 夜雨聆风
夜雨聆风导言
当 ChatGPT 掀起大模型浪潮,全球目光聚焦于 GPU 算力军备竞赛——英伟达市值一度突破 3 万亿美元,A100/H100 一卡难求。然而,一场更深刻的变革正在GPU光环背后悄然发生:随着 AI 进入大规模推理部署阶段,CPU 正在重新定义其在 AI 栈中的战略位置。
从数据中心到手机芯片,从 x86 老将到 RISC-V 新锐,AI 推理的爆发对处理器架构提出了全新的技术需求。理解这场变革,不仅是技术选型的必修课,更是把握下一轮半导体投资机会的关键线索。
第一章:AI CPU 的架构版图——三大阵营的分化与演进
1.1 CPU 的三次 AI 身份转变
CPU 在 AI 计算史上经历了截然不同的三种角色定位。
第一阶段(2010年前):"旁观者"。彼时 AI 研究尚处学术阶段,神经网络训练依赖 CPU 串行执行,矩阵运算极度低效。AlexNet(2012)的爆发式成功,直接将 GPU 推上了 AI 计算的王座,CPU 开始退居幕后,扮演"I/O 调度者"和"任务分发者"的角色。
第二阶段(2016—2022年):"协同者"。Intel 推出 AVX-512 向量指令集,AMD 引入 EPYC 平台,CPU 开始内置专用向量加速单元,用于处理中小规模推理任务。这一时期的定位是"辅助加速",真正的重型计算仍在 GPU/TPU 上完成。
第三阶段(2023年至今):"主力玩家重返赛场"。大模型推理的规模化落地、边缘端侧部署需求爆发,以及新一代 AI 原生指令集(Intel AMX、ARM SVE2)的商用,让 CPU 重新进入 AI 算力核心赛道。更深刻的原因在于:大模型推理的本质特征与 CPU 架构的优势区间高度契合——这一点将在第二章详细展开。
1.2 三大架构阵营深度解析
▌x86:CISC 遗产与 AI 精准反击
架构基因与历史包袱
x86 是 CISC(复杂指令集)的典型代表,诞生于 1978 年。其设计哲学是"一条指令干更多事",通过硬件译码器将复杂指令转化为底层微操作(μops)执行。这一设计在通用计算领域极为成熟,但也带来了明显的历史包袱:
• 译码复杂度高:前端译码器面积大、功耗高,在 AI 批量矩阵运算中并不占优 • ISA 兼容负担重:Intel/AMD 必须兼容 40 余年的软件生态,无法像 ARM 或 RISC-V 那样做"干净"的架构设计 • 功耗墙突出:高性能 x86 服务器 CPU 单颗 TDP 普遍在 200—350W,在以能效比(TOPS/W)为核心指标的 AI 推理场景中处于劣势
AI 反击:AMX 矩阵引擎的技术内核
Intel 的核心答案是 AMX(Advanced Matrix Extensions,高级矩阵扩展),首发于 2023 年的第四代 Xeon(Sapphire Rapids)。理解 AMX,需要先理解为什么矩阵运算是 AI 计算的核心原语:
Transformer 模型的计算核心是大量的矩阵乘法(GEMM)。传统 SIMD 指令(如 AVX-512)每次处理一个向量(一行/一列数据),而 AMX 引入了"Tile"(瓦片)抽象——8 个 1KB 的片上 Tile 寄存器,配合专用的 TMUL(Tile Matrix Multiply Unit),单周期可执行 2048 次 INT8 运算或 1024 次 BF16 运算,相当于在 CPU 内部内嵌了一个小型矩阵协处理器。
实际效果相当显著:在 Llama 3.2B 模型(Q8_0 量化)的推理测试中,启用 AMX 可将推理速度从 28 tokens/s 提升至 57 tokens/s;Google Cloud 的测试数据显示,Intel AMX 使 AI 推理首词延迟(TTFT)降低约 3 倍,吞吐量提升约 7 倍。
2025 年推出的 Intel Xeon 6 系列进一步完善了对 INT8、BF16、FP8 全量化格式的原生支持,并在 Intel 官方演示中展示了部署大型混合专家(MoE)模型(DeepSeek 系列)的 CPU 单机推理能力。
AMD 方面,EPYC 9005(Turin) 以最高 192 核 Zen 5c 架构和 512MB L3 Cache,以极高的核心密度和大带宽内存应对大并发推理场景。AMD 与 Intel 之间关于 AI 推理 TOPS 的"数据口水战"贯穿 2024—2025 年,折射出双方在高密度推理服务器市场的激烈角力。
x86 的未来走向
优势会继续放大还是收窄?答案是双向分化。在存量数据中心(数十亿台已有 x86 服务器)的"就地推理"(CPU-native inference)场景中,AMX 赋予了 x86 前所未有的竞争力,这一优势在可见未来仍难被颠覆。但在增量新建 AI 推理集群中,x86 的功耗劣势将持续受到 ARM 的侵蚀,市场份额的压力只会越来越大。
▌ARM:从"手机芯片"到数据中心颠覆者
架构基因:RISC 的能效天赋
ARM 是 RISC(精简指令集)阵营中当之无愧的王者。其设计哲学是"指令简单、流水线高效、编译器承担更多优化责任"。相比 x86,ARM 的核心优势在于:
• 前端译码更简洁:指令格式固定,译码器面积小、功耗低 • 能效比天然领先:在相同工艺节点上,ARM 处理器普遍比同级 x86 低 30—50% 的功耗 • 架构现代性更强:SVE/SVE2(可扩展向量扩展)是 ARM 为高性能 AI 和科学计算专门设计的指令集扩展,向量寬度可从 128-bit 扩展至 2048-bit,在矩阵运算密集型推理场景中具备天然适配性
