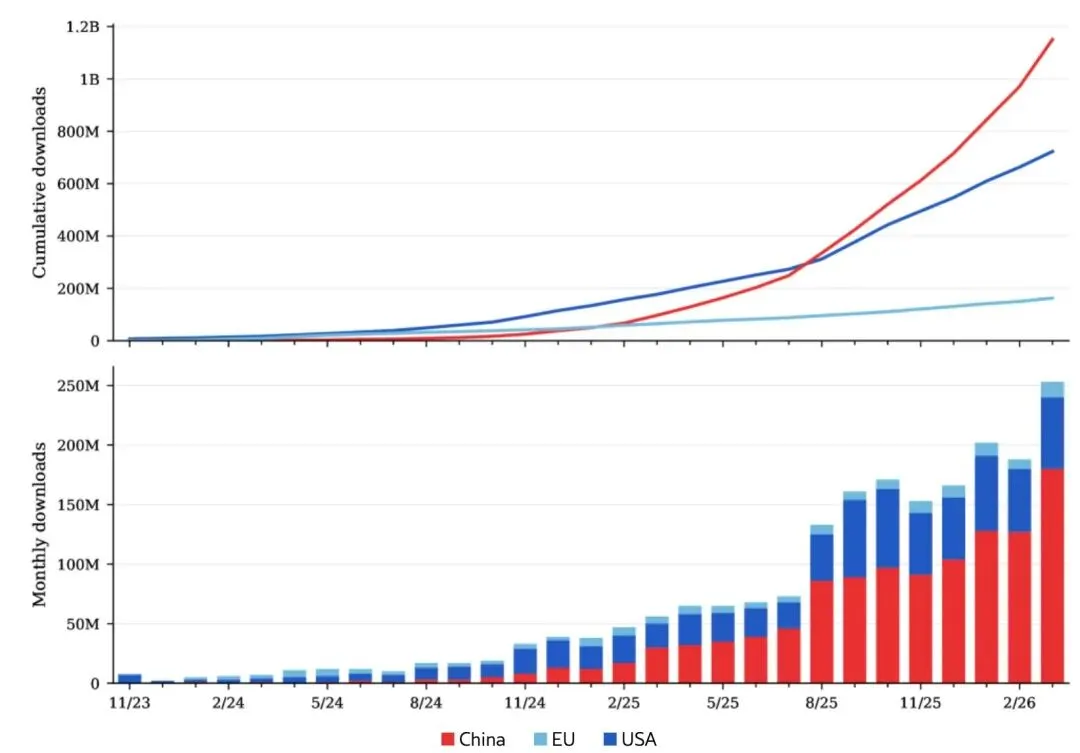
夜雨聆风942.1 百万次下载,占全球开源模型下载量的 50% 以上——这是美国 AI 追踪机构 Interconnects AI 在 4 月 10 日发布的报告中,给阿里云通义千问(Qwen)系列模型打出的成绩单。
更绝的是,仅 2026 年 2 月一个月,Qwen 的下载量就达到 1.536 亿次——这个数字超过了 Meta、DeepSeek、OpenAI、Mistral、Nvidia、智谱 AI、月之暗面和 MiniMax 这 8 家加起来的总和。
而在这场开源 AI 的全球争夺战中,还有一个更值得关注的信号:在 Hugging Face 平台上,中国开源模型的月下载占比已达到 41%,美国为 36.5%——这是中国首次在这一指标上超越美国。
01|半壁江山怎么拿下的?从追赶到碾压只用了 7 个月
说实话,当我第一次看到这个数据的时候,第一反应是“会不会统计口径有问题”。但仔细翻了 Interconnects AI 的完整报告后发现,这个逆转不仅真实,而且来得比想象中更快。
转折点发生在 2024 年 9 月。那个月,阿里云发布了 Qwen 2.5,这是一个在多个基准测试中表现出色的开源模型系列。Interconnects AI 的报告明确指出,中国模型从 2025 年夏天开始超越美国模型,而 Qwen 2.5 的发布正是这个转折的关键推动力。
到 2025 年 12 月,情况已经变得有些“离谱”:那个月 Qwen 的下载量超过了 Meta、DeepSeek、OpenAI、Mistral、Nvidia、智谱 AI、月之暗面和 MiniMax 这 8 家的总和。这不是小幅领先,而是碾压式的优势。
2026 年 2 月,阿里云又扔出了一颗重磅炸弹:Qwen 3.5。阿里云在发布时称,这个系列的能力已经与 OpenAI、Anthropic 的顶级模型持平。当月,Qwen 的下载量达到 1.536 亿次,是第 2 到第 9 名总和的两倍多。
到 2026 年 3 月,累计下载量达到 9.421 亿次,距离 10 亿大关只差临门一脚。更夸张的是,到 2026 年 1 月,基于 Qwen 微调和衍生的模型数量已经突破 20 万个。这意味着什么?意味着全球有 20 万个团队或个人,选择把 Qwen 作为他们 AI 项目的“地基”。
让我们用一张表格来看看这个增长有多疯狂:
从 7 亿到接近 10 亿,只用了两个月。这个增速,已经不是“追赶”,而是“甩开”了。
02|中国 41% vs 美国 36.5%,这个“反超”意味着什么?
