 夜雨聆风
夜雨聆风声明
本系列文章只是一组阶段性的思考与实践记录,主要用于抛砖引玉,并不构成对所有学科、所有工具或所有研究场景都适用的标准答案。由于 AI 工具迭代很快,本文中的部分判断、界面描述与工作流经验都具有较强时效性,随着模型、插件和平台的发展,后续很可能需要重新修订,因此也请读者结合自己的实际情况自行甄别。另需特别说明:本文讨论的是 AI 对研究工作区、材料组织与日常流程的辅助作用,而不是鼓励任何形式的学术不端。无论工具如何发展,文献理解、研究判断、结果核查与学术责任都不能外包给 AI。
此文章中的示意图与分析图由Gemini Nano Banana Pro生成,特此声明。
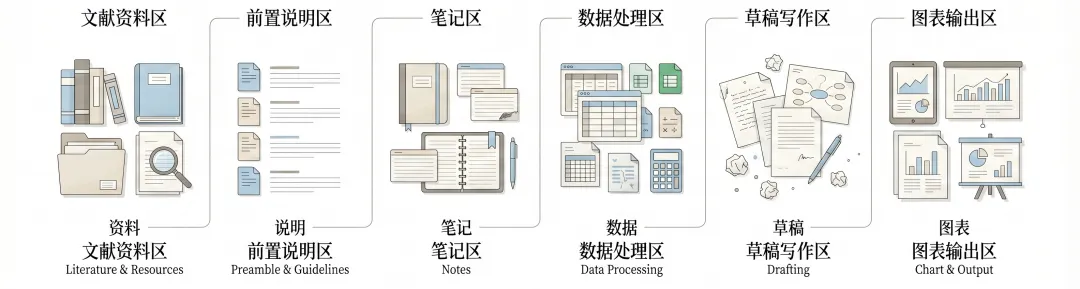
如果第一期讨论的是“AI 在研究里应该放在什么位置”,那么第二期就需要进一步回答一个更实际的问题:这些工具到底依附于什么样的环境,才能稳定发挥作用。答案并不复杂,不是提示词先行,而是工作环境先行。
这里先把门槛放低一点。所谓“工作区”,不必急着把它想成一个很专业的术语。你现在手头如果已经有一个放文献的文件夹,有一个保存草稿的地方,有一个专门记笔记的软件或目录,再加上几张图表、几份表格和一些零散说明,那其实就已经构成了你的研究工作环境。只是很多时候,这些材料虽然都在,却没有被有意识地组织起来。于是项目一旦持续推进,问题就会慢慢出现。资料找不到,版本分不清,图表不知道对应哪一稿,自己隔几天回来看都要先回忆半天,更不用说让别人或 AI 迅速理解现场。

这其实也是现代研究和工具演化之间一个很典型的矛盾。研究越来越像项目,材料越来越像系统,然而很多人的文件管理方式却仍然停留在“哪里顺手先放哪里”。在任务还很轻的时候,这种做法问题不大;一旦时间拉长、材料增多、任务并行,混乱就会很快显形。更重要的是,科研和一般性的临时写作并不完全一样。它往往带有明确的问题链条、阶段节点、版本责任和结果可回查的要求。你今天做的判断、保存的文件、写下的说明,迟早都要在之后的某一天被重新接上,甚至被拿去解释、答辩、修改、复核。如果没有一个像样的环境,这种接续就会越来越费力。也正因为如此,工作区的重要性并不来自某种技术潮流,而来自研究劳动本身对连续性、可追溯性和责任边界的要求。
所以真正值得做的,不是急着追求复杂自动化,而是先把研究材料放到一个相对清楚的结构里。这里说的“清楚”,并不意味着非要搭一套庞大系统,而是至少让原始材料、草稿、图表、工具文件和说明文件彼此有基本区分。命名尽量稳定,别把“最终版”“最后版”当作长期习惯。关键目录里尽量留一点说明,哪怕只有几句话,也比完全靠记忆可靠。
一旦这样做了,你会发现“工作区”这个词其实并不玄。它说到底不过是在提醒你,研究不是一篇孤立文档,而是一组彼此有关联的材料。只有把这些材料放得明白,后面的协作——无论是你自己回看,还是让 AI 帮忙——才有可能真正顺起来。
这里尤其值得单独说的是索引文件。很多人会觉得,目录清楚就够了,为什么还要写 README、目录说明或者索引。原因其实很简单:目录结构只能告诉你“这里有什么”,索引文件则能进一步说明“这些东西大致是做什么的”。对于重新打开项目的自己来说,这很有用;对于刚开始接手目录的 AI 来说,这更有用。它可以少花很多时间在猜测文件作用上,而把注意力更快放到真正的任务上。
