 夜雨聆风
夜雨聆风
一个 CPU 模块的 UT 级验证,从拿到 spec 到 sign-off 签字,通常需要一位资深验证工程师投入四个月以上。现在,有人用三个 AI agent 串成的流水线,把这件事压到了两天以内——覆盖率不降反升,过程中还发现了两位资深工程师都没注意到的 spec 与 RTL 的隐性不一致。
这不是实验室里的概念验证。最终产物是一份完整的 sign-off package:line coverage 99.86%、branch 99.74%、functional coverage 100%(effective)、17 个 testcase 全部 PASS、58 个 waiver 每一条都有技术 justification、282 个测试点全部可追溯到 spec。和人工做出来的包放在一起,sign-off committee 分不出哪份是 agent 跑的。
更值得关注的是后面发生的事:跑完这个模块之后,团队把过程中踩的 11 个坑编码回了 skill 本身——下一个模块用同一条流水线,这 11 个坑不会再踩。工具在用的过程中自己变强了。
核心结果:
- 人工做同一个模块至少 4 个月;三个 skill 联合闭环压到 1-2 个工作日——近 60 倍加速
- 三个 skill 串联构成 8 Phase 核心流水线,6 个全自动,2 个由人做高价值判断
Line 覆盖率 99.86%,Branch 99.74%,Condition 92.86%,Functional coverage 100%(effective) 17 个 testcase,282 个测试点,58 个 waiver(全部有技术 justification) 过程中发现并修复了 2 个隐藏的采样 bug,找到 1 条 spec 与 RTL 的隐性不一致 整条闭环的经验被反哺回 skill 自身,完成了第一轮自我进化
最后一条是这篇文章最想讲的:不只是"用 AI 做完了一个模块的验证",而是"做完之后把踩的坑编码回了工具,让下一个模块更快"。
为什么模块级 UT 这么磨人?
一个典型 CPU 子模块(ITLB、LSU、分支预测的一部分)的输入材料通常包括:架构 spec 50-150 页 PDF、RTL 源码 3k-15k 行 SystemVerilog、寄存器 + 接口文档 10-50 页、历史 bug 复盘 0-30 条。合计轻松突破 30 万 token。人脑一次塞不下,大模型即使 context 够长,注意力也会摊得很薄。
输出的测试点表有严格格式:12 列,每条都要可追溯(到 spec 章节)、可度量(明确的 checkpoint)、有优先级、有分解方法、有覆盖模型。一个合格的 testpoint 表往往 300 条起步,需要按 8 个维度做平衡覆盖——基础结构、输入路径、内部状态、内部更新、输出路径、异常恢复、时序反压、cross 场景。
新人写出的测试点,D1/D2 占 50% 以上,D7/D8 几乎是空的。这种不平衡直接反映到后续的覆盖率爬坡——D7/D8 缺失的模块,代码覆盖率会在 80% 左右卡死,再往上每一个百分点都要用大量随机测试去碰运气。前期省下来的 3 天,后期要用 3 周还回来。
而验证的后半段——从"UVM 环境写完"到"sign-off 签字"——同样磨人。218 条 checklist 要逐条走读,RM 边界要架构师 review,SVA 要设计,coverage hole 要逐个分析是"真的没覆盖"还是"采样链路断了",waiver 要逐条写理由。这一段没有 glamour,全是合规性工作,但少了任何一步 sign-off committee 都不会签字。
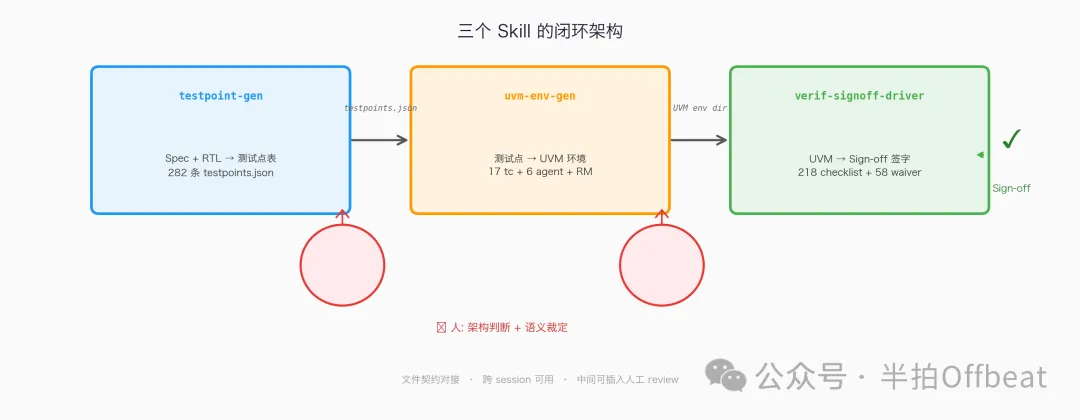
三个 skill 各自干什么
三个 skill 的边界非常清晰:
| testpoint-gen | ||||
| uvm-env-gen | ||||
| verif-signoff-driver |