超大规模自研浪潮:Hyperscaler 用脚投票
ARM 在数据中心的突破,本质上是云计算巨头以"定制化主权"换取"性价比"的战略选择:
• AWS Graviton5(2025年底):192 核 Neoverse V3,台积电 3nm,搭载 5× 更大 L3 Cache,跑 Llama 3.1 8B 推理时 Token 吞吐量超 Intel Xeon 的 162%,超 AMD EPYC 的 168% • Google Axion:72 核 Neoverse V2,576GB 内存,相比 x86 实例价格性能比提升 65%,能效提升 60% • Microsoft Cobalt 200:Neoverse V3 计算子系统,台积电 3nm,深度绑定 Azure AI 推理工作负载
这些数据背后的商业逻辑是清晰的:推理服务是云厂商的"印钞机",每降低一个点的推理单位成本,都直接转化为数亿美元的利润。ARM 的能效优势,在大规模推理服务场景下实现了商业价值的非线性放大。
Arm 公司数据显示,2025 年流向头部超大规模云服务商的新增算力中,接近 50% 已基于 ARM 架构——而这一数字在 2023 年还不到 20%。更激进的预测(来自 Tom's Hardware 引用的行业报告)认为,到 2029 年,定制 AI ASIC 服务器中 90% 的主机 CPU 将基于 ARM 架构。
端侧的 ARM 生态:Qualcomm 的 AI PC 布局
在边缘端侧,ARM 同样是主导力量。Qualcomm Snapdragon X Elite(2024)和 Snapdragon X2 Elite(2026)代表了 ARM 在 AI PC 领域的最新形态:
• Snapdragon X Elite:Hexagon NPU 提供 45 TOPS,支持本地运行百亿参数量化模型,推理速度 30+ tokens/s • Snapdragon X2 Elite Extreme:NPU 提升至 80 TOPS,18 核 ARM CPU 主频达 5.0 GHz,矩阵运算吞吐量较上代提升 78%,已支持超过 1000 个 AI 模型的本地化推理
ARM 的未来走向
ARM 的优势将持续放大,且短期内看不到明显的天花板。驱动因素有三:其一,台积电 3nm/2nm 制程的性能提升对能效比高的 RISC 架构更为友好;其二,超大规模云服务商的定制芯片投入具有极高的研发壁垒,一旦形成闭环生态将难以逆转;其三,端侧 AI 的爆发趋势为 ARM SoC 打开了新的增量市场。
唯一的风险在于软件生态的碎片化——各家超大规模云厂商的定制 ARM 芯片各有优化,推理框架的适配维护成本正在上升。
▌RISC-V:开源架构的 AI 战略突围
架构基因:极简主义与可定制性
RISC-V 是 RISC 理念的终极形态,诞生于 2010 年加州伯克利大学。其指令手册仅有 236 页(相比 ARM 的 2000+ 页、x86 的 2,000,000+ 字),但这种极简背后蕴含了深刻的设计哲学:Base ISA + Extension 模块化结构,允许设计者按需裁剪和扩展,极度适合针对特定 AI 推理负载进行架构定制。
RISC-V 的 V(Vector)扩展指令集,允许处理器设计者自定义向量宽度,原生支持并行矩阵运算,这一特性与 AI 推理对批量矩阵乘法的计算需求高度契合。
技术优势的量化
在针对 AI 推理的特定场景下,RISC-V 相比 ARM 和 x86 可实现约 3× 计算性能/瓦特 的优势。这一优势来源于:
1. 零额外译码开销:指令格式极简,译码器功耗极低 2. 定制化向量单元:可针对 INT8/BF16 推理直接在 ISA 层面进行硬件加速 3. 无授权成本:RISC-V 完全开源,无需向 ARM 支付授权费,芯片设计成本显著降低
生态突破:NVIDIA 的背书
2024 年,NVIDIA 宣布累计出货超过 10 亿颗 RISC-V 核心(主要用于 GPU 微控制器),并积极推动 CUDA 生态向 RISC-V 架构迁移——这是 RISC-V 从"控制核"走向"AI 计算主核"的历史性信号。
RISC-V 的短板:软件生态的明显差距
然而,RISC-V 面临的挑战同样真实:编译器优化成熟度、推理框架适配完整性、操作系统生态稳定性,均明显落后于 ARM 和 x86。高端 RISC-V CPU 核的性能(IPC × 主频)目前仍落后于主流 x86/ARM 服务器核 30—50%。
RISC-V 的未来走向
RISC-V 的优劣势将呈现不对称放大趋势:技术优势(定制化、能效比)在 AI 推理特化场景中将持续放大;软件生态劣势则会随着产业投入增加而逐步收窄,预计到 2026 年底,高端 RISC-V 核的性能将与同代 ARM Neoverse 进入可比拟区间。最重要的是,架构主权的战略价值——尤其在中国市场——正在将 RISC-V 从技术选项升级为国家战略选择。
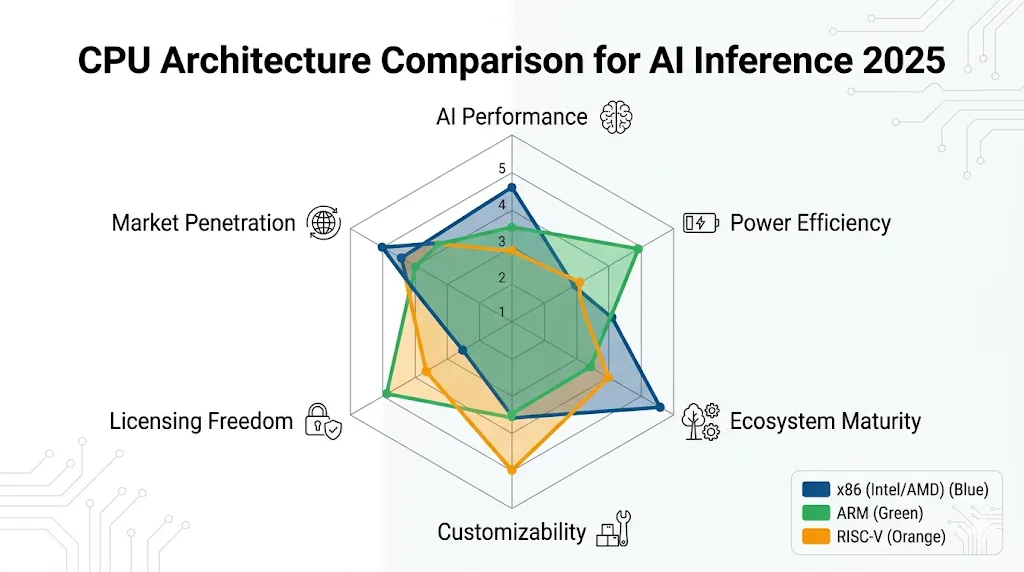
1.3 三大架构横向技术对比
第二章:为什么 AI 推理需要 CPU?——不是 GPU 不够强,而是场景不同
这是整篇文章最核心也是最常被误解的问题。GPU 在并行计算上的绝对优势是不争的事实——数千个 CUDA Core、高达 TB 级的内存带宽、超过 1000 TOPS 的 INT8 算力,这些规格让 CPU 望尘莫及。那么,为什么还需要 CPU 做 AI 推理?