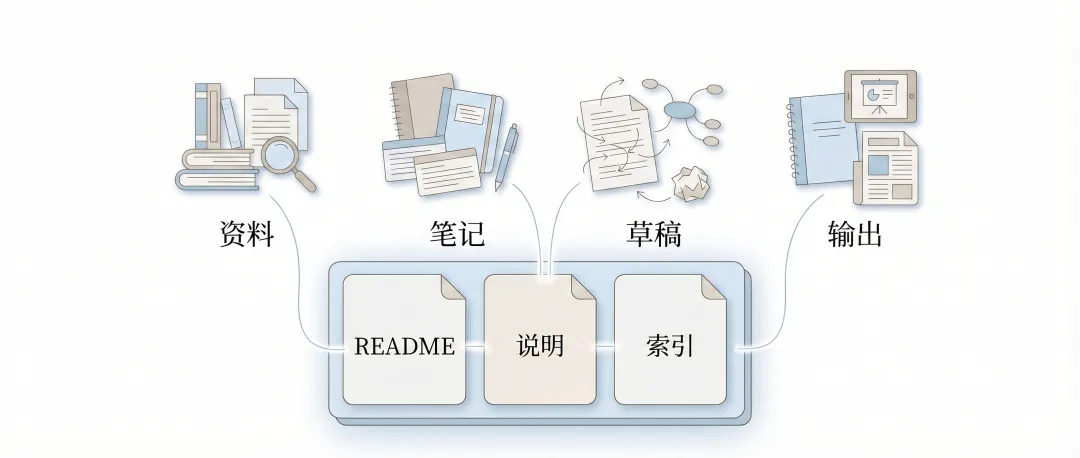
如果再往深一点看,索引文件的价值其实不只在于方便查找。它还是工作区从“文件堆”变成“项目现场”的标志。文件堆只有内容,没有解释;项目现场既有内容,也有最基本的自我说明。对于学术工作来说,这一点尤其重要。因为研究中的很多材料并不是看文件名就能完全理解其作用的。一个表格可能只是中间处理结果,一张图可能只是汇报草图,一份摘要可能只是临时摘录。要让这些材料在时间上保持可回溯,在结构上保持可理解,最经济的办法往往不是记忆力,而是显式说明。
除了目录和索引,还有一个更技术、却不该回避的问题,那就是编码。中文用户在 Windows 环境里做研究,很难完全绕开 UTF-8、UTF-8 with BOM、GBK 这些编码之间的摩擦。平时也许感觉不到,一旦牵涉 PowerShell、CSV、Markdown、脚本读写或者旧文档导出,问题就可能突然出现。没有人希望一份已经写好的文档打开之后变成乱码(你也不想自己的论文被Codex看完之后变成锟斤拷烫烫烫吧),也没有人愿意把时间花在这种本可预防的地方。所以比较稳妥的做法,是在工作环境一开始就把编码约定尽量统一。这个动作看上去很小,却是在保护你已经写出来的内容。
这里还需要补一句:工作环境并不是程序员专属概念。很多不怎么写代码的人,也一样有自己的研究现场,只是以前没有这样命名而已。你存 PDF 的文件夹、记笔记的目录、导出的图表、做汇报的文档、保存草稿的地方,本来就构成了这套环境。现在的变化,只是你开始有意识地把它组织起来,并让一个工具能够在其中持续协作。
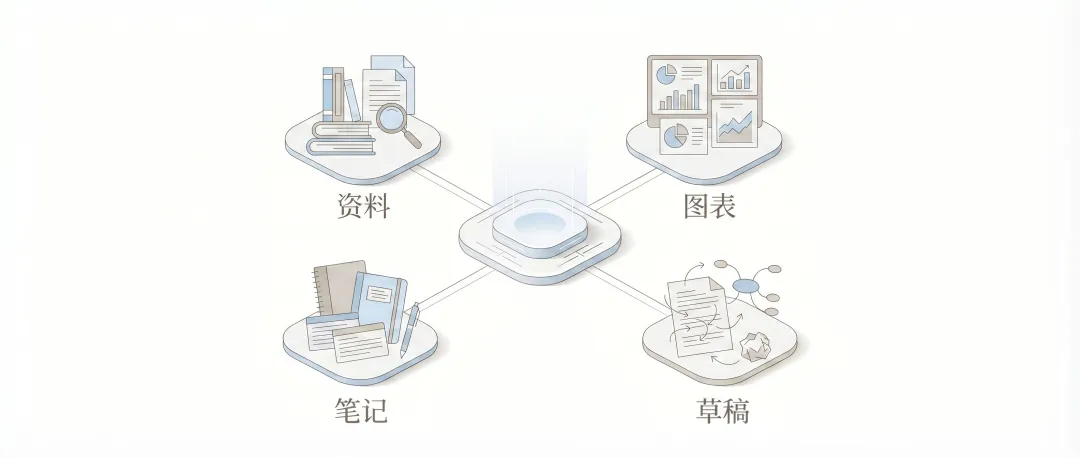
如果进一步概括,一个好的研究工作环境至少应当满足两个要求。第一,它能帮你自己减少混乱。第二,它能让后来的自己,或者外部协作者,快速理解现场。这里的“外部协作者”不一定是别人,也可以是今天的 AI,或者一周之后重新打开项目的你;在更典型的科研场景里,它也可能是导师、同门、合作者,甚至是几个月之后回来补材料、改图表、补附录的你自己。只要一个目录能让后来的自己顺利接上之前的工作,它就已经是有效的;只要一个目录能让合作者或 AI 少问很多不必要的问题,它就已经开始产生价值。
也正是在这个意义上,日志、索引、编码约定乃至后面要谈到的 AGENTS.md,才会显得重要。它们并不夺目,却共同构成了一个工作环境的“可接手性”。如果说日常文件夹管理更多是在追求方便,那么研究工作区管理其实还多了一层“交代得清楚”的要求。你不仅要自己找得到,还要在需要的时候说得明白:这一版从哪里来,这个图是怎么做出来的,这个判断对应哪一批材料,这个阶段为什么这样推进。研究中最怕的,从来不是材料多,而是材料多了以后没有结构;也不是工具强,而是工具强了以后没有边界。工作区的作用,恰恰就是在两者之间建立秩序。
因此,与其把工作区理解成一种额外负担,不如把它理解成研究过程最基础的一层整理。它不负责替你做判断,但它会决定你的判断能否在一个清楚、可追溯、可维护的环境中持续展开。没有这一层,再强的 AI 也只能在局部帮忙;有了这一层,后面的协作才真正有可能变得稳定。
下一期我们就从这里继续往前走,讨论当这些基础打稳以后,Codex 这类工具究竟能怎样进入现场,辅助文档、脚本和文献整理。