如果说下载量的领先还可以用“中国开发者多”来解释,那么接下来这组数据就更有意思了。
Hugging Face 是全球最大的 AI 模型托管平台,几乎所有开源模型都会在这里发布和分发。它的下载数据,被业内视为观察全球开发者选择偏好的“风向标”。而根据最新统计,中国开源模型在 Hugging Face 的月下载占比已经达到 41%,美国为 36.5%。
这是历史上第一次,中国在这个指标上超越美国。
但更值得关注的是另一个数据:不只是下载量,调用量也在反超。
OpenRouter 是一个聚合了超过 400 个 AI 模型的平台,开发者可以通过同一个 API Key 在不同模型之间随时切换。它的调用量数据,能更直接地反映“开发者真正在用哪个模型”。2026 年 2 月 9 日至 15 日那一周,中国模型的调用量首次超越美国模型,此后这个领先优势持续了近两个月。
到 4 月 3 日那一周,OpenRouter 调用量排名前十的模型中,有 6 个来自中国:小米的 MiMo-V2-Pro、阶跃星辰的 Step 3.5 Flash、MiniMax 的 M2.7、DeepSeek 的 V3.2、智谱的 GLM 5 Turbo,以及 MiniMax 的 M2.5。
这里有个细节特别值得玩味。OpenRouter 的联合创始人兼 COO Chris Clark 在 2 月公开表示,中国开源模型在美国企业运行的 Agent(智能体)工作流中占比“不成比例的高”。这意味着:不仅中国开发者在用中国模型,而且美国开发者也在大量使用中国模型。
为了验证这个判断,我找到了 OpenRouter 2025 年底发布的年度报告。那份报告显示,当时平台用户中 47% 来自美国,中国开发者仅占 6%;调用内容中英语占 83%,中文不足 5%。换句话说,这是一个以美国开发者为主、英语为主的平台。但就是在这样一个平台上,中国模型在短短几个月内占据了调用量榜单的前六名。
这说明什么?说明不是用户结构变了,而是美国开发者主动选择了中国模型。
03|Qwen 凭什么能“一打八”?三个关键策略
看到这里,你可能会好奇:Qwen 到底做对了什么,能在这么短的时间内拿下半壁江山?
我梳理了一下公开信息,发现有三个关键策略。
策略一:小参数模型的“降维打击”
Interconnects AI 的报告里有一句话特别关键:Qwen 的主导地位,很大程度上源于小参数版本(10B 以下)的极高人气。
也就是说,大多数开发者其实不需要千亿参数的“巨无霸”模型,他们需要的是能在自己电脑上跑、能随意修改、部署成本低的模型。一个 7B 或者 14B 的模型,对于大部分应用场景来说已经够用了。
Qwen 在这方面做得非常极致。它提供了从 0.5B 到 3970B 的完整参数梯度,支持 119 种语言。到 2026 年 1 月,Qwen 已经发布了超过 100 个开放权重的模型。你想要什么规格的,基本都能找到。
这就像是在卖车:特斯拉只卖高端电动车,而 Qwen 从电动自行车到大货车全都有,还都是开源设计图,你可以随便改装。哪个更容易占领市场?答案不言而喻。
策略二:Apache 2.0 许可证的“无门槛开放”
Qwen 3 系列全部采用 Apache 2.0 许可证,这是目前最宽松的开源协议之一。开发者可以自由商用、修改、二次分发,没有任何法律风险。
对比一下:Meta 的 Llama 早期版本曾经有商业使用限制,比如月活用户超过 7 亿的公司不能用。虽然 Llama 3 后来完全开放了,但这个“前科”让很多企业在选型时心里有顾虑。
Qwen 从一开始就没有这些限制。你拿去做商业产品?没问题。你改了代码不想开源?也没问题。这种“无门槛”的策略,大大降低了企业采用的心理成本。
策略三:高频迭代 + 生态滚雪球
从 Qwen 2.5(2024 年 9 月)到 Qwen 3.5(2026 年 2 月)再到 Qwen 3.6(2026 年 3 月),迭代速度快得惊人。而且每次迭代都不是小修小补,而是能力的显著提升。
更关键的是,Qwen 已经形成了一个庞大的生态网络。20 万个衍生模型,意味着有 20 万个“Qwen 的变种”在全球各地运行。这些衍生模型又会吸引更多开发者,形成正向循环。
有个典型案例:DeepSeek 基于 Qwen 微调出了一个叫 R1-Distill-Qwen-32B 的模型,在某些基准测试上甚至超越了原始的 Qwen 模型。这种“学生超过老师”的案例,反而证明了 Qwen 作为“基座”的价值。