答案不在于 CPU 更"强",而在于:GPU 并非在所有推理场景下都是最优解,甚至在某些关键场景下 GPU 存在明显劣势。
2.1 推理计算的本质特征:带宽受限,而非算力受限
首先需要打破一个根本性认知误区。
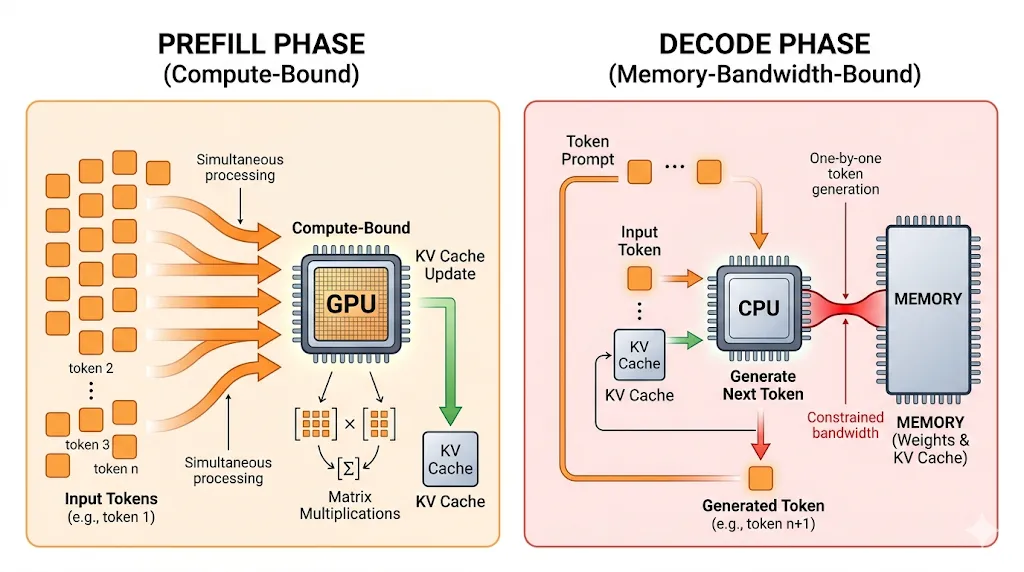
LLM 推理的计算过程分为两个截然不同的阶段:
预填充(Prefill Phase):并行处理输入 Prompt,将所有 Token 同时送入 Transformer 计算。这一阶段计算密集,FLOPs 利用率高,是 GPU 的主场。
解码(Decode Phase):逐 Token 自回归生成——每生成一个 Token,都需要完整地从内存中读取一次模型权重和 KV Cache。这一阶段计算量极低,但内存访问量极大,是典型的内存带宽受限(Memory-bandwidth-bound)操作。
以 Llama 3.1 70B 模型为例,解码阶段每生成一个 Token,需要读取约 140GB 的模型权重(BF16精度)。如果内存带宽为 1TB/s(高端 GPU 的水平),理论极限也只能达到约 7 tokens/s——与算力(TOPS)无关,与带宽直接挂钩。
这一特性的深刻含义是:GPU 那高达 2000 TOPS 以上的算力,在单流(Batch Size = 1)解码场景下几乎全部空闲,硬件利用率可能低至 5%,极度浪费。
现代高端 CPU(如 Intel Xeon 6 或 AMD EPYC 9005)的内存带宽通常在 460—500 GB/s 之间,配合系统的大容量 DDR5 内存,在中小批量推理任务中完全能够实现与 GPU 相近的吞吐效率,同时功耗和成本远低于 GPU 集群。
2.2 CPU 的五大核心优势场景
场景一:低延迟、低并发的在线推理
在 Batch Size 较小(1—8)的实时推理场景中(如 AI 客服、代码补全、个人助理),GPU 的大量并行计算单元无法被充分利用,反而因为 PCIe 传输开销、GPU 内存预热等因素带来额外延迟。CPU 直连内存、无传输延迟的架构优势,使其在此类场景下可以达到 50—200ms 的响应延迟,部分场景甚至优于 GPU(GPU 通常 10—50ms,但需要保持 GPU 常驻内存,成本高昂)。
场景二:成本敏感的中规模推理部署
对于中小企业而言,一块 NVIDIA H100 的市场价高达 3—4 万美元,且需要专用的电力和散热基础设施。与之相比,一台双路 Intel Xeon 6 服务器的采购成本约为 3—5 万元人民币,运行 7B 量化模型的推理速度可达 30—50 tokens/s,足以支撑中等规模的推理服务。CPU 推理是 AI 能力民主化的关键基础设施。
场景三:超大规模 MoE 模型的异构推理——CPU 的"结构性优势"
这是 CPU 在 AI 推理中最具技术深度的应用场景,也是2025 年学术界和工程界最热门的研究方向之一。
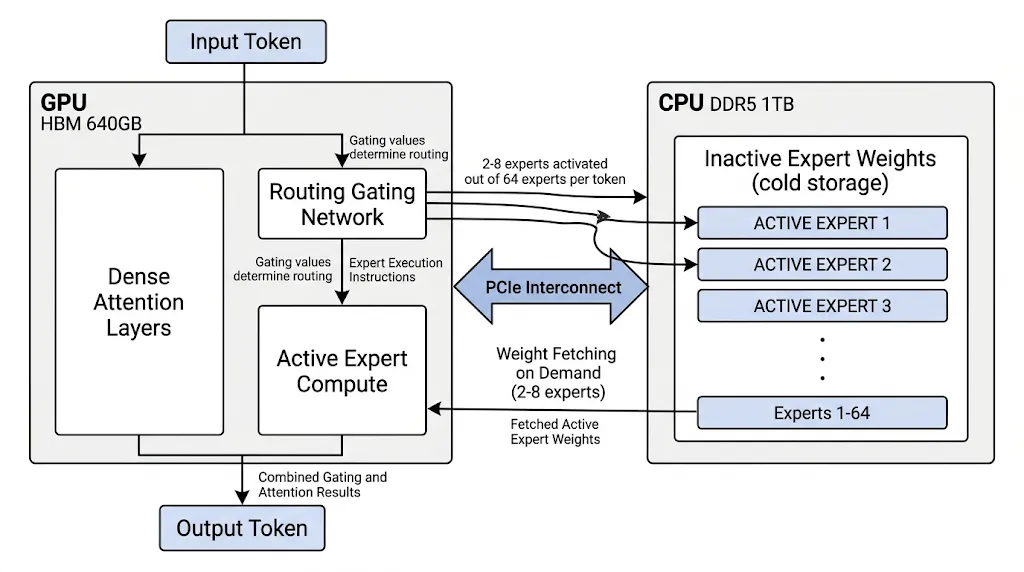
MoE 模型的悖论:以 DeepSeek-V3(671B 参数)、Mixtral 8×22B 为代表的混合专家(Mixture of Experts)模型,通过门控网络(Gating Network)将 Token 动态路由至少量激活的"专家子网络"进行计算——每个 Token 通常只激活 2—8 个 Expert,有效计算量远小于等效规模的稠密模型。
然而,MoE 模型存在一个严峻的硬件挑战:所有专家的权重必须常驻内存,但每次推理时只有极少数专家被激活。对于 GPU 而言,这意味着大量 HBM 显存被"占用但不使用",硬件利用率极低。一台 8×H100 服务器(80GB × 8 = 640GB HBM)的理论显存上限,仅能勉强装下 DeepSeek-V3 的 FP8 量化权重。
CPU 的异构调度优势:CPU 在此展现出 GPU 无法替代的能力:
1. 大容量 DDR5 内存作为权重缓冲池:单路服务器平台通常支持 512GB—1TB DDR5 内存,远超 GPU 的 HBM 容量,可容纳更多专家权重 2. 灵活的分支控制能力:专家路由本质上是动态条件分支——"这个 Token 走哪个 Expert?"这类稀疏、不规则的控制流,正是 CPU 乱序执行引擎(Out-of-Order Engine)和分支预测器的强项,而 GPU 的 SIMD 架构(同时执行相同指令的大量核心)在面对稀疏、不规则计算时效率极低 3. KV Cache 的分层管理:长上下文推理(32K—128K Token)使 KV Cache 快速膨胀,CPU 可作为 GPU HBM 的第二级缓存,实现 KV Cache 的动态卸载(Offloading)
KTransformers:CPU/GPU 混合推理的工程范本
清华大学发布的 KTransformers 框架(2025年在 SOSP 顶会发表)是迄今最具代表性的 MoE 异构推理工程实践。其核心思路是:将 MoE 模型的 Expert 权重卸载至 CPU DDR 内存,仅将稠密的 Attention 层和 Gate 网络保留在 GPU 上执行。
技术细节层面,KTransformers 实现了:
• 基于 AMX 的 Tiling 感知内存布局(AMX tiling-aware memory layout),在 CPU 侧最大化矩阵乘法效率 • 动态 Expert 调度(Expert Deferral):将 CPU 利用率从 74% 提升至 100%,GPU 利用率从 28% 提升至 37%,解码吞吐提升 33—45% • 支持在一台消费级工作站(单 GPU + 大容量内存)上运行 DeepSeek-V3 671B 全量参数模型
类似的研究还包括 HybriMoE(2025):通过动态层内调度(Intra-layer Scheduling)、影响力驱动预取(Impact-driven Prefetching)和分数感知缓存(Score-aware Caching),在标准 CPU/GPU 混合平台上实现了 Prefill 延迟降低 1.33×、Decode 延迟降低 1.70×。
一句话结论:GPU 是 AI 计算的超级跑车,但 MoE 推理的"赛道"是充满岔路的复杂地形,而 CPU 才是真正擅长在复杂路况下灵活调度的全地形车。两者的最优解是协同,而非替代。
场景四:边缘端侧推理的功耗约束
在手机、PC、嵌入式设备等端侧场景中,功耗包络通常在 5—45W 之间,GPU 根本没有登场机会。ARM 大小核架构(big.LITTLE™)将高性能核与能效核相结合,配合 NPU 单元,在功耗受限条件下实现推理效率的最大化。Apple M4 Pro、Qualcomm Snapdragon X Elite 等端侧旗舰 SoC 均以此架构实现了 7B—13B 量化模型的本地流畅推理。
场景五:隐私敏感与离线推理
医疗、法律、金融等领域的企业客户,出于数据隐私合规要求(如 GDPR、数据本地化法规),无法将数据发送至云端推理服务。本地 CPU 推理服务器提供了"数据不出境"的完整闭环解决方案,这一需求在 2025 年随着全球数据主权立法的强化而快速增长。
2.3 CPU 需要具备的六大 AI 能力维度
基于上述场景分析,AI 推理时代对 CPU 的技术能力要求可以归纳为六个维度:
① 矩阵运算原生加速
从 SIMD 向量运算向 Tile 矩阵运算的跨越是关键分水岭。Intel AMX、ARM SVE2、RISC-V V Extension 分别代表三大阵营在这一维度的解题路径。核心指标:单 CPU 路 AI TOPS(INT8),主流高端服务器 CPU 目前约在 30—100 TOPS 区间。
② 超大容量、高带宽内存子系统
推理是带宽受限的计算。主流服务器 CPU 平台的 DDR5 内存带宽约 460—500 GB/s,是 LLM 推理 KV Cache 吞吐的硬上限。未来趋势是 CXL(Compute Express Link)内存扩展技术的引入,将内存容量从 TB 级扩展至 10TB+,以容纳超大规模 MoE 模型的完整权重。
③ 高效的分支预测与乱序执行
MoE 路由的核心就是稀疏分支控制流。现代高性能 CPU(Intel Xeon 6、AMD Zen 5、ARM Neoverse V3)的分支预测准确率已超过 99%,乱序执行窗口(ROB 大小)通常在 256—512 条指令,使稀疏 Expert 路由的调度效率远高于 GPU 的 SIMT 执行模型。
④ 量化推理栈的硬件原生支持
INT8、BF16、FP8、INT4 等低精度量化格式是降低推理内存占用和提升带宽效率的关键技术。新一代 AI CPU 必须在硬件层面对这些格式提供原生计算支持(而非软件仿真),否则量化带来的理论收益将大打折扣。
⑤ 高效的 CPU/GPU 异构互联
对于云端大模型推理,CPU 不可能独立承担全部计算——它更多时候是作为 GPU 的"指挥中枢"和"内存扩展池"。PCIe 5.0(带宽 128 GB/s)、CXL 3.0 等高速互联技术的成熟,是 CPU/GPU 异构协同效率的关键基础设施。
⑥ 软件生态与推理框架的深度集成
硬件能力最终需要通过软件栈落地。Intel 的 oneAPI + OpenVINO、ARM 的 Compute Library + KleidiAI、RISC-V 生态的 LLVM/GCC 工具链适配,是三大阵营在"最后一公里"的竞争焦点。llama.cpp、vLLM、SGLang 等主流推理框架对 CPU 后端的优化深度,直接决定了 AI CPU 的实际可用性。
第三章:中国 AI CPU 生态——自主可控背景下的技术突围
中国 AI CPU 市场的特殊性在于,它同时受到两股强大力量的驱动:AI 推理应用的商业需求 和 技术自主化的国家战略。中美科技博弈带来的出口管制压力,反而加速了国内 AI CPU 生态的形成——一个以"两超引领、三强支撑、一新突破、创企涌现"为主要格局的自主算力体系正在成形。
3.1 格局概览:两超、三强、一新与创业新锐
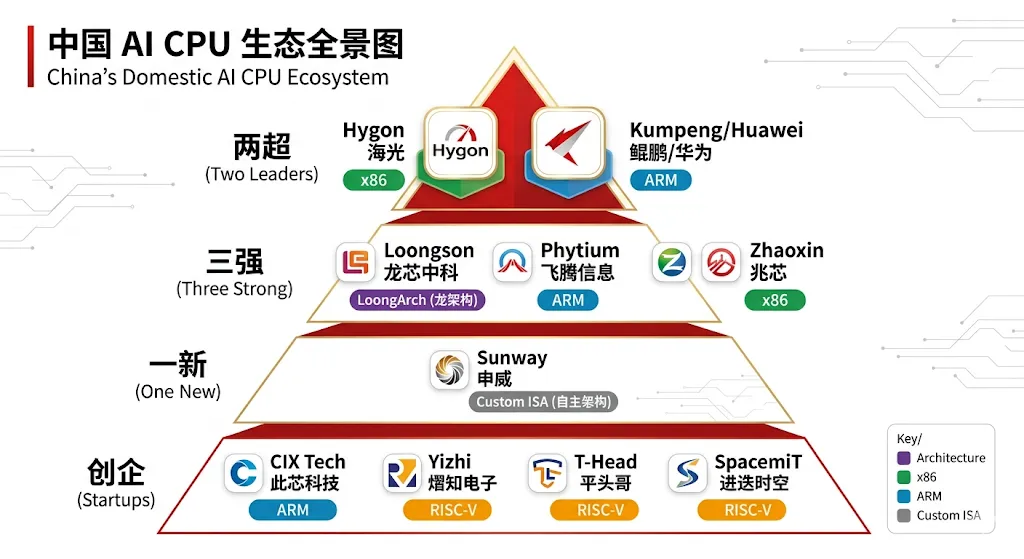
业界通常以技术来源、市场规模和战略地位,将国内 AI CPU 玩家划分为四个梯队:
• 两超:海光信息(x86 兼容,商业规模最大)、华为鲲鹏(ARM 授权,生态最完整) • 三强:龙芯中科(自主 ISA LoongArch)、飞腾信息(ARM 授权,军工/国防背景)、兆芯(x86 兼容,上海国资背景) • 一新:申威(自主 ISA,超算专用,民用化探索中) • 创企新锐:此芯科技(ARM AI PC)、熠知电子(RISC-V CPU+NPU 混合 XPU)、阿里平头哥(RISC-V 服务器)、进迭时空(RISC-V 边缘)