它们之间用文件契约对接,不是函数调用。testpoints.json 是前两个 skill 的中间产物,也是第三个 skill 的输入。这种解耦让三个 skill 可以独立迭代、跨 session 运行,也允许人在任何一个节点插入 review 或手动修改。
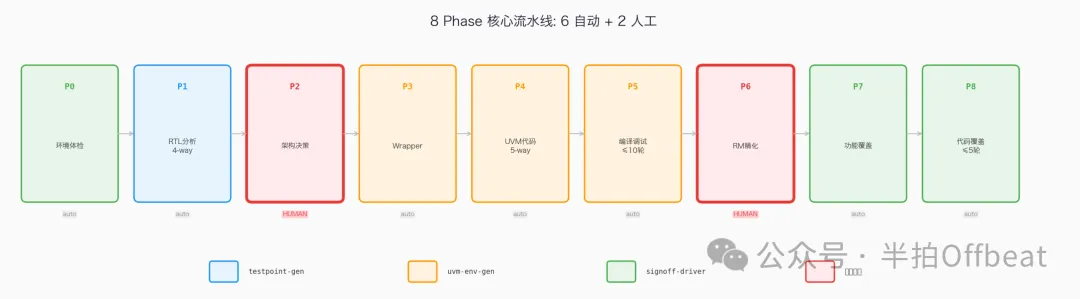
8 Phase 闭环:6 自动 + 2 人工
三个 skill 合起来构成一条 8 Phase 核心流水线:
| 2 | 架构决策 | 单 | 人 | 人 |
| 6 | RM 精化 + mismatch 裁定 | 单 | 人 | 人 |
Phase 2(架构决策)和 Phase 6(语义裁定)是整条流水线上判断力最密集的两个点。它们不是 agent 做不了所以退回来让人做——它们本来就应该由人做。人在 Phase 2 注入的不是信息,是判断:预算、ROI、架构稳定性、上下游解耦可能性——这些东西不在任何文件里。
Phase 2 让人介入不是退步。这是流水线懂事的证明:它知道哪些事该自动化、哪些事必须人做,并主动停下来等人。
Sign-off 驱动:6 阶段 × 5 个 checkpoint
第三个 skill verif-signoff-driver 是整条闭环的"收官"环节。它从"覆盖率已收敛"出发,用一个 6 阶段状态机驱动 sign-off 流程:
5 个硬 checkpoint,其余全自动。最终产出是一份可以交给 sign-off committee 的完整 package:覆盖率分析报告、追溯矩阵、waiver 报告、bug 列表、checklist 状态、签字页。
深度 debug:6 层追踪找到采样根因
Sign-off 过程中最有价值的技术发现是——functional coverage 的采样链路断了,导致 page_size 覆盖率永远是 0%。
这个 bug 非常隐蔽。我们先跑了 1000 个 random seeds(functional 只涨了 0.16pp),又试了 clean rebuild(发现 VDB 目录用 rm -f 删不掉导致旧 design database 残留),又写了 VA diversity 的 tc(发现 bins 不在预期的 covergroup 里)。每一次"以为找到了"都被新的数据推翻。
最终定位到 RTL 的一个 always_ff 块:
tlb_size_c2 只在 dbg_tlb_rw_c1=1 (debug read) 时更新
↓ 正常 lookup 时输出 stale 值或 X
↓ monitor 采到的 size 永远不匹配 bin 定义
↓ 同时 lu2common 的 skip_output 关闭了 fcov 通道
↓ 非 4K 页的采样被完全阻断
两个 bug 叠加:debug-gated 信号让 size/global/smash 三个字段在正常 lookup 时输出无效值;lu2common 的 skip_output 和 fcov 共用同一个 analysis port,RM skip 时顺带关了 fcov。单修一个都不会生效——必须同时修。
修复方式:在 tb_top 加 ungated flop 从 RTL 内部直接采样 C1 信号;给 lu2common 加独立的 fcov analysis port,始终输出,不受 skip 影响。
修复后,cp_page_size 从 0% 跳到 100%,cg_context 从 30% 跳到 75%。整体 functional coverage 从 57.76% 提升到 65.33%。
这说明什么?1000 个 random seeds 只涨 0.16pp,修采样链路涨 7.57pp。当 coverage 不涨时,先查采样,再查 stimulus。这是我们在整个 sign-off 过程中学到的最贵的一课。
覆盖率收敛:从 57% 到 100%
| random 无效 | ||
| +58 waivers | 100% effective |
最终数字:
| Functional | 65.33% raw / 100% effective | PASS |