还有一个不得不提的点:成本优势。虽然这篇文章的重点不是价格,但有个数据值得一提:企业自部署 Llama 这样的开源模型,成本比使用闭源 API 低 88%。而 Qwen 还提供了免费版本(比如 Qwen3.6 Plus free),让开发者可以零成本试用和部署。
在 AI 成本越来越高的今天,这是个实实在在的杀手锏。
04|Meta 的“战略转向”和硅谷的焦虑
Qwen 的崛起,最直接的“受害者”是谁?Meta。
2026 年 4 月,Meta 发布了一个名为 Muse Spark 的模型。这个模型本身没什么特别的,但有一点很特别:它是闭源的。
这是 Meta 多年来首次放弃开源策略。要知道,过去三年 Meta 一直靠 Llama 系列在开源 AI 领域建立了最大的生态:累计下载量 12 亿次,日均下载约 100 万次。但到 2025 年底,中国模型在 Hugging Face 的下载占比已经达到 41%,美国只占 35%。
有报道称,Llama 4 的表现不及预期,加速了市场份额的流失。Muse Spark 的闭源发布,某种程度上是承认了现实:与其继续做开源基础设施供应商,不如先把自家产品的 AI 能力补上来。
但 Meta 的困境不是个例。Interconnects AI 最近发了一篇文章,标题很直白:《开源模型联盟的必然需求》。文章里提到,随着训练成本从数百万美元飙升至数十亿美元,单个公司越来越难以负担。未来可能会出现“开源模型联盟”,多家公司分摊成本——每家承担 1/10 或 1/50。
这背后透露出的信息是:硅谷的开源 AI 玩家们,正在重新思考自己的策略。
不过也不是所有美国公司都在“败退”。Interconnects AI 的报告显示,尽管 Meta 和 Google 的 Gemma 模型在过去一年发布较少,但它们仍然各自保持着约 10% 的衍生模型份额,远高于其他竞争者。这说明,老牌玩家的生态惯性依然存在,只是增长速度被中国模型超越了。
05|Qwen 的“隐忧”也在浮现
2026 年 3 月 3 日,一条简短的推文在开发者社区引发了不小的震动。Qwen 的负责人林俊旸(Lin Junyang)在 X 上发了一句话:“me stepping down. bye my beloved qwen.”
林俊旸是谁?他曾领导 Qwen3-Max 和 Qwen3.5 的开发,可以说是 Qwen 团队的灵魂人物。而且他不是唯一离开的高管——2026 年初,多位 Qwen 核心成员相继离职。
这种核心团队的动荡,对任何一个技术项目来说都不是好消息。尤其是在 AI 这个“人才就是一切”的领域,关键人物的离开往往意味着技术路线和产品节奏的不确定性。
除了人的问题,还有商业化的挑战。Interconnects AI 在那篇关于“开源联盟”的文章里提到了一个很现实的矛盾:今天发布最强模型的开源策略,与专注于能产生收入和利润的 AI 产品存在“主动冲突”。
你把最好的模型都免费开源了,那靠什么赚钱?阿里云当然可以通过云服务来变现,但这个商业模式能否支撑 Qwen 持续的高强度投入,还是个未知数。
还有一个容易被忽略的点:下载量领先,不等于能力领先。2024 年 7 月,基准测试平台 SuperCLUE 的排名显示,Qwen2-72B-Instruct 落后于 GPT-4o 和 Claude 3.5 Sonnet。虽然这个排名有些过时了,但至少说明在某些能力维度上,Qwen 和顶级闭源模型之间还是有差距的。
开源模型的优势是“够用、便宜、灵活”,但如果你需要的是“最强”,那 GPT、Claude 这些闭源模型可能仍然是更好的选择。
开源 AI 的“中国时刻”
942.1 百万下载、50% 市场份额、20 万衍生模型——这些数字背后,是全球开发者用“下载”和“调用”投出的真实选票。中国模型在 Hugging Face 的 41% 占比,标志着开源 AI 格局的一个历史性转折。
从追赶到并跑再到领跑,中国开源模型用了不到两年。这个速度,放在任何一个技术领域都算得上惊人。
但这不是终点。OpenAI、Anthropic 的闭源模型在某些维度上仍然保持领先,开源和闭源的竞争还在继续。而且正如 Interconnects AI 报告所说,开源模型的竞争已经从“谁更强”变成了“谁能持续投入”。
Qwen 能否守住这半壁江山,取决于阿里云能否在团队稳定、技术迭代和商业变现之间找到可持续的路径。毕竟,下载量可以靠一两个爆款模型冲上去,但要长期保持领先,靠的是体系化的能力。
不过至少现在,全球开发者已经用行动证明了一件事:在开源 AI 这个赛道上,中国不再是追赶者,而是领跑者。