每一梯队背后,有着截然不同的技术逻辑与竞争战场。
3.2 两超:商业化规模与生态完整度的领跑者
▌海光信息(Hygon):x86 兼容路线的现实主义
海光选择了国内 AI CPU 玩家中生态兼容性最强的路线——基于 x86 指令集架构,兼容现有 Linux 生态和主流 AI 框架,可无缝运行为 Intel/AMD 优化的应用。
这一选择有其历史背景:海光曾与 AMD 存在技术合作,其早期 CPU 微架构基于 AMD Zen 的衍生设计。尽管目前已完全独立演进,x86 兼容性使其对企业客户的迁移成本极低——这正是其快速商业化的根本原因。
核心产品与 AI 战略:
海光的 AI 推理竞争力,来自其"CPU + DCU 双芯协同"体系——这也是 2025 年 HAIC 峰会发布的核心战略:
• 海光 CPU(x86):承担通用计算、任务调度、系统管理,是 AI 推理系统中的"控制大脑";支持最高 128 核/512 线程的下一代规格 • DCU(Deep Computing Unit):自研 GPGPU 架构加速器,兼容类 CUDA 环境(DTK 软件栈),DCU8100 系列算力对标 NVIDIA A100/AMD MI100,并已被 DeepSeek 官方列为一类支持的国产硬件平台
量化指标: 海光 2025 年 Q3 营收同比增长 57%,2026 年 Q1 延续高速增长,是国内 AI 算力需求爆发的直接受益者。
核心优势:迁移成本最低(x86 生态无缝兼容)、AI 框架原生支持(DeepSeek/PyTorch/TF 全覆盖)、"CPU+DCU"一体化部署方案成熟。核心挑战:x86 授权的长期合规性存在不确定性;DCU 在 FP16/BF16 混精度推理上与 NVIDIA 仍有代差,主要竞争力集中在 INT8 量化推理场景。
▌华为鲲鹏(Kunpeng):ARM 生态的中国标杆
鲲鹏是华为海思自研的 ARM 架构服务器 CPU,也是国内生态体系最完整、算力集成度最高的国产 CPU 平台。
旗舰产品鲲鹏920:
• 基于 ARMv8 架构,7nm 工艺,最高 64 核,主频 2.6GHz(高端型号达 3.0GHz) • SPECint 分值超过 930,超行业基准 25%,能效比优于行业标准 30% • 支持 8 通道 DDR4,内存带宽较竞品提升 46% • 集成双 100GbE RoCE 网络接口,PCIe Gen4,CCIX 跨芯片一致性互联
AI 推理生态:
鲲鹏的差异化优势在于与华为昇腾 AI 加速器的深度协同。在"鲲鹏 CPU + 昇腾 NPU"的组合架构中:
• 鲲鹏负责模型加载、数据预处理、任务调度、KV Cache 管理 • 昇腾负责 Transformer 矩阵运算等计算密集型推理核心
这一架构在 DeepSeek 等大模型的国内部署中表现突出。2025 年华为合作伙伴大会上,多家厂商联合基于鲲鹏硬件底座发布 DeepSeek 一体机,成为国产 AI 推理服务器的重要标志性事件。
市场数据(2024—2025): IDC 数据显示,2024 年中国 ARM 服务器出货量同比增长 87%,收入同比增长 192.2%;鲲鹏处于这一增长的核心位置,市场份额突破 20%(通用计算服务器市场)。
核心优势:华为全栈(鲲鹏+昇腾+欧拉 OS+MindSpore 框架)生态闭环,软硬件协同优化深度国内无出其右;在党政、金融、运营商三大主战场长期深耕,国产化替代渗透率最高。核心挑战:美国出口管制持续压制先进制程的获取,鲲鹏下一代产品的工艺演进路径受限,与国际最新 ARM 服务器芯片(Neoverse V3,3nm)的工艺代差有拉大风险。
3.3 三强:细分领域的自主化守门人
▌龙芯中科(Loongson):自主 ISA 的长期主义
龙芯是国内坚持完全自主 ISA最彻底的 CPU 厂商,没有之一。其自研 LoongArch™ 指令集,在架构设计层面不依赖任何境外授权。这一选择在当前地缘政治背景下具有极高的战略溢价,但也意味着必须独立构建整个软件生态,代价相当高昂。
旗舰产品 3C6000 系列(2025 年 6 月发布):
• 单芯 16 核(3C6000/S)至四芯 64 核(3C6000/Q),FP64 算力 844.8 GFlops—3072 GFlops • 独创 LoongLink 片间高速互联,实现多芯一致性互联(设计理念对标 NVLink/CXL) • 中国电子标准院测试:64 核 3C6000/Q 整机性能超越 Intel Xeon Platinum 8380(40 核)
AI 推理布局:
• 配套 9A1000 GPGPU(2025 年 Q4 流片):INT8 算力 32 TOPS,支持 LoongArch 原生 AI 推理栈 • 下一代 9A2000 预计性能提升 8—10×,定位中小规模 AI 推理集群 • 端侧方面,3B6000M 芯片集成第二代 GPGPU(LG200),支持 8 TOPS AI 推理
市场定位:党政、金融、能源、电力等关键信息基础设施领域的国产化"最后防线"。在这些场景中,LoongArch 的完全自主可控是不可替代的核心竞争力,而非性能。核心挑战:主流 AI 框架(PyTorch、TensorFlow、vLLM 等)对 LoongArch 后端的支持深度有限,推理框架生态成熟度与 x86/ARM 存在 2—3 年的差距;商业化推进速度受制于生态建设节奏。
▌飞腾信息(Phytium):ARM 授权体系的军工出身