58 个 waiver 分 11 类,每一个都有技术 justification。最大的一类是 cross bulk waiver(~200 bins)——auto-generated cross 组合的稀疏 bins,constituent variable bins 全部已覆盖或单独 waived。其余包括 reserved encoding(ARM 保留的 page size 编码,RTL 永远不产生)、pipeline 内部信号(UT wrapper 不暴露 C3 stage)、config IT-scope(msid/EL2/security 模式需要 IT 级别测试)。
waiver 不是掩耳盗铃。waiver 是一种正式的"声明这个 bin 在当前验证级别不可达,并说明理由"的机制。effective coverage = covered / (total - waived) = 100%——这是行业标准做法。
一个让我们印象最深的发现
Sign-off 流程的 cross-synthesizer 在做 spec 和 RTL 的交叉对比时,主动标出了一条 warning:
某个需要 broadcast 失效的微架构模块——spec 说收到失效请求后应立即清空状态表项,RTL 实际行为是惰性清空(打 stale 标记,下次访问才真清空)。两者稳态等价,但在"失效完成到首次访问"的瞬态窗口里,可观测状态不同。
两位做过不止一代同类模块的资深工程师没发现过这个差异。看 spec 时大脑自动"等价化",看 RTL 时又已经接受了惰性清空这个事实——两边的视线从来没有在那一个瞬态窗口上交汇过。
不是 agent 比人聪明,是 agent 不带人的先验。资深工程师最大的优势——"看一眼就知道"——在某些场景下会转成劣势,它让人跳过"看起来没问题的地方"。agent 没有这种偏好。不是炫耀,是互补。
Skill 自我进化:把经验编码回流水线
ITLB sign-off 过程中踩了 11 个坑、做了 13 次人工决策。跑完之后我们问自己:下一个模块能不能少踩几个?
答案是:可以。方法是把经验分层编码回 skill。
Layer 1(已实施):工程加固——7 项
rm -f | rm -rf | |
预计效果:下一个模块的 Phase 0 启动成功率从 ~60% 提到 ~95%,减少 4 个人工阻塞点。
Layer 2(待验证):智能提案——5 项
自动检测 coverage 平台期(N 轮 < 0.5pp → 切到 hole analysis)、自动生成 waiver 提案(分 risk 等级,ckpt4 仍然人审)、checklist 阈值自动通过。
Layer 3(远期):Checkpoint 瘦身——3 项
ckpt2/ckpt4 改为"例外 review"——只展示异常项。需要在 5+ 模块上验证后才推进。
绝不动的:Phase 2 架构决策、ckpt5 最终签字、Type 3 mismatch 裁定。加速人的决策,不替代人的判断——这是 skill 自我进化的红线。
这才是这套工具最有价值的地方:不是某一次跑出了 99.86% 的覆盖率,而是每跑一个模块,skill 自己就变得更好一点。Phase 0 的启动越来越顺畅,常见的坑被自动绕过,但 Phase 2 和 Phase 6 的判断层始终由人把控。Flywheel 的终态不是"完全无人",是无摩擦的 80/20——80% 的体力活彻底消失,20% 的判断力被精准投放到最需要它的地方。
对行业的启示
芯片验证是 agent 闭环的天选甜区
大多数人的直觉:AI 在写文章、写业务代码、客服对话这些领域会先跑通。恰好相反。
芯片验证同时具备两个绝大多数领域没有的条件:方法论可编码为 Phase(UVM 20 年积累的不是 SystemVerilog 语法手册,是一套可执行的工作流,每一层的输入输出都有明确契约)+ 反馈信号客观且即时(line/branch/functional coverage 是数字,mismatch 是数字,编译错误是枚举,仿真器是客观裁判)。