飞腾起源于国防科技大学,背景与龙芯相近,但选择了 ARM 授权路线——在自主可控与技术成熟度之间取得了务实的平衡。其产品线完整覆盖桌面、嵌入式、服务器三大市场,是国内 ARM CPU 阵营中除鲲鹏之外的最重要玩家。
核心产品线:
AI 推理进展(2025):
飞腾采用"CPU + AI 加速卡"的协同部署策略:
• 腾云 S5000C 服务器平台已实现对 DeepSeek 全系列大模型的端到端支持,覆盖数据中心与终端场景 • 飞腾 AI Lab 测试:基于 S5000C 单机 8 卡推理平台,DeepSeek-R1-Distill-Llama-70B 推理速度达 22 tokens/s,推理效率与境外同类架构相当 • 战略方向:"通用计算 + 智能计算双轮驱动",CPU 基础性能持续提升,同时加快"CPU+XPU"异构 AI 算力布局
市场数据:截至 2024 年底,飞腾 CPU 累计出货量突破 1000 万片,成为国内首个突破这一里程碑的国产 CPU 品牌。在亚太区 ARM 服务器市场,飞腾与鲲鹏共同占据本土市场约 15% 份额(政府及特定行业场景)。
核心优势:军工/国防背景带来的可信供应链;产品线完整,覆盖终端到数据中心;ARM 生态兼容性较好,软件适配成本低于龙芯。核心挑战:ARM 授权风险同样存在(尽管历史上飞腾曾面临授权中断风险);在商用市场与鲲鹏的正面竞争中处于下风;AI 推理软件栈的生态建设仍需加速。
▌兆芯(Zhaoxin):x86 兼容的上海样本
兆芯是上海市国资背景下,VIA Technologies(威盛)与上海国资委合资的产物,是国内另一条 x86 兼容路线的代表。其技术来源于 VIA 对 x86 授权的历史积累,走的是"渐进式架构自研 + 生态兼容"的路线。
旗舰产品 KX-7000(2024—2025 发布):
• 全新自研"世纪大道"(Century Avenue)微架构,12nm 工艺,最高 8 核,主频 3.7GHz • SPEC CPU2017 整数测试较上代提升 48.8%,浮点测试提升超 2× • 支持 DDR5 和 PCIe 4.0,图形性能提升 4×
AI 推理战略(2024—2025):
• 基于 KX-7000 平台,联想等 OEM 厂商已推出面向信创市场的 AI PC 产品(联想开天 P90z G1t),内嵌本地大模型推理能力 • 商用翻译机等边缘 AI 应用已在 KX-7000 上实现 95%+ 的功能迁移,验证了国产 x86 平台的工程可用性 • 路线图产品 KX-S(下一代):8 核 16 线程,主频突破 3.5GHz,将集成专用 NPU 单元,彻底告别依赖外置 GPU 的 AI 加速模式
核心优势:x86 生态兼容,软件迁移成本极低;上海国资背景,在本地信创采购中具有政策红利;KX-7000 架构自研度较高,授权合规性风险低于海光。核心挑战:性能仍落后于 Intel Core/AMD Ryzen 主流一代以上,在非政策驱动的市场中缺乏纯商业竞争力;AI 推理生态建设(NPU 工具链、推理框架适配)尚处早期阶段。
3.4 一新:申威——超算基因,民用化破局
申威(Sunway)是中国 AI CPU 格局中最特殊的存在:拥有完全自主的指令集架构,且经历了世界级超算(神威·太湖之光)的工程验证,但长期游离于民用商业市场之外。
技术内核——SW26010-Pro:
申威最新一代处理器 SW26010-Pro 是目前已知单颗处理器核心数最多的量产芯片之一:
• 单芯 384 个计算核心,分布于 6 个核心组(CG) • FP64 峰值算力 13.8 TFLOPS,计算核主频 2.25 GHz • 数万颗 SW26010-Pro 互联可组成总核数超 4000 万的超算系统,具备 E 级(百亿亿次)计算能力
申威架构的核心特点是:使用本地存储(local memory)替代传统 Cache,允许精确控制数据移动,这种设计在大规模并行计算中可以避免 Cache 一致性开销,但对程序员的编程能力要求极高。
AI 推理潜力:
学术界已开始探索在申威超算上优化 AI 推理。SWattention(2024 年发表,《The Journal of Supercomputing》)是首个专为 SW26010-Pro 设计的 Transformer 注意力机制高效实现,显著降低了 LLM 推理在申威上的内存访问开销和延迟。这标志着申威架构已从"科学计算专用"向"AI 推理可用"迈出关键一步。
民用化路径:
申威当前的民用化难题集中在两点:其一,民用软件生态几乎为零,应用开发门槛极高;其二,现有硬件形态(超算节点)不适合数据中心 AI 推理的标准化部署。未来的突破方向可能在军用/航天 AI 推理(高可信、完全自主)以及科学计算与 AI 融合(气象预报、分子动力学仿真)的交叉领域。
战略定位:申威代表了中国算力自主化的"战略纵深"——不是当下的商业选择,而是极端情境下的兜底保障。
3.5 创业新锐:差异化突围的新生力量
▌此芯科技(CIX Technology):ARM 生态的端侧 AI PC
此芯科技由顺为资本等机构支持,专注于 AI PC 端侧推理,与高通 Snapdragon X 系列直接竞争。
此芯 P1 SoC(2024 年发布,首款国产量产 ARM AI PC 芯片):
• ARM big.LITTLE™ 架构:8 性能核 + 4 能效核,主频最高 3.2GHz,集成 2 个 SVE2 向量加速单元 • 提供 45 TOPS 端侧 AI 异构算力(CPU+GPU+NPU 统一内存架构) • 支持 100 亿参数以内大模型本地部署,推理速度 30+ tokens/s • 2025 年 6 月:联合登临科技推出"CPU + 外挂 AI 加速卡"边缘一体机,将算力边界延伸至更大规模推理场景
技术路线评价:ARM 授权带来软件生态天然兼容优势,是商业化最快的路径;代价是授权依赖风险。中期看,随着此芯科技规模扩大,向 RISC-V 或自研 ISA 的演进将是自然选择。
▌熠知电子(Yizhi Electronics):XPU——CPU+NPU 融合的新物种
熠知电子是国内 AI CPU 创业赛道中技术路线最具创新性的玩家之一。公司成立于 2017 年,核心团队拥有 15 年以上半导体经验,专注于高端服务器 CPU+NPU 混合算力芯片的设计,自定义了"XPU"这一新型架构范式。
XPU 架构的核心理念:
不同于"CPU 旁挂 GPU/NPU 加速器"的传统异构方案,熠知的 XPU 将 CPU 通用计算核心 与 AI 神经网络专用推理单元(NPU) 深度融合在同一芯片上,共享统一内存和高速互联总线,从根本上消除 CPU-加速器之间的 PCIe 带宽瓶颈和数据搬运开销。这一设计与 NVIDIA Grace Hopper(CPU+GPU 统一内存)的思路一脉相承,但剑指服务器推理场景的更低成本实现。
旗舰产品 TF9000 系列(第三代):
• 定位对标 NVIDIA Grace CPU(ARM 架构服务器 CPU) • 核心性能提升 30%,成本降低 30%(相比对标产品) • 内存带宽提升 200%,PCIe 5.0 带宽提升 100%,内存总容量提升 300% • 面向云计算、大模型一体机、工业智能化等高算力场景
投资背景:2026 年 1 月,上海科创集团宣布战略投资熠知电子,是上海科创资本首次投资 XPU 混合芯片领域,意味着地方政府算力自主化资本正在向创新架构倾斜。
技术路线评价:熠知的 XPU 融合路线代表了 AI 推理芯片设计的前沿方向——从"外挂加速"走向"原生融合"。若 TF9000 的性价比主张得以产品化落地,将对"CPU + 独立 GPU"的传统服务器 AI 推理部署模式形成直接挑战。当前主要风险在于量产交付能力验证和软件生态的配套建设。
▌RISC-V 创新阵营:平头哥 & 进迭时空
阿里平头哥 XuanTie C950(2026 年 3 月):台积电 5nm,主频 3.2GHz,是目前全球性能最高的 RISC-V 服务器 CPU,面向数据中心 AI Agent 推理场景深度优化;XuanTie 系列已成为 RISC-V 高性能服务器核的全球技术标杆。
进迭时空 SpacemiT K3(2026 年 1 月):RISC-V 边缘 AI CPU,功耗 15—25W,声称支持 800 亿参数模型本地推理,专攻零售机器人、工业网关、车载等边缘场景,是 RISC-V 向高性能边缘推理市场突破的代表性产品。
3.6 中国 AI CPU 竞争格局全景对比
3.7 中国 AI CPU 的战略意涵
中国 AI CPU 生态的多元化路线,折射出深层的技术战略逻辑,不同梯队承担着不同的历史角色:
两超承担商业放量:海光和鲲鹏以成熟的 x86/ARM 生态为支撑,将在 2025—2027 年的国内 AI 推理基础设施建设中承担主力,共同分食因出口管制催生的"国产替代"市场红利。
三强守卫战略纵深:龙芯、飞腾、兆芯在各自的细分战场(党政关基、军工国防、信创桌面)构建差异化壁垒,是不依赖境外授权的自主可控"最后防线"。三者的竞争力高度依赖政策采购,市场化空间有限但韧性极强。
申威守卫极端底线:申威代表了中国算力自主化的"战略纵深储备"——极端情境下技术完全自主、不受任何境外约束的终极算力底座。
创企定义未来形态:此芯(ARM AI PC)、熠知(CPU+NPU XPU)、平头哥(RISC-V 服务器)代表了三个方向的前沿探索。其中,熠知的 XPU 融合架构最具颠覆潜力——若能实现量产和软件生态配套,将为 AI 推理芯片的产品形态提供一种中国原创的答案。
短期(1—3 年):海光+鲲鹏主导增量市场,飞腾+龙芯稳固关基存量。中期(3—5 年):XPU 融合架构(熠知)、RISC-V 服务器(平头哥)逐步进入主流视野,LoongArch 生态成熟度持续提升。长期(5 年以上):RISC-V 有望成为中国 AI 芯片生态的"底层共识协议";架构竞争的胜负将越来越多地由软件生态和算法框架适配深度决定,而非单纯的硬件规格。
第四章:市场格局与前瞻判断
4.1 市场规模:推理时代的增量爆发
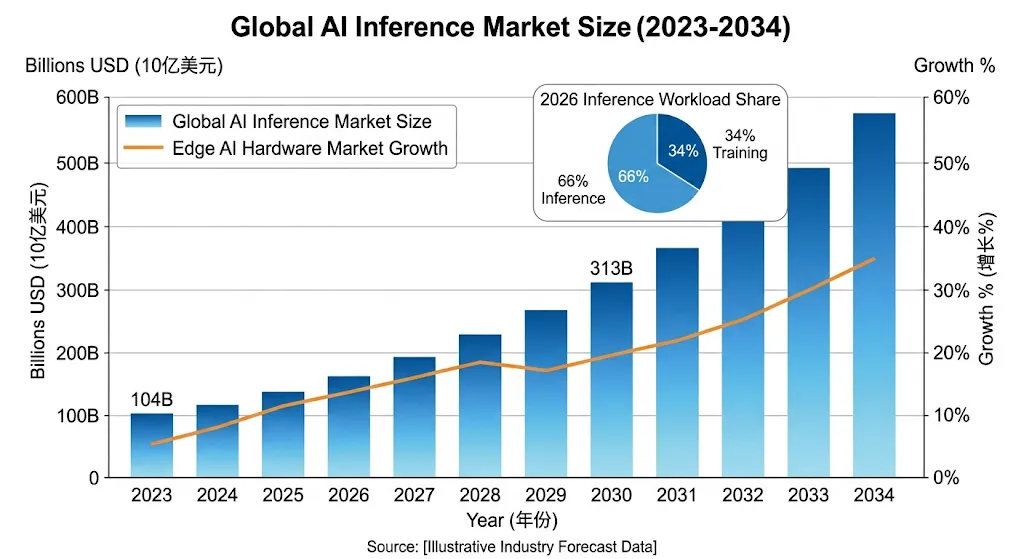
几组核心数据勾勒市场全貌:
• 全球 AI 推理市场 2025 年约 1037 亿美元,预计 2034 年达 3126 亿美元,CAGR 约 13% • 边缘 AI 硬件市场 2025 年约 262 亿美元,2031 年将达 687 亿美元,CAGR 约 17.5% • 推理工作负载占 AI 全量计算的比重:2023 年约 1/3 → 2025 年约 1/2 → 2026 年预计 2/3 • 边缘侧 CPU 在边缘 AI 硬件市场的体量占比约 88.8%(2024 年),CPU 是端侧 AI 不可绕过的核心载体 • RISC-V SoC 市场渗透率:2024 年 5.9% → 2031 年 25.7%(预测)