大多数 agent 系统做不出真正的闭环,根源正在第二条——它们没有一个客观、即时的裁判。写业务代码的 agent 跑完一段,谁告诉它对错?通常是另一个更大的模型或者人,两者都不够客观不够即时。"agent 闭环的甜区"不是能力问题,是结构性契合问题。
Workflow Engineering:继 prompt / context engineering 之后的下一层
Prompt engineering 优化单次交互的措辞 Context engineering 优化单次交互的信息供给 - Workflow engineering 优化的是:多 agent 协作、反馈信号设计、人机分工边界
这三个 skill 本质上是一次 workflow engineering 实践。它们的价值不在于"某个 prompt 写得好",而在于整个 8 Phase 的分层结构 + 人机边界 + 反馈回路设计。最值钱的东西不是某一个 prompt,而是"把 Phase 2 和 Phase 6 留给人"这个决定。
验证工程师的价值在上移
原本手做的 6 个 Phase 被折叠进 agent 的执行层。但 Phase 2 和 Phase 6 被加粗了——这两步承担的判断责任比过去重。过去你写十行 sequence,现在你写一条边界。写一条边界的时间比写十行 sequence 短,但权重大得多。被折叠的是体量,不是价值。
一句话:你省下来的不是脑力,是体力;你需要增加的是判断力。
我们的判断
这条闭环的核心价值不是"省了多少时间",而是四件事:
第一,三个 skill 串联证明了 agent 闭环能在芯片验证里端到端跑通。从 spec 读取到 sign-off 签字,不是 demo,是一个能复用的流水线。UVM 20 年积累的方法论不是 AI 时代的负债,是工业底座。
第二,sign-off 过程中发现的 2 个采样 bug 比任何一个功能 bug 都有价值。debug-gated 信号让 functional coverage 永远是 0%——如果没有 verif-signoff-driver 的系统性 hole analysis,这个 bug 可能永远不会被发现,覆盖率数字会一直"看起来还行"。
第三,skill 自我进化把"一次性经验"变成了"可复用资产"。ITLB 踩的 11 个坑,7 个被编码进了 skill 的 Phase 0 逻辑。下一个模块跑同样的流水线,这 7 个坑不会再踩。这不是"用 AI 做了一个模块",是"用一个模块的经验升级了 AI"。
第四,人和 agent 的分工边界被实践验证了。80% 无人在环 + 20% 判断力密集——这个比例在 ITLB 上被证明是可行的。Phase 2 的架构决策和 Phase 6 的语义裁定,目前看不到自动化的可能,也不应该自动化。
这套方法不是银弹。它最适合中等复杂度、规格清晰、方法论成熟的模块级验证场景。对于超大规模设计或规格模糊的场景,仍需人工深度参与。但这正是工具的价值——不是替代人,是让人知道自己应该把判断力花在哪一个格子里。
延伸思考
按"方法论可编码 + 反馈信号客观"这两个条件看,有几个值得尝试的相邻领域:
- 编译器优化:IR 一致性 + 性能 benchmark
- 数据库 query planner:查询结果正确性 + 执行时间
- DFT 设计自动化:规则库 + 测试覆盖率
- 物理综合质量检查:时序、面积、功耗都是硬指标
- RTL lint:规则库 + 规则违反数
另一个值得思考的方向:skill 自我进化的 flywheel。每跑一个模块,skill 就从中学到几条新规则。跑得越多,Phase 0 的启动越顺畅,人工决策点越少,但 Phase 2/6 的判断层始终由人把控。这个 flywheel 的终态不是"完全无人",是"无摩擦的 80/20"。
点这里👆加关注,锁定更多原创内容
*免责声明:文章内容系作者个人观点,半导体芯闻转载仅为了传达一种不同的观点,不代表半导体芯闻对该观点赞同或支持,如果有任何异议,欢迎联系我们。
推荐阅读

喜欢我们的内容就点“在看”分享给小伙伴哦~