4.2 三层竞争结构
第一层:超大规模自研(Hyperscaler Custom Silicon)
AWS Graviton5、Google Axion、Microsoft Cobalt 代表了 ARM 架构在数据中心的最高形态。这类芯片深度绑定云服务商的专有推理栈,形成"自研芯片 + 自研框架 + 自有基础设施"的垂直闭环,护城河极深,且不对外销售。这一层的竞争本质是超大规模云厂商之间的算力主权之争,外部玩家难以介入。
第二层:通用商用 CPU(Intel、AMD、ARM IP 授权)
Intel Xeon 6 和 AMD EPYC 9005 守卫着全球数亿台现存服务器的存量市场——这是短期内无可撼动的基本盘。Intel 在 AI PC CPU 市场的份额约 56%(2025 年),是端侧 AI 入场的重要渠道。但在数据中心增量 AI 推理服务器市场,ARM 的渗透速度正在快速提升,x86 的市场份额承压趋势明显。
第三层:RISC-V 新生态与中国本土阵营
以阿里平头哥、进迭时空、龙芯(自主 ISA)、海光(x86 兼容)为代表的中国 AI CPU 玩家,背靠国内市场的巨大体量和技术自主化政策,形成了独特的"中国 AI CPU 小生态"。这一层的竞争逻辑既有商业驱动,也有政策驱动,估值逻辑与全球市场存在显著差异。
4.3 五个前瞻判断
判断一:内存带宽将超越 TOPS,成为 AI CPU 的首要评价指标
大模型推理的带宽密集特性决定了,能够提供更高内存带宽(HBM 集成、LPDDR5X 优化、CXL 扩展)的架构,将在推理场景中获得系统级竞争优势。未来 3—5 年,"内存带宽/参数量"将成为选型的核心性价比指标,而非单纯的 TOPS。
判断二:CPU/GPU/NPU 异构融合是推理架构终局
纯 CPU 推理和纯 GPU 推理都是过渡形态。无论是 Intel Xeon + Gaudi 的服务器端协同,还是 Apple M 系列的端侧三核融合,"异构集成、统一内存、协同调度"将成为 AI 推理硬件的主流范式。MoE 模型的大规模部署将进一步强化这一趋势。
判断三:ARM 将主导增量市场,x86 稳固存量市场
Arm 的 2029 年预测(定制 AI ASIC 服务器中 90% 的主机 CPU 将基于 ARM)并非空穴来风。超大规模云厂商的持续自研投入是最有力的市场信号。但 x86 在数十亿台存量设备和 Windows 生态中的统治地位,短期内无人能撼动。这是一场"增量被 ARM 拿走、存量 x86 守住"的结构性演变。
判断四:RISC-V 是中国 AI 芯片生态的战略支点,5 年后价值将被重新评估
RISC-V 当前最重要的价值不是性能,而是架构主权。在出口管制压力持续演化的背景下,构建"RISC-V ISA + 自主编译器 + 开源推理框架"的完整技术栈,是中国 AI 算力自主化的必经之路。这一逻辑在当前市场估值中尚未被充分 Price In。
判断五:边缘 AI CPU 是 2026—2028 年最快增长的细分市场
端侧 AI 推理的爆发——手机、PC、汽车、机器人、IoT 设备——将以 17.5%+ 的 CAGR 快速增长,远超云端 AI 推理的增速。在这一市场中,ARM 和 RISC-V 是主导架构,而"百亿参数 × 本地推理 × 低功耗"将成为产品竞争力的核心三要素。
结语:CPU 的第二春,由 AI 推理亲手书写

GPU 是 AI 训练时代的毋庸置疑的主角,但推理时代的剧本,正在被 CPU 悄悄改写。
当 AI 推理从云端数据中心蔓延至每一台手机、每一辆汽车、每一个工业网关,CPU 的部署规模优势将被充分释放。AMX 矩阵引擎、ARM 能效优势、RISC-V 架构主权——三条技术路线,分别对应着三种商业逻辑,三个时代机遇。
而 MoE 大模型的兴起,是这个故事最戏剧性的转折:原本被认为"只能辅助"的 CPU,在稀疏专家调度、KV Cache 卸载、异构协同推理等关键工程挑战上,展现出 GPU 无法独立完成的结构性价值。
对于技术从业者而言,理解这场架构之争的本质,是做出正确技术选型的前提。对于投资者而言,在 GPU 估值高企的当下,AI CPU 赛道——尤其是 ARM Hyperscaler 生态、中国本土 x86 兼容/RISC-V 产业链——或许正是那个在大浪叙事中被系统性低估的 Alpha。
不是所有的算力革命,都发生在 GPU 机房里。
数据与资料来源(综合整理自以下公开信息,数据截至 2026 年 Q1):MarketsandMarkets AI Inference Market Report · SemiEngineering · Tom's Hardware · The Register · Arm Newsroom · CNBC · South China Morning Post · EDN China · AWS Blog · Google Cloud Blog · Digitimes · 清华大学 KTransformers 论文(SOSP 2025)· HybriMoE 论文(arXiv 2025)· Intel AMX 技术文档 · 龙芯中科官方发布 · 海光信息 HAIC 2025 峰会材料 · 此芯科技官网 · 阿里巴巴 DAMO 院官方发布
本文为技术研究性文章,不构成任何投资建议。
